ハルバートン、Amazon Bedrock と生成 AI を活用して地震データ処理ワークフローを強化
ハルバートンが AWS の生成 AI サービスを活用して、地震データ処理ワークフローの構築時間を最大 95% 短縮する対話型アシスタントを開発した。
キーポイント
対話型ワークフロー構築の実現
従来の約 100 種類の専門ツールを手動で設定する必要があったプロセスを、自然言語による対話で実行可能なワークフローに変換する機能を導入した。
AWS 生成 AI サービスの活用
Amazon Bedrock、Knowledge Bases、Nova モデル、DynamoDB を組み合わせたクラウドネイティブなアーキテクチャにより、専門知識がなくても高度な解析が可能になった。
劇的な効率化とアクセシビリティ向上
ワークフロー構築の所要時間を桁違いに短縮し(最大 95% の加速)、複雑な地質解析ツールをより広範なユーザー層が利用可能にした。
ドキュメント Q&A システム
Seismic Engine の技術文書やツールの仕様に対する質問に答えるインテリジェントなシステムも併せて構築され、学習コストの削減に寄与している。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI が単なるチャットボットの枠を超え、石油・ガス探査のような極めて専門的で複雑な産業プロセスにおいて、実務効率を劇的に向上させる具体的な成功事例を示しています。特に、熟練した専門家のみが扱えた高度なツールを、自然言語操作で誰でも使えるようにする「民主化」の動きは、エネルギー分野における DX の重要な転換点となるでしょう。
編集コメント
エネルギー探査という重厚な産業領域において、生成 AI が「専門家の勘」を補完し、業務フローそのものを再定義する実例として非常に示唆に富んでいます。
地震データ解析はエネルギー探査における不可欠な要素ですが、複雑な処理ワークフローの構成は従来、時間がかかりミスが発生しやすい課題でした。Halliburton の Seismic Engine は地震データ処理用のクラウドネイティブアプリケーションであり、以前はワークフローを作成するために約 100 の専門ツールを手動で設定する必要がありましたが、これは強力なツールである一方で、このプロセスには時間がかかるだけでなく深い専門知識を要し、ソフトウェアのアクセシビリティと効率性を制限する可能性があります。
この課題に対処するため、Halliburton は AWS Generative AI Innovation Center と連携して、Seismic Engine 向けの AI パワーアシスタントを開発しました。本ソリューションは Amazon Bedrock、Amazon Bedrock Knowledge Bases、Amazon Nova、および Amazon DynamoDB を活用し、複雑なワークフロー作成を会話に変換します。地球科学者やデータサイエンティストは、手動設定ではなく自然言語による対話を通じて処理ツールを設定できるようになります。
本稿では、自然言語による問い合わせを実行可能な地震波ワークフローに変換し、Seismic Engine のツールおよびドキュメントに対する質問応答機能を提供するプロトタイプの構築方法について探ります。このソリューションの技術的詳細を解説し、ワークフローの加速が最大 95% に達することを示す評価結果を共有するとともに、生成 AI を活用して複雑な技術ワークフローを強化したい他の組織に役立つ重要な教訓についても議論します。
