Amazon Bedrock を活用した AI エージェントによる自己サービス型 AWS ヘルス分析の構築
AWS は、Amazon Bedrock と MCP を活用したオープンソースの AI エージェント「Chaplin」を発表し、企業の AWS 運用チームが自然言語で健康イベントを分析・優先順位付けできるセルフサービス機能を実現しました。
キーポイント
Chaplin の概要と目的
AWS Health イベントの分析を自動化するオープンソースソリューション「Chaplin」が公開され、AI エージェントを通じて自然言語で質問できるセルフサービス機能を提供します。
MCP と AI エージェントの活用
Model Context Protocol (MCP) を介して AI アシスタントと連携し、AWS サポートへの依存を減らしつつ、コンテキストに即した正確な分析結果を迅速に得られるようになります。
運用課題の解決
従来の TAM 依存や手動分類によるボトルネックを解消し、反応的な対応から予防的・戦略的な意思決定へと運用プロセスを転換させることを目指しています。
影響分析・編集コメントを表示
影響分析
この記事は、クラウド運用における「AI エージェント」の実用化事例を示す重要な一歩であり、複雑なインフラ情報を自然言語で処理できるツールの登場が、企業の DX や DevOps 文化に大きな影響を与える可能性があります。特に MCP という標準プロトコルを採用することで、AWS 独自のツールだけでなく、汎用的な AI アシスタントとの連携を容易にし、業界全体のセルフサービス分析の基準を変える可能性があります。
編集コメント
「Chaplin」という具体的なプロジェクト名と、MCP という最新のプロトコルを組み合わせることで、AWS のヘルスケア情報を扱う際の AI エージェントの導入ハードルを劇的に下げた点が評価できます。
典型的な月曜日の朝、企業の運用チームは、50 以上のアカウントにまたがる Amazon Linux 2 のサポート終了、RDS バージョンの非推奨、EC2 インスタンスの廃止などに関する複数の AWS Health 通知を受け取ります。セルフサービス分析がない場合、チームには生産システムに影響を与えるイベントを迅速に特定したり、即時対応が必要なイベントと長期的な計画を要するイベントを区別したり、各イベントカテゴリのビジネスへの影響を理解したりする方法がありません。
運用チームはまた、Technical Account Managers (TAM) が健康イベントを解釈するのを待たされるため時間を費やしており、重要な運用決定に遅れが生じます。その結果、イノベーションよりも反応的な消火活動に時間が割かれることになります。
本稿では、Model Context Protocol (MCP) を通じて公開された AI エージェントを活用し、セルフサービスの健康イベント分析を提供するオープンソースソリューション「Chaplin」(Customer Health and Planned Lifecycle Intelligence Nexus) の構築方法をご紹介します。Chaplin により、チームは MCP 互換の AI アシスタントから自然言語で質問を行い、AWS サポートに依存することなく、正確で文脈を考慮した回答を受けることができます。詳細なデプロイ手順については、Chaplin AWS Health Agentic Assistant GitHub リポジトリをご覧ください。
課題:反応的なヘルスイベント管理
AWS で本番ワークロードを実行している企業は、数十から数百のアカウントにわたるサービス変更、メンテナンスウィンドウ、セキュリティパッチ、運用通知など、絶え間ないヘルスイベントのストリームを管理しています。AWS Health は AWS Health API と Amazon EventBridge を通じて包括的なイベントデータを提供しますが、反応的な管理アプローチには課題が残ります。
- チームは TAM(Technical Account Manager)に依存してヘルスイベントの解釈や影響分析を行っており、意思決定にボトルネックが生じています。事前定義されたスキーマを持つビジネスインテリジェンスダッシュボードでは、動的な質問に対応できず、運用チームがその場で必要とする文脈に基づいた洞察を提供できません。
