Phi-4-reasoning-visionとマルチモーダル推論モデル訓練の教訓
Microsoft Researchは、150億パラメータのマルチモーダル推論モデル「Phi-4-reasoning-vision-15B」を公開し、計算コストと精度のバランス(パレート最適)を追求するトレーニング手法やアーキテクチャ設計の教訓を共有した。
キーポイント
Phi-4-reasoning-vision-15Bの公開と特徴
150億パラメータのオープンウェイトマルチモーダルモデルがMicrosoft Foundry、HuggingFace、GitHubで公開され、画像キャプション、文書読解、数学・科学推論、UI理解など幅広いタスクに対応する。
計算効率と精度のトレードオフの刷新
同等の速度を持つモデルよりも高精度であり、より多くの計算リソースを要する大規模モデルと競争できる性能を持ち、精度と計算コストのパレートフロンティアを押し広げる成果を示している。
トレーニング手法と設計思想の共有
慎重なアーキテクチャ選択、厳格なデータキュレーション、推論用データと非推論用データの混合使用など、マルチモーダル推論モデルを訓練する際のベストプラクティスと教訓を開示している。
小規模モデルによる効率性の追求
Phi-4-reasoning-vision-15Bは、パラメータ数や生成トークン数を抑制し、リソース制約のある環境でも実用的な軽量化を実現している。
学習データと計算コストの削減
約2000億トークンのマルチモーダルデータで学習しており、同規模の競合モデル(1兆トークン以上)と比較して大幅に少ない計算資源で高精度を達成している。
マルチモーダル学習における設計課題
マルチモーダル推論モデルの訓練では、アーキテクチャ(早期融合か中期融合か)、データセットの質と構成、推論重視タスクと知覚重視タスクの相互作用に関する多くの設計上の選択が必要となる。
Mid-fusionアーキテクチャの採用
視覚エンコーダーとLLMを結合するMid-fusion方式を採用し、膨大なトークンで事前学習された既存コンポーネントを活用しつつ、計算リソースと性能のバランスを取った。
影響分析・編集コメントを表示
影響分析
このリリースは、小規模モデルでも高度な推論能力を発揮できることを示し、リソース制約のある環境やコスト敏感なユースケースにおけるAI導入の障壁を下げることになる。特に、計算効率と精度のバランスを最適化したアプローチは、業界標準の見直しを促す可能性がある。
編集コメント
Microsoft Researchが公開したPhi-4シリーズの最新モデルは、計算リソースと性能のバランスを重視する実用的なアプローチを示しており、中小規模の開発者や企業にとって魅力的な選択肢となり得る。
このアプローチには限界がないわけではありません。モード間のバランスは、最近の文献(新しいタブで開く)およびトレーニング中に観察されたモデルの挙動に基づく設計上の選択の直接的な結果ですが、データ分布から暗黙的に学習されるため、モード間の境界は不明確な場合があります。私たちのモデルでは、ユーザーがデフォルトの推論動作を上書きしたい場合に、「」または「」トークンを用いた明示的なプロンプトによる制御が可能です。20対80という推論データと非推論データの分割比は、すべてのドメインや展開コンテキストにおいて最適であるとは限りません。データの理想的なバランスと、モデルがモード間を適切に切り替える能力の評価は、未解決の問題として残っています。
私たちはこの混合アプローチを決定的な解決策ではなく、マルチモーダルシステムにおけるレイテンシ、精度、柔軟性のバランスを取る設計空間における、実用的で十分な根拠のある一つの到達点と見なしています。
応用例
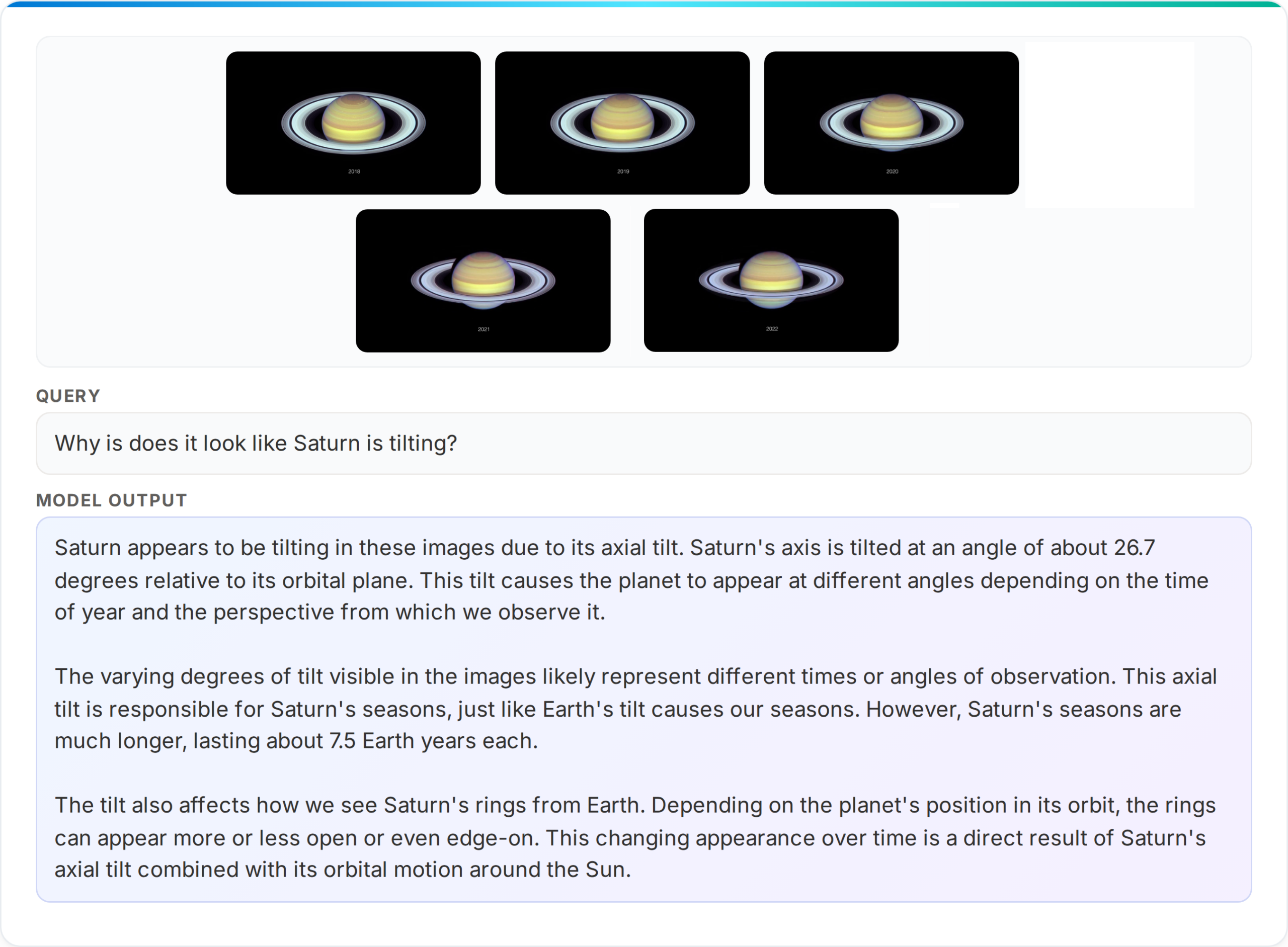 image図4: Phi-4-Reasoning-Visionはシーケンスを解釈できます
image図4: Phi-4-Reasoning-Visionはシーケンスを解釈できます
原文を表示
At a glance
Phi-4-reasoning-vision-15B is a compact and smart open‑weight multimodal reasoning model that balances reasoning power, efficiency, and training data needs. It is a broadly capable model that allows for natural interaction for a wide array of vision-language tasks and excels at math and science reasoning and understanding user-interfaces.
We share lessons learned and best practices for training a multimodal reasoning model—showing the benefit of careful architecture choices, rigorous data curation, and the benefits of using a mixture of reasoning and non-reasoning data.
