マルチエージェント協調ガイド:5つの主要モードの選び方・使い方
宝玉の分享は、多智能体システムの実装において、問題に応じて「生成-検証者」「スケジューラ-サブエージェント」「エージェントチーム」「メッセージバス」「共有状態」の5つの主要な協調パターンから適切なものを選択し、その原理と限界を理解するための実践的なガイドを提供している。
キーポイント
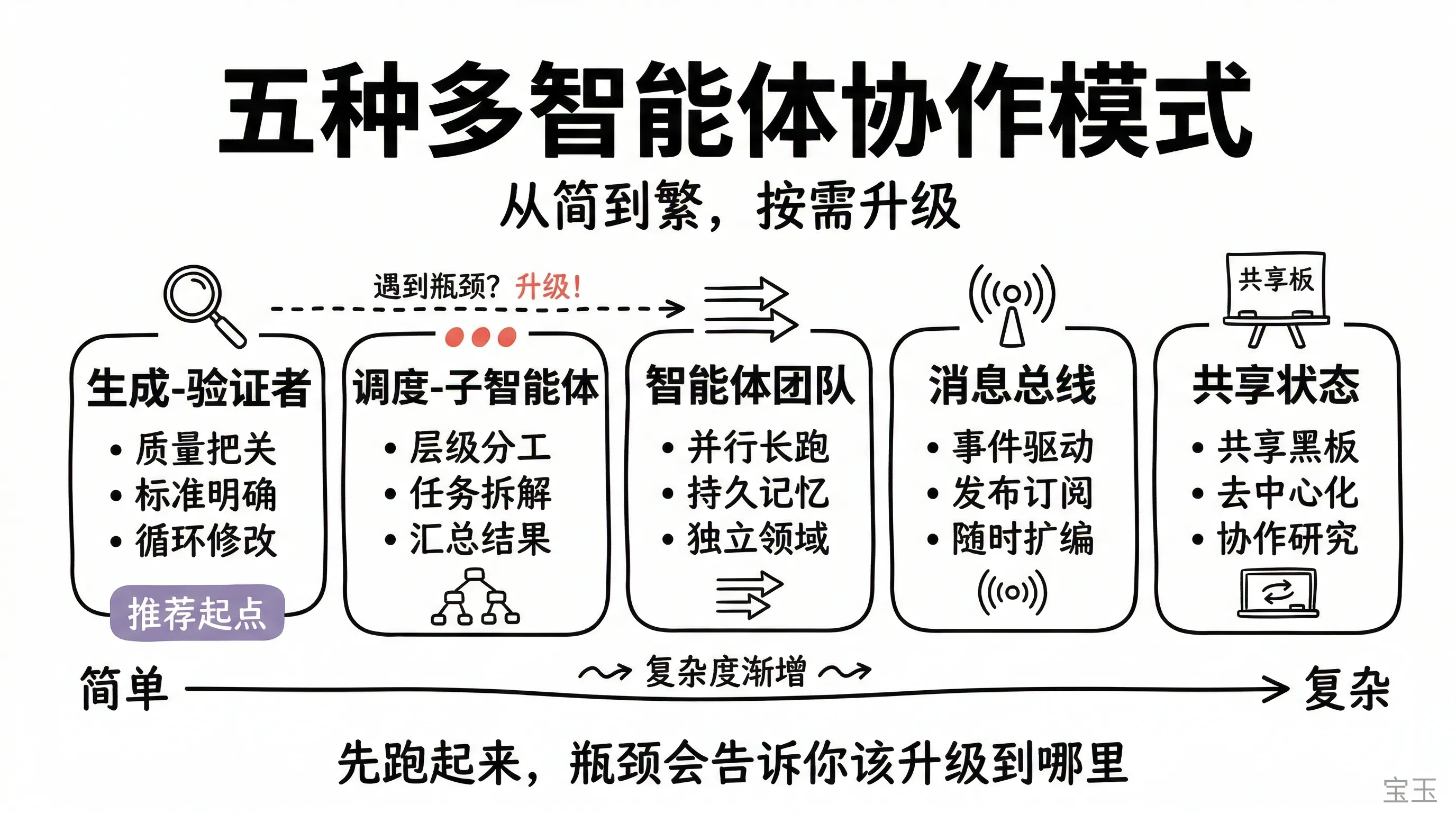
5つの主要な多智能体協調パターン
記事は、生成-検証者、スケジューラ-サブエージェント、エージェントチーム、メッセージバス、共有状態という5つの主要な協調パターンを紹介し、それぞれの適用シナリオを明確にしている。
パターン選択の実践的アプローチ
チームは、問題に最も適した「高級な」パターンを選ぶのではなく、最もシンプルで機能するものから始め、ボトルネックを観察しながら段階的にアップグレードすることを推奨している。
各パターンの詳細な原理と限界
各パターンについて、その動作原理、具体的な適用例(例:コード生成、顧客対応、コードレビュー)、および陥りやすい落とし穴や制約(例:検証基準の不明確さ、情報のボトルネック、デッドロック)を詳細に解説している。
実装における重要な注意点
パターンの実装では、検証基準の明確な定義、最大反復回数の設定、並列処理の考慮、情報共有の効率化など、具体的な設計上の考慮事項が強調されている。
团队模式的特点与适用场景
团队模式中成员长期存在,持续积累领域知识,适合处理相互独立、多步骤、长时间的子任务,如代码库迁移。
消息总线模式的运作方式与挑战
消息总线通过发布/订阅机制实现智能体间解耦通信,适合事件驱动的流水线系统,但存在问题排查困难和路由器分发准确性的风险。
共享状态模式的优势与风险
共享状态模式消除了中间商和单点故障,支持智能体直接协作,但可能导致重复工作、结果不可预测,以及陷入反应式死循环的风险。
影響分析・編集コメントを表示
影響分析
この記事は、多智能体システムの実装を目指す開発者やチームに対して、理論ではなく実践に焦点を当てた明確な選択フレームワークを提供している。これにより、AIエージェントの協調設計における試行錯誤を減らし、より効率的で堅牢なシステム構築を促進する可能性がある。
編集コメント
多智能体の実装において、パターンの選択と設計上の落とし穴を具体的に解説した実践的なガイド。技術的な革新性よりも、現場での適用可能性と設計の深さに価値がある。
以前の記事で、マルチエージェントシステムが最大の価値を発揮するのはどのような場合か、そして単一エージェントの方が適しているのはどのようなケースかを検討しました。今回の記事は、「マルチエージェント」の道を選んだチーム向けです:現在抱えている問題に対して、どの協調パターンを選ぶべきでしょうか?
私たちはよく、あるチームがパターンを選定する際、「高級感」があるものばかりを選び、実際に手元の問題に適合しているかどうかを無視しているのを目にします。私たちのアドバイスは、動作可能な最もシンプルなパターンから始め、どこでボトルネックが発生するかを観察し、その後段階的にアップグレードすることです。本記事では、5つの一般的なパターンの動作原理と限界を分解します:
ジェネレーター・ベリファイア(Generator-verifier):出力の品質を重視し、明確な評価基準があるシナリオに適しています。
オーケストレーター・サブエージェント(Orchestrator-subagent):タスクの分解が明確で、サブタスクの境界がはっきりしているシナリオに適しています。
エージェントチーム(Agent teams):並列処理が可能で互いに干渉せず、長時間実行されるサブタスクがあるシナリオに適しています。
メッセージバス(Message bus):イベント駆動型のパイプライン作業や、システムが継続的に新しいエージェントを追加しているシナリオに適しています。
共有状態(Shared-state):高い協調性が必要で、エージェント同士が他の発見を参照し合う必要があるシナリオに適しています。
パターン1:ジェネレーター・ベリファイア(Generator-verifier)
これは最もシンプルなマルチエージェントパターンであり、現在実装例が最も豊富なパターンの一つです。以前の記事では「検証サブエージェントパターン」と呼んでいましたが、ここでは「ジェネレーター」が必ずしも全体を指揮するオーケストレーターである必要がないため、より広義の「ジェネレーター・ベリファイア」という名称を使用します。
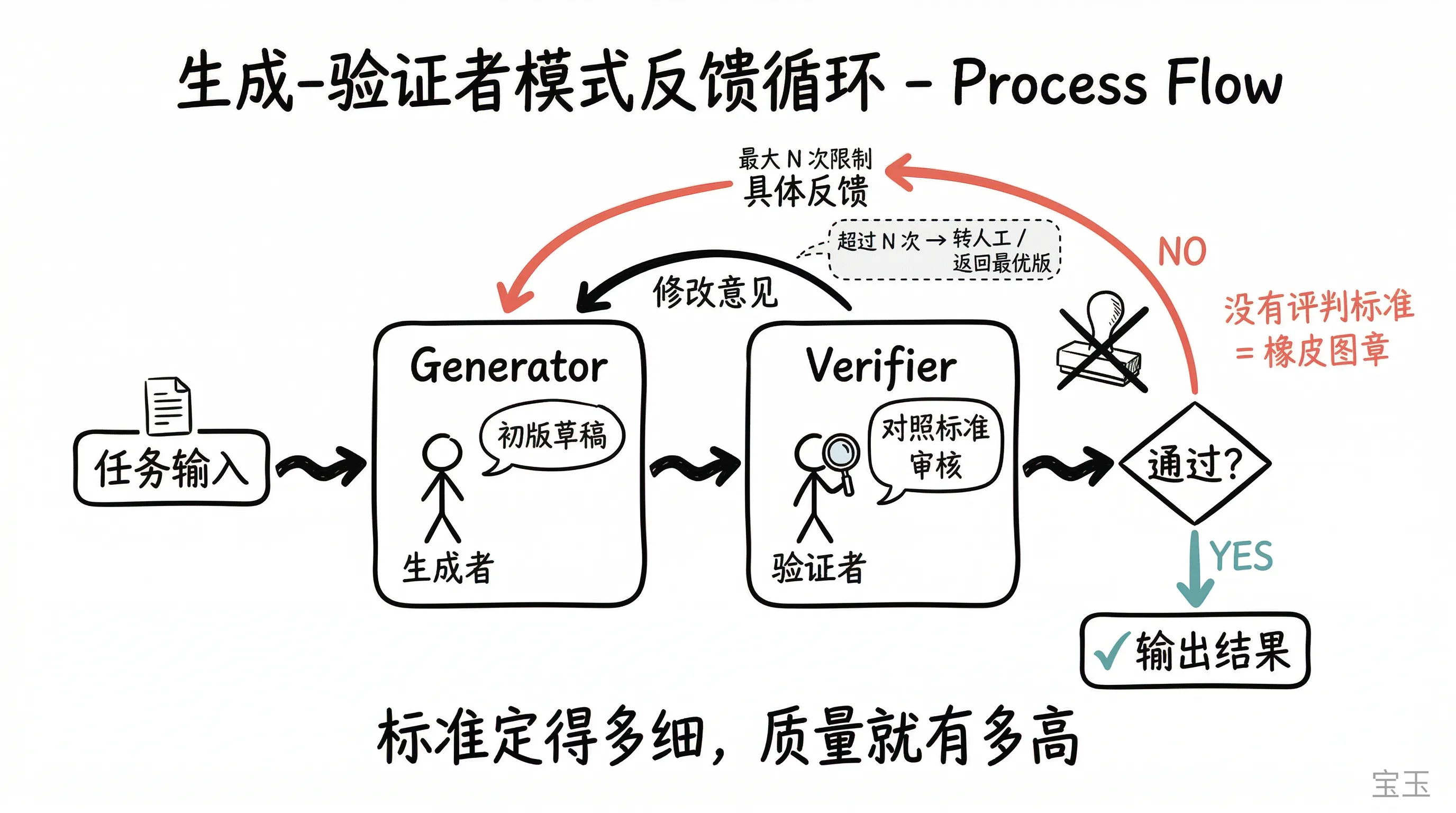
ジェネレーター(Generator)はタスクを受け取ると、まず初期結果を出力し、それをベリファイア(Verifier)に渡して評価させます。ベリファイアは、その結果が規定された基準を満たしているかを確認します。基準を満たせば承認し、満たさなければ具体的な修正意見(フィードバック)をジェネレーターに戻します。ジェネレーターはこれらのフィードバックを受け取って再修正を行います。この「修正・審査」のループは、ベリファイアが満足するか、システムが設定した最大修正回数の制限に達するまで続きます。
顧客からのサポートチケットに対応する自動メールシステムを想像してみてください。ジェネレーターは製品ドキュメントとチケットの詳細情報を用いて下書きを作成します。ベリファイアは「品質管理担当者」として機能し、ナレッジベースを確認して事実の正確性を検証し、トーンがブランド要件に適合しているかチェックし、顧客が提起したすべての問題に対応しているか確認します。審査に通らなかった場合、ベリファイアは具体的な問題をジェネレーターに戻し、「ある機能を誤って基本版に分類している」や「特定の質問への回答を漏らしている」といった指摘を行います。
