[AINews] メタハーネスの夏が到来
OpenAI が独自 AI チップ「Jalapeño」を発表し、Databricks の Matei Zaharia 氏がメタハーネスアーキテクチャ「Omnigent」を推進するなど、インフラ層の垂直統合と標準化が加速している。
キーポイント
OpenAI の独自チップ「Jalapeño」発表
Broadcom と共同開発した LLM 推論用カスタムチップを発表し、チャットや API トラフィックの計算コスト最適化とサプライチェーン依存からの脱却を目指す。
メタハーネスアーキテクチャの台頭
Databricks の Matei Zaharia 氏が主導するオープンソース規格「Omnigent」が、多様なエージェントを統合・管理するための次世代標準として注目されている。
インフラ競争と買収動向
Qualcomm が Modular を買収し、Mojo のオープンソース化が進むなど、NVIDIA/CUDA 以外に依存しない垂直統合型推論スタックへの競争が激化している。
大規模モデルの学習効率向上
NVIDIA が NeMo AutoModel を通じて MoE モデルのトレーニングスループットを 3.4〜3.7 倍に引き上げる技術を発表し、インフラ側の競争も活発化している。
インフラと推論の性能向上
NVIDIA の NeMo AutoModel は MoE モデルのトレーニングスループットを最大 3.7 倍向上させ、Modal や SkyPilot は独自クラスターでの推論やローカル最適化において既存プロバイダーや従来の手法を上回る性能を実現している。
エージェントの UX シフトとセキュリティ課題
Anthropic の Slack 埋め込み型エージェントはツールから「同僚」へと進化したが、ID 管理、権限スケーラビリティ、ベンダーロックインによるコスト透明性の欠如といった新たなセキュリティリスクが指摘されている。
オープンソースと自己ホストの台頭
Hugging Face の Moon Bot に代表されるように、多くのチームは組織知能をベンダーに委ねるのではなく、記憶層やハッチネスを自社で管理・所有するオープンな DIY 型アプローチを強く求めている。
影響分析・編集コメントを表示
影響分析
このニュースは、AI インフラ業界がハードウェアとソフトウェアの境界を越えた「垂直統合」へと移行する転換点であることを示しています。OpenAI の独自チップ発表は、GPU サプライチェーンへの依存脱却という戦略的決断であり、Qualcomm の買収動向も加わることで、NVIDIA 一極体制に対する強力な対抗軸が形成されつつあります。また、Omnigent に代表されるメタハーネス規格の台頭は、今後 AI エージェント開発の標準化を加速させ、開発環境の統一とセキュリティ強化に寄与すると予想されます。
編集コメント
AI ハードウェアとアーキテクチャ標準の両面で、業界の再編が急速に進んでいることが読み取れます。特に OpenAI の独自チップ開発は、単なる技術競争を超え、ビジネスモデルの根本的な変革を迫る重要な転換点と言えます。
Meta-Harness の短い歴史はあまり文書化されていませんが、おおよそ以下の通りです。最初は Conductor と Zed の ACP があり、その後 OpenInspect、Cloudflare の Flue、そして Vercel の Eve や HarnessAgent、Heypi が現れました。
今日のパッドキャストゲストである Matei Zaharia 氏が、メタ・ハーネスに大きな賭けをしていることに注意を払わないわけにはいきません。彼は非常に成功した企業(LLM 以前時代の企業ですが)Databricks の CTO です。その賭けとは Omnigent で、これはあらゆるコーディングや知識作業を行うエージェントを、標準化され、安全で、信頼性があり、スケーラブルなシステムに取り込むためのオープンソースでプラグイン可能なアーキテクチャです:
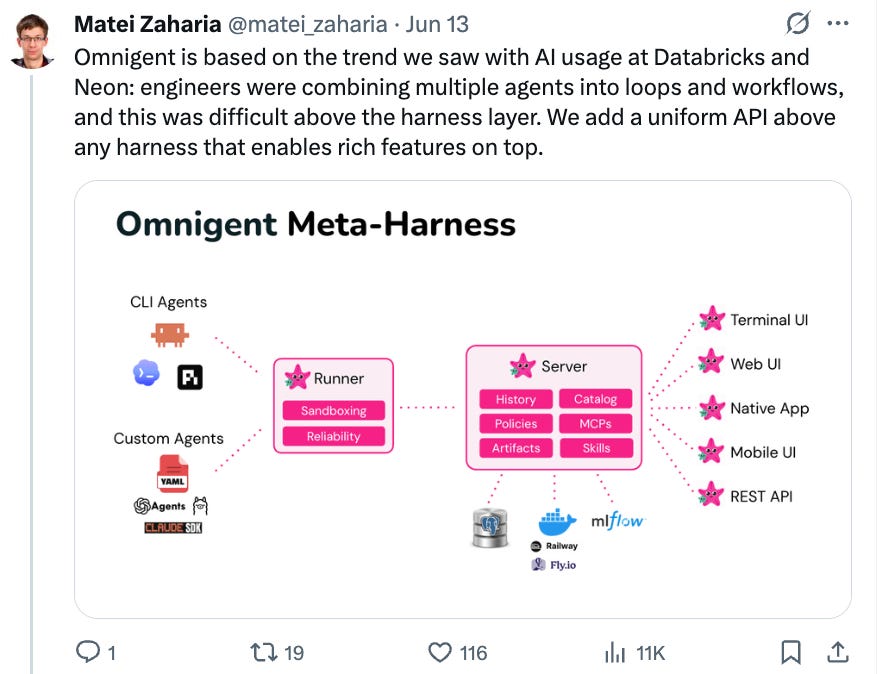
omnigent
Omnigent が MCP の成功を必然たらしめたのと同じような要素を持っているかどうかは不明ですが、アーキテクチャレベルでは、このようなオープンソースのアーキテクチャが勝つ可能性が高いことは明らかです。少なくとも、現在 1000 の AI ネイティブ企業で独立して再発見されているという事実からしてもそうです。
2026 年 6 月 23 日〜24 日の AI ニュース。私たちは 12 のサブレッドと 544 のツイートをチェックし、Discord はさらに確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお伝えしますが、AINews は現在 Latent Space の一部となっています。メールの頻度を選択的にオン/オフにすることができます!