**
*AWS との協力は、地下構造解釈ワークフローの加速において決定的な役割を果たしました。Amazon Bedrock サービスを Halliburton Landmark の DS365 Seismic Engine に統合したことで、従来は時間のかかるワークフロー構築タスクを桁違いに短縮することができました。この生成 AI 駆動型ワークフローアシスタントは、効率性と精度の向上だけでなく、より広範なユーザーが高度な地球物理ツールを利用可能にするものです。AWS 上のスケーラブルでクラウドネイティブなアーキテクチャにより、シームレスで対話型の体験を提供し、地下構造ワークフロー全体における生産性を根本的に向上させることができました。
— Phillip Norlund, Halliburton Landmark 地下技術マネージャー— Slim Bouchrara, Halliburton Landmark 地下研究開発シニアプロダクトオーナー
ソリューションの概要
本プロジェクトでは、2 つの主要な目標を達成することを目指しました。1 つ目は自然言語によるクエリを実行可能な地震波ワークフローに変換すること、2 つ目は Seismic Engine のドキュメントに対するインテリジェントな質問応答(Q&A)システムを提供することです。これらを実現するために、地質学者が複雑な地震波ツールを自然な会話を通じて操作できる Amazon Bedrock を活用したソリューションを開発しました。
本システムの基盤は、AWS App Runner にデプロイされた FastAPI アプリケーションであり、ストリーミングインターフェースを介してユーザーのクエリを処理します。ユーザーがクエリを入力すると、Amazon Nova Lite によって駆動される意図ルーターがリクエストを分析し、ワークフロー生成を求めているのか技術情報を求めているのかを判断します。Q&A リクエストの場合、システムは Amazon Bedrock Knowledge Bases と Amazon OpenSearch Serverless を使用して、インデックス化されたドキュメントから関連する回答を提供します。一方、ワークフローリクエストの場合、Amazon Bedrock 上で Anthropic の Claude を活用した生成エージェントが、利用可能な 82 種類の Seismic Engine ツールの中から選択し、YAML 形式のワークフローを作成します。
文脈を維持し、多回にわたる対話を可能にするために、チャット履歴やインタラクションのログ記録には Amazon DynamoDB を統合しました。本システムは Q&A およびワークフロー生成の両方においてストリーミング応答をサポートしており、リクエスト処理中にユーザーに対して即座にフィードバックを提供します。このアーキテクチャにより、自然な対話を通じて複雑な技術的ワークフローを作成・修正することが可能となりながら、地震データ処理に必要な精密な制御も維持されます。以下の図は本ソリューションのアーキテクチャを示しています。
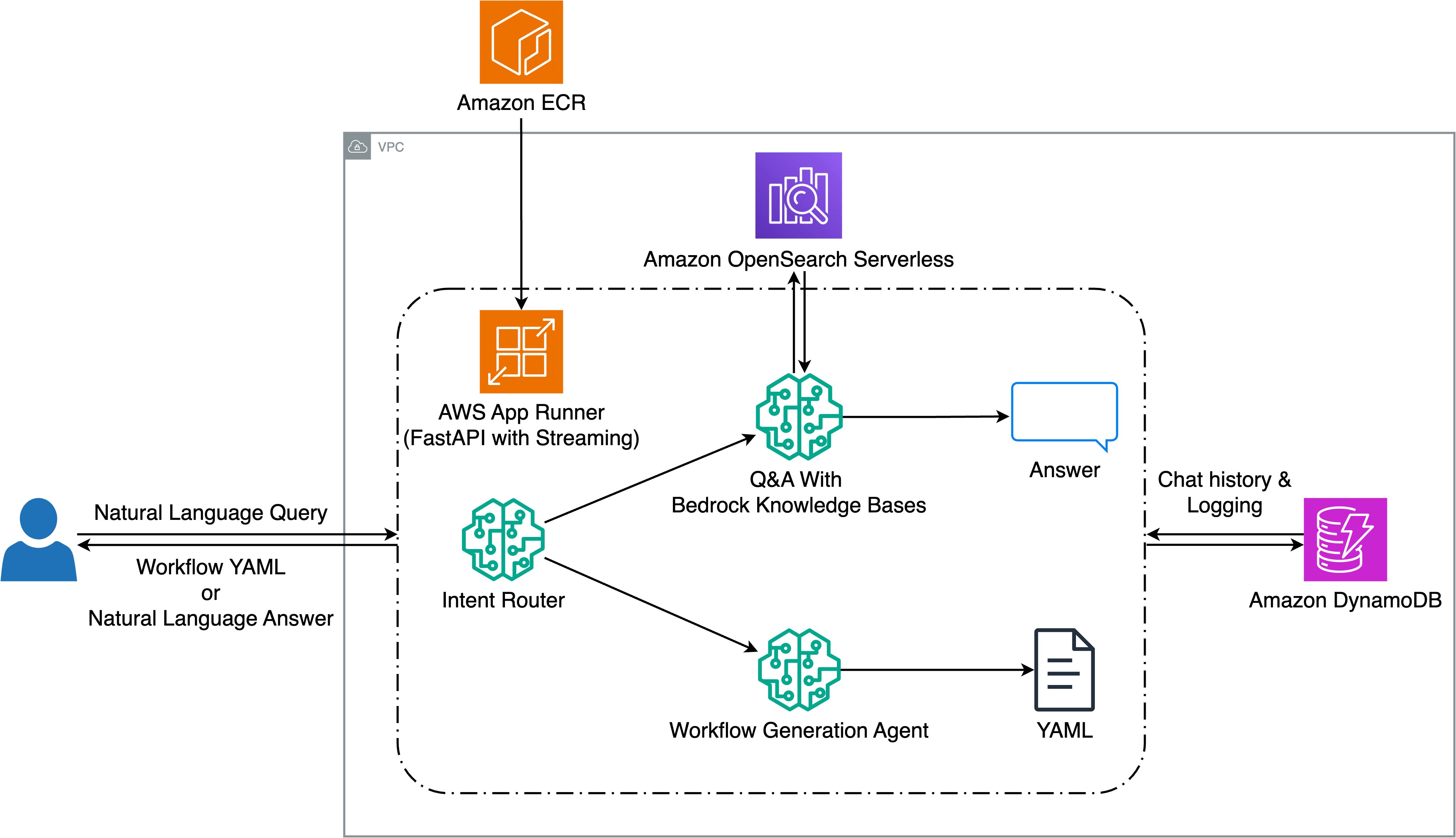
クエリルーティングと意図分類
ユーザーのクエリがシステムに提供された後、Intent Router は Amazon Bedrock API を介して Amazon Nova Lite を呼び出すことで、与えられたクエリの意図ラベルを分類します。大規模言語モデル(LLM)には、3 つの意図ラベル「Workflow_Generation」、「QnA」、および「General_Question」のいずれかを生成するプロンプトが与えられます。「Workflow_Generation」ラベルは、データセットの読み込み/ロード、データ処理操作、特定のデータセットを操作する様々なリクエストなど、ワークフロー生成に関連するクエリをルーティングするために使用されます。「QnA」意図ラベルは、特定ツールに関する質問、サンプルワークフローのリクエスト、または Seismic Engine のドキュメントに関する質問に使用されます。「General_Question」ラベルは、Seismic Engine の操作やワークフローとは無関係なクエリのために予約されています。当社の実装では、Amazon Nova Lite がルーティングタスクを効率的に実行し、精度とレイテンシの良好なバランスを提供しました。