出力の品質が極めて重要であり、「良い結果とは何か」を明確な基準で記述できる場合、このパターンは間違いなく適しています。これはコード生成(1つのエージェントがコードを記述し、もう1つがテストを記述して実行する)、事実確認、固定スコアシートに基づく採点、コンプライアンス監査、そして「1回の失敗のコストが複数回の修正プロセスを上回る」あらゆる分野に非常に適しています。
このシステムの下限は、完全に検証者の審査基準がどの程度細密かにかかっています。(注:もし検証者に「これが良いかどうか見て」とだけ伝えて、具体的な基準を与えなければ、それは往々にして目を閉じて「合格」の判を押すだけの形骸化したプロセスになってしまいます。)チームがこのモードを適用する際、最も犯しやすい誤りは、ループメカニズムは構築したものの、「検証」が何を意味するかを明確に定義しなかったことです。これでは、「品質管理を行っている」という偽りの繁栄を生むだけです。
さらに、このモードは「生成」と「検証」が切り離可能な二つのスキルであると仮定しています。しかし、もしあなたが卓越したアイデアを評価しようとする場合、それを評価する難しさは、そのアイデアを生み出す難しさと同等かそれ以上になる可能性があり、この場合、検証者の信頼性は必ずしも高くありません。
最後に、このループは「行き詰まり」に陥りやすいです。生成者が検証者の指摘する問題を解決できない場合、システムは両者の間でボールを蹴り合い続け、永遠に収束しません。したがって、最大ループ回数の制限を設定し、バックアッププラン(例えば、人間への手渡しや、プロンプト付きで現在最良のバージョンを返す処理など)を用意して、無限ループに陥るのを防ぐ必要があります。
モード2:オーケストレーター - サブエージェント (Orchestrator-subagent)
このモードの核心は「階層制」にあります。「チームリーダー」のような中核エージェントが業務の計画立案、タスクの割り当て、そして結果の最終的な集約を担当し、各サブエージェント (Subagents) は具体的な分担業務を処理して上司に報告します。
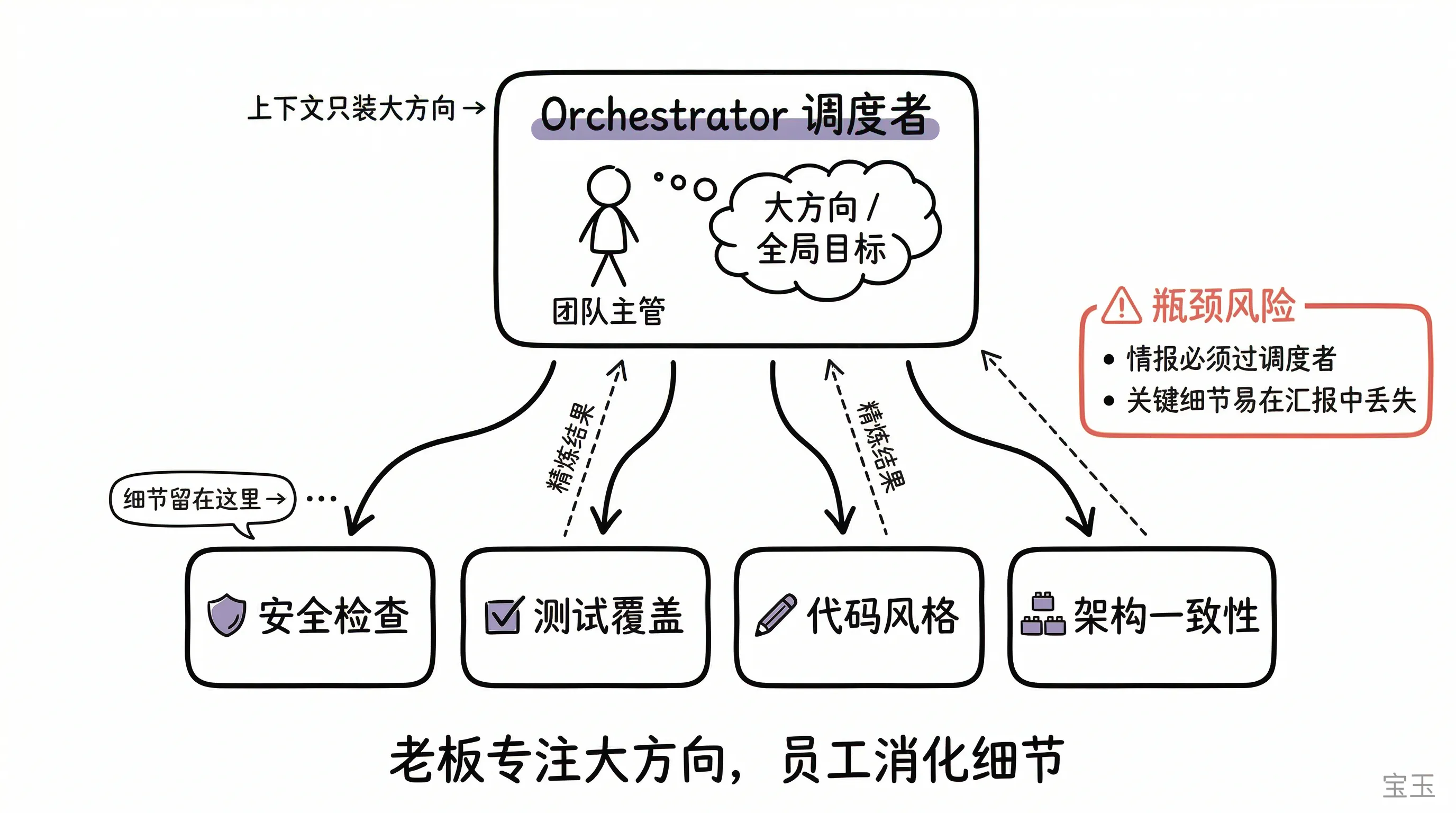
主導するオーケストレーター (Orchestrator) はタスクを受け取ると、どのように着手すべきかを考えます。一部は自身で解決し、残りを異なるサブエージェントに割り当てます。部下たちが作業を完了して結果を提出した後、オーケストレーターはそれらの断片を組み合わせて完全な最終回答を作成します。
Claude Code はこのモードを採用しています。主エージェントはコードの記述、ファイルの変更、コマンドの実行を自身で担当しますが、膨大なコードベースでの広範な検索や、独立した問題の調査が必要な場合、バックグラウンドでサブエージェントに委任します。これによりメインの作業が停止することなく、検索結果が絶え間なく送られてきます。各サブエージェントは独自のコンテキストウィンドウ (Context window) で動作し、精査された調査結果のみを返します。(注:これはまるで、上司の頭脳(コンテキスト)が大きな方向性に集中し、資料調査などの複雑な情報は従業員の頭脳内で処理されるため、上司の思考が細かな事柄で埋め尽くされないようにするようです。)
自動化されたコードレビュー (Code review) システムを想像してみてください。新しいコードが提出されると、システムはセキュリティ脆弱性のチェック、テストカバレッジの検証、コードスタイルの評価、アーキテクチャの一貫性確認を行います。これらのチェック方向は互いに干渉せず、必要な背景知識も異なり、明確なレポートを出力できます。この場合、オーケストレーターはタスクを複数の専門サブエージェントに分配し、それらが調査を終えた後、レポートを融合して包括的な審査意見を作成します。
タスクの分解が非常に明確で、サブタスク間の相互依存関係が少ない場合、このモードは非常に効果的です。オーケストレーターは大目標を常に掌握し、サブエージェントは細分化された作業に集中して遂行できます。
オーケストレーターは情報の「ボトルネック」になりやすいです。あるサブエージェントが他のサブエージェントの作業に影響を与える可能性のある情報を発見した場合、その情報はまずオーケストレーターに報告され、そこから再配布されます。例えば、セキュリティ調査を行うエージェントが認証の脆弱性を発見し、それがアーキテクチャ分析を行うエージェントの分析に影響する場合です。情報が上下の間で頻繁にやり取りされると、重要な詳細が繰り返される「要約報告」の過程で見失われやすくなります。
さらに、専用の並列処理を行わない場合、サブエージェントは順番に作業を行います。これは、マルチエージェントでデータを処理(Token)するコストを支払いつつ、「人手が多ければ仕事が速い」という速度の恩恵を受けられないことを意味します。
モード3:エージェントチーム (Agent teams)
大規模な作業が複数の並列サブタスクに分解可能であり、かつこれらのタスクが長時間の独立した完了を要する場合、「リーダーによる業務配分」の階層制は硬直しすぎてしまいます。
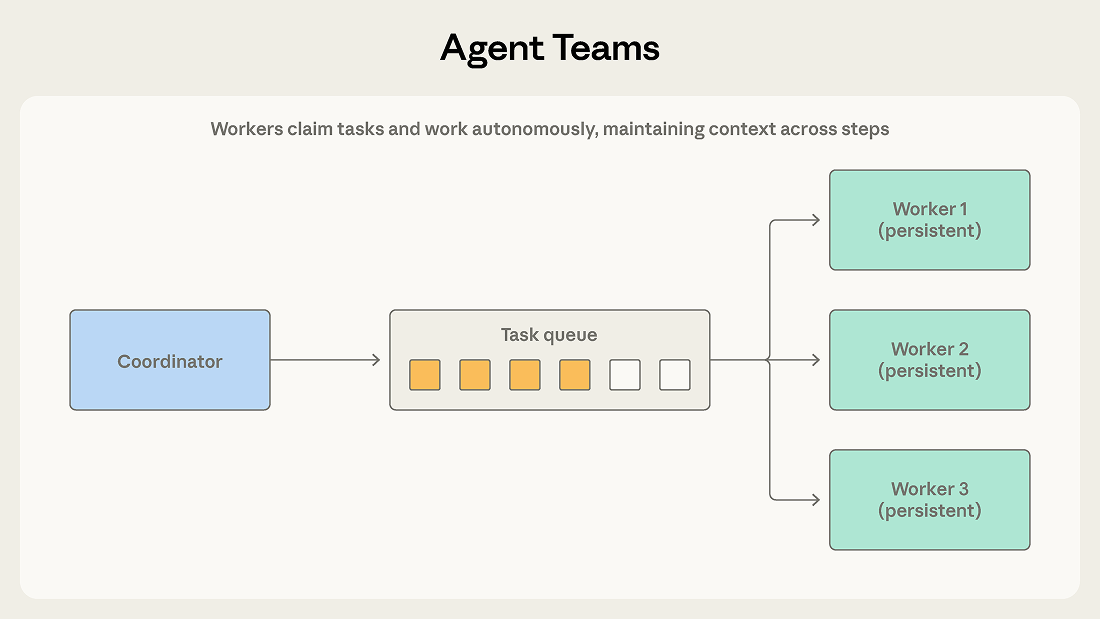