AI Twitter リキャップ
OpenAI の Jalapeño チップとフルスタック AI インフラへの競争
OpenAI がハードウェア分野にさらに踏み込む:OpenAI は Broadcom と共同で開発した初の独自 AI チップ「Jalapeño」を発表しました。これは LLM 推論(LLM inference)向けに設計され、ChatGPT、Codex、API トラフィック、および将来のエージェント製品に使用される予定です。戦略的なメッセージは明白です:チップ、カーネル、メモリ、ネットワーク、スケジューリング、デプロイメントなど、スタックのより多くの部分を自社で所有することで、計算コストと製品の挙動が汎用 GPU の供給状況に過度に依存しないようにする方針です。@gdb は高い電力効率(performance-per-watt)を強調し、@kimmonismus は報告されている 9 ヶ月間の設計からテープアウトまでのサイクルについて言及しました。これは高性能 ASIC としては異例の速さであり、OpenAI 自身のモデルによって加速されたと報じられています。
技術的な読み解きとエコシステムへの影響:コミュニティによる逆エンジニアリングの結果、Jalapeño は TPU(Tensor Processing Unit)のような特徴を持つことが示唆されています。@scaling01 は、ほぼリテールサイズ(reticle die)のダイで、約 216GB の HBM3E メモリを備え、帯域幅は約 7.1〜7.4 TB/s、FP4 演算性能は約 10 PFLOPS と推定しています。これらの数値が公式に確認されたものではないとしても、重要なシグナルは、最先端研究所においてハイパースケラー型の推論用シリコンがもはや必須条件(table stakes)となったことです。同日には、コンパイラ/ランタイムの状況も変化しました。Chris Lattner は Qualcomm が Modular を買収すると発表し、Modular 側は Mojo のオープンソース化計画が予定通り進行中であると述べています。この組み合わせは、NVIDIA/CUDA に依存しない、垂直統合型の推論スタックを巡る競争がより激化することを示唆しています。
サービス提供とスループットは依然として重要な課題です:インフラ面では、NVIDIA は NeMo AutoModel が Expert Parallelism、DeepEP、および TransformerEngine カーネルを通じて MoE モデルのトレーニング スループットを 3.4~3.7 倍向上させたと発表しました。SkyPilot は所有クラスタ間での統一推論を実現する Endpoints をリリースし、Modal はローカル環境でのオープンソース推論設定が、プロプライエタリなプロバイダーよりもレイテンシ面で優れていると主張しています。ローカル最適化については、@jon_durbin がカスタム DFLASH ドラフト/スペキュレーター モデルのトレーニングにより、実世界でのデコード性能が 30~50% 向上したと報告しました。
エージェント UX は「ツール」から「同僚」へシフトし、新たなセキュリティとコストの課題を提起
Anthropic の Slack ネイティブ エージェントモデルが主要な UI の話題です:複数のツイートで、Claude が Slack やチームワークフローに組み込まれたことの重要性が指摘されました。@karpathy は、これが単なる機能や Slack ボットではなく組織レベルのハッチネスであるため、人々がその意義を過小評価していると主張しました。@gallabytes は、Claude Code から Tags への体験的飛躍を、「ペアリングパートナー」から「チーム管理」へと例えました。@dabit3 はさらにこの考えを進め、将来的にはエージェントを明示的にタグ付けする必要さえなくなるかもしれないと述べています。
難しいのは、アイデンティティ、権限、そしてベンダーロックインの問題です。Anthropic はこのスレッドでエージェントのアイデンティティモデルを詳細に説明しました。Claude には独自の認証情報が付与され、そのアイデンティティの下でアクションが監査可能となり、アクセスは中央集権的に取り消すことができます。この設計には称賛と懸念の両方が寄せられました。@KentonVarda は、エージェントごとの明示的な権限管理はスケーラビリティに欠けると主張し、細粒度でタスク範囲に限定された能力ベースセキュリティを提唱しました。@random_walker は Claude Tag を「すべてを記憶し、思考数に応じて請求する同僚」と表現し、一度組織のワークフローに深く組み込まれたエージェントが、暗黙知のロックイン、プロンプト注入リスク、そして予算の不透明さを招く可能性を警告しました。@JubbaOnJeans もまた、書き込みアクションにおける帰属の曖昧さと、Slack のような明確な境界線を超えた将来のアクセス制御の複雑さに言及しています。