We are pleased to announce Phi-4-reasoning-vision-15B, a 15 billion parameter open‑weight multimodal reasoning model, available through Microsoft Foundry (opens in new tab), HuggingFace (opens in new tab) and GitHub (opens in new tab). Phi-4-reasoning-vision-15B is a broadly capable model that can be used for a wide array of vision-language tasks such as image captioning, asking questions about images, reading documents and receipts, helping with homework, inferring about changes in sequences of images, and much more. Beyond these general capabilities, it excels at math and science reasoning and at understanding and grounding elements on computer and mobile screens. In particular, our model presents an appealing value relative to popular open-weight models, pushing the pareto-frontier of the tradeoff between accuracy and compute costs. We have competitive performance to much slower models that require ten times or more compute-time and tokens and better accuracy than similarly fast models, particularly when it comes to math and science reasoning.
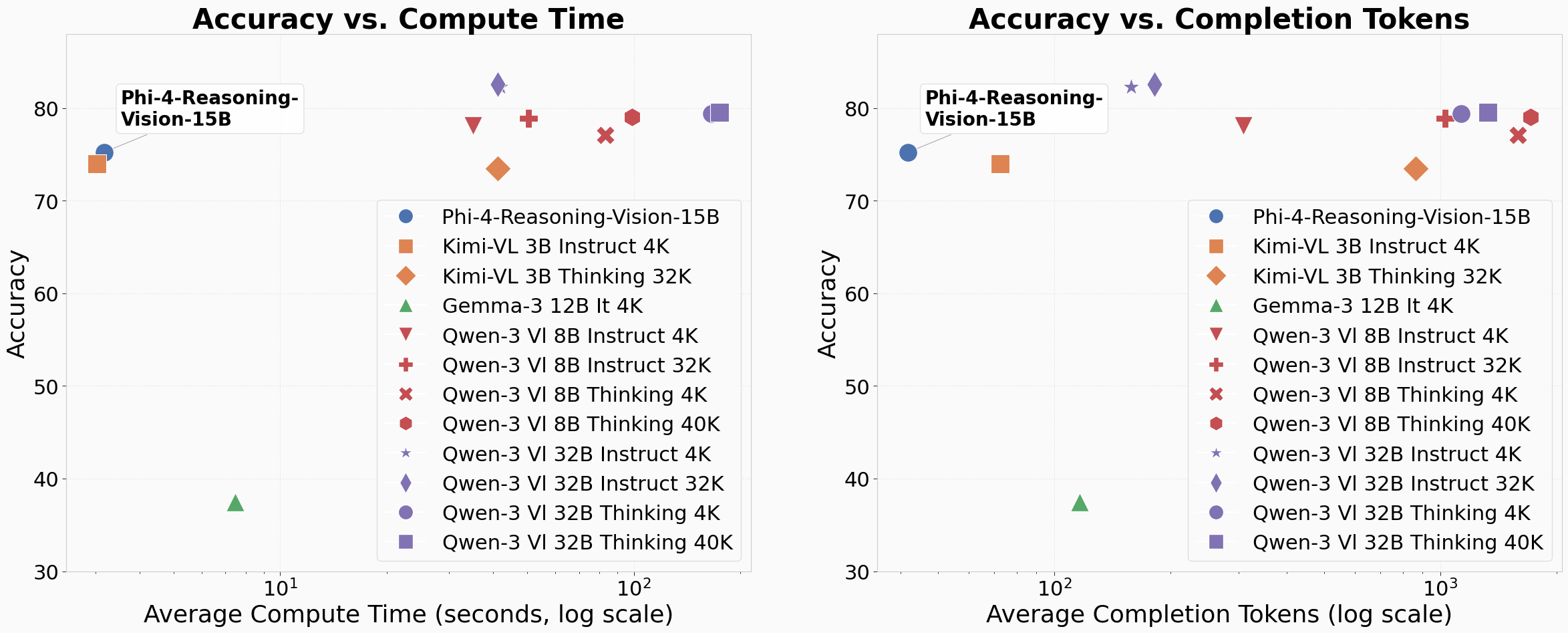 imageFigure 1: Phi-4-reasoning-vision-15B presents a compelling option compared to existing models, pushing the pareto-frontier of the tradeoff between accuracy and compute costs. We have competitive performance to much slower models that require more time and tokens and higher accuracy than similarly fast models. These values were computed by averaging accuracy, time, and output token-counts for a subset of 4 benchmarks: ChartQA_TEST, MathVista_MINI, MMMU_VAL, and ScreenSpot_v2, where we had logged these values.
imageFigure 1: Phi-4-reasoning-vision-15B presents a compelling option compared to existing models, pushing the pareto-frontier of the tradeoff between accuracy and compute costs. We have competitive performance to much slower models that require more time and tokens and higher accuracy than similarly fast models. These values were computed by averaging accuracy, time, and output token-counts for a subset of 4 benchmarks: ChartQA_TEST, MathVista_MINI, MMMU_VAL, and ScreenSpot_v2, where we had logged these values.
