Amazon SageMaker Unified StudioとSageMaker Catalogを使用したオフライン機能ストアの構築
AWSはSageMaker Unified StudioとCatalogを活用し、S3 TablesやApache Iceberg、Lake Formationを統合したオフラインフィーチャーストアの構築ガイドを発表し、MLチーム間での機能管理とガバナンスを効率化する。
キーポイント
ML機能管理の分散課題
パイプラインの断片化と定義の不整合がモデル精度の低下やガバナンス不全を招くため、一元化された機能管理基盤が必須となる。
SageMaker統合ソリューション
Unified StudioとCatalogを活用した公開・購読パターンにより、データエンジニアとデータサイエンティスト間の資産共有と協業が安全に実現する。
技術スタックの統合設計
S3 TablesとApache Icebergでトランザクション整合性を保証し、Lake Formationで細粒度アクセス制御を適用する実装パターンを示す。
運用効率と再現性の向上
時系列整合性のあるデータ提供によりデータリーケージを防ぎ、実験の再現性と企業横断的な機能再利用を加速させる。
影響分析・編集コメントを表示
影響分析
本記事は、大規模なML運用における機能管理のベストプラクティスを具体化しており、特にAWSエコシステム利用者にとってMLOpsの成熟度を高める実装基準となる。オープン標準(Iceberg)とマネージドサービスの組み合わせは、ベンダーロックインを緩和しつつガバナンスを強化する傾向を示しており、業界全体のMLインフラ標準化に寄与する。
編集コメント
既存のオープン標準をAWSマネージドサービスで包み込むアプローチは、実装コストを抑えつつガバナンスを確保する現実的な解と言える。ただし、オンプレミスや他クラウド環境への移植性を考慮した設計ガイドが別途必要となる点には留意が必要だ。
大規模な機械学習(ML)機能の構築と管理は、現代のデータサイエンスワークフローにおいて最も重要かつ複雑な課題の一つです。組織では、断片化された機能パイプライン、一貫性のないデータ定義、チーム間での重複するエンジニアリング作業に苦労することがよくあります。機能の保存と再利用のための集中型システムがない場合、モデルが古びたまたは不一致のデータでトレーニングされるリスクがあり、その結果、汎化性能の低下、モデル精度の低下、ガバナンス上の問題が生じます。さらに、各グループが独自の孤立したデータセットと変換を維持している場合、データエンジニアリング、データサイエンス、ML 運用チーム間の協力を促進することが困難になります。
Amazon SageMaker は、SageMaker Unified Studio と SageMaker Catalog を通じてこれらの課題に対処します。これらは組織がプロジェクトやアカウント間で資産を安全に構築、管理、共有するために使用できます。このエコシステムにおける重要な機能の一つは、オフライン特徴ストアの実装です。これはモデルのトレーニングと検証に使用される履歴特徴データを管理するために設計された構造化リポジトリです。オフライン特徴ストアは、スケーラビリティ、系譜追跡、再現性を目的として設計されており、データサイエンティストがデータリークを防ぎ、実験全体で一貫性を維持する正確な時間整合型データセット上でモデルをトレーニングできるようにします。
本ブログ記事では、SageMaker Unified Studio ドメイン内で SageMaker Catalog を活用してオフライン特徴ストアを実装するためのステップバイステップのガイドを提供します。公開・購読パターンを採用することで、データプロデューサーはキュレーション済みでバージョン管理された特徴テーブルを公開でき、データコンシューマーはそれらを安全に発見し、購読し、モデル開発のために再利用できます。このアプローチでは、トランザクション整合性のために Amazon S3 Tables と Apache Iceberg を統合し、細粒度アクセス制御には AWS Lake Formation を、視覚的およびコードベースのデータエンジニアリングには Amazon SageMaker Studio をそれぞれ活用します。
この統一されたソリューションを通じて、チームは一貫した特徴ガバナンスを達成し、機械学習の実験を加速し、運用オーバーヘッドを削減できます。本記事では、信頼できる ML 特徴の企業全体での再利用を実現するための、協力的でガバナンスが効いた、かつ本番環境対応のオフライン特徴ストアを設計する方法をご紹介します。
ソリューションの概要
このソリューションは、SageMaker Catalog と統合された SageMaker Unified Studio ドメイン を用いてオフライン特徴量ストアを実装する方法を示しています。これにより、ML チーム間でスケーラブルでガバナンスが効き、協働可能な特徴量管理が可能になります。本アーキテクチャは、管理者、データエンジニア、データサイエンティストが高品質で再利用可能な特徴量テーブルを作成し、公開し、利用するプロセスを効率化する統一された環境を構築します(以下の図参照)。
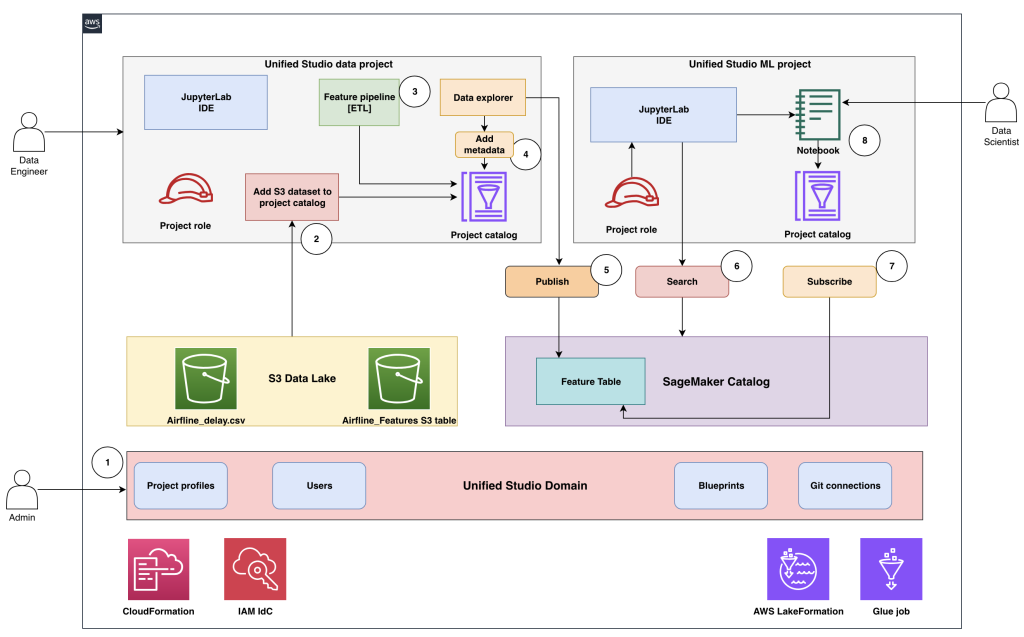
