知性を損なわずに特化型AIを構築:Nova Forgeデータ混合の実践
AWSは「Nova Forge」サービスを通じて、専門知識を必要とするドメイン特化タスクにおけるモデル性能向上と、汎用能力の維持という両立を可能にするデータ混合手法の実証結果を発表した。
キーポイント
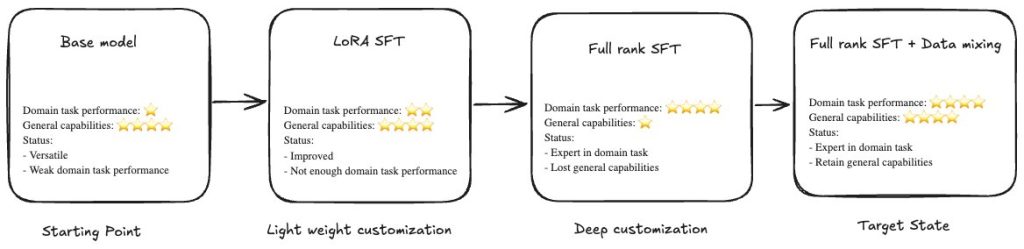
Full-rank SFTとCatastrophic Forgettingの課題
全パラメータを更新するFull-rank SFTはドメイン知識の習得に優れるが、学習に伴って汎用的な推論能力や指示従順性が失われる「壊滅的忘却」が発生し、実用性を損なう課題があった。
Nova Forgeによるデータ混合アプローチ
Amazon Novaの早期チェックポイントから開始し、独自データとAmazonがキュレーションしたトレーニングデータを混合することで、専門領域のタスク性能を向上させつつ汎用能力を維持する手法を提供している。
VOC分類タスクにおける実証結果
16,000件以上の顧客コメントを用いた複雑な分類タスクにおいて、F1スコアが17%向上し、かつMMLUスコアや指示従順性がベースラインに近い状態を維持することを検証した。
影響分析・編集コメントを表示
影響分析
本記事は、エンタープライズレベルでのLLM活用において長年懸念されてきた「専門化による汎用性の低下」というジレンマに対する具体的な解決策を示すものであり、業界に大きな影響を与える。AWSが提供するNova Forgeのようなマネージドサービスにより、中小規模の組織でも高度なファインチューニングを低リスクで実施できる環境が整いつつあり、AI実装のハードル引き下げと普及加速に寄与すると予想される。
編集コメント
専門領域モデルの構築における「壊滅的忘却」は実務上の重大な課題であり、それを解決するデータ混合戦略の具体数値開示は信頼性が高い。AWSが自社のNovaモデル基盤を活用したこのアプローチの成功事例は、競合他社に対する差別化要因となり得る。
大規模言語モデル(LLM)は一般的なタスクでは高い性能を発揮しますが、独自データや内部プロセス、業界固有の用語を理解する必要がある専門的な業務においては苦戦を強いられます。教師あり微調整(SFT: Supervised Fine-Tuning)は、これらの組織文脈に合わせて LLM を適応させる手法です。SFT は 2 つの異なる方法論を通じて実装できます。1 つ目はパラメータ効率型微調整(PEFT: Parameter-Efficient Fine-Tuning)で、モデルのパラメータの一部のみを更新するため、学習が高速化され計算コストが低減される一方で、合理的な性能向上を維持します。2 つ目はフルランク SFT で、パラメータの一部ではなくすべてのパラメータを更新し、PEFT よりも多くのドメイン知識を取り込みます。
フルランク SFT はしばしば課題に直面します:壊滅的忘却 です。モデルがドメイン固有のパターンを学習するにつれ、指示の遵守、推論能力、広範な知識といった一般的な能力を失ってしまいます。組織は専門性と汎用知能の間で選択を迫られ、これによりエンタープライズユースケース全体におけるモデルの有用性が制限されてしまいます。
Amazon Nova Forge はこの問題に対処します。Nova Forge は、Nova を活用して独自の最先端モデルを構築できる新しいサービスです。Nova Forge の顧客は、初期のモデルチェックポイントから開発を開始し、独自データを Amazon Nova がキュレーションしたトレーニングデータとブレンドし、カスタムモデルを AWS 上で安全にホストすることができます。
本投稿では、AWS China Applied Science チームが、難易度の高い顧客の声(VOC)分類タスクを用いて Nova Forge を包括的に評価した結果を共有します。この評価はオープンソースモデルとのベンチマークに基づいています。複雑な 4 レベルのラベル階層構造(1,420 のリーフカテゴリを含む)にわたる 16,000 件以上の顧客コメントサンプルを対象に、Nova Forge のデータミキシングアプローチがもたらす 2 つの利点を示します。
- ドメイン内タスクのパフォーマンス向上:F1 スコアで 17% の改善を達成
- 汎用能力の維持:ファインチューニング後も MMLU(Massive Multitask Language Understanding)スコアと指示従順性をほぼベースラインレベルで維持
チャレンジ:実世界の顧客フィードバック分類