In this post, we share the motivations, design choices, experiments, and learnings that informed its development, as well as an evaluation of the model’s performance and guidance on how to use it. Our goal is to contribute practical insight to the community on building smaller, efficient multimodal reasoning models and to share an open-weight model that is competitive with models of similar size at general vision-language tasks, excels at computer use, and excels on scientific and mathematical multimodal reasoning.
A focus on smaller and faster vision–language models
Many popular vision-language models (VLMs) have trended towards growing in parameter count and, in particular, the number of tokens they consume and generate. This leads to increase in training and inference-time cost and latency, and impedes their usability for downstream deployment, especially in resource‑constrained or interactive settings.
A growing countertrend towards smaller (opens in new tab) models aims to boost efficiency, enabled by careful model design and data curation – a goal pioneered by the Phi family of models (opens in new tab) and furthered by Phi-4-reasoning-vision-15B. We specifically build on learnings from the Phi-4 and Phi-4-Reasoning language models and show how a multimodal model can be trained to cover a wide range of vision and language tasks without relying on extremely large training datasets, architectures, or excessive inference‑time token generation. Our model is intended to be lightweight enough to run on modest hardware while remaining capable of structured reasoning when it is beneficial. Our model was trained with far less compute than many recent open-weight VLMs of similar size. We used just 200 billion tokens of multimodal data leveraging Phi-4-reasoning (trained with 16 billion tokens) based on a core model Phi-4 (400 billion unique tokens), compared to more than 1 trillion tokens used for training multimodal models like Qwen 2.5 VL (opens in new tab) and 3 VL (opens in new tab), Kimi-VL (opens in new tab), and Gemma3 (opens in new tab). We can therefore present a compelling option compared to existing models pushing the pareto-frontier of the tradeoff between accuracy and compute costs.

