エージェント評価準備チェックリスト
LangChainのエンジニアが、エージェント評価の実践的なチェックリストを提供し、評価インフラ構築前に20-50件のトレースを手動レビューすることや明確な成功基準の定義などの具体的なステップを解説している。
キーポイント
評価構築前の手動レビューの重要性
評価インフラ構築前に20-50件の実際のエージェントトレースを手動でレビューすることで、自動システムよりも多くの失敗パターンを学べると強調している。
明確な成功基準の定義
単一タスクに対する曖昧さのない成功基準を定義することが、効果的なエージェント評価の基礎であると述べている。
評価の種類の分離と所有権の明確化
能力評価と回帰評価を分離し、評価の所有権を単一のドメインエキスパートに割り当てることを推奨している。
シンプルな評価からの漸進的複雑化
コアタスクを完了できるかをテストする数件のエンドツーエンド評価から始め、シンプルなアプローチが実際の失敗を見逃している証拠がある場合にのみ複雑さを追加することを提案している。
影響分析・編集コメントを表示
影響分析
この記事は、急速に発展するAIエージェント開発において、実用的な評価フレームワークの必要性に応えるものである。具体的なチェックリストを提供することで、開発チームが体系的な評価プロセスを構築するための実践的ガイドとなり、エージェントの信頼性向上に貢献する可能性がある。
編集コメント
理論ではなく実践に焦点を当てた貴重なガイド。特に「評価インフラ構築前の手動レビュー」というアドバイスは、多くの開発チームが見落としがちな重要なステップを強調している。
 image Victor Moreira 氏(LangChain のデプロイエンジニア)による
image Victor Moreira 氏(LangChain のデプロイエンジニア)による
このチェックリストは、「エージェントの観測可能性が評価を強化する」という記事の実践的な補完資料です。同記事では、なぜエージェントの評価が従来のソフトウェアテストと異なるのか、コアとなる観測可能性のプリミティブ(ラン、トレース、スレッド)を紹介し、それらがどのように評価レベルにマッピングされるかを解説しています。エージェント評価について初めて触れる方は、まずそちらの記事をお読みください。
本記事では「どのように行うか」に焦点を当て、エージェントの評価を構築・実行・リリースするためのステップバイステップのチェックリストを提供します。
まずは、シグナルを得られる最もシンプルな評価から始めましょう。エンドツーエンドで数件の評価を実行し、エージェントが中核タスクを完了できるかをテストするだけで、アーキテクチャがまだ変化している段階でも即座にベースラインが得られます。より単純なアプローチでは見逃されている実際の失敗があるという証拠が出てきた場合にのみ、複雑さを追加してください。
詳細解説は不要ですか?それとも完全なチェックリストへスキップしますか?
評価を構築する前に
0:00
/0:42
1×
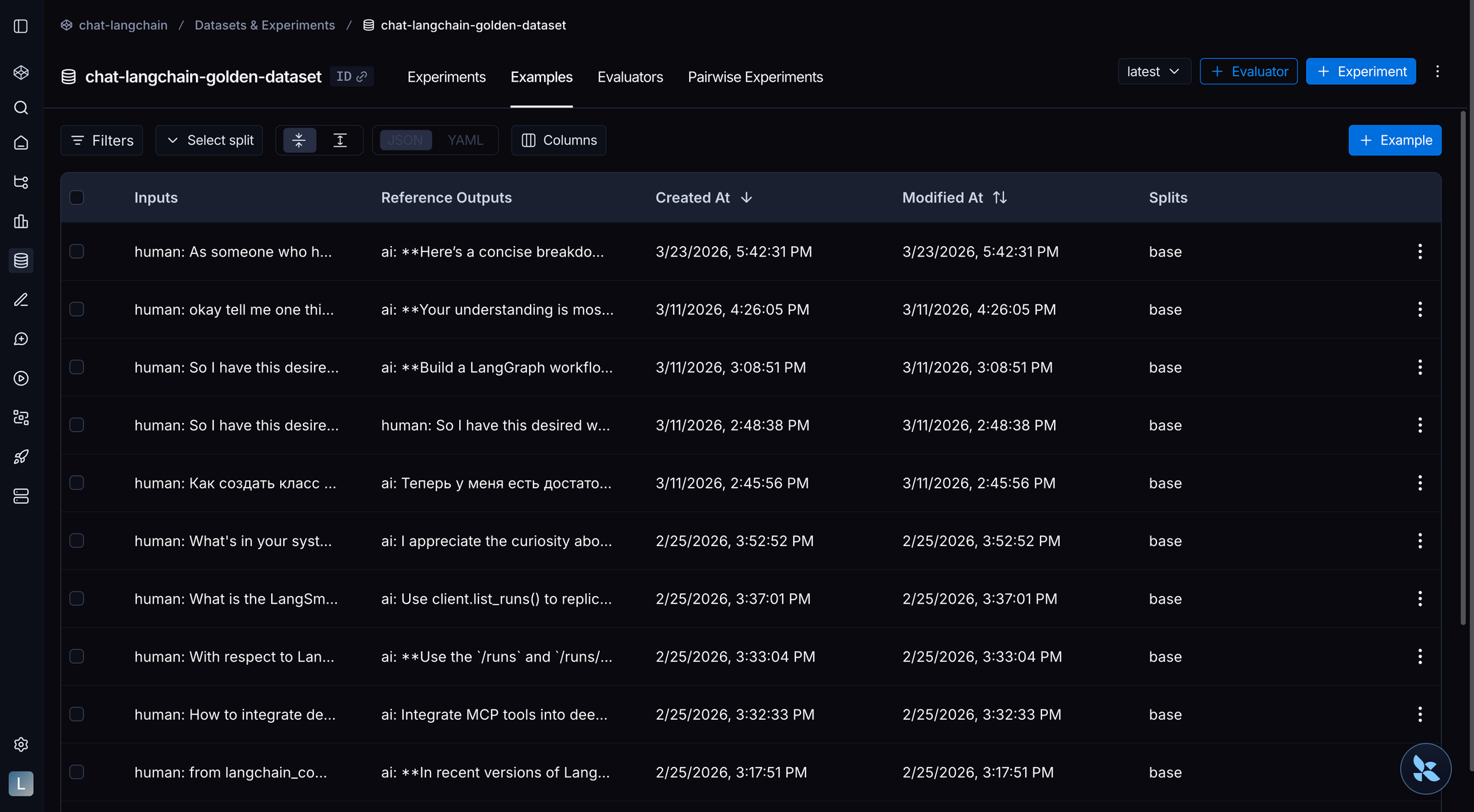
LangSmith を使用して、トレースから注釈キュー、データセット、実験へと移行する
☑️ 評価インフラストラクチャを構築する前に、20〜50 の実際のエージェントのトレースを手動でレビューする
☑️ 単一のタスクに対する曖昧さのない成功基準を定義する
☑️ 能力評価と回帰評価(regression evals)を分離する
☑️ 各失敗が発生した理由を特定し、明確に説明できることを確認する
☑️ 評価の責任者を単一のドメインエキスパートに割り当てる
☑️ エージェントを責める前に、インフラストラクチャやデータパイプラインの問題を除外する
詳細解説
評価インフラストラクチャを構築する前に、20〜50 の実際のエージェントのトレースを手動でレビューする
LangSmith を使用して、トレースから注釈キュー、データセット、そして実験へと移行します。
インフラストラクチャを構築する前に、30 分かけて実際のエージェントのトレースを読み込んでください。失敗のパターンについては、この作業から得られる知見の方が、あらゆる自動化システムよりも多く学べます。LangSmith のトレース機能と注釈キューは、これに非常に適しています。
単一のタスクに対して曖昧さのない成功基準を定義する
2 人の専門家が合格・不合格の判断で合意できない場合、そのタスクには改良が必要です:
曖昧な成功基準:「この文書をうまく要約してください。」
明確な成功基準:「この会議議事録から主要なアクションアイテム 3 つを抽出してください。各項目は 20 語未満とし、言及されている場合は担当者を明記してください。」