大規模な EC 企業の典型的なシナリオを想定してください。カスタマーエクスペリエンスチームは、製品品質、配送体験、支払い問題、ウェブサイトの使いやすさ、カスタマーサービスとのやり取りにわたる詳細なフィードバックを含む、毎日数千件の顧客コメントを受け取ります。効率的に運営するためには、各コメントを高精度で実行可能なカテゴリに自動的に分類できる大規模言語モデル(LLM)が必要です。各分類は、物流、財務、開発、またはカスタマーサービスなど、適切なチームに問題をルーティングし、適切なワークフローをトリガーするために十分なほど具体的である必要があります。これにはドメイン特化が求められます。
しかし、この LLM は孤立して動作するわけではありません。組織全体で、各チームはモデルに対して以下のような要求を持っています:
- 一般コミュニケーションスキルを要する顧客向け応答の生成
- 数学的・論理的推論を必要とするデータ分析の実行
- 特定のフォーマットガイドラインに従ったドキュメント草案の作成
これには、広範な汎用能力—指示従順性、推論力、多分野にわたる知識、そして会話流暢さ—が必要です。
評価手法
テスト概要
Nova Forge がドメイン特化性と汎用能力の両方を提供できるかを検証するため、私たちは二つの次元にわたるパフォーマンスを測定するデュアル評価フレームワーク(dual-evaluation framework)を設計しました。
ドメイン固有のパフォーマンスについては、実際の顧客レビューから派生したリアルワールド・ボイス・オブ・カスタマー(Voice of Customer: VOC)データセットを使用します。このデータセットには、14,511 件のトレーニングサンプルと 861 件のテストサンプルが含まれており、生産規模のエンタープライズデータを反映しています。本データセットは 4 レベルの階層構造を採用しており、レベル 4 がリーフカテゴリ(最終分類対象)を表します。各カテゴリにはその範囲を説明する記述が含まれています。例示されるカテゴリ:
レベル 1
レベル 2
レベル 3
レベル 4 (リーフカテゴリ)
インストール – アプリ設定
初期セットアップガイダンス
セットアッププロセス
簡単なセットアップ体験: インストールプロセスの特徴と複雑度レベル
使用法 – ハードウェア体験
ナイトビジョン性能
低照度画像品質
ナイトビジョンの明瞭さ: ナイトビジョンモードは、低照度または暗闇の条件下で画像を生成します
使用法 – ハードウェア体験
パン・チルト・ズーム機能 (Pan-tilt-zoom)
回転能力
360 度回転: カメラは完全な 360 度の回転が可能であり、完全なパノラマカバレッジを提供します
アフターサービスポリシーとコスト
返品および交換ポリシー
返品プロセスの実行
製品返品の完了: 顧客が機能上の問題により製品の返品を開始し、完了させました
このデータセットは、現実世界の顧客フィードバック環境に典型的な極端なクラス不均衡を示しています。以下の画像はクラスの分布を表示しています:
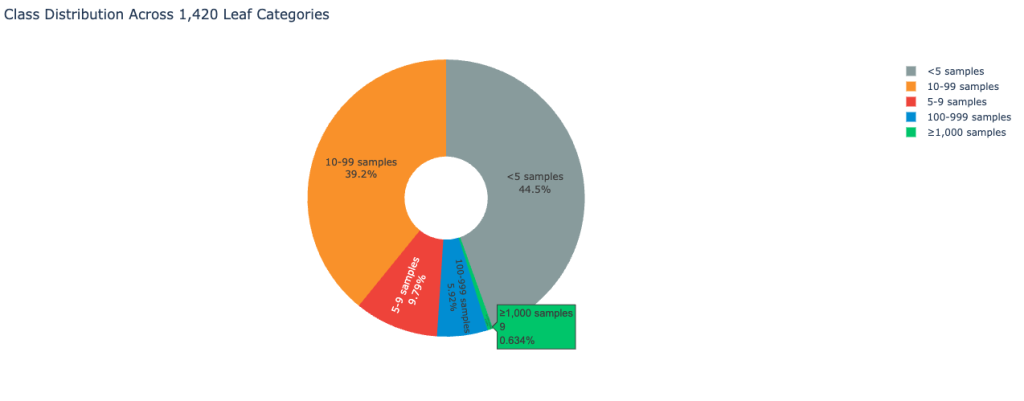
その結果、このデータセットは分類精度に大きな課題を課しています。
汎用能力の評価には、公開されている MMLU(大規模多機能言語理解)ベンチマークのテストセット分割版(全サブセット)を使用します。https://huggingface.co/datasets/cais/mmlu/viewer/all このテストは、人文科学、社会科学、自然科学など、一部の人にとって学習が重要な分野にわたっています。本記事では、MMLU は汎用能力の保持を代理する指標として機能します。これを用いて、教師あり微調整(Supervised Fine-Tuning: SFT)がドメイン性能を向上させる一方で、基盤モデルの振る舞いを劣化させていないかを測定し、また Nova データ混合が壊滅的忘却(Catastrophic Forgetting)を緩和する効果があるかを評価します。
Item | Description
---|---
Total samples | 15,372 件の顧客レビュー
Label hierarchy | 4 レベル分類、合計 1,420 カテゴリ
Training set | 14,511 件
Test set | 861 件
MMLU Benchmark all (test split) | 14,000 件
ドメイン内タスク評価:顧客の声(Voice of Customer)分類
Nova Forge が実際の企業シナリオでどのように機能するかを理解するため、まず教師あり微調整前後における VOC 分類タスクのモデル精度を評価します。このアプローチにより、ドメイン適応による向上度を定量化しつつ、その後の堅牢性分析のためのベースラインを設定できます。
