Strands + Amazon Bedrock AgentCore + Athenaで簡単データ分析システムを構築する
ABEJA は Strands と Amazon Bedrock AgentCore を活用し、非エンジニアが自然言語で安全にデータ分析を行える基盤を構築する実証事例を発表した。
キーポイント
本番 DB 分離による安全性の確保
Aurora のスナップショットを S3 にエクスポートし、Athena で分析することで、本番データベースへの直接アクセスや負荷影響を完全に排除している。
AgentCore と Strands の連携アーキテクチャ
Strands Agent が自然言語の意図を解釈し、Bedrock AgentCore Gateway を経由して Lambda で SQL を検証・実行する安全なフローを実現した。
コスト効率と管理性の両立
Athena と Glue の組み合わせで低コストな分析基盤を構築しつつ、AgentCore を用いてツールの呼び出しや IAM ガードレールを統制可能にした。
MCPプロトコルとSigV4署名による安全な連携
ローカルのStrands AgentからAgentCore Gatewayへ、MCP JSON-RPC形式でリクエストを送信し、SigV4署名(サービス名:bedrock-agentcore)を用いて認証・通信を行う仕組みです。
多層的な防御壁によるSQL実行の安全確保
危険キーワードのブロックチェックに加え、Lambda側でユーザー固有のcompany_idをサブクエリに強制付与し、Athena WorkGroupでのスキャン量制限を設定することで、不正操作や高額請求を防ぎます。
プロンプトによる振る舞い制御と簡易実装
Pythonロジックの変更を最小限に抑えつつ、システムプロンプトで「SELECT文のみ使用」「company_idの自動付与」などのルールを定義し、AIのエージェントとしての賢さを調整しています。
Athena クエリの非同期実行アーキテクチャ
長時間かかるクエリ処理を「開始」と「結果取得」の2フェーズに分割し、DynamoDB で状態管理することで、Lambda のステートレス化と安全なポーリングを実現しています。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI の導入において頻発する「本番 DB への直接アクセスリスク」や「SQL 作成の難易度」という実務課題に対し、AWS エコシステムを活用した具体的な解決策を提供しています。特に AgentCore を用いた統制と、読み取り専用環境の構築は、データドリブンな意思決定を求める企業にとって即座に適用可能な重要な知見となります。
編集コメント
生成 AI の実装において「安全な沙箱環境」の重要性を再認識させる、非常に質の高い技術記事です。特に AgentCore を用いたガバナンス設計は、今後多くの企業が直面する課題に対する模範となるでしょう。

こんにちは。 株式会社ABEJAのシステム開発部でエンジニアをしている吉田です。 こちらはABEJAアドベントカレンダー2025の24日目の記事です。
ABEJAで仕事をしていると、「エンジニアではないけれど、データベースにあるデータを分析したい」という相談を受けることがあります。
ABEJAでは、比較的SQLを書ける非エンジニアも多いのですが、それでも
JOIN や集計を含むSQLを書くハードル
本番DBへの直接アクセスによるセキュリティ・誤操作リスク
分析専用基盤をシステムごとに用意する工数
といった問題があり、「誰でも・安全に・気軽に分析できる」環境を用意するのは簡単ではありません。
そこで今回、「非エンジニアでも、自然言語で安全にデータベース分析ができる仕組み」をテーマに、Strands + Amazon Bedrock AgentCore + Athena を使った分析基盤を検証・構築してみました。
課題と実現したいこと データ活用のボトルネック
今回構築したシステムの概要 処理のフロー
アーキテクチャのポイント 1. 直接DBには触れさせない
- Athena + Glueのコスパ
- AgentCoreによる統制
Strands Agentの実装 1. ツールの定義
セキュリティ設計 ① 書き込み不可
Terraformと非同期処理 AgentCore GatewayのTerraform化
Athenaクエリの状態管理について
ビジネスの現場ではデータドリブンな意思決定が求められますが、データベースに直接触れるにはいくつもの壁があります。
SQLスキルの壁: 生成AIの登場でSQL生成は容易になりましたが、複雑なスキーマを理解し、正しいクエリを書くのは依然として難易度が高いです。
DBアクセスのリスク: 負荷問題:重い分析クエリで本番DBのパフォーマンスが劣化する
データ破壊: 誤って UPDATE / DELETE を実行してしまうリスク