Q&A 実装
Q&A コンポーネントは、Amazon Bedrock Knowledge Bases を活用して Seismic Engine 関連の問い合わせに対応します。これはエンドツーエンドの検索拡張生成(RAG)ワークフローのための完全管理型サービスです。ベクトルデータベースの管理、チャンキング戦略、埋め込みパイプラインの運用負荷を軽減できるため、Bedrock Knowledge Bases を選択しました。完全管理型サービスとして、インフラのスケーリング、セキュリティ、メンテナンスを自動的に処理するため、当チームは RAG インフラの運用ではなくソリューション開発に注力できます。このサービスは、階層チャンキングを含む複数のチャンキング戦略をネイティブでサポートしており、親と子の関係を維持することで、細粒度の検索と広範な文脈情報をバランスよく扱います。
データソースには、S3 に保存されたツールドキュメントの Markdown ファイルと Seismic Engine のマニュアルが含まれます。ツールドキュメントは比較的短いためチャンキングせず、個々のツールの完全な文脈を保持しました。Seismic Engine マニュアルのような長文書については、デフォルト設定で階層チャンキングを使用しています。埋め込み生成には Amazon Titan Text Embeddings V2 を、ベクトルデータベースには OpenSearch Serverless を採用しています。また、システムは各インデックスされたアイテムに対してファイル名、URL、ドキュメントタイプなどのメタデータを保存し、後続処理で利用できるようにしています。
検索と応答生成の両方において、Amazon Bedrock Knowledge Bases の retrieve_and_generate API を使用し、モデルには Claude 3.5 Haiku を採用しています。システムはセッションコンテキストを維持することで多段階会話に対応し、応答は追跡性を高めるためにインライン引用形式で出力されます。
注:このソリューションは、Claude 3.5 Sonnet V2 および Claude 3.5 Haiku を用いて開発・評価されました。その後、これらのモデルは Claude Sonnet 4.5、直近では Claude Sonnet 4.6、および Claude Haiku 4.5 に引き継がれており、これらはすべて Amazon Bedrock で利用可能です。本ソリューションのアーキテクチャはコード変更なしでモデルのアップグレードをサポートするため、最新のモデル機能をそのまま活用できます。
このアプローチにより、当社のシステムは Seismic Engine のツールやワークフローに関するユーザーの問い合わせに対して、文脈を考慮した関連性の高い回答を提供できるようになります。
ワークフロー生成
「Workflow_Generation」と分類された問い合わせに対し、本ソリューションでは LLM エージェント(大規模言語モデルエージェント)を用いて、自然言語を実行可能な YAML ワークフローに変換します。このエージェントは Seismic Engine で利用可能な 82 のツールにバインドされています。ユーザーの問い合わせと、入力・パラメータ・出力を定義するツールの仕様に基づき、エージェントは適切なツールを選択し、正しい実行順序を決定して、ユーザーの要件を満たす YAML ワークフローを生成します。以下の図はワークフロー生成のプロセスを示しています。