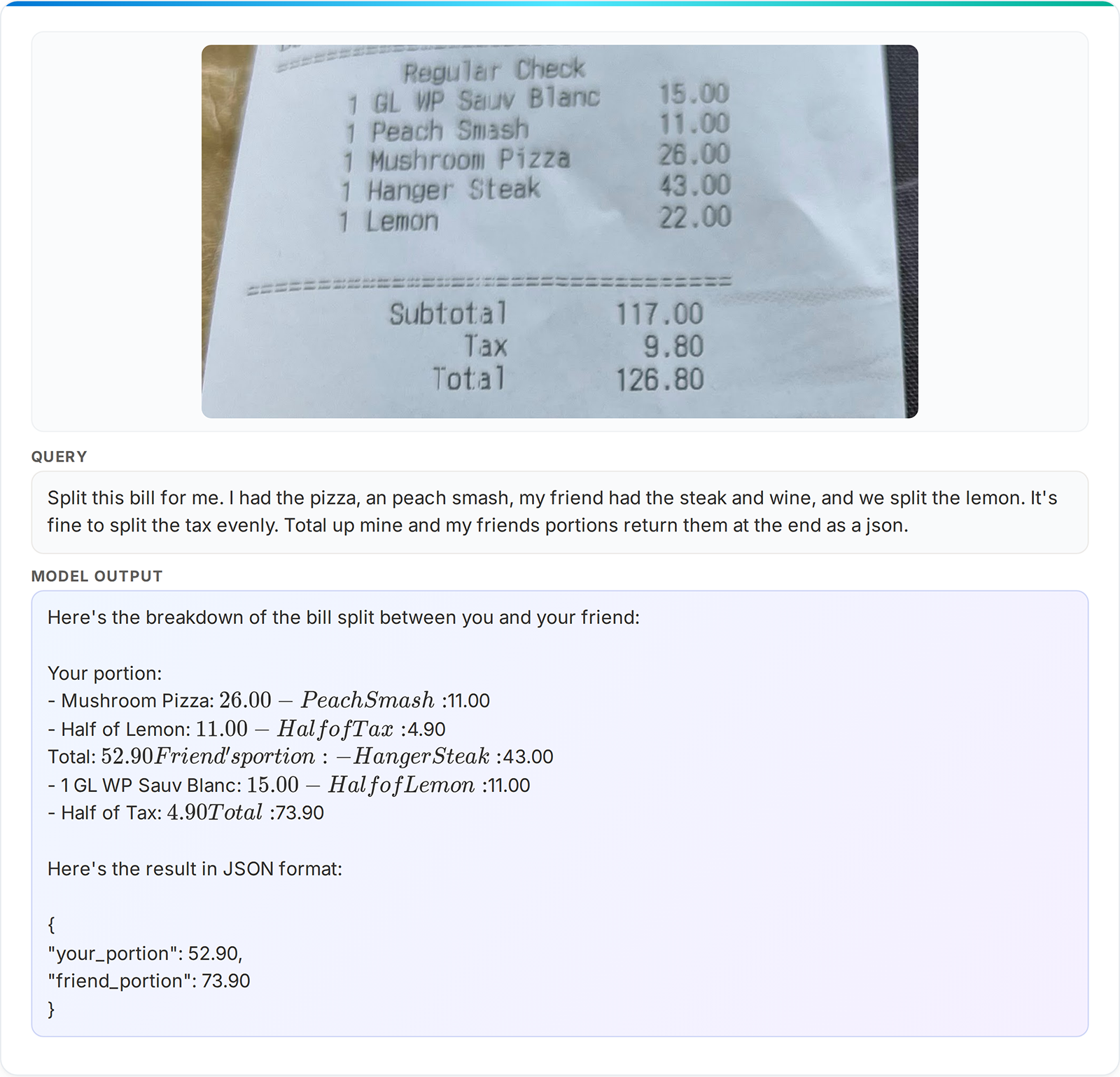
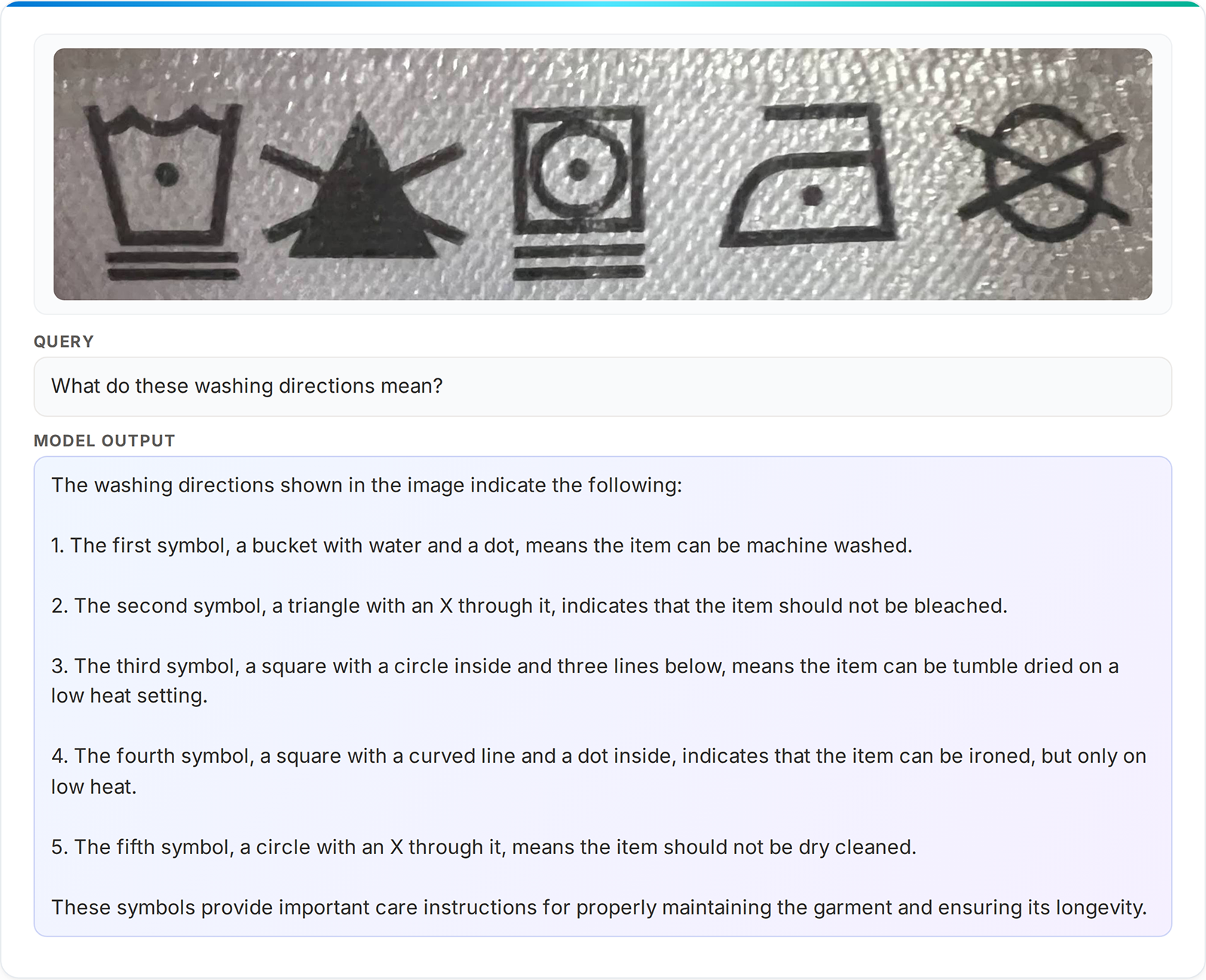
Figure 2: Phi-4-Reasoning-Vision can help with a wide range of everyday tasks.
