Amazon Nova モデルのファインチューニングによる正確なメールデータ抽出
Parcel Perform は AWS との連携により Amazon Nova モデルをファインチューニングし、メールからのデータ抽出精度を 94.77% に向上させつつコストと遅延を大幅に削減した。
キーポイント
実証された高精度なデータ抽出
Amazon Nova Micro モデルのファインチューニングにより、複雑な HTML メールからの構造化情報抽出精度が 94.77% に達し、ベースラインから 16.6 ポイント向上した。
コストとレイテンシの劇的改善
ファインチューニングにより推論遅延が 30% 以上短縮され、従来モデルと比較してコストを半減させることに成功した。
PEFT と LoRA を活用した効率的な学習
Amazon SageMaker AI を用いた教師ありファインチューニング(SFT)と低ランク適応(LoRA)により、限られたデータで計算コストを抑えつつモデルをカスタマイズした。
業界特有の課題解決
注文番号と追跡番号の混同やハルシネーションといった一般的な課題に対し、特定のデータパターンを学習させることで効果的に対応した。
コスト効率の高いモデル選択
実験では、Amazon Nova Pro や他モデルと比較して低コストかつ競争力のあるパフォーマンスを持つ「Nova Lite」と「Nova Micro」が選定されました。
SageMaker を用いたファインチューニング設定
Amazon SageMaker AI API と SDK を使用し、LoRA(PEFT)スキームや学習率などのパラメータを指定してトレーニングジョブを実行します。
Bedrock での推論デプロイ
トレーニング完了後、SageMaker で訓練されたモデルを Amazon Bedrock のカスタムモデルとしてインポートし、API を介してエンティティ抽出の推論を実行できます。
影響分析・編集コメントを表示
影響分析
この事例は、生成 AI モデルを汎用的に使用するだけでなく、特定の業務プロセスに合わせてファインチューニングすることで、実務レベルの精度とコスト効率を同時に達成できることを示す重要な証拠です。特に、複雑な非構造化データ(HTML メール)からの抽出において、LLM のハルシネーションや誤認識といった課題を技術的解決で克服した点は、物流・EC 業界における AI 実装の標準的なベストプラクティスとして広く参照されるでしょう。
編集コメント
本記事は、生成 AI の実用化において「汎用モデルの直接使用」から「ドメイン特化型のファインチューニング」へ移行する必要性を具体的に数値で示した好例です。特に PEFT 技術を活用してコストと精度の両立を図ったアプローチは、多くの企業が直面している課題に対する即効性のある解決策として参考になります。
著者らは、このイニシアチブの実現に貢献してくれた Karan Bhandarkar 氏、Sue Cha 氏、Yash Shah 氏、そして Nieves Garcia 氏にも謝意を表します。
毎日数百万通のメールを処理している場合、Amazon Nova モデルのファインチューニングにより、コストとハルシネーション(幻覚)を削減しながら正確なデータ抽出を自動化できます。世界中の EC ビジネス向けに AI デリバリ体験プラットフォームのリーディングカンパニーである Parcel Perform は、単純な通知から広範な JavaScript 要素を含む複雑な HTML ドキュメントに至るまで、多様なメールフォーマットから構造化情報を抽出する際にまさにこの課題に直面していました。
一般的な課題としては、モデルによるハルシネーション、注文番号と追跡番号のような類似データタイプ間の混同、および HTML フォーマットのメールを処理する際の極めて高額なトークンコストが挙げられます。
本記事では、Amazon SageMaker AI を用いて Amazon Nova モデルをファインチューニングすることで、モデルに正確なデータパターンを認識させ、類似フィールドを区別し、より効率的に情報を処理させることでこれらの特定の課題に対処する方法について解説します。これにより、抽出精度は最大 94.77% に達し、コストは 50% 削減されます。
コラボレーション
Parcel Perform は、顧客の旅程全体を通じてビジネスおよび技術的なコンサルティングを提供する AWS 生成 AI イノベーションセンター(GenAIIC)と協力しました。Parcel Perform の課題定義から逆算して、チームは Nova モデルをさまざまなカスタマイズ手法やパラメータ最適化を通じて最適化するプロジェクトの範囲を定めました。
このコラボレーションにより、精度、レイテンシ、コストという複数の指標を並行して改善することが可能になりました。Parcel Perform の AI チームリーダーである Le Vy 氏は、ファインチューニングされた Nova Micro モデルがテストデータセットにおいて最大 94.77% の抽出精度を達成し、ベースラインと比較して最大で 16.6 ポイント向上したと報告しています。また、ファインチューニングされた Nova Micro は、推論レイテンシを 30% 以上短縮し、Parcel Perform が以前使用していたモデルと比較してコストを半減させながら、より低コストでファインチューニングされた Nova Lite モデルに匹敵する、あるいはそれを超える性能を発揮しました。これらの結果を受け、Parcel Perform はこのソリューションを実環境へ移行し、e コマース物流業務の改善を図りました。