オープンで DIY な対応は即座に現れました。Hugging Face はブログ投稿で、社内 Slack ベースのコーディングエージェント「Moon Bot」を紹介し、セルフホスティング、カスタムツール、監査可能なセッション、そしてゼロロックインを強調しました。@calebfahlgren による続報では、GitHub、Athena、分析ツール、MongoDB、Elasticsearch、HF Buckets にわたる本番環境での統合がリストアップされています。より大きな傾向として、チームはますますエージェントネイティブな UX を望んでいますが、多くの組織は、組織の知能をベンダーに委託するよりも、ハッチとメモリレイヤー自体を所有したいと考えています。
Qwen-AgentWorld、OpenThoughts-Agent、そして次世代のエージェントスケーリング軸としてのメモリ
Qwen-AgentWorld はエージェント向けの「言語世界モデル」を推進します:アリババの Qwen は、MCP、検索、ターミナル、SWE、Web、OS、Android の 7 つの環境を単一のモデル内でシミュレートするネイティブな言語世界モデルとして Qwen-AgentWorld を位置づけました。Qwen は2つのアプローチを示しています:シミュレータ自体を構築すること、およびエージェントの前学習に世界モデリングを活用することです。35B モデル(MoE 構成でアクティブパラメータは 3B)かつ 256K コンテキスト長を持つ Qwen-AgentWorld-35B-A3B と AgentWorldBench をオープンソース化しました。注目すべき結果として、単一ターンでの環境予測がマルチターンエージェントタスクへ転移し、ドメイン内およびドメイン外の両ベンチマークで性能向上が見られました。これは本続編記事で要約されています。
OpenThoughts-Agent は本格的なオープンデータレシピを提供します:@iScienceLuvr と @RichardZ412 が OpenThoughts-Agent を紹介しました。これはエージェントモデル向けのオープンなキュレーション・トレーニングパイプラインであり、100 以上の制御されたアブレーション実験を含んでいます。チームは 10 万例のトレーニングセットを構築し、Qwen3-32B をファインチューニングすることで、7 つのエージェントベンチマーク全体で平均精度 44.8% を達成しました。実務家にとって有用な主な知見は以下の通りです:指示の選択が不均衡に大きな影響を与える、最強のベンチマーク教師が必ずしも最良の教師とは限らない、より長い実行トレースが有益である、そして大規模化においてはソースの多様性が過剰な反復よりも優れていることです。
メモリがファーストクラスのシステム層へと進化している:エージェントにおける未解決の問題として、メモリを中心とした高シグナルの議論が多く見られます。Weaviate の Engram GA は、メモリを単にコンテキストにすべて書き込むのではなく、非同期インフラストラクチャ(asynchronous infrastructure)として位置づけ、メモリの抽出、重複排除、整合性確保、スコープ定義を行うものとして捉えています。@hwchase17 は、「睡眠時間計算(sleep-time compute)」のための LangSmith/Context Hub ワークフローを示し、トレーシングをオフラインで分析してメモリとして書き戻す手法を紹介しました。@dair_ai は、エージェントのメモリはエンドタスクの成功のみで評価されるブラックボックスではなく、ストレージ、検索、更新、統合、ライフサイクルを含む完全なデータ管理層(data-management layer)として評価すべきだと主張する論文を指摘しました。これが、エージェントの差別化が進む領域となっています。
中国オープンモデルが格差を縮め続ける:GLM-5.2、Kimi Distribution、そして計算規模
GLM-5.2 は引き続きオープンモデル議論を主導しています:複数のツイートで GLM-5.2 が現在の最強のオープンウェイト(open-weight)候補として位置づけられています。CoreWeave によれば、Artificial Analysis および Agent Arena のオープンモデルランキングで首位に立っており、Baseten と Cursor での利用可能性は迅速なサービングと配布の採用を示しています。@nutlope は GLM 5.2 を Opus 4.8 とウェブタスクで比較し、品質は同等ながらトークン出力が約 2 倍、さらに高速かつコストは約 3 分の 1 であると報告しました。また、Arena によれば、GLM-5.2 Max は Code Arena のフロントエンド分野において強力な競合群をリードしています。
