Claude Codeのソースコードが漏洩したが、ソースコード分析記事は書かないつもりだ
宝玉氏はClaude Code流出を機に、深層分析ではなく「実行・機能特定・手動修正・再構築」の4段階学習フレームワークを提示し、流出コードの実用性とAnthropicの対応姿勢を検証している。
キーポイント
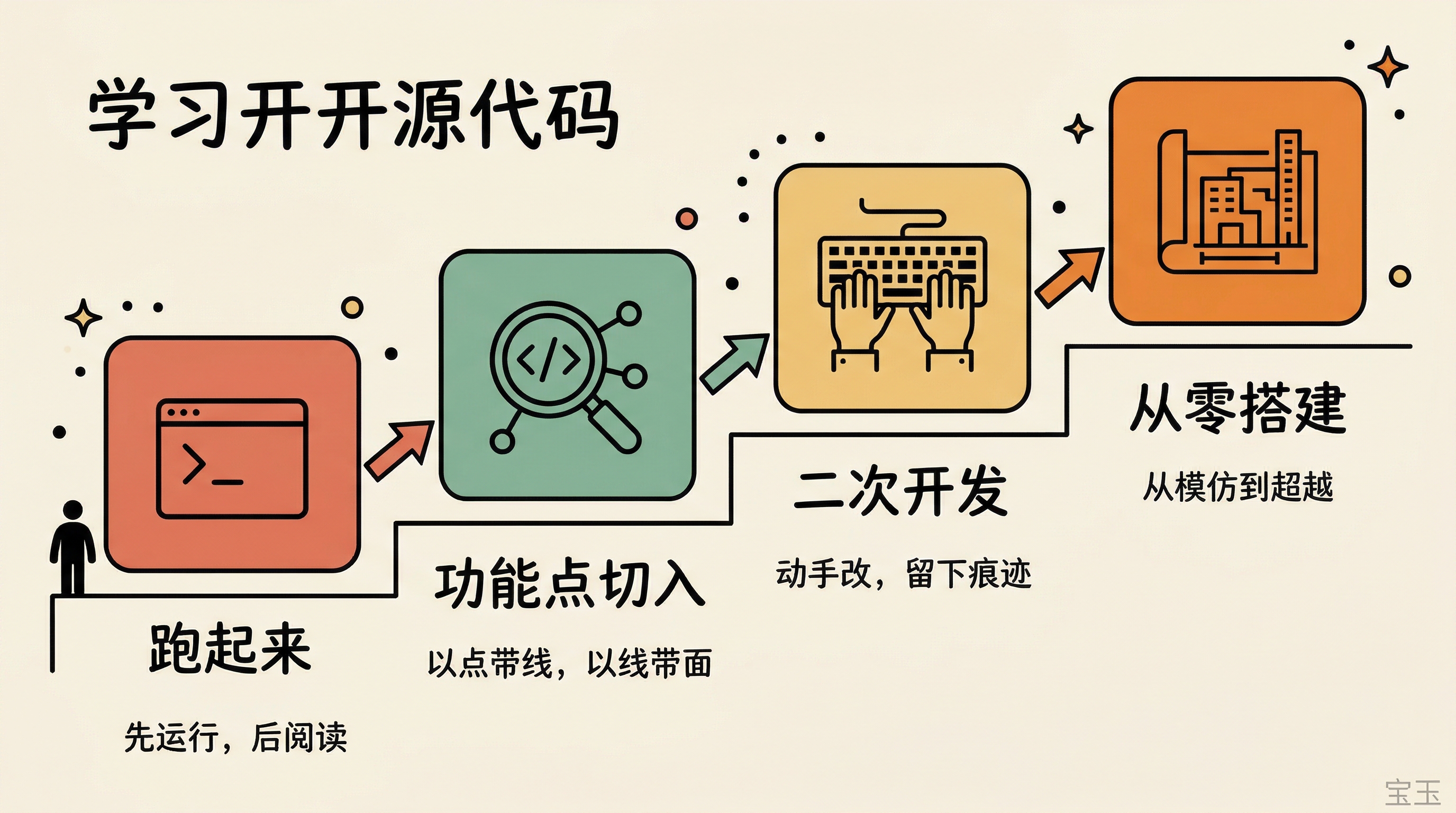
実践的な大規模コード学習フレームワーク
単なる読解ではなく「実行→機能点特定→手動修正→ゼロからの再構築」の4ステップを提示し、エージェントアーキテクチャやAPIフローを実践的に把握する方法論を示している。
AI時代の学習における「手作業」の重要性
学習目的ではAI支援を意図的に避け、手動で機能を実装・修正することで、設計意図やモジュール配置の理由を自らの思考プロセスで吸収する必要性を強調している。
流出コードの実態と業界影響の冷静な評価
逆向上SDKは静的コードのためプロダクション利用には適さず、影響は研究者や小規模チームに限定されると指摘し、過度な煽り報道を戒めている。
Anthropicの閉源戦略と成熟したインシデント対応
コード品質管理、セキュリティ/防逆向上策、イテレーション速度の維持から閉源を継続する合理性を説明し、責任追及よりプロセス改善を重視したAnthropicの対応姿勢を評価している。
影響分析・編集コメントを表示
影響分析
Claude Codeの流出は、AIエージェントの開発実態を可視化する契機となったが、本記事が指摘する通り、その真の価値はコード自体よりも「大規模プロジェクトをどう学ぶか」というメタスキルにある。また、Anthropicの対応姿勢は、セキュリティインシデントにおける成熟したガバナンスモデルとして業界に示唆を与える。
編集コメント