情報漏洩:本来見せるべきでないデータまで参照できてしまう可能性
今回目指したのは、以下のような体験です。
インターフェースは自然言語のみ: 「先月のユーザー登録数を教えて」と聞くだけ
システム側で安全を担保: ユーザーが何をどう聞いても、データが壊れることはなく、見てはいけないデータは見えない。
このために、AWSの Amazon Bedrock AgentCore を中心としたアーキテクチャを設計しました。 今回はAgentCore Runtimeへのエージェントのデプロイまでは行わず、AgentCore Gateway + Lambda を使い、ローカルで実行するStrands Agentからツール呼び出しを行う構成にしています。

安全なデータレイクに対するクエリ実行
という、いわゆる LLM × 構造化データ分析基盤 です。
安全性を最優先し、本番DB(Aurora)には一切直接接続しません。 AuroraのスナップショットをS3へエクスポートし、Athena経由で参照する構成としています。
Strands Agent が Bedrock(Claude Sonnet)で意図を解釈
データ取得が必要と判断した場合、AgentCore Gateway 経由でツールを呼び出し
Gatewayに紐づいた Lambda が SQL を検証
問題なければ Athena にクエリを実行
結果を自然言語に変換してユーザーへ返却
今回の構成では、以下のAWSサービスを組み合わせました。それぞれの選定理由を深掘りします。
AgentCore Gateway
LambdaのMCP化 エージェントが呼び出すツール(Lambda)をAWSリソースとして統制
AWSが開発したPythonコードベースで動作する軽量なエージェントフレームワーク。AgentCoreとの親和性が高い。
元データのソース(直接は触らせない)
AuroraスナップショットをParquet形式で保存するデータレイク
S3上のデータをAthenaで扱うためのスキーマ管理
サーバーレスで安全にSQL実行
SQLの検証・強制フィルタリングを行うセキュリティゲート
Amazon DynamoDB
Athenaクエリの非同期実行をサポートするため、クエリのジョブID・実行状態・結果パスなどを管理
- 直接DBには触れさせない
分析クエリを本番DBで実行させないことを最優先にしました。 Athena + S3構成にすることで、どれだけ重いクエリを投げてもAuroraに負荷はかかりません。
今回S3への出力はAuroraの機能である「S3へのスナップショットエクスポート」を利用しました。 これにより、データはS3上にParquetファイル(列指向フォーマット)として静的に配置されます。
- Athena + Glueのコスパ
Athenaは $5 / TB(スキャン量) の従量課金です。Parquet形式であれば、月数百円〜数千円程度で運用できます。
Redshift Serverlessと比べても、「たまにアドホック分析したい」用途には十分すぎるほど安価です。
- AgentCoreによる統制
AgentCoreを使うことで、
ツール呼び出しをAWS側で管理
IAMやLambdaを使ったガードレール設計
がしやすくなり、「AIが何をしているか分からない」状態を避けられます。
Strands Agentの実装
Strands Agentを使うことで、エージェントの思考プロセスやツール定義を非常にシンプルに実装できます。
まずは、AIが呼び出すためのツール(関数)を定義します。 @tool
tools.py from strands import tool @tool def execute_sql_query(sql: str, limit: int = 100) -> dict: """ SQLクエリを実行してデータを取得します(AgentCore Gateway経由)。 Args: sql: 実行するSQLクエリ(SELECT文のみ) limit: 取得する最大行数(デフォルト100、最大10000) Returns: dict: クエリ結果(カラム名とデータのリスト) """ # AgentCore Gateway経由でMCP呼び出し return _execute_sql_query_impl(sql=sql, limit=limit) @tool def get_table_schema(table_name: str) -> dict: """ 指定されたテーブルのスキーマ情報(カラム名と型)を取得します。 SQLを生成する前に必ずこのツールでカラム名を確認してください。 """ # ... @tool def get_column_info(table_name: Optional[str] = None) -> dict: """ テーブルのカラム情報を取得します。 """ # ...