中核となるこのソリューションでは、SageMaker Unified Studio ドメインをガバナンスおよび協働のレイヤーとして活用し、中央集権的な管理下でプロジェクト、ユーザー、データ資産を管理します。Apache Iceberg 形式の S3 Tables が特徴量データの保存とバージョン管理の基盤となります。また、データセットに対する統一されたガバナンスを可能にする SageMaker Catalog は、特徴量テーブルの公開、発見、購読のための中央レジストリとして機能します。
以下に、エンドツーエンドのワークフローにおける各ペルソナ(役割)がどのように関与するかを説明します。
- 管理者は、AWS CloudFormation テンプレートと AWS Management Console を使用して環境を設定・構成します。これには、SageMaker Unified Studio ドメインのプロビジョニングや、ユーザーおよびグループのオンボーディングが含まれます。
- 管理者は SageMaker Unified Studio のデータプロジェクトを作成し、航空遅延データ(airline_delay.csv)や S3 テーブルである airline_features など、Amazon Simple Storage Service (Amazon S3) データセットをプロジェクトカタログに登録します。その後、データエンジニアをプロジェクトの所有者として指定します。
- データエンジニアはデータプロジェクトを開き、ビジュアル型抽出・変換・ロード(ETL)ツールまたはデータ処理ジョブを使用して特徴量パイプラインを構築し、プロジェクトカタログ内の airline_features テーブル内で特徴量を作成します。
- データエンジニアはデータエクスプローラーツールにアクセスして、airline_features テーブルにメタデータを付与し、発見可能性とガバナンスの向上を図ります。
- 検証および承認の後、データエンジニアは airline_features テーブルを SageMaker Catalog に公開し、組織全体での利用を可能にします。
- データサイエンティストは ML プロジェクトを開き、AI 搭載検索機能を使用してカタログ内の airlines_features テーブルを検索し、モデル開発に適した公開済み特徴量テーブルを特定します。
- データサイエンティストは、公開された特徴量テーブルの購読リクエストを提出します。自動承認が設定されていない場合、パブリッシャーがアクセス要求を確認して承認する必要があります。
- 承認後、データサイエンティストはプロジェクトカタログを通じて、データエクスプローラーおよび Jupyter ノートブックから直接、モデルトレーニングや実験のために特徴量テーブルにアクセスできるようになります。
この構造化されたワークフローにより、一貫したデータガバナンスが提供され、協力が促進されるとともに、信頼性が高くバージョン管理された ML 特徴量を企業全体で再利用可能にするため、重複する特徴量エンジニアリングの努力を排除します。
コアコンポーネント
オフラインフィーチャーストアのソリューションアーキテクチャは、いくつかの統合されたコンポーネントで構成されています。各コンポーネントは、セキュアなデータガバナンスの実現、スケーラブルな特徴量エンジニアリング、および ML パーソンナ間でのシームレスなコラボレーションを可能にする上で、それぞれ固有の役割を果たします。主要なコンポーネントには以下が含まれます:
SageMaker Unified Studio ドメイン: SageMaker Unified Studio ドメインは、ML プロジェクト、ユーザー、データアセットを管理するための中央制御プレーンとして機能します。データエンジニア、データサイエンティスト、管理者間のコラボレーションのための統一されたインターフェースを提供します。このドメインでは、きめ細やかなアクセス制御の適用が可能となり、AWS IAM Identity Center と統合してシングルサインオンを実現し、チームやアカウント間での ML アセットの安全な共有を支援する承認ワークフローをサポートします。
Apache Iceberg 形式の S3 Tables: S3 Tables は、Apache Iceberg テーブルフォーマットを使用して、特徴量データのスケーラブルでサーバーレスなストレージを実現します。Apache Iceberg Open Table Format (OTF) は、ACID トランザクション、スキーマ進化、タイムトラベル機能を可能にし、チームはこれらを活用して、完全な再現性を保ちながら特徴量データの履歴バージョンをクエリすることができます。S3 Tables は Spark、Glue、および SageMaker とシームレスに統合され、分析ワークロードと ML ワークロードの両方で一貫したデータアクセスを実現します。
特徴量エンジニアリングパイプライン: 特徴量エンジニアリングパイプラインは、生データセットをキュレーション済みで高品質な特徴量へ変換するプロセスを自動化します。Apache Spark を基盤として構築されており、大規模な分散データ処理を提供することで、遅延率の計算、カテゴリカルエンコーディング、特徴量の集約といった複雑な変換を可能にします。このパイプラインは出力を直接 S3 テーブルへ書き込むため、生データ/処理済みデータとエンジニアリングされた特徴量との間の追跡可能性と一貫性を確保するのに役立ちます。