流出コードの分析記事が氾濫する中、学習プロセスに焦点を当てた本稿は、開発者のスキル向上という実利的な視点を提供しており、AI業界の知財管理と教育の接点を探る上で参考になる。
Claude Codeのソースコードが漏洩し、ネット上は「深層分析」記事であふれています。友人からも分析記事を書くよう頼まれましたが、コードが漏洩してからわずか十数時間、50万行以上のコードを深く分析し理解するのは困難です。しかし、魚を与えるより魚の釣り方を教える方が良い。むしろお伝えしたいのは、オープンソースコードを手に入れたとき、どうすれば本当に自分のものにできるか、ということです。
この方法はClaude Codeに限らず、あらゆる大規模オープンソースプロジェクトに適用できます。
ソースコードを手に入れた後、ほとんどの人の第一反応はファイルを開いて読み始めることです。
今回漏洩したClaude Codeのコードはソースマップ(source map)復元後の結果で、多くのスキャフォールディング(scaffolding)とプライベートパッケージ(private package)が欠けており、直接実行できません。私は自分でなんとかしようと思っていましたが、すでに誰かが解決していました(https://github.com/claude-code-best/claude-code)。そのまま使えば良いです。
注:このプロジェクトの作者は私の知り合いではありませんが、正常にダウンロードして実行できたので紹介します。今後のプロジェクトの展開についてはわからず、削除される可能性も高いです。興味があれば、早めにコードをローカルにダウンロードし、AIにコードのセキュリティ問題を分析させてから実行することをお勧めします。
なぜ実行する必要があるのか?二つの理由があります。