実際の実装では、ローカルのStrands AgentからAgentCore GatewayにMCPプロトコルでリクエストを送信しています。 Gateway経由の呼び出しにはSigV4署名が必要で、サービス名は bedrock-agentcore
AgentCore Gateway呼び出しの概要 def _mcp_call(method: str, params: Optional[Dict] = None) -> Dict: """MCP JSON-RPC call to AgentCore Gateway /mcp""" payload = { "jsonrpc": "2.0", "id": f"{method}-{int(time.time()*1000)}", "method": method, } if params: payload["params"] = params # SigV4署名(サービス名: bedrock-agentcore) headers = _sigv4_headers("POST", GATEWAY_URL, json.dumps(payload)) resp = requests.post(GATEWAY_URL, json=payload, headers=headers) return resp.json()
次に、システムプロンプトとツールを渡してエージェントを初期化します。 ここで重要なのは、AIにデータベースの構造と制約を正しく理解させることです。
agent.py from strands import Agent from strands.models import BedrockModel # システムプロンプトで「専門家」としての振る舞いとDB構造を定義 SYSTEM_PROMPT = """ あなたはデータ分析の専門家です。 ユーザーの自然言語での質問をSQLクエリに変換し、データベースから情報を取得して回答します。 ## SQL作成のルール 1. 必ず execute_sql_query ツールを使用すること 2. 常に SELECT 文のみを使用すること 3. ユーザーの会社ID (company_id) はLambda側で自動付与されるため、WHERE句に含める必要はありません """ def create_agent(): model = BedrockModel( model_id="お好きなモデルを利用", region_name="ap-northeast-1" ) agent = Agent( model=model, system_prompt=SYSTEM_PROMPT, tools=[execute_sql_query, get_table_schema, list_available_tables] ) return agent
このように、コード自体は非常にシンプルです。 「どのテーブルが使えるか」「どうやってクエリを書くべきか」といった知識はプロンプトに持たせることで、Pythonのロジックを変更することなくエージェントの賢さを調整できます。
「AIが勝手に変なSQLを実行したらどうするの?」という懸念に対して、Lambda関数内で多層的な防御壁を実装しました。
まず、AthenaがアクセスするS3バケットに対して、書き込み権限を持たせません。 さらにLambdaのコードレベルでも防御します。
Lambda内でのチェックロジック(イメージ) dangerous_keywords = ['DROP', 'DELETE', 'INSERT', 'UPDATE', 'ALTER', 'TRUNCATE', 'GRANT'] for keyword in dangerous_keywords: # SQL内に危険なキーワードが含まれていないかチェック if re.search(r'\b' + keyword + r'\b', sql_upper): raise ValueError(f"Dangerous keyword '{keyword}' is not allowed")
