社内向けHEROZ ASKにSLMのPhi-3.5を導入した実装例
HEROZ Tech Blog は、社内向けシステムに軽量言語モデル Phi-3.5 mini を導入する際の実装手順と、Azure ML Studio と AI Foundry のエンドポイント構成の違いについて詳述している。
キーポイント
SLM の社内導入の背景と選定理由
セキュリティやコスト、レイテンシーを重視し、Phi-3.5 mini (3.8B) を採用。従来の小規模モデルへの誤解(精度不足)が払拭されつつある現状を踏まえた判断である。
Azure ML Studio と AI Foundry のエンドポイント差異
LangChain 連携において、Machine Learning Studio で作成した「サーバーレス」エンドポイントは API ルートが利用可能だが、AI Foundry 経由の「Azure AI Services」系は異なる挙動を示すという重要な技術的違いを指摘している。
LangChain を用いた実装コードと構成
AzureMLChatOnlineEndpoint と CustomOpenAIChatContentFormatter を使用し、サーバーレス API へ接続する具体的な Python コード例を提供しており、実務での即座の適用を可能にしている。
コストと性能の実証
1000 トークンあたり約 0.00013 ドルという低コストで推論が可能であり、社内環境での実用性を裏付ける数値データを提示している。
プロンプト設計の重要性
Phi-3.5 は小規模モデル特有の誤答が発生する可能性はあるが、適切なプロンプト設計により正確な回答を得られることが確認された。
サーバーレス推論の速度特性
Azure Machine Learning サーバーレス API の推論速度はモデルサイズに対して速くなく、起動オーバーヘッドの影響が大きいと判断される。
影響分析・編集コメントを表示
影響分析
この記事は、大規模モデルに依存しない「軽量・高効率」な AI 活用戦略を示す実践的なガイドラインを提供しており、特にオンプレミスや社内データ保護が求められる環境での SLM 導入における技術的障壁(API 接続の違い)を解消する価値がある。