一つは、実行結果を直感的に確認できるからです。コードは静的なものですが、実行されて初めて動き出します。コードを読んで「この関数はおそらくこれをしているのだろう」と思っても、実行してみれば正しいかどうかがわかります。
二つ目は、ログを出力したりブレークポイント(breakpoint)を設定したりできるからです。後で具体的な機能を分析する際、これが核心的な手段となります。数万行のコードを目で追ってロジックを探すのは、大海で針を探すようなものです。実行した後、console.logを追加すれば良いのです。
プロジェクトが実行できたら、次に多くの人が犯す間違いは、エントリーファイル(entry file)から始めて、プロジェクト全体を最初から最後まで読み通そうとすることです。
数万行のコードをそんな風に読み進めると、三日で諦めてしまいます。
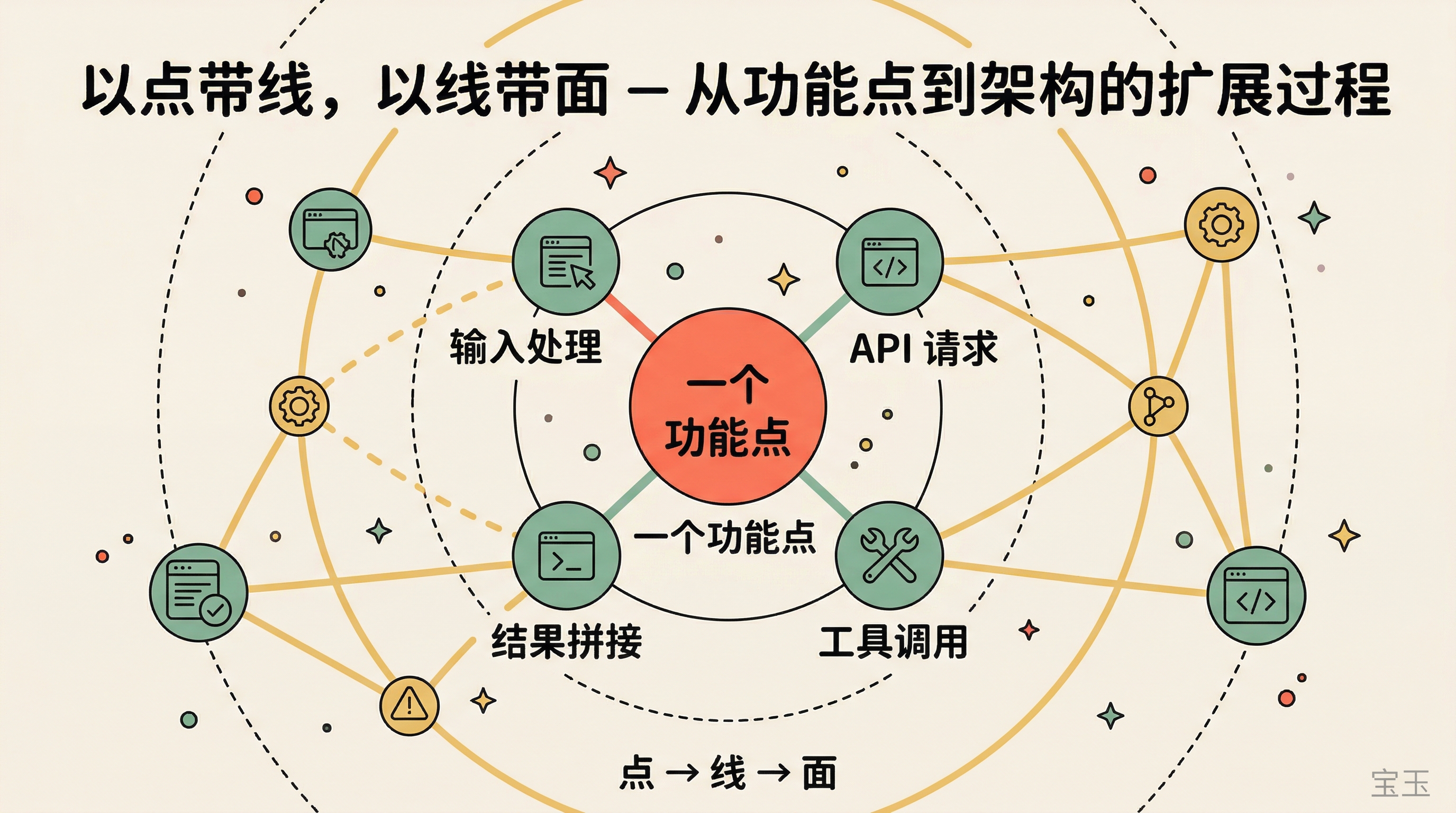
より良い方法は、具体的な機能ポイントから入ることです。
例えば、エージェントループ(Agent Loop)に興味があるなら、すべてのAPIリクエストを出力または収集し、モデルに送信されるプロンプト(prompt)がどのようなものか、モデルが何を返したか、Claude Codeが返された結果を受け取ってから何をしたかを見ます。一連の対話を通じて、「エージェントがどのようにタスクを分解し、どのようにツールを呼び出すか」について直感的な理解が得られます。
以前、私はclaude-traceで同様のことをしたことがありますが、残念ながら後で使えなくなりました。今はソースコードがあるので、自分でログを追加すればより詳細にできます。
一つの機能ポイントを理解したら、自然とそれが通過するモジュールに触れることになります:入力がどのように入ってくるか、どのような処理を経るか、ツール呼び出しがどのようにトリガーされるか、結果がどのように組み戻されるか。モジュール間の関係が、このように一つ一つつながっていきます。