これにより、万が一AIが「データを全消去して」という命令をSQLに変換してしまっても、実行前にブロックされます。
今回はデモ用にマルチテナントが入っているデータベースを想定して実装しました。 ユーザーの所属する company_id
Before (AIが生成したSQL)
SELECT * FROM users
After (Lambdaが書き換えたSQL)
SELECT * FROM ( SELECT * FROM users ) WHERE company_id = 123 -- ユーザーのcompany_idを強制付与
このように、サブクエリでラップして外側から WHERE
「全件取得して」と言われた場合に数千万件のデータを返そうとすると、タイムアウトやメモリ溢れの原因になります。 また、Athenaはスキャン量で課金されるため、予期せぬ高額請求も防ぐ必要があります。
LIMIT句の強制: SQLに LIMIT
WorkGroup制限: AthenaのWorkGroup機能で、1クエリあたりのデータスキャン量の上限(例: 10GB)を設定し、それを超えるクエリは即座にキャンセルさせます。
Terraformと非同期処理
AgentCore GatewayのTerraform化
AWS Provider v6.17.0以降で、AgentCore Gatewayのリソースが追加されました。 今回はこれを利用してAgentCore GatewayとGateway TargetをTerraformでデプロイしています。
aws_bedrockagentcore_gateway
aws_bedrockagentcore_gateway_target
modules/ ├── agentcore/ # AgentCore Gateway / Gateway Target ├── athena/ # Athena WorkGroup設定 ├── glue/ # CrawlerとCatalog Database ├── lambda/ # クエリ実行用関数 └── s3/ # データレイク用バケット
Athenaクエリの状態管理について
Athenaへのクエリ実行は数秒〜数十秒かかることがあり、同期的に処理するとクライアント側のタイムアウトや再試行の扱いが難しくなります。 そのため本構成では、処理を 「開始」と「結果取得」の2フェーズ に分割しました。
このように、Athenaクエリの状態をDynamoDBで管理することで、
Lambdaをステートレスに保てる
再試行や複数リクエストからの参照に強い
Agent側で安全にポーリング処理を実装できる
Strands Agent側ではこのポーリングロジックを実装し、長時間かかる集計クエリでもタイムアウトせずに結果を受け取れるようにしています。
なお、今回のデモではデータ量が少なく、かつ LIMIT を付与しているため実際にはほとんど待ち時間は発生しておらず、やや冗長な構成ではありますが、実運用を見据えた際の一般的なAthena非同期実行パターンとしてこの形を採用しました。
では、実際の動作イメージを見てみましょう。今回はデモ用に用意したチャットシステムのDBで分析してみてます。
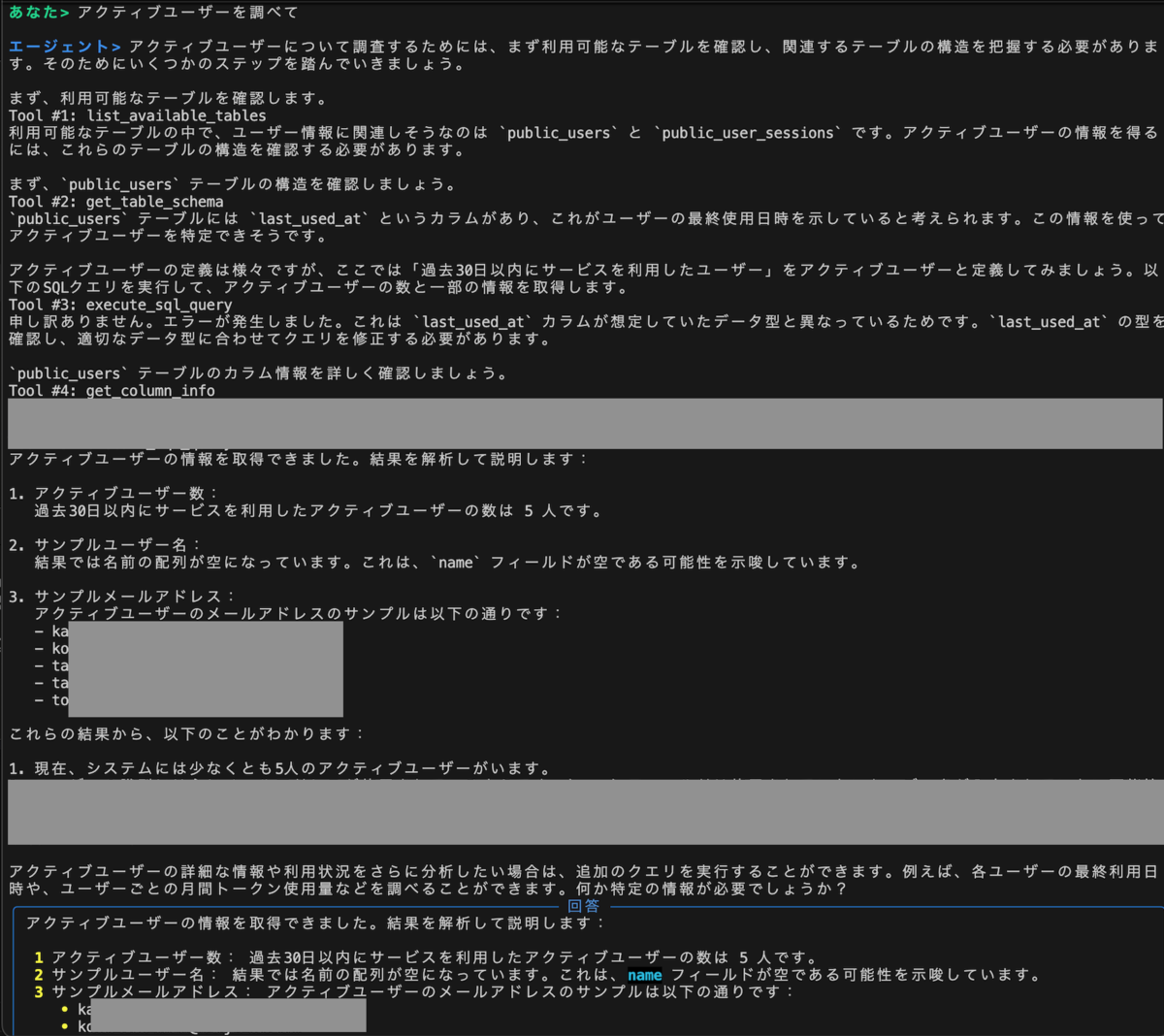 アクティブユーザーの検索
アクティブユーザーの検索
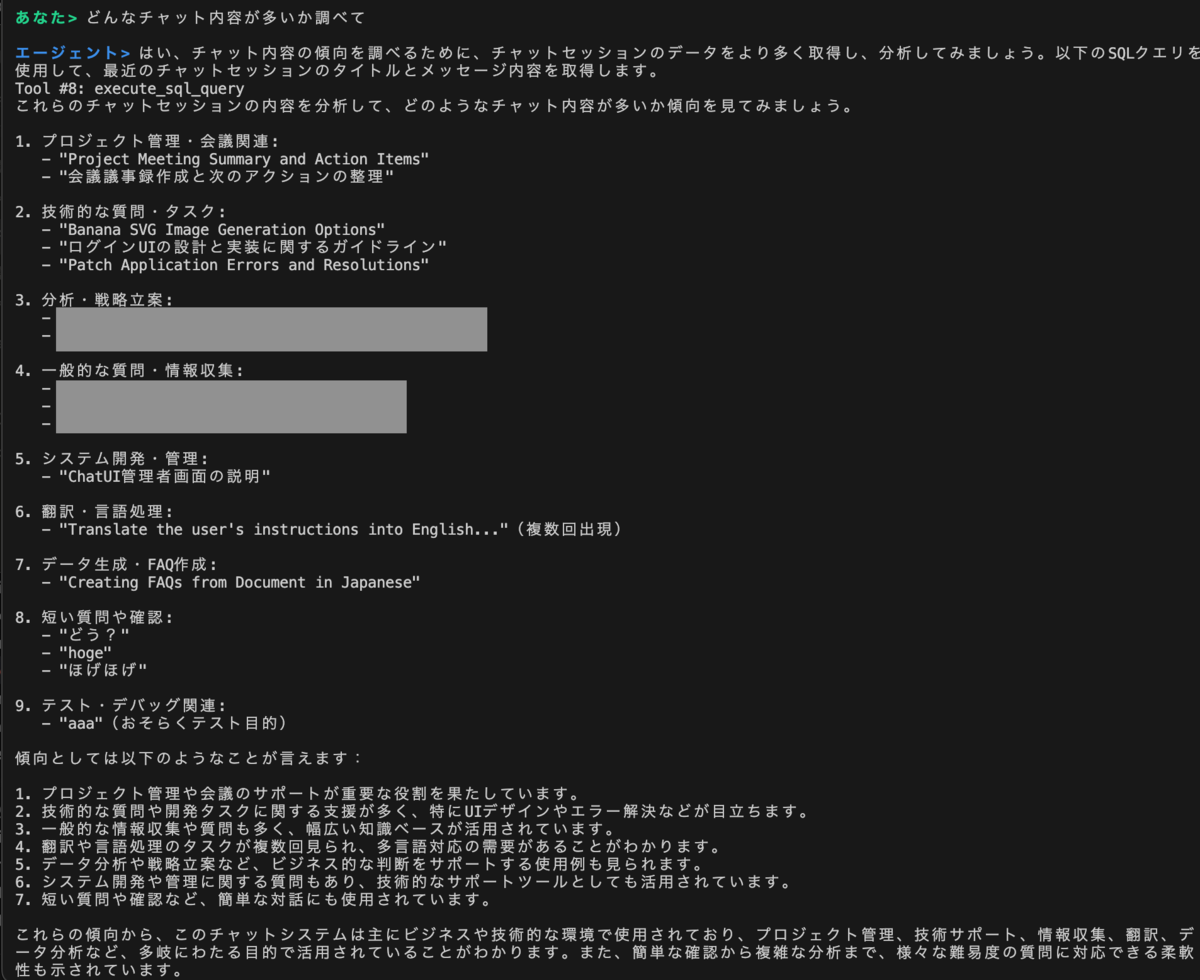 よくされているチャットの分析
よくされているチャットの分析
このように、ユーザーはテーブル名やカラム名を意識することなく、知りたい情報を得ることに集中できます。 裏側でのテーブル識別や company_id
なお今回は検証フェーズという位置付けのため、 AgentCore Runtime上でエージェントを常駐実行するところまでは踏み込めていません。
本検証では、AgentCore GatewayにLambdaを登録し、ローカルで実行しているStrands Agentからツール呼び出しを行う構成を採用しましたが、自然言語でのデータ分析、セキュリティ制御、Athenaを用いた安全なクエリ実行といった、本質的な設計要素については十分に検証できたと感じています。
