Miro が Amazon Bedrock を活用し、ソフトウェアバグの経路特定精度を向上させ解決時間を数日から数時間に短縮
Miro は Amazon Bedrock を活用した AI ベースの BugManager を導入し、バグの自動振り分け精度を大幅に向上させ、解決までの時間を数日から数時間に短縮する成功事例を発表しました。
キーポイント
Amazon Bedrock を活用した自動化ソリューションの構築
Miro は AWS Prototyping and Cloud Engineering (PACE) チームと協力し、動的な組織構造や多様なデータ形式(テキスト、スタックトレース、スクリーンショット等)に対応可能な BugManager を開発しました。
RAG 技術による文脈の補完と分類精度向上
従来の NLP モデルが苦手とする動的な組織変化や複雑なコンテキストに対し、GitHub や Confluence などの外部ソースから関連情報を取得して補完する RAG(検索拡張生成)アプローチを採用しました。
劇的な業務効率化と生産性向上の実証
導入によりチーム間の再振り分け回数が 6 分の 1 に、解決までの時間(Time-to-Resolution)が 5 分の 1 に短縮され、年間推定 42 年分の生産性ロスを削減する成果を達成しました。
影響分析・編集コメントを表示
影響分析
この事例は、大規模なソフトウェア開発現場において LLM を単なるチャットボットとしてではなく、複雑な業務フロー(バグ管理)の自動化エンジンとして実装した成功例を示しています。特に、組織構造の変化に柔軟に対応できる RAG アーキテクチャの有効性を証明しており、他の企業における AI 導入の参考モデルとなる重要な知見です。
編集コメント
大規模組織における AI の実用化において、静的なモデルの限界を克服し、動的な環境に適応する RAG アーキテクチャの有効性を示す優れたケーススタディです。
本記事は、Miro の Philipp Pavlov、Dmytro Romantsov、Evgeny Mironenko、Gowri Suryanarayana と共著です。
Miro は、世界で 9,500 万人以上のユーザーにサービスを提供する AI 搭載のイノベーションワークスペースであり、チームが非構造化されたアイデアを整理されたワークフローへと変換するのを支援しています。この規模に対応し、システムをさらに強化するために、Miro の開発者体験チームは、現代技術を活用して開発者の生産性を向上させるため、Miro 自身のためのイノベーションワークスペースの構築を決断しました。チームが直面する主要な課題の一つは、ソフトウェアの不具合(バグ)を責任あるチームへ効率的にルーティングすることです。迅速かつ正確なバグのルーティングは、不要なコンテキストスイッチングを取り除き、開発者のフラストレーションを軽減し、解決までの時間を短縮し、最終的にはより良い製品と満足度の高い顧客につながります。Miro では、不具合の多くが内部の SLA(サービスレベルアジメント)を満たせず、主に誤ったルーティングやチーム間での繰り返し再割り当てが原因となっています。この問題により、遅延と重複する調査活動によって、年間推定で 42 年分の累積した生産性が失われています。この課題に対処するため、Miro は AWS のプロトタイピングおよびクラウドエンジニアリング(PACE)チームと連携し、AI を活用した自動バグトライアージのためのソリューション「BugManager」を開発しました。
本稿では、Miro のバグルーティングを改善するために採用したアーキテクチャと技術について詳しく解説します。これにより、チームの再割り当てが 6 分の 1 に減少し、Amazon Bedrock を活用することで、解決までの所要時間が数日から数時間に短縮されました。