編集コメント
Azure のプラットフォーム間(Studio vs Foundry)における微妙な仕様の違いが実装の成否を分けるケースを示しており、開発者にとって非常に示唆に富む技術的知見です。
モデルのデプロイ 1. ワークスペースの作成
- サーバーレスエンドポイントの作成
Azure AI Foundryで作成したエンドポイントとの比較
langchainからの呼び出しコード
実行結果 モデルの精度と推論速度
昨今、小規模言語モデル(SLM, Small Language Model)の話が生成AI界隈で賑わせています。 SLMはgpt-4oのような大規模言語モデル(LLM, Large Language Model)と比較して小型軽量である故に以下のような特徴があるとされています。
エッジデバイスやオンプレサーバーで動作させることができる。動作させてもコストが大きくならない。 セキュリティーやプライバシーの問題で海外のサーバーへプロンプトを送ることに対しての抵抗は根強くあると思います。
応答までのレイテンシーが短い 特に音声会話のような場合にはミリ秒(ms)を争うので、レイテンシーが低いに越したことはないです。
ドメイン特化のためのファインチューニングを実施しやすい。 従来の中規模や大規模のモデルと比べてはるかに少ないGPU枚数でファインチューニングができるので、敷居が下がることを期待できます。
弊社でもSLMの動向は追っていましたが、以前の実験のように小規模のモデル(この時は10B前後)だと大した精度が出ないと考えていましたので、スルーしていました。 ところが、最近のSLMは以前のgpt-3.5-turboに匹敵する精度が出るという話や、精度が多少劣っても使い所があるかもしれないという話を聞き、遅ればせながら社内向けの環境に導入して、いろいろ検証しようと思いました。