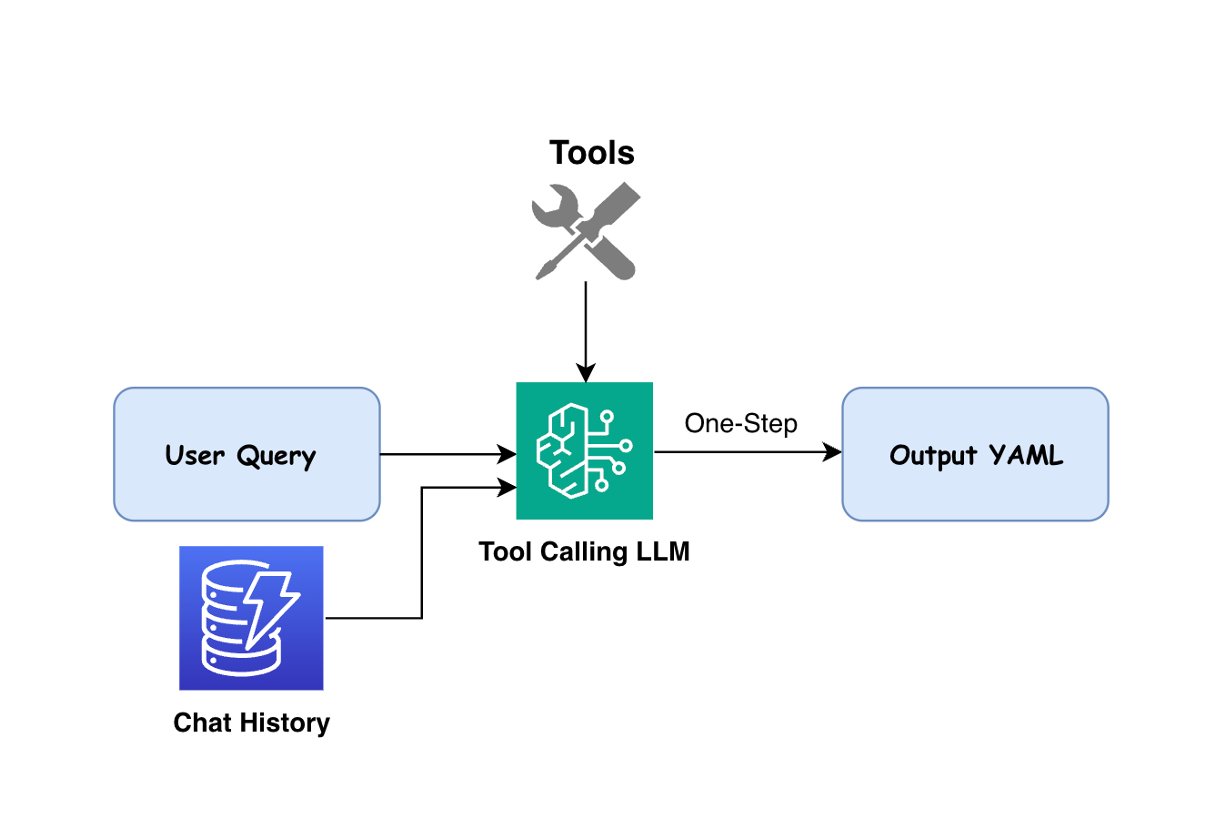
実装では、Claude 3.5 Sonnet V2 と Claude 3.5 Haiku の両方を使用し、エージェント管理とツールバインディングのために LangChain フレームワークを通じてオーケストレーションを行いました。各モデルには詳細なツールの説明と仕様が提供されており、それぞれのツールの機能や要件を理解できるようにしています。ワークフローを生成する際、システムはユーザーのクエリに含まれる明示的な要件だけでなく、特定の値が指定されていない場合に必要なデフォルトパラメータも考慮します。
ワークフロー生成プロセスは多回対話に対応しており、ユーザーは自然言語によるリクエストを通じて以前に生成されたワークフローを変更できます。Amazon DynamoDB に保存された会話履歴を活用することで、LLM はユーザーの現在のクエリに応じて新しいワークフローを生成したり、既存のワークフローを変更したりすることが可能です。
評価
本ソリューションの有効性を評価するため、低複雑度および中程度の複雑度のワークフローを含む、クエリとワークフローのペアからなる包括的なテストデータセットを作成しました。これらは実際の過去のワークフローに基づいて作成され、典型的なユーザー要求を正確に反映していることを検証するために専門家の評価を受けました。
ワークフロー生成結果
| モデル | 複雑度 | 成功率 | 平均生成時間 (秒) | 中央値生成時間 (秒) |
|---|---|---|---|---|
| Claude Haiku 3.5 | simple | 84% | 8.3 | 5.9 |
| medium | 90% | 12.4 | 9.1 |
Claude Sonnet 3.5 V2
simple
86%
11.2
11.5
medium
97%
15.8
16.6
両モデルとも高いパフォーマンスを示しましたが、特に中程度の複雑さを持つワークフローにおいて、Claude Sonnet 3.5 V2 がより優れた成功率を記録しました。本システムはストリーミング方式で応答を提供し、ワークフロー生成中にユーザーに即座フィードバックを与え、完全なワークフローの提供には 5.9〜16.6 秒を要します。Claude Haiku 3.5 はさらに高速な生成時間を提供し、速度と精度の間のトレードオフオプションとなります。
ベースライン性能との比較
ユーザータイプ
成功率
失敗率
シンプルフロー構築時間(分)
複雑フロー構築時間(分)
新規ユーザー
70%
20%
4
20
熟練ユーザー
85%
10%
2
5
本ソリューション
84-97%
3-16%
0.13-0.26
0.21-0.28
本生成 AI ソリューションは、以下の改善を示しています:
- 成功率が 84〜97% に達し、新規ユーザーおよび熟練ユーザーの両者を上回ります。
- ワークフロー作成時間が数分から数秒に短縮され、時間削減率は 95% を超えます。
これらの結果は、経験レベルに関わらずユーザーが生産性を 95% 以上向上させながら、手動でのワークフロー作成と同等かそれ以上の精度を維持できることを示しています。
結論
本稿では、Amazon Bedrock を活用して複雑な技術プロセスを自然な対話に変換する方法について紹介しました。統合された Q&A 機能を備えた AI ベースのアシスタントを実装することで、手作業によるプロセスと比較して作成時間を 95% 以上短縮し、ワークフロー生成の成功率を 84-97% に達成しました。このシステムは、低複雑度から中程度の複雑度のワークフローを処理する能力と、Seismic Engine ツールに対する文脈理解力を併せ持っており、生成 AI が精度を損なうことなく産業用ソフトウェアの使いやすさを向上させる可能性を示しています。