チャレンジ:約100のソフトウェアチームへのバグ報告の正確なルーティング
現代のソフトウェア環境におけるバグのトリアージ(選別)を自動化することは複雑です。バグ報告はしばしば不整然としており、文脈が欠落しており、テキスト、スタックトレース、スクリーンショット、さらには動画など多様なデータを含んでいます。多くのチームを抱えるソフトウェア特化型企業ではこの複雑性が倍増し、多数の可能なラベルを持つマルチクラス分類問題となります。Miro のエンジニア組織は約100のチームで構成されており、それぞれが特定の製品側面を担当しています。高精度なバグ分類には、GitHub のプルリクエスト、Confluence ドキュメント、README ファイル、および以前解決されたチケットなど、さまざまなソースから関連する製品情報を報告に付加する必要があります。さらに、組織構造は動的であり、チームの統合や新設、製品の進化によりチームの責任範囲が絶えず変化します。ソフトウェア機能についても同様で、追加、更新、または非推奨となることで常に変化しています。
従来の自然言語処理(NLP)に基づくテキスト分類器、例えばファインチューニングされた BERT モデルやファインチューニングされた大規模言語モデル(LLM)分類器は、こうした動的環境において深刻な制限に直面します。組織変更が発生した際に再学習が必要であり、新しい構造にはラベル付きデータが存在しない可能性もあります。Miro は、ファインチューニングされた GPT モデルに基づく既存のソリューションでパフォーマンスが急速に低下する経験をしました。
これらの課題を認識し、Miro はチーム分類のための最適化されたプロンプトと、文脈取得のための検索拡張生成(RAG)を組み合わせた LLM 駆動のアプローチを採用しました。これにより、より適応性が高く、ゼロトレーニングで済み、精度の高いバグトリアージソリューション「BugManager」が実現されました。
BugManager: Amazon Bedrock を活用した RAG ベースのバグトリアージ
BugManager は、LLM(大規模言語モデル)を活用したアプローチを採用してバグ分類を行います。新しいバグレポートが受信されると、BugManager の分類システムが即座に動作を開始します。まず、BugManager は Amazon Nova Pro のマルチモーダル画像およびビデオ理解機能 を用いて、スクリーンショットや画面録画などの非テキストデータを解析します。その後、システムは RAG(Retrieval-Augmented Generation:検索拡張生成)技術を活用し、複数のナレッジベースから重要な文脈情報を付加してレポートを強化します。これらのナレッジベースには、過去に解決済みの Jira イシュー、GitHub のプルリクエスト、Confluence のドキュメント、および GitHub の README ファイルなどが含まれています。Amazon Bedrock 上で Anthropic の Claude Sonnet 4 を使用することで、システムは強化されたバグ記述と、各チームおよびその責任範囲に関する詳細なテキスト情報を統合し、正しいチームへのルーティングを実行する最適化された分類プロンプトを生成します。オプション機能として、収集した情報に関連するソースコードリポジトリの検索結果を組み合わせて、詳細な根本原因分析も生成可能です。これにより、問題に対するより深い洞察を提供し、解決策に関する仮説を提示することができます。
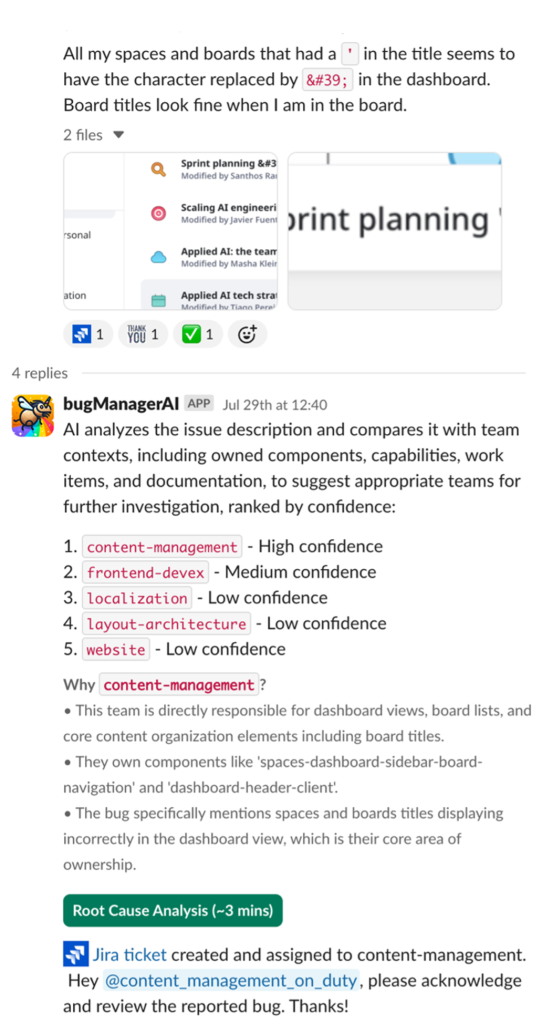
