PinterestのCDCベース取り込みフレームワークがデータベース遅延を24時間から15分に短縮
PinterestはKafka、Flink、Spark、Icebergを活用した次世代CDCベースのデータベース取り込みフレームワークを導入し、データ利用可能までの遅延を24時間以上から15分に短縮し、変更レコードのみを処理する効率的なシステムを構築した。
キーポイント
劇的なデータ遅延の短縮
新システムにより、データが利用可能になるまでの遅延時間が24時間以上からわずか15分に大幅に短縮された。
効率的な変更データキャプチャ(CDC)アーキテクチャ
変更されたレコードのみを処理するCDCベースのアプローチを採用し、増分更新と削除をサポートしている。
大規模スケーラビリティとコスト最適化
ペタバイトレベルのデータを数千のパイプラインで処理可能なスケーラビリティを実現し、コストと効率を最適化している。
現代的なデータ技術スタックの統合
Kafka、Flink、Spark、Icebergといった最新のデータ処理技術を組み合わせたフレームワークを構築した。
影響分析・編集コメントを表示
影響分析
この技術革新は、大規模データプラットフォームにおけるリアルタイム性と効率性の新たな基準を示しており、特にEコマースやソーシャルメディアなどデータ駆動型ビジネスに大きな影響を与える可能性がある。CDCベースのアーキテクチャは、データエンジニアリングのベストプラクティスとして業界全体に波及効果をもたらすだろう。
編集コメント
大規模プラットフォームにおけるデータ遅延の劇的な改善は、データ駆動意思決定の速度を根本から変える可能性があり、業界全体のデータインフラ設計に影響を与える重要なケーススタディと言える。
Pinterest は、Kafka、Flink、Spark、Iceberg を活用した次世代の CDC ベースデータベース取り込みフレームワークを立ち上げました。このシステムはデータ利用までの遅延を 24 時間以上から 15 分へ短縮し、変更されたレコードのみを処理し、インクリメンタルな更新と削除をサポートします。また、数千ものパイプラインにわたるペタバイトレベルのデータにもスケーリング可能で、コストと効率の最適化を実現しています。
*By Leela Kumili*
原文を表示
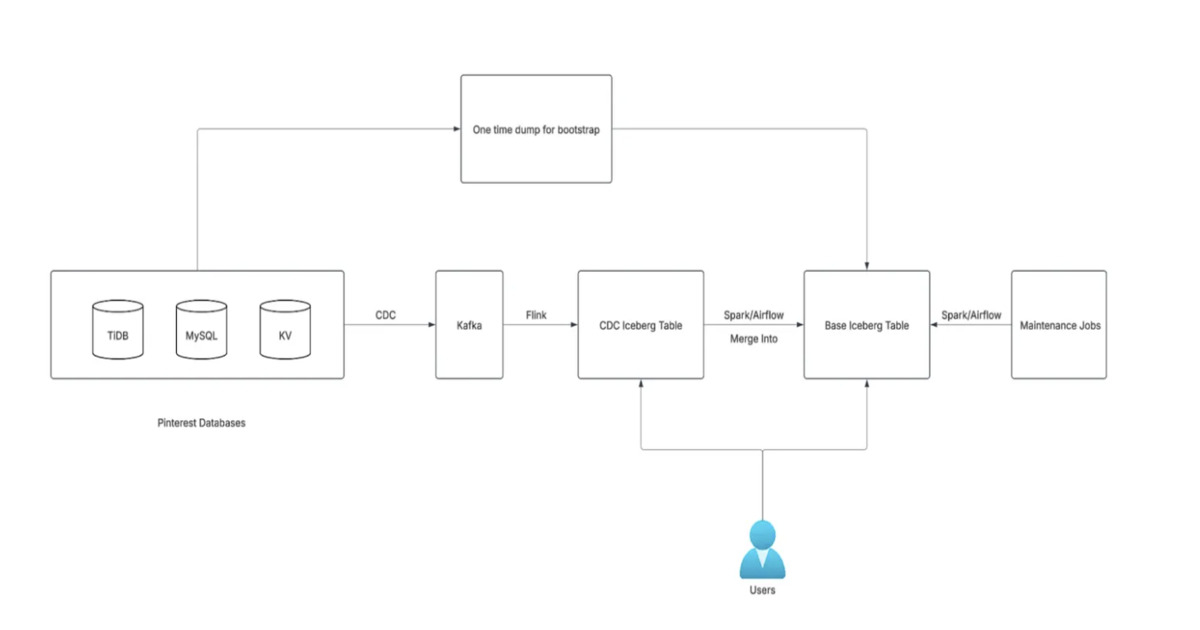
Pinterest launched a next-generation CDC-based database ingestion framework using Kafka, Flink, Spark, and Iceberg. The system reduces data availability latency from 24+ hours to 15 minutes, processes only changed records, supports incremental updates and deletions, and scales to petabyte-level data across thousands of pipelines, optimizing cost and efficiency.
*By Leela Kumili*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み