このアプローチは、専門的なツール知識や設定を要する複雑で多段階のアジェンシーワークフロー(agent workflows)を必要とする他の分野にも広く適用可能です。今後のステップとして、Strands Agents SDK や Amazon Bedrock AgentCore などのフレームワークを活用したマルチエージェントアーキテクチャの検討をお勧めします。これにより、専門的なサブエージェントを通じて精度をさらに向上させることが期待されます。
著者紹介

Yuan Tian
Yuan は AWS 生成 AI イノベーションセンターの応用科学者であり、医療、ライフサイエンス、金融、エネルギー分野の顧客向けに、エージェント型システムなどの生成 AI ソリューションを設計・実装しています。機械学習と計算生物学を組み合わせた学際的な背景を持ち、アラバマ大学バーミンガム校で免疫学の博士号を取得しています。

Di Wu
Di は AWS 生成 AI イノベーションセンターのディープラーニングアーキテクトであり、生成 AI(GenAI)、AI エージェント、モデルのカスタマイズを専門としています。多様な業界の企業顧客と協力し、医療データ分析エージェント、旅行予約音声エージェント、データベース深層調査エージェントなど、本番環境で即座に導入可能な AI ソリューションの設計と提供を行っています。仕事以外では、読書や執筆を楽しんでいます。

Gan Luan
Gan は AWS 生成 AI イノベーションおよびデリバリーチームの応用科学者です。生成 AI の技術を活用して、顧客が現実世界のビジネス課題を解決するのを支援することに情熱を持っています。

Haochen Xie
Haochen は、AWS 生成 AI イノベーションセンターのシニアデータサイエンティストです。彼はごく普通の人物です。

Hayley Park
Hayley は、AWS 生成 AI イノベーションセンターの応用科学者です。彼女は企業に対し、生成 AI アプリケーションを構築することで現実的なビジネス課題に取り組む支援を行っています。AWS GenAI 入社前は、Alexa Kids および Fire TV SLU チームで音声および言語体験の開発に従事していました。イリノイ大学アーバナ・シャンペーン校で計算言語学博士号を取得し、低資源言語に対する計算手法の研究に注力しました。また、統計学の修士号も保有しています。

Baishali Chaudhury
Baishali は、
原文を表示
Seismic data analysis is an essential component of energy exploration, but configuring complex processing workflows has traditionally been a time-consuming and error-prone challenge. Halliburton’s Seismic Engine, a cloud-native application for seismic data processing, is a powerful tool that previously required manual configuration of approximately 100 specialized tools to create workflows. This process was not only time-consuming but also required deep expertise, potentially limiting the accessibility and efficiency of the software.
To address this challenge, Halliburton partnered with the AWS Generative AI Innovation Center to develop an AI-powered assistant for Seismic Engine. The solution uses Amazon Bedrock, Amazon Bedrock Knowledge Bases, Amazon Nova, and Amazon DynamoDB to transform complex workflow creation into conversations. Geoscientists and data scientists can configure processing tools through natural language interaction instead of manual configuration.
In this post, we’ll explore how we built a proof-of-concept that converts natural language queries into executable seismic workflows while providing a question-answering capability for Seismic Engine tools and documentation. We’ll cover the technical details of the solution, share evaluation results showing workflow acceleration of up to 95%, and discuss key learnings that can help other organizations enhance their complex technical workflows with generative AI.
Our collaboration with AWS has been instrumental in accelerating subsurface interpretation workflows. By integrating Amazon Bedrock services with Halliburton Landmark’s DS365 Seismic Engine, we were able to reduce traditionally time‑consuming workflow‑building tasks by an order of magnitude. This generative AI–powered workflow assistant not only improves efficiency and accuracy but also makes our advanced geophysical tools more accessible to a broader range of users. The scalable cloud‑native architecture on AWS has enabled us to deliver a seamless, conversational experience that fundamentally improves productivity across subsurface workflows.