ベンチマークの微妙な違いが重要:GLM-5.2 は ARC-AGI-2 にも登場しました。@fchollet はこれをオープンソースモデルによる ARC-AGI-2 の結果として現時点で最も強力だと呼びましたが、他方ではその 22.8% という数値が最先端の西側モデルと比較して何を意味するのかについて議論が続いています。より広い教訓は、特定の単一ベンチマークに関するものではなく、コーディング、エージェント、知識作業 across にわたって中国のオープンソースモデルが一貫して「現場に存在している」点にあります。
商業化とインフラの加速:Moonshot の Kimi API は現在 AWS Marketplace で利用可能となり、統合請求書や EDP(Enterprise Data Plan)の引き落としを通じて企業の調達を容易にしています。一方、中国国内の計算資源は依然として主要なテーマです。@teortaxesTex は、Huawei が 950 SuperPOD スケールのシステムを実演する可能性があるという報道を指摘し、これは大規模な国内 NPU クラスターの有意なスケールでの生産を暗示しています。これが事実であれば、中国のモデル提供エコノミーの経済性と回復力に実質的な改善をもたらすことになります。
政策、人材、そしてフロンティア・ラボ戦略が競争環境を再構築中
Anthropic は依然として政策論争の中心にあります:@kimmonismus は、トランプ政権時代の AI 輸出規制に対する最初の主要な法的挑戦を報告しました。Legion は、ホストされたモデルへのアクセスは重み(weights)や技術データの輸出とは同等ではないと主張しています。並行して、長く議論されてきた Mythos の話に文脈が加わりました:Reuters/AP の詳細はここに要約されていますが、Anthropic のモデルが制限付きのテスト演習中に米国政府の機密システムにおける脆弱性を発見したと示唆しており、一部のコメントでは以前の報道が誇張されていた可能性を警告しています。
蒸留とアクセス制御が地政学的問題に:@kimmonismus氏も報じた通り、Anthropicはアリババ系オペレーターが約 25,000 の不正アカウントと 2880 万回の Claude 交換を用いて、最先端の能力を Qwen クラスのシステムへ蒸留したと非難しました。これが事実であれば、「敵対的蒸留」に関する議論は噂から、執行や国家戦略に近しい事象へとエスカレートすることになります。
人材と新研究所:同日には人材の移動と新たな機関の設立も報告されました。アーサー・コンミーがアライメント分野で Anthropic へ合流したことは注目すべき点です。Mirendil AI は、科学における自己加速型 AI R&D をテーマに 2 億ドルのシードラウンドを完了して発足しました。英国では、BOLD Lab と SOFAIR が 2 つの新国立基礎 AI ラボに対して合わせて 6000 万ポンドのシード資金を受け取り、UCL DARK は BOLD に統合されました。また商業面では、ブルームバーグが報じた Google DeepMind から Anthropic への離脱は、スタートアップの上昇余地が引き続き最先端の人材を引きつけていることを裏付けています。
主要なツイート(エンゲージメント順)
OpenAI Jalapeño:OpenAI が初の独自推論チップを発表。これは本セットにおける最も重要な製品・インフラのローンチです。
GPT-5.5 Instant 更新:OpenAI は、意図理解、制約処理、会話スタイルを改善した改訂版 GPT-5.5 Instant をリリースしました。
Qwen-AgentWorld:アリババ Qwen がエージェント向け言語世界モデルを発表し、オープンソース化しました。
Anthropic のエージェントアイデンティティモデル:Slack で利用可能な Claude は、独自の認証情報と監査証跡を使用するようになり、企業向けエージェント設計における最も難しい質問の一つが明確になりました。
Cursor と Notion の連携:Cursor のタスクは now、Notion から直接委任できるようになりました。これは、エージェントワークフローがスタンドアロンのチャットアプリに留まるのではなく、既存のチームソフトウェアへと移行していることを示すもう一つの兆候です。
AI Reddit リキャップ
/r/LocalLlama + /r/localLLM リキャップ
続きを読む
原文を表示
The brief history of Meta-Harnesses is a little undocumented, but it roughly goes: at first there was Conductor and Zed’s ACP, then there came OpenInspect, Cloudflare’s Flue, and then Vercel’s Eve and HarnessAgent, and Heypi.
