Krea 2 技術レポート(59 分読了)
Krea は、単一の polished な出力に収束する既存の画像生成モデルの問題を解決し、多様な美学やスタイルを探索できる「創造的探求」のための基盤モデル Krea 2 を発表しました。
キーポイント
創造的探求への焦点転換
既存の生成 AI が信頼性向上のために特定の美学に収束する傾向にある中、Krea 2 は多様なスタイルやムードを探索できることを主目的としたモデルとして設計されています。
大規模データ基盤とトレーニングパイプライン
ゼロから構築した大規模なデータインフラと分散トレーニングフレームワークを用い、事前学習から RL(強化学習)に至る多段階の学習プロセスでモデルを訓練しています。
高度なアーキテクチャ改良
DiT 基盤に iREPA、改善された VAE、Qwen3-VL の統合に加え、GQA や sigmoid-gated attention などの効率化・安定化技術を採用しています。
詳細なキャプション学習
モデルは画像の視覚的詳細を記述した豊富で慎重に構築されたキャプションから学習しており、短い入力でも意図する分布に到達できるように設計されています。
影響分析・編集コメントを表示
影響分析
この発表は、画像生成 AI の進化が「高品質な出力の安定化」から「多様な表現可能性の拡大」へとパラダイムシフトしていることを示唆しています。特に、クリエイターが単なるツールとしてではなく、スタイル探索のパートナーとして AI を活用できる環境を整える点で、次世代の生成 AI ツール開発に大きな影響を与える可能性があります。
編集コメント
既存の生成 AI が「完成された画像」を作ることに特化しすぎた現状に対し、Krea は「創造的な探求」を主軸に据えたアプローチで対抗しています。技術的な詳細(iREPA や GQA など)も非常に具体的であり、業界のトレンド転換を示す重要なレポートです。
イントロダクション
過去数年間、画像生成は目覚ましい進歩を遂げてきました。拡散モデルやフローマッチングモデルは、高解像度の画像を生成し、鮮明なフォトリアリズムと安定した構造を実現し、高密度のテキストをレンダリングし、広範な世界知識をエンコードし、ユーザーのプロンプトを精密な詳細に従って実行できます。これらの改善は、スケーラブルなトランスフォーマーアーキテクチャ、キャプション付けおよびテキストエンコーダーの向上、より優れた潜在表現(latent representations)、パイプライン化されたポストトレーニング技術など、いくつかの相互作用する要因によって推進されてきました。しかし、分野がこれらの機能に対する信頼性の最適化を進めるにつれて、多くのシステムは限られたデフォルトの美学に収束してきました。効果的な生産ツールである一方で、これはクリエイティブな探求のためのエンジンとしては効果が薄れます。なぜなら、ユーザーはしばしば単一の磨き上げられたデフォルトを受け取るのではなく、スタイル、ムード、構成、視覚的方向性 across 検索する必要があるからです。
これらの制限に対処するため、私たちはKrea 2を発表します。これはクリエイティブな探求に焦点を当てた一連のファウンデーションモデルです。Krea 2 のモデルは、画像生成が探求的な媒体であるべきだという信念に基づいて構築されています:多くの美学を網羅するほど表現力豊かであり、かつクリエイターがそれらをナビゲートできるほど制御可能であるべきです。
私たちは、広範な世界知識とスタイルのカバレッジを持つ包括的な事前学習データセットを策定するために、大規模なデータインフラストラクチャと分散トレーニングフレームワークを一から構築しました。
このインフラストラクチャを用いて、事前学習、中間学習、教師あり微調整(SFT)、選好最適化、強化学習(RL)にわたる多段階パイプラインを通じて表現力豊かなモデルを訓練します。各段階は、モデルの出力分布を段階的に洗練させるように設計されています。私たちは徹底的なアブレーション研究を通じて、シンプルかつ高性能な diffusion transformer (DiT) アーキテクチャを開発しました。当モデルは収束を加速するいくつかのコンポーネントを組み込んでおり、これには iREPA、改良版 VAEs、および Qwen3-VL が含まれます。また、テキストエンコーダ特徴に対する grouped-query attention (GQA)、sigmoid-gated attention、軽量なタイムステップ変調、および 多層特徴集約 を含む、いくつかのアーキテクチャ上の改良点も統合しており、これらが訓練の安定性と効率性を向上させます。
強力なベースモデルは、ユーザーがその分布の関心のある部分に確実に到達できる場合にのみ有用です。トレーニングでは、モデルは画像の詳細な視覚的詳細を記述する豊かで慎重に構築されたキャプションから学習します。しかし実際には、ユーザーの入力はより短く、より曖昧であり、多くの異なる表現習慣によって形成されます。一部のユーザーは自然言語でシーンを描写しますが、他のユーザーは雰囲気やスタイル、あるいは参照画像に向かってジェスチャーを示します。これにより、モデルが学習した条件付け空間と、推論時に創造的意図が表現される方法との間にギャップが生じます。
このギャップを縮めるために、テキストおよび画像入力から Krea 2 をより探索可能で制御可能にする 2 つのシステムを構築しました。1 つはプロンプトエクスパンダー、もう 1 つはスタイル参照システムです。プロンプトエクスパンダーは、ユーザーの意図を上書きすることなく、単純または不十分なユーザープロンプトをより豊かな視覚的方向へマッピングします。これはオープンソースの大規模言語モデル(LLM)上で 2 段階の教師あり微調整(SFT)と強化学習(RL)パイプラインを通じてトレーニングされ、その目的は画像品質の向上だけでなく、創造的な多様性と制御可能な探索を促すことです。このテキストインターフェースを補完するスタイル参照システムでは、言葉が不十分な場合にユーザーが画像を通じて視覚的意図を表現できます。これにより、1 つ以上の参照画像からスタイルや雰囲気を注入しつつ、コンテンツの漏洩を最小限に抑えながら、スタイル強度と加重されたスタイル混合に対する微細な制御を提供します。
これらすべてのコンポーネントを合わせると、Krea 2 は探索的生成のための基盤モデルとして定義されます。単一の磨き上げられたデフォルト値の最適化に留まらず、Krea 2 は広範な視覚空間を露呈し、テキストと画像に基づく制御の両方を用いてユーザーがその空間を実用的に移動できるように設計されています。Krea 2 は、テキストから画像への生成における Artificial Analysis リーダーボードでトップ 10 に入るモデルの一つであり、独立した研究所からのモデル群の中では第 2 位を獲得しています。Krea 2 は包括的なベースラインとして機能し、競争力のあるパフォーマンスを維持しながら、創造的な生成体験を可能にします。
データ
データキュレーションの原則
データパイプラインの詳細に入る前に、私たちの目的にとって何が「良いデータのミックス」を構成するのかを明確にしておくことが重要です。良いミックスは、「高品質」な画像だけで構成されるものではありません。表現力豊かでスタイルが多様なモデルを構築するという私たちの目標を踏まえると、多様性と広範なドメインのカバー範囲が不可欠です。私たちは、美観スコアや画像品質評価(IQA)モデルを用いた従来のモデルベースのフィルタリングは、暗黙的なバイアスを導入すると主張します。例えば、そのような手法では、モーションブラーや柔らかさが意図的な芸術的選択である場合でも、ぼやけた画像を低品質と分類してしまう可能性があります。
さらに、キャプションが画像を正確に記述している限り、望ましくない画像であっても下流のユースケースにおいて有用であると主張します。なぜなら、モデルがその望ましくない振る舞いを正確に理解するため、これらのサンプルは後で生成をその分布から遠ざけるために使用できるからです。
これらの理由により、私たちは事前学習データセットを以下の項目のみをフィルタリングすることで構築しました:
- 重複したサンプルおよび過剰に表現された概念。
- VLM(Vision-Language Model)が画像の重要な側面を捉えることに一貫して失敗するサンプル。
- 望ましくないバイアスやアーティファクトを引き起こすサンプル。
- 低解像度で信頼性を持ってモデル化することが困難すぎるほど視覚的複雑度が高いサンプル。
- AI 生成のサンプル
これらの条件は、広範なカバレッジを備えつつ、テキストから画像への整合性の欠如やアーティファクトを回避する事前学習データセットを形成します。
重要なのは、私たちの事前学習ミックスにおいて AI 生成画像を一切使用しないことです。合成データや蒸留(distillation)は、モデルの能力を獲得するための効果的な近道となり得ます。しかし、私たちは、AI 生成画像がわずかな割合でも含まれると、モデルの出力分布にバイアスが生じることが分かりました。これは、合成画像が学習しやすい傾向にあるためで、結果的にモデル品質に上限を課すことになります。そのため、私たちはこれらの画像をフィルタリングするために社内開発した分類器を設計しました。
キャプション生成