コーディネーター(Coordinator)は、独立したプロセスとして動作する複数のチームメンバー(Teammates)を作成します。これらのメンバーは共有されたタスクキューから自ら「注文」を受け取り、受領後には多段階の操作を自律的に完了し、終了時にシグナルを送ります。
このパターンと「スケジューラ-サブエージェント」模式の最大の違いは、メンバーの永続性にあります。スケジューラは通常、小さなタスクのために一時的にサブエージェントを呼び出し、完了後に解散させます。しかし、チーム模式ではメンバーは長期的に存在し、タスクを引き受ける過程でドメイン知識やコンテキストを蓄積し、経験を積むにつれて熟練していきます。コーディネーターはタスクの割り当てと結果の回収のみを行い、各タスク完了後にメンバーの記憶をクリアすることはありません。
例えば、巨大なコードベースをあるフレームワークから別のフレームワークへ移行する場合を考えます。各チームメンバーは、独立して1つのサービスモジュールの移行を担当し、依存関係の処理、コード修正、テストバグの修復、検証を自分で行います。コーディネーターはモジュールをメンバーに分配し、メンバーはその一連の移行プロセスを自律的に完了します。最後にコーディネーターはすべての移行済みモジュールを集め、システムレベルの統合テストを実行します。
サブタスクが互いに独立しており、多段階かつ長時間の処理を必要とする場合、この模式が最も効果的です。各メンバーは毎回新人のように振る舞うのではなく、自身の小さな領域での経験を蓄積し続けるためです。
「独立性」はこの模式の生命線であり、同時に弱点でもあります。スケジューラ模式のように調整役が仲介して情報を共有するのではなく、チームメンバーは各自黙々と作業を行うため、中間進捗を互いに共有することは困難です。もしAの作業がBに影響を与える場合、両者がそれを認識していなければ、最終的な出力で競合が発生する可能性があります。
進捗管理も頭痛の種です。作業完了までの時間がメンバーによって異なり、2分で終わるものもあれば20分かかるものもあるため、コーディネーターはこうした「ばらつきのある」部分的な完了状態を忍耐強く処理する必要があります。
さらに、共有リソースの競合が発生すると問題が深刻化します。複数のメンバーが同時に同じコードベース、データベース、またはファイルを変更する場合、2人が同じファイルを編集したり、互いに矛盾する変更を行ったりすることが容易に発生します。これに対応するためには、タスク割り当て時に明確な境界線(「楚河漢界」)を定め、競合解決メカニズムを準備しておく必要があります。
模式四:メッセージバス (Message bus)
エージェントの数が増加するにつれて、相互に連携する方法は複雑さを増し、直接対話による通信は破滅的なものになりかねません。そこで登場するのがメッセージバス (Message bus) です:これは共有の通信ホールを提供し、エージェントが「公開(Publish)」と「購読(Subscribe)」を通じて作業を調整できるようにします。
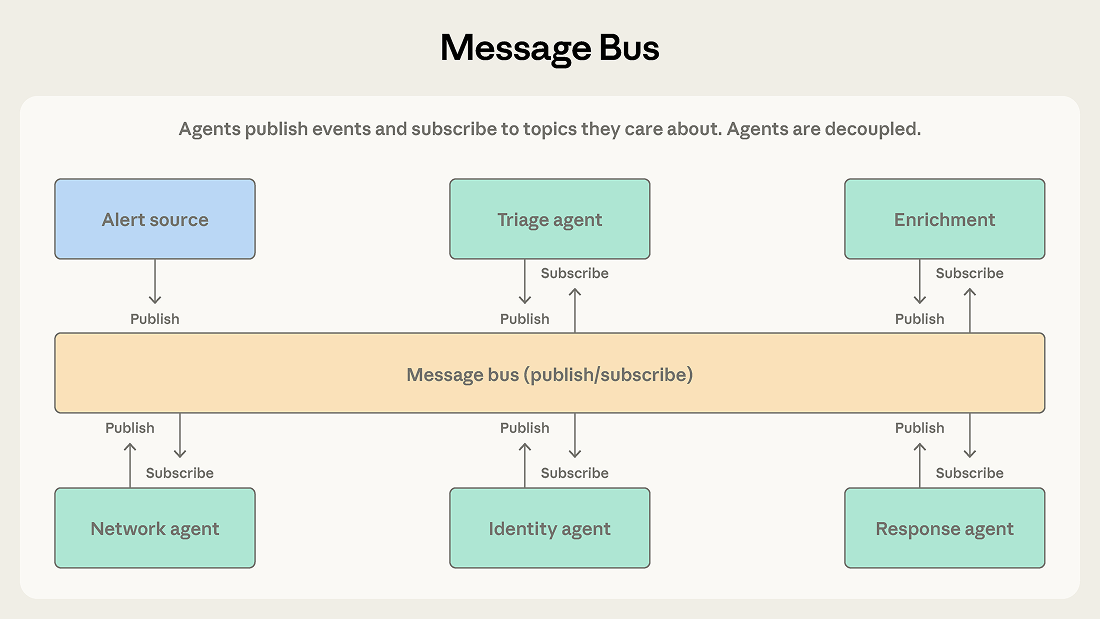
エージェントは公開(Publish)と購読(Subscribe)という2つの基本的な動作のみで通信を行います。エージェントは関心のある「トピック」を購読し、ルーター(Router)が関連するメッセージを正確に配信します。(注:これは大規模な企業チャットグループで、誰かがニーズを投稿し、関連部門の担当者がそれを見て自動的に引き受けることに似ています。誰が注文を引き受けたかを知る必要はありません。)将来、新機能を持つエージェントが参加した場合、それらは関連するトピックを購読するだけで直接業務を開始でき、既存のネットワーク構成を変更する必要はありません。
自動化されたセキュリティ運用システムは、この模式にとって完璧な舞台です。さまざまなチャネルから警报が雪崩のように届きます。「トリアージエージェント」は重大度とタイプを評価し、高リスクのネットワーク警报を「ネットワーク調査エージェント」に送り、「アカウント関連警报」を「アイデンティティ分析エージェント」に送ります。調査エージェントが作業中、「より多くの背景情報が必要」というメッセージを公開することがあり、インテリジェンス収集を担当する専用エージェントがそれを見て支援します。最後に、すべての発見は「レスポンスコーディネーションエージェント」に流れ、そこで最終的な処理方針が決定されます。
このパイプラインはまさにメッセージバス用に設計されています:イベントは前のステージから次のステージへスムーズに流れ、新しい脅威が登場すればチームはいつでも新たなセキュリティエージェントを追加でき、各エージェントの開発とデプロイメントも互いに干渉することなく進められます。
システムがイベント駆動型のパイプライン(ワークフローは固定された順序ではなく、突発的なイベントによって決定される)であり、かつエージェントチームが今後さらに拡大する見込みがある場合、このパターンを選択します。
このイベント駆動型の通信はあまりにも柔軟であるため、問題のトラブルシューティングが非常に困難になります。あるアラートがドミノ倒しのように5つのエージェントの連鎖反応を引き起こした場合、中間で何が起こったのかを把握するには、非常に詳細なログ記録を確認し、それらを関連付けて比較する必要があります。これは「オーケストレーター」に従って順番にバグを追跡するよりもはるかに苦痛です。