ソリューション概要
Amazon SageMaker AI のカスタムモデルファインチューニング機能を利用することで、EC からのメールにおける専門的なエンティティ抽出のために Amazon Nova Lite および Amazon Nova Micro モデルを適応させることが可能です。このソリューションでは、低ランク適応(LoRA)を用いたパラメータ効率的ファインチューニング(PEFT)による教師ありファインチューニング(SFT)を採用しています。PEFT を用いることで、限られたトレーニングデータでもモデルを効果的にカスタマイズしつつ、計算効率を維持することができます。
PEFT を使用してモデルを Amazon Bedrock にデプロイし、トークン単位で課金されるオンデマンド推論で呼び出すこともできます。Amazon Bedrock は柔軟なデプロイオプションを提供しており、PEFT を用いる場合は オンデマンド推論 を通じてデプロイできますが、フルランクの SFT(Supervised Fine-Tuning)は、Amazon Bedrock 上のプロビジョニング済みスループット または SageMaker AI エンドポイント のいずれかを通じてデプロイをサポートしています。
カスタムモデルのファインチューニングでは、Amazon Nova レシピ が使用されます。これは YAML 形式の設定ファイルであり、ベースモデル名、トレーニングハイパーパラメータ、最適化設定、および追加オプションなど、カスタマイズジョブを実行する方法に関する詳細情報を Amazon SageMaker AI に提供します。以下の図はソリューションアーキテクチャを示しています。
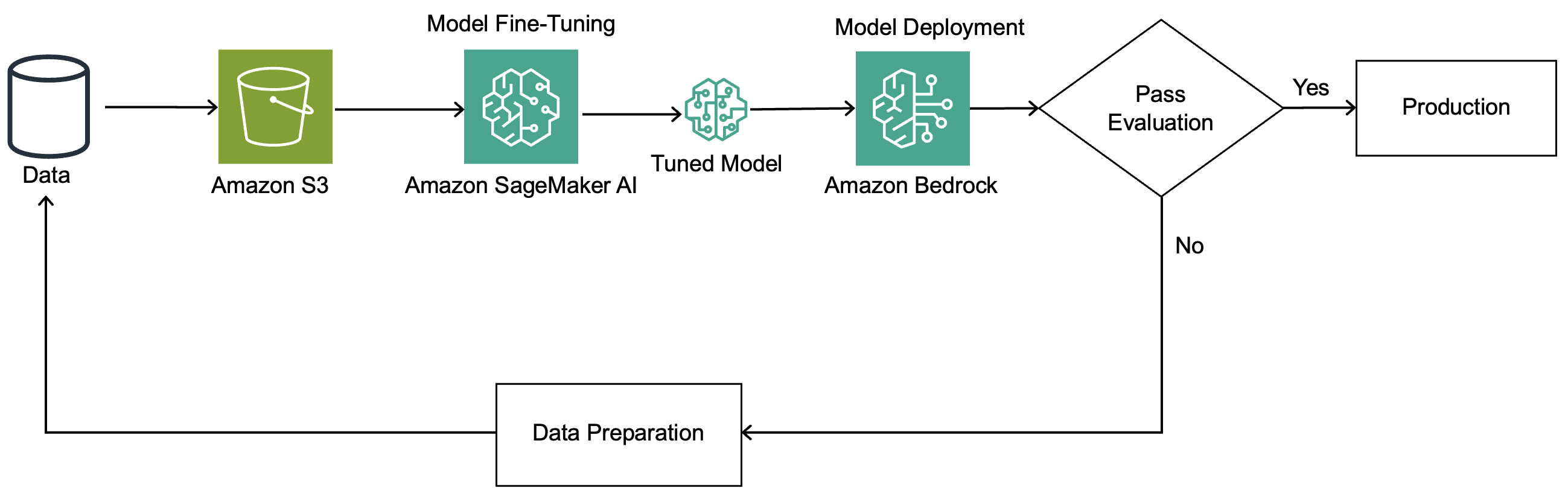
ワークフローの仕組みは以下の通りです。
- メールコンテンツを入力、抽出されたエンティティを出力とする Amazon Bedrock の会話形式でトレーニングデータを準備します。
- トレーニングデータを Amazon Simple Storage Service (Amazon S3) にアップロードします。
- Low-Rank Adaptation (LoRA) 設定を使用して SageMaker AI でファインチューニングジョブを作成します。
- オンデマンド推論を用いて Amazon Bedrock でファインチューニング済みモデルをデプロイします。
- 新しいメールからエンティティを抽出するために推論を実行します。
前提条件
Nova モデルのファインチューニングとデプロイには以下のものが必要です:
- 適切な権限を持つ AWS アカウント: AWS サービスへのアクセスおよびリソース作成に必要です。
- Amazon Bedrock および Amazon Nova モデルへのアクセス: 選択した AWS リージョンで利用可能である必要があります。
- IAM サービスロール: Amazon Bedrock モデルのカスタマイズ権限を持つ AWS Identity and Access Management (IAM) ロールです。
- S3 バケット: トレーニングデータおよび出力アーティファクトの保存用です。
- JSONL 形式のトレーニングデータ: データ形式と準備ガイダンスに従ってください。
- 十分なサービスクォータ: SageMaker AI Training で選択したインスタンスタイプおよびサイズに対して適切なクォータを確保してください。
サービスロールの作成手順については、モデルカスタマイズ用のサービスロールの作成 を参照してください。
訓練データの準備
訓練データは、Amazon Bedrock の会話スキーマ形式に従う必要があります。各サンプルには、ユーザー入力としてメール内容と、アシスタントの応答として抽出されたエンティティが含まれます。
必要なフォーマットの簡略化された例を以下に示します:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "あなたは e コマース注文メールから構造化データを抽出する専門家です。情報を捏造することなく、関連するすべてのフィールドを正確に抽出してください。"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "*ご注文番号 #12345 が発送されました!荷物の追跡はこちら:TRK789456123"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "{\"order_number\": \"12345\", \"tracking_number\": \"TRK789456123\", \"status\": \"shipped\"}"
}
]
}
]
}
私たちの実験では、2 つの訓練データセットを準備しました。1 つはサンプル数 1,300 の小規模なセット、もう 1 つはサンプル数 4,900 の大規模なセットです。これにより、訓練データのサイズがモデルのパフォーマンスに与える影響を評価することができました。