キャプション生成には多段階のアプローチを採用しています。まず、各対象画像に対して OCR モデルを実行し、表示されているテキストを抽出します。2 段目の工程では、OCR の結果と利用可能なメタデータ(カメラ設定、既知のエンティティなど)をキャプション生成モデルに提供し、抽出されたテキストに加えて世界知識も取り入れた、情報豊富なキャプションを作成します。
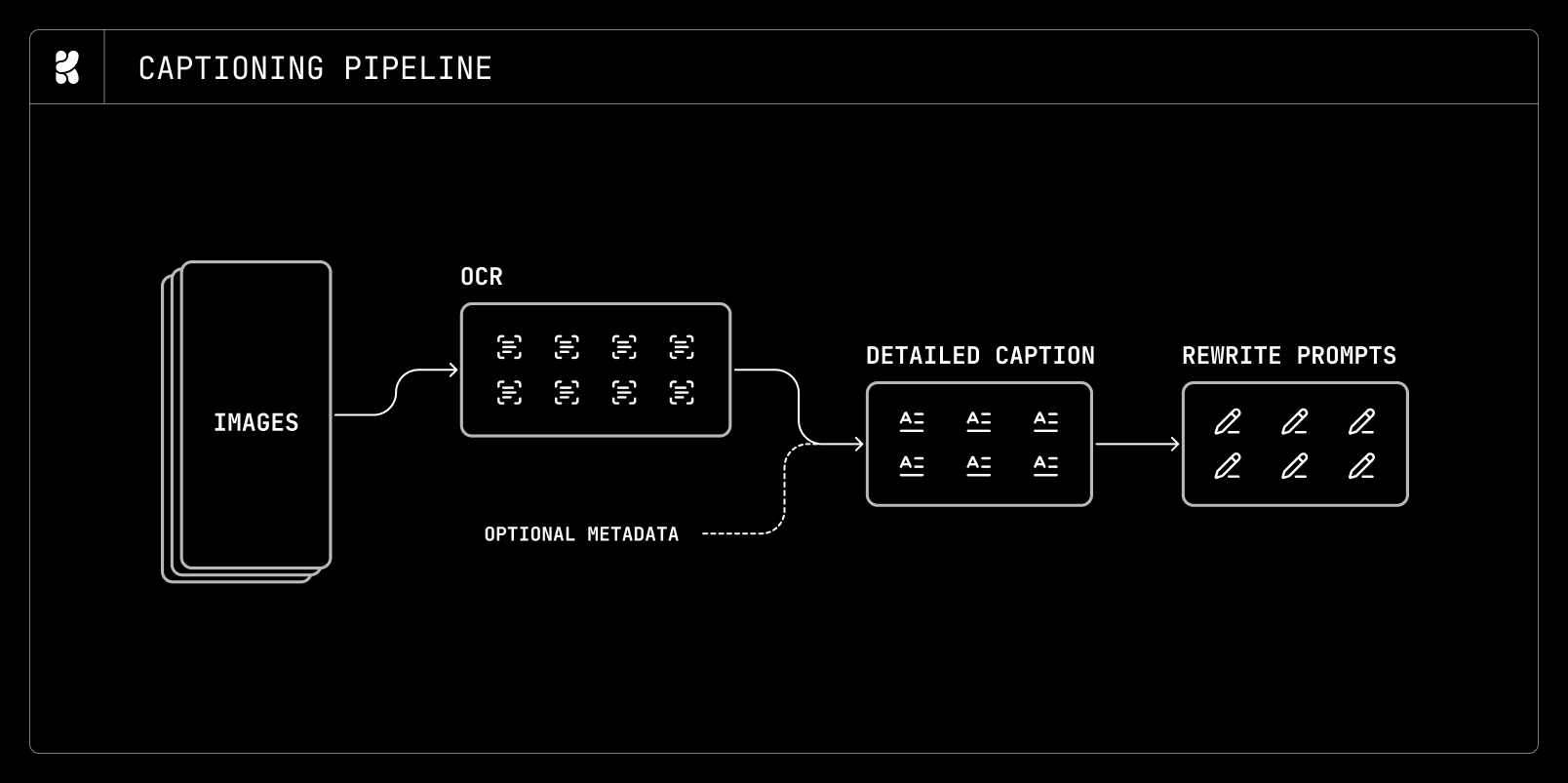
*一般的なキャプション生成パイプライン*
文脈に富み、長文の自然言語によるキャプションが得られた後、よりコスト効率の高い大規模言語モデル(LLM)を用いて、これをさまざまな長さや形式へと再フォーマットし、多様なプロンプトスタイルに対してモデルを学習させます。経験則として、長いプロンプトでの訓練は密な教師信号を提供し、収束速度の向上と訓練損失の低下をもたらすことが分かっています。しかし、多くの下流タスクや実用的なユースケースにおいては、短く中程度の長さのプロンプトに対する性能も依然として重要です。そのため、主に長いキャプションで訓練を行いつつ、訓練を通じてモデルが短いおよび中程度の長さのプロンプトにも常に曝露されるように配慮しています。
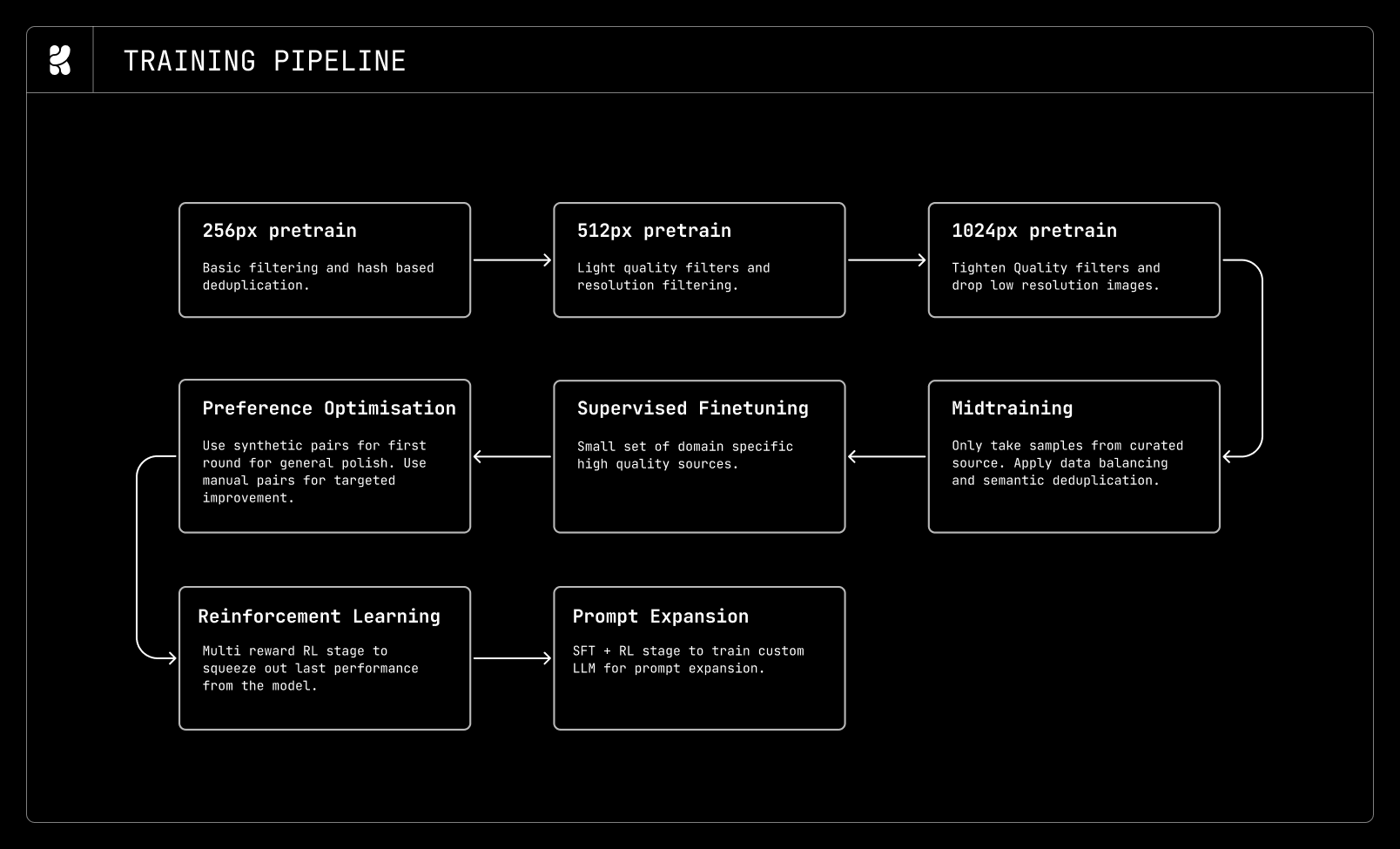
*全体の訓練パイプラインとデータステージ*
事前学習用データ
Pretraining data spans 256px, 512px, and 1024px resolution stages. Progressively scaling the resolution forms a curriculum-learning strategy: we dedicate the majority of FLOPs to the low-resolution stages to build core model capabilities efficiently, then equip the model with high-fidelity generation capabilities as the training resolution increases.
Low-resolution pretraining is the stage at which basic text-image alignment and structure are learned. At this stage the dataset is on the order of billions of images, so we rely heavily on inexpensive CPU-based filters to remove low-quality images. These range from simple broken-file, resolution, and aspect-ratio filters that remove unqualified images, to Laplacian filters that remove images with extreme textures and noise patterns.
As an example, one issue we encountered while pretraining K2 was a tendency for the model to generate flat-color backgrounds and border artifacts. To mitigate this, we used RGB entropy, white/black pixel ratios, custom heuristics, and in-house classifiers to filter out samples that induced this behavior.
自社向け分類器を構築する際、効果的な戦略の一つは、大規模な VLM(視覚言語モデル)を用いてフィルタリングタスク専用のシステムプロンプトを作成し、疑似ラベル付きデータセットを生成した上で、小規模な DINOv3 または SigLIP-2 ベースの分類器を訓練して、大規模なフィルタリングを実行することです。低解像度段階で GPU 計算リソースを必要とするフィルタリングモデルは、効率化のためにパラメータ数を 1B(10 億)未満に抑えます。
低解像度段階での重複除去には、主にコストの低いハッシュベースの方法を採用し、md5、phash、colorhash を組み合わせて、最小限の計算リソースで重複画像を削除します。デフォルトの 8x8 phash は色情報を考慮しておらず偽陽性率が高いため、より堅牢な重複除去のために 12x12 phash と colorhash を組み合わせます。
トレーニング解像度をスケールさせる際、画像品質および美的評価フィルタを導入します。重要なのは、これらの品質スコアが極端に品質の低い画像を除外する目的でのみ使用され、スコアに基づいて画像を過剰サンプリングするために用いられない点です。さらに、画像複雑度スコアと OCR 結果からのテキスト密度を用いて、低解像度では意味のある表現ができないテキストやコンテンツを含む画像を除外します。トレーニングの進行に応じて、品質、複雑度、およびテキスト密度の閾値を調整します。
従来の品質フィルタを超えて、事前学習コーパスのサンプル上で計算された SigLIP-2 埋め込み表現に対して スパース自己符号化器 (SAE) を訓練します。SAE の訓練後、各 SAE 特徴をその上位 k 個の活性化サンプルに基づいて VLM(視覚言語モデル)で注釈付けします。これらの注釈付き特徴は、各画像から主要な SAE 特徴を抽出する教師なしタグ付けシステムを形成し、明示的な分類器を訓練することなく明確な視覚アーティファクトをフィルタリングするのに役立ちました。
ミッドトレーニングデータ
事前学習段階とは異なり、ミッドトレーニングでは特定の視覚ドメインにおいて優れたスタイルカバレッジと高品質な画像を提供することが知られている特定の画像ソースを明示的に選択します。一方、事前学習は一般的なプールから始まるボトムアッププロセスであるのに対し、ミッドトレーニングデータはトップダウンでキュレーションされます:まずドメインとソースが選ばれます。ミッドトレーニングは、一般的な事前学習分布と高品質な SFT(Supervised Fine-Tuning)分布を滑らかに橋渡しする重要な段階です。分布の質を向上させるため、セマンティッククラスタリングを導入し、世界知識のカバレッジを確保するために検索ベースの戦略を使用します。
【Automatic Data Curation for Self-Supervised Learning】(https://arxiv.org/abs/2405.15613) のアプローチに基づき、FAISS を用いて階層的 k-means クラスタリング(hierarchical k-means clustering)を実行し、その後サンプリングを行うことで、計算リソースを浪費することなく長尾の視覚概念を保持します。階層クラスタを計算した後、各クラスタ中心点に最も近い画像を VLM(Vision Language Model: 視覚言語モデル)が調査し、クラスタの名前付けと、必要に応じてフラグ付けを行います。人間によるフラグ付きクラスタのレビュー後、低品質または問題のあるいくつかのクラスタは削除しました。さらに残りのリーフクラスタ内の画像間で SigLIP 類似度を計算することで、意味的な重複データを除去します。
画像生成モデルの重要な機能の一つは、ユーザーが単に名前を参照するだけで既知の実体を忠実に表現できることです。スポーツ選手や俳優などの一部の実体は、多くの他の実体を含む意味的なクラスターに属することがあり、単純な階層的サンプリングではそれらが除外されるリスクがあります。これを解決するため、Danker を用いて英語版ウィキペディア上で PageRank を実行し、ランク上位 90% の記事のみを保持しました。その後、Wikidata メタデータに基づき表現不可能な対象を記述する記事をすべて除外し、残りの約 500 万の概念について、データセット内のすべてのキャプションに対して全文検索を行い、カバレッジを評価しました。サンプリング時には、キャプションが稀な概念を参照している画像を優先しました。最後に、このカバレッジ分析を結果として得られたサンプルに対して再度実行し、初期データセットに含まれていた概念が完全に除外されていないことを確認しました。
教師あり微調整データ
教師あり微調整(SFT: Supervised Finetuning)段階では、個々の視覚ドメインに焦点を当てた小規模で手作業で選別されたデータセットを使用します。十分なボリュームに達した後は、データセットの規模よりもその品質の方がはるかに重要であることがわかりました。
アーキテクチャ
アーキテクチャのアブレーション(比較実験)においては、各アブレーションの目的を以下のカテゴリのいずれかに分類することが有用であると発見しました:
- 安定性:トレーニングをより安定させるか?損失や勾配のスパイクを低減するか?
- パフォーマンス:モデルの収束をより速くするものか?もしそうなら、その傾向は長期にわたって、また高解像度においても維持されるのか?
- 効率性:モデルの品質を損なうことなく、パラメータ数、FLOPs(浮動小数点演算回数)、メモリ使用量、または通信要件を削減できるか?
- シンプルさ:他のカテゴリに影響を与えずに、モデルをよりシンプルにできるか?