- DevOps およびクラウド運用チームは、複数のアカウントやリージョンに散在する数千のヘルスイベントを手動で分類し優先順位をつけるために多大な時間を費やしています。分析のための中央集約場所がないため、全体的な影響を評価したり、チーム間で対応を調整したり、問題が深刻化する前に移行計画を立てたりメンテナンスをスケジュールしたりするといった予防的な機会を特定したりすることが困難です。
対象となるヘルスイベントは間もなく AWS Transform テンプレートに直接リンクされ、顧客がイベントに対して直接アクションを起こせるようになります。Chaplin は、お客様の環境におけるこれらの実行可能なイベントを抽出し、優先順位付けを行います。
ソリューション概要:Chaplin を活用したセルフサービス分析
Chaplin は、Amazon Bedrock によって駆動されるエージェント型 AI(Agentic AI)を活用し、Model Context Protocol (MCP) を通じてセルフサービスのヘルスイベント分析を実現します。事前に定義されたダッシュボードスキーマの代わりに、Chaplin は MCP 互換クライアントが利用可能な AI 駆動ツールを公開しています。チームは、Claude Code や Kiro CLI などの AI アシスタントから直接 Chaplin と対話し、自然言語で質問を行います。例えば、チームメンバーは「今後 60 日間の RDS のライフサイクルイベント」を尋ねたり、「緊急性に基づいて優先順位付けされた未解決の EC2 イベントの要約」を要求したり、生産環境に影響を与えるセキュリティパッチを照会したり、高優先度のアプリケーションに影響を与える可能性のあるメンテナンスウィンドウを確認したりすることができます。
必要な情報がすべて揃い、根拠ある意思決定を行い是正計画を策定するまで、チームは引き続きクエリを実行し続けることができます。このアプローチにより、DevOps、セキュリティ、運用チームはボトルネックを生み出すことなく、独自にヘルスイベントを分析し、移行を計画し、運用への影響を評価することが可能になります。Chaplin は MCP を採用しているため、チームはワークフロー内で他の MCP 対応ツール(JIRA、GitHub、ServiceNow など)と組み合わせることもでき、エージェント型エクスペリエンスでアクションを実行することもできます。
さらに、MCP は AWS データおよびメタデータを、リソースタグ、環境分類、所有権情報など、ビジネスまたはアプリケーションレベルのコンテキストと直接関連付けることを可能にし、組織的な文脈を付与することで健康イベント分析を強化します。
エージェント型 AI が構造化データと非構造化データを統合する方法
Chaplin は、エンタープライズデータ分析における根本的な課題である、構造化データと非構造化データの処理を効果的に組み合わせることを解決するマルチエージェントアーキテクチャを採用しています。従来の検索拡張生成(RAG: Retrieval-Augmented Generation)システムや生成 AI アプローチには重要な限界があります。すなわち、数値演算や集計処理において本質的に非確定的である点です。RAG の基盤となるベクトル類似度検索は意味的に類似したコンテンツを抽出しますが、数学的な正確性を保証することはできません。データのカウント、合計、または集計を求められた場合、RAG ベースのシステムは結果を捏造する可能性があります(例えば、ライフエンドに関連する健康イベントが 958 件あるにもかかわらず、190 件と報告されるなど)。この非確定性は、文書を検索するメカニズム(完全一致ではなく意味的類似度に基づいてドキュメントをランク付けする)および言語モデルの生成プロセス(正確な値を計算するのではなく、可能性の高いトークンを予測する)という両方の要素が確率的性質を持つことに起因しています。
AWS Health のイベントはまさにこの課題を提示します。各イベントには、構造化されたメタデータが含まれており、イベントタイプ、サービス名、影響を受けるリソース、タイムスタンプ、深刻度レベル、アカウント ID などが含まれ、これらには正確なフィルタリングと集約が必要です。また、各イベントには自然言語による問題の説明、影響評価、推奨アクションを含む非構造化記述も含まれており、これらには意味理解と文脈分析が求められます。