ベースモデルの評価
まず、タスク固有のファインチューニングを一切行わずに VOC クラス分類タスクにおけるアウト・オブ・ザ・ボックス(初期状態)のパフォーマンスを評価するため、「ベースモデルの評価」から始めます。この設定により、厳格な出力形式制約下で極めて細粒度な分類を処理する各モデルの固有能力が確認されます。VOC 分類タスクには以下のプロンプトが使用されます:
ロール定義
あなたは厳格な顧客体験分類システムです。あなたの唯一の責任は、ユーザーフィードバックを既存のラベルタクソノミー(レベル 1 からレベル 4:L1–L4)にマッピングすることです。事前に定義されたタクソノミー構造を厳守し、新しいラベルを作成・変更・推論してはなりません。
運用原則
1. 厳格なタクソノミー整合性** すべての分類は、提供されたラベルタクソノミーに完全に根ざしており、その階層構造を厳密に遵守する必要があります。
2. MECE 原則を用いたフィードバック分解
ユーザーフィードバックの 1 つには、1 つまたは複数の課題が含まれている可能性があります。記述されているすべての課題を注意深く分析し、MECE(Mutually Exclusive, Collectively Exhaustive:相互排他的かつ全体網羅的)の原則に従って、重複しないセグメントにフィードバックを分解する必要があります。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
- 意味的特異点: 各セグメントは、1 つの問題、機能、サービス、または接点(例えば、価格、パフォーマンス、UI など)のみを記述するものとする。
- 独立性: セグメント間には意味的な重複があってはならない。
- 完全な網羅性: 元のフィードバックに含まれるすべての情報は、省略なく保持されなければならない。
3. タクソノミーの拡張禁止
ラベルやタクソノミレベルを新たに発明したり、推論したり、変更したりしてはならない。
ラベル・タクソノミー
以下のセクションでラベル・タクソノミーを提供します:{tag category}。このタクソノミーを使用して、元の VOC(Voice of Customer)フィードバックに対して L1~L4 の分類を実行してください。タクソノミーの拡張は許可されません。
タスク指示
ユーザーからのフィードバックの一部が提供されます:{user comment}。ユーザーは異なる地域から来ており、異なる言語を使用している可能性があります。ラベルを割り当てる前に、ユーザーの言語と意図を正確に理解する必要があります。
期待されるラベリング形式については、提供された例を参照してください。
出力形式
分類結果は JSON フォーマットのみで返してください。各フィードバックセグメントについて、元のテキストに対応する L1~L4 のラベルおよび感情(センチメント)を出力します。コンテンツの生成や書き換えは行わないこと。
[
{
"content": "",
"L1": "",
"L2": "",
"L3": "",
"L4": "",
"emotion": ""
}
]ベースモデルの評価において、以下のモデルを選択しました:
- Amazon Nova 2 Lite: Amazon Bedrock で評価済み
- Qwen3-30B-A3B: vLLM を使用して Amazon Elastic Compute Cloud (Amazon EC2) にデプロイされたオープンソースモデル
モデル
精度
再現率
F1 スコア
Nova 2 Lite
0.4596
0.3627
0.387
Qwen3-30B-A3B
0.4567
0.3864
0.394
The F1-scores reveal that Nova 2 Lite and Qwen3-30B-A3B demonstrate comparable performance** on this domain-specific task, with both models achieving F1-scores near 0.39. These results also highlight the inherent difficulty of the task: even strong foundation models struggle with fine-grained label classification when no domain-specific data is provided.