— Phillip Norlund, Manager of Subsurface Technologies, Halliburton Landmark— Slim Bouchrara, Senior Product Owner of Subsurface R&D, Halliburton Landmark
Solution overview
Our project aimed to address two key objectives: transforming natural language queries into executable seismic workflows, and providing an intelligent question and answer (Q&A) system for Seismic Engine documentation. To achieve this, we developed a solution using Amazon Bedrock that enables geoscientists to interact with complex seismic tools through natural conversation.The backbone of our system is a FastAPI application deployed on AWS App Runner, which handles user queries through a streaming interface. When a user submits a query, an intent router powered by Amazon Nova Lite analyzes the request to determine whether it’s seeking workflow generation or technical information. For Q&A requests, the system uses Amazon Bedrock Knowledge Bases with Amazon OpenSearch Serverless to provide relevant answers from indexed documentation. For workflow requests, a generation agent using Anthropic’s Claude on Amazon Bedrock creates YAML workflows by selecting from 82 available Seismic Engine tools.
To maintain context and enable multi-turn conversations, we integrated Amazon DynamoDB for chat history and interaction logging. The system supports streaming responses for both Q&A and workflow generation, providing immediate feedback to users as the system processes their requests. This architecture allows complex technical workflows to be created and modified through natural conversation, while maintaining the precise control required for seismic data processing. The following diagram illustrates the solution architecture.
Query routing and intent classification
After the user’s query is provided to the system, the Intent Router classifies the intent label of the given query by calling Amazon Nova Lite via the Amazon Bedrock API. The large language model (LLM) is given a prompt to produce one of three intent labels: “Workflow_Generation”, “QnA”, and “General_Question”.The “Workflow_Generation” label is used to route queries related to workflow generation, including reading/loading datasets, data processing operations, and various requests involving manipulating specific datasets. The “QnA” intent label is used for questions related to specific tools, requests for sample workflows, or questions about Seismic Engine documentation. The “General_Question” label is reserved for queries unrelated to Seismic Engine operations or workflows.In our implementation, Amazon Nova Lite performed the routing task efficiently, offering a good balance between accuracy and latency.
Question answering implementation
The Q&A component handles Seismic Engine-related queries by using Amazon Bedrock Knowledge Bases, a fully managed service for end-to-end Retrieval Augmented Generation (RAG) workflow. We chose Bedrock Knowledge Bases because it alleviates the operational overhead of managing vector databases, chunking strategies, and embedding pipelines. As a fully managed service, it handles infrastructure scaling, security, and maintenance automatically, so that our team could focus on solution development rather than RAG infrastructure operations. The service provides native support for multiple chunking strategies including hierarchical chunking, which maintains parent-child relationships to balance granular retrieval with broader document context.The data sources include tool documentation markdown files and Seismic Engine manuals stored in S3. We kept tool documentation files unchunked since they’re relatively short, preserving complete context for individual tools. For longer documents like Seismic Engine manuals, we used hierarchical chunking with default settings. We use Amazon Titan Text Embeddings V2 for embedding generation and OpenSearch Serverless as the vector database. The system also stores metadata such as file names, URLs, and document types for each indexed item for downstream use.For both retrieval and response generation, we use Amazon Bedrock Knowledge Bases’ retrieve_and_generate API with Claude 3.5 Haiku as the model. The system supports multi-turn conversations by maintaining session context, and responses are formatted with inline citations for enhanced traceability.
*Note: This solution was developed and evaluated using Claude 3.5 Sonnet V2 and Claude 3.5 Haiku. Since then, these models have been succeeded by Claude Sonnet 4.5 and most recently Claude Sonnet 4.6, as well as Claude Haiku 4.5, all available through Amazon Bedrock. The solution architecture supports model upgrades without code changes, so that you can use the latest model capabilities.*
This approach enables our system to provide context-aware, relevant answers to user queries about Seismic Engine tools and workflows.
Workflow generation
For queries classified as “Workflow_Generation”, our solution uses LLM agents to convert natural language into executable YAML workflows. The agent is bound with 82 tools available on Seismic Engine. Based on the user’s query and tool specifications that define inputs, parameters, and outputs, the agent selects appropriate tools, determines their correct execution order, and generates a YAML workflow that addresses the user’s requirements. The following figure illustrates the workflow generation process.