摩擦のない導入と利用を可能にするために、BugManager はシンプルな Slack ベースのワークフローを通じて Miro エンジニアリングコミュニティに公開されています。以下のスクリーンショットは、ユーザーが BugManager と対話する例を示しています。バグの初期説明に基づき、BugManager は優先順位の高い順に最大 5 つの適切なチームを提案し、その根拠も示します。デフォルトではバグは最も可能性の高いチームへルーティングされますが、ユーザーはこの選択を手動で上書きすることもできます。オプションとして、BugManager は Miro のフルコードベースから取得した情報を元に、報告されたバグの原因分析をエンジニアに提供することもあります。
次のセクションでは、BugManager のアーキテクチャについて詳しく掘り下げていきます。
アーキテクチャの深掘り
BugManager は主に Amazon Bedrock を使用します。これは、単一の API を通じて主要な AI 企業から高パフォーマンスなファウンデーションモデル(FMs)を選択できるフルマネージドサービスです。Amazon Bedrock Knowledge Bases、Anthropic の Claude Sonnet 4、および Amazon Nova Pro を Amazon Bedrock で活用することで、Slack に投稿されたバグの説明を Jira に作成されたイシューに変換し、解決のためにチームに割り当てるエンドツーエンドのワークフローを開発しました。
BugManager は Amazon Elastic Kubernetes Service(Amazon EKS)クラスター内で Python マイクロサービスとして実行されます。アーキテクチャとアプリケーションの流れは、以下の図で示されています。
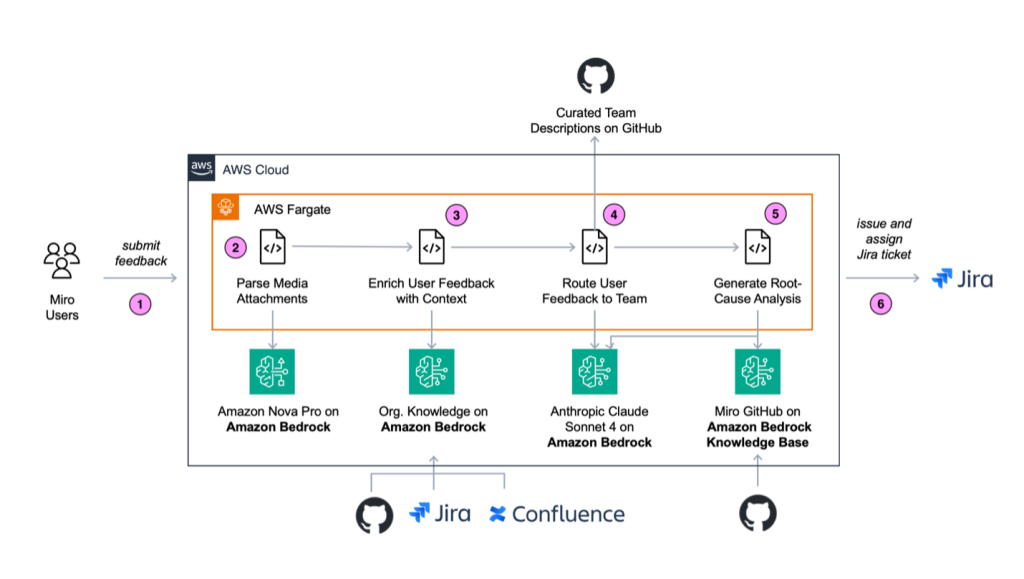
BugManager ワークフローは、以下のステップで構成されています:
- ユーザーからのフィードバックレポートを提出する。
- メディア添付ファイルを解析する。
- コンテキスト情報を付与してユーザーのフィードバックを強化する。
- ユーザーのフィードバックを適切なチームへルーティングする。
- 根本原因分析(Root Cause Analysis)を生成する。
- 結果をユーザーに返却してレビューしてもらう。
以下のセクションでは、これらのステップについてより詳細に探求します。
ステップ 1: ユーザーからのフィードバックレポートの提出
ユーザーは、専用の Slack チャンネルにフィードバックレポート(例えばバグに関するもの)を投稿します。このレポートにはテキストとメディア添付ファイルが含まれる可能性があります。メディア添付ファイルには、バグを再現する手順を説明した動画(通常は画面録画)、バグの様子を示すスクリーンショット、または機能強化のための製品ページのスクリーンショットなどが含まれます。バグレポートは JSON オブジェクトとして配信され、そこにはコンテンツ(テキスト)と、Amazon Simple Storage Service (Amazon S3) に保存された添付ファイルへのリンクが含まれています。
ステップ 2:メディア添付ファイルの解析