今後、実運用を見据える場合には、
Strands AgentをAgentCore Runtime上で動かす構成への移行
認証・認可を含めたマルチユーザー対応
フロントエンドから直接利用できるUIの整備
などを検討していきたいと考えています。
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
careers.abejainc.com
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
トランスフォーメーション領域:ソフトウェアエンジニア
トランスフォーメーション領域:ソフトウェアエンジニア(リードクラス)
原文を表示
こんにちは。 株式会社ABEJAのシステム開発部でエンジニアをしている吉田です。 こちらはABEJAアドベントカレンダー2025の24日目の記事です。
ABEJAで仕事をしていると、「エンジニアではないけれど、データベースにあるデータを分析したい」という相談を受けることがあります。
ABEJAでは、比較的SQLを書ける非エンジニアも多いのですが、それでも
JOIN や集計を含むSQLを書くハードル
本番DBへの直接アクセスによるセキュリティ・誤操作リスク
分析専用基盤をシステムごとに用意する工数
といった問題があり、「誰でも・安全に・気軽に分析できる」環境を用意するのは簡単ではありません。
そこで今回、「非エンジニアでも、自然言語で安全にデータベース分析ができる仕組み」をテーマに、Strands + Amazon Bedrock AgentCore + Athena を使った分析基盤を検証・構築してみました。
課題と実現したいこと データ活用のボトルネック
今回構築したシステムの概要 処理のフロー
アーキテクチャのポイント 1. 直接DBには触れさせない
- Athena + Glueのコスパ
- AgentCoreによる統制
Strands Agentの実装 1. ツールの定義
セキュリティ設計 ① 書き込み不可
Terraformと非同期処理 AgentCore GatewayのTerraform化
Athenaクエリの状態管理について
ビジネスの現場ではデータドリブンな意思決定が求められますが、データベースに直接触れるにはいくつもの壁があります。
SQLスキルの壁: 生成AIの登場でSQL生成は容易になりましたが、複雑なスキーマを理解し、正しいクエリを書くのは依然として難易度が高いです。
DBアクセスのリスク: 負荷問題:重い分析クエリで本番DBのパフォーマンスが劣化する
データ破壊: 誤って UPDATE / DELETE を実行してしまうリスク
情報漏洩:本来見せるべきでないデータまで参照できてしまう可能性
今回目指したのは、以下のような体験です。
インターフェースは自然言語のみ: 「先月のユーザー登録数を教えて」と聞くだけ
システム側で安全を担保: ユーザーが何をどう聞いても、データが壊れることはなく、見てはいけないデータは見えない。
このために、AWSの Amazon Bedrock AgentCore を中心としたアーキテクチャを設計しました。 今回はAgentCore Runtimeへのエージェントのデプロイまでは行わず、AgentCore Gateway + Lambda を使い、ローカルで実行するStrands Agentからツール呼び出しを行う構成にしています。
安全なデータレイクに対するクエリ実行
という、いわゆる LLM × 構造化データ分析基盤 です。
安全性を最優先し、本番DB(Aurora)には一切直接接続しません。 AuroraのスナップショットをS3へエクスポートし、Athena経由で参照する構成としています。
Strands Agent が Bedrock(Claude Sonnet)で意図を解釈
データ取得が必要と判断した場合、AgentCore Gateway 経由でツールを呼び出し
Gatewayに紐づいた Lambda が SQL を検証
問題なければ Athena にクエリを実行