Supervised fine-tuning
We then apply full-parameter supervised fine-tuning (SFT) using customer VOC data. All models are fine-tuned using the same dataset and comparable training configurations for a fair comparison.
Training infrastructure:
- Nova 2 Lite: Fine-tuned on Amazon SageMaker HyperPod cluster using four p5.48xlarge instances (as specified in the Nova customization SageMaker hyperpod topic in the Amazon SageMaker AI Developer Guide)
- Qwen3-30B-A3B: Fine-tuned on Amazon EC2 using p6-b200.48xlarge instances
In domain task performance comparison
Model
Training Data
Precision
Recall
F1-Score
Nova 2 Lite
None (baseline)
0.4596
0.3627
0.387
Nova 2 Lite
Customer data only
0.6048
0.5266
0.5537
Qwen3-30B
Customer data only
0.5933
0.5333
0.5552
カスタムデータのみでファインチューニングを施した後、Nova 2 Lite は大幅な性能向上を達成し、F1 スコアは 0.387 から 0.5537 に上昇しました。これは絶対値で 17 ポイントの改善であり、このタスクにおいて Nova モデルを最上位クラスに位置づけ、ファインチューニング済みの Qwen3-30B オープンソースモデルと同等の性能を実現しています。これらの結果は、複雑なエンタープライズ分類ワークロードに対するNova のフルパラメータ SFT(Supervised Fine-Tuning:教師あり微調整)の有効性を裏付けています。
汎用能力の評価:MMLU ベンチマーク
VOC 分類用にファインチューニングされたモデルは、単一のタスクに限定されず、より広範なエンタープライズワークフローに統合されて展開されるのが一般的です。汎用的な能力を維持することは重要です。業界標準のベンチマークである MMLU は、汎用能力の評価や、ファインチューニング済みモデルにおける壊滅的な忘却(Catastrophic Forgetting)の検出に対して効果的なメカニズムを提供します。
ファインチューニング済みの Nova モデルについては、Amazon SageMaker HyperPod が すぐに使える評価レシピ を提供しており、最小限の設定で MMLU 評価を簡素化できます。
Model | Training data | VOC F1-Score | MMLU accuracy
---|---|---|---
Nova 2 Lite | なし(ベースライン) | 0.38 | 0.75
Nova 2 Lite | カスタムデータのみ | 0.55 | 0.47
Nova 2 Lite | カスタムデータ 75% + Nova データ 25% | 0.5 | 0.74
原文を表示
Large language models (LLMs) perform well on general tasks but struggle with specialized work that requires understanding proprietary data, internal processes, and industry-specific terminology. Supervised fine-tuning (SFT) adapts LLMs to these organizational contexts. SFT can be implemented through two distinct methodologies: Parameter-Efficient Fine-Tuning (PEFT), which updates only a subset of model parameters, offering faster training and lower computational costs while maintaining reasonable performance improvements; Full-rank SFT, which updates all model parameters rather than a subset and incorporates more domain knowledge than PEFT.
Full-rank SFT often faces a challenge: catastrophic forgetting. As models learn domain-specific patterns, they lose general capabilities including instruction-following, reasoning, and broad knowledge. Organizations must choose between domain expertise and general intelligence, which limits model utility across enterprise use cases.