メッセージにメディア添付ファイルが含まれている場合、後続のステップでバグ分析と分類を単一モダリティ(テキスト)で行えるようにするために、これらをテキストに変換する必要があります。ここでは、Amazon Nova Pro の画像理解機能を用いて、メディア添付ファイルの説明をテキストとして解析します。このアプローチにおける一つの課題は、LLM がデフォルトでは文脈を意識していない点です。つまり、画像の種類(通常は Miro 製品のスクリーンショット)に関する情報が欠落しているため、それを特定の有用な方法で解釈することができません。したがって、必要な文脈を提供するために、まずバグテキストに基づいて RAG(検索拡張生成)を実行し、メディア資産に描かれている可能性が高い機能に関する情報をプロンプトに追加します。当社の RAG アプローチでは、Amazon Bedrock Knowledge Bases を使用して、Miro の社内製品ドキュメントから自動的にデータを取得します。これにより、添付ファイルから抽出される情報の特定性が大幅に向上します。解析が完了すると、メディア添付ファイルのテキスト説明が元のバグテキストに追加され、アプリケーションワークフローの次のステップへ引き渡されます。
ステップ3:文脈を付与してユーザーフィードバックを強化する
私たちは、Amazon Bedrock Knowledge Bases を使用して、さまざまなソースから自動的にデータを取得し、FM(ファウンデーションモデル)に対して、Miro の内部および外部の多様なデータソースからの文脈情報を提供しました。Amazon Bedrock Knowledge Bases は、セッションコンテキスト管理とソース帰属機能を備えた完全マネージド型機能であり、データソースへのカスタム統合構築やデータフロー管理を行うことなく、インgestion から検索、プロンプト拡張に至るまでの RAG ワークフロー全体を実装できます。具体的には、Amazon S3 と Confluence のコネクタをデータソースとして使用しました。Amazon OpenSearch Service のオンデマンドサーバーレスオプションである Amazon OpenSearch Serverless をベクトルストアとして構成しました。知識ベースには、以下のデータソースをインデックス化しました:Confluence ドキュメント、Miro ヘルプセンター記事、解決済みの Jira チケット、GitHub README、および Backstage ドキュメント(技術ドキュメントとソフトウェアカタログ)。Amazon Bedrock Knowledge Bases は増分再同期をサポートしており、コスト効果の高い方法で、文書の変更に合わせて知識ベースを最新状態に保つことが容易になります(変更されたドキュメントのみが再埋め込みされ、再インデックスされます)。
ステップ4:ユーザーフィードバックを適切なチームへルーティング
Amazon Bedrock と Anthropic の Claude Sonnet 4 の支援により、バグを担当チームへルーティングしました。LLM に正確な分類を行わせるために提供されたコンテキストには、拡張されたバグの説明、拡張された添付ファイルの説明(添付ファイルが存在する場合)、および Backstage で中央集権的にキュレーションされバージョン管理されている(GitHub をバックエンドとして利用)チーム説明が含まれます。チーム説明は、必要に応じて随時更新可能な生きたドキュメントです。Miro のプロダクトおよびエンジニアリング組織は動的な構造であり、プロダクト機能の追加や廃止、チームの責任範囲の変更が行われます。BugManager がプロンプトベースのアプローチを採用しているため、これらの変更は、対応するチーム説明(英語で記述された Markdown ファイル)を更新するだけで比較的容易に反映できます。変更は即座に伝播します。以下は、バグからチームへの分類に使用したプロンプスの簡略化版です。出力における <tags> タグの使用にご注意ください。これにより、出力の堅牢な解析が可能になります。
翻訳全文
Miro チームの記述
思考を段階的に実行してください!