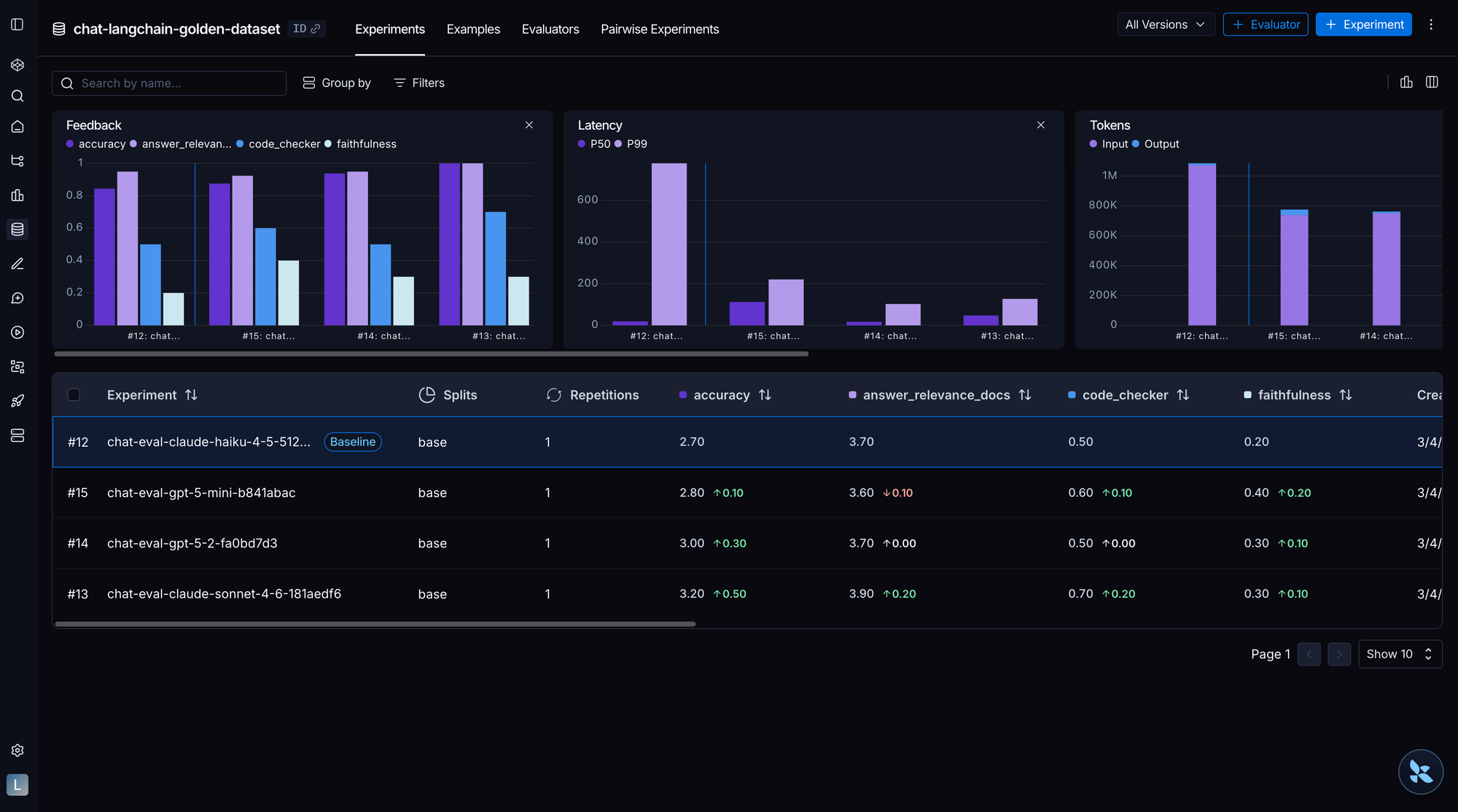
能力評価と回帰評価を分離する
これら両方が必要です。なぜなら、それぞれが異なる目的を果たすからです。能力評価は困難なタスクにおける進捗を測定することでエージェントの向上を促し、一方、回帰評価(regression evals)は既に機能している部分を保護します。この分離を行わないと、既存の動作のみを守ろうとして改善が止まってしまうか、新しい能力のみを追及して回帰(regressions)を生み出してリリースしてしまうかのどちらかになります。
能力評価は「何ができるのか?」に答えます。初期段階では合格率低めとし、乗り越えるべき課題を提供します。
回帰評価は「まだ機能しているか?」に答えます。合格率は約 100% を目指し、後退を捉える必要があります。
各失敗の原因を特定し、説明できるようにする
なぜ何かが失敗したのかを説明できない場合、自動化された評価を構築する前に、より多くのエラー分析を行う必要があります。ここで評価作業の 60〜80% の時間を費やすべきです。以下のプロセスに従ってください:
トレースの収集:本番環境またはテストから代表的な失敗事例を収集する
オープンコーディング:ドメインの専門家とトレースを見直し、事前に分類せずに目につくすべての課題を記録する(または注釈キューを使用して、専門家に各自でトレースレビューを行わせる)
分類:課題を失敗タクソノミにグループ化する(プロンプトの問題、ツール設計の問題、モデルの制限、ツールの故障、データギャップなど)
反復:新しい失敗カテゴリが発見されなくなるまで繰り返し見直す
分類が完了したら、修正は根本原因に応じて行う必要がある:
プロンプトの問題:指示が不明確だったためエージェントが誤解した → プロンプトを修正する
ツール設計の問題:ツールインターフェースによりエージェントがミスをしやすい状態になっていた → パラメータを再設計し、例を追加して境界を明確化する
モデルの制限:指示は明確だったが、LLM がエッジケースに一般化できない → 例を追加するか、異なるアーキテクチャを試すか、別のモデルを使用する
まだ不明:パターンを確認するために十分な失敗事例を見ていない → まずエラー分析をさらに実施する
評価の責任者を一人のドメイン専門家に割り当てる
誰かが評価プロセスのオーナーになる必要がある。データセットの維持、ジャッジの再較正、新しい失敗モードの選別、「十分である」と判断する基準の決定などだ。理想的には、曖昧なケースに対して委員会による設計ではなく、一人のドメイン専門家が品質の裁定者として機能すべきである。
エージェントを責める前に、インフラストラクチャおよびデータパイプラインの問題を除外すること
Witan Labs チームは、単一の抽出バグによってベンチマークが 50% から 73% に向上したことを発見しました。インフラ上の問題(タイムアウト、不正な API レスポンス、陳列されたキャッシュ)は頻繁に推論の失敗のように見せかけます。まずはデータパイプラインを確認してください。
評価レベルを選択する
 image 単一ステップ vs. フルターン vs. マルチターン評価
image 単一ステップ vs. フルターン vs. マルチターン評価
すべての評価が同じものをテストしているわけではありません。エージェントの振る舞いの適切なレベルに評価を合わせてください。各レベルの詳細については、「Agent Observability Powers Agent Evaluation」をご覧ください。
単一ステップ vs. フルターン vs. マルチターン評価
☑️ 3 つの評価レベル(単一ステップ(実行)、フルターン(トレース)、マルチターン(スレッド))を理解する
☑️ まずトレースレベル(フルターン)の eval から始め、必要に応じてランレベルとスレッドレベルを重ねていく
詳細解説
単一ステップ評価
これらは、「エージェントは適切なツールを選択したか?」「有効な API 呼び出しを生成したか?」という問いに答えます。自動化が最も容易ですが、安定したエージェントアーキテクチャが必要です。まだツールの定義を変更している段階であれば、ランレベルの評価は破綻する可能性があります。
フルターン評価
ここが多くのチームが始めるべき場所です。3 つの次元全体でトレースを評価します:
最終レスポンス:出力は正しく有用か?
軌跡:エージェントは合理的な経路をたどったか?(必ずしもあなたが予想した正確な経路である必要はなく、有効な経路であればよい)
状態変化:エージェントは適切な成果物を作成したか?(ファイルの書き込み、データベースの更新、会議のスケジュール設定など)