私たちのアーキテクチャ上の多くの決定は、LLM(大規模言語モデル)分野での採用によって導かれていることに留意すべきである。LLM エコシステムで確立されたアーキテクチャを選択することで、拡散モデルであっても既存のカーネルや最適化を活用することが可能となる。
これらの目標を念頭に置き、以下のベースラインから開始する。
コンポーネント ベースライン アブレーション(単一変数実験) 最終コンポーネント
Attention(注意機構)Multi head attention(マルチヘッドアテンション)GQA, MLA, Gated Sigmoid attention(ゲート付きシグモイドアテンション)GQA with gated sigmoid attention(ゲート付きシグモイドアテンションを備えた GQA)
MLPGeLU MLPSwiGLUSwiGLU
ResidualStandard residualValue residual, LaurelStandard residual(標準的残差接続)
Text encoderT5-XXL encoderT5Gemma, Qwen 2.5 VL, Qwen 3 VL, umT5Qwen 3 VL
ModulationMLP modulation per blockLight modulation with bias(バイアス付き軽量モジュレーション)Light modulation with bias(バイアス付き軽量モジュレーション)
AutoencoderFLUX AEQwen Image VAE, DC-AE, FLUX 2 AE, Internal VAEQwen Image VAE & FLUX 2 AE
Block designSingle stream transformer blockHybrid Stream, Parallel single stream,Single stream transformer block(シングルストリームトランスフォーマーブロック)
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
NormLayer正規化、QKNormRMSNorm、ゼロ中心RMSNorm、Derfゼロ中心RMSNorm、QKNorm
位置符号化3D軸方向RoPEGolden Gate RoPE、MRoPE、正規化RoPE、部分RoPE3D軸方向RoPE
Transformerブロック
まず、GeLU MLPを、LLMアーキテクチャにおいて事実上の標準モジュールとなっている4倍の拡張係数を持つSwiGLU層に置き換えることから始めます。SwiGLUを導入したことで一貫して性能が向上したため、その後のすべてのアブレーション実験においてこれを採用しました。
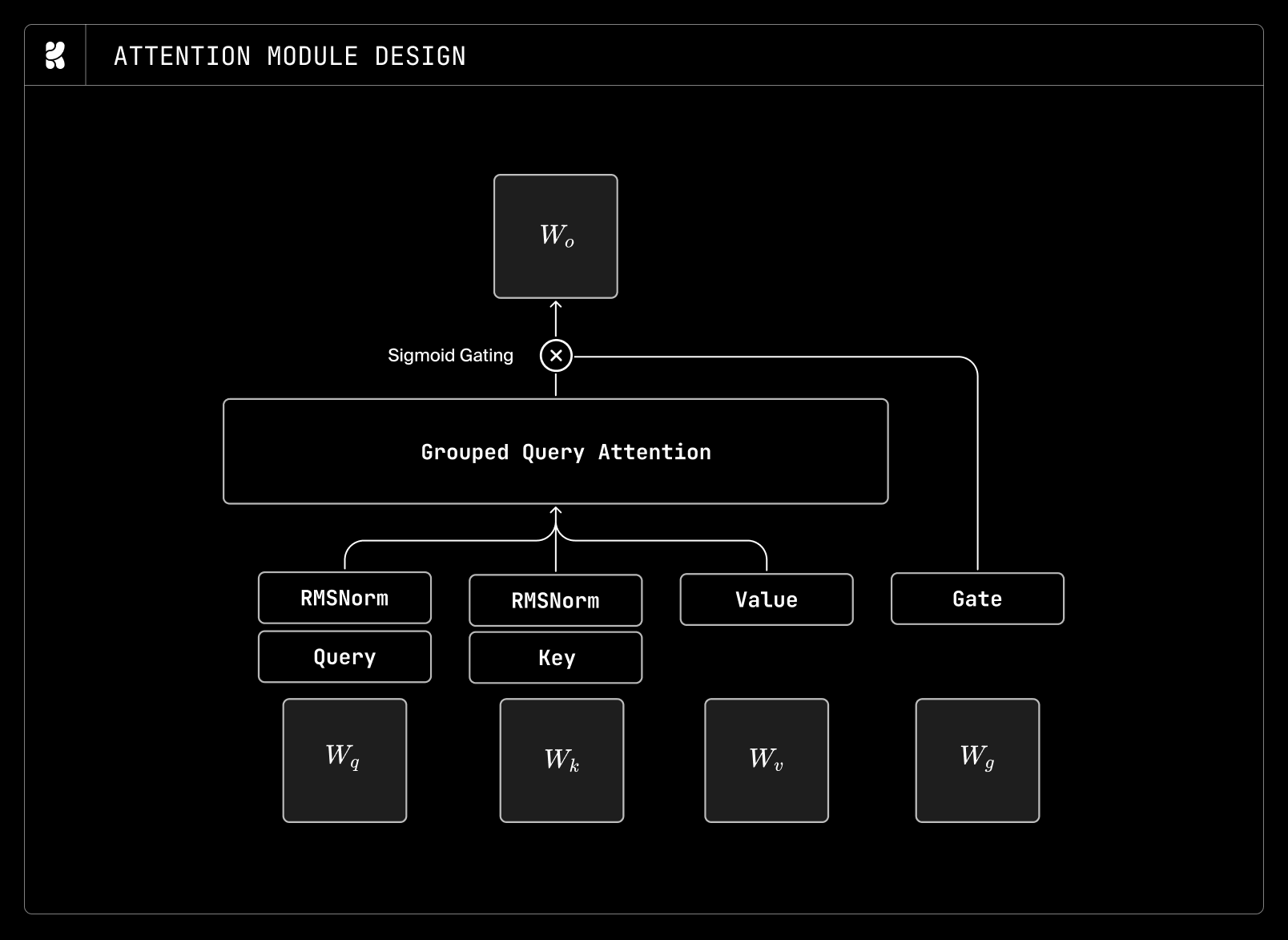
MLP設計を見直した後、マルチヘッドアテンションのベースラインに対する代替案として、GQA、MLA、およびゲート付きシグモイドアテンションを検討しました。その結果、GQAは計算効率の向上をもたらす一方で、性能低下は最小限に抑えられることが分かりました。またMLAも探索しましたが、GQAに対してわずかな性能向上が確認されましたが、追加の計算オーバーヘッドが生じるため採用は見送りました。なお、本稿ではKV圧縮のために上下投影を用いたMLAと、分離されたRoPEを含まない構成を使用しました。これは拡散モデルが純粋にプリフィル(prefill)のみであり、推論時にKVキャッシュを使用しないためです。
GQA に加え、大規模言語モデルのためのゲート付きシグモイドアテンション に従ってゲート付きシグモイドアテンションを追加しました。ゲート付きシグモイドアテンションは、計算量やパラメータのオーバーヘッドをほとんど増やすことなく実装できます。性能面で顕著な向上は見られませんでしたが、学習全体を通じて損失曲線や勾配ノルム曲線に表れるように、より安定した学習ダイナミクスをもたらしました。
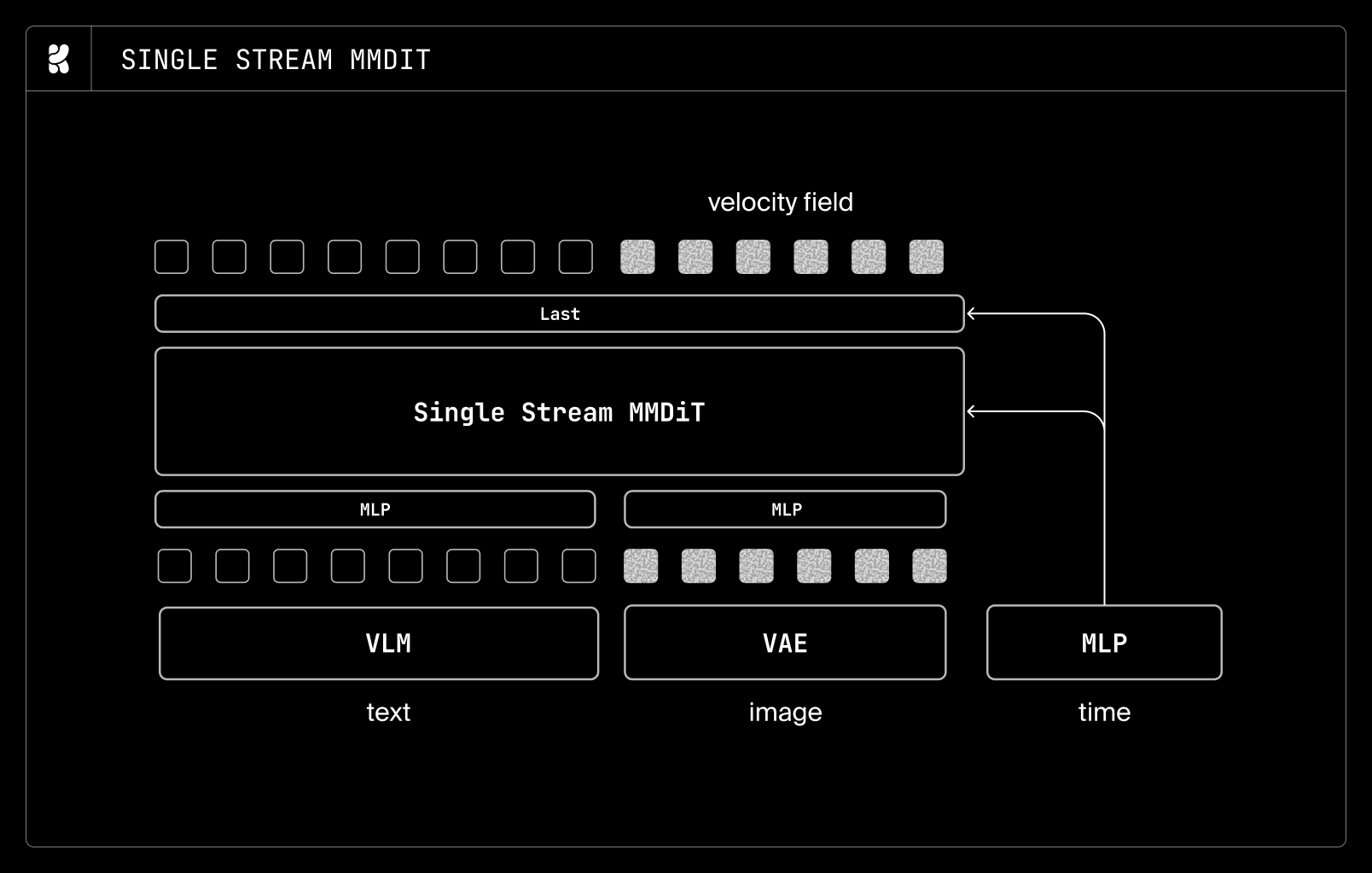
また、モダリティストリームの設計についてもアブレーション実験を行いました。
- シングルストリーム設計:テキストトークンと画像トークンの間でアテンション重みと MLP 重みを共有する標準的なトランスフォーマーブロック。
- ダブルストリーム設計:テキストトークンと画像トークンそれぞれに独立したアテンション重みと MLP 重みを持つ、結合型アテンション。
- ハイブリッドストリーム設計:上記 2 つの組み合わせ。ネットワークの最初の 3 分の 1 にダブルストリーmblock を、残りの 3 分の 2 にシングルストリームブロックを使用する構成。
これら 3 つの設計間で顕著な性能差は観測されませんでしたが、ハイブリッドストリーム設計のみがわずかに他者を上回る結果を示しました。ただし、簡素さを優先するため、最終的なアーキテクチャではシングルストリームブロックを採用しています。
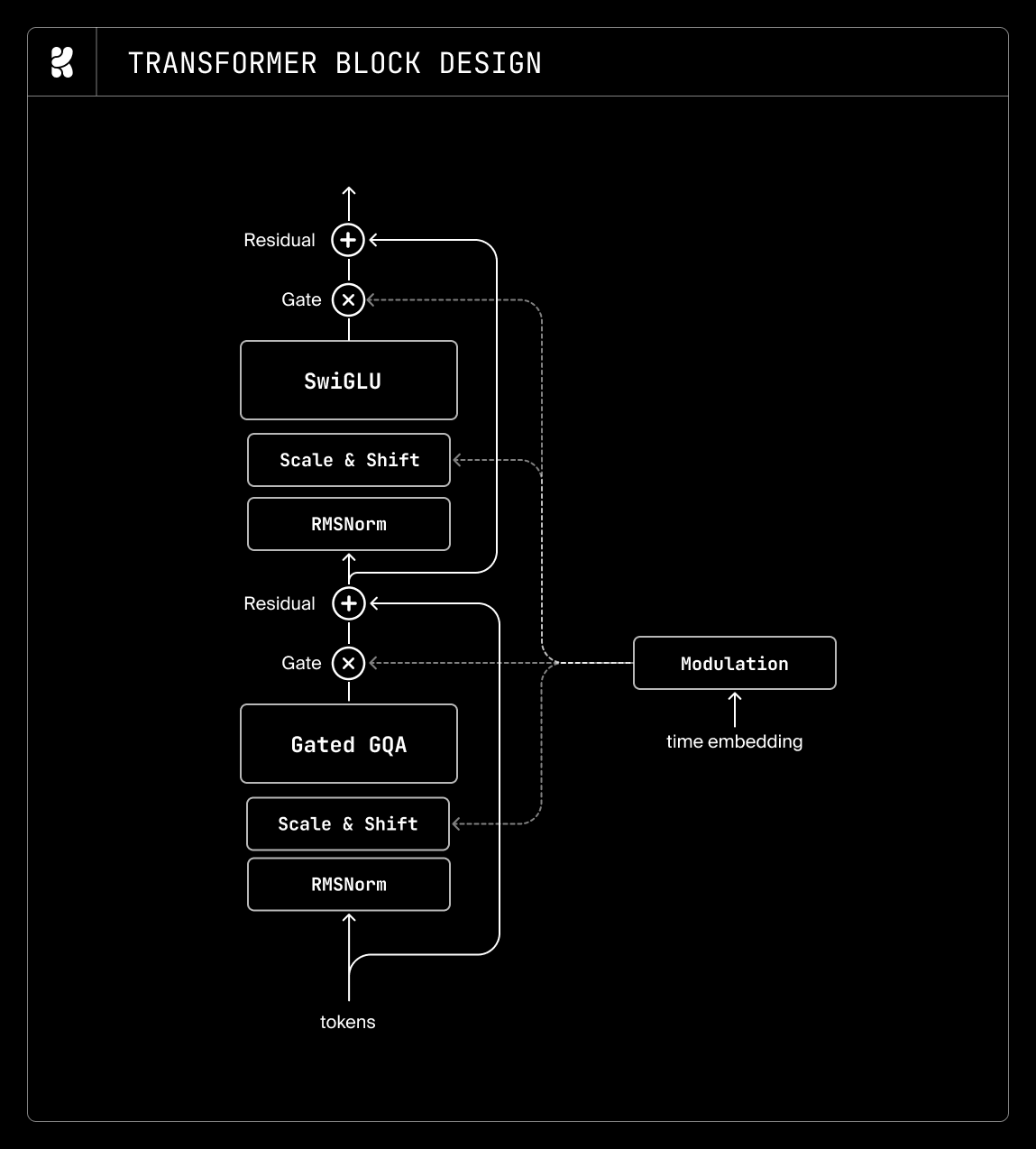
タイムステップ条件付け
多くの MMDiTs は、スケーリング、シフト、ゲート係数を生成するためにブロックごとの MLP を使用しています。これらの MLP ブロックは、総パラメータ数の 20〜30% を占めることがあり、スカラー条件を注入するには過剰であると判断されます。そのため、ブロックごとの MLP の代わりに、ブロックごとの調整可能なバイアス項を採用しました。この変更により、モデルのパフォーマンスを犠牲にすることなく、アテンション層と MLP 層へより多くのパラメータを割り当てることが可能になります。
AdaLN モジュレーション Beyond として、2 つの代替案を検討しました:(1) タイムステップ条件付けを完全に削除する、および (2) タイムステップトークンによるコンテキスト内タイムステップ条件付け。低解像度事前学習の実行では、タイムステップ情報を完全に削除することは、AdaLN ベースラインに対して一貫して性能が劣る結果となりました。コンテキスト内条件付けについては、正弦波埋め込みを用いて時間埋め込みを作成し、これらを統合されたテキスト+画像+時間のシーケンスに結合し、AdaLN 層を完全に削除しました。256px の事前学習では、4〜16 のタイムステップトークンで AdaLN を置き換えるのに十分でした。しかし、512px および 1024px では、コンテキスト内条件付けは AdaLN ベースラインと比較して性能が低く評価されました。これを緩和するためにタイムステップトークンの数を増やそうと試みましたが、収穫逓減の現象を観察し、より高い解像度では競争力のある性能を達成できませんでした。
位置符号化
アブレーション実験のために、いくつかの RoPE 方式を実装しました。ここでは、フレーム、高さ、幅にそれぞれ専用割り当てられた次元を持つ 3D 軸方向 RoPE を使用しています。テキストトークンについては、RoPE のインデックスをゼロに設定します。低解像度では、Golden Gate RoPE、MRoPE、正規化 RoPE、または 部分 RoPE へ切り替えても、顕著な改善は観察されませんでした。部分 RoPE では、次元の前半のみを回転させ、残りは回転なしのままにしています。予想通り、モデルを 256px から 512px にスケールする際、部分 RoPE はゼロショット推論においてより良い結果を生み出し、一般的な複製アーティファクトの影響も受けませんでした。この初期の解像度一般化能力にもかかわらず、高解像度でのトレーニングが継続されるにつれ、部分 RoPE の性能は最終的にベースラインとなる RoPE 設定よりも劣ることが判明しました。
オートエンコーダー
最近の研究では、オートエンコーダーの潜在空間設計が画像生成モデルのトレーニングを大幅に加速できる可能性が示されています。私たちは FLUX.1-dev オートエンコーダーをベースラインとして採用し、Qwen Image VAE、DC-AE、FLUX 2 VAE、および自社開発のオートエンコーダーと比較・ベンチマークを行いました。当初は DC-AE シリーズをテストしましたが、これは最大 32 倍の空間圧縮(spatial compression)を提供し、トレーニングと推論の効率性を大幅に向上させる可能性があります。しかし、再構成誤差(reconstruction error)により、DC-AE は拡散モデルが微細な詳細を解像する能力に対して厳密な上限を課すことが判明しました。
一方、Qwen Image VAE と FLUX 2 VAE は、優れた再構成品質を維持しつつ、事前トレーニングにおけるアブレーション実験で潜在空間の収束が著しく速いことを示しています。そのため、初期モデルのスケールアップには Qwen Image オートエンコーダーを採用し、より大規模なモデルには後から FLUX 2 VAE を採用しました。また、DINOv3 を用いたセマンティックアライメント(semantic alignment)と軽量な拡散損失(diffusion loss)を組み合わせた自社開発のオートエンコーダーをトレーニングするアプローチも試みました。これは REPA-E に類似した手法です。このアプローチが Qwen Image オートエンコーダーと競合する性能を示すことを検証しましたが、時間的制約のため、大規模スケールで実証済みの Qwen Image および FLUX 2 VAE を採用することを選択しました。
Residual design
デフォルトでは標準的な残差接続(residual connections)を使用しています。Laurel では、低ランクのボトルネックブランチを追加することで残差接続の表現力を向上させる試みを簡潔に行いましたが、目に見える改善は確認できませんでした。今後のモデルでは、拡散トランスフォーマー(diffusion transformers)の残差設計を改善するために、NOBLE、delta アテンション残差、およびmHC などの代替案を探求する予定です。
Normalization