データ準備ステップを実行するには、開発環境として Amazon SageMaker Studio を使用し、Jupyter Notebook を実行することができます。
訓練データを S3 バケットにアップロード
SageMaker AI Training は、コードやデータの開発環境とは別の環境でジョブを実行します。SageMaker AI Training を使用すれば、トレーニング完了時に自動的に停止する、1 つまたは複数の強力な GPU 搭載インスタンスを効率的に利用できます。インスタンスがデータ準備環境と分離されているため、データを集中管理場所である Amazon S3 にアップロードする必要があります。
以下のコードは、SageMaker Studio から S3 バケットへデータをアップロードする方法を示しています:
import boto3
s3 = boto3.client('s3')
s3.upload_file('train.jsonl', 'your-training-bucket', 'train.jsonl')Amazon Nova モデルのファインチューニング
訓練データが準備できたら、SageMaker SDK を通じて Amazon SageMaker AI API を使用してファインチューニングジョブを作成できます。Amazon Nova Customization Hub の例に従ってください。これにより、選択した種類とサイズの 1 つまたは複数の独立したインスタンス上でコンテナを実行する Amazon SageMaker AI Training を使用したトレーニングジョブがプロビジョニングされます。
以下の表は、実験における主要なファインチューニングパラメータを要約しています:
| Parameters | Description |
|---|---|
| model_type | "amazon.nova-lite-v1:0:300k" または "amazon.nova-micro-v1:0:128k" |
| model_name_or_path | "nova-lite/prod" または "nova-micro/prod" |
| replicas | g5/g6 の場合 1、p5 の場合 4 |
※注:原文の表形式は Markdown テーブルとして保持されています。
max_length
g5/g6 の場合 8192、p5 の場合 32768
global_batch_size
64
max_epochs
2
peft_scheme (パラメータ効率的微調整スキーム)
lora
loraplus_lr_ratio
8.0
alpha
32
Amazon Nova Pro や他のモデルと比較して、コストが低く競争力のあるパフォーマンスを示すため、Nova Lite と Nova Micro を選択しました。
デプロイと推論の実行
ファインチューニングジョブが正常に完了したら、Amazon SageMaker AI によってトレーニングされた PEFT(Parameter-Efficient Fine-Tuning)チューニング済みの Nova モデルをインポートするために、Amazon Bedrock でカスタムモデルを作成できます。詳細な手順については、カスタムモデルの作成 をご参照ください。その後、以下の例に示すように、このカスタムモデルを使用して推論を実行することができます:
import boto3
import json
bedrock_runtime = boto3.client(service_name="bedrock-runtime")def extract_entities(email_content, provisioned_model_arn):
body = {
"messages": [{
"role": "user",
"content": f"Extract all relevant data fields from this email:\n\n{email_content}"
}],
"max_tokens": 2048,
"temperature": 0.1
}
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
response = bedrock_runtime.invoke_model(
body=json.dumps(body),
modelId=provisioned_model_arn,
accept="application/json",
contentType="application/json"
)
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
response_body = json.loads(response.get('body').read())
return response_body['output']['message']['content'][0]['text']
Example usage
email = """
Dear Customer,
Your order has been shipped!