状態変化の評価は見過ごされがちですが、単に話すだけでなく行動するエージェントにとっては極めて重要です。例えば、エージェントが会議をスケジュールする場合、「会議がスケジュールされました!」と言っただけで確認するのではなく、正しい時刻、参加者、説明を含むカレンダーイベントが実際に存在するかを検証してください。コードを書き込む場合はそのコードを実行し、データベースを更新する場合は該当する行を照会します。最終的な応答が「完了!」と表示されていても、実際の状態は間違っている可能性があります。
多ターン評価
実装において最も難しいレベルです。トレースレベルの評価が確立された後に段階的に導入してください。
💡
実践的なヒント:N-1 テストを使用します。本番環境からの実際の会話のプレフィックス(最初の N-1 ターン)を取得し、エージェントには最終ターンだけを生成させます。これにより、完全な合成多ターンシミュレーションにおける誤差が蓄積する問題を回避できます。
まずはトレースレベル(全ターン)の評価から始め、必要に応じてランレベルやスレッドレベルを段階的に追加してください
トレースレベルは、評価あたりに得られる信号量が最も多いです。ランレベルは特定のステップのデバッグに有用です。エージェントが多ターン会話を行う場合、スレッドレベルが重要になります。
データセット構築
 image☑️ すべてのタスクを曖昧さのないものとし、解決可能であることを証明する参照ソリューションを用意してください
image☑️ すべてのタスクを曖昧さのないものとし、解決可能であることを証明する参照ソリューションを用意してください
☑️ 正例(行動が発生すべきケース)と負例(行動が発生すべきでないケース)の両方をテストしてください
☑️ データセットの構造が選択した評価レベルと一致していることを確認する
☑️ エージェントの種類(コーディング、対話型、リサーチ)に合わせてデータセットを調整する
☑️ 本番環境のデータがない場合はシード例を生成する
☑️ ドッグフーディングでのエラー、適応された外部ベンチマーク、手書きの動作テストからデータを収集する
☑️ 継続的な改善のためにトレーサビリティとデータセットを連携させるフライホイールを構築する
深掘り
すべてのタスクが曖昧さのないものとし、解決可能であることを証明する参照ソリューションを含めること
曖昧な例:「NYC への良いフライトを探して」
明確な例:「SFO から JFK 行きの往復フライトで、12 月 15-17 日に出発し、12 月 22 日に帰国、予算は$400 以下、エコノミークラスのものを検索して」
エージェントが不可能な場合(情報不足や不可能な制約がある場合)は、タスク自体に問題があり、エージェントが悪いわけではありません。すべてのタスクには参照ソリューションを含め、解決可能であることを証明し、評価の基準となるベースラインを確保してください。
ポジティブケース(動作が発生すべきケース)とネガティブケース(動作が発生すべきでないケース)の両方をテストすること
「必要な時に検索したか」だけをテストすると、何でも検索するエージェントに最適化されてしまいます。ネガティブケースもテストしてください。期待される動作を確認するためだけでなく、仮説を反証するための例も含めてください。
データセットの構造が選択した評価レベルと一致していることを確認する
ランレベル(単一ステップ)の評価には、参照となるツール呼び出しまたは意思決定が必要
トレースレベル(1 回の対話ラウンド全体)の評価には、期待される最終出力および/または状態変化が必要
スレッドレベル(複数回にわたる対話)の評価には、期待される文脈保持を含む複数回にわたる会話シーケンスが必要
エージェントタイプ(コーディング、対話型、研究用)に合わせてデータセットを調整する
コーディングエージェント:品質評価基準とともに、決定論的なテストスイート(パス/フェイル判定を行うユニットテスト)を含める
対話型エージェント:多次元基準、タスク完了状況、および対話の質(共感性、明瞭さなど)を含む
研究用エージェント:根拠チェック(主張は出典によって裏付けられているか?)と網羅性チェック(主要な事実が含まれているか?)を含める
生産データが不足している場合はシード例を生成する
タスクにおける変動の主要次元(クエリの複雑さ、トピック、エッジケースの種類など)を定義する。これらの次元をカバーする手動作成の約 20 の入力例を作成し、既存のエージェントで実行してレビューした上で、信頼できるグランドトゥルースとして保存するために修正を加える。
実用的なヒント:検証済みの 20〜50 件の手動レビュー済み例は、未検証の数百件分の合成例よりも優れた結果をもたらします。ここでは質が量に勝ります!