検証に使用したSLMは今年の8月にリリースされたMicrosoft社のPhi-3.5の中で最も軽量なPhi-3.5 mini instructとしました。Phi-3.5 mini instructは3.8Bとかなり軽量です。 これをAzure Machine Learning サーバーレスAPIで動作させました。Phi-3.5 mini instructは1000トークンあたり$0.00013で推論できます。
HEROZ ASKに組み込むにあたってはlangchainで動作するようにしなければならないのですが、Azure Machine Learning サーバーレスAPIへの接続に関する情報がほとんどありませんでしたので、こちらに書こうと思います。
langchainからの呼び出しにはAzureMLChatOnlineEndpoint
以下がMachine Learning Studioでのモデルのデプロイ方法です。
Azure Machine Learning Studioにログインし、ワークスペースを作成する。
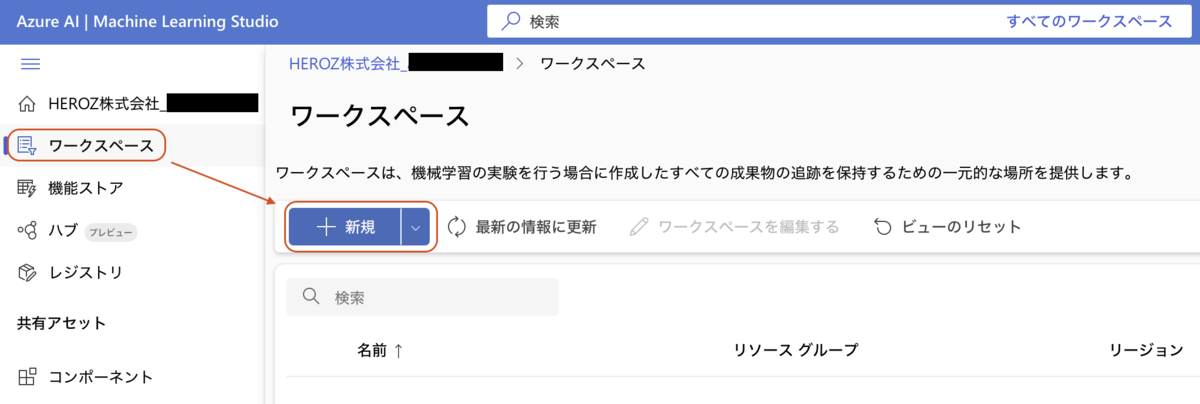 ワークスペースの作成
ワークスペースの作成
- サーバーレスエンドポイントの作成
作成したワークスペースに入り、エンドポイントページのサーバーレスエンドポイントタブからサーバーレスエンドポイントを作成する。
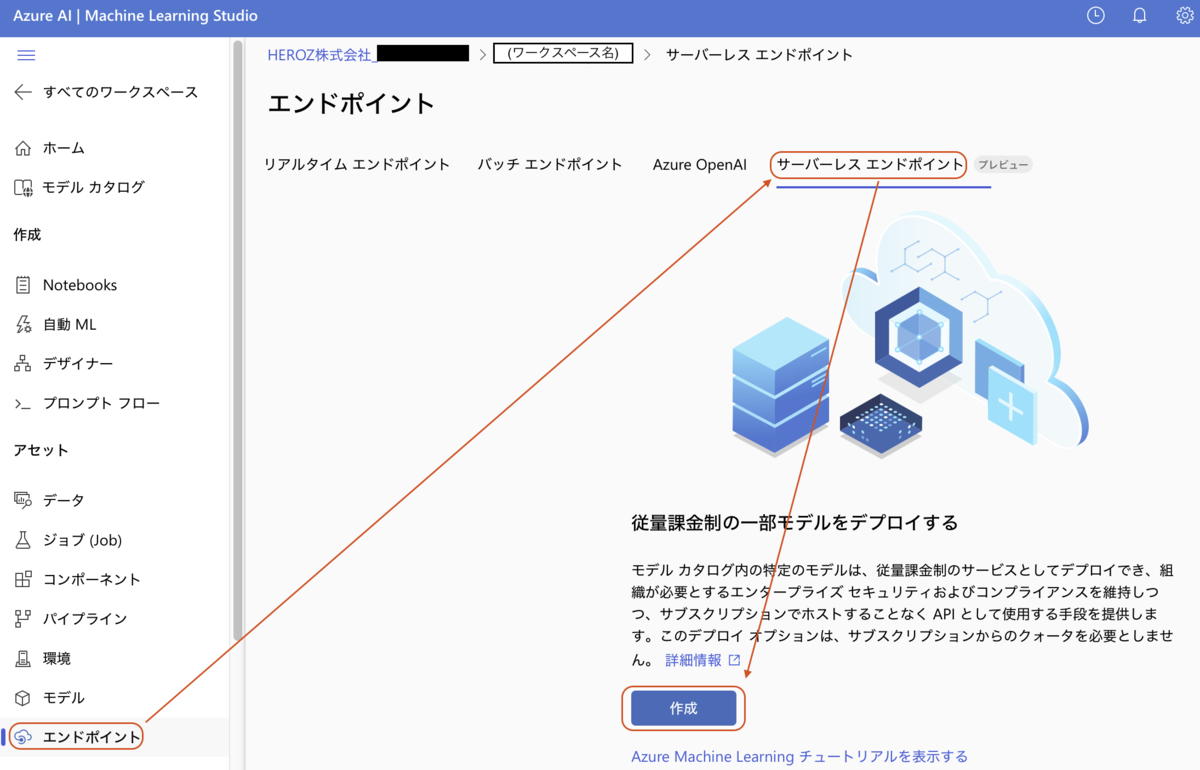 サーバーレスエンドポイントの作成
サーバーレスエンドポイントの作成
作成したエンドポイントの詳細ページを開くと、エンドポイントのURLとAPIキーを取得できます。この時に「APIルート」のパネルがあることがポイントです。
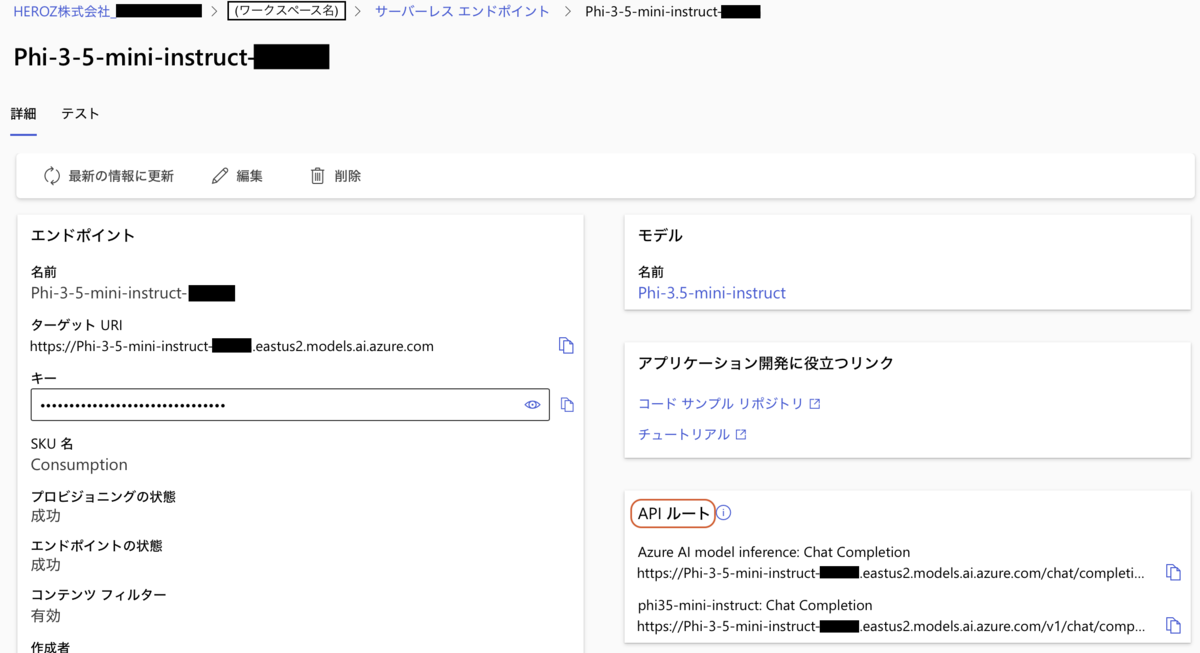 エンドポイントの詳細
エンドポイントの詳細
Azure AI Foundryで作成したエンドポイントとの比較
Azure AI Foundryで作成したエンドポイントの詳細には「APIルート」が存在しません。
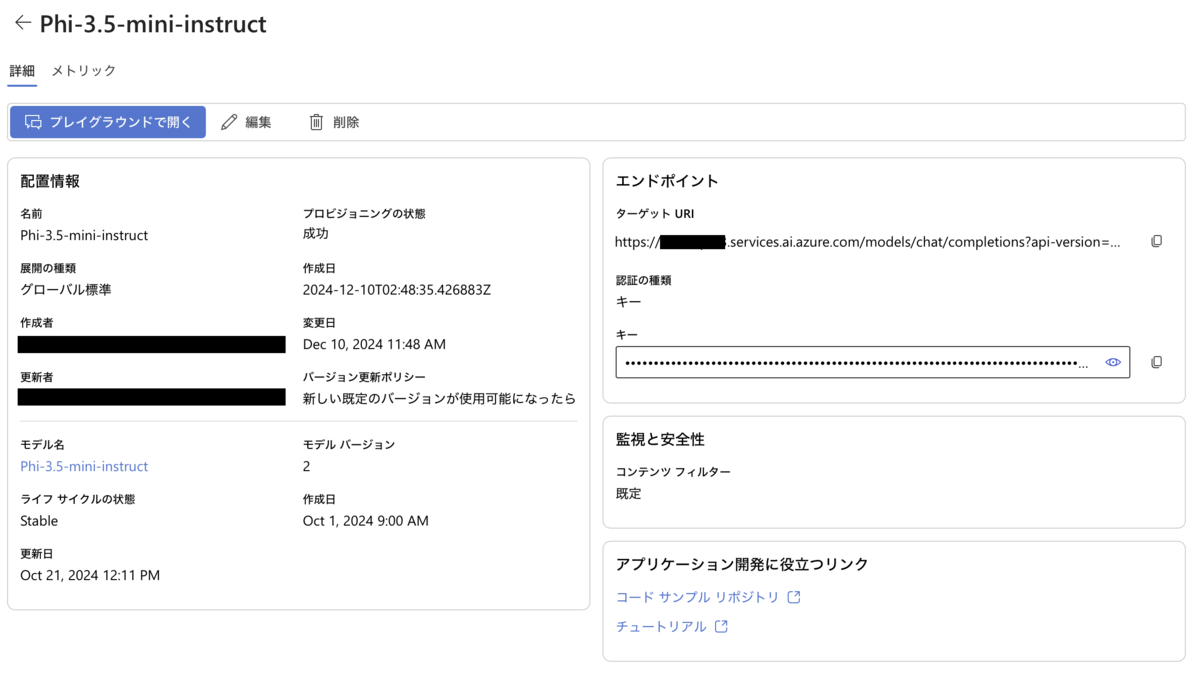 AI Foundryで作成したエンドポイント
AI Foundryで作成したエンドポイント