インテリジェントクエリ処理
Chaplin に質問すると、3 つの専門コンポーネントが連携して動作します。自然言語から構造化クエリへのエージェントは、健康イベントメタデータに対する正確な構造化データクエリを、平易な英語の質問に変換します。これは健康イベントのスキーマを理解しており、event_type、affected_accounts、start_time などのフィールドが存在するかどうかも把握し、ユーザーの意図に一致するフィルタを構築します。「生産環境アカウントでの EC2 の廃止を表示して」といった質問は、キーワードマッチングではなく、正確なフィールドフィルタを持つ構造化クエリに変換されます。
- コンテキスト影響分析エージェントは、構造化されていない健康イベントの説明を、お客様のメタデータ(本番環境と非本番環境の区別、事業部門、アプリケーションティア、所有権情報など)と組み合わせることで処理します。このエージェントはシステムレベルでの推論を行い、イベントが何を述べているかだけでなく、特定のインフラストラクチャや組織文脈においてそれが何を意味するかを解釈します。
- パターンベース分類エンジンは、ルールベースのパターンマッチングを用いて健康イベントをカテゴリ分類します。これにより、一般的なカテゴリ分類における AI 処理コストを削減しつつ、高い精度を維持できます。このコスト最適化レイヤーが、大規模展開において本ソリューションを実用的なものにしています。
コスト最適化された AI アーキテクチャ
Chaplin は、選択的な AI 強化を通じてインテリジェントなコスト最適化を実現しています。このシステムは、ルールベースの分類がほとんどのイベントを処理し、AI コストが発生しないようにするパターンファースト処理アプローチを採用しています。30 日、60 日、120 日の期間に対応したフィルター付きの事前構築済み要約ビューにより、チームは重要なアラートを迅速に特定できます。現在の実装では、Amazon Bedrock と Claude は、文脈分析を必要とする非構造化データのみを処理します。ただし、このソリューションは LLM(大規模言語モデル)に依存しない設計であり、Amazon Bedrock、OpenAI、Anthropic などの複数のモデルプロバイダーや、Ollama などのローカルモデルをサポートしています。これにより、要件とコスト制約に基づいた柔軟な対応が可能となります。インテリジェントなキャッシングにより冗長な AI 処理が削減され、構造化クエリの精度は AWS Health API のスキーマ(schema)を使用することで、AI 推論コストを伴わずに正確な数値分析を実現します。
アーキテクチャ概要
以下の図は、Chaplin の完全なアーキテクチャを示しています。これは、健康イベントが複数の AWS アカウントから中央集権型のデータパイプラインを経由し、Amazon Bedrock 上で構築された AI エージェントによって駆動される MCP サーバーへ流れ込み、最終的に MCP 互換の AI アシスタントに至るまでのプロセスを説明するものです。チームはここで自然言語を通じてデータと対話します。各レイヤーについては、図の後に詳細に記述されます。
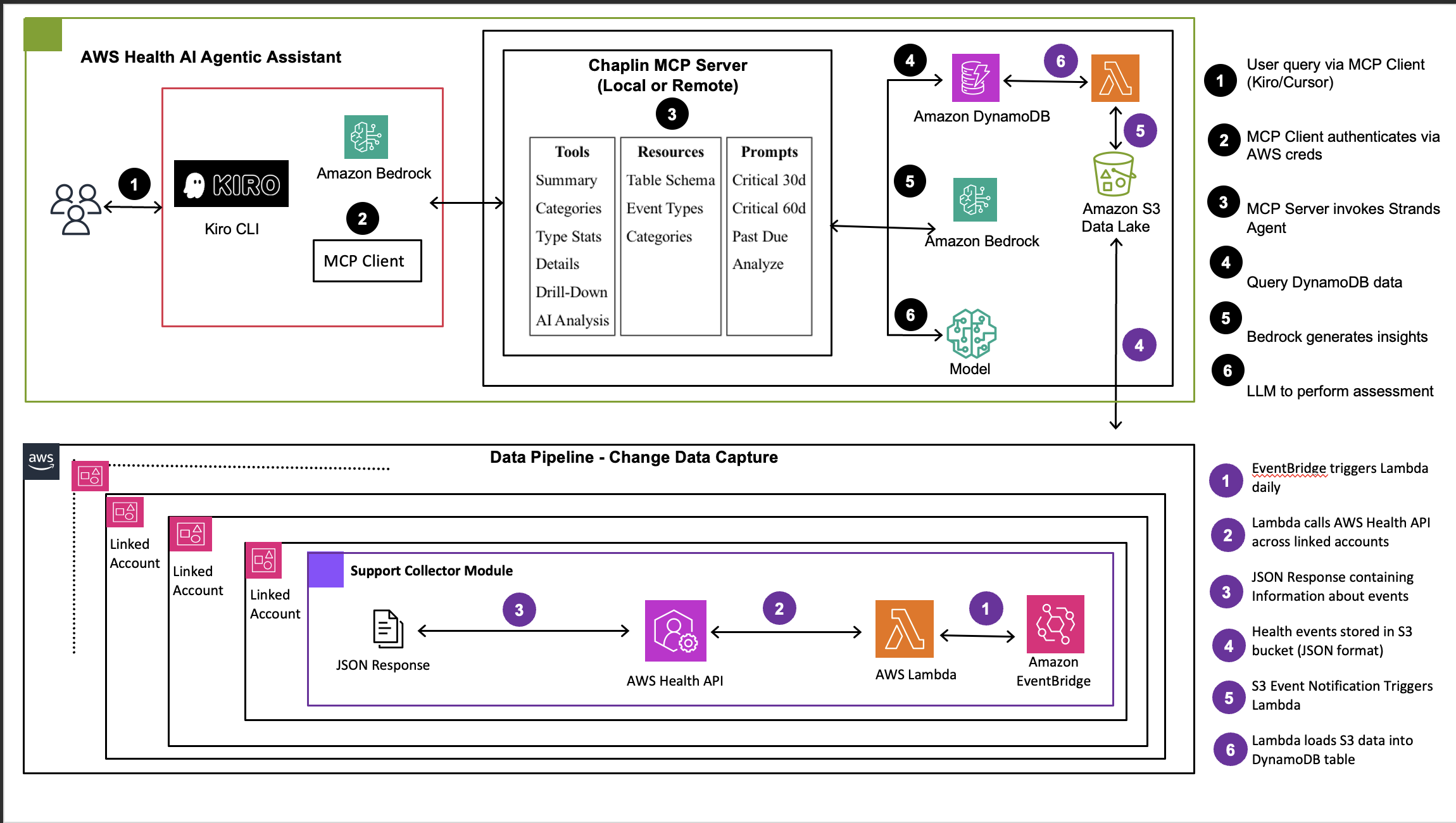
Figure 1: Chaplin architecture showing three-layer system with multi-account data collection, AI-powered MCP server with Amazon Bedrock agents, and MCP client integration"
このアーキテクチャは、インテリジェントなヘルスイベント分析を提供するために連携して動作する 3 つの主要なレイヤーで構成されています。
1. データ層 – 収集層(マルチアカウント)