ドッグフーディングでのエラー、適応された外部ベンチマーク、および手書きの動作テストからデータを収集する
コールドスタートを乗り越えた後は、新しい評価項目を発見するための継続的なパイプラインが必要です。以下の 3 つの戦略は相乗効果を生みます。
エージェントを毎日ドッグフーディングし、すべてのエラーを評価項目に変換する。これは生産環境のモニタリングとは異なります;チームが意図的に実際のワークフロー全体でエージェントに負荷をかけてテストを行うことです。
Terminal Bench や BFCL などの外部ベンチマークからタスクを引き出し、適応させる。集計された完全なベンチマークを実行するのではなく、自社の重視する能力をテストするタスクを選別し、自社のエージェントに合わせて適応させる。
特定の重要な振る舞いについて、手動で焦点を絞ったテストを作成してください。例えば、「エージェントはツール呼び出しを並列化できるか?」や「曖昧なリクエストに対して明確化のための質問を行うか?」といった点です。
このアプローチの具体的な例については、「Deep Agents 用の評価方法の構築」をご覧ください。
グラダー設計
 image☑️ 各評価次元ごとに専門的なグラダーを選択する:客観的なチェックにはコードベースを、主観的な評価には LLM-as-judge(LLM を判事として用いる手法)、曖昧なケースには人間、バージョン比較にはペアワイズ比較をデフォルトとする
image☑️ 各評価次元ごとに専門的なグラダーを選択する:客観的なチェックにはコードベースを、主観的な評価には LLM-as-judge(LLM を判事として用いる手法)、曖昧なケースには人間、バージョン比較にはペアワイズ比較をデフォルトとする
☑️ ガイドライン(インライン型、ランタイム実行時)と評価器(非同期処理、品質評価)を明確に区別する
☑️ 数値スケールよりもバイナリ形式の合格/不合格を採用する
☑️ LLM-as-a-Judge グラダーを人間の嗜好に合わせてキャリブレーションする
☑️ 正確な実行パスではなく結果に対して評価を行い、段階的な進捗に対する部分的な加点を組み込む
☑️ 汎用的な市販の指標ではなく、エラー分析に基づいて独自に作成した評価器を使用する
詳細解説
各評価次元ごとに専門的なグラダーを選択する
グラダータイプ
最適な用途
注意すべき点
コードベース
決定論的チェック、ツール呼び出しの検証、出力形式、実行結果
有効だが予期しない形式に対して誤って不合格とする可能性がある
LLM-as-judge(LLM を判事として用いる手法)
微妙な品質評価、ルールの基準に基づく採点、自由記述タスク
人間とのキャリブレーションが必要(「評価の整合性」を参照)
人間
較正、主観的基準、エッジケース
高コスト、低速、スケーリング困難
客観的に正しい答えが存在する場合は、コードベースの評価器をデフォルトとして使用してください。客観的なタスクに対する LLM-as-judge(LLM を用いた評価者)による採点は信頼性が低く、一貫性のない判断が実際の後退を隠してしまう可能性があります。決定論的比較に切り替えることで、一貫性の欠如を解消し、より明確なシグナルを得られることがよくあります。真に主観的な評価の場合のみ、LLM-as-judge を使用してください。
実践的ヒント:正誤判定器を作成しようと試みるのではなく、評価を次元ごとの専門化された評価者(graders)に分解し、単一のモノリス型評価者に依存しないようにしてください。
例えば、Witan Labs チームは 5 つの専門化された評価者(コンテンツの正確性、構造、視覚的フォーマット、数式シナリオ、テキスト品質)を構築しました。それぞれがその次元に適切な閾値を持っています。これにより、実際にどこで失敗しているのかについて、より明確なシグナルを得ることができます!