""".strip()
BugManager は、バグからチームへのルーティングにおけるトップ 1 の精度が 75% を超えることを達成しました(これは、微調整された NLP モデルに基づく既存の社内ソリューションと比較して 70% の向上です)。平均分類レイテンシは 53 秒であり、本番環境での展開において実用的であることが証明されました。BugManager は、信頼度順にランク付けされた最大 5 つの有望なチームオプションを返します(正確な数は設定可能です)。トップ 3 の精度は 95% に達しており、これは人間が関与するアプローチと組み合わせることで、さらにトリアージ精度を向上させることが実証されています。これらの結果は、Anthropic の Claude の拡張思考 を通じて可能となりました。これにより、追加で 7〜9% の精度向上が実現しました。
各分類において、このソリューションは特定のルーティング決定が行われた理由についての包括的な根拠も提供します。これは、単一のチームのみを説明なしに返す微調整された NLP ソリューションと比較して、ユーザーの受容性と信頼性を大幅に向上させました。
ステップ 5:根本原因分析の生成
BugManager はオプションとして、バグの根本原因分析を生成することができます。再び、Amazon Bedrock Knowledge Bases を使用して必要なコンテキストを提供し、今回は Miro の GitHub コードベース全体を参照元として活用します。根本原因分析の実行中、LLM(Anthropic の Claude Sonnet 4、拡張思考機能を有効化)には、バグの説明、以前に取得されたコンテキスト、およびバグを解決する担当ソフトウェアチームが提供されます。その後、LLM は Amazon Bedrock Knowledge Bases を用いて該当するコードセクションを取得し、観測されたバグの根本原因に関する一連の仮説を生成します。これにより、ソフトウェアエンジニアはアクションの方向性を特定するために必要な調査作業から解放されます。
ステップ 6:結果をユーザーに返してレビューしてもらう
分類および根本原因分析(オプション)の結果は、最初に投稿されたメッセージへのレスポンスとして Slack に送信されます。ユーザーはルーティング結果を確認し、必要に応じてデフォルトの選択を変更できます。その後、元のバグ説明と、知識ベースから取得した関連ドキュメント、ならびに根本原因分析の結果を記載した Jira チケットが作成され、選定されたチームに割り当てられます。
結論
BugManager は、Amazon Bedrock を活用した非常に優れたバグトリアージソリューションであり、Miro のエンジニアリング組織全体で大きな成功を収めています。その主な機能は以下の通りです。
- 高精度な初回トライでのバグから担当チームへのルーティング
- マルチクラス予測による人間が関与する意思決定のサポートを通じたさらなるパフォーマンス向上
- ユーザー受容性を高める透明性の高いルーティング判断
- 解決を加速させるバグ根本原因分析
- 継続的に更新される組織ナレッジとの連携強化
- チーム責任範囲の変化に対する堅牢性と柔軟性
BugManager は本番環境で数千件のバグとサポートリクエストを正常にルーティングし、Miro の開発ワークフローにおいて卓越した成果を上げています。このシステムにより、顧客サポートリクエストのチーム再割り当てが 6 分の 1 に減少し、解決までの中央値時間が 5 倍改善されました。かつては数日かかっていたプロセスが、今では数時間で完了するようになっています。BugManager は年間を通じて累積した待機時間と調査時間を数年分節約できると予測されており、最終的には Miro の製品体験を大幅に向上させることになります。
独自のフィードバックルーティングシステムを構築し始めるには、AWS の生成 AI リソースとサンプルアーキテクチャ Generative AI on AWS を探索してください。ここでは、AI 駆動の運用効率化への道筋を加速させるためのステップバイステップガイド、リファレンス実装、ベストプラクティスを見つけることができます。
著者について

Philipp Pavlov
Philipp は Miro の技術および製品リーダーであり、AI ファーストのデベロッパー支援と大規模な運用効果向上イニシアチブを推進しています。彼は Miro Digital Twin(社内のすべてのシステムにわたるコンテキストを集約し、文脈認識型 AI ワークフローや文脈駆動型の意思決定を可能にする接続されたセマンティック知識レイヤー)に関する作業を主導しています。

Dmytro Romantsov
Dmytro は、クラウドインフラストラクチャ、JVM エコシステム、応用 AI にわたる 12 年以上の経験を持つシニア SRE(Site Reliability Engineer)および Developer Experience エンジニアです。エンジニアリングチームがより迅速に動き、より信頼性高く運用できるよう支援する内部プラットフォームと自動化を構築しています。彼の専門分野には、開発者向けツール、AI の活用促進、ソフトウェアの所有権とガバナンス、コストと運用効率、そしてプロダクションエクセレンス(生産性の卓越)が含まれ、断片化されたシステムを拡張可能な基盤へと変革し、速度、信頼性、ビジネス成果を向上させています。

Evgeny Mironenko
Evgeny は、フロントエンド、バックエンド、AI 技術を横断して活動するソフトウェアエンジニアであり、スケーラブルな内部プラットフォームの構築を専門としています。彼の焦点は、システムの統合、開発者体験の向上、そして自動化と堅固なエンジニアリング基盤を通じてチームがより迅速に動けるようにすることです。
<img loading="lazy" class="alignnone wp-image-127430 size-full" src="https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b
原文を表示
*This post is co-authored with Philipp Pavlov, Dmytro Romantsov, Evgeny Mironenko, and Gowri Suryanarayana from *Miro.