データ層は、AWS Organization 全体からヘルスイベントを収集し、分析のために一元化します。各メンバーアカウントでは、AWS Health API がヘルスイベントのソースとして機能します。Amazon EventBridge はリアルタイムキャプチャのためのイベント駆動型トリガーを提供し、AWS Lambda コレクター関数は、最小権限アクセスで構成されたクロスアカウント IAM ロールを使用してイベントを取得します。
これらのイベントは、中央管理アカウントに流れ込み、そこでは Amazon Simple Storage Service (Amazon S3) データレイクが、アカウント、日付、イベントタイプごとにインテリジェントなパーティショニングを行って収集されたヘルスイベントを保存します。新しいイベントが到着すると、S3 イベント通知が AWS Lambda 関数をトリガーし、JSON 形式のヘルスイベントを処理して、高速クエリのために Amazon DynamoDB にロードします。
このマルチアカウントアーキテクチャは、2 つのデプロイメントモデルをサポートしています:
- オプション 1: AWS Organizations API を使用した、全アカウントにわたる中央集権的かつ自動化されたデプロイメント。
- オプション 2: セキュリティ制限のある組織向けの個別アカウントごとのデプロイメント。
2. ミドルティア – MCP サーバーとインテリジェンス層
ミドルティアは、生きた健康イベントデータをアクション可能なインテリジェンスに変換し、MCP サーバーを通じて公開する場所です。Amazon DynamoDB は、構造化された健康イベントメタデータの主要なデータストアとして機能し、イベントタイプ、重大度、日付、アカウントにインデックスを設けることで高速クエリに最適化されています。これにより、パターンベースの分類と AI 分析の両方に対してリアルタイムアクセスが可能になります。
パターンベースのイベント分類器が最初のインテリジェンス層を提供します。このルールベースのカテゴライゼーションエンジンは、イベントタイプに対する正規表現(regex)パターンを使用して、イベントを以下の 5 つのビジネスカテゴリにマッピングします:移行要件、セキュリティとコンプライアンス、メンテナンスとアップデート、コスト影響イベント、および運用通知です。ほとんどのイベントが予測可能なパターンに従うため、このアプローチでは AI コストを発生させることなく、効率的なパターンマッチングを通じて大多数のイベントを処理します。
より深い分析を要するイベントについては、Amazon Bedrock を基盤とした AI 駆動の分析エンジンが引き継ぎます。このエンジンは、AWS が開発したオープンソースのエージェント型フレームワークである Strands Agents フレームワークを採用し、大規模言語モデルには Claude 4.5 Sonnet を使用しています。必要に応じて、お好みの他の LLM に切り替えることも可能です。分析の異なる側面を担う 3 つの専門エージェントが存在します:SQL クエリ エージェントは自然言語によるクエリを構造化された DynamoDB クエリに変換し、正確な数値分析を実現します。インパクト分析エージェントは、環境、事業部、所有権などの顧客メタデータと照合して、非構造化のイベント記述を評価します。また、DBQueryBuilder エージェントは多次元集計のための最適化されたデータベースクエリを生成します。これらの機能すべてが MCP ツールとして公開されており、互換性のあるクライアントが呼び出すことができます。
3. プレゼンテーション層 – MCP クライアント – AI アシスタントの統合
プレゼンテーション層には、Claude Code や Kiro CLI などの MCP 対応 AI アシスタントが含まれます。カスタムのフロントエンドを設けるのではなく、Chaplin はその機能を MCP ツールとして公開し、これらのクライアントがネイティブに利用できるようにしています。ユーザーは既存の開発環境内で自然言語を通じて対話を行い、AI アシスタントが Chaplin の MCP サーバーへの呼び出しを調整して、ヘルスイベントデータの取得、AI 駆動分析の実行、文脈に応じた結果の提示を行います – これらすべてが、開発タスクにすでに使用している同じ会話型インターフェース内で行われます。