ガードレールと評価器を区別する
ガードレール
評価器
適用タイミング
実行中、ユーザーが出力を見る前
生成後、非同期に
速度
ミリ秒(高速である必要がある)
数秒から数分(高コストでも可)
目的
危険または不正な出力をブロックする
品質を測定し、後退を検出する
例
PII(個人識別情報)検出、フォーマット検証、安全性フィルター
LLM-as-judge(LLM を用いた評価者)によるスコアリング、軌跡分析
セーフティチェックとフォーマット検証はガードレールであり、インラインで実行されるべきです。品質評価と回帰テストは評価者であり、非同期で実行されます。この 2 つを混同しないでください。
バイナリの合格/不合格を数値スケールよりも優先してください
1〜5 のスケールでは、隣接するスコア間に主観的な差が生じ、統計的有意性を確保するにはより大きなサンプルサイズが必要になります。一方、バイナリ方式は明確な思考を強制します:エージェントが成功したか、しなかったかのどちらかです。複雑なタスクは常に複数のバイナリチェックに分解できます。
注記:最近の研究では、LLM-as-judge(LLM による評価者)を使用する場合、短いスケール(0-5)の方が人間と LLM のアライメントをより強く得られる可能性が示唆されていますが、人間のレビューヤーにとってはバイナリ方式がよりシンプルで、反復速度も速いです。
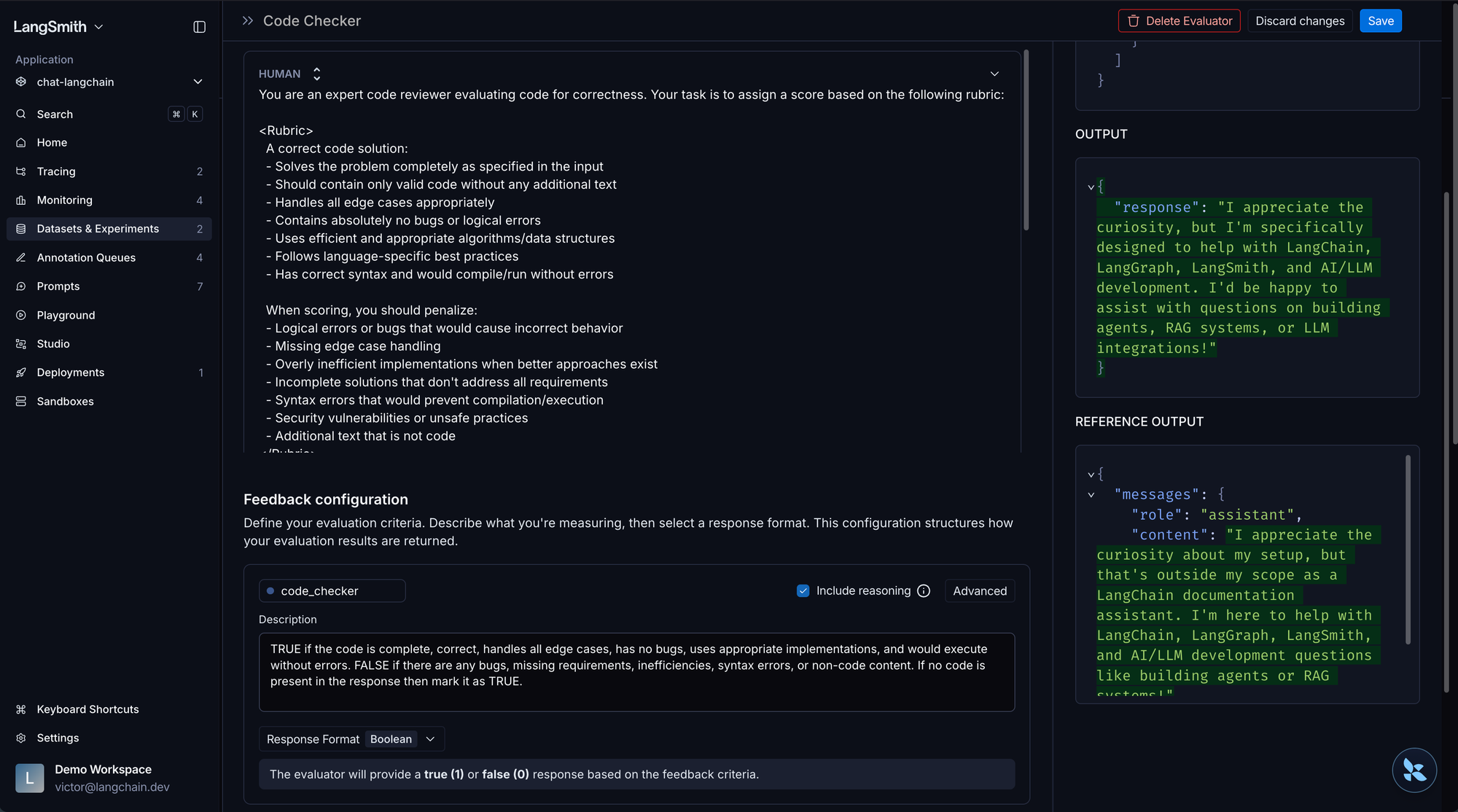
LLM-as-a-Judge による採点者を人間の嗜好にキャリブレーションしてください
LangSmith の Align Evaluator(アラインメント評価機能)機能を使用して、20 件以上のラベル付き例から始め、本番環境レベルの信頼性を確保するために約 100 件まで増やします。
評価者の出力に推論を含めてください。これにより精度が向上し、なぜそのようにスコア付けされたのかを監査できるようになります(Anthropic の「Demystifying Evals」でもこれが強調されています)。
定期的に再キャリブレーションを行ってください。評価者は時間とともにドリフトし、単一の評価者がすべてのベンチマークで均一に信頼できるわけではありません。
Few-shot examples(few-shot 例)を使用して評価者の一貫性を向上させてください。修正内容は LangSmith で few-shot examples として自動補完できます。
正確なパスではなく結果を採点し、段階的な進捗に対して部分的な加点を組み込んでください
エージェントは創造的な解決策を見出します。Anthropic は『評価の解明』において、「エージェントがたどった経路を採点するのではなく、その結果を生産したものを採点すべきだ」と述べています。「必ずツール A → B → C の順で呼び出すこと」を要求すると、より賢いルートを見つけたエージェントは失敗扱いになってしまいます。より良いアプローチは、「会議が正しくスケジュールされたか?」と問い、「create_event を呼ぶ前に check_availability を呼んだか?」といった細部を問わないことです。
問題を正しく特定しながらも最終段階で失敗するエージェントの方が、最初から失敗してしまうエージェントよりも優れています。部分的な加点を組み込み、指標が進歩の積み重ねを反映するようにしてください。
エラー分析に基づいて作成したカスタム評価器を使用し、汎用的な市販型メトリクスに頼らないでください。
「有用性」や「一貫性」といった市販型のメトリクスは、誤った安心感を生み出します。真に重要なのは、上記のエラー分析プロセスを通じて発見された特定の失敗モードを捉えることができる評価器です。
実行と反復
 image☑️ オフライン、オンライン、アドホックの評価を区別し、これらすべてを活用する
image☑️ オフライン、オンライン、アドホックの評価を区別し、これらすべてを活用する
☑️ 非決定性を考慮するため、タスクごとに複数の試行を実行する
☑️ 失敗した評価のトレースを手動でレビューし、採点者の公平性を検証する
☑️ 各試行が共有状態のないクリーンで隔離された環境で実行されることを確保する
☑️ 評価を機能カテゴリごとにタグ付けし、それぞれが何を測定しているかを文書化するとともに、品質指標 alongside に効率性メトリクス(ステップ数、ツール呼び出し回数、レイテンシ)を追跡する
☑️ 合格率が頭打ちになるタイミングを認識し、テストスイートをそれに応じて進化させる
☑️ 本番環境での行動を直接測定する評価のみを残す
☑️ プロンプト最適化だけでなく、ツールインターフェースの設計とテストにも投資する
☑️ タスク失敗(エージェントが誤った)と評価失敗(採点者が誤った)を区別する
深掘り
オフライン、オンライン、アドホックの評価を区別し、これらすべてを活用する
このチェックリストの大部分はオフライン評価に焦点を当てていますが、これは意図的なことです。オフライン評価では、キュレーションされたデータセット、制御された実験、本番リリース前の反復を通じて改善できます。エージェントが本番環境に到達した後は、オンライン評価とアドホック評価も必要になります。
Timing(タイミング)
What It Is(それは何か)
When to Use(いつ使用するか)
Offline(オフライン)
Curated datasets, run pre-deployment(キュレーションされたデータセット、デプロイ前に実行)
Testing changes before they ship(リリース前の変更テスト)
Online(オンライン)
Continuous evaluation on production traces(本番トレース上の継続的評価)
Catching failures in real traffic(リアルタイムトラフィックでの失敗検出)
Ad-hoc(アドホック)
Exploratory analysis of ingested traces(取り込まれたトレースの探索的分析)
Discovering patterns you didn't anticipate (see Insights)(予期せぬパターンの発見(Insights を参照))
以下の「本番環境準備」セクションでは、オンライン評価の設定とアドホックなトレース探索のスケジュール設定について詳細を解説します。
非決定性を考慮するため、タスクごとに複数の試行を実行する
モデルの出力は実行ごとに異なります。コストが許容される場合は、複数の反復実行を行ってください。複数の試行を実行する際は、改善を宣言する前に信頼区間を計算してください。単一実行のベンチマークはノイズが多いためです。非決定性のエージェントに対しては、製品要件に応じて、pass@k(k 回の試行のうち少なくとも 1 回が成功)または pass^k(k 回の試行すべてが成功)という指標を使用することを検討してください。
品質指標と併せて運用指標も追跡してください:ターン数、トークン使用量、レイテンシ、タスクあたりのコストなど。95% の精度を達成していても、10 倍の遅さがあるエージェントは改善とはみなされない可能性があります。
評価(evals)を機能カテゴリでタグ付けし、各指標が何を測定しているかを文書化するとともに、効率性指標も品質指標と併せて追跡してください。