It should not go unnoticed that today’s podcast guest Matei Zaharia, CTO of the enormously successful (for a pre LLM era company) Databricks, has a big bet now on meta-harnesses - Omnigent, an open source, pluggable architecture for pulling in any coding or knowledge work agent into a standardized, secure, reliable, scalable system:
omnigent
It’s unclear whether or not Omnigent has the same kind of ingredients that made MCP’s success inevitable, but it is clear on an architectural level that some open source architecture that looks like this will probably win, if only because it is currently being independently rediscvoered at 1000 AI native shops.
AI News for 6/23/2026-6/24/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s Jalapeño Chip and the Race Toward Full-Stack AI Infrastructure
OpenAI goes deeper into hardware: OpenAI announced Jalapeño, its first custom AI chip for LLM inference, built with Broadcom and intended for ChatGPT, Codex, API traffic, and future agent products. The strategic message is straightforward: own more of the stack—chips, kernels, memory, networking, scheduling, deployment—so compute economics and product behavior become less dependent on merchant GPU supply. @gdb emphasized strong performance-per-watt, while @kimmonismus highlighted the reported 9-month design-to-tapeout cycle, unusually fast for a high-performance ASIC and reportedly accelerated by OpenAI’s own models.
Technical read-through and ecosystem implications: Community reverse-engineering suggests Jalapeño looks TPU-like: @scaling01 estimated a near-reticle die, roughly 216GB HBM3E, ~7.1–7.4 TB/s bandwidth, and ~10 PFLOPS FP4. Even if those numbers remain unofficial, the signal is that hyperscaler-style inference silicon is now table stakes for frontier labs. The same day also reshaped the compiler/runtime landscape: Chris Lattner announced Qualcomm is acquiring Modular, while Modular said Mojo open-sourcing remains on track. That combination points to more serious competition around vertically integrated inference stacks beyond NVIDIA/CUDA.