RMSNorm は大規模言語モデル(LLM)アーキテクチャの標準コンポーネントとなっていますが、最新の拡散トランスフォーマーアーキテクチャにはまだ完全に統合されていません。LayerNorm ベースラインから始め、すべての正規化層を RMSNorm に置き換えたところ、品質の低下は極めてわずかであることを確認しました。そのため、デフォルトの正規化モジュールとして RMSNorm を採用しています(例えば、prenorm および QKNorm に対して)。また、ゼロ中心化された RMSNorm を使用し、学習可能なパラメータには重み減衰(weight decay)を適用しています。Derf のようなより効率的なバリアントも実験しましたが、品質の低下が無視できない程度であることを発見しました。
Text encoder
ベースラインのテキストエンコーダーとして T5-XXL を使用しました。当初から、アーキテクチャをシンプルに保ち、単一のテキストエンコーダーを使用することを意図的に選択しました。特筆すべきは、T5Gemma、umT5、Qwen 2.5 VL、および Qwen 3 VL と比較しても、T5-XXL が非常に競争力のあるテキストエンコーダーであり続けることを発見した点です。最終的に、VLM(Vision-Language Model: ビジョン・ランゲージモデル)はより豊かな入力空間(テキストと画像)と強力な多言語汎化能力を提供するため、Qwen 3 VL を最終的なテキストエンコーダーとして採用しました。
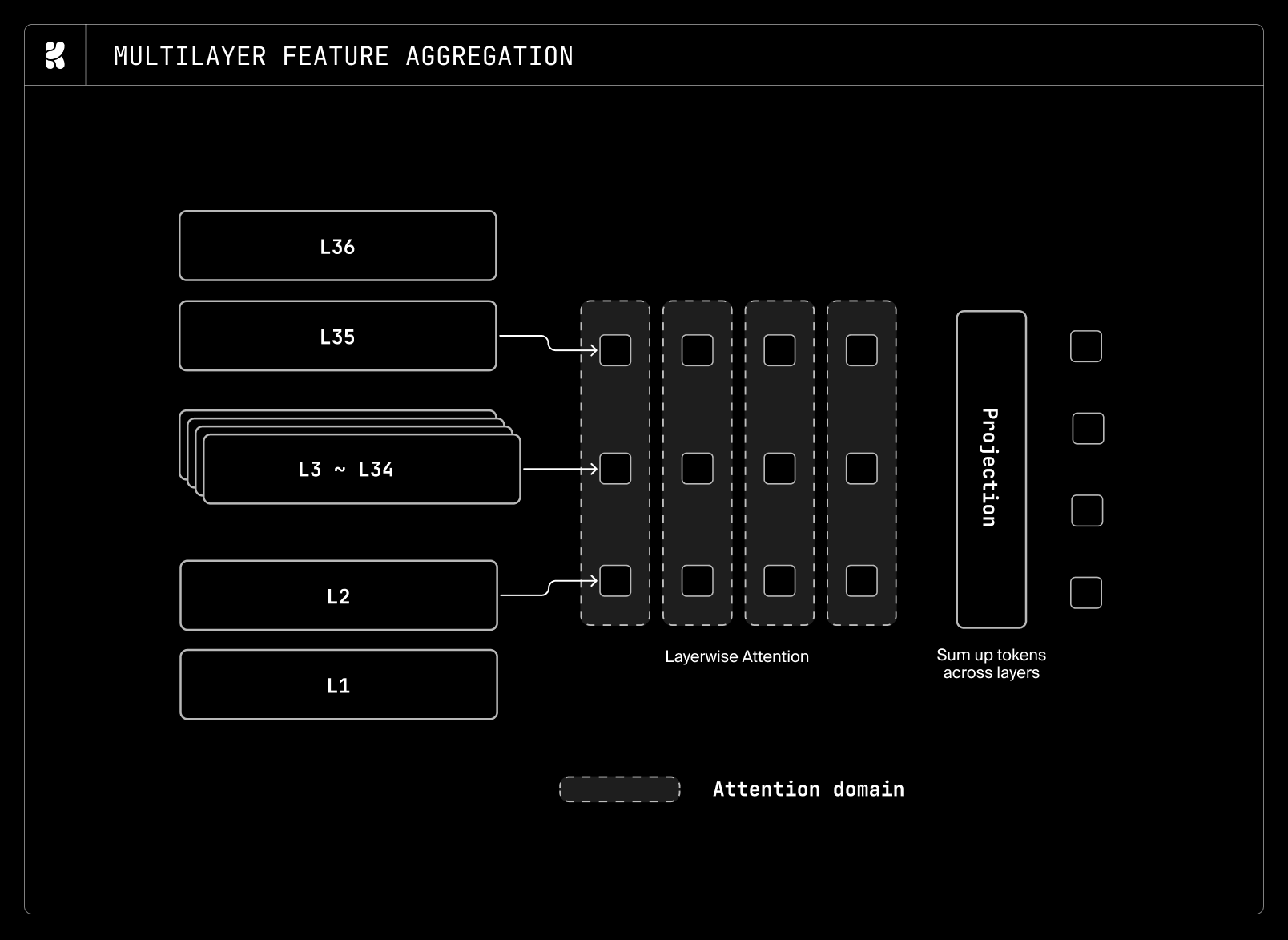
さらに、Unifusion に着想を得て、VLM の最終層の特徴量を採用するのではなく、層間を横断して隠れ特徴量を集約する浅いアテンション層を導入しました。この設計により、モデルは粗から細へとテキスト表現を動的に選択できるようになります。自己回帰型 LLM(Large Language Model: 大規模言語モデル)の最終層の特徴量は、次トークンの予測ではなく画像生成のために最適化されているため、私たちの目的には最適ではありません。この層ごとの特徴量集約に加えて、表現空間における自己回帰バイアスを低減するために、トークン軸全体に軽量な双方向トランスフォーマー層を追加しました。
最適化
私たちはパイプライン全体を通じて、AdamW を主要な最適化アルゴリズムとして使用しています。当初、Muon を MMDiT アーキテクチャに適用した際には結果が混在していました。デフォルトでは、Dion から提供される Muon の実装と、Moonlight からの RMS-matched 設定を採用し、AdamW のハイパーパラメータを転送しています。
私たちの探索において、Muon は初期ステップでは AdamW よりも収束が速いものの、より長い期間にわたっては性能が劣ることがわかりました。また、トレーニング全体を通じて頻繁な損失や勾配ノルムのスパイクが発生するなど、Muon には多くの安定性の問題にも直面しました。MMDiT の最初の線形層と最後の線形層を Muon パラメータから除外することが重要であることが判明しました。これは、埋め込み層と LM ヘッドのパラメータが Muon から除外されるという LLM の文献とも一致しています。これらの層を除外し、Nesterov モメンタムを追加したところ、Muon は低解像度および高解像度の両方で AdamW ベースラインを上回る結果を常に示しました。時間的制約のため、最新の事前トレーニング実行では Muon を採用しませんでしたが、これらの強力な結果を踏まえ、次の事前トレーニングサイクルで導入する計画です。
トレーニング
私たちのトレーニングパイプラインは、現代の LLM 学習パイプラインに触発された多段階構造に従っています。
事前トレーニング
事前学習は、テキストと画像の整合性、テキストレンダリング、スタイルのカバレッジ、構造的な一貫性を含むモデルの基本機能を確立します。解像度は 256px から 512px、そして 1024px へと段階的にスケーリングします。最終モデルでは、v パラメータ化(v-parameterization)の下で標準的な整流フロー損失(rectified-flow loss)を用いて訓練を行います。初期段階を加速するために、256px ステージの最初のエポックには iREPA を使用し、その後これを削除します。これにより、MMDiT が独自の表現を学習しつつも、初期収束が大幅に高速化されます。TREAD などの代替加速戦略も探索しましたが、ほとんど効果は見られませんでした。
256px および 512px ステージでは 8 ビット訓練(8-bit training)を使用し、bf16 ベースラインと比較して訓練速度で 15〜20% の向上を観測しました。一方、訓練損失や評価指標における低下は極めて最小限です。256px ではテンソル全体に対するスケーリング(tensorwise scaling)を伴う 8 ビット訓練を採用し、512px ではより細粒度な行ごとのスケーリング(rowwise scaling)を使用します。1024px 以降および最終的な RL ステージでは、標準的な bf16 訓練を行います。
高解像度事前学習のもう一つの重要な側面は、解像度依存のタイムシフトスケジュールの適応です。トレーニングと推論の両方でシフトされたロジット正規サンプリングスケジュールを使用し、解像度が上がるにつれてシフトを徐々に増加させます。FLUX 2 VAE blog に従い、各解像度において最適なトレーニング時のタイムシフトを探索します。推論時のタイムシフトは、特定のオートエンコーダーが推論時のタイムシフトに対してあまり敏感ではないため、トレーニング時のみシフトを探索し、推論時のスケジュールは一定に保ちます。
事前学習中、私たちはウォームアップ・スタブル・デケイ学習率スケジュールを使用し、Large Language Models の事前学習におけるモデルマージ に従って PMA(パラメータ混合アプローチ)を適用します。PMA は EMA(指数移動平均)と同等の性能を達成しつつ、その大きなメモリオーバーヘッドを回避できることを検証しました。マージ手法間の顕著な差異は観察されませんでしたが、マージするチェックポイントの数やマージ間隔を調整することで、下流タスクの指標においてわずかな向上が得られる可能性があります。
Midtraining(中間学習)
中間学習は LLM 文献において一般的になっており、私たちは同様の段階をパイプラインに組み込みます。その焦点は、教師あり微調整(SFT)ステージの前にモデルの分布を温めることです。私たちは、中間学習が通常、高忠実度・高解像度の生成、強力なドメインカバレッジ、テキストレンダリングといった下流タスク機能をモデルに付与できるパイプライン上の最後のポイントであることを発見しました。
教師あり微調整 (SFT)
教師あり微調整 (SFT) の段階では、私たちは非常に美的な画像の小さな専用セットを厳選します。この段階の目的は、モデルをさらに審美的に望ましい方向へバイアスさせることです。私たちはこの段階が、全体的なチェックポイントの品質を向上させ、以前のチェックポイントで一般的に見られる高彩度やテクスチャの問題に対処するために特に有用であることを発見しました。
ドメイン固有の SFT チェックポイントをトレーニングした後、モデルマージを使用して一般的な SFT チェックポイントを生成します。改善の方向性がチェックポイント間で競合し始めるため、パイプラインの後期段階に向かうにつれて、モデルマージによる効果は次第に減少していきます。
選好最適化 (PO)
選好最適化 (PO) は、私たちのポストトレーニングスタックにおける最初の段階であり、2 つのステージからなるパイプラインで構成されています。第一段階では、delta learning に似た戦略を用いて、初期の洗練のために大規模な合成選好ペア生成パイプラインを実行します。ここで重要なのは、ペアの大多数が少なくとも 1 つのオンポリシーサンプルを含むようにすることです。第二段階は校正段階であり、これは人間の注釈のみを使用します。これらの注釈は、モデルの特定の強み、弱み、そして癖に精通した人々によって、完全に社内で行われたものです。
PO(Preference Optimization)中に起こりやすい現象の一つに、ポリシーの分岐があります。高レベルでは、DPO などの選好最適化手法は、参照モデルに対して、望ましいサンプルを生成する確率と望ましくないサンプルを生成する確率との差(マージン)を広げるようモデルに促します。しかし実際には、異なる選好データセットの組み合わせにおいて、モデルはこの目的を達成するために両方のサンプルの生成確率を低下させることで対応していることが観察されますが、その低下率は異なります。これは、勝つ側と負ける側の両方のサンプルが現在のモデル分布よりも品質が低い場合に望ましい結果ですが、この仮定は選好セットのキュレーション方法によっては常に成り立つわけではありません。さらに、この分岐はモデルを一般的な事前学習分布から遠ざけ、トレーニングの後期段階において高周波数のアーティファクトとして現れます。これを緩和するために、私たちは DPO の変種である STPO を設計しました。これは、この分岐を減らすために補助損失(auxiliary loss)を追加し、元の DPO 式に修正を加えたものです。
リンフォースメントラーニング (RL)
強化学習(RL)はトレーニングパイプラインの最終段階です。私たちは、いくつかの報酬モデルを用いたマルチ報酬 GRPO スタイルの方法を採用しています:(1) 一般的な審美性モデル、(2) プロンプト追従報酬、(3) テキストレンダリング報酬、(4) アーティファクトおよび構造報酬。一般的な審美性モデルは、PO(プロンプト最適化)段階で収集された選好データを用いてオープンソースの VLM(視覚言語モデル)をファインチューニングすることで取得されます。私たちは、報酬ハッキングによって生じるアーティファクトを防ぐために、報酬構造を慎重に設計し、データの混合比率を調整しています。