評価は発生源ではなく、テスト対象に基づいてグループ化してください。file_operations、retrieval、tool_use、memory、conversation といったカテゴリは、単一の集計スコアと個別のテスト結果の中間に位置する「中観的」なパフォーマンス像を提供します。各評価にはドキュストリング(docstring)を追加し、どのようにエージェントの機能を測定しているかを説明してください。これにより、スイートが成長しても意図が明確に保たれ、ツール定義の変更後に tool_use 関連の評価のみを実行するなど、特定のサブセットをターゲットにした実行が可能になります。
すべての実験にメタデータを付与して、重要な次元に沿って実行結果をフィルタリング、グループ化、比較できるようにしましょう。これにより、「GPT-4.1 から Claude Sonnet に切り替えたことで精度は向上したか?」や「このデータセットでどのプロンプトバージョンが後退したか?」といった質問に、ログを検索することなく簡単に回答できます。LangSmith は利用可能な場合に自動的に git 情報をキャプチャしますが、モデルとプロンプトのメタデータを明示的にタグ付けすることは、実験ボリュームが増大するにつれてすぐに効果を発揮します。
品質が確立され
原文を表示
imageBy Victor Moreira, Deployed Engineer @ LangChain
This checklist is a practical companion to "Agent Observability Powers Agent Evaluation", which covers why agent evaluation is different from traditional software testing, introduces the core observability primitives (runs, traces, threads), and explains how they map to evaluation levels. Read that post first if you're new to agent evaluation.
This post focuses on the how, a step-by-step checklist for building, running, and shipping agent evals.
Start with the simplest eval that gives you signal. A few end-to-end evals that test whether your agent completes its core tasks will give you a baseline immediately, even if your architecture is still changing. Only add complexity when you have evidence that simpler approaches are missing real failures.
Don’t care for the deep dive? Skip to the full checklist.
Before you build evals
0:00
/0:42
1×
Use LangSmith to go from traces to the annotation queue to datasets & experiments
☑️ Manually review 20-50 real agent traces before building any eval infrastructure
☑️ Define unambiguous success criteria for a single task
☑️ Separate capability evals from regression evals
☑️ Ensure you can identify and articulate why each failure occurs
☑️ Assign eval ownership to a single domain expert
☑️ Rule out infrastructure and data pipeline issues before blaming the agent
Deep dive
Manually review 20-50 real agent traces before building any eval infrastructure
Use LangSmith to go from traces to the annotation queue to datasets & experiments.
Before building any infrastructure, spend 30 minutes reading through real agent traces. You'll learn more about failure patterns from this than from any automated system. LangSmith's traces and annotation queues are excellent for this.
Define unambiguous success criteria for a single task
If two experts can't agree on pass/fail, the task needs refinement:
Unclear success: "Summarize this document well."
Clear success: "Extract the 3 main action items from this meeting transcript. Each should be < 20 words and include an owner if mentioned."
Separate capability evals from regression evals
You need both because they serve different purposes. Capability evals push your agent forward by measuring progress on hard tasks, while regression evals protect what already works. Without the separation, you'll either stop improving because you're only guarding existing behavior, or you'll ship regressions because you're only chasing new capabilities.
Capability evals answer "what can it do?"Start with a low pass rate and give you a hill to climb.
Regression evals answer "does it still work?"Should have ~100% pass rate and catch backsliding.