Serving and throughput remain active fronts: On the infra side, NVIDIA said NeMo AutoModel delivers 3.4–3.7x higher training throughput for MoE models via Expert Parallelism, DeepEP, and TransformerEngine kernels. SkyPilot launched Endpoints for unified inference across owned clusters, and Modal claimed open-source inference setups outperforming proprietary providers on latency. For local optimization, @jon_durbin reported 30–50% real-world decode gains from training custom DFLASH draft/speculator models.
Agent UX Shifts From “Tool” to “Coworker,” Raising New Security and Cost Questions
Anthropic’s Slack-native agent model is the big UI story: Several tweets converged on the significance of Claude embedded into Slack/team workflows. @karpathy argued people are underrating it because it is not “just a feature” or Slack bot, but an org-level harness. @gallabytes described the experiential jump from Claude Code as a “pairing partner” to Tags as “managing a team.” @dabit3 pushed the idea further: eventually, you may not even need to explicitly tag agents.
The hard part is identity, permissions, and lock-in: Anthropic detailed its agent identity model in this thread: Claude gets its own credentials, actions are auditable under that identity, and access can be revoked centrally. That design drew both praise and concern. @KentonVarda argued explicit per-agent permissioning does not scale and advocated capability-based security with fine-grained, task-scoped access. @random_walker framed Claude Tag as “a coworker that remembers everything and bills by the thought,” warning of tacit-knowledge lock-in, prompt-injection risk, and budget opacity once one shared agent becomes deeply embedded in org workflows. @JubbaOnJeans similarly flagged attribution ambiguity for write actions and future access-control complexity outside clean Slack-like boundaries.
The open/DIY response is immediate: Hugging Face described its internal Slack-based coding agent Moon Bot in a blog tweet, emphasizing self-hosting, custom tools, auditable sessions, and zero lock-in. A follow-up from @calebfahlgren listed production integrations spanning GitHub, Athena, analytics, MongoDB, Elasticsearch, and HF Buckets. The larger pattern: teams increasingly want agent-native UX, but many would rather own the harness and memory layer than outsource organizational intelligence to a vendor.
Qwen-AgentWorld, OpenThoughts-Agent, and Memory as the Next Agent Scaling Axis
Qwen-AgentWorld pushes “language world models” for agents: Alibaba Qwen introduced Qwen-AgentWorld, positioning it as a native language world model that simulates 7 environments—MCP, Search, Terminal, SWE, Web, OS, Android—inside a single model. Qwen claims two paths: build the simulator itself, and use world modeling as agent pretraining. They open-sourced Qwen-AgentWorld-35B-A3B and AgentWorldBench, with a 35B MoE / 3B active, 256K context model. One notable result: single-turn environment prediction transfers to multi-turn agent tasks with gains across both in-domain and out-of-domain benchmarks, as summarized in this follow-up.
OpenThoughts-Agent contributes a serious open data recipe: @iScienceLuvr and @RichardZ412 highlighted OpenThoughts-Agent, an open curation/training pipeline for agentic models with 100+ controlled ablations. The team builds a 100K-example training set and fine-tunes Qwen3-32B, reaching 44.8% average accuracy across seven agentic benchmarks. The key findings are useful for practitioners: instruction choice matters disproportionately, strongest benchmark teacher ≠ best teacher, longer execution traces help, and source diversity beats over-repetition at scale.
Memory is turning into a first-class systems layer: A lot of high-signal discussion centered on memory as the unresolved problem in agents. Weaviate’s Engram GA frames memory as asynchronous infrastructure that extracts, deduplicates, reconciles, and scopes memories rather than dumping everything into context. @hwchase17 showed a LangSmith/Context Hub workflow for “sleep-time compute,” where traces are analyzed offline and written back as memory. @dair_ai pointed to a paper arguing agent memory should be evaluated as a full data-management layer—storage, retrieval, update, consolidation, lifecycle—not a black box judged only by end-task success. This is increasingly where agent differentiation appears to be moving.