ルーターの分发(ルーティング)精度も極めて重要です。もしルーターがメッセージを誤って分類したり、完全に送信し忘れたりした場合、システムは「サイレントクラッシュ(静かなる停止)」に陥します。エラーは発生せず、システムもダウンしませんが、何もしない状態になります。大規模言語モデル(LLM)に基づくルーターは意味理解において柔軟性が高い反面、LLM固有の失敗リスク(解釈の偏りやハルシネーションなど)も伴います。
パターン5:共有状態 (Shared state)
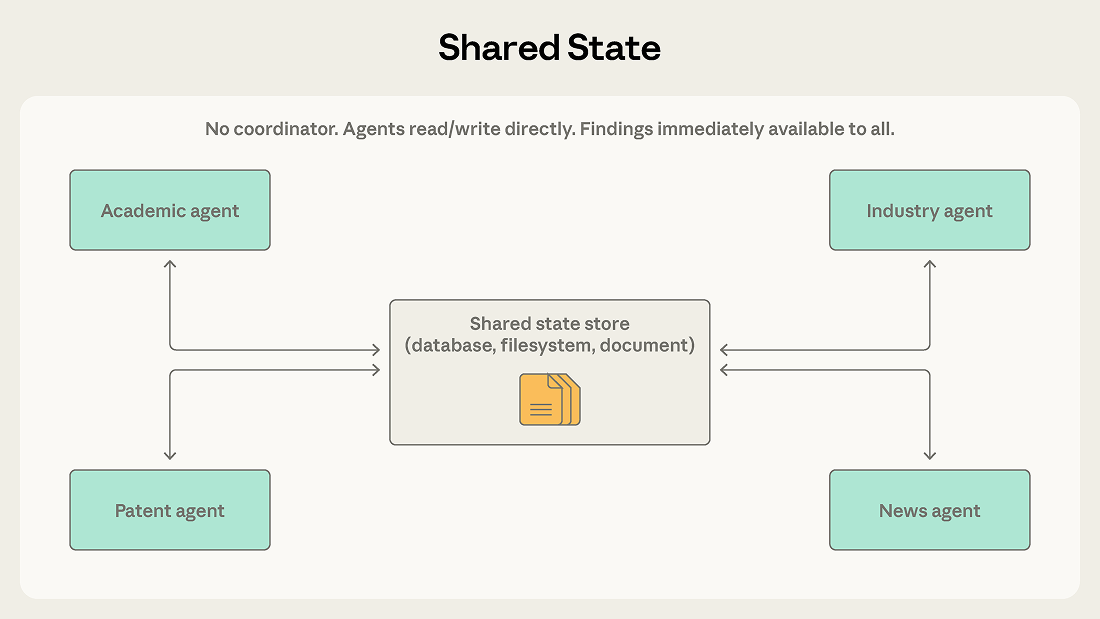
前述のどのパターン(オーケストレーター、コーディネーター、ルーター)においても、本質的には情報フローの「仲介者」が機能しています。一方、共有状態 (Shared state) パターンは仲介者を完全に排除し、すべてのエージェントが永続的なストレージ領域(データベース、ファイルシステム、またはドキュメントなど)を共有してアクセスできるようにします。各エージェントはそこから直接情報を読み取り、結果を書き込むことができます。
このパターンでは「中央指揮官」は存在しません。エージェントたちは公共の黒板の前で作業しているかのように振る舞います:黒板上の线索(手がかり)を確認し、自分たちが処理できるものを取得して作業を行い、新しい発見があればそれを黒板に書き戻します。通常、起動プロセスは黒板上に大きな問題文を書くか、初期データを一括配置することで行われます。特定の終了条件が満たされた時点で作業は停止します。例えば、時間切れになった場合、誰も新しい発見をしなくなった場合(収束閾値)、または特定のエージェントが「黒板上の答えは十分良い」と宣言した場合などです。
分野横断的な総合調査を担当するシステムを想像してみてください。複雑な問題を調べるために、あるエージェントは学術論文を検索し、別のエージェントは業界レポートを確認し、さらに別のエージェントは特許文献を解析し、また別のエージェントがニュース動向を追跡します。各エージェントが調査した内容は、他者にとって重要な线索となる可能性があります。例えば、学術論文を検索するエージェントが核心研究者を偶然発見した場合、業界レポートを確認するエージェントは直ちにその研究者の背後にある企業を深く掘り下げることができます。
共有状態では、すべての発見が直接黒板に記録されます。業界レポートを確認するエージェントは、学術論文を検索するエージェントの新しい発見を即座に確認でき、コーディネーターを介して情報をやり取りする必要はありません。各エージェントは互いの成果を活用しながら進歩し、この共有黒板は次第に進化し続ける知識ベースへと変貌していきます。
このパターンのもう一つの利点は、単一障害点(Single Point of Failure)を排除できることです。あるエージェントがダウンしても、他のエージェントは黒板に対して読み書きを続けることができます。しかし、オーケストレーションパターンやメッセージバスパターンでは、指揮官やルーターが機能停止すれば、システム全体が麻痺してしまいます。
統一された指揮系統を失うと、エージェントは容易に同じ作業の繰り返し(輪造り)や、正反対の方向への進捗を引き起こします。例えば、2つのエージェントが偶然にも同じ线索を調査する可能性があります。システムの最終的な振る舞いは、各要素の相互作用によって生み出されるものであり、上から下へ設計されたものではないため、結果の予測が困難になります。
最も致命的な故障モードは、「反応型ループ(Reactive loops)」に陥ることです。例えば、エージェントAが一つの発見を記録し、それを見たエージェントBが補足を追加し、その補足を見たAがさらに返信する……という状況です。システム全体がまるで2つのロボットが無限にネストされたチャットを行い、高価な計算リソース(トークン)を浪費しながらも結論に到達しない状態になります。重複作業や並行書き込みに対しては、ロックの追加、バージョン管理、パーティショニングなど、エンジニアリング界には確立された解決策があります。しかし、「無限のネスト」というのは動作パターンに関する問題であり、システム設計の初期段階で「一票否决」の終了条件を定義する必要があります。具体的には、固定された時間予算を与える、連続数ラウンドで新たな発見がない場合に強制停止する、あるいは「審判者」エージェントを配置して回答が完結したかどうかを随時判定させるなどの方法があります。(注:終了メカニズムの設計を無視すると、システムは破産するまで無限ループに陥るか、あるいはあるエージェントの脳(コンテキストウィンドウ)が溢れてシステムがクラッシュします。)
どのパターンを選ぶかは、システムに対するいくつかの核心的な構造的問題への判断に依存します。以前の投稿で私たちは、「コンテキスト中心型分解(Context-centric decomposition)」を提唱しました。これは、エージェントが「どのような種類の作業を行うか」ではなく、「どの背景情報を必要とするか」という観点で役割を分担するアプローチです。この原則は今回の議論でも同様です。これら5つのパターンの最大の違いは、コンテキストの境界をどのように区切り、情報の流れを管理するかという点にあります。
オーケストレーション - サブエージェント vs. エージェントチーム
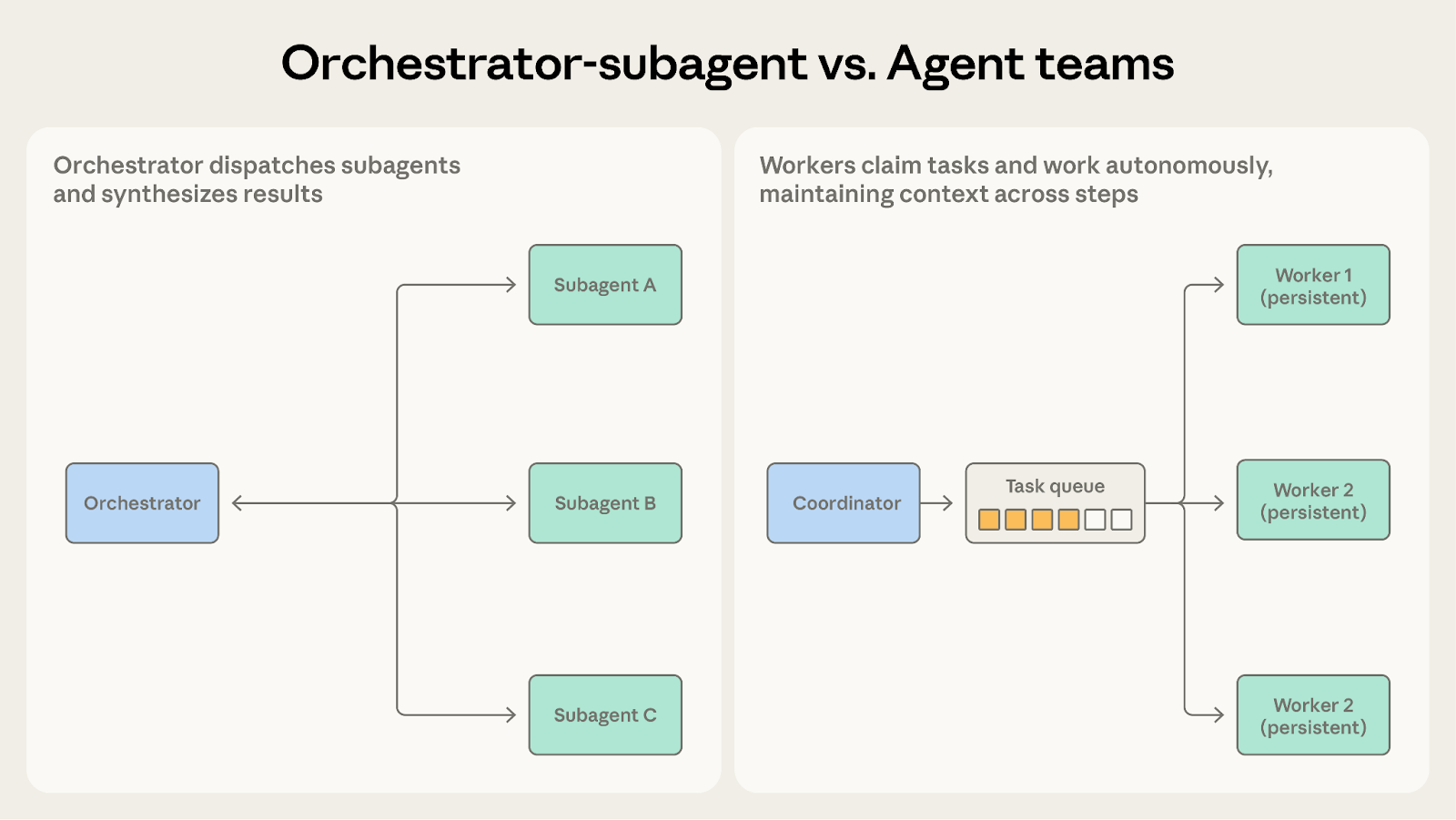
両者には「作業の割り当て」を行うコーディネーターが存在します。どう選べばよいでしょうか? 次の問いに自問してください:作業を行うエージェントは、長期間にわたって記憶(コンテキスト)を保持する必要があるか?