Carrier: FedEx
Estimated Delivery: January 15, 2025
"""
result = extract_entities(email, "arn:aws:bedrock:us-east-1:${account-id}:provisioned-model/your-model-id")
The function returns extracted fields similar to the following:
{
Carrier: FedEx,
Date: January 15, 2025
}
You also have the option of iteratively training the model with a different method. For example, you can use the checkpoint from SFT-PEFT tuning as a base for downstream Direct Preference Optimization (DPO) training. See the documentation on iterative training.
Evaluation results
Fine-tuned models improved accuracy by 5.6–16.6 percentage points over baselines, with Nova Micro achieving the highest overall accuracy of 94.77 percent despite being the smaller model. Fine-tuning also reduced inference latency by approximately 32 percent and cut costs by approximately 50 percent through PEFT tuning on lighter models compared to existing models with pay-per-use pricing. These combined gains in accuracy, speed, and cost enabled Parcel Perform to deploy the tuned Amazon Nova model into production.
精度比較
Parcel Perform は、データ項目全体にわたる抽出精度を統合した同社の加重精度指標を用いて、微調整済みモデルとベースラインモデルを評価しました。テストは、それぞれ 100 サンプルと 200 サンプルからなる 2 つの代表的なデータセットに対して行われました。
主な知見:
微調整により、すべてのモデルで精度が向上し、ベースラインモデルと比較して 5.6 ポイントから 16.6 ポイントの改善が見られました。Nova Micro は最も大きな上昇を示し、微調整後には 76.63 パーセントから 93.27 パーセントに達しました。トレーニングデータを 1,300 サンプルから 4,900 サンプルへ拡大することで、さらに最大 3.3 パーセントのパフォーマンス向上がもたらされ、トレーニング量の modest な増加でも有意義な成果が得られることが示されました。比較的小さなモデルである Nova Micro は、200 サンプルのテストセットにおいて 94.77 パーセントという最高レベルの全体的な精度を達成しました。ドメイン固有タスクにおいては、よく調整されたコンパクトなモデルの方が、より大規模な代替モデルよりも優れた性能を発揮し得ます。
レイテンシ改善
微調整は推論レイテンシ(応答遅延)も大幅に削減しました。Nova Lite では 31 パーセント、Nova Micro では 32 パーセントの短縮が実現されました。これは、Parcel Perform の以前のモデルと比較して Nova Micro のモデルサイズが小さく、パラメータ数が少ないことによるものです。これは推論あたり約 7.7 秒に相当し、毎日大量のメールを処理する際の速度向上につながります。
インプパクト
Parcel Perform の以前のモデルと比較して、処理時間が大幅に短縮されました。コストは約 50% 削減され、これは PEFT(Parameter-Efficient Fine-Tuning:パラメータ効率的微調整)により、軽量なモデルが特定のタスクでより高い性能を発揮できるようになり、かつ従量課金型価格体系でのデプロイが可能になったためです。精度の向上に加え、コストとレイテンシの削減により、Parcel Perform は微調整を施した Amazon Nova モデルを実環境(production)で使用できるようになりました。
結論
本稿では、e コマースメールからの正確なエンティティ抽出のために、Amazon SageMaker AI を用いて Amazon Nova モデルを微調整する方法を示しました。Parcel Perform との共同プロジェクトを通じて、LoRA(Low-Rank Adaptation:低ランク適応)を用いたパラメータ効率的微調整が、推論レイテンシを 30% 以上削減しながらも、精度に顕著な向上をもたらすことができることが実証されました。
本取り組みからの主なポイント:
ファインチューニングはハルシネーション(幻覚)を削減する上で効果的であることが証明されました。モデルは注文番号と追跡番号を正しく区別し、ソース資料に存在しないデータを捏造することはありませんでした。実用的な結果を得るために大規模なデータセットが必要というわけではありません:25 のエンティティにわたるわずか 1,300 件のトレーニングサンプルでさえも、意味のある精度の向上をもたらしました。これは、ラベル付きデータの限られたチームにとってもファインチューニングが実用的な選択肢であることを示しています。直感に反する発見として、ファインチューニング後には、より小さな Nova Micro モデルがより大きな Nova Lite モデルを上回りました。これは、タスク固有の最適化がベースモデルサイズの差を十分に補償し得ることを示しています。これにはコスト上の意味合いがあります:Nova Micro のような小さく高速なモデルと推論レイテンシの削減を組み合わせることで、大規模なメール処理に対するコスト効果の高いソリューションが実現します。PEFT(Parameter-Efficient Fine-Tuning)で調整されたモデルをオンデマンド・トークンベース課金の Amazon Bedrock に直接デプロイできるため、必要に応じて完全にカスタマイズされたモデルを実行でき、専用 LLM ホスティングインフラの用意や維持管理が不要になります。