SageMaker Catalog: SageMaker Catalog は、データセット、特徴量テーブル、モデルなどの ML アセットの登録、公開、発見のための組織全体のリポジトリとして機能します。Lake Formation と統合して細粒度のアクセス制御を提供し、IAM Identity Center と統合してユーザー管理を担います。カタログはメタデータの拡張、バージョン管理、承認ワークフローをサポートしており、チームが信頼できるアセットをプロジェクト間で安全に共有・再利用できるようになります。
これら 2 つのコンポーネントは、エンタープライズグレードのガバナンスとデータ系譜(ラインジーン)追跡を維持しつつ、ML 特徴量のライフサイクル管理(作成から公開、発見、利用まで)を簡素化する、まとまったエコシステムを構築します。
管理者ワークフロー
管理者ワークフローは、オフライン特徴ストアを実装するための安全かつ協力的な環境を確立するために必要な初期セットアップを定義します。管理者は SageMaker Unified Studio ドメインのプロビジョニングを行い、ユーザー認証のために IAM Identity Center を有効化し、Lake Formation を使用した S3 テーブルを設定して統制されたデータアクセスを実現します。また、専用のプロデューサーおよびコンシューマープロジェクトを作成し、環境ブループリント(CloudFormation ベース)を通じて必要なインフラストラクチャを展開し、適切な権限を持つユーザーとグループを割り当てます。このセットアップにより、データエンジニアやデータサイエンティストが SageMaker Unified Studio 内でシームレスに ML 特徴の構築、公開、利用を行うことができるよう、一貫性があり適切に統制された基盤が確保されます。
前提条件
シームレスな統合とガバナンスのために必要な AWS サービスおよび権限が適切に設定されるようにするため、以下の前提条件を完了させる必要があります。
- IAM Identity Center を有効にする
コンソールで IAM Identity Center に移動します。
- すでにアクティブ化されていない場合は「有効にする」を選択してください。
- AWS Organizations と連携して有効にするか、スタンドアロンとして有効にし、セットアップウィザードを完了してください。
- S3 Tables を有効にする
コンソールで Amazon S3 に移動します。
- S3 Tables セクションを選択し、「S3 Tables 統合の有効化」を選択してください。
- Lake Formation の管理者
リソースの作成と権限管理を適切に行うために、コンソールのロールが Lake Formation の管理者に追加されていることを確認してください。
環境の設定
前提条件を完了した後、次のステップはオフラインフィーチャーストアアーキテクチャ内でユーザー、プロジェクト、データ資産を管理するための中央作業領域として機能する SageMaker Unified Studio ドメインを作成および設定することにより、環境を設定することです。
SageMaker Unified Studio ドメインのセットアップ:
- SageMaker Unified Studio コンソールに移動し、ナビゲーションペインで「ドメイン」を選択します。「ドメインの作成」をクリックし、「クイックセットアップ」を選択してください。
- ドメインのネットワーク設定のために、新しい VPC を作成するか、既存の VPC を選択します。
- 「クイックセットアップの設定」を展開し、ドメイン名(例:Corporate)を入力します。
- 「ドメイン実行ロール」と「ドメインサービスロール」については、「新規サービスロールを作成して使用」を選択してください。
- VPC(SageMaker Unified Studio とタグ付けされた VPC は正しく設定されている必要があります)を選択し、異なるアベイラビリティゾーンに配置された少なくとも 3 つのプライベートサブネットを選択します。
- 「次へ」をクリックしてドメイン作成を続行します。
- IAM Identity Center ユーザーアカウントを作成するには、メールアドレス、名、姓を入力してください(作成後、IAM Identity Center アカウントを有効化するためのメールが送信されます)。
- 「ドメインの作成」を選択してドメイン作成プロセスを開始します。ドメインの作成には通常 2〜5 分かかります。
SageMaker Unified Studio プロジェクトの作成:
- SageMaker Unified Studio のドメイン URL にアクセスし、ドメイン設定時に作成された IAM Identity Center の資格情報を使用してサインインし、受信した招待メールがあればそれを受け入れてください。
- プロジェクトの作成:
ドメインホームページから「プロジェクトの選択」へ移動し、「プロジェクトの作成」を選択してプロデューサー用プロジェクトを作成し、その名前は airlines_core_features とします。説明を追加し、設定を構成し、ユーザーと権限を割り当てます。
- プロジェクトのプロファイルでは、「すべての機能(All Capabilities)」を選択してください。
- 上記の 2 つの手順を繰り返して、コンシューマー用プロジェクト airlines_ml_models を作成します。注記:プロジェクトの作成には通常 5〜10 分かかります。