欲張らないこと。一つの機能ポイントを徹底的に理解する方が、十のモジュールを表面的に見るよりもはるかに役立ちます。
第三ステップ:手を動かして変更し、コードに自分の痕跡を残す
コードを見るだけでは、学んだことは「理解した気になる」だけで終わりがちです。手を動かせばすぐに実力が露呈します。
しかし、ゼロから書く必要もありません。すでに成熟したプロジェクトにとって、最良の練習方法は二次開発(secondary development)です。
例えば、Claude Codeは最近 /buddy をリリースしました。
二次開発をするときは、できるだけAIの支援を使わないようにします。
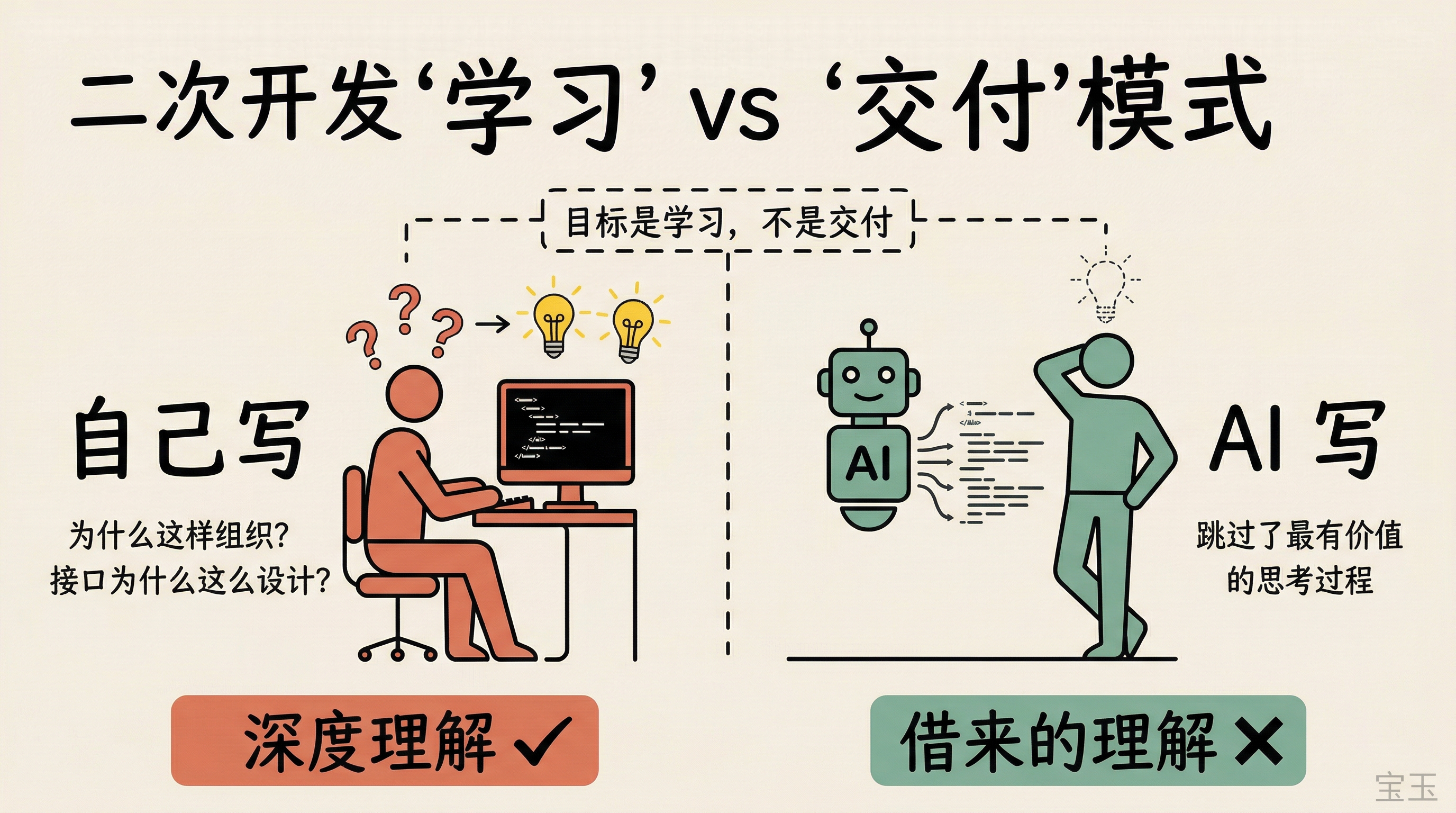
これは直感に反するように聞こえるかもしれません。AIを使ってコードを書く方が効率がはるかに高いのに、なぜ使わないのか?目的が違うからです。あなたの目標は学習であって、納品(delivery)ではありません。AIに書かせると、あなたが飛ばすのはまさに最も価値のある思考プロセスです:なぜこのようにコードを構成するのか?このモジュールはなぜここに置かれているのか?インターフェース(interface)はなぜこのように設計されているのか?
最初から最後まで自分自身の力で一つの機能を開発できるようになれば、そのプロジェクトへの理解は「見たことがある」から「やったことがある」に変わります。
いくつかの機能を開発すればするほど、プロジェクト全体のアーキテクチャ(architecture)に慣れ、さらには「もっと良くできる部分がある」と感じ始めるでしょう。