始め方
このソリューションを実装するには、まず前述の形式でトレーニングデータを準備することから始めます。意味のある結果を得るためには、本記事に示されているように少なくとも 1,300 件のサンプルを含むデータセットを開始点とします。最適な結果を得るには、プロダクション環境で遭遇するであろう多様なメールフォーマットをトレーニングデータが網羅していることを確認してください。
同様のエンティティ抽出の課題に直面している場合は、SageMaker AI モデルのカスタマイズ機能を使用して、正確かつ本番環境で利用可能なソリューションを構築できます。このアプローチでは、Nova Micro や Nova Lite のような高速でコスト効率の高いモデルを、精度・速度・コスト効率を実現する本番用途向けに適応させる方法を示しています。
実際に試してみませんか? これらのリソースをご覧ください:
- Amazon Bedrock でのモデルカスタマイズ: Amazon Bedrock モデルのカスタマイズに関する詳細はこちら。
- Amazon Nova Forge の製品詳細ページ: Nova を用いたカスタムモデル開発についてご紹介します。
- 生成 AI イノベーションセンター: AWS GenAIIC と共に、同様のユースケースに取り組むことができます。
AWS GenAIIC は、2023 年に組織が生成 AI の可能性をビジネス価値に変えるのを支援するために AWS が開始したプログラムです。このセンターは、生成 AI の全プロセスを通じて顧客と協力し、優先すべきユースケースの特定、戦略的ロードマップの構築、そして AI ソリューションを概念から本番環境への移行を支援する、AWS の科学および戦略の専門家を集めています。設立以来、インノベーションセンターは F1、ナスダック、ライアンエアー、S&P グローバルなど多様な業界に属する 1,000 社以上の顧客と協力し、近年ではプロジェクトの 65% 以上が生産環境への展開に至っています。AWS はその後、生成 AI ソリューションを構築する顧客に対するサポートを拡大するため、このプログラムへの投資を倍増させました。
著者について

Vy Le
Vy Le は Parcel Perform の AI チームリーダーを務め、AI アプリケーションの開発を主導し、新たな AI 研究の探求を行っています。彼女はデータ分析からキャリアを開始し、人工知能(Artificial Intelligence)の修士号を取得することで AI への関心を深めました。データと AI を活用して現実のビジネス課題を解決することに情熱を持ち、将来の技術者へのメンタリングや、若手技術者のための支援コミュニティ構築にも時間を割いています。彼女の活動を通じて、業界における性別に関する規範に挑戦し、生涯学習がイノベーションへの鍵であると提唱しています。

Xiaogang Wang
王少剛博士は、AWS ジェネレーティブ AI イノベーションセンターのシニア・アプライド・サイエンティストです。同センターでは、AWS サービスを活用して顧客が AI/ML ソリューションを設計・実装するのを支援しています。彼の活動範囲には、フィジカル AI(物理的 AI)、フィンテック、ヘルスケアなど多様な業界が含まれ、組織が生成的モデルの活用、大規模なモデルのトレーニングおよびファインチューニング、インテリジェントなドキュメント処理を駆使してイノベーションを加速し、ビジネス成果を導き出すことを可能にしています。シンガポール国立大学で博士号を取得しており、CVPR、ICCV、IROS、T-PAMI などのトップカンファレンスや学術誌に多数の論文を発表しています。また、CVPR、ICCV、ECCV、ICML、NeurIPS などの主要カンファレンスの査読委員も務めています。
<img loading="lazy" class="alignnone size-full wp-image-133601" src="https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2026/06
原文を表示
*The authors would also like to thank Karan Bhandarkar, Sue Cha, Yash Shah and Nieves Garcia** for their contributions in making this initiative possible.*
If you process millions of email messages daily, fine-tuning Amazon Nova models can help you automate accurate data extraction while reducing costs and hallucinations. Parcel Perform, a leading AI Delivery Experience Platform for ecommerce businesses worldwide, faced this exact challenge when extracting structured information from diverse email formats, ranging from simple notifications to complex HTML documents with extensive JavaScript elements.