一般的に主観的な性質を持つ審美性報酬とは異なり、プロンプト追従とテキストレンダリングは、ユーザーの明示された意図に対して検証可能であるため、より具体的なシグナルを提供します。課題となるのは、この意図がプロンプトによって大きく異なる点です。これに対処するため、私たちは LLM 訓練におけるルブリック評価(評価基準に基づく評価)に着想を得た、プロンプト固有のルブリック報酬を採用しています。単一の総合スコアを判定モデルに求めるのではなく、各プロンプトを検証可能な要件に分解し、生成された画像がそれらに対してどのように適合するかを評価します。これにより、RL 段階にはユーザーの意図との整合性に対するより構造化されたシグナルが与えられ、プロンプト追従を単なる一般的な画像品質に矮小化することなく、微細なプロンプト制約を満たす能力をモデルが向上させます。
また、美観とプロンプトの追従のみを最適化すると、報酬ハッキングにつながることも発見しました。モデルは、一見すると妥当に見えるが、余分な指や変形した四肢、歪んだテキストなどの構造的欠陥を含む画像を生成するよう学習してしまう可能性があります。これらの失敗は人間には視覚的に明白ですが、汎用的な VLM 判定器ではしばしば見逃されます。これを解決するため、我々はこれらの構造的エラーを検出し、視覚的正しさを犠牲にしてベンチマーク対応の信号を改善しようとする RL 段階を抑制する、専用のアーティファクト報酬モデルを訓練しました。
RL(強化学習)段階において、成功は報酬モデルの品質だけでなく、プロンプト間でのトレーニング計算リソースをいかに効率的に配分するかにも依存することが分かりました。報酬モデルは改善の方向性を定義する一方、プロンプププールはモデルがどのような学習シグナルを受け取るかを決定します。そのため、多様なスタイル、概念、設定、主題にわたる広範なプロンプトプールを構築し、生成されたグループの報酬統計を継続的に分析して、どのプロンプトが最も情報量が多いかを特定しています。すでに難易度が低すぎる、一貫して高すぎるといった場合や、サンプル間でばらつきがほとんど生じないプロンプトは有用なシグナルを提供できず、優先順位を下げるか削除されます。実務において効果的な RL(強化学習)を実現するには、プロンプト選択をリソース配分問題として捉え、モデルがまだ学習可能な事例に対して計算リソースを多く割り当て、飽和したフィードバックやノイズの多い事例には少ないリソースで対応するようトレーニングプロセスを設計する必要があります。
拡散 RL におけるもう一つの現実的な考慮事項は、クラスifier-free ガイダンス(CFG)をどのように扱うかです。ロールアウト生成とトレーニングの両方において、CFG を用いる場合と用いない場合のどちらでも実行可能であり、異なる選択がアライメント、安定性、効率性の間で異なるトレードオフを生み出します。アブレーション実験の結果、ロールアウト分布とトレーニング分布を整合させつつ、不必要な計算オーバーヘッドを避けることが重要であることがわかりました。そのため、RL 全体ステージでは CFG を用いずにトレーニングを行います。この設定により、条件付きモデル分布が急速に改善され、トレーニング初期段階で非 CFG サンプルがガイダンス付きサンプルに近づきます。推論時には、CFG を追加の制御ノブとして有効化することができ、必要に応じて品質をさらに向上させることができます。
タイムステップ蒸留
RL ステージの後に、オプションのタイムステップ蒸留ステージを追加し、ここでガイダンス蒸留とタイムステップ蒸留を同時に適用します。DMD、DMD2、Decoupled DMD、piFlow、および APT など、いくつかの蒸留手法を検討しましたが、以下の理由から Trajectory Distribution Matching (TDM) を採用しました。私たちは、ハイパーパラメータを最小限に抑えつつ調整が容易な手法を探しており、これにより GAN ベースの手法や piFlow(後者はモデルをマルチタイムステップ予測モデルへ適応させる必要があるため)は除外されました。TDM を選定した理由は、それが高速でデータ不要かつ柔軟な多段階蒸留を提供するからです。
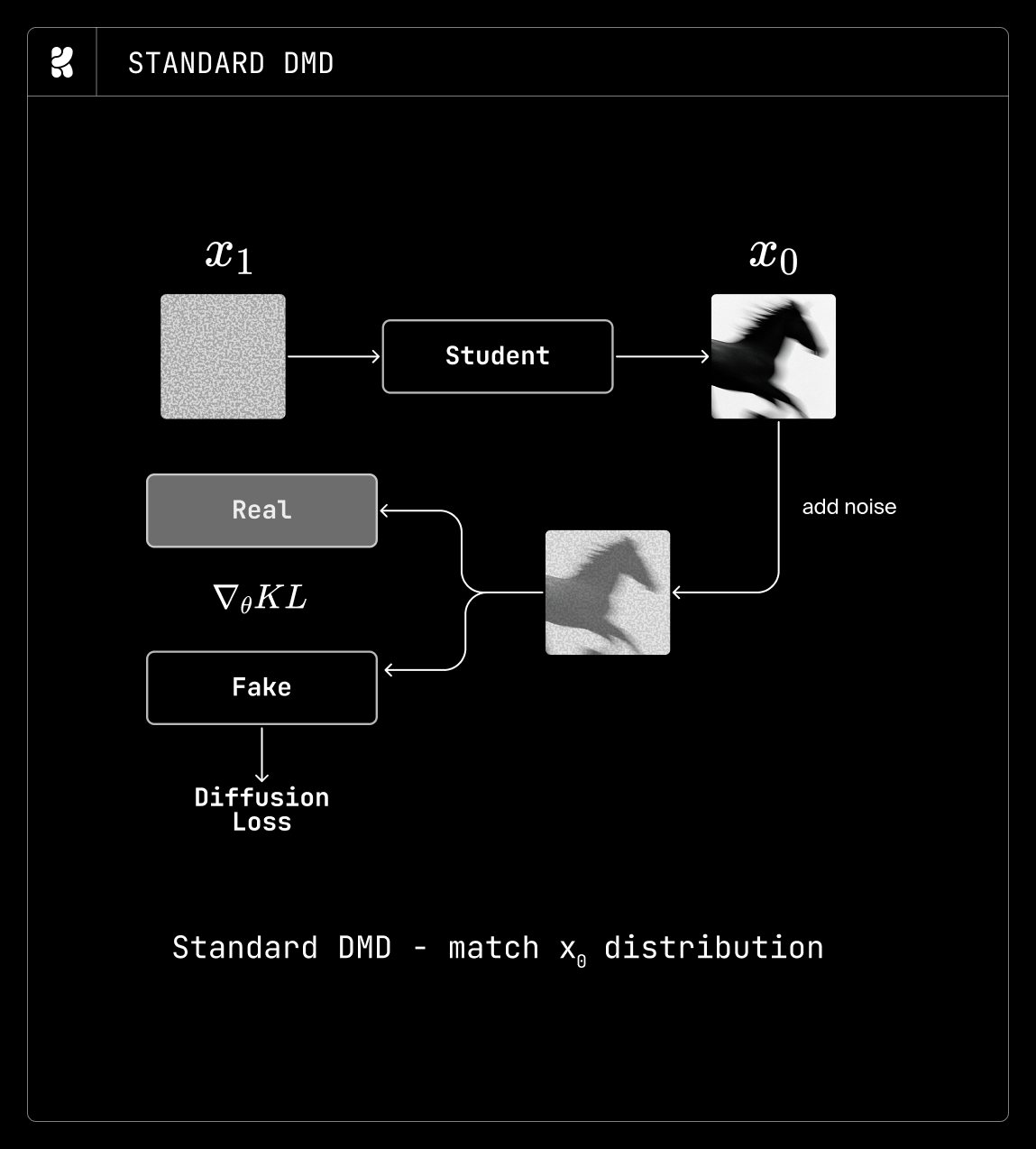
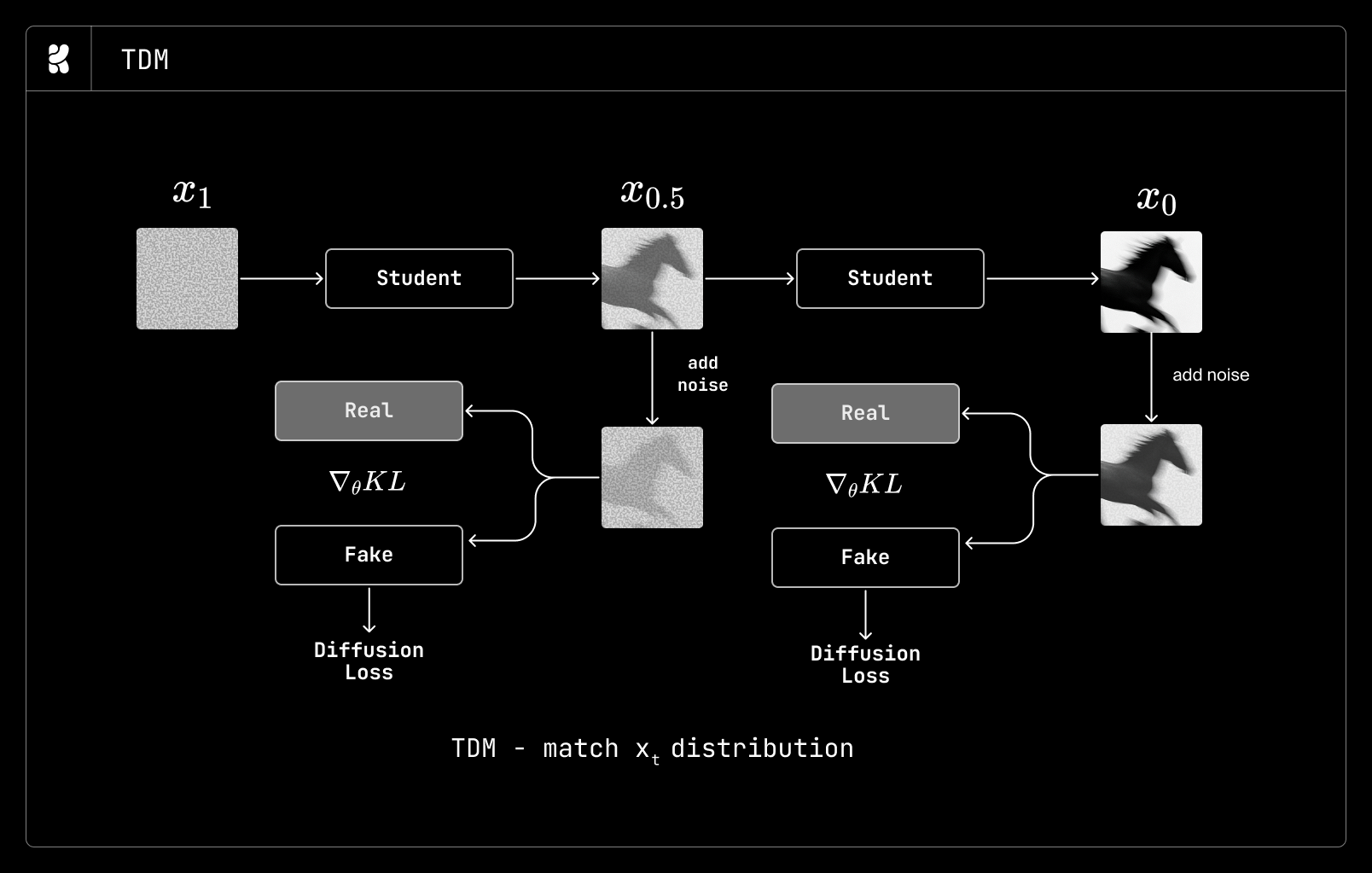
DMD は、生成されたサンプルと実データの分布をクリーン画像の分布上で一致させることで教師モデルを蒸留します。したがって、標準的な DMD では数ステップの学生モデルがクリーン画像を予測し、その予測結果に再度ノイズを加えて学生モデルを訓練します(上記図参照)。DMD がクリーン画像の分布のみを一致させるのに対し、TDM は時間ステップ全体にわたって DMD を適用し、サンプルレベルではなく軌跡レベルで分布マッチングを実行します。私たちの目標が柔軟な多ステップ学生モデルであったため、TDM がユースケースに最も適した方法であると判断しました。
プロンプト拡張
密なプロンプトは信頼性が高く、より優れた画像生成結果をもたらしますが、ユーザーがトレーニング時に使用される豊富なキャプションに似たプロンプトを書くことは稀です。私たちはこれを分布マッピング問題として捉えます。画像モデルは、そのトレーニング分布に近い詳細なキャプションによって最もよく条件付けられますが、実際のユーザープロンプトは短く、会話調であり、不十分なことが多いのです。そこで、ユーザーの意図を解釈し、入力プロンプトをより豊かでモデルに優しいキャプションに変換するプロンプト拡張器を開発しました。
まず、既存のオープンソース大規模言語モデル(LLM)に対して教師あり微調整を施行します。トレーニングデータの構築には別の言語モデルを用いて、長いキャプションから合成された「ユーザーキャプション」を生成します。これはより短く、会話調であり、半指示的なプロンプトで、ターゲットとなるキャプションに含まれる多くの視覚的詳細を意図的に省略したものです。これにより、「不十分なユーザープロンプト → 拡張されモデルに親和性のあるキャプション」という形式のペアデータが生成されます。また、モデルの推論能力を維持するため思考プロセス(thinking traces)も合成し、中間的な意図再構成ステップが下流タスクの動作を改善することを確認したためです。これに加え、少量のターゲット指向型分布整形を適用します。高レベルでは、創造的かつ美的なプロンプトスタイルに対するモデルの対応範囲を広げるため、視覚的に豊かで芸術性の高い画像を過剰サンプリングし、フォトリアリスティックな記述へと展開すべきプロンプトに対しては軽量な写真メディアバイアスを追加します。目的は特定のハウススタイルを強制することではなく、拡張されたプロンプト分布が表現力豊かなアートディレクション付きのイメージと、ストレートなフォトリアルなリクエストの両方をカバーすることを保証することです。
SFT は、エクスパンダーを望ましいキャプション分布に近づけますが、合成ターゲットとの一致は最終画像の改善とは同じではありません。そのため、生成された出力を通じてエクスパンダーを直接最適化するために RL(強化学習)を使用します。この段階では、目標はターゲットのキャプションを模倣することから、ユーザーの意図を保持しつつ画像品質を向上させる展開を行うことにシフトします。私たちは GDPO を用いて、マルチ報酬目的関数でトレーニングを行います:画像レベルの報酬は生成結果の品質と選好度を測定し、プロンプトレベルの検証可能な報酬は、展開が元の要求に忠実であるかを確認します。また、明らかにプロンプトに含まれていないまたは受け入れられないコンテンツをエクスパンダーが導入しないよう、安全性および制約チェックも組み込んでいます。これらのチェックは本質的にスパース(疎)であるため、全体報酬に対するゲートとして使用し、密な最適化シグナルとしては使用しません。
私たちは、ユーザー入力の現実的な分布を一致させることと、各グループに高コントラストの良し悪しのロールアウトが混在することのバランスを取ることを目指しました。そのために、RL プロンプトミックスは、現実的なユーザーのようなトラフィックと採掘された困難なケースを組み合わせています。現実的な側面には、実際のプロンプトと以前観測された失敗事例が含まれ、手作業で選別した失敗事例や既知の失敗モードに対する合成拡張データが補完されています。選別された例は、内部での低評価、バグレポート、手動で書き直されたプロンプトから得られ、既知のすべての失敗クラスが常に代表されるように分類されます。合成例は、手作業で作成した報酬トリガープローブを出発点とし、多数の変種に拡張され、RL 中と同じ報酬スキーマを用いてオフラインでスコアリングされます。私たちは「困難だが絶望的ではない」プロンプトを選択し、中間的な複合スコアと実際の報酬変動を持つグループを生成することで、GDPO が明白な勝利や完全な失敗だけでなく、意味のある選好信号を受け取れるようにしています。
私たちが明示的に最適化しようとしている失敗モードの一つに、多様性の崩壊があります。プロンプト拡張機能は、特に画像報酬が支配的な場合、単一の安全で高報酬のハウススタイルを学習してしまう可能性があります。これに対抗するため、プロンプトグループ全体に対して単純な DINOv3 埋め込み多様性スコアを追加し、品質と整合性に加えてグループ内の視覚的多様性を報奨します。多様性報酬を annealing(漸減)させる実験を一時的に行いましたが、その重みが小さくなりすぎるとモデルがすぐに多様性の少ない生成へと崩壊してしまうことが分かりました。実際には、変異を維持するためにトレーニング全体を通じて多様性報酬を活性状態に保つ必要があります。
スタイル参照システム
私たちのスタイル参照システムはベースモデルの上に構築されています。これにより、ユーザーはテキストから画像を生成する際に、1 つ以上の参照画像を使用して出力のスタイルをガイドすることができます。本システムは、(1) 複数のスタイルの滑らかな意味的混合、(2) 各スタイル参照の強度に対する連続的な制御、(3) 複雑なスタイルへの最先端の準拠をサポートするように設計されています。