Azure AI Foundryのエンドポイント一覧では、Machine Learning Studioで作成したOKの方のエンドポイントは「サーバーレス」となっていて、AI Foundryで作成したNGの方のエンドポイントは「Azure AI Services」となっています。
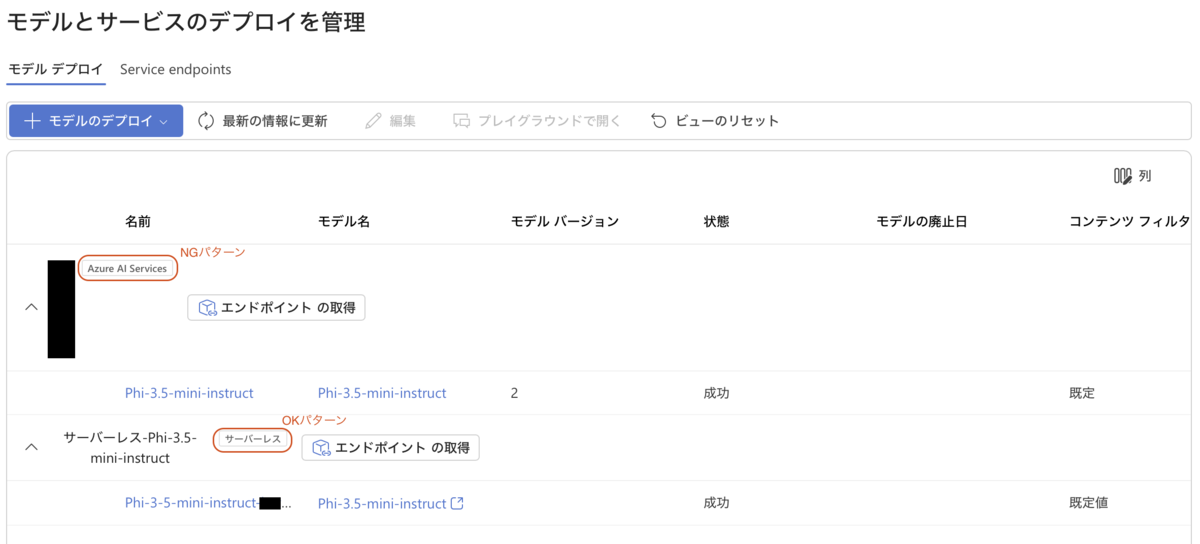 エンドポイントの一覧
エンドポイントの一覧
langchainからの呼び出しコード
langchainからは以下のコードにて呼び出すことができます。
!pip install langchain langchain_community from langchain_core.prompts import ChatPromptTemplate from langchain_community.chat_models.azureml_endpoint import AzureMLChatOnlineEndpoint, AzureMLEndpointApiType, CustomOpenAIChatContentFormatter AZURE_PHI3_ENDPOINT="(エンドポイント)" AZURE_PHI3_API_KEY="(APIキー)" human = "あなたは何者ですか?" prompt = ChatPromptTemplate.from_messages([("human", human)]) chat = AzureMLChatOnlineEndpoint( endpoint_url=AZURE_PHI3_ENDPOINT, endpoint_api_type=AzureMLEndpointApiType.serverless, endpoint_api_key=AZURE_PHI3_API_KEY, content_formatter=CustomOpenAIChatContentFormatter(), ) chain = prompt | chat chain.invoke({}) → AIMessage(content='私はMicrosoftのAIアシスタントです。...