セキュリティは、認証と認可のために AWS Identity and Access Management (AWS IAM) に依存しています。MCP クライアントは AWS 資格情報を読み取り専用としてマウントし、アクセスは最小権限の原則に基づいて IAM ロールを通じて制御されます。データは転送中に TLS 1.2+ で暗号化され、保存時には AES-256 で暗号化されており、AWS CloudTrail が API コールの監査ログを提供します。
主要な機能
Chaplin は、組織が現在 AWS Health イベントを管理する方法におけるギャップに対応する 3 つのコア機能を備えています。
Chaplin は動的な会話型分析を提供します。これは、特定の質問に基づいてオンデマンドで実行可能なインサイトを生成し、事前構築されたレポートやダッシュボードなしに AI アシスタント内で動的に生成される、正確なカウント、影響を受けるアカウント、および文脈分析を含む精密な内訳を提供します。Chaplin は以下の 3 つの統合機能を通じてこれを実現します。
MCP 搭載ヘルスインテリジェンスツール
Chaplin は包括的な MCP ツールセットを公開しており、これらは 3 つのカテゴリーに整理されています。サマリーツールは DynamoDB に直接クエリを実行し即座に返答し、サービス、ステータス、カテゴリ、およびリージョンごとの高レベルなカウントを提供します。ディテールツールを使用すると、特定のエベントカテゴリ、イベントタイプ、またはフィルタリングされたイベントリストの詳細を掘り下げることができます。AI 分析ツールは、Strands Agents と Amazon Bedrock を使用して自然言語のクエリを解釈し、関連データを取得して文脈に即したインサイトを生成します。
マルチアカウントデータパイプライン
Chaplin は、お客様の AWS アカウントからヘルスイベントを収集し、セキュリティ状況に基づいた柔軟なデプロイモデルをサポートしながら、データを Amazon S3 に集約します。このデータパイプラインは、自動化されたヘルスイベントの取り込みを行う AWS Lambda 関数、設定可能な収集頻度(日次または時間単位)を持つ Amazon EventBridge スケジューラ、最小権限の原則に基づいた安全なマルチアカウントデータ収集のためのクロスアカウント IAM ロール、効率的なクエリを可能にするパーティショニングを備えた Amazon S3 データレイク、および設定可能な保持ポリシーによる自動化されたライフサイクル管理で構成されています。
精密な分析処理
Chaplin は包括的な分析のために構造化データと非構造化データの両方の処理を組み合わせています。構造化データについては、イベント数や分布といった正確な数値結果、トレンド検出を伴うタイムライン分析、アカウント、サービス、深刻度という多次元軸にわたる集計、そして正確なパーセンテージを含むカテゴリ別内訳を提供します。非構造化データについては、イベント説明に基づく影響評価、アーキテクチャ上の欠陥の特定、関連するイベント間のリスク相関、およびイベントの文脈に基づいた推奨アクションといった文脈的な洞察を提供します。
実装ウォークスルー:EC2 インスタンスのライフサイクル管理
Chaplin が何ができるかその範囲を示すために、以下のウォークスルーでは Kiro CLI を通じて発行された一連の自然言語クエリを紹介しています。これらの例は、運用上の概要を素早く把握することから、特定サービスへの詳細な調査、そして修復計画の策定に至るまで、ユースケース別に整理されています。
注:以下の例は Chaplin の機能を説明するためにサンプルデータを使用しています。実際の回答は、お客様の AWS 環境内のヘルスイベントに応じて異なります。
運用状況の把握
一日を始めたチームは、アカウント全体にわたる現在のヘルスイベントの状態を素早く評価し、即座に対応が必要な事項を特定できます:

Tier-1 生産用アカウントにおける RDS PostgreSQL の非推奨(deprecation)の推定影響は、リスクのある月額支出に基づいてランク付けするとどうなりますか?