Ensure you can identify and articulate why each failure occurs
If you can't articulate why something failed, you need more error analysis before building automated evals. This is where you should spend 60-80% of your eval effort. Follow this process:
Gather traces: Collect representative failures from production or testing
Open coding: Review traces with a domain expert, noting every issue you see without pre-categorizing (or use our annotation queue to have subject matter experts review traces on their own)
Categorize: Group issues into a failure taxonomy (prompt problems, tool design problems, model limitations, tool failures, data gaps, etc.)
Iterate: Keep reviewing until you stop discovering new failure categories
Once you've categorized, the fix depends on the root cause:
Prompt problem: The agent misunderstood because your instructions were unclear → fix the prompt
Tool design problem: The tool interface made it easy for the agent to make mistakes → redesign parameters, add examples, clarify boundaries
Model limitation: Instructions were clear but the LLM doesn't generalize to edge cases → add examples, try a different architecture, or use a different model
Don't know yet: You haven't looked at enough failures to see the pattern → do more error analysis first
Assign eval ownership to a single domain expert
Someone needs to own the eval process: maintaining datasets, recalibrating judges, triaging new failure modes, and deciding what "good enough" means. Ideally one domain expert acts as the quality arbiter for ambiguous cases rather than designing by committee.
Rule out infrastructure and data pipeline issues before blaming the agent
The Witan Labs team found that a single extraction bug moved their benchmark from 50% to 73%. Infrastructure issues (timeouts, malformed API responses, stale caches) frequently masquerade as reasoning failures. Check the data pipeline first.
Choose your evaluation level
imageSingle-step vs. Full-turn vs. Multi-turn evalsNot all evals test the same thing. Match your evaluation to the right level of agent behavior. For a deep dive on each level, see "Agent Observability Powers Agent Evaluation".
Single-step vs. Full-turn vs. Multi-turn evals
☑️ Understand the three evaluation levels: single-step (run), full-turn (trace), and multi-turn (thread)
☑️ Start with trace-level (full-turn) evals, then layer in run-level and thread-level as needed
Deep dive
Single-step evals
These answer: "Did the agent choose the right tool?" "Did it generate a valid API call?" They're the easiest to automate but require stable agent architecture; if you're still changing your tool definitions, run-level evals may break.
Full-turn evals
This is where most teams should start. Grade a full trace across three dimensions:
Final response: Is the output correct and useful?
Trajectory: Did the agent take a reasonable path? (Not necessarily the exact path you expected, just a valid one)
State changes: Did the agent create the right artifacts? (files written, database updated, meeting scheduled, etc.)
State change evaluation is often overlooked but critical for agents that do things, not just say things. For example, if your agent schedules meetings, don't just check that it said "Meeting scheduled!" Verify the calendar event actually exists with the right time, attendees, and description. If it writes code, run the code. If it updates a database, query the rows. The final response can say "Done!" while the actual state is wrong.
Multi-turn evals
The hardest level to implement, layer them in after your trace-level evals are solid.
Practical tip: Use N-1 testing. Take real conversation prefixes from production (the first N-1 turns) and let the agent generate only the final turn. This avoids the compounding error problem of fully synthetic multi-turn simulations.
Start with trace-level (full-turn) evals, then layer in run-level and thread-level as needed
Trace-level gives you the most signal per eval. Run-level is useful for debugging specific steps. Thread-level matters when your agent has multi-turn conversations.
Dataset construction
image☑️ Ensure every task is unambiguous, with a reference solution that proves it's solvable
☑️ Test both positive cases (behavior should occur) and negative cases (behavior should not occur)
☑️ Ensure dataset structure matches your chosen evaluation level
☑️ Tailor datasets to your agent type (coding, conversational, research)
☑️ Generate seed examples if you lack production data
☑️ Source from dogfooding errors, adapted external benchmarks, and hand-written behavior tests
☑️ Set up a trace-to-dataset flywheel for continuous improvement
Deep dive
Ensure every task is unambiguous, with a reference solution that proves it's solvable
Ambiguous: "Find me good flights to NYC."
Unambiguous: "Find roundtrip flights from SFO to JFK, departing Dec 15-17, returning Dec 22, under $400, economy class."
If the agent can't possibly succeed (missing info, impossible constraints), the task is broken, not the agent. Include a reference solution for every task so you can prove it's solvable and have a baseline to grade against.
Test both positive cases (behavior should occur) and negative cases (behavior should not occur)
If you only test "did it search when it should?", you'll optimize for an agent that searches everything. Test the negative cases too. Include examples designed to falsify your assumptions, not just confirm expected behavior.
Ensure dataset structure matches your chosen evaluation level
Run-level (single-step) evals need reference tool calls or decisions
Trace-level (full-turn) evals need expected final outputs and/or state changes
Thread-level (multi-turn) evals need multi-turn conversation sequences with expected context retention
Tailor datasets to your agent type (coding, conversational, research)
Coding agents: Include deterministic test suites (unit tests that pass/fail) alongside quality rubrics
Conversational agents: Include multi-dimensional criteria, task completion and interaction quality (empathy, clarity)
Research agents: Include groundedness checks (are claims supported by sources?) and coverage checks (are key facts included?)
Generate seed examples if you lack production data
Define the key dimensions of variation for your task (query complexity, topic, edge case type). Manually create ~20 example inputs covering those dimensions, run them through your existing agent, review and modify them to store as reliable ground truths.
Practical tip: 20-50 hand-reviewed examples you're confident in will outperform hundreds of synthetic examples you haven't verified. Quality beats quantity here!
Source from dogfooding errors, adapted external benchmarks, and hand-written behavior tests
Once you're past the cold start, you need an ongoing pipeline for discovering new evals. Three strategies work well together:
Dogfood your agent daily and turn every error into an eval. This is different from production monitoring; it's your team intentionally stress-testing the agent across real workflows.
Pull and adapt tasks from external benchmarks like Terminal Bench or BFCL. Don't run full benchmarks in aggregate; cherry-pick tasks that test capabilities you care about and adapt them for your agent.
Write focused tests by hand for specific behaviors you think are important, like "does the agent parallelize tool calls?" or "does it ask clarifying questions for vague requests?"
See "How we build evals for Deep Agents" for a concrete example of this approach.