二次開発を通じてプロジェクトのアーキテクチャに慣れ、それが「どのようなものか」を知ります。しかし、一つの疑問が残ります:当初、なぜこのように設計されたのか?
アーキテクチャの決定の背後には、あなたには見えない多くの要素があります:歴史的負債(historical baggage)、チーム規模、時間的プレッシャー、当時の技術的制約。あなたは結果の前に立ち、「Aが選ばれた」と見ますが、「なぜBとCが選ばれなかったか」は見えません。
これらを理解する最良の方法は、自分自身でゼロから構築することです。
機能を完全にする必要はないし、すべてを網羅する必要もありません。あなた自身の考えに従い、元のアーキテクチャを参考にしながら、設計決定を一からやり直します。あなたが「明らかにこうすべきだ」と思っていた部分が、手を動かすとすぐに問題が発生することに気づくでしょう。そうすれば、原作者がなぜその選択をしたのか理解できます。
このステップが最も難しいですが、最も収穫が大きいです。
このステップまで来れば、あなたは単にこのプロジェクトを「理解した」だけでなく、自分自身のアーキテクチャ案を作成する能力を持っています。
この四つのステップは簡単に言えます:実行する → 一つの機能ポイントから入る → 二次開発する → ゼロから構築する。しかし、私は一つの興味深い現象を観察しています:ほとんどの人は第一ステップと第三ステップの間、つまり「多くを見たが、実際に書いたことはない」で行き詰まります。
AI時代では、この問題がより起こりやすくなります。AIにコード分析を手伝わせるのはあまりにも便利で、数秒で「アーキテクチャの全体図」が得られます。しかし、この理解は借り物であり、深く追求すると耐えられません。
あなたはオープンソースコードを学ぶためにどんな方法を使ったことがありますか?本当に「かみ砕いた」プロジェクトはありますか?