Common challenges include model hallucinations, confusion between similar data types (such as order numbers and tracking numbers), and prohibitively high token costs when processing HTML-formatted email.
In this post, you’ll learn how fine-tuning Amazon Nova models using Amazon SageMaker AI addresses these specific issues by teaching the models to recognize your exact data patterns, distinguish between similar fields, and process information more efficiently—achieving up to 94.77% extraction accuracy while reducing costs 50%.
The collaboration
Parcel Perform worked with the AWS Generative AI Innovation Center (GenAIIC), which provides business and technical consultancy throughout the customer journey. Working backward from Parcel Perform’s problem statement, the team scoped a project to optimize Nova models through various customization techniques and parameter optimization.
This collaboration allowed concurrent improvement of multiple metrics: accuracy, latency, and cost. Le Vy, AI Team Lead at Parcel Perform, reported that the fine-tuned Nova Micro models achieved up to 94.77% extraction accuracy on the testing dataset, an improvement of up to 16.6 percentage points over the baseline. The fine-tuned Nova Micro reduced inference latency by more than 30 percent and halved costs compared with Parcel Perform’s previous model, while matching or exceeding the fine-tuned Nova Lite model at lower cost. With these results, Parcel Perform moved the solution into production to improve its e-commerce logistics operations.
Solution overview
You can use Amazon SageMaker AI custom model fine-tuning to adapt Amazon Nova Lite and Amazon Nova Micro models for specialized entity extraction from ecommerce email. This solution uses supervised fine-tuning (SFT) with Parameter-Efficient Fine-Tuning (PEFT) through Low-Rank Adaptation (LoRA). With PEFT, you can customize models effectively with limited training data while maintaining computational efficiency.
You can also use PEFT to deploy the model into Amazon Bedrock and invoke it with on-demand inference priced per token. Amazon Bedrock offers flexible deployment options: with PEFT, you can deploy using on-demand inference, while full-rank SFT supports deployment through either Provisioned Throughput on Amazon Bedrock or a SageMaker AI endpoint.
The custom model fine-tuning uses Amazon Nova recipes, which are YAML configuration files that provide details to Amazon SageMaker AI on how to run your model customization job, including the base model name, training hyperparameters, optimization settings, and additional options. The following diagram illustrates the solution architecture.
Here’s how the workflow works:
- Prepare training data in the Amazon Bedrock conversation format with email content as input and extracted entities as output.
- Upload training data to Amazon Simple Storage Service (Amazon S3).
- Create a fine-tuning job in SageMaker AI using Low-Rank Adaptation (LoRA) configuration.
- Deploy the fine-tuned model using Amazon Bedrock with on-demand inference.
- Run inference to extract entities from new email.
Prerequisites
You will need the following to fine-tune and deploy Nova models:
- AWS account with appropriate permissions: Required to access AWS services and create resources.
- Access to Amazon Bedrock and Amazon Nova models: Must be available in your chosen AWS Region.
- IAM service role: An AWS Identity and Access Management (IAM) role with permissions for Amazon Bedrock model customization.
- S3 bucket: For storing training data and output artifacts.
- Training data in JSONL format: Follow the data format and preparation guidance.
- Sufficient Service Quotas: Establish adequate quota for your chosen instance type and size in SageMaker AI Training.
For instructions on creating the service role, see Create a service role for model customization.
Prepare the training data
Your training data must follow the Amazon Bedrock conversation schema format. Each sample contains the email content as user input and the extracted entities as the assistant response.