「スタイル」と「コンテンツ」が画像において何を構成するかという曖昧さのため、スタイル転送は困難です。最も一般的な失敗モードの一つに、スタイル画像からのコンテンツや主題が最終画像へ漏洩することがあります。さらに、従来の編集タスクのように動画などのソースからデータをマイニングできるのとは異なり、私たちが目指した忠実度で大量のスタイル転送データを入手することは大幅に困難です。
これらの課題に対処するため、スタイル参照モジュールのトレーニングに新たな自己教師あり手法を考案し、さらに出力を整合させるために好意最適化ステップを追加しました。
トレーニングインフラストラクチャ
当社の分散トレーニングフレームワークは、PyTorch を基盤としてゼロから構築されています。主に DTensor 抽象化と、torchtitan プロジェクト がサポートするネイティブな PyTorch 機能に依存しています。事前トレーニングおよびポストトレーニングの大部分の実行では、FSDP2 と Megatron-LM スタイルのテンソル並列処理を併用します。TP サイズが 2 より大きい設定では、torch.compile フラグを通じて 非同期 TP を有効化し、単純なテンソル並列処理(TP)と比較して中程度の速度向上を実現しています。オートエンコーダーのパラメータはメモリオーバーヘッドが最小限であるため、これらはすべてのデバイスに複製されたままとし、テキストエンコーダーと主要な MMDiT バックボーンのみをシャードします。ノード内の接続には NVLinkSharp を、ノード間の接続には InfiniBand を使用しています。
トレーニング効率のために、私たちは隠れ次元を大きくしたわずかに広いモデルを使用しています。その理由は二つあります。第一に、隠れサイズが大きくなると各層の計算集約度が高まり、FSDP2 プリフェッチでレイテンシを隠しやすくなります。また、層の数を減らすことで、all-gather および reduce-scatter 操作の回数も減少します。この変更により、事前トレーニングの実行全体を通じて NCCL 関連のエラーが大幅に削減されました。第二に、行列乗算サイズが大きくなることで、8 ビットトレーニングにおける量子化および逆量子化のオーバーヘッドを分散しやすくなります。
私たちは主要な最適化戦略として torch.compile に大きく依存しています。アテンションについては、デフォルトで最新の cuDNN カーネルを使用し、必要に応じて FlexAttention または FlashAttention 3 を採用します。低解像度では選択的活性化チェックポイントを使用し、活性化がメモリを支配し始める高解像度では完全な活性化チェックポイントを使用します。
データローディングについては、Parquet を主要フォーマットとして使用しています。各行には、画像への参照(例:ローカルパスまたは S3 場所)、切り取りおよびリサイズ寸法、キャプション、その他の関連メタデータを格納します。大規模な実行では、事前に行をシャッフルしてパッキングし、各データローダーワーカーが同じアスペクト比の画像バッチを読み込むようにしています。このパッキングにより、オートエンコーダーの単一パスで潜在変数を符号化することが可能になります。
この実装にはいくつかの利点があります。データを事前にシャッフルすることで、ディスクからのシークエンシャルスキャンを実行してパフォーマンスの高いデータローディングを実現しつつ、適切なグローバルシャッフルを確保できます。また、事前シャッフルは再現性とデバッグにも不可欠です。なぜなら、損失スパイクの原因となった可能性のあるサンプルを特定するために、データを正確な順序で再再生できるからです。
最大の事前トレーニング実行中、さまざまなインフラストラクチャとフォールトトレランスの課題に直面しました。従来の大規模分散トレーニングでは、クラスター全体に多くのグローバル同期ポイント(例えば、DP レプリカ間の勾配アロウリデュースなど)が存在し、本質的に不安定です。GPU の単一の故障や遅延ノードが実行全体の停止を引き起こす可能性があります。torch-ft や decoupled DiLoCo などのフォールトトレランスソリューションは存在しますが、私たちのスケールでは、高速かつ頻繁なチェックポイントと起動時間の改善を通じて、故障間平均時間 (MTBF: Mean Time Between Failures) と復旧までの平均時間 (MTTR: Mean Time To Recovery) を最適化することが満足すべき解決策であることがわかりました。
信頼性にとってもう一つの重要な要因は、トレーニングデバイス全体にわたる I/O、CPU、GPU への負荷を均一に保つことでした。私たちは明示的にデータローダーを設計し、各 CPU と GPU がほぼ等しい負荷を負担するようにしています。初期の大規模な実行では、低解像度ステージで使用される高解像度画像は、その場で切り抜かれて低解像度にリサイズされていました。しかし、最も大規模な実行においては、元の画像が高解像度かどうかによってデバイス間で CPU と I/O の負荷に偏りが生じるという問題がありました。これを緩和するために、すべての画像を事前にターゲットのトレーニング解像度に合わせて切り抜き、リサイズしています。さらに、すべての GPU が正確に同じ形状にパディングされたテンソル入力を受け取るようにし、負荷を均等化しています。
RL(強化学習)インフラストラクチャについては、報酬モデルの推論をメインのトレーニングプロセスから分離しました。Krea 2 は私たちの最初の主要な RL イテレーションであったため、トレーニング用 GPU とロールアウト用 GPU を共有するシンプルな設計を採用しています。近い将来、非同期 RL [asynchronous RL](PipelineRL などの手法をサポートするために、トレーニングと推論を分離した構成を実装する予定です。
システムインフラストラクチャ
私たちの研究は、GPU が本番環境の推論処理と共有された単一の Kubernetes クラスター内で行われました。このシステムは、必要に応じて研究チームが GPU プール全体を確保できるように設計されていました:もしクラスター内のすべての GPU がトレーニング実行に割り当てられた場合でも、Krea の推論ワークロードは自動的に他の場所へ移行します。これにより、トレーニング実行を開始する際に本番環境の容量を考慮する必要がなくなりました。システムがトラフィックのフェイルオーバー処理を行い、ローカルで利用可能な GPU が残っていない状況であっても本番環境の応答性を維持したためです。
この機能は当初から存在していたわけではありません。スケジューリングおよび管理システムは、研究サイクルを通じて研究チームのニーズに合わせて進化してきました。以下のセクションでは、主要なコンポーネントについて説明します:Kueue を用いたワークロードスケジューリング、クラスター外での推論処理のスケーリング、これら 2 つを結びつけるスケジューリングポリシー、トレーニング実行の手順、そして大規模事前学習において不可欠であった観測スタックです。
Kueue を用いたスケジューリング
Kueue は私たちのセットアップの中核を担っていますが、その利用方法は大きく変化しました。Kueue の Workload priority と Kubernetes の Pod priority を組み合わせた 2 レベルの優先度システムを提供しており、適切に設定することで、有用なスケジューリングセマンティクスを実現します。
Volcano などのカスタムスケジューラーを検討しましたが、kube-scheduler を直接修正するアプローチも検討しました。これらはさらに望ましい特性を提供できたはずです。しかし最終的に、デフォルトの Kubernetes スケジューラーに Kueue を組み合わせることで、当社の要件を十分に満たすことができました。
原文を表示
Introduction
Over the past few years, image generation has seen remarkable progress. Diffusion and flow-matching models can generate high-resolution images, produce sharp photorealism and stable structure, render dense text, encode broad world knowledge, and follow user prompts in precise detail. These improvements have been driven by several interacting factors including scalable transformers architectures, improved captioning and text encoders, better latent representations, and pipelined post-training techniques. Yet as the field has optimized for reliability on these capabilities, many systems have converged toward a narrow set of default aesthetics. While effective production tools, this makes them less effective as engines for creative exploration, where users often need to search across styles, moods, compositions and visual directions rather than receive a single polished default.