Amazon Nova Forge addresses the problem. Nova Forge is a new service that you can use to build your own frontier models using Nova. Nova Forge customers can start their development from early model checkpoints, blend proprietary data with Amazon Nova-curated training data, and host their custom models securely on AWS.
In this post, we share results from the AWS China Applied Science team’s comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models. Working with over 16,000 customer comment samples across a complex four-level label hierarchy containing 1,420 leaf categories, we demonstrate how Nova Forge’s data mixing approach provides two advantages:
- In-domain task performance gains: achieving 17% F1 score improvements
- Preserved general capabilities: maintaining near-baseline MMLU (Massive Multitask Language Understanding) scores and instruction-following abilities post-finetuning
The challenge: real-world customer feedback classification
Consider a typical scenario at a large ecommerce company. The customer experience team receives thousands of customer comments daily with detailed feedback spanning product quality, delivery experiences, payment issues, website usability, and customer service interactions. To operate efficiently, they need an LLM that can automatically classify each comment into actionable categories with high precision. Each classification must be specific enough to route the issue to the right team: logistics, finance, development, or customer service, and trigger the appropriate workflow. This requires domain specialization.
However, this same LLM doesn’t operate in isolation. Across your organization, teams need the model to:
- Generate customer-facing responses that require general communication skills
- Perform data analysis requiring mathematical and logical reasoning
- Draft documentation following specific formatting guidelines
This requires broad general capabilities—instruction-following, reasoning, knowledge across domains, and conversational fluency.
Evaluation methodology
Test overview
To test whether Nova Forge can deliver both domain specialization and general capabilities, we designed a dual-evaluation framework measuring performance across two dimensions.
For domain-specific performance, we use a real-world Voice of Customer (VOC) dataset derived from actual customer reviews. The dataset contains 14,511 training samples and 861 test samples, reflecting production-scale enterprise data. The dataset employs a four-level taxonomy where Level 4 represents the leaf categories (final classification targets). Each category includes a descriptive explanation of its scope. Example categories:
Level 1
Level 2
Level 3
Level 4 (leaf category)
Installation – app configuration
Initial setup guidance
Setup process
Easy setup experience: Installation process characteristics and complexity level
Usage – hardware experience
Night vision performance
Low-light Image quality
Night vision clarity: Night vision mode produces images in low-light or dark conditions
Usage – hardware experience
Pan-tilt-zoom functionality
Rotation capability
360-degree rotation: The camera can rotate a full 360 degrees, providing complete panoramic coverage
After-sales policy and cost
Return and exchange policy
Return process execution
Product return completed: Customer initiated and completed product return due to functionality issues
The dataset exhibits extreme class imbalance typical of real-world customer feedback environments. The following image displays the class distribution:
As a result, the dataset places a significant challenge on classification accuracy.
For evaluating general-purpose capabilities, we use the public test set split of the MMLU (Massive Multitask Language Understanding) benchmark (all subsets). The test spans subjects in the humanities, social sciences, hard sciences, and other areas that are important for some people to learn. In this post, MMLU serves as a proxy for general capability retention. We use it to measure whether supervised fine-tuning improves domain performance at the cost of degrading foundational model behaviors, and to assess the effectiveness of Nova data mixing in mitigating catastrophic forgetting.
Item
Description
Total samples
15,372 customer reviews
Label hierarchy
4-level classification, 1,420 categories in total
Training set
14,511 samples
Test set
861 samples
MMLU Benchmark all (test split)
14,000 samples
In-domain task evaluation: voice of customer classification
To understand how Nova Forge performs in real enterprise scenarios, we first evaluate model accuracy on the VOC classification task before and after supervised fine-tuning. With this approach, we can quantify domain adaptation gains while establishing a baseline for subsequent robustness analysis.
Base model evaluation
We begin with a base model evaluation to assess out-of-the-box performance on the VOC classification task without any task-specific fine-tuning. This setup establishes each model’s inherent capability to handle highly granular classification under strict output format constraints. The following prompt is used for the VOC classification task:
# Role Definition
You are a rigorous customer experience classification system. Your sole responsibility is to map user feedback to the existing label taxonomy at Level 1 through Level 4 (L1–L4). You must strictly follow the predefined taxonomy structure and must not create, modify, or infer any new labels.
## Operating Principles
### 1. Strict taxonomy alignment** All classifications must be fully grounded in the provided label taxonomy and strictly adhere to its hierarchical structure.