オーケストレーション - サブエージェントを選ぶ場合:サブタスクが短く、焦点が絞られており、出力が明確な場合に適しています。コードレビューシステムがその例です。各チェックは単発的であり、分析を実行しレポートを生成して提出するだけです。サブエージェントは複数のタスク間で記憶を保持する必要はありません。
エージェントチームを選ぶ場合:サブタスクが複数のステップにまたがり、長期的な処理を経て成果が出る場合に適しています。コードベースの移行がその例です。メンバーは同じサービスモジュールと長期間向き合い、依存関係、テストの法則、デプロイ設定などを徐々に把握していきます。こうした蓄積された背景知識は、「使い捨て」のオーケストレーションモードでは提供できません。
サブエージェントが複数回の起動間で以前の状態を記憶する必要がある場合、エージェントチームの方が適した選択肢となります。
オーケストレーション - サブエージェント vs. メッセージバス
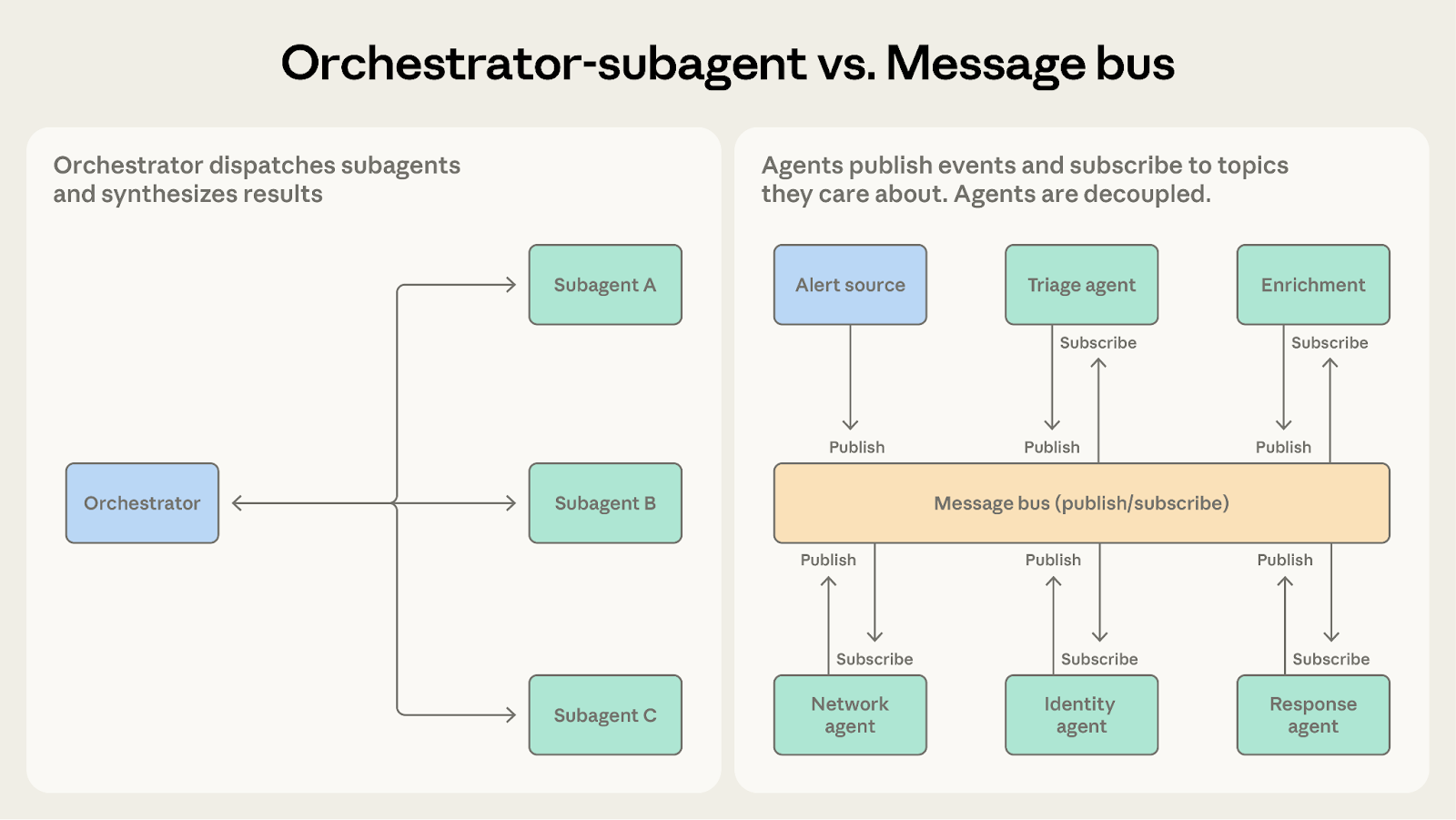
両者ともマルチステップワークフローを処理できます。どう選べばよいでしょうか? 次の問いに自問してください:あなたのワークフローは事前に予測可能か?