To address these limitations, we present Krea 2, a series of foundation models focused on creative exploration. Krea 2’s models are built on the belief that image generation should be an exploratory medium: expressive enough to span many aesthetics, and controllable enough for creators to navigate them.
We built a large-scale data infrastructure and distributed training framework from scratch to curate a comprehensive pretraining dataset with broad world knowledge and style coverage.
Using this infrastructure, we train expressive models through a multi-stage pipeline spanning pretraining, midtraining, supervised finetuning (SFT), preference optimization, and reinforcement learning (RL), with each stage designed to progressively refine the model’s output distribution. We develop a simple yet performant diffusion transformer (DiT) architecture through thorough ablations. Our model incorporates several components that accelerate convergence , including iREPA, improved VAEs, and Qwen3-VL. We also integrate several architectural improvements, including grouped-query attention (GQA), sigmoid-gated attention, lightweight timestep modulation, and multilayer feature aggregation for text-encoder features, which together improve training stability and efficiency.
A strong base model is only useful if users can reliably reach the parts of its distribution they care about. In training, the model learns from rich, carefully constructed captions that describe images with dense visual detail. In practice, user inputs are often shorter, more ambiguous, and shaped by many different habits of expression. Some users describe a scene in natural language; others gesture toward a mood, a style, or a reference image. This creates a gap between the model’s learned conditioning space and the way creative intent is expressed at inference time.
To reduce this gap, we build two systems that make Krea 2 more exploratory and steerable from both text and image inputs: a prompt expander and a style-reference system. The prompt expander maps simple or underspecified user prompts into richer visual directions without overwriting the user’s intent. It is trained through a two-stage SFT and RL pipeline on top of open-source LLMs, where the objective is not only to improve image quality, but also to encourage creative variation and controllable exploration. Complementing this textual interface, the style-reference system lets users express visual intent through images when words are insufficient. It allows users to inject the style or mood of one or more reference images with minimal content leakage, while providing fine-grained control over style strength and weighted style mixing.
Together, these components define Krea 2 as a foundation model for exploratory generation. Instead of optimizing only for a single polished default, Krea 2 is designed to expose a broad visual space and give users practical ways to move through it, using both text and image-based control. Krea 2 is among the top 10 models on the the Artificial Analysis leaderboard for text-to-image, and scores 2nd place among models from independent labs. Krea 2 serves as a comprehensive baseline and enables a creative generative experience while maintaining competitive performance.
Data
Data Curation Principles
Before detailing our data pipeline, it is important to establish what constitutes a good data mix for our purpose. A good mix does not consist solely of “high quality” images. Diversity and broad domain coverage are essential given our objective of building an expressive, stylistically diverse model. We argue that conventional model-based filtering, which uses aesthetic-score and image-quality-assessment (IQA) models, introduces implicit biases. For example, such methods may classify a blurry image as low quality, even though motion blur or softness can be a deliberate artistic choice.
Furthermore, we argue that as long as a caption accurately describes its image, even an undesirable image may be helpful in downstream use cases: because the model precisely understands the undesired behavior, such samples can later be used to steer generations away from that distribution.
For these reasons, we build the pretraining dataset by filtering out only:
- Duplicated samples and over-represented concepts.
- Samples for which VLMs consistently fail to capture important aspects of the image.
- Samples that induce undesired biases and artifacts.
- Samples with high visual complexity that is too difficult to model reliably at low resolution.
- AI-generated samples
These conditions shape a pretraining dataset with broad coverage while avoiding poor text-to-image alignment and artifacts.
Importantly, we use no AI-generated images in our pretraining mix. Synthetic data and distillation can be an effective shortcut for acquiring model capabilities. However we find that even a small proportion of AI-generated images introduces biases into the model’s output distribution, as synthetic images tend to be easier to learn, which effectively imposes an upper bound on model quality. We therefore designed in-house classifiers to filter such images out.
Captioning
We employ a multi-stage approach to produce captions. First, we run an OCR model on each target image to extract any visible text. In the second stage, we provide both the OCR results and any available metadata (camera settings, known entities, and so on) to the captioning model, which produces an enriched caption that incorporates world knowledge alongside the extracted text.
*General captioning pipeline*
Once a context-rich, long-form natural-language caption is obtained, we use a cheaper LLM to reformat it into a variety of lengths and formats, exposing the model to a range of prompt styles. Empirically, we find that training on long prompts provides dense supervision, yielding faster convergence and lower training loss. For many downstream and applied use cases, however, performance on short and medium-length prompts remains important. We therefore train predominantly on long captions while ensuring the model is exposed to short and medium-length prompts throughout training.
*Our overall training pipeline and data stages*
Pretraining Data
Pretraining data spans 256px, 512px, and 1024px resolution stages. Progressively scaling the resolution forms a curriculum-learning strategy: we dedicate the majority of FLOPs to the low-resolution stages to build core model capabilities efficiently, then equip the model with high-fidelity generation capabilities as the training resolution increases.
Low-resolution pretraining is the stage at which basic text-image alignment and structure are learned. At this stage the dataset is on the order of billions of images, so we rely heavily on inexpensive CPU-based filters to remove low-quality images. These range from simple broken-file, resolution, and aspect-ratio filters that remove unqualified images, to Laplacian filters that remove images with extreme textures and noise patterns.
As an example, one issue we encountered while pretraining K2 was a tendency for the model to generate flat-color backgrounds and border artifacts. To mitigate this, we used RGB entropy, white/black pixel ratios, custom heuristics, and in-house classifiers to filter out samples that induced this behavior.
Building an in-house classifier, one effective strategy was to use a large VLM to craft a task-specific system prompt for the filtering task (for example, detecting a specific pattern or artifact), produce a pseudo-labeled dataset, and then train a small DINOv3- or SigLIP-2-based classifier to run the filter at scale. Any filtering model that requires GPU compute at the low-resolution stage is kept under 1B parameters for efficiency.
For deduplication at the low-resolution stages, we primarily use inexpensive hash-based methods, combining md5, phash, and colorhash to remove duplicate images with minimal compute. We find that the default 8x8 phash does not account for color and has a high false-positive rate; we therefore combine a 12x12 phash with colorhash for more robust deduplication.
As we scale the training resolution, we introduce image-quality and aesthetic filters. Importantly, these quality scores are used only to drop images of extremely poor quality, not to oversample images on the basis of their scores. We additionally use an image-complexity score and text density (from OCR results) to exclude images whose text and content cannot be meaningfully represented at low resolution. We adjust the quality, complexity, and text-density thresholds as training progresses.
Beyond conventional quality filters, we also train a sparse autoencoder (SAE) on SigLIP-2 embeddings computed over a sample of our pretraining corpus. After training the SAE, we use a VLM to annotate each SAE feature based on its top-k activating samples. These annotated features form an unsupervised tagging system in which we extract the predominant SAE features from each image. This tagging system was useful for filtering clear visual artifacts without training an explicit classifier.
Midtraining Data
Unlike the pretraining stages, midtraining explicitly selects specific image sources known to offer good stylistic coverage and high-quality images for particular visual domains. Whereas pretraining is a bottom-up process that begins from a general pool, midtraining data is curated top-down: the domains and sources are chosen first. Midtraining is a crucial stage that smoothly bridges the general pretraining distribution and the high-quality SFT distribution. To improve the quality of the distribution, we introduce semantic clustering and use retrieval-based strategies to ensure world-knowledge coverage.
Building on the approach in Automatic Data Curation for Self-Supervised Learning, we use FAISS to perform hierarchical k-means clustering, which we then sample so as to retain long-tail visual concepts without wasting compute over-sampling head concepts. After computing the hierarchical clusters, we have a VLM examine the images nearest each cluster centroid in order to name and, where appropriate, flag the cluster. Following human review of the flagged clusters, we dropped several that were low quality or problematic. We remove further redundant data through semantic deduplication, computing the SigLIP similarity between images within each remaining leaf cluster.
An important capability of image generation models is faithfully representing known entities that users may reference simply by name. Some entities, such as sports players or actors, can fall into semantic clusters containing many other entities, which risks their being dropped under straightforward hierarchical sampling. To address this, we ran PageRank over English Wikipedia using Danker and retained the top 90% of articles by rank. We then filtered out all articles describing unrepresentable subjects based on their Wikidata metadata, and for the remaining ~5 million concepts we performed a full-text search across all captions in our dataset to assess coverage. When sampling, we prioritized images whose captions referenced rare concepts. Finally, we repeated this coverage analysis on the resulting sample to confirm that no concepts present in the initial dataset had been dropped entirely.
Supervised Finetuning Data
For the supervised finetuning (SFT) stage, we use a small, hand-curated dataset focused on individual visual domains. We find that, once a sufficient volume is reached, the quality of the dataset matters far more than its scale.
Architecture
For our architectural ablations, we found it useful to classify each ablation’s objective into one of the following categories:
- Stability: Does it make training more stable? Does it reduce loss and gradient spikes?
- Performance: Does it make the model converge faster? If so, does the trend hold over an extended horizon and at higher resolution?
- Efficiency: Does it reduce parameter count, FLOPs, memory, or communication requirements without compromising model quality?
- Simplicity: Can we make the model simpler without affecting the other categories?
It is worth noting that many of our architectural decisions are guided by their adoption in the LLM space. Choosing an architecture that is well established in the LLM ecosystem allows us to take advantage of existing kernels and optimizations, even for diffusion models.
With these objectives in mind, we begin from the following baseline.
ComponentBaselineAblationsFinal component
AttentionMulti head attentionGQA, MLA, Gated Sigmoid attentionGQA with gated sigmoid attention
MLPGeLU MLPSwiGLUSwiGLU
ResidualStandard residualValue residual, LaurelStandard residual
Text encoderT5-XXL encoderT5Gemma, Qwen 2.5 VL, Qwen 3 VL, umT5Qwen 3 VL
ModulationMLP modulation per blockLight modulation with biasLight modulation with bias
AutoencoderFLUX AEQwen Image VAE, DC-AE, FLUX 2 AE, Internal VAEQwen Image VAE & FLUX 2 AE
Block designSingle stream transformer blockHybrid Stream, Parallel single stream,Single stream transformer block
NormLayer normalisation, QKNormRMSNorm, Zero center RMSNorm, DerfZero center RMSNorm, QKNorm
Positional encoding3D Axial RoPEGolden Gate RoPE, MRoPE, Normalised RoPE, Partial RoPE3D Axial RoPE
Transformer block
We begin by replacing the GeLU MLP with SwiGLU layers at a 4x expansion factor, which have become a de facto module in LLM architectures. Introducing SwiGLU led to consistent performance gains, so we adopted it across all subsequent ablations.
Having revised the MLP design, we considered GQA, MLA, and gated sigmoid attention as alternatives to the multi-head attention baseline. We find that GQA introduces minimal degradation while offering improved computational efficiency. We also explored MLA and observed slight gains over GQA, but did not adopt it, as it introduced additional computational overhead. We used MLA with up/down projection for KV compression and without decoupled RoPE, since diffusion is purely prefill and does not use a KV cache at inference.
On top of GQA, we add gated sigmoid attention, following Gated Attention for Large Language Models. Gated sigmoid attention adds very little compute and parameter overhead. While it did not yield significant performance gains, it produced more stable training dynamics, as reflected in the loss and gradient-norm curves throughout training.
We also ablate the modality-stream design:
- Single-stream design: a standard transformer block in which the attention and MLP weights are shared between text and image tokens.
- Dual-stream design: joint attention with separate attention and MLP weights for text and image tokens.