Miro is an AI-powered innovation workspace that serves over 95 million users globally, helping teams transform unstructured ideas into organized workflows. To support this scale and continue enhancing their system, Miro’s developer experience team decided to create an innovation workspace for Miro itself, using modern technologies to boost developer productivity. One of the key challenges faced by the team is efficiently routing software bugs to the responsible teams. Quick and accurate bug routing removes unnecessary context-switching, reduces developer frustration, improves time-to-resolution, and ultimately leads to a better product and happier customers. At Miro, a significant percentage of bugs miss internal resolution SLAs primarily due to misrouting and repeated reassignments between teams. This issue results in an estimated 42 years of cumulative lost productivity annually from delays and redundant investigation efforts. To tackle this problem, Miro partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop BugManager, an AI-powered solution for automated bug triaging.
In this post, we dive deep into the architecture and techniques we used to improve Miro’s bug routing, achieving six times fewer team reassignments and five times shorter time-to-resolution powered by Amazon Bedrock.
Challenge: Accurately routing bug reports to approximately 100 software teams
Automating bug triaging in modern software environments is complex. Bug reports are often messy, lack context, and contain diverse data including text, stack traces, screenshots, and even videos. The complexity multiplies in software-focused companies with many teams, creating a multi-class classification problem with numerous possible labels. Miro’s engineering organization consists of nearly 100 teams, each responsible for specific product aspects.High-accuracy bug classification requires augmenting reports with relevant product information from various sources, including GitHub pull requests, Confluence documentation, README files, and previously resolved tickets. Additionally, organizational structures are dynamic—teams merge, new teams form, and products evolve, continuously changing team responsibilities. The same holds true for software features that are added, updated, or deprecated.Traditional natural language processing (NLP) based text classifiers, such as fine-tuned BERT models or fine-tuned large language model (LLM) classifiers, face severe limitations in these dynamic environments. They require retraining when organizational changes occur and depend on labeled data that might not exist for new structures. Miro experienced quickly degrading performance with an existing solution based on a fine-tuned GPT model.Recognizing these challenges, Miro opted for an LLM-powered approach that combines optimized prompts for team classification with Retrieval Augmented Generation (RAG) for context retrieval, creating a more adaptable, zero-training, and higher-accuracy bug triaging solution: BugManager.
BugManager: RAG-based bug triaging powered by Amazon Bedrock
BugManager adopts an LLM-powered approach to bug classification. When a new bug report is received, the BugManager classification system takes action. BugManager first parses non-text data such as screenshots or screen recordings using the multimodal image and video understanding capabilities of Amazon Nova Pro. The system then enriches the parsed report with important context from several knowledge bases (using Amazon Bedrock Knowledge Bases) with RAG. These knowledge bases contain, for example, previously resolved Jira issues, GitHub pull requests, Confluence documentation, and GitHub READMEs. Using Anthropic’s Claude Sonnet 4 on Amazon Bedrock, the system combines the enriched bug descriptions along with detailed textual information on each team and their responsibilities into a single, optimized classification prompt that performs the routing to the correct team. As an optional feature, the system can also generate a detailed root cause analysis, using the collected information in combination with retrieval of relevant source code repositories to provide deeper insights into the issue and offer hypotheses on how to resolve them.
To enable frictionless adoption and use, BugManager is exposed to the Miro Engineering community through a simple Slack-based workflow. The following screenshot shows an example of a user interaction with BugManager. Based on the initial description of the bug, BugManager proposes up to five suitable teams (in order of priority) along with a rationale. By default, the bug is routed to the most likely team, but users can manually overwrite this selection. Optionally, BugManager also provides engineers with a root cause analysis of the reported bug, drawing on information retrieved from the full Miro code base.
In the following sections, we dive into the BugManager architecture.