★
Chaplin の回答
すべてのイベントはAWS_RDS_PLANNED_LIFECYCLE_EVENTタイプです。10 件のアカウントのうち 6 件がすでに期限を過ぎています。最も古いのは CustomerSupport-production-5365(2024 年 10 月)です。Orders アカウントの 2026 年 5 月 15 日が、最も緊急性の高い今後のイベントです。
● Tier-1 アカウント
6 件のアカウント | 14 のイベント | リスクのある月額支出 $304,400
Account(アカウント)
BU(事業部門)
Division(部署)
Spend/mo(月額支出)
Events(イベント数)
Deadline(期限)
Analytics-production-8137
<td style="color: #1f2328;padding: 10px 12px;border-bottom
原文を表示
On a typical Monday morning, an enterprise operations team receives multiple AWS Health notifications about Amazon Linux 2 end-of-life, RDS version deprecations, and EC2 instance retirements across 50+ accounts. Without self-service analytics, the team has no way to quickly identify the events that affect production systems, the events that require immediate action versus long-term planning, and the business impact of each event category.
Operations teams also spend time waiting for Technical Account Managers (TAMs) to interpret health events, adding delays to critical operational decisions. The result is time spent on reactive firefighting rather than innovation.
In this post, we show you how to build Chaplin (Customer Health and Planned Lifecycle Intelligence Nexus), an open source solution that uses AI agents exposed through the Model Context Protocol (MCP) to provide self-service health event analytics. With Chaplin, teams can ask questions in natural language directly from MCP-compatible AI assistants and receive precise, contextualized answers without depending on AWS Support for routine analysis. Detailed deployment instructions are available in the Chaplin AWS Health Agentic Assistant GitHub repository.
The challenge: Reactive health event management
Enterprises running production workloads on AWS manage a constant stream of health events – service changes, maintenance windows, security patches, and operational notifications – across dozens or hundreds of accounts. AWS Health provides comprehensive event data through the AWS Health API and Amazon EventBridge, but reactive management approaches leave gaps.
- Teams depend on TAMs for health event interpretation and impact analysis, creating bottlenecks in decision-making. Business intelligence dashboards with predefined schemas cannot adapt to dynamic questions or provide the contextual insights that operations teams need in the moment.
- DevOps and cloud operations teams spend significant time manually categorizing and prioritizing thousands of health events scattered across multiple accounts and regions. Without a central location for analysis, it is difficult to assess overall impact, coordinate responses across teams, or identify proactive opportunities – such as planning migrations or scheduling maintenance before issues become critical.
Eligible Health events will soon be linked directly to AWS Transform templates, enabling customers to act on events directly. Chaplin can surface and prioritize these actionable events for your environment.
Solution overview: Self-service analytics with Chaplin
Chaplin implements self-service health event analytics using agentic AI powered by Amazon Bedrock, delivered through the Model Context Protocol (MCP). Instead of predefined dashboard schemas, Chaplin exposes AI-powered tools that MCP-compatible clients can consume. Teams interact with Chaplin directly from their AI assistant – such as Claude Code or Kiro CLI – and ask questions in natural language. For example, a team member might ask for upcoming RDS lifecycle events in the next 60 days, request a summary of open EC2 events prioritized by urgency, query security patches affecting production environments, or check which maintenance windows could affect high-priority applications.
Your teams can continue to query until you have all the information required to make an informed decision and draw up a remediation plan. This approach enables DevOps, security, and operations teams to independently analyze health events, plan migrations, and assess operational impacts without creating bottlenecks. Because Chaplin uses MCP, teams can also combine it with other MCP-enabled tools (like JIRA, GitHub, or ServiceNow) in their workflow to perform actions with agentic experience.
Additionally, MCP enables direct association of AWS data and metadata with business or application-level context – such as resource tags, environment classifications, and ownership information – enriching health event analysis with organizational relevance.
How agentic AI unifies structured and unstructured data
Chaplin uses a multi-agent architecture that addresses a fundamental challenge in enterprise data analytics: effectively combining structured and unstructured data processing. Traditional Retrieval-Augmented Generation (RAG) systems and generative AI approaches face a critical limitation: they are inherently non-deterministic when handling numerical operations and aggregations. Vector similarity search, the foundation of RAG, retrieves semantically similar content but cannot guarantee mathematical accuracy. When asked to count, sum, or aggregate data, RAG-based systems may hallucinate results (for example, reporting 190 health events related to End-of-life when the actual count is 958). This non-determinism stems from the probabilistic nature of both the retrieval mechanism (which ranks documents by semantic similarity rather than exact matches) and the language model’s generation process (which predicts likely tokens rather than computing precise values).