オーケストレーション - サブエージェントを選ぶ場合:ステップが事前に決定されている場合に適しています。コードレビューシステムのように、常に同じ3つの手順(コミットリクエストの受信、チェックの実行、結果の集計)が繰り返されます。
メッセージバスを選ぶ場合:ワークフローが突発的なイベントによってトリガーされ、方向性が常に変化する可能性がある場合に適しています。セキュリティ運用システムは、次に来るアラートや展開すべき調査を事前に予測できません。さらには、新しいタイプのアラートを随時受け入れる必要すらあります。メッセージバスは、イベントを処理可能なエージェントにプッシュすることでこうした変数に対応し、固定されたシナリオに縛られません。
特殊なケースが増えるにつれて「オーケストレーター」内のIf-Else分岐が肥大化している場合、それはメッセージバスへ移行し、分散メカニズムをより明確かつ拡張可能にする時期です。
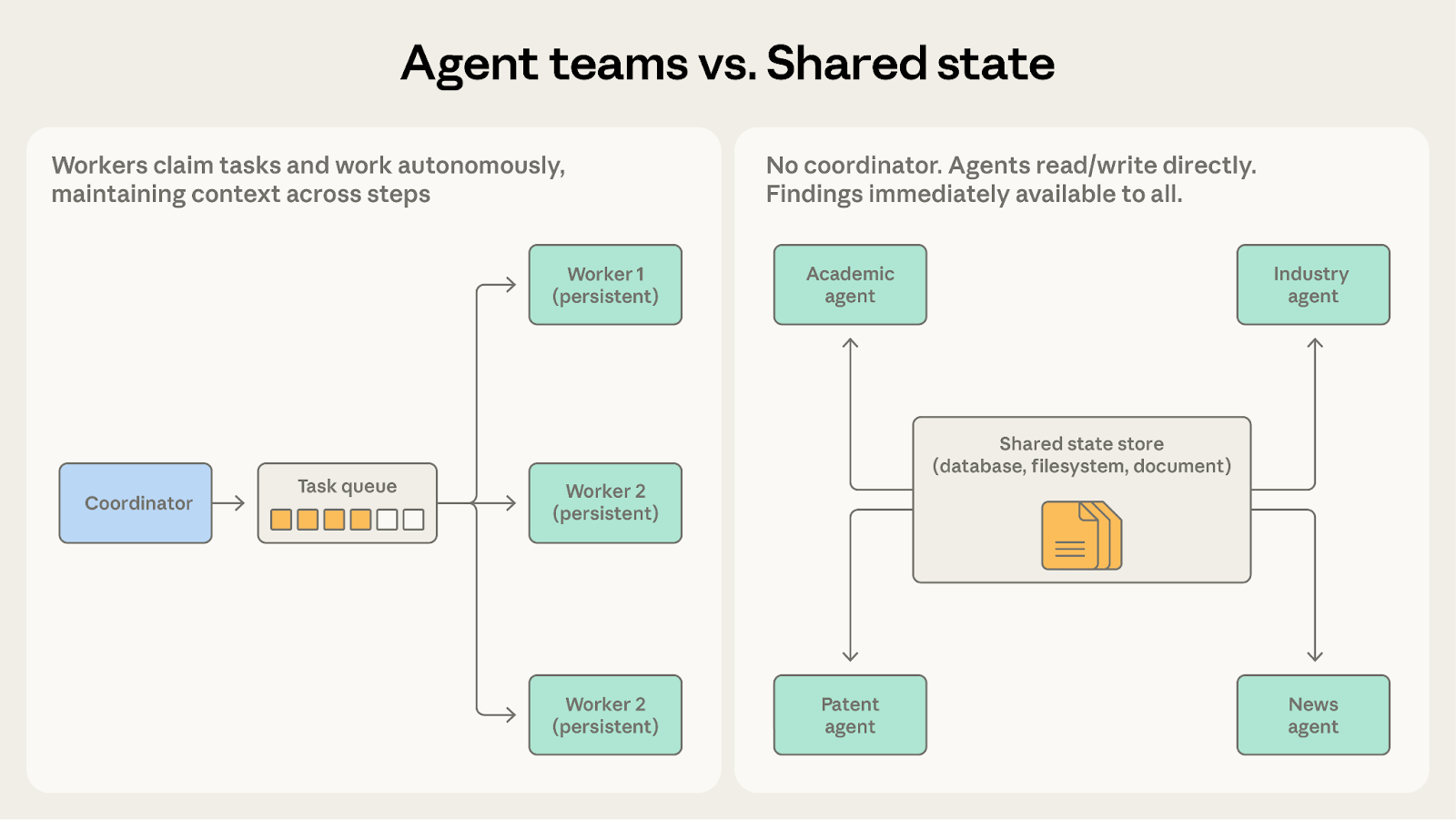
両方のパターンにおけるエージェントは自律的に作業を行います。どう選べばよいでしょうか? 次の問いに自問してください:エージェント同士は互いに答え合わせや参照を行う必要があるか?
エージェントチームの選択:各メンバーが自分の領域だけを守り、互いに干渉しない場合。コードリポジトリの移行では、各人が自分のサービスを担当し、最後に統合してマージすればよい。
共有状態の選択:これは高度な協調が必要なタスクであり、手がかりがリアルタイムで流れる必要がある場合。総合研究システムが非常に適している。論文を読むエージェントに新しい発見があれば、業界を分析するエージェントはすぐにそれを利用できる。
チームメンバーが単に作業完了時に結果をまとめ合うだけでなく、作業中に頻繁に情報交換を行う必要がある場合、すぐに共有状態パターンに変更すべきだ。これにより、コミュニケーションがはるかにスムーズになる。
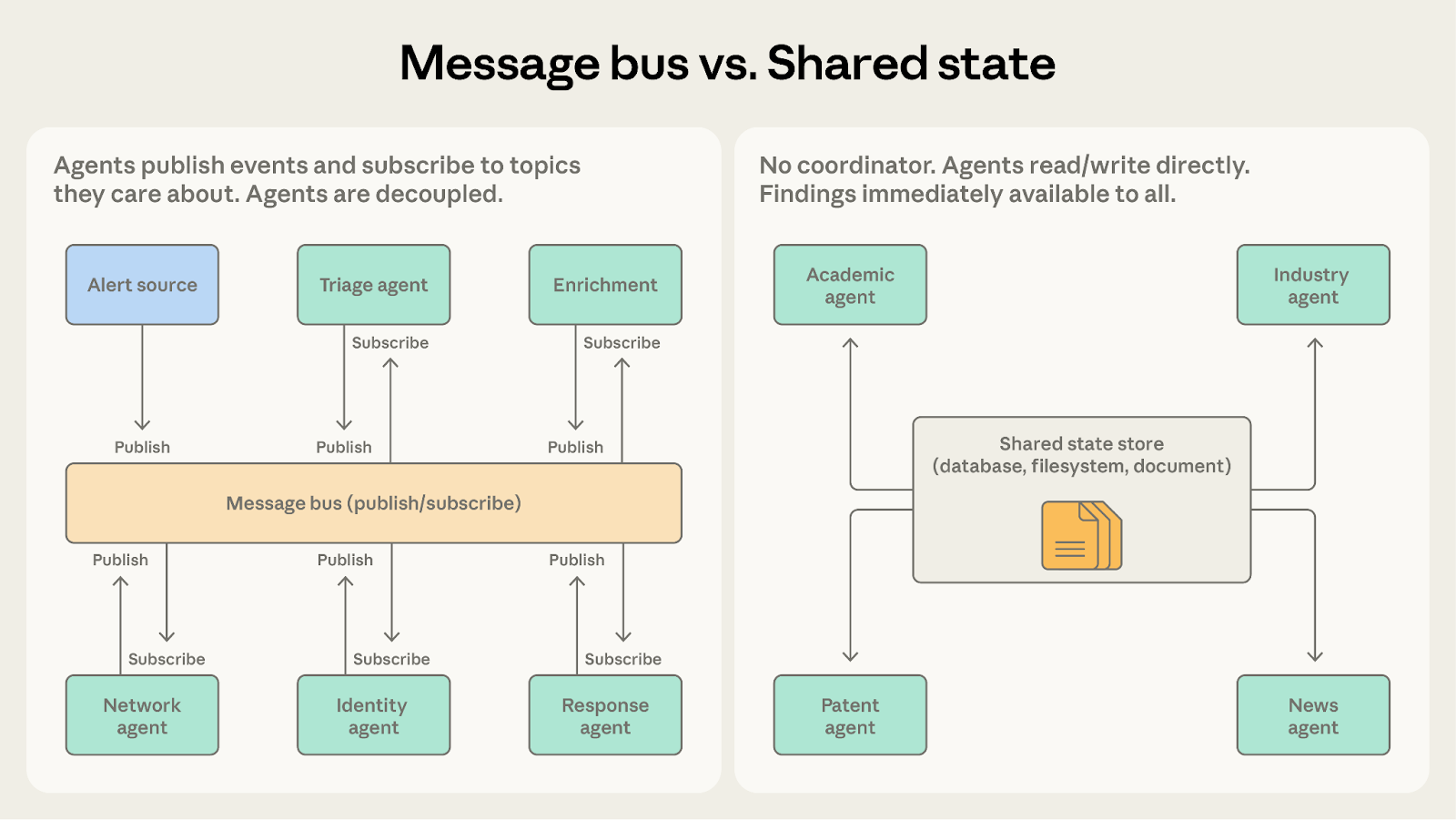
両方とも複雑なマルチエージェント協調を処理することに優れている。どう選ぶか?自分に問うてみよ:タスクはイベントを一つずつ解決するアセンブリラインのようなものか、それとも知識ベースをゆっくりと構築するためのものか?
メッセージバスの選択:エージェントがアセンブリライン上のイベントに反応する場合。セキュリティシステムは連鎖的に動作し、前のステップが処理されて初めて次のステップがトリガーされる。このパターンは「正確なタスク割り当て」に非常に強い。
共有状態の選択:エージェントが蓄積された手がかりに基づいて継続的に深く掘り下げる場合。総合研究システムは知識を絶えず集約している。エージェントたちは何度もホワイトボードの前に戻り、他の人が何を見つけ出したかを確認し、自分の調査方向を調整する。
覚えておこう。メッセージバスには依然として「ルーター」が中心にあり、誰がタスクを引き受けるかを決めている。一方、共有状態は完全に分散型だ。「単一障害点」を排除することに非常に注力している場合、共有状態が最大の安心感をもたらす。
さらに、メッセージバスシステムにおいて、メンバーが情報を公開する主な目的が「他のアクションをトリガーすること」ではなく「情報の共有」である場合、それは選択ミスだ。そのような作業には共有状態パターンの方が適している。

実際のビジネス環境(プロダクション環境)では、これらのパターンを混在させて使用することが多い。一般的な組み合わせとしては、大まかなワークフローに「オーケストレーター - サブエージェント」を使用し、多くの協調が必要なサブタスク内で「共有状態」を適用するケースがある。また、一部のシステムではイベントの配布にメッセージバスを使用し、各イベント処理の末端にエージェントチームを接続する。これらのパターンは本質的にレゴブロックのようなもので、互いに排他的ではない。
以下の表は、各種パターンの適用シーンをまとめたものである:
出力の品質を重視し、明確な評価基準がある場合
ジェネレーター - ベリファイア (Generator-Verifier)
タスクの分解が明確で、サブタスクの境界がはっきりしており、短く迅速な場合
オーケストレーター - サブエージェント (Orchestrator-Subagent)
作業量が並列化可能で、サブタスクが独立しており、長時間実行が必要な場合
エージェントチーム (Agent Teams)
イベント駆動型のパイプラインであり、エージェントエコシステムが成長し続けている場合
メッセージバス (Message Bus)
協調型研究であり、エージェント間で新しい発見を頻繁に共有する必要がある場合
共有状態 (Shared State)
単一障害点によるシステム停止が絶対に許されない場合
共有状態 (Shared State)
大多数の初期段階にあるニーズに対して、「オーケストレーター - サブエージェント (Orchestrator-subagent)」から始めることを強く推奨する。これは極めて低い調整コストで、最も広範な問題を解決できる。まずこれを実行してシステムがどこで瓶颈を起こすかを観察し、その後、具体的な課題に応じて他のパターンに進化させる。
次の記事では、プロダクションレベルの実例を交え、各パターンの具体的な実装方法について深く掘り下げる。もし「なぜマルチエージェントシステムに投資する価値があるのか、いつ使うべきか」を振り返りたい場合は、『マルチエージェントシステムの構築:いつ、どのようにそれらを使用するか』を参照されたい。
本記事はCara Phillipsによって執筆され、Eugene Yang、Jiri De Jonghe、Samuel Weller、およびErik Schluntzが寄稿している。
原文を表示
在之前的一篇文章中,我们探讨了多智能体 (Multi-agent) 系统何时能发挥最大价值,以及什么时候只用单个智能体 (Agent) 其实更好。这篇文章则是为那些已经决定采用“多智能体”路线的团队准备的:面对手头的问题,到底该选哪种协作模式?