Architecture deep dive
BugManager primarily uses Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies through a single API. With Amazon Bedrock Knowledge Bases, Anthropic’s Claude Sonnet 4, and Amazon Nova Pro on Amazon Bedrock, we developed an end-to-end workflow that converts a bug description posted in Slack to an issue created in Jira and assigned to a team for resolution.
BugManager runs as a Python microservice in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The architecture and application flow is depicted in the following diagram.
The BugManager workflow consists of the following steps:
- Submit user feedback report.
- Parse media attachments.
- Enrich user feedback with context.
- Route user feedback to the correct team.
- Generate root cause analysis.
- Return results to user for review.
In the following sections, we explore these steps in more detail.
Step 1: Submit user feedback report
A user posts a feedback report (for example, of a bug) into a dedicated Slack channel. The report might contain text and media attachments. Media attachments might include a video (typically a screen recording) that describes the process to reproduce the bug, a screenshot that depicts the bug, or a screenshot of a product page for feature enhancement. The bug report is delivered as a JSON object, which includes the content (text) and the link to the attachments deposited in Amazon Simple Storage Service (Amazon S3).
Step 2: Parse media attachments
If the message contains media attachments, these must be parsed to text to enable bug analysis and classification in a single modality (text) in later steps. We use the image understanding capabilities of Amazon Nova Pro to parse the media attachment description as text. One challenge with this approach is that the LLM isn’t context-aware by default; it lacks information about the type of image (typically a screenshot of the Miro product) to interpret it in a specific and useful way. Therefore, to supply the required context, we first run RAG based on the bug text to supplement our prompt with information about the specific feature likely depicted in the media asset. Our RAG approach uses Amazon Bedrock Knowledge Bases to automatically fetch data from Miro’s internal product documentation. This meaningfully improves specificity of the extracted information from the attachment. After it’s parsed, the text description of the media attachment is appended to the original bug text and passed on to the next step in the application workflow.
Step 3: Enrich user feedback with context
We used Amazon Bedrock Knowledge Bases to automatically fetch data from various sources and provide the FMs with contextual information from a wide range of Miro internal and external data sources. Amazon Bedrock Knowledge Bases is a fully managed capability with built-in session context management and source attribution that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. More specifically, we used the Amazon S3 and Confluence connector as data sources. We configured Amazon OpenSearch Serverless, the on-demand serverless option of Amazon OpenSearch Service, as a vector store. We indexed the following data sources in the knowledge base: Confluence documentation, Miro help center articles, resolved Jira tickets, GitHub READMEs, and Backstage documents (technical documentation and the software catalog). Amazon Bedrock Knowledge Bases supports incremental re-syncs, which makes it straightforward to keep the knowledge base up to date with documentation changes in a cost-effective manner (only modified documents are re-imbedded and re-indexed).
Step 4: Route user feedback to the correct team
With the help of Amazon Bedrock and Anthropic’s Claude Sonnet 4, we routed the bug to the responsible team. The context given to the LLM to do the correct classification consists of the enriched bug description, the enriched attachment description, if the attachment is available, and the team descriptions that are centrally curated and versioned in Backstage (backed by GitHub). Team descriptions are living documents that can be updated whenever necessary. Miro’s product and engineering organization are dynamic constructs. Product features are added or deprecated, and team responsibilities change. Given BugManager’s prompt-based approach, such updates can be incorporated with relative ease by simply updating the respective team descriptions (a markdown file written in English). Changes are propagated immediately. The following is a simplified version of the prompt we used for bug-to-team classification. Note the use of `` tags in the output, which allows robust parsing of outputs.
ROUTING_PROMPT = """
You are a bug report routing assistant for Miro, a software company providing a collaboration and canvas software. You are responsible for analyzing incoming bug reports and determining which software team should handle them. Your goal is to accurately route each bug report to the most appropriate Miro software team based on their areas of responsibility.
When analyzing a bug report, follow these steps:
1. Carefully read the provided team descriptions to understand each team's domain expertise and responsibilities
2. Analyze the bug report for:
- Affected systems or components
- Technical keywords and terminology
- Error messages or stack traces
- User impact and behavior
- Related capabilities, features or functionality
3. Compare the bug details against each team's responsibilities
4. Select the most appropriate Miro software team based on:
- Direct ownership of affected components
- Required technical expertise
- Historical handling of similar issues
- Cross-cutting concerns and dependencies
Return the five most appropriate software teams, provide a confidence of HIGH, MEDIUM, LOW and a rationale per each choice. Enclose your answers in , and xml tags, respectively.