We used both Claude 3.5 Sonnet V2 and Claude 3.5 Haiku in our implementation, orchestrated through the LangChain framework for agent management and tool binding. The models are provided with detailed tool descriptions and specifications, so that they can understand each tool’s capabilities and requirements. When generating workflows, the system considers not only the explicit requirements in the user’s query but also includes necessary default parameters when specific values aren’t provided.The workflow generation process supports multi-turn conversations, so that users can modify previously generated workflows through natural language requests. By using conversation history stored in Amazon DynamoDB, the LLM can either generate new workflows or modify existing ones according to the user’s current query.
Evaluation
To evaluate our solution’s effectiveness, we created a comprehensive test dataset of query-workflow pairs, consisting of both low and medium complexity workflows. These were derived from real historical workflows and validated by subject matter experts to verify they accurately represent typical user requests.
Workflow generation results
Model
Complexity
Success Rate
Mean Generation Time (s)
Median Generation Time (s)
Claude Haiku 3.5
simple
84%
8.3
5.9
medium
90%
12.4
9.1
Claude Sonnet 3.5 V2
simple
86%
11.2
11.5
medium
97%
15.8
16.6
Both models demonstrated strong performance, with Claude Sonnet 3.5 V2 showing superior success rates, particularly for medium complexity workflows. The system delivers responses through streaming, providing users with immediate feedback as the workflow is generated, with complete workflows delivered within 5.9-16.6 seconds. Claude Haiku 3.5 offers faster generation times, providing a trade-off option between speed and accuracy.
Comparison to baseline performance
User Type
% Success
% Failure
Time to Build Simple Flow (min)
Time to Build Complex Flow (min)
New User
70%
20%
4
20
Experienced User
85%
10%
2
5
Our Solution
84-97%
3-16%
0.13-0.26
0.21-0.28
Our generative AI solution demonstrates the following improvements:
- Success rates of 84-97% surpass both new and experienced users.
- Workflow creation time is reduced from minutes to seconds, representing over a 95% time reduction.
These results demonstrate that users across experience levels can enhance productivity by over 95%, while maintaining or exceeding the accuracy of manual workflow creation.
Conclusion
In this post, we showed how we used Amazon Bedrock to transform complex technical processes into natural conversations. By implementing an AI-powered assistant with integrated Q&A capabilities, we achieved workflow generation success rates of 84-97% while reducing creation time by over 95% compared to manual processes. The system’s ability to handle both low and medium complexity workflows, combined with its contextual understanding of Seismic Engine tools, demonstrates how generative AI can improve industrial software usability without compromising accuracy.
This approach also generalizes well to other domains with complex, multi-step agentic workflows requiring specialized tool knowledge and configuration. As next steps, consider exploring multi-agent architectures using frameworks like Strands Agents SDK with Amazon Bedrock AgentCore for improved accuracy through specialized sub-agents.
About the authors
Yuan Tian
Yuan is an Applied Scientist at the AWS Generative AI Innovation Center, where he architects and implements generative AI solutions such as agentic systems for customers across healthcare, life sciences, finance, and energy. He brings an interdisciplinary background combining machine learning with computational biology, and holds a Ph.D. in Immunology from the University of Alabama at Birmingham.
Di Wu
Di is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in GenAI, AI agents, and model customization. He works with enterprise customers across diverse industries to architect and deliver production-ready AI solutions, including healthcare data analyst agents, travel booking voice agents, and database deep research agents. Outside of work, Di enjoys reading and writing.
Gan Luan
Gan is an Applied Scientist on the AWS Generative AI Innovation and Delivery team. He is passionate about leveraging generative AI techniques to help customers solve real-world business problems.
Haochen Xie
Haochen is a Senior Data Scientist at AWS Generative AI Innovation Center. He is an ordinary person.
Hayley Park
Hayley is an Applied Scientist at the AWS Generative AI Innovation Center, where she helps companies tackle real business problems by building generative AI applications. Before joining AWS GenAI, she worked on voice and language experiences across the Alexa Kids and Fire TV SLU teams. She holds a Ph.D. in Computational Linguistics from the University of Illinois at Urbana-Champaign, where her research focused on computational methods for low-resource languages, as well as an M.S. in Statistics.
Baishali Chaudhury
Baishali is a
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み