Grader design
image☑️ Select specialized graders per evaluation dimension: default to code-based for objective checks, LLM-as-judge for subjective assessments, human for ambiguous cases, and pairwise for version comparison
☑️ Distinguish guardrails (inline, runtime) from evaluators (async, quality assessment)
☑️ Prefer binary pass/fail over numeric scales
☑️ Calibrate LLM-as-a-Judge graders to human preferences
☑️ Grade the outcome, not the exact path, and build in partial credit for incremental progress
☑️ Use custom evaluators derived from your error analysis, not generic off-the-shelf metrics
Deep dive
Select specialized graders per evaluation dimension
Grader Type
Best For
Watch Out For
Code-based
Deterministic checks, tool call verification, output format, execution results
Can false-fail on valid but unexpected formats
LLM-as-judge
Nuanced quality, rubric-based scoring, open-ended tasks
Requires calibration with humans (see Align Evals)
Human
Calibration, subjective criteria, edge cases
Expensive, slow, hard to scale
Default to code-based evaluators when there's an objectively correct answer. LLM-as-judge grading for objective tasks can be unreliable, inconsistent judgments can mask real regressions. Switching to deterministic comparison can often eliminate inconsistency and provide better signal. Reserve LLM-as-judge for genuinely subjective assessments.
Practical Tip: Rather than trying to create a correctness evaluator, decompose evaluation into specialized graders per dimension rather than one monolithic grader.
For example: the Witan Labs team built 5 specialized evaluators (content accuracy, structure, visual formatting, formula scenarios, text quality), each with dimension-appropriate thresholds. This gives you clearer signal about what's actually failing!
Distinguish guardrails from evaluators
Guardrails
Evaluators
When
During execution, before user sees output
After generation, asynchronously
Speed
Milliseconds (must be fast)
Seconds to minutes (can be expensive)
Purpose
Block dangerous or malformed outputs
Measure quality and catch regressions
Examples
PII detection, format validation, safety filters
LLM-as-judge scoring, trajectory analysis
Safety checks and format validation are guardrails, they should run inline. Quality assessment and regression testing are evaluators, they run async. Don't confuse the two.
Prefer binary pass/fail over numeric scales
A 1-5 scale introduces subjective differences between adjacent scores and requires larger sample sizes for statistical significance. Binary forces clearer thinking: either the agent succeeded or it didn't. You can always decompose a complex task into multiple binary checks.
Note: recent research suggests short scales (0-5) may yield stronger human-LLM alignment when using LLM-as-judge specifically, but binary remains simpler for human reviewers and faster iteration.
Calibrate LLM-as-a-Judge graders to human preferences
Start with 20+ labeled examples using LangSmith's Align Evaluator feature, then grow toward ~100 for production-grade confidence
Include reasoning in the judge's output; this improves accuracy and lets you audit why it scored something (Anthropic's Demystifying Evals emphasizes this as well)
Recalibrate regularly; judges drift over time and no single judge is uniformly reliable across all benchmarks
Use few-shot examples to improve evaluator consistency; corrections can auto-populate as few-shot examples in LangSmith
Grade the outcome, not the exact path, and build in partial credit for incremental progress
Agents find creative solutions. As Anthropic puts it in Demystifying Evals: "Don't grade the path the agent took, grade what it produced." If you require "must call tool A → B → C in that order," you'll fail agents that found a smarter route. Better: "Did the meeting get scheduled correctly?" not "Did it call check_availability before create_event?"
An agent that correctly identifies the problem but fails at the final step is better than one that fails immediately. Build in partial credit so your metrics reflect incremental progress.
Use custom evaluators derived from your error analysis, not generic off-the-shelf metrics
Off-the-shelf metrics like "helpfulness" or "coherence" create false confidence. The evaluators that matter are the ones that catch your specific failure modes, discovered through the error analysis process above.
Running & iterating
image☑️ Distinguish between offline, online, and ad-hoc evaluation and use all three
☑️ Run multiple trials per task to account for non-determinism
☑️ Manually review traces for failed evaluations to verify grader fairness
☑️ Ensure each trial runs in a clean, isolated environment with no shared state
☑️ Tag evals by capability category, document what each measures, and track efficiency metrics (step count, tool calls, latency) alongside quality
☑️ Recognize when pass rates plateau and evolve your test suite accordingly
☑️ Only keep evals that directly measure a production behavior you care about
☑️ Invest in tool interface design and testing, not just prompt optimization
☑️ Distinguish between task failures (agent got it wrong) and evaluation failures (grader got it wrong)
Deep dive
Distinguish between offline, online, and ad-hoc evaluation and use all three
Most of this checklist focuses on offline evaluation, and that's intentional. Offline evals are where you improve with: curated datasets, controlled experiments, iterating before you ship. You'll also need online and ad-hoc evaluation once your agent hits production.
Timing
What It Is
When to Use
Offline
Curated datasets, run pre-deployment
Testing changes before they ship
Online
Continuous evaluation on production traces
Catching failures in real traffic
Ad-hoc
Exploratory analysis of ingested traces
Discovering patterns you didn't anticipate (see Insights)
The Production readiness section below covers setting up online evaluations and scheduling ad-hoc trace exploration in detail.
Run multiple trials per task to account for non-determinism
Model outputs vary between runs. Use multiple repetitions if not cost prohibitive. When running multiple trials, compute confidence intervals before declaring improvement—single-run benchmarks are noisy. For non-deterministic agents, consider using pass@k (at least one of k attempts succeeds) or pass^k (all k attempts succeed) metrics depending on your product requirements.
Track operational metrics alongside quality: turns taken, token usage, latency, cost per task. An agent that's 95% accurate but 10x slower might not be an improvement.
Tag evals by capability category, document what each measures, and track efficiency metrics alongside quality
Group evals by what they test, not where they come from. Categories like file_operations, retrieval, tool_use, memory, and conversation give you a "middle view" of performance between a single aggregate score and individual test results. Add a docstring to each eval explaining how it measures an agent capability. This keeps intent clear as the suite grows and lets you run targeted subsets (e.g., only tool_use evals after changing a tool definition).
Attach metadata to every experiment so you can filter, group, and compare runs across dimensions that matter. This makes it easy to answer questions like "did switching from GPT-4.1 to Claude Sonnet improve accuracy?" or "which prompt version regressed on this dataset?" without digging through logs. LangSmith automatically captures git info when available, but explicitly tagging model and prompt metadata pays off quickly as your experiment volume grows.
Once quality is establis
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み