Lessons from training a multimodal model
Training a multimodal reasoning model raises numerous questions and requires many nuanced design choices around model architecture, dataset quality and composition, and the interaction between reasoning‑heavy and non-reasoning perception‑focused tasks.
Model architecture: Early- vs mid-fusion
Model architectures for VLMs differ primarily in how visual and textual information is fused. Mid-fusion models use a pretrained vision encoder to convert images into visual tokens that are projected into a pretrained LLM’s embedding space, enabling cross-modal reasoning while leveraging components already trained on trillions of tokens. Early-fusion models process image patches and text tokens in a single model transformer, yielding richer joint representations but at significantly higher compute, memory, and data cost. We adopted a mid-fusion architecture as it offers a practical trade-off for building a performant model with modest resources.
Model architecture: Vision encoder and image processing
We build on the SigLIP-2 (opens in new tab) vision encoder and the Phi-4-Reasoning backbone. In previous research, we found that multimodal language models sometimes struggled to solve tasks, not because of a lack of reasoning proficiency, but rather an inability to extract and select relevant perceptual information from the image. An example would be a high-resolution screenshot that is information-dense with relatively small interactive elements.
Several open-source multimodal language models have adapted their methodologies accordingly, e.g., Gemma3 (opens in new tab) uses pan-and-scan and NVILA (opens in new tab) uses Dynamic S2. However, their trade-offs are difficult to understand across different datasets and hyperparameters. To this end, we conducted an ablation study of several techniques. We trained a smaller 5 billion parameter Phi-4 based proxy model on a dataset of 10 million image-text pairs, primarily composed of computer-use and GUI grounding data. We compared with Dynamic S2, which resizes images to a rectangular resolution that minimizes distortion while admitting a tiling by 384×384 squares; Multi-crop, which splits the image into potentially overlapping 384×384 squares and concatenates their encoded features on the token dimension; Multi-crop with S2, which broadens the receptive field by cropping into 1536×1536 squares before applying S2; and Dynamic resolution using the Naflex variant of SigLIP-2, a natively dynamic-resolution encoder with adjustable patch counts.
Our primary finding is that dynamic resolution vision encoders perform the best and especially well on high-resolution data. It is particularly interesting to compare dynamic resolution with 2048 vs 3600 maximum tokens: the latter roughly corresponds to native HD 720p resolution and enjoys a substantial boost on high-resolution benchmarks, particularly ScreenSpot-Pro. Reinforcing the high-resolution trend, we find that multi-crop with S2 outperforms standard multi-crop despite using fewer visual tokens (i.e., fewer crops overall). The dynamic resolution technique produces the most tokens on average; due to their tiling subroutine, S2-based methods are constrained by the original image resolution and often only use about half the maximum tokens. From these experiments we choose the SigLIP-2 Naflex variant as our vision encoder.
MethodMax TokensMathVistaScreenSpotScreenSpot-ProV*Bench
Dynamic-S2309642.978.49.452.9
Multi-crop309643.467.85.451.8
Multi-crop with S2204843.479.110.657.1
Dynamic resolution204845.281.59.251.3
Dynamic resolution360044.979.717.556.0
Table 1: Results with different resolution handling approaches. The top two configurations on each benchmark are in bold.
Data: Quality and composition
As with its language backbone Phi-4-Reasoning, Phi-4-reasoning-vision-15B was trained with a deliberate focus on data quality. Our final dataset consists primarily of data from three sources: open-source datasets which were meticulously filtered and improved; high-quality domain-specific internal data; and high-quality data from targeted acquisitions. The overwhelming majority of our data lies in the first category: data which originated as open-source data, which were significantly filtered and improved, whether by removing low-quality datasets or records, programmatically fixing errors in data formatting, or using open-source images as seeds to synthetically generate higher-quality accompanying text.