Azure AI Foundryで作成したエンドポイントもlangchain_azure_ai
AzureAIChatCompletionsModel
langchain_azure_ai
learn.microsoft.com
HEROZ ASKの社内環境に組み込み、無事に動作しました。
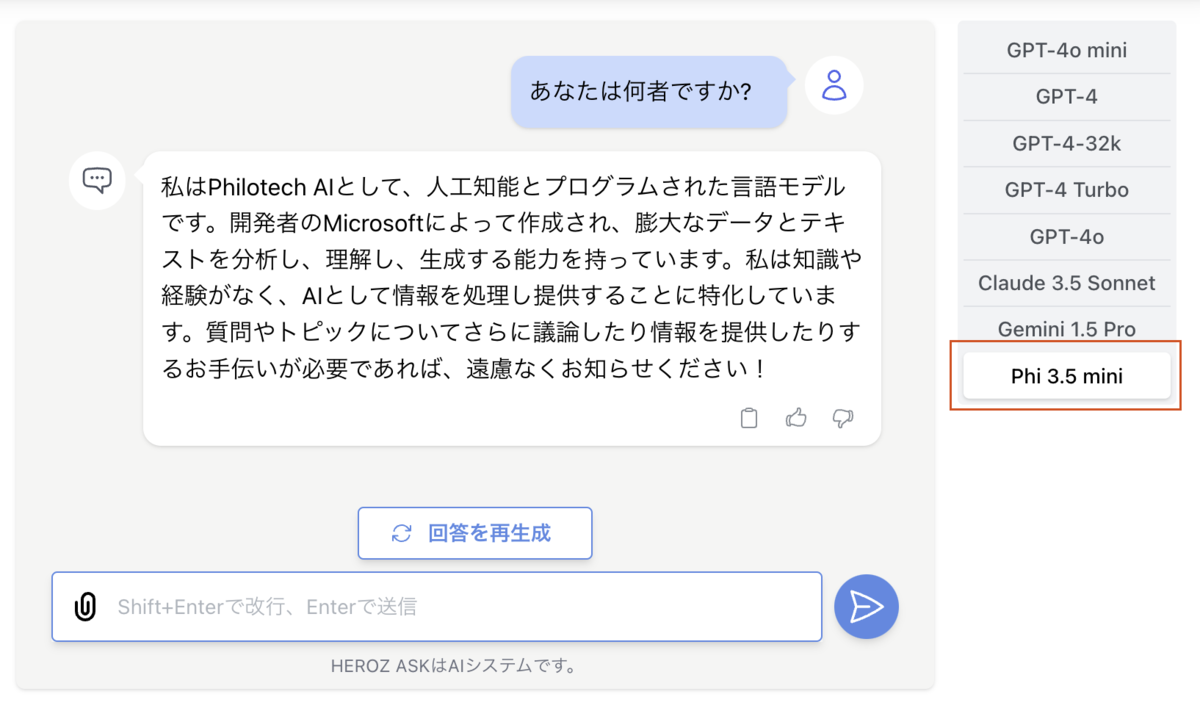 Phi-3.5の動作
Phi-3.5の動作
以下、実行して気になったことです。
モデルの精度については、プロンプトの些細な違いによっては壊れた回答になったり、Few-shotの例に引きづられすぎたりといった小中規模のオープンソースのモデルにありがちな間違いが発生することもありますが、プロンプトが合っていれば正しい回答を得られることは確認できました。
また、Azure Machine Learning サーバーレスAPIによる推論速度はモデルサイズの割には速くはなかったです。 やはりサーバーレスタイプですと、起動のオーバーヘッドがそれなりにあるのかもしれません。
AzureMLChatOnlineEndpoint
from typing import Any, List, Optional from langchain_core.callbacks import ( AsyncCallbackManagerForLLMRun, CallbackManagerForLLMRun, ) from langchain_core.language_models.chat_models import ( agenerate_from_stream, generate_from_stream, ) from langchain_core.messages import BaseMessage from langchain_core.outputs import ChatResult class AzureMLChatOnlineEndpointStreaming(AzureMLChatOnlineEndpoint): streaming: bool = False def _generate( self, messages: List[BaseMessage], stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, stream: Optional[bool] = None, kwargs: Any, ) -> ChatResult: should_stream = stream if stream is not None else self.streaming if should_stream: stream_iter = self._stream( messages, stop=stop, run_manager=run_manager, kwargs ) return generate_from_stream(stream_iter) return super()._generate(messages, stop, run_manager, *kwargs) async def _agenerate( self, messages: List[BaseMessage], stop: Optional[List[str]] = None, run_manager: Optional[AsyncCallbackManagerForLLMRun] = None, kwargs: Any, ) -> ChatResult: should_stream = self.streaming if should_stream: stream_iter = self._astream( messages, stop=stop, run_manager=run_manager, kwargs ) return await agenerate_from_stream(stream_iter) return await super()._agenerate(messages, stop, run_manager, *kwargs)
AzureMLChatOnlineEndpoint
AzureMLChatOnlineEndpoint
今回は話題のSLMについて、Phi-3.5をHEROZ ASKの社内環境で動作させることに成功しました。 まだ多くは触っていないですが、社内で精度限界の検証ならびにユースケースの発掘を引き続き進めていきたいと思います。 何か分かりましたら、別途記事にしようと思います。
原文を表示
モデルのデプロイ 1. ワークスペースの作成
- サーバーレスエンドポイントの作成
Azure AI Foundryで作成したエンドポイントとの比較
langchainからの呼び出しコード
実行結果 モデルの精度と推論速度