- プロジェクトロール ARN のコピー
airlines_core_features プロジェクトの詳細ページへ移動します。
- プロジェクトにアクセスし、プロジェクトロールの Amazon Resource Name (ARN)(arn:aws:iam::ACCOUNT:role/datazone_usr_role_*)をコピーしてください。
- 上記の 2 つの手順を airlines_ml_models に対しても繰り返してください。
インフラストラクチャのデプロイメント
ドメイン作成、プロジェクト作成、IAM Identity Center のセットアップ、S3 Tables(Amazon S3 テーブル)の有効化を含む上記の手順が完了した後、CloudFormation スタックのみをデプロイしてください。このスタックには以下の入力パラメータが必要です:
- IAM Identity Center ID: IAM Identity Center コンソールに移動して、AWS アクセスポータルの URL の最初の部分を取得します。形式は https://d-1234da5678.awsapps.com/start のようになります。
- SMUSProducerProjectRoleName: Unified Studio プロジェクトポータルに移動し、プロデューサープロジェクトを開いて、プロジェクトロール名を取得します。例:arn:aws:iam:::role/datazone_usr_role_xxxx_yyyy
- SMUSConsumerProjectRoleName: 上記の手順を繰り返して、コンシューマープロジェクトのロール名を取得します。
スタックが正常にデプロイされると、以下の AWS リソースが作成されます:
- S3 バケット:生データおよびキュレーション済みデータの保存用(例:amzn-s3-demo-blog-smus-featurestore-{account-id})
- S3 テーブルバケット:Iceberg テーブルの保存用(例:amzn-s3-demo-airlines-s3tables-bucket)
- S3 テーブル名前空間:整理された特徴量テーブルの名前空間(例:airlines)
- S3 テーブル:特徴量の保存用(例:fg_airline_features)
- Glue データベース:ソースデータのカタログ用(例:airline_raw_db)
- IAM Identity Center グループ:プロデューサーおよびコンシューマーグループ(例:FeatureStore-Producers, FeatureStore-Consumers)
- Lake Formation 権限:細粒度アクセス制御(例:データベースおよびテーブルへの権限)
- IAM ロールとポリシー:サービス統合用(例:SageMaker 実行ロール)。
##
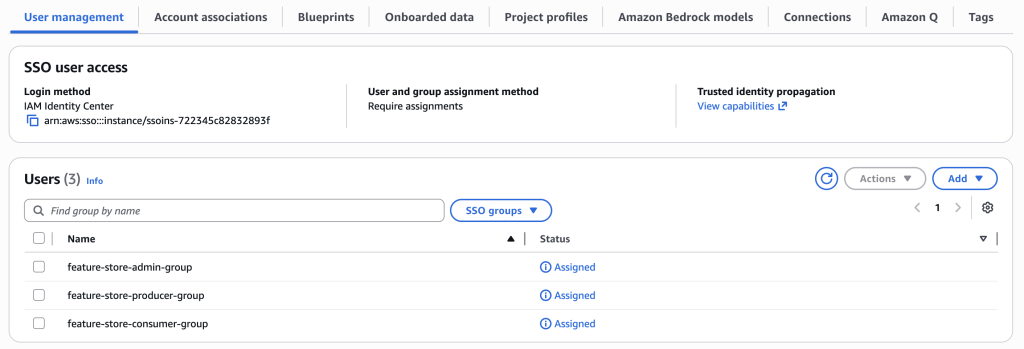
SageMaker ドメインに SSO グループを追加する
シングルサインオン (SSO) のための IAM Identity Center グループを SageMaker ドメインに割り当て、プロジェクト間でのユーザーアクセスとコラボレーションを有効化します。
- SageMaker Unified Studio コンソールに移動し、ナビゲーションペインからドメインを選択します。
- ユーザー管理へ移動します。
- ドメインアクセスを管理するために「ユーザーとグループの追加」を選択します。
- SSO グループを選択します。
- インフラストラクチャデプロイメント時に作成された SSO グループを選択します:
feature-store-admin-group (管理者用)
- feature-store-producer-group (データエンジニアリングチーム用)
- feature-store-consumer-group (データサイエンスチーム用)
- 割り当てを完了し、グループアクセスを有効化するために「追加」を選択します。
- ユーザー管理セクションには、SSO グループが「割り当て済み」として表示されます。
##
IAM Identity Center ユーザーの作成
SageMaker ドメインにアクセスするためのデータプロデューサー、コンシューマー、および管理者個別のユーザーを作成します。
データプロデューサーユーザーの作成:
- IAM Identity Center コンソールに移動し、ナビゲーションペインから「ユーザー」を選択します。
- 「ユーザーの追加」を選択し、ユーザーの詳細を入力します:
ユーザー名:dataproducer と入力します。
- メールアドレス:dataproducer@example.com などの有効なアドレスを入力します。
- 姓:Data と入力します。
- 名:Producer と入力します。
- ユーザーを feature-store-producer-group に割り当てます。
- アカウント有効化のための招待メールを送信します。
データコンシューマーおよび管理者ユーザーの作成:
データコンシューマーと管理者ユーザーを作成するには、以下の手順 2 の違いを除き同じ手順を使用します。
- データコンシューマーユーザーの作成:
ユーザー名:dataconsumer と入力します。
- メールアドレス:dataconsumer@example.com などの有効なアドレスを入力します。