我们常常看到,有些团队在挑选模式时,只顾着选听起来“高大上”的,却忽略了到底适不适合手头的问题。我们的建议是:从最简单的、能跑通的模式开始,观察它在哪里会遇到瓶颈,然后再逐步升级。 今天这篇文章,我们就来拆解五种常见模式的运作原理和局限性:
生成 - 验证者 (Generator-verifier):适用于看重输出质量、且有明确评估标准的场景。
调度 - 子智能体 (Orchestrator-subagent):适用于任务拆解清晰、子任务边界分明的场景。
智能体团队 (Agent teams):适用于可以并行处理、互不干扰且需要长时间运行的子任务。
消息总线 (Message bus):适用于事件驱动的流水线作业,以及系统还在不断扩展新智能体的场景。
共享状态 (Shared-state):适用于需要高度协作、智能体之间需要互相参考别人发现的场景。
模式一:生成 - 验证者 (Generator-verifier)
这是最简单的多智能体模式,也是目前落地应用最广泛的模式之一。在我们之前的文章中,曾将其称为“验证子智能体模式”,这里我们使用更宽泛的“生成 - 验证者”来称呼它,因为这里的“生成者”不一定非得是个指挥全局的调度者。
生成者 (Generator) 接到一个任务后,会先给出一版初步结果,然后把它传给验证者 (Verifier) 去评估。验证者会检查这个结果是否符合规定的标准。如果符合,就盖章通过;如果不符合,验证者会把具体的修改意见(反馈)打回去。生成者拿着这些反馈再重新修改一版。这个“修改 - 审核”的循环会一直进行,直到验证者满意,或者达到了系统设定的最大修改次数限制。
想象一个用来回复客户工单的自动邮件系统。生成者利用产品文档和工单详情写出一封初稿。验证者则充当“质检员”:核对知识库看事实准不准、检查语气符不符合品牌要求、确认客户提到的每个问题是不是都回答了。如果检查没通过,验证者会把具体问题甩回给生成者,比如指出“把某个功能错误地归到了低配版里”或者“漏答了某个问题”。
当输出质量至关重要,而且你能把“什么是好结果”用明确的标准写出来时,用这个模式准没错。它非常适合代码生成(一个智能体写代码,另一个写测试并运行)、事实核查、按固定评分表打分、合规性审查,以及任何“一次错误的代价远大于多跑一圈修改流程”的领域。
这个系统的下限,完全取决于验证者的审核标准有多细。(注:如果你只告诉验证者“帮我看看这东西好不好”,却不给它具体的条条框框,它往往就会变成一个闭着眼睛盖“合格”章的橡皮图章。) 团队在应用这个模式时最常犯的错误,就是建好了循环机制,却没定义清楚“验证”到底意味着什么,这只会营造出一种“我们在做质量控制”的虚假繁荣。
另外,这种模式假设“生成”和“验证”是两种可以拆开的技能。但如果你要评估的是一个绝妙的创意,评估它的难度可能和想出它一样高,这时候验证者往往就不太靠谱了。
最后,这种循环很容易陷入“死胡同”。如果生成者就是无法解决验证者提出的问题,系统就会在两者之间来回踢皮球,永远无法收敛。因此,必须设置一个最大循环次数限制,并准备好后备方案(比如转交人工,或者带着提示说明返回当前最好的一版),防止它变成死循环。
模式二:调度 - 子智能体 (Orchestrator-subagent)
这个模式的核心在于“层级制”。有一个像“团队主管”一样的核心智能体负责规划工作、分发任务,并最终汇总结果;而各个子智能体 (Subagents) 则负责处理具体的分摊工作,做完后向上级汇报。
主导的调度者 (Orchestrator) 收到任务后,会先思考该怎么动手。它可以自己解决一部分,把剩下的指派给不同的子智能体。等小弟们把活干完、交上结果后,调度者再把这些碎片拼成一份完整的最终答案。
Claude Code 用的就是这种模式。主智能体自己负责写代码、改文件、跑命令,但当它需要在庞大的代码库里大范围搜索,或者需要调查一些独立问题时,它就会在后台派发给子智能体。这样主线工作不会停,搜索结果也会源源不断地送回来。每个子智能体都在自己独立的上下文窗口 (Context window) 里工作,只返回精炼后的调查结果。(注:这就好比老板的脑子(上下文)只需专注于大方向,而查资料等繁杂信息都在员工的大脑里消化,从而保证老板的思路不被琐事塞满。)
想想一个自动化的代码审查 (Code review) 系统。当有人提交了新代码,系统需要检查安全漏洞、验证测试覆盖率、评估代码风格、并检查架构一致性。这几个检查方向互不干涉,需要的背景知识也不同,并且都能产出清晰的报告。此时,调度者就可以把任务分发给几个专门的子智能体,等它们查完,再把报告融合成一份全面的审查意见。
当任务拆解非常明确,且子任务之间互相没啥依赖时,这个模式非常得心应手。调度者能时刻保持对大目标的掌控,而子智能体则心无旁骛地干好自己的细分工作。
调度者很容易变成信息的“瓶颈”。一旦某个子智能体发现了可能影响另一个子智能体工作的信息,这个情报必须先上报给调度者,再由调度者下发。比如,查安全的智能体发现了一个认证漏洞,这个漏洞恰好会影响查架构的智能体的分析。如果信息在上下级之间倒手太多次,关键细节很容易就在被一次次“总结汇报”的过程中弄丢了。
另外,如果不做专门的并行处理,子智能体会按顺序一个个干活。这意味着你要花着多智能体处理数据(Token)的钱,却享受不到“人多干活快”的速度优势。
模式三:智能体团队 (Agent teams)
当一份大工作可以被拆成多个并行的子任务,而且这些任务需要花很长时间独立完成时,“组长派活”的层级制就会显得太死板了。
一个协调者 (Coordinator) 会创建出多个作为独立进程运行的团队成员 (Teammates)。这些成员会从一个共享的任务队列里自己“抢单”,接单后自主完成多步操作,干完再举手示意。
它和“调度 - 子智能体”最大的区别在于成员的持久性。调度者通常是为了一件小事临时叫出一个子智能体,干完就解散。但在团队模式里,成员们是长期存在的,它们在接手一个个任务的过程中,会不断积累领域知识和上下文,越干越熟练。协调者只管派活和收作业,并不会在每次任务结束后把它们的记忆清空。
假设你要把一个庞大的代码库从一个框架迁移到另一个框架。每个团队成员都可以独立负责迁移其中一个服务模块,自己处理依赖项、改代码、修测试 bug、做验证。协调者把一个个模块分给成员,成员们自主完成这一整套迁移流程。最后协调者把所有迁移好的模块攒在一起,跑一遍系统级的集成测试。
当子任务相互独立,且需要跨越多步、长时间处理时,用这个模式最爽。因为每个成员都在不断积累自己那个小领域的经验,而不是每次接活都像个失忆的新手。
“独立”是这个模式的生命线,也是软肋。不像调度模式里有个组长帮忙传话,团队成员们都是闷头干活的,彼此之间很难共享中间进度。如果 A 的工作会影响到 B,他们俩却毫不知情,最后交上来的结果可能就打架了。
进度管理也是个让人头疼的问题。因为大家干活的时间长短不一,有的两分钟搞定,有的要弄二十分钟,协调者必须得有耐心处理这种“参差不齐”的部分完成状态。
如果大家还要抢夺公共资源,问题就更大了。当多个成员同时在改同一个代码库、数据库或文件时,很容易发生两个人改同一个文件或者做出互相冲突的修改。这就要求我们在任务分配时划好“楚河汉界”,并准备好冲突解决机制。
模式四:消息总线 (Message bus)
随着智能体数量增加,大家互动的方式越来越复杂,直接让他们面对面交流会变成一场灾难。这时候,消息总线 (Message bus) 就登场了:它提供了一个共享的通讯大厅,让智能体们通过“发布”和“订阅”来协调工作。
智能体只靠两个基本动作交流:发布 (Publish) 和订阅 (Subscribe)。智能体会订阅自己关心的“话题”,一个路由器 (Router) 会把相关的消息精准推给它们。(注:这就好比在一个大型公司群里,有人在群里发需求,相关部门的人看到了自动领走,你根本不需要知道具体是谁接了单。) 如果未来有了新功能的智能体加入,它们只要订阅相应的话题就能直接上岗,完全不需要改动现有的网络线路。
自动化安全运营系统是这个模式的完美舞台。各种渠道的警报像雪片一样飞来,一个“分诊智能体”负责评估严重程度和类型,把高危的网络警报推给“网络调查智能体”,把账号相关警报推给“身份分析智能体”。调查智能体在干活时,可能还会发布一条“需要更多背景”的需求,专门负责收集情报的智能体看到后就会去帮忙。最后,所有的发现都会流向“响应协调智能体”,由它来拍板怎么处理。
这种流水线简直就是为消息总线量身定制的:事件从上一个环节顺畅地流向下个环节;随着新型威胁出现,团队可以随时往里塞新的安保智能体;各个智能体的开发和部署也可以互不干扰。
当系统是一个由事件驱动的流水线(工作流是由突发事件决定的,而不是定死的顺序),而且你的智能体团队未来很可能会继续扩编时,选它。
这种事件驱动的通讯过于灵活,导致排查问题非常困难。当一个警报像多米诺骨牌一样触发了五个智能体的连锁反应时,想搞清楚中间到底发生了什么,你必须查阅非常仔细的日志记录并进行关联对比。这可比跟着“调度者”一步步按顺序查 bug 痛苦多了。