結果を自然言語に変換してユーザーへ返却
今回の構成では、以下のAWSサービスを組み合わせました。それぞれの選定理由を深掘りします。
AgentCore Gateway
LambdaのMCP化 エージェントが呼び出すツール(Lambda)をAWSリソースとして統制
AWSが開発したPythonコードベースで動作する軽量なエージェントフレームワーク。AgentCoreとの親和性が高い。
元データのソース(直接は触らせない)
AuroraスナップショットをParquet形式で保存するデータレイク
S3上のデータをAthenaで扱うためのスキーマ管理
サーバーレスで安全にSQL実行
SQLの検証・強制フィルタリングを行うセキュリティゲート
Amazon DynamoDB
Athenaクエリの非同期実行をサポートするため、クエリのジョブID・実行状態・結果パスなどを管理
- 直接DBには触れさせない
分析クエリを本番DBで実行させないことを最優先にしました。 Athena + S3構成にすることで、どれだけ重いクエリを投げてもAuroraに負荷はかかりません。
今回S3への出力はAuroraの機能である「S3へのスナップショットエクスポート」を利用しました。 これにより、データはS3上にParquetファイル(列指向フォーマット)として静的に配置されます。
- Athena + Glueのコスパ
Athenaは $5 / TB(スキャン量) の従量課金です。Parquet形式であれば、月数百円〜数千円程度で運用できます。
Redshift Serverlessと比べても、「たまにアドホック分析したい」用途には十分すぎるほど安価です。
- AgentCoreによる統制
AgentCoreを使うことで、
ツール呼び出しをAWS側で管理
IAMやLambdaを使ったガードレール設計
がしやすくなり、「AIが何をしているか分からない」状態を避けられます。
Strands Agentの実装
Strands Agentを使うことで、エージェントの思考プロセスやツール定義を非常にシンプルに実装できます。
まずは、AIが呼び出すためのツール(関数)を定義します。 @tool
tools.py from strands import tool @tool def execute_sql_query(sql: str, limit: int = 100) -> dict: """ SQLクエリを実行してデータを取得します(AgentCore Gateway経由)。 Args: sql: 実行するSQLクエリ(SELECT文のみ) limit: 取得する最大行数(デフォルト100、最大10000) Returns: dict: クエリ結果(カラム名とデータのリスト) """ # AgentCore Gateway経由でMCP呼び出し return _execute_sql_query_impl(sql=sql, limit=limit) @tool def get_table_schema(table_name: str) -> dict: """ 指定されたテーブルのスキーマ情報(カラム名と型)を取得します。 SQLを生成する前に必ずこのツールでカラム名を確認してください。 """ # ... @tool def get_column_info(table_name: Optional[str] = None) -> dict: """ テーブルのカラム情報を取得します。 """ # ...
実際の実装では、ローカルのStrands AgentからAgentCore GatewayにMCPプロトコルでリクエストを送信しています。 Gateway経由の呼び出しにはSigV4署名が必要で、サービス名は bedrock-agentcore