昨今、小規模言語モデル(SLM, Small Language Model)の話が生成AI界隈で賑わせています。 SLMはgpt-4oのような大規模言語モデル(LLM, Large Language Model)と比較して小型軽量である故に以下のような特徴があるとされています。
エッジデバイスやオンプレサーバーで動作させることができる。動作させてもコストが大きくならない。 セキュリティーやプライバシーの問題で海外のサーバーへプロンプトを送ることに対しての抵抗は根強くあると思います。
応答までのレイテンシーが短い 特に音声会話のような場合にはミリ秒(ms)を争うので、レイテンシーが低いに越したことはないです。
ドメイン特化のためのファインチューニングを実施しやすい。 従来の中規模や大規模のモデルと比べてはるかに少ないGPU枚数でファインチューニングができるので、敷居が下がることを期待できます。
弊社でもSLMの動向は追っていましたが、以前の実験のように小規模のモデル(この時は10B前後)だと大した精度が出ないと考えていましたので、スルーしていました。 ところが、最近のSLMは以前のgpt-3.5-turboに匹敵する精度が出るという話や、精度が多少劣っても使い所があるかもしれないという話を聞き、遅ればせながら社内向けの環境に導入して、いろいろ検証しようと思いました。
検証に使用したSLMは今年の8月にリリースされたMicrosoft社のPhi-3.5の中で最も軽量なPhi-3.5 mini instructとしました。Phi-3.5 mini instructは3.8Bとかなり軽量です。 これをAzure Machine Learning サーバーレスAPIで動作させました。Phi-3.5 mini instructは1000トークンあたり$0.00013で推論できます。
HEROZ ASKに組み込むにあたってはlangchainで動作するようにしなければならないのですが、Azure Machine Learning サーバーレスAPIへの接続に関する情報がほとんどありませんでしたので、こちらに書こうと思います。
langchainからの呼び出しにはAzureMLChatOnlineEndpoint
以下がMachine Learning Studioでのモデルのデプロイ方法です。
Azure Machine Learning Studioにログインし、ワークスペースを作成する。
ワークスペースの作成
- サーバーレスエンドポイントの作成
作成したワークスペースに入り、エンドポイントページのサーバーレスエンドポイントタブからサーバーレスエンドポイントを作成する。
サーバーレスエンドポイントの作成
作成したエンドポイントの詳細ページを開くと、エンドポイントのURLとAPIキーを取得できます。この時に「APIルート」のパネルがあることがポイントです。
エンドポイントの詳細
Azure AI Foundryで作成したエンドポイントとの比較
Azure AI Foundryで作成したエンドポイントの詳細には「APIルート」が存在しません。
AI Foundryで作成したエンドポイント
Azure AI Foundryのエンドポイント一覧では、Machine Learning Studioで作成したOKの方のエンドポイントは「サーバーレス」となっていて、AI Foundryで作成したNGの方のエンドポイントは「Azure AI Services」となっています。
エンドポイントの一覧
langchainからの呼び出しコード
langchainからは以下のコードにて呼び出すことができます。
!pip install langchain langchain_community from langchain_core.prompts import ChatPromptTemplate from langchain_community.chat_models.azureml_endpoint import AzureMLChatOnlineEndpoint, AzureMLEndpointApiType, CustomOpenAIChatContentFormatter AZURE_PHI3_ENDPOINT="(エンドポイント)" AZURE_PHI3_API_KEY="(APIキー)" human = "あなたは何者ですか?" prompt = ChatPromptTemplate.from_messages([("human", human)]) chat = AzureMLChatOnlineEndpoint( endpoint_url=AZURE_PHI3_ENDPOINT, endpoint_api_type=AzureMLEndpointApiType.serverless, endpoint_api_key=AZURE_PHI3_API_KEY, content_formatter=CustomOpenAIChatContentFormatter(), ) chain = prompt | chat chain.invoke({}) → AIMessage(content='私はMicrosoftのAIアシスタントです。...