The process of improving open-source data began by manually reviewing samples from each dataset. Typically, 5 to 10 minutes were sufficient to classify data as excellent-quality, good questions with wrong answers, low-quality questions or images, or high-quality with formatting errors. Excellent data was kept largely unchanged. For data with incorrect answers or poor-quality captions, we re-generated responses using GPT-4o and o4-mini, excluding datasets where error rates remained too high. Low-quality questions proved difficult to salvage, but when the images themselves were high quality, we repurposed them as seeds for new caption or visual question answering (VQA) data. Datasets with fundamentally flawed images were excluded entirely. We also fixed a surprisingly large number of formatting and logical errors across widely used open-source datasets.
We extracted additional value from existing datasets through reformatting, diversification, and using images as seeds for new data generation. We generated detailed image descriptions alongside original QA pairs for math and science data, had data perform “double-duty” by embedding instruction-following requirements directly into domain-specific QA, created “scrambled,” “caption-matching,” and “what’s changed?” records to improve multi-image reasoning and sequential navigation for CUA scenarios, and diversifying prompt styles to encourage robustness beyond perfectly structured questions.
To supplement the improved open-source data, we utilize high-quality internal datasets, several math-specific datasets which were acquired during training of the Phi-4 language model, and also some domain-specific curated data; for example, latex-OCR data generated by processing and rendering equations from arXiv documents.
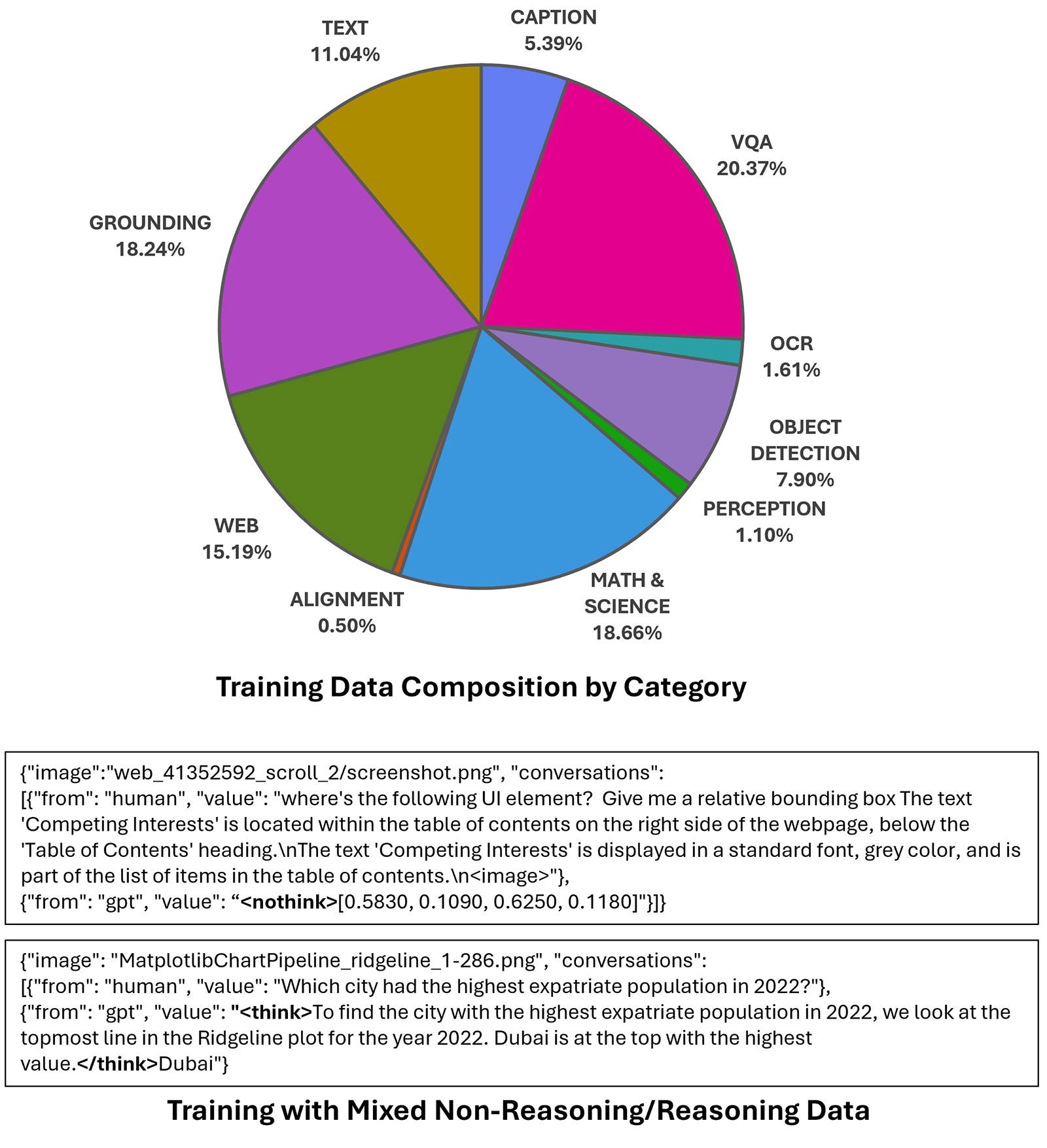
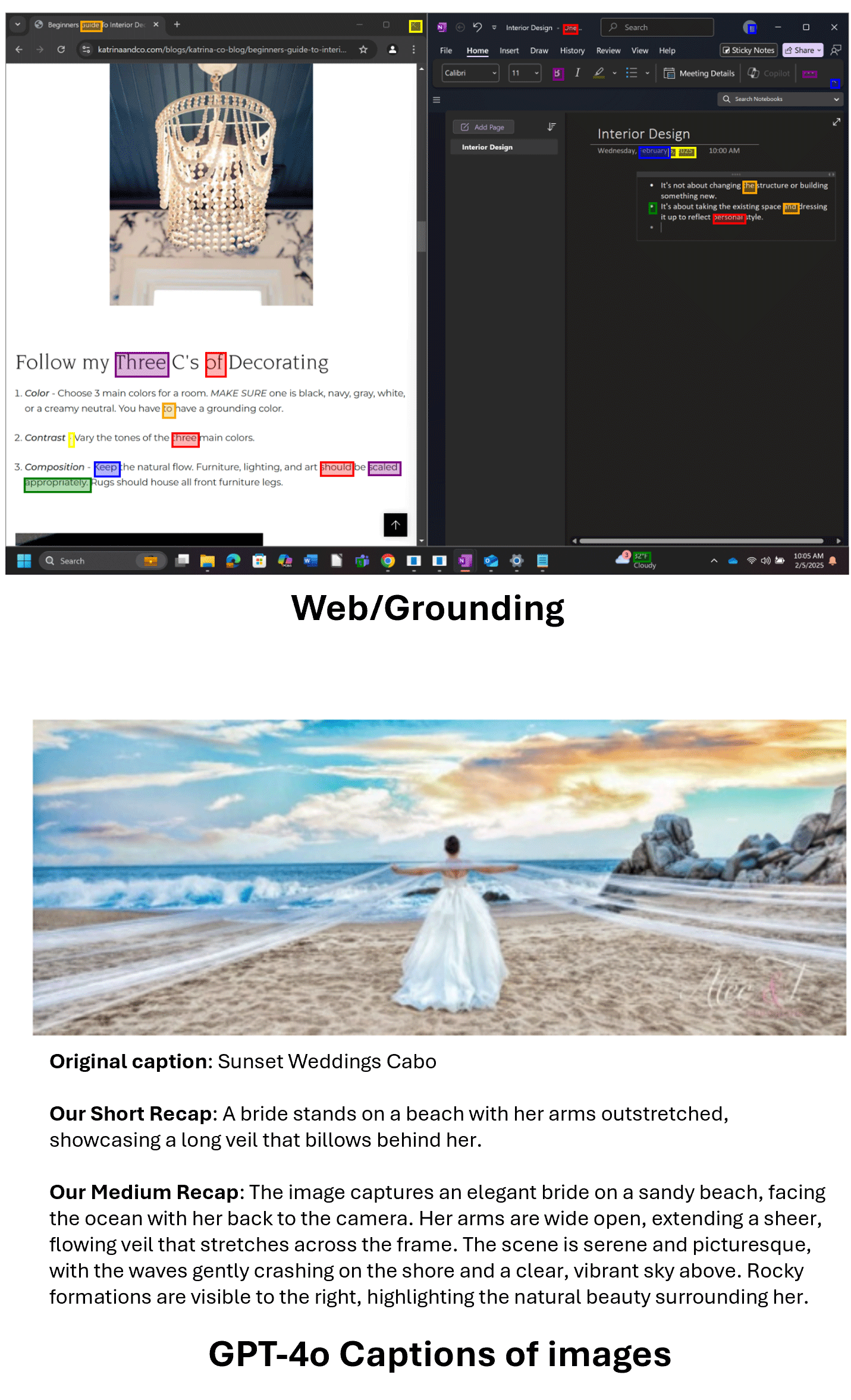