Here’s a simplified example of the required format:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "You are an expert at extracting structured data from e-commerce order emails. Extract all relevant fields accurately without fabricating any information."
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "Your order #12345 has shipped! Track your package: TRK789456123"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "{\"order_number\": \"12345\", \"tracking_number\": \"TRK789456123\", \"status\": \"shipped\"}"
}
]
}
]
}In our experiment, we prepared two training datasets: a smaller set with 1,300 samples and a larger set with 4,900 samples. This allowed us to evaluate how training data size impacts model performance.
You can use Amazon SageMaker Studio as your development environment to run Jupyter Notebook for the data preparation step.
Upload training data to an S3 bucket
SageMaker AI Training runs jobs in separate environments from your code and data development environment. With SageMaker AI Training, you can efficiently use one or multiple powerful GPU-powered instances that automatically stop when training finishes. Because the instances are separate from your data preparation environment, you will need to upload the data to a centralized location: Amazon S3.
The following code illustrates uploading data from SageMaker Studio to an S3 bucket:
import boto3
s3 = boto3.client('s3')
s3.upload_file('train.jsonl', 'your-training-bucket', 'train.jsonl')Fine-tune the Amazon Nova model
With your training data prepared, you can create a fine-tuning job using the Amazon SageMaker AI API through the SageMaker SDK. Follow the examples in the Amazon Nova Customization Hub. This provisions a training job with Amazon SageMaker AI Training that runs on a container on one or multiple separate instances with the type and size you choose.
The following table summarizes the key fine-tuning parameters in our experiment:
Parameters
Description
model_type
“amazon.nova-lite-v1:0:300k” or “amazon.nova-micro-v1:0:128k”
model_name_or_path
“nova-lite/prod” or “nova-micro/prod”
replicas
1 for g5/g6 4 for p5
max_length
8192 for g5/g6 32768 for p5
global_batch_size
64
max_epochs
2
peft_scheme
lora
loraplus_lr_ratio
8.0
alpha
32
We selected Nova Lite and Nova Micro because of their lower cost and competitive performance compared with Amazon Nova Pro and other models.
Deploy and run inference
When your fine-tuning job completes successfully, you can create a custom model in Amazon Bedrock to import the PEFT-tuned Nova model trained by Amazon SageMaker AI. Follow Create a custom model for detailed steps. Then you can run inference using the custom model as shown in the following example:
import boto3
import json
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
def extract_entities(email_content, provisioned_model_arn):
body = {
"messages": [{
"role": "user",
"content": f"Extract all relevant data fields from this email:\n\n{email_content}"
}],
"max_tokens": 2048,
"temperature": 0.1
}
response = bedrock_runtime.invoke_model(
body=json.dumps(body),
modelId=provisioned_model_arn,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get('body').read())
return response_body['output']['message']['content'][0]['text']
# Example usage
email = """
Dear Customer,
Your order has been shipped!
Carrier: FedEx
Estimated Delivery: January 15, 2025
"""
result = extract_entities(email, "arn:aws:bedrock:us-east-1:${account-id}:provisioned-model/your-model-id")The function returns extracted fields similar to the following:
{
Carrier: FedEx,
Date: January 15, 2025
}You also have the option of iteratively training the model with a different method. For example, you can use the checkpoint from SFT-PEFT tuning as a base for downstream Direct Preference Optimization (DPO) training. See the documentation on iterative training.
Evaluation results
Fine-tuned models improved accuracy by 5.6–16.6 percentage points over baselines, with Nova Micro achieving the highest overall accuracy of 94.77 percent despite being the smaller model. Fine-tuning also reduced inference latency by approximately 32 percent and cut costs by approximately 50 percent through PEFT tuning on lighter models compared to existing models with pay-per-use pricing. These combined gains in accuracy, speed, and cost enabled Parcel Perform to deploy the tuned Amazon Nova model into production.
Accuracy comparison
Parcel Perform evaluated the fine-tuned models against baseline models using Parcel Perform’s weighted accuracy metric, which combines extraction accuracy across the data fields. We tested on two representative datasets with 100 samples and 200 samples, respectively.
Key findings:
Fine-tuning delivered accuracy gains across all models, with improvements ranging from 5.6 to 16.6 percentage points over their baseline counterparts. Nova Micro showed the largest jump, climbing from 76.63 percent to 93.27 percent after fine-tuning. Scaling the training data from 1,300 to 4,900 samples further boosted performance by up to 3.3 percent, showing that modest increases in training volume continue to yield meaningful returns. Despite being the smaller model, Nova Micro achieved the highest overall accuracy of 94.77 percent on the 200-sample test set. A well-tuned compact model can outperform larger alternatives on domain-specific tasks.