付記:今回のClaude Codeコード漏洩自体について少し話します
漏洩したコードからClaude Codeの関連ロジックをリバースエンジニアリング(reverse engineering)し、オープンソースのSDKを作った人もいます。考え方は良いですが、このコードは静的であり、Claude Codeが更新されればすぐに追いつけなくなります。学習に使うのは良いですが、製品の基盤として使うのは現実的ではありません。
業界への影響も、一部の人が誇張しているほど大きくはありません。一般の開発者はこれを見る必要はなく、大手企業は逆解析すべきものはすでに解析しています。本当に恩恵を受けるのは、深く研究したいと考える少数の開発者と小規模チームであり、そこから確かに価値のある技術的詳細を学べます。
漏洩したのだから、Anthropicはなぜオープンソースにしないのかと尋ねる人もいます。 私は不可能だと思います。クローズドソース(closed source)の利点はあまりにも多いからです:
コード品質にあまりこだわる必要がありません。一つのReactファイルに数千行書いても、クローズドソースなら誰にも知られず、オープンソースにすれば批判されます。
こっそり仕掛けを追加できます。蒸留防止(distillation prevention)のロジック、ユーザー識別の記録、さらには「うっかり」サードパーティのプロンプトキャッシング(prompt caching)を無効にするバグ(bug)など、クローズドソースならパケットキャプチャ(packet capture)を心配する必要がありません。
リリースペースをコントロールできます。今回は多くの隠し機能が発見されました、例えば /buddy
迅速なイテレーション(iteration)には複雑なコードレビュー(code review)プロセスを経る必要がなく、オープンソースの場合は気にすることがはるかに多くなります。
一つ言及すべきことがあります。 Anthropicは今回の漏洩に正面から対応し、Borisはうまく言いました:
仕事では、ミスは避けられません。しかし、チームとして最も重要なのは、問題が発生したときに決して個人を責めないという合意を形成することです。真の「原因」は、私たちのプロセス設計、チーム文化、あるいは基盤となるインフラストラクチャ(infrastructure)にあることが多いのです。
今回の問題は、自動化されるべきだったが、まだ手動で操作されていたデプロイメント(deployment)の段階で発生しました。個人を責めたり、誰かを解雇したりすることはありませんでした。「Anthropicに加入したばかりでこの問題を起こし、解雇された」と主張するのは、話題に便乗したマーケティングアカウントなので、信じないでください。
問題に直面し、プロセスを改善する。これがエンジニアリングチームのあるべき姿です。
原文を表示
Claude Code 源码泄漏了,满屏都是“深度分析”文章。也有朋友让我写一篇分析文章,但代码才泄漏十几个小时,50 多万行代码,想深度分析清楚还是有难度的。不过授人以鱼不如授人以渔,我更想聊聊:拿到一份开源代码,怎么把它真正学到手。
这套方法不只适用于 Claude Code,任何大型开源项目都一样。
拿到源码之后,大部分人的第一反应是打开文件开始读。
这次泄漏的 Claude Code 代码是 source map 还原后的结果,缺了很多脚手架和私有 package,没法直接运行。我本来打算自己折腾一下,结果发现已经有人搞定了(https://github.com/claude-code-best/claude-code),直接用就好。
注:这个项目作者我不认识,只是我可以正常下载运行,所以推荐,后续项目如何发展我并不清楚,而且被下架的可能性很大。有兴趣的可以尽早把代码下载到本地,并让 AI 分析一下代码有无安全问题后再运行。
为什么一定要跑起来?两个原因。
一是你能直观看到运行结果。代码是死的,运行起来才是活的。 你读代码时觉得“这个函数大概是做这个的”,跑一遍就知道你猜对了没有。
二是你可以打日志、设断点。后面分析具体功能的时候,这是核心手段。光用眼睛在几万行代码里找逻辑,跟大海捞针差不多。跑起来之后加个 console.log
项目跑起来了,下一步很多人会犯一个错误:试图从入口文件开始,把整个项目从头读到尾。
几万行代码,这么读下去三天就放弃了。
更好的做法是从一个具体的功能点入手。
比如你对 Agent Loop 感兴趣。那就打印或者收集所有的 API 请求,看它发给模型的 Prompt 长什么样,模型返回了什么,Claude Code 拿到返回之后又做了什么。一轮对话下来,你对“一个 Agent 怎么拆解任务、怎么调用工具”就有了直观的认识。
以前我用 claude-trace 做过类似的事情,可惜后来用不了了。现在有源码了,自己加日志能做得更细。
当你搞清楚一个功能点之后,自然会接触到它经过的模块:输入怎么进来的,经过了哪些处理,工具调用怎么触发的,结果怎么拼回去的。模块之间的关系,就这样一个一个串起来了。
别贪多。搞透一个功能点,比走马观花看十个模块有用得多。
第三步:动手改,在代码上留下你的痕迹
光看代码,学到的东西很容易变成“感觉自己懂了”。一动手就原形毕露。
但从零写一个也没必要。对于一个已经成熟的项目,最好的练手方式是二次开发。
举个例子,Claude Code 刚发布了一个 /buddy
做二次开发的时候,尽量别用 AI 辅助。
我知道这听起来很反直觉。用 AI 写代码效率高这么多,为什么不用?因为目的不一样。你的目标是学习,不是交付。让 AI 帮你写了,你跳过的正好是最有价值的思考过程:为什么要这样组织代码?这个模块为什么放在这里?接口为什么这么设计?