AgentCore Gateway呼び出しの概要 def _mcp_call(method: str, params: Optional[Dict] = None) -> Dict: """MCP JSON-RPC call to AgentCore Gateway /mcp""" payload = { "jsonrpc": "2.0", "id": f"{method}-{int(time.time()*1000)}", "method": method, } if params: payload["params"] = params # SigV4署名(サービス名: bedrock-agentcore) headers = _sigv4_headers("POST", GATEWAY_URL, json.dumps(payload)) resp = requests.post(GATEWAY_URL, json=payload, headers=headers) return resp.json()
次に、システムプロンプトとツールを渡してエージェントを初期化します。 ここで重要なのは、AIにデータベースの構造と制約を正しく理解させることです。
agent.py from strands import Agent from strands.models import BedrockModel # システムプロンプトで「専門家」としての振る舞いとDB構造を定義 SYSTEM_PROMPT = """ あなたはデータ分析の専門家です。 ユーザーの自然言語での質問をSQLクエリに変換し、データベースから情報を取得して回答します。 ## SQL作成のルール 1. 必ず execute_sql_query ツールを使用すること 2. 常に SELECT 文のみを使用すること 3. ユーザーの会社ID (company_id) はLambda側で自動付与されるため、WHERE句に含める必要はありません """ def create_agent(): model = BedrockModel( model_id="お好きなモデルを利用", region_name="ap-northeast-1" ) agent = Agent( model=model, system_prompt=SYSTEM_PROMPT, tools=[execute_sql_query, get_table_schema, list_available_tables] ) return agent
このように、コード自体は非常にシンプルです。 「どのテーブルが使えるか」「どうやってクエリを書くべきか」といった知識はプロンプトに持たせることで、Pythonのロジックを変更することなくエージェントの賢さを調整できます。
「AIが勝手に変なSQLを実行したらどうするの?」という懸念に対して、Lambda関数内で多層的な防御壁を実装しました。
まず、AthenaがアクセスするS3バケットに対して、書き込み権限を持たせません。 さらにLambdaのコードレベルでも防御します。
Lambda内でのチェックロジック(イメージ) dangerous_keywords = ['DROP', 'DELETE', 'INSERT', 'UPDATE', 'ALTER', 'TRUNCATE', 'GRANT'] for keyword in dangerous_keywords: # SQL内に危険なキーワードが含まれていないかチェック if re.search(r'\b' + keyword + r'\b', sql_upper): raise ValueError(f"Dangerous keyword '{keyword}' is not allowed")
これにより、万が一AIが「データを全消去して」という命令をSQLに変換してしまっても、実行前にブロックされます。
今回はデモ用にマルチテナントが入っているデータベースを想定して実装しました。 ユーザーの所属する company_id
Before (AIが生成したSQL)
SELECT * FROM users
After (Lambdaが書き換えたSQL)
SELECT * FROM ( SELECT * FROM users ) WHERE company_id = 123 -- ユーザーのcompany_idを強制付与
このように、サブクエリでラップして外側から WHERE