AWS Health events present this exact challenge. Each event contains structured metadata – event type, service name, affected resources, timestamps, severity levels, and account IDs – that requires precise filtering and aggregation. Each event also contains unstructured descriptions with natural language explanations of the issue, impact assessments, and recommended actions that require semantic understanding and contextual analysis.
Intelligent query processing
When you ask Chaplin a question, three specialized components work together. The Natural Language to Structured Query Agent converts plain English questions into precise structured data queries against health event metadata. It understands the schema of your health events – which fields exist, such as event_type, affected_accounts, and start_time – and constructs filters that match your intent. A question like “Show me EC2 retirements in production accounts” becomes a structured query with exact field filters rather than keyword matching.
- The Contextual Impact Analysis Agent handles unstructured health event descriptions by combining them with your customer metadata – production vs. non-production environments, business units, application tiers, and ownership information. This agent performs system-level reasoning, interpreting not just what the event says but what it means for your specific infrastructure and organizational context.
- The Pattern-Based Classification Engine categorizes health events using rule-based pattern matching, which eliminates AI processing costs for routine categorization while maintaining high accuracy. This cost optimization layer makes the solution practical at scale.
Cost-optimized AI architecture
Chaplin implements intelligent cost optimization through selective AI enhancement. The system uses a pattern-first processing approach where rule-based classification handles most events without incurring AI costs. Pre-built summarized views for 30-day, 60-day, and 120-day windows with filters help teams quickly identify critical alerts. In the current implementation, Amazon Bedrock with Claude processes only unstructured data that requires contextual analysis. But the solution is also LLM-agnostic, supporting multiple model providers such as Amazon Bedrock, OpenAI, Anthropic, or local models like Ollama, providing flexibility based on your requirements and cost constraints. Intelligent caching reduces redundant AI processing, and structured query precision uses the AWS Health API schema for exact numerical analysis without AI inference costs.
Architecture overview
The following diagram illustrates the complete Chaplin architecture. It shows how health events flow from multiple AWS accounts through a centralized data pipeline, into an MCP server powered by AI agents built on Amazon Bedrock, and finally to MCP-compatible AI assistants where teams interact with the data through natural language. Each layer is described in detail after the diagram.
Figure 1: Chaplin architecture showing three-layer system with multi-account data collection, AI-powered MCP server with Amazon Bedrock agents, and MCP client integration”
The architecture consists of three primary layers working together to deliver intelligent health event analytics.
1. Data tier – Collection layer (multi-account)
The data tier collects health events from across your AWS Organization and centralizes them for analysis. In each member account, AWS Health API serves as the source of health events. Amazon EventBridge provides event-driven triggers for real-time capture, and AWS Lambda collector functions retrieve events using cross-account IAM roles configured with least-privilege access.
These events flow to a centralized management account where an Amazon Simple Storage Service (Amazon S3) data lake stores collected health events with intelligent partitioning by account, date, and event type. When new events arrive, S3 event notifications trigger an AWS Lambda function that processes the JSON health events and loads them into Amazon DynamoDB for fast querying.
This multi-account architecture supports two deployment models:
- Option 1: AWS Organizations API for centralized, automated deployment across your accounts.
- Option 2: Individual account deployments for organizations with security restrictions.
2. Middle tier – MCP server and intelligence layer
The middle tier is where raw health event data is transformed into actionable intelligence and exposed through an MCP server. Amazon DynamoDB serves as the primary data store for structured health event metadata, optimized for fast queries with indexes on event type, severity, date, and account. This enables real-time access for both pattern-based classification and AI analysis.
A pattern-based event classifier provides the first layer of intelligence. This rule-based categorization engine uses regex patterns on event types to map events to five business categories: Migration Requirements, Security & Compliance, Maintenance & Updates, Cost Impact Events, and Operational Notifications. Because most events follow predictable patterns, this approach processes the majority of events through efficient pattern matching without incurring AI costs.
For events requiring deeper analysis, the AI-powered analysis engine built on Amazon Bedrock takes over. This engine uses the Strands Agents framework, an open-source agentic framework developed by AWS, with Claude 4.5 Sonnet as the large language model. You can switch this to a preferred LLM of your choice. Three specialized agents handle different aspects of analysis: a SQL Query Agent converts natural language queries to structured DynamoDB queries for precise numerical analysis, an Impact Analysis Agent evaluates unstructured event descriptions against customer metadata such as environment, business unit, and ownership, and a DBQueryBuilder Agent generates optimized database queries for multi-dimensional aggregations. All these capabilities are exposed as MCP tools that compatible clients can invoke.