Chinese Open Models Keep Closing the Gap: GLM-5.2, Kimi Distribution, and Compute Scale
GLM-5.2 continues to dominate the open-model conversation: Multiple tweets positioned GLM-5.2 as the strongest open-weight contender right now. CoreWeave said it tops open-model rankings on Artificial Analysis and Agent Arena, while Baseten and Cursor availability showed rapid serving/distribution uptake. @nutlope compared GLM 5.2 against Opus 4.8 on web tasks, reporting similar quality, ~2x token output, but still faster and roughly 3x cheaper. Arena also said GLM-5.2 Max leads Code Arena: Frontend against a strong field.
Benchmark nuance matters: GLM-5.2 also showed up on ARC-AGI-2. @fchollet called it the strongest ARC-AGI-2 result to date by an open-source model, while others debated what its 22.8% really implies relative to frontier Western models. The broader takeaway is less about any single benchmark and more about open Chinese models being consistently “in the room” across coding, agents, and knowledge work.
Commercialization and infrastructure acceleration: Moonshot’s Kimi API is now on AWS Marketplace, easing enterprise procurement via consolidated billing and EDP drawdown. Meanwhile, Chinese domestic compute remains a major theme: @teortaxesTex flagged reports that Huawei may demo a 950 SuperPOD scale system, implying production of large domestic NPU clusters at meaningful scale. If true, that would materially improve the economics and resilience of China’s model-serving ecosystem.
Policy, Talent, and Frontier-Lab Strategy Are Reshaping the Competitive Landscape
Anthropic remains at the center of policy disputes: @kimmonismus reported the first major legal challenge to Trump-era AI export controls, with Legion arguing hosted model access is not equivalent to exporting weights or technical data. In parallel, the much-discussed Mythos story gained context: Reuters/AP details summarized here suggest Anthropic’s model found vulnerabilities in sensitive U.S. systems during a restricted testing exercise, though some commenters warned earlier coverage had been overstated.
Distillation and access control are becoming geopolitical issues: @kimmonismus also reported Anthropic’s accusation that Alibaba-linked operators used ~25,000 fraudulent accounts and 28.8 million Claude exchanges to distill frontier capabilities into Qwen-class systems. If accurate, that escalates the “adversarial distillation” debate from rumor to something closer to enforcement and statecraft.
Talent and new labs: The day also brought talent movement and new institutional formation. Arthur Conmy joining Anthropic is notable on the alignment side. Mirendil AI launched with a $200M seed round and a thesis around self-accelerating AI R&D for science. In the UK, BOLD Lab and SOFAIR received £60M in seed funding across two new national fundamental AI labs, with UCL DARK merging into BOLD. And on the commercial side, Bloomberg-reported departures from Google DeepMind toward Anthropic underscore how startup upside is continuing to pull frontier talent.
Top Tweets (by engagement)
OpenAI Jalapeño: OpenAI announces its first custom inference chip — the most consequential product/infra launch in the set.
GPT-5.5 Instant update: OpenAI rolls out a revised GPT-5.5 Instant with improved intent understanding, constraint handling, and conversational style.
Qwen-AgentWorld: Alibaba Qwen launches and open-sources language world models for agents.
Anthropic’s agent identity model: Claude in Slack now uses its own credentials and audit trail, clarifying one of the thorniest enterprise-agent design questions.
Cursor x Notion: Cursor tasks can now be delegated directly from Notion, another sign that agent workflows are moving into existing team software rather than living in standalone chat apps.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Read more
関連記事
OpenAI の「Jalapeño」チップの数学的背景
OpenAI は Broadcom と共同で、サードパーティ製ハードウェアへの依存による巨額の資本支出を削減するため、独自に ASIC チップ「Jalapeño」を開発した。これにより、Nvidia 製品の高い利益率から生じるコスト圧力を緩和し、自社の財務軌道を支える狙いがある。
ブラウザ互換性データベースをSQLite化
Simon Willison氏が、MozillaのMDNが提供する包括的なブラウザ互換性情報データを基に、SQLiteデータベース形式に変換するプロジェクト「simonw/browser-compat-db」を開始した。
AI SDK 7 の発表
Vercel は、週に 1600 万回のダウンロードがある TypeScript 製 AI SDK の新バージョン「7」を発表した。このアップデートにより、推論制御やツール承認機能など、エージェント開発の生産性を高める機能が強化された。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み