路由器的分发准确性也至关重要。如果路由器把消息分错了类,或者干脆漏发了,系统就会陷入“静默崩溃”——它不报错,没死机,但就是什么也不干。基于大语言模型 (LLM) 的路由器虽然能在理解语义上更灵活,但也带来了 LLM 特有的失灵风险(比如理解偏差或幻觉)。
模式五:共享状态 (Shared state)
在前几种模式里,无论是调度者、协调者还是路由器,本质上都在充当信息流的“中间商”。而共享状态 (Shared state) 模式则彻底干掉了中间商,它让所有智能体共同面对一个持久化的存储区(比如数据库、文件系统或文档),大家可以直接从中读取信息、写入结果。
在这个模式下,没有所谓的“中心指挥官”。智能体们像在一个公共的大黑板前工作:他们看着黑板上有什么线索,拿走自己能处理的去干活,有了新发现再写回黑板上。通常,启动流程就是在黑板上写下一个大问题或放下一堆初始数据;当满足某个结束条件时,工作就停止——比如时间到了、大家很久没新发现了(收敛阈值),或者某个被专门指派的智能体站出来说“黑板上的答案已经足够好了”。
想象一个负责跨领域综合研究的系统。为了调查一个复杂问题,有的智能体负责翻学术论文,有的看行业报告,有的扒专利文件,还有的盯着新闻动态。每个人查到的东西都可能成为别人的关键线索。比如,看论文的智能体偶然发现了一位核心研究员,看行业报告的智能体立马就可以去深挖这家研究员背后的公司。
在共享状态下,所有的发现都直接上黑板。看行业的智能体立马就能看到看论文智能体的新发现,根本不用等协调者来回传话。大家互相踩着对方的肩膀往上爬,这块共享黑板也就渐渐变成了一个不断进化演进的知识库。
这种模式还有一个好处:消除了单点故障。即便某个智能体宕机了,其他人依然能对着黑板继续读写。但在调度模式或消息总线模式里,一旦指挥官或路由器罢工,整个系统就全瘫痪了。
失去了统一指挥,智能体很容易会重复造轮子,或者南辕北辙。比如两个智能体可能不约而同地去调查了同一条线索。系统的最终行为是大家碰撞出来的,而不是从上往下设计好的,这也让结果变得难以预测。
最致命的故障模式是陷入 “反应式死循环” (Reactive loops)。比如,智能体 A 写下了一个发现,智能体 B 看到后写了一句补充,A 看到补充后又回了一句…… 整个系统就像两个机器人在无限套娃聊天,疯狂燃烧昂贵的算力 (Token) 却无法得出结论。针对重复工作和并发写入,工程师们有成熟的解决办法(比如加锁、版本控制、分区);但这这种“无限套娃”是一个行为模式问题,你必须在系统设计之初就设定好“一票否决”的终止条件:比如只给固定的时间预算,或者一旦连续几轮都没有新发现就强制停止,或者指派一个“裁判”智能体随时判定答案是否已经圆满。(注:如果忽略了停止机制的设计,系统要么会无限循环到破产,要么会因为某个智能体的大脑(上下文窗口)被塞满而死机。)
选哪种模式,取决于你对系统的几个核心结构问题的判断。在我们之前的文章中,我们提倡围绕“上下文”来拆解工作(Context-centric decomposition),即按照每个智能体“需要知道哪些背景信息”来分工,而不是按“它干什么类型的活”来分工。这个原则在这里同样适用。这五种模式最大的区别,就在于它们如何划分上下文的边界,以及如何管理信息的流动。
调度 - 子智能体 vs. 智能体团队
两者都有一个“分配工作”的协调者。怎么选?问自己:干活的智能体需要长时间保留记忆(上下文)吗?
选调度 - 子智能体:如果子任务短平快,目标集中,且输出明确。代码审查系统就适用,因为每次检查都是单次的:跑分析、出报告,直接交差。子智能体不需要在多次任务间保留记忆。
选智能体团队:如果子任务需要跨越多步、长时间处理才能出成效。代码库迁移适用这个,因为成员们需要长期对付同一个服务模块,慢慢摸透它的依赖关系、测试规律和部署配置。这种积累下来的背景知识,是“用完即走”的调度模式给不了的。
当子智能体需要在多次被唤醒之间记住以前的状态时,智能体团队是更好的选择。
调度 - 子智能体 vs. 消息总线
两者都能处理多步工作流。怎么选?问自己:你的工作流程是可以提前预测的吗?
选调度 - 子智能体:如果步骤早就定好了。就像代码审查系统,永远是那三板斧:接收提交请求、跑检查、汇总结果。
选消息总线:如果工作流是由突发事件触发的,而且随时可能改变方向。安全运营系统永远猜不到下一秒会来什么警报,或者需要开展什么调查。它甚至需要随时容纳新类型的警报。消息总线通过把事件推给能干活的智能体来适应这种变数,而不是死守着预设的剧本。
如果为了应付越来越多的特殊情况,你的“调度者”脑子里的“If-Else”判断语句越堆越多,那么是时候换成消息总线,让分发机制变得更加清晰和容易扩展了。
两者里的智能体都是自主干活的。怎么选?问自己:智能体之间需要互相对答案、抄作业吗?
选智能体团队:如果大家各人自扫门前雪,互不干涉。代码库迁移中,每个人负责自己的服务,最后统一合并就行。
选共享状态:如果这是一场需要高度协作的任务,且线索需要实时流转。综合研究系统就很合适,看论文的智能体只要有新发现,看行业的智能体立马就能用上。
一旦团队成员们不再仅仅是交差时汇总结果,而是需要在干活途中频繁互通有无,那赶紧换成共享状态模式吧,它会让交流顺畅得多。
两者都擅长处理复杂的多智能体协作。怎么选?问自己:任务是像流水线一样一个个解决事件,还是为了慢慢攒出一个知识库?
选消息总线:如果智能体是对流水线上的事件做出反应。安全系统就是一环扣一环,处理完上一步才触发下一步。这个模式对“精准派活”非常在行。
选共享状态:如果智能体是要基于日积月累的线索持续深入。综合研究系统是在不断汇聚知识。智能体们会反复回到黑板前,看看别人发现了什么,然后调整自己的调查方向。
记住,消息总线里依然有个“路由器”在中心掌控全局决定谁接活。而共享状态是彻头彻尾的去中心化。如果你非常在意消除“单点故障”,共享状态能给你最大的安全感。
另外,如果你的消息总线系统里,大家发布消息主要只是为了“共享情报”而不是为了“触发别人的动作”,那说明你选错了,这活儿更适合共享状态模式。
在真实的商业环境(生产环境)中,我们往往会混搭使用这些模式。一种常见的组合是:大方向的工作流用调度 - 子智能体,而在某个需要大量协作的子任务里套用共享状态。还有的系统会用消息总线来分发事件,而在处理每类事件的末端挂上一个个智能体团队。这些模式本质上是积木,并非水火不容。
下表总结了各种模式的适用场景:
看重输出质量,且有明确的评估标准
生成 - 验证者 (Generator-Verifier)
任务拆解清晰,子任务边界分明且短平快
调度 - 子智能体 (Orchestrator-Subagent)
工作量可并行,且子任务独立、需要长时间运行
智能体团队 (Agent Teams)
事件驱动的流水线,智能体生态系统还在不断增长
消息总线 (Message Bus)
协作式研究,智能体之间需要频繁共享新发现
共享状态 (Shared State)
绝对不允许出现单点故障导致系统瘫痪
共享状态 (Shared State)
对于绝大多数刚刚起步的需求,我们强烈建议从“调度 - 子智能体 (Orchestrator-subagent)”开始。 它能以极低的协调成本搞定最广泛的问题。先用它跑起来,观察系统在哪里卡了脖子,然后再根据具体痛点进化到其他模式。
在接下来的文章中,我们将结合生产级别的实际案例,深入探讨每种模式的具体落地做法。如果你想回顾“我们到底什么时候值得投入多智能体系统”,请参阅:《构建多智能体系统:何时及如何使用它们》。
本文由 Cara Phillips 撰写,Eugene Yang, Jiri De Jonghe, Samuel Weller 以及 Erik Schluntz 亦有贡献。
関連記事
バックグラウンドでのサブエージェントの実行
Deep Agentsは、同期サブエージェントがスーパーバイザーをブロックする問題を解決し、非同期サブエージェントをサポート。これにより、バックグラウンドタスクをリアルタイムで起動・制御・中止可能になった。
Vercel Sandbox を活用し、Conductor が並列コーディングエージェントをクラウドへ移行した方法
Conductor は Vercel Sandbox を利用して、Claude Code や Codex など複数の並列コーディングエージェントをクラウド上で実行可能にし、エンジニアリングチームが直感的に管理・レビューできる GUI を提供している。
Amazon Bedrock AgentCore を用いた AWS 上の高スケーラブルなサーバーレス LangGraph マルチエージェントシステムの構築
AWS は、生成 AI の本番環境運用における遅延や拡張性などの課題に対処するため、Amazon Bedrock AgentCore と LangGraph を組み合わせた高スケーラブルなサーバーレス型マルチエージェントシステム構築の手法を公開した。