Figure 3: Phi-4-reasoning-vision-15B training data composition and examples
Data: Mathematics vs. computer-use data proportion
One of our goals was to train a model that performs well across general vision-language tasks, while excelling at mathematical and scientific reasoning and computer-use scenarios. How to structure datasets for generalizable reasoning remains an open question—particularly because the relationship between data scale and reasoning performance can lead to starkly different design decisions, such as training a single model on a large dataset versus multiple specialized models with targeted post-training.
Research on long-tailed classification robustness has suggested that balancing or removing data from overrepresented tasks or subgroups (opens in new tab) is an effective method for ensuring good performance. Nevertheless, these insights are not fully utilized or explored when it comes to training VLMs, which at times have favored scale over careful data balancing. To achieve our goals, we conducted a set of experiments to analyze a range of data ratios between our focus domains.
Using the same 5 billion parameter proxy model as for previous experiments, we trained while varying the amount of mathematics and science vs. computer-use data for each run. Each dataset included the same subset of 1 million general image-text pairs as a baseline. For mathematics and science data, we used a subsample of 150,000 records, optionally duplicating each one up to three times. Next, we included up to 450,000 computer-use records, and optionally an additional 400,000 from Phi-Ground.
We found that that multimodal mathematics and science performance were not harmed by additional computer-use data, and vice versa. Interestingly, we found that increasing mathematics data by 3x while keeping computer-use data constant improved math, science, and computer-use benchmarks.