- 姓:Data と入力します。
- 名:Consumer と入力します。
- ユーザーを feature-store-consumer-group に割り当てます。
- 管理者ユーザーの作成:
ユーザー名:dataadmin と入力します。
- メールアドレス:dataadmin@example.com などの有効なアドレスを入力します。
- 姓:Data と入力します。
- 名:Admin と入力します。
- ユーザーを feature-store-admin-group に割り当てます。
プロジェクトへのユーザーグループの追加
管理者ユーザーとして SageMaker Unified Studio の企業ドメインに UI コンソールからサインインし、適切なアクセス制御のために各ユーザーグループを対応するプロジェクトに割り当ててください。
ユーザーを Producer プロジェクトに割り当てる:
Na
原文を表示
Building and managing machine learning (ML) features at scale is one of the most critical and complex challenges in modern data science workflows. Organizations often struggle with fragmented feature pipelines, inconsistent data definitions, and redundant engineering efforts across teams. Without a centralized system for storing and reusing features, models risk being trained on outdated or mismatched data, leading to poor generalization, lower model accuracy and governance issues. Furthermore, enabling collaboration across data engineering, data science, and ML operations teams becomes difficult when each group maintains its own isolated datasets and transformations.
Amazon SageMaker addresses these challenges through SageMaker Unified Studio and SageMaker Catalog, which organizations can use to build, manage, and share assets securely across projects and accounts. A key capability within this ecosystem is the implementation of an offline feature store—a structured repository designed for managing historical feature data used in model training and validation. Offline feature stores are designed for scalability, lineage tracking, and reproducibility, so that data scientists can train models on accurate, time-aligned datasets that prevent data leakage and maintain consistency across experiments.
This blog post provides step-by-step guidance on implementing an offline feature store using SageMaker Catalog within a SageMaker Unified Studio domain. By adopting a publish-subscribe pattern, data producers can use this solution to publish curated, versioned feature tables—while data consumers can securely discover, subscribe to, and reuse them for model development. The approach integrates Amazon S3 Tables with Apache Iceberg for transactional consistency, AWS Lake Formation for fine-grained access control, and Amazon SageMaker Studio for visual and code-based data engineering.