Latency improvements
Fine-tuning also reduced inference latency significantly: 31 percent for Nova Lite and 32 percent for Nova Micro because of Nova Micro’s smaller model size and fewer parameters compared with Parcel Perform’s previous model. This represents about 7.7 seconds per inference, making it faster to process large volumes of email daily.
Impact
Processing time decreased significantly compared with Parcel Perform’s previous model. Costs reduced by approximately 50 percent because PEFT lets lighter models perform better at specific tasks while supporting deployment with pay-per-use pricing. The improved accuracy, paired with reduced cost and latency, lets Parcel Perform use the fine-tuned Amazon Nova model in production.
Conclusion
In this post, we demonstrated how you can fine-tune Amazon Nova models using Amazon SageMaker AI for accurate entity extraction from e-commerce email. Our collaboration with Parcel Perform showed that Parameter-Efficient Fine-Tuning using LoRA can achieve significant accuracy improvements while reducing inference latency by more than 30 percent.
Key takeaways from this engagement:
Fine-tuning proved effective at reducing hallucinations. The models correctly distinguished between order numbers and tracking numbers without fabricating data that doesn’t exist in the source material. You don’t need massive datasets to see real results: meaningful accuracy gains were achieved with as few as 1,300 training samples across 25 entities, making fine-tuning a practical option even for teams with limited labeled data. In a counterintuitive finding, the smaller Nova Micro model outperformed the larger Nova Lite after fine-tuning, showing that task-specific optimization can more than compensate for differences in base model size. This has cost implications: pairing a smaller, faster model like Nova Micro with reduced inference latency creates a cost-effective solution for processing large volumes of email at scale. The ability to deploy PEFT-tuned models directly into Amazon Bedrock with on-demand, token-based pricing means you can run a fully customized model on a pay-per-use basis, removing the need to provision and maintain dedicated LLM-hosting infrastructure.
Get started
To implement this solution, start by preparing your training data in the preceding format. Begin with a dataset of at least 1,300 samples as shown in this post for meaningful results. To get optimal results, make sure your training data represents the variety of email formats that you will encounter in production.
If you face similar entity extraction challenges, you can use SageMaker AI model customization to build accurate, production-ready solutions. This approach shows how you can adapt fast and cost-effective models like Nova Micro and Nova Lite for production use cases that deliver accuracy, speed, and cost-effectiveness.
Ready to try it yourself? Explore these resources:
- Customize models in Amazon Bedrock: Learn more about Amazon Bedrock model customization.
- Amazon Nova Forge product details page: Discover custom model development using Nova.
- Generative AI Innovation Center: Work with AWS GenAIIC on similar use cases.
*AWS GenAIIC is a program launched by AWS in 2023 to help organizations turn generative AI potential into business value. The center brings together AWS science and strategy experts who work with customers across the generative AI journey, helping prioritize use cases, build strategic roadmaps, and move AI solutions from concept into production. Since its inception, the innovation center has collaborated with more than 1,000 customers across industries, including Formula 1, Nasdaq, Ryanair, and S&P Global, with more than 65 percent of projects in recent years reaching production deployment. AWS has since doubled its investment in the program to expand the support available to customers building generative AI solutions.*
About the authors
Vy Le
Vy Le is the AI Team Lead at Parcel Perform, where she drives the development of AI applications and explores emerging AI research. She started her career in data analysis and deepened her focus on AI through a Master’s in Artificial Intelligence. Passionate about applying data and AI to solve real business problems, she also dedicates time to mentoring aspiring technologists and building a supportive community for youth in tech. Through her work, Vy actively challenges gender norms in the industry and champions lifelong learning as a key to innovation.
Xiaogang Wang
Dr. Xiaogang Wang is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he helps customers design and implement AI/ML solutions using AWS services. His work spans industries including physical AI, fintech, and healthcare, enabling organizations to leverage generative models, large-scale model training and fine-tuning, and intelligent document processing to accelerate innovation and drive business outcomes. He holds a PhD from the National University of Singapore and has published numerous papers in top-tier conferences and journals, including CVPR, ICCV, IROS, T-PAMI, etc. He also serves as a reviewer for leading conferences such as CVPR, ICCV, ECCV, ICML, NeurIPS, etc.
<img loading="lazy" class="alignnone size-full wp-image-133601" src="https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2026/06
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み