Azure AI Foundryで作成したエンドポイントもlangchain_azure_ai
AzureAIChatCompletionsModel
langchain_azure_ai
learn.microsoft.com
HEROZ ASKの社内環境に組み込み、無事に動作しました。
Phi-3.5の動作
以下、実行して気になったことです。
モデルの精度については、プロンプトの些細な違いによっては壊れた回答になったり、Few-shotの例に引きづられすぎたりといった小中規模のオープンソースのモデルにありがちな間違いが発生することもありますが、プロンプトが合っていれば正しい回答を得られることは確認できました。
また、Azure Machine Learning サーバーレスAPIによる推論速度はモデルサイズの割には速くはなかったです。 やはりサーバーレスタイプですと、起動のオーバーヘッドがそれなりにあるのかもしれません。
AzureMLChatOnlineEndpoint
from typing import Any, List, Optional from langchain_core.callbacks import ( AsyncCallbackManagerForLLMRun, CallbackManagerForLLMRun, ) from langchain_core.language_models.chat_models import ( agenerate_from_stream, generate_from_stream, ) from langchain_core.messages import BaseMessage from langchain_core.outputs import ChatResult class AzureMLChatOnlineEndpointStreaming(AzureMLChatOnlineEndpoint): streaming: bool = False def _generate( self, messages: List[BaseMessage], stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, stream: Optional[bool] = None, kwargs: Any, ) -> ChatResult: should_stream = stream if stream is not None else self.streaming if should_stream: stream_iter = self._stream( messages, stop=stop, run_manager=run_manager, kwargs ) return generate_from_stream(stream_iter) return super()._generate(messages, stop, run_manager, *kwargs) async def _agenerate( self, messages: List[BaseMessage], stop: Optional[List[str]] = None, run_manager: Optional[AsyncCallbackManagerForLLMRun] = None, kwargs: Any, ) -> ChatResult: should_stream = self.streaming if should_stream: stream_iter = self._astream( messages, stop=stop, run_manager=run_manager, kwargs ) return await agenerate_from_stream(stream_iter) return await super()._agenerate(messages, stop, run_manager, *kwargs)
AzureMLChatOnlineEndpoint
AzureMLChatOnlineEndpoint
今回は話題のSLMについて、Phi-3.5をHEROZ ASKの社内環境で動作させることに成功しました。 まだ多くは触っていないですが、社内で精度限界の検証ならびにユースケースの発掘を引き続き進めていきたいと思います。 何か分かりましたら、別途記事にしようと思います。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み