GeneralMath and ScienceCUATotalMMMUMathVistaScreenSpot-V2
1M150K450K1.6M44.037.448.2
1M150K850K2.0M44.137.360.0
1M450K450K1.9M45.336.048.3
1M450K850K2.3M43.438.963.1
1M150K150K1.3M44.236.929.8
1M150K250K1.4M45.437.437.7
Table 2: Varying the ratios of math and CUA data. Increasing math data by 3x while keeping computer-use data constant improves both math and computer-use benchmarks.
Data: Synthetic data for text-rich visual reasoning
Recent work (opens in new tab) suggests that targeted synthetic data can materially improve multimodal reasoning, particularly for text-rich visual domains such as charts, documents, diagrams, and rendered mathematics. Using images, questions, and answers that are programmatically generated and grounded in the visual structure enables precise control over visual content and supervision quality, resulting in data that avoids many annotation errors, ambiguities, and distributional biases common in scraped datasets. This enables cleaner alignment between visual perception and multi-step inference, which has been shown to translate into measurable gains on reasoning-heavy benchmarks.
Synthetic text-rich images expand coverage of long-tail visual formats that are underrepresented in real data but disproportionately impact reasoning accuracy, improving not only visual grounding but also downstream reasoning by ensuring that failures are less often caused by perceptual errors. We found that programmatically generated synthetic data is a useful augmentation to high-quality real datasets — not a replacement, but a scalable mechanism for strengthening both perception and reasoning that complements the training objectives in compact multimodal models such as Phi-4-reasoning-vision-15B.
Mixing non-reasoning and reasoning as a design objective
In language-only settings, reasoning traces have improved performance on many tasks, but they require additional compute which adds undesired latency. In multimodal settings, this tradeoff is less clear-cut, for tasks such as image captioning and optical character recognition (OCR), reasoning is often unnecessary and can even be harmful (opens in new tab), while mathematical and scientific problem-solving benefit from multi-step reasoning. Thus, the choice of when to reason or not can be quite nuanced.
Training approaches for multimodal reasoning models
Language-only reasoning models are typically created through supervised fine-tuning (SFT) or reinforcement learning (RL): SFT is simpler but requires large amounts of expensive reasoning trace data, while RL reduces data requirements at the cost of significantly increased training complexity and compute. Multimodal reasoning models follow a similar process, but the design space is more complex. With a mid-fusion architecture, the first decision is whether the base language model is itself a reasoning or non-reasoning model. This leads to several possible training pipelines:
Non-reasoning LLM → reasoning multimodal training: Reasoning and multimodal capabilities are trained together.
Non-reasoning LLM → non-reasoning multimodal → reasoning multimodal training: Multimodal capabilities are learned first, then reasoning is added.
Reasoning LLM → reasoning multimodal training: A reasoning base is used, but all multimodal data must include reasoning traces.
Our approach: Reasoning LLM → mixed non-reasoning / reasoning multimodal training. A reasoning-capable base is trained on a hybrid data mixture, learning when to reason and when to respond directly.
Approaches 1 and 2 offer flexibility in designing multimodal reasoning behavior from scratch using widely available non-reasoning LLM checkpoints but place a heavy burden on multimodal training. Approach 1 must teach visual understanding and reasoning simultaneously and requires a large amount of multimodal reasoning data, while Approach 2 can be trained with less reasoning data but risks catastrophic forgetting, as reasoning training may degrade previously learned visual capabilities. Both risk weaker reasoning than starting from a reasoning-capable base. Approach 3 inherits strong reasoning foundations, but like Approach 1, it requires reasoning traces for all training data and produces reasoning traces for all queries, even when not beneficial.
Our approach: A mixed reasoning and non-reasoning model
Phi-4-reasoning-vision-15B adopts the 4th approach listed previously, as it balances reasoning capability, inference efficiency, and data requirements. It inherits a strong reasoning foundation but uses a hybrid approach to combine the strengths of alternatives while mitigating their drawbacks. Our model defaults to direct inference for perception-focused domains where reasoning adds latency without improving accuracy, avoiding unnecessary verbosity and reducing inference costs, and it invokes longer reasoning paths for domains, such as math and science, that benefit from structured multi-step reasoning (opens in new tab).
Our model is trained with SFT, where reasoning samples include “…” sections with chain-of-thought reasoning before the final answer, covering domains like math and science. Non-reasoning samples are tagged to start with a “” token, signaling a direct response, and cover perception-focused tasks such as captioning, grounding, OCR, and simple VQA. Reasoning data comprises approximately 20% of the total mix. Starting from a reasoning-capable backbone means this data grounds existing reasoning in visual contexts rather than teaching it to reason from scratch.
This approach is not without limitations. The balance between modes is a direct function of design choices we made, informed by recent literature (opens in new tab) and observed model behavior during training—though the boundary between modes can be imprecise as it is learned implicitly from the data distribution. Our model allows control through explicit prompting with “” or “” tokens when the user wants to override the default reasoning behavior. The 20/80 reasoning-to-non-reasoning data split may not be optimal for all domains or deployment contexts. Evaluating the ideal balance of data and the model’s ability to switch appropriately between modes remains an open problem.
We view this mixed approach not as a definitive solution, but as one practical and well-motivated point in the design space for balancing latency, accuracy, and flexibility in multimodal systems.
Applications
imageFigure 4: Phi-4-Reasoning-Vision can interpret sequence
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み