Through this unified solution, teams can achieve consistent feature governance, accelerate ML experimentation, and reduce operational overhead. in this post, we show you how to design a collaborative, governed, and production-ready offline feature store to unlock enterprise-wide reuse of trusted ML features.
Solution overview
This solution demonstrates how to implement an offline feature store using a SageMaker Unified Studio domain integrated with SageMaker Catalog to enable scalable, governed, and collaborative feature management across ML teams. The architecture establishes a unified environment, shown in the following figure, that streamlines how administrators, data engineers, and data scientists create, publish, and consume high-quality, reusable feature tables.
At its core, the solution uses a SageMaker Unified Studio domain as the governance and collaboration layer for managing projects, users, and data assets under centralized control. S3 Tables in the Apache Iceberg format serve as the foundation for storing and versioning feature data. SageMaker Catalog, which allows unified governance for datasets, acts as the central registry for publishing, discovering, and subscribing to feature tables.
The following describes how various personas interact in the end-to-end workflow:
- Admin uses AWS CloudFormation templates and the AWS Management Console to set up and configure the environment, including provisioning the SageMaker Unified Studio domain and onboarding users and groups.
- Admin creates the SageMaker Unified Studio data project and onboards Amazon Simple Storage Service (Amazon S3) datasets—such as airline_delay.csv and airline_features (an S3 table)—to the project catalog, then designates the data engineer as the project owner.
- Data engineer opens the data project, uses the Visual extract, transform, load (ETL) tool or a data processing job to build the feature pipeline, and creates features in the airline_features table within the project catalog.
- Data engineer accesses the data explorer tool to enrich the airline_features table with metadata for improved discoverability and governance.
- After validation and approval, the data engineer publishes the airline_features table into SageMaker Catalog for organization-wide access.
- Data scientist opens the ML project, uses AI powered search to find the airlines_features table in the catalog, and identifies the published feature table as suitable for their model development.