3. Presentation tier – MCP client – AI assistant integration
The presentation tier consists of an MCP-compatible AI assistant, such as Claude Code or Kiro CLI. Instead of a custom front end, Chaplin exposes its capabilities as MCP tools that these clients consume natively. Users interact through natural language in their existing development environment, and the AI assistant orchestrates calls to Chaplin’s MCP server to retrieve health event data, run AI-powered analysis, and present contextualized results – all within the same conversational interface they already use for development tasks.
Security relies on AWS Identity and Access Management (AWS IAM) for authentication and authorization. The MCP client mounts AWS credentials as read-only, and access is controlled through IAM roles with least-privilege principles. Data is encrypted with TLS 1.2+ in transit and AES-256 at rest, and AWS CloudTrail provides audit logging for API calls.
Key capabilities
Chaplin provides three core capabilities that address gaps in how organizations manage AWS Health events today.
Chaplin offers dynamic conversational analytics. It generates actionable insights on demand based on your specific questions, providing precise breakdowns with exact counts, affected accounts, and contextual analysis – generated dynamically within your AI assistant without pre-built reports or dashboards. Chaplin delivers this through three integrated capabilities:
MCP-powered health intelligence tools
Chaplin exposes a comprehensive set of MCP tools organized into three categories. Summary tools query DynamoDB directly and return instantly, providing high-level counts by service, status, category, and region. Detail tools let you drill into specific event categories, event types, or filtered event lists. AI analysis tools use Strands Agents with Amazon Bedrock to interpret your natural language queries, fetch relevant data, and generate contextual insights.
Multi-account data pipeline
Chaplin collects health events from your AWS accounts and centralizes data in Amazon S3, supporting flexible deployment models based on your security posture. The data pipeline consists of AWS Lambda functions for automated health event ingestion, Amazon EventBridge schedulers with configurable collection frequency (daily or hourly), cross-account IAM roles for secure multi-account data collection with least-privilege principles, an Amazon S3 data lake with partitioning for efficient querying, and automated lifecycle management with configurable retention policies.
Precise analytical processing
Chaplin combines structured and unstructured data processing for comprehensive analysis. For structured data, it delivers exact numerical results including event counts and distributions, timeline analysis with trend detection, multi-dimensional aggregations across account, service, and severity dimensions, and categorical breakdowns with precise percentages. For unstructured data, it provides contextual insights such as impact assessment based on event descriptions, architectural deficiency identification, risk correlation across related events, and recommended actions based on event context.
Implementation walkthrough: EC2 instance lifecycle management
To illustrate the breadth of what Chaplin can do, the following walkthrough shows a series of natural language queries issued through Kiro CLI. These examples are organized by use case – from getting a quick operational overview to deep-diving into specific services and planning remediation.
Note: The following examples use sample data to illustrate Chaplin’s capabilities. Your actual responses will vary based on the health events in your AWS environment.
Getting the operational picture
A team starting their day can quickly assess the current state of health events across your accounts and identify what needs immediate attention:
What’s the estimated impact of RDS PostgreSQL deprecation for our Tier-1 production accounts, ranked by monthly spend at risk?
★
Chaplin Response
All events are of type AWS_RDS_PLANNED_LIFECYCLE_EVENT. 6 of 10 accounts have deadlines that are already past due, with the oldest being CustomerSupport-production-5365 (Oct 2024). The Orders account deadline of May 15, 2026 is the most urgent upcoming event.
● Tier-1 Accounts
6 accounts | 14 events | $304,400/mo at risk
Account
BU
Division
Spend/mo
Events
Deadline
Analytics-production-8137
<td style="color: #1f2328;padding: 10px 12px;border-bottom
関連記事
フロンティア・エコシステムはオープンであるべき:Databricks の Matei Zaharia 氏と Reynold Xin 氏が語る理由
Databricks の Matei Zaharia 氏と Reynold Xin 氏は、AI エンジニアリング分野の主要カンファレンスで、コードエージェント層やデータベース設計を見直すなど、フロンティア・エコシステムがオープンである必要性を強調した。
General Intuition の 23 億ドル投資:ビデオゲームが現実世界の AI エージェントを訓練できるという賭け
General Intuition は、ビデオゲーム環境を活用して現実世界で動作する AI エージェントを訓練する技術に 23 億ドルを投資すると発表した。同社は、ゲーム内での学習が実社会のタスク遂行能力に転用可能であると確信している。
エージェントがどのように業務を変革しているか
OpenAI は、自律的な AI エージェントが人間の業務プロセスを根本から変えつつある現状について解説した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み