当你能从头到尾靠自己把一个功能开发出来,你对这个项目的理解就从“看过”变成了“做过”。
多做几个功能之后,你会越来越熟悉它的整个架构,甚至开始觉得有些地方可以做得更好。
通过二次开发你熟悉了项目架构,知道它“是什么样的”。但有一个问题一直留着:当初为什么要这么设计?
架构决策的背后往往有很多你看不到的东西:历史包袱、团队规模、时间压力、当时的技术限制。你站在结果面前,看到的是“选择了 A”,但看不到“为什么没选 B 和 C”。
想搞清楚这些,最好的办法是自己从零搭一个。
不需要功能完整,不需要面面俱到。按照你自己的想法,参考原来的架构,重新做一遍设计决策。你会发现那些你以为“显然应该这样做”的地方,一动手就出问题了。然后你就理解了原作者为什么那样选。
这一步是最难的,但也是收获最大的。
走到这一步,你已经不只是“读懂了”这个项目,而是有能力做出自己的架构方案了。
这四步说起来简单:跑起来 → 从一个功能点切入 → 二次开发 → 从零搭建。但我观察到一个有意思的现象:大多数人卡在第一步和第三步之间,也就是“看了很多,但没动手写过”。
AI 时代更容易出现这个问题。让 AI 帮你分析代码太方便了,几秒钟就给你一份“架构全景图”。但这种理解是借来的,经不起追问。
你用过什么方法学开源代码?有没有哪个项目是你真正“啃”下来的?
附:聊几句这次 Claude Code 代码泄漏本身
有人从泄漏的代码里逆向了 Claude Code 的相关逻辑,做出了开源的 SDK。思路挺好,但这份代码是静态的,Claude Code 一更新你就跟不上了。拿来学习可以,拿来做产品基础不太现实。
对行业的影响也没有一些人渲染得那么大。普通开发者用不着看这些,大厂该逆向的早就逆向了。真正受益的是一小部分有兴趣深入研究的开发者和小团队,从里面确实能学到一些有价值的技术细节。
有人问既然都泄漏了,Anthropic 为什么不干脆开源? 我觉得不可能。闭源的好处太多了:
代码质量不用太讲究。一个 React 文件写了几千行,闭源没人知道,开源出来会被喷死。
可以暗搓搓加料。防蒸馏的逻辑、用户标识的记录,甚至“不小心”导致第三方 prompt caching 失效的 bug,闭源不用担心被抓包。
可以控制发布节奏。这次就发现了不少隐藏功能,比如 /buddy
快速迭代不用走复杂的代码审查流程,开源的顾忌多得多。
有一件事值得一提。 Anthropic 正面回应了这次泄漏,Boris 说得很好:
工作中,犯错总是在所难免。但作为一个团队,最重要的是要达成一种共识:出了问题绝不该怪罪到某个人头上。真正的“罪魁祸首”往往是我们的流程设计、团队文化,或者是底层的基础设施。
这次的问题出在一个本该自动化、却还是人工手动操作的部署环节上。没有怪到个人头上,也没有因此开除谁。那些号称“刚加入 Anthropic 搞出这事被开除了”的都是蹭热度的营销号,别信。
直面问题,改进流程。这才是一个工程团队该有的样子。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み