### 2. Feedback decomposition using MECE principles
A single piece of user feedback may contain one or multiple issues. You must carefully analyze all issues described and decompose the feedback into multiple non-overlapping segments, following the MECE (Mutually Exclusive, Collectively Exhaustive) principle:
- **Semantic singularity**: Each segment describes only one issue, function, service, or touchpoint (for example, pricing, performance, or UI).
- **Independence**: Segments must not overlap in meaning.
- **Complete coverage**: All information in the original feedback must be preserved without omission.
### 3. No taxonomy expansion
You must not invent, infer, or modify any labels or taxonomy levels.
## Label Taxonomy
The following section provides the label taxonomy: {tag category}. Use this taxonomy to perform L1–L4 classification for the original VOC feedback. No taxonomy expansion is allowed.
## Task Instructions
You will be given a piece of user feedback: {user comment}. Users may come from different regions and use different languages. You must accurately understand the user's language and intent before assigning labels.
Refer to the provided examples for the expected labeling format.
## Output Format
Return the classification results in JSON format only. For each feedback segment, output the original text along with the corresponding L1–L4 labels and sentiment. Do not generate or rewrite content.
`json</code><br> <code>[</code><br> <code>{</code><br> <code>"content": "<comment_text>",</code><br> <code>"L1": "<L1>",</code><br> <code>"L2": "<L2>",</code><br> <code>"L3": "<L3>",</code><br> <code>"L4": "<L4>",</code><br> <code>"emotion": "<emotion>"</code><br> <code>}</code><br> <code>]</code><br> <code>`
For base model evaluation, we selected:
- Amazon Nova 2 Lite: Evaluated on Amazon Bedrock
- Qwen3-30B-A3B: Open source model deployed on Amazon Elastic Compute Cloud (Amazon EC2) with vLLM
Model
Precision
Recall
F1-Score
Nova 2 Lite
0.4596
0.3627
0.387
Qwen3-30B-A3B
0.4567
0.3864
0.394
The F1-scores reveal that Nova 2 Lite and Qwen3-30B-A3B demonstrate comparable performance** on this domain-specific task, with both models achieving F1-scores near 0.39. These results also highlight the inherent difficulty of the task: even strong foundation models struggle with fine-grained label classification when no domain-specific data is provided.
Supervised fine-tuning
We then apply full-parameter supervised fine-tuning (SFT) using customer VOC data. All models are fine-tuned using the same dataset and comparable training configurations for a fair comparison.
Training infrastructure:
- Nova 2 Lite: Fine-tuned on Amazon SageMaker HyperPod cluster using four p5.48xlarge instances (as specified in the Nova customization SageMaker hyperpod topic in the Amazon SageMaker AI Developer Guide)
- Qwen3-30B-A3B: Fine-tuned on Amazon EC2 using p6-b200.48xlarge instances
In domain task performance comparison
Model
Training Data
Precision
Recall
F1-Score
Nova 2 Lite
None (baseline)
0.4596
0.3627
0.387
Nova 2 Lite
Customer data only
0.6048
0.5266
0.5537
Qwen3-30B
Customer data only
0.5933
0.5333
0.5552
After fine-tuning on customer data alone, Nova 2 Lite achieves a substantial performance improvement, with F1 increasing from 0.387 to 0.5537—an absolute gain of 17 points. This result places the Nova model in the top tier for this task and makes its performance comparable to that of the fine-tuned Qwen3-30B open-source model. These results confirm the effectiveness of Nova full-parameter SFT for complex enterprise classification workloads.
General capabilities evaluation: MMLU benchmark
Models fine-tuned for VOC classification are often deployed beyond a single task and integrated into broader enterprise workflows. Preserving general-purpose capabilities is important. Industry-standard benchmarks such as MMLU provide an effective mechanism for evaluating general-purpose capabilities and detecting catastrophic forgetting in fine-tuned models.
For the fine-tuned Nova model, Amazon SageMaker HyperPod offers out-of-the-box evaluation recipesthat streamline MMLU evaluation with minimal configuration.
Model
Training data
VOC F1-Score
MMLU accuracy
Nova 2 Lite
None (baseline)
0.38
0.75
Nova 2 Lite
Customer data only
0.55
0.47
Nova 2 Lite
75% customer + 25% Nova data
0.5
0.74
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み