「全件取得して」と言われた場合に数千万件のデータを返そうとすると、タイムアウトやメモリ溢れの原因になります。 また、Athenaはスキャン量で課金されるため、予期せぬ高額請求も防ぐ必要があります。
LIMIT句の強制: SQLに LIMIT
WorkGroup制限: AthenaのWorkGroup機能で、1クエリあたりのデータスキャン量の上限(例: 10GB)を設定し、それを超えるクエリは即座にキャンセルさせます。
Terraformと非同期処理
AgentCore GatewayのTerraform化
AWS Provider v6.17.0以降で、AgentCore Gatewayのリソースが追加されました。 今回はこれを利用してAgentCore GatewayとGateway TargetをTerraformでデプロイしています。
aws_bedrockagentcore_gateway
aws_bedrockagentcore_gateway_target
modules/ ├── agentcore/ # AgentCore Gateway / Gateway Target ├── athena/ # Athena WorkGroup設定 ├── glue/ # CrawlerとCatalog Database ├── lambda/ # クエリ実行用関数 └── s3/ # データレイク用バケット
Athenaクエリの状態管理について
Athenaへのクエリ実行は数秒〜数十秒かかることがあり、同期的に処理するとクライアント側のタイムアウトや再試行の扱いが難しくなります。 そのため本構成では、処理を 「開始」と「結果取得」の2フェーズ に分割しました。
このように、Athenaクエリの状態をDynamoDBで管理することで、
Lambdaをステートレスに保てる
再試行や複数リクエストからの参照に強い
Agent側で安全にポーリング処理を実装できる
Strands Agent側ではこのポーリングロジックを実装し、長時間かかる集計クエリでもタイムアウトせずに結果を受け取れるようにしています。
なお、今回のデモではデータ量が少なく、かつ LIMIT を付与しているため実際にはほとんど待ち時間は発生しておらず、やや冗長な構成ではありますが、実運用を見据えた際の一般的なAthena非同期実行パターンとしてこの形を採用しました。
では、実際の動作イメージを見てみましょう。今回はデモ用に用意したチャットシステムのDBで分析してみてます。
アクティブユーザーの検索
よくされているチャットの分析
このように、ユーザーはテーブル名やカラム名を意識することなく、知りたい情報を得ることに集中できます。 裏側でのテーブル識別や company_id
なお今回は検証フェーズという位置付けのため、 AgentCore Runtime上でエージェントを常駐実行するところまでは踏み込めていません。
本検証では、AgentCore GatewayにLambdaを登録し、ローカルで実行しているStrands Agentからツール呼び出しを行う構成を採用しましたが、自然言語でのデータ分析、セキュリティ制御、Athenaを用いた安全なクエリ実行といった、本質的な設計要素については十分に検証できたと感じています。
今後、実運用を見据える場合には、
Strands AgentをAgentCore Runtime上で動かす構成への移行
認証・認可を含めたマルチユーザー対応
フロントエンドから直接利用できるUIの整備
などを検討していきたいと考えています。
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
careers.abejainc.com
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
トランスフォーメーション領域:ソフトウェアエンジニア
トランスフォーメーション領域:ソフトウェアエンジニア(リードクラス)
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み