Details about the bug report and the responsibilities of each Miro software team are provided below:
Bug details and context:
{bug_report}
{parsed_attachments}
{parsed_attachments}
Miro software teams descriptions:
{teams_info}
Miro team descrip
Think step-by-step!
""".strip()BugManager achieves a top-1 accuracy for bug-to-team routing of over 75% (a 70% increase vs. an existing internal solution based on a fine-tuned NLP model). Average classification latency is 53 seconds, which proved practical when deployed in production. BugManager returns up to five likely team options (ranked by confidence, exact number is configurable). Top-3 accuracy is 95%, which—when paired with a human-in-the-loop approach—has been proven to boost triaging accuracy further. These results were made possible through Anthropic’s Claude’s extended thinking, which resulted in additional accuracy gains of 7–9%.
For each classification, the solution also provides a comprehensive rationale for why a certain routing decision was made. This significantly improved user acceptance and trust vs. the fine-tuned NLP solution that only returned a single team without further explanation.
Step 5: Generate root cause analysis
BugManager can optionally generate a root cause analysis of the bug. Again, we provide the necessary context to run such an analysis using Amazon Bedrock Knowledge Bases, this time drawing on the entire Miro GitHub code base for reference. During root cause analysis, we provide the LLM (Anthropic’s Claude Sonnet 4 with extended thinking enabled) with the bug description, the previously retrieved context, and the selected software team to resolve the bug. The LLM then retrieves the respective code sections using Amazon Bedrock Knowledge Bases and generates a set of hypotheses for the root cause of the observed bug. In doing so, it relieves software engineers of the required research work necessary to identify a course for action.
Step 6: Return results to user for review
The result of the classification and root cause analysis (optional) is sent to Slack as a response to the initial message posted. Users can review the routing results and make changes to the default choice if needed. After that, a Jira ticket with the original bug description and supporting documentation retrieved from the knowledge bases as well as the results for the root cause analysis is cut and assigned to the selected team.
Conclusion
BugManager boasts several key features that make it a highly capable bug triaging solution powered by Amazon Bedrock that has been adopted with significant success across Miro’s engineering org. These key features include:
- High-accuracy first-try bug-to-team routing
- Further performance boosts through multi-class prediction enabling human-in-the-loop decision-making
- Transparent routing decisions that drive user acceptance
- Bug root cause analysis to accelerate resolution
- Augmentation with continuously refreshed organizational knowledge
- Robustness and flexibility to changes in team responsibilities
BugManager has successfully routed thousands of bugs and support requests in production, delivering exceptional results for Miro’s development workflow. The system has achieved a six-fold reduction in team reassignments for customer support requests and a five-fold improvement in median time-to-resolution, transforming what once took days into an hours-long processes. BugManager is projected to save years of cumulative waiting and investigation time annually, ultimately delivering a significantly better Miro product experience.
To get started building your own feedback routing system today, explore the AWS generative AI resources and sample architectures at Generative AI on AWS, where you can find step-by-step guides, reference implementations, and best practices to accelerate your journey toward AI-powered operational efficiency.
About the authors
Philipp Pavlov
Philipp is a Technical and Product Leader at Miro, driving AI-first developer enablement and large-scale operational effectiveness initiatives. He leads work on the Miro Digital Twin — a connected semantic knowledge layer that brings together context across all company systems, enabling context-aware AI workflows and context-driven decision-making
Dmytro Romantsov
Dmytro is a Senior SRE and Developer Experience engineer with 12+ years of experience across cloud infrastructure, the JVM ecosystem, and applied AI. He builds internal platforms and automation that help engineering teams move faster and operate more reliably. His focus areas include developer tooling, AI enablement, software ownership and governance, cost and operational efficiency, and production excellence—turning fragmented systems into scalable foundations that improve velocity, reliability, and business outcomes.
Evgeny Mironenko
Evgeny is a software engineer working across frontend, backend, and AI technologies and specializing in building scalable internal platforms. His focus is on unifying systems, improving developer experience, and enabling teams to move faster through automation and solid engineering foundations
<img loading="lazy" class="alignnone wp-image-127430 size-full" src="https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み