- Data scientist submits a subscription request to consume the published feature table. If auto-approval isn’t configured, the publisher must review and approve the access request.
- After approval, the data scientist gains access to the feature table through the project catalog, both through the data explorer and directly from Jupyter notebooks for model training and experimentation.
This structured workflow provides consistent data governance, promotes collaboration, and eliminates redundant feature engineering efforts by enabling enterprise-wide reuse of trusted, versioned ML features.
Core components
The offline feature store solution architecture is composed of several integrated components. Each component plays a distinct role in enabling secure data governance, scalable feature engineering, and seamless collaboration across ML personas. The key components include:
SageMaker Unified Studio domain: The SageMaker Unified Studio domain serves as the central control plane for managing ML projects, users, and data assets. It provides a unified interface for collaboration between data engineers, data scientists, and administrators. This domain enables enforcement of fine-grained access controls, integrates with AWS IAM Identity Center for single sign-on, and supports approval workflows to help ensure secure sharing of ML assets across teams and accounts.
S3 Tables with Apache Iceberg format: S3 Tables enables scalable, serverless storage for feature data using the Apache Iceberg table format. Apache Iceberg Open Table Format (OTF) enables ACID transactions, schema evolution, and time-travel capabilities, which teams can then take advantage of to query historical versions of feature data with full reproducibility. S3 Tables seamlessly integrate with Spark, Glue, and SageMaker for consistent data access across analytical and ML workloads.
Feature engineering pipeline: The feature engineering pipeline automates the transformation of raw datasets into curated, high-quality features. Built on Apache Spark, it provides distributed data processing at scale, enabling complex transformations such as delay-rate computation, categorical encoding, and feature aggregation. The pipeline directly writes outputs to S3 tables, helping to ensure traceability and consistency between raw/processed data and engineered features.
SageMaker Catalog: SageMaker Catalog acts as the organization-wide repository for registering, publishing, and discovering ML assets such as datasets, feature tables, and models. It integrates with Lake Formation for fine-grained access control and IAM Identity Center for user management. The catalog supports metadata enrichment, versioning, and approval workflows, so teams can securely share and reuse trusted assets across projects.
Together, these components create a cohesive ecosystem that simplifies ML feature lifecycle management—from creation and publication to discovery and consumption—while maintaining enterprise-grade governance and data lineage tracking.
Administrator workflow
The administrator workflow defines the initial setup required to establish a secure and collaborative environment for implementing the offline feature store. Administrators provision the SageMaker Unified Studio domain, enable IAM Identity Center for user authentication, and configure S3 tables with Lake Formation for governed data access. They also create dedicated producer and consumer projects, deploy the necessary infrastructure through environment blueprints (based on CloudFormation), and assign users and groups with appropriate permissions. This setup helps ensure a consistent, well-governed foundation that data engineers and data scientists can use to build, publish, and consume ML features seamlessly within SageMaker Unified Studio.
Prerequisites
The following prerequisites must be completed to help ensure that the required AWS services and permissions are properly set up for seamless integration and governance.
- Enable IAM Identity Center
Navigate to IAM Identity Center in the console.
- Choose Enable if not already activated.
- Choose Enable with AWS Organizations or standalone and complete the setup wizard.
- Enable S3 Tables
Go to Amazon S3 in the console.
- Select the S3 Tables section and choose Enable S3 Tables integration.
- Lake Formation administrator
Verify that the console role is added to Lake Formation administrators for proper resource creation and permissions management.
Set up the environment
After completing the prerequisites, the next step is to set up the environment by creating and configuring the SageMaker Unified Studio domain, which serves as the central workspace for managing users, projects, and data assets within the offline feature store architecture.
Set up a SageMaker Unified Studio domain:
- Navigate to the SageMaker Unified Studio console and choose Domains in the navigation pane. Choose Create domain and then choose Quick Setup.
- Choose to create a new VPC or select an existing VPC for the domain network configuration.
- Expand Quick setup settings and enter a domain name (for example, Corporate).
- For Domain Execution role and Domain Service role, select Create and use a new service role.
- Select a VPC (VPCs tagged with SageMaker Unified Studio should be correctly configured) and choose at least three private subnets, each in a different Availability Zone.
- Choose Continue to proceed with domain creation.
- Create an IAM Identity Center user account by providing an email address, first name, and last name (you will receive an email to activate your IAM Identity Center account after creation).
- Choose Create domain to start the domain creation process. Domain creation typically takes 2–5 minutes to complete.
Create a SageMaker Unified Studio project:
- Go to the SageMaker Unified Studio domain URL and sign in using the IAM Identity Center credentials created during domain setup and accept the invitation email if received.
- Create projects:
Go to Select Project and choose Create project from the domain homepage to create a producer project and name it airlines_core_features. Add descriptions, configure settings, and assign users and permissions.
- For Project profile, select All Capabilities.
- Repeat the two preceding steps to create a consumer project names airlines_ml_models. Note :- Project creation typically takes 5–10 minutes to complete.
- Copy the project role ARN
Navigate to airlines_core_features project details.
- Navigate to the project and copy the project role Amazon Resource Name (ARN) (arn:aws:iam::ACCOUNT:role/datazone_usr_role_*)
- Repeat the preceding two steps for airlines_ml_models
Infrastructure deployment
Deploy the CloudFormation stack only after completing the previous steps, including domain creation, project creation, IAM Identity Center setup, and S3 Tables enablement. The stack requires the following input parameters:
- IAM Identity Center ID: Navigate to the IAM Identity console to retrieve the first part of the AWS access portal URL. It will look like https://d-1234da5678.awsapps.com/start
- SMUSProducerProjectRoleName: Navigate to the Unified Studio project portal, open your producer project, and retrieve the project role name. For example, arn:aws:iam:::role/datazone_usr_role_xxxx_yyyy
- SMUSConsumerProjectRoleName: Repeat the preceding step to retrieve consumer project role name.
After the stack deploys successfully, the following AWS resources will be created:
- S3 bucket: For raw and curated data storage, such as amzn-s3-demo-blog-smus-featurestore-{account-id}
- S3 table bucket: For Iceberg table storage, such as amzn-s3-demo-airlines-s3tables-bucket
- S3 table namespace: Organized feature table namespace, such as airlines
- S3 table: for feature storage, such as fg_airline_features
- Glue Database: for source data catalog, such as airline_raw_db
- IAM Identity Center groups: Producer and consumer groups, such as FeatureStore-Producers, FeatureStore-Consumers
- Lake Formation permissions: Fine-grained access control, such as database and table permissions
- IAM roles and policies: For service integrations, such as – SageMaker execution roles.
###
Add SSO groups to the SageMaker domain
Assign IAM Identity Center groups for single sign on (SSO) to the SageMaker domain to enable user access and collaboration across projects.
- Navigate to the SageMaker Unified Studio console and choose domain from the navigation pane.
- Goto User management.
- Choose Add users and groups to manage domain access.
- Select SSO Groups.
- Choose the SSO groups that were created during infrastructure deployment:
feature-store-admin-group (for admin)
- feature-store-producer-group (for data engineering teams)
- feature-store-consumer-group (for data science teams)
- Choose Add to complete the assignment and enable group access
- The User Management section will show the SSO groups as Assigned.
###
Create IAM Identity Center users
Create individual users for data producers, consumers, and administrators to access the SageMaker domain.
Create the data producer user:
- Navigate to the IAM Identity Center console and choose Users from the navigation pane.
- Choose Add user enter the user details:
Username: Enter dataproducer.
- Email: Enter a valid address, such as dataproducer@example.com.
- First name: Enter Data.
- Last name: Enter Producer.
- Assign the user to feature-store-producer-group.
- Send an invitation email for account activation.
Create the data consumer and admin users:
Use the same steps to create the data consumer and admin users, with the following differences for step 2:
- Create the data consumer user:
Username: Enter dataconsumer.
- Email: Enter a valid address, such as dataconsumer@example.com.
- First name: Enter Data.
- Last name: Enter Consumer.
- Assign the user to feature-store-consumer-group.
- Create the admin user:
Username: Enter dataadmin.
- Email: Enter a valid address, such as dataadmin@example.com.
- First name: Enter Data.
- Last name: Enter Admin.
- Assign the user to feature-store-admin-group.
Add user groups to projects
Sign in to the SageMaker Unified Studio corporate domain as the admin user from UI Console and assign the user groups to their corresponding projects for proper access control.
Assign users to the Producer project:
Na
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み