- Hybrid-stream design: a mix of the two, using dual-stream blocks for the first third of the network and single-stream blocks for the remaining two-thirds.
We did not observe significant performance differences among the three designs, with the exception of the hybrid-stream design, which slightly outperformed the others. For the sake of simplicity, however, we use single-stream blocks in our final architecture.
Timestep conditioning
Many MMDiTs use a per-block MLP to produce scale, shift, and gate factors. These MLP blocks can account for 20—30% of the total parameter count, which we consider excessive for injecting a scalar condition. We therefore replace the per-block MLP with a per-block tunable bias term. This change allows us to allocate more parameters to the attention and MLP layers without sacrificing model performance.
Beyond AdaLN modulation, we explored two alternatives: (1) removing timestep conditioning entirely, and (2) in-context timestep conditioning via timestep tokens. In our low-resolution pretraining runs, removing timestep information entirely consistently underperformed the AdaLN baseline. For in-context conditioning, we create time embeddings using sinusoidal embeddings, concatenate them into a unified text + image + time sequence, and remove the AdaLN layers entirely. At 256px pretraining, 4—16 timestep tokens were sufficient to replace AdaLN. At 512px and 1024px, however, in-context conditioning performed poorly relative to the AdaLN baseline. We attempted to mitigate this by increasing the number of timestep tokens, but observed diminishing returns and could not achieve competitive performance at higher resolutions.
Positional encoding
We implemented several RoPE schemes for our ablations. We use 3D axial RoPE, with head dimensions dedicated to frame, height, and width. For text tokens, we set the RoPE indices to zero. At low resolution, we did not observe significant gains from switching to Golden Gate RoPE, MRoPE, normalized RoPE, or partial RoPE. For partial RoPE, we rotate only the first half of the head dimension and leave the remainder unrotated. As expected, partial RoPE produced better zero-shot inference results when scaling the model from 256px to 512px and did not suffer from the common duplication artifacts. Despite this initial resolution generalization, partial RoPE ultimately performed worse than the baseline RoPE setting as high-resolution training continued.
Autoencoder
Recent work suggests that the latent-space design of the autoencoder can significantly accelerate the training of image generation models. We start from the FLUX.1-dev autoencoder as a baseline and benchmark it against the Qwen Image VAE, DC-AE, FLUX 2 VAE, and our internal autoencoder. We initially tested the DC-AE series, as it offers up to 32x spatial compression, which can substantially benefit both training and inference efficiency. However, we found that DC-AE imposes a hard upper limit on the diffusion model’s ability to resolve fine detail, owing to its reconstruction error.
By contrast, the Qwen Image VAE and FLUX 2 VAE offer a latent space with significantly faster convergence across our pretraining ablations while maintaining excellent reconstruction quality. We therefore initially used the Qwen Image autoencoder to scale our early models and later adopted the FLUX 2 VAE for our larger models. We also briefly explored training an internal autoencoder using DINOv3 for semantic alignment together with a light diffusion loss, following an approach similar to REPA-E. We validated that it performs competitively with the Qwen Image autoencoder, but owing to time constraints we opted for the Qwen Image and FLUX 2 VAEs, which have been validated at scale.
Residual design
We use standard residual connections as our default. We briefly experimented with Laurel, which improves the expressivity of the residual connection by adding a low-rank bottleneck branch, but observed no noticeable improvement. For future models, we intend to explore alternatives such as NOBLE, delta attention residuals, and mHC to improve the residual design of diffusion transformers.
Normalization
RMSNorm has become a standard component of LLM architectures but has not been fully integrated into recent diffusion transformer architectures. Starting from a LayerNorm baseline, we replaced all normalization layers with RMSNorm and observed very little quality degradation. We therefore use RMSNorm as the default normalization module (for example, for prenorm and QKNorm). We use the zero-centered RMSNorm and apply weight decay to its learnable parameters. We also experimented with more efficient variants such as Derf, but found non-negligible quality degradation.
Text encoder
We used T5-XXL as our baseline text encoder. From the outset, we deliberately chose to keep the architecture simple and use a single text encoder. Notably, we find that T5-XXL remains a very competitive text encoder relative to T5Gemma, umT5, Qwen 2.5 VL, and Qwen 3 VL. Ultimately, we use Qwen 3 VL as our final text encoder, as a VLM offers a richer input space (text and image) and stronger multilingual generalization.
Furthermore, inspired by Unifusion, rather than taking the last layer of the VLM features, we introduce a shallow attention layer that aggregates hidden features across layers. This design allows the model to dynamically select coarse-to-fine text representations. The last-layer features of an autoregressive LLM are suboptimal for our purpose, as they are optimized for next-token prediction rather than image generation. Alongside this layerwise feature aggregation, we add lightweight bidirectional transformer layers across the token axis to reduce the autoregressive bias in the representation space.
Optimization
We use AdamW as our primary optimizer throughout the pipeline. We initially saw mixed results applying Muon to the MMDiT architecture. By default, we use the Muon implementation from Dion and the RMS-matched setting from Moonlight to transfer AdamW hyperparameters.
In our exploration, Muon converged faster than AdamW in the initial steps but underperformed it over longer horizons. We also encountered a number of stability issues with Muon, including frequent loss and gradient-norm spikes throughout training. We found it crucial to exclude the first and last linear layers of the MMDiT from the Muon parameters; this is consistent with the LLM literature, where embedding and LM-head parameters are excluded from Muon. After excluding these layers and adding Nesterov momentum, Muon consistently outperformed the AdamW baseline at both low and high resolution. We did not adopt Muon for our most recent pretraining run owing to time constraints, but given these strong results we plan to adopt it in our next pretraining cycle.
Training
Our training pipeline follows a multi-stage structure inspired by modern LLM training pipelines.
Pretraining
Pretraining establishes the model’s basic capabilities, including text-image alignment, text rendering, stylistic coverage, and structural consistency. We progressively scale the resolution from 256px to 512px to 1024px. For our final model, we train with the standard rectified-flow loss under v-parameterization. To accelerate the early stages, we use iREPA for the first epoch of the 256px stage and then remove it, which encourages the MMDiT to learn its own representations while substantially speeding up initial convergence. We also explored alternative acceleration strategies such as TREAD, but saw little benefit.
During the 256px and 512px stages, we use 8-bit training and observe 15—20% gains in training speed over a bf16 baseline, with very minimal degradation in training loss and evaluation metrics. At 256px we use 8-bit training with tensorwise scaling, and at 512px we use finer-grained rowwise scaling. From 1024px onward, and through the final RL stage, we use standard bf16 training.
Another important aspect of high-resolution pretraining is adapting the resolution-dependent timeshift schedule. We use a shifted logit-normal sampling schedule for both training and inference, and gradually increase the shift as resolution increases. Following FLUX 2 VAE blog, we sweep for the optimal training timeshift at each resolution. We sweep the shift only for training and keep the inference shift schedule constant, as certain autoencoders are less sensitive to the inference timeshift.
During pretraining, we use a warmup-stable-decay learning-rate schedule and apply PMA following Model Merging in Pre-training of Large Language Models. We validate that PMA achieves performance comparable to EMA while avoiding its significant memory overhead. We do not observe significant differences between merging methods, although tuning the number of merged checkpoints and the merge interval can yield slight gains on downstream metrics.
Midtraining
Midtraining has become common in the LLM literature, and we incorporate an analogous stage into our pipeline. Its focus is to warm up the model’s distribution before the supervised finetuning (SFT) stage. We find that midtraining is typically the last point in the pipeline at which we can equip the model with downstream capabilities such as high-fidelity, high-resolution generation, strong domain coverage, and text rendering.
Supervised finetuning (SFT)
In the supervised finetuning (SFT) stage, we curate a small, dedicated set of highly aesthetic images. The objective is to further bias the model toward aesthetically desirable directions. We find this stage particularly helpful for improving overall checkpoint quality and for addressing the high-saturation and texture issues that are prevalent in earlier checkpoints.
After training domain-specific SFT checkpoints, we use model merging to produce a generalist SFT checkpoint. Model merging yields diminishing returns toward the later stages of the pipeline, as the directions of improvement begin to conflict across checkpoints.
Preference optimization (PO)
Preference optimization (PO) is the first stage of our post-training stack and consists of a two-stage pipeline. In the first stage, we run a large-scale synthetic preference-pair generation pipeline for initial refinement, using a strategy similar to delta learning; we ensure that the majority of pairs include at least one on-policy sample. The second stage is a calibration stage that uses only human annotations. These annotations are collected entirely in house, by people familiar with the specific strengths, weaknesses, and quirks of the model.
A common phenomenon during PO is policy divergence. At a high level, preference-optimization methods such as DPO encourage the model to increase the margin between its likelihood of generating a preferred sample and that of generating a dispreferred one, relative to the reference model. In practice, across different preference-dataset mixtures, we observe that the model achieves this objective by decreasing the likelihood of generating both samples, but at different rates. This would be desirable if both the winning and losing samples were of lower quality than the current model distribution, but that assumption does not always hold, depending on how the preference set was curated. Moreover, this divergence drifts the model away from the general pretraining distribution, which manifests as high-frequency artifacts in the later stages of training. To mitigate this, we designed a variant of DPO, which we call STPO, that adds an auxiliary loss and a modification to the original DPO formulation in order to reduce this divergence.
Reinforcement learning (RL)
Reinforcement learning (RL) is the final stage of the training pipeline. We use a multi-reward GRPO-style method with several reward models: (1) a general aesthetic model, (2) a prompt-following reward , (3) a text-rendering reward, (4) an artifact and structure reward. The general aesthetic model is obtained by finetuning an open-source VLM on the preference data collected during the PO stage. We carefully design the reward structure and tune the data mixture to prevent artifacts introduced by reward hacking.
Unlike general aesthetic rewards, which are inherently subjective, prompt following and text rendering provide more concrete signals because they can be checked against the user’s stated intent. The challenge is that this intent varies widely across prompts. To handle this, we use a prompt-specific rubric reward inspired by rubric-based evaluation in LLM training. Instead of asking a judge model for a single holistic score, we decompose each prompt into verifiable requirements and evaluate the generated image against them. This gives the RL stage a more structured signal for alignment with user intent, making the model better at satisfying fine-grained prompt constraints without reducing prompt following to generic image quality.
We also found that optimizing only for aesthetics and prompt following can lead to reward hacking. The model may learn to produce images that appear plausible at first glance while containing structural artifacts such as extra fingers, malformed limbs, or distorted text. These failures are visually obvious to humans but are often missed by general-purpose VLM judges. To address this, we train a dedicated artifact reward model that detects these structural errors and discourages the RL stage from improving benchmark-facing signals at the expense of visual correctness.
During the RL stage, we find that success depends not only on the quality of the reward models, but also on how efficiently training compute is allocated across prompts. Reward models define the direction of improvement, while the prompt pool determines where the model receives useful learning signal. We therefore curate a broad pool of prompts spanning diverse styles, concepts, settings, and subjects, then continuously analyze the reward statistics of generated groups to identify which prompts are most informative. Prompts that are already too easy, consistently too hard, or produce little variance across samples contribute limited signal and are deprioritized or removed. In practice, effective RL requires treating prompt selection as a resource-allocation problem, where the training process should spend more compute on examples where the model can still learn, and less on examples that provide saturated or noisy feedback.
Another practical consideration in diffusion RL is how to handle classifier-free guidance (CFG). Both rollout generation and training can be performed with or without CFG, and different choices create different trade-offs between alignment, stability, and efficiency. After ablations, we found it important to keep the rollout and training distributions aligned while avoiding unnecessary computational overhead. We therefore train the whole RL stage without CFG. This setting quickly improves the conditional model distribution, bringing no-CFG samples much closer to guided samples early in training. At inference time, CFG can still be enabled as an additional control knob, further improving quality when desired.
Timestep distillation
After the RL stage, we include an optional timestep-distillation stage in which we apply guidance distillation and timestep distillation simultaneously. We considered several distillation techniques, including DMD, DMD2, Decoupled DMD, piFlow, and APT, but adopted Trajectory Distribution Matching (TDM) for the following reasons. We sought a technique that was simple to tune, with minimal hyperparameters, which ruled out GAN-based methods and piFlow (the latter requires adapting the model into a multi-timestep prediction model). We chose TDM because it provides a fast, data-free method with flexible multistep distillation.
DMD distills the teacher by matching the distributions of real and generated samples over the clean-image distribution. Accordingly, standard DMD uses a few-step student to predict a clean image and then renoises the prediction to train the student (see figure above). Unlike DMD, which matches only the clean-image distribution, TDM applies DMD across timesteps, effectively performing distribution matching at the trajectory level rather than at the sample level. Since our goal was a flexible multistep student, we found TDM to be the most suitable method for our use case.
Prompt Expansion
Dense prompts reliably produce better image-generation results, but users rarely write prompts that resemble the rich captions used during training. We frame this as a distribution-mapping problem: the image model is best conditioned on detailed captions that lie close to its training distribution, while real user prompts are often short, conversational, and underspecified. We therefore develop a prompt expander that interprets user intent and maps an input prompt into a richer, model-friendly caption.
We first perform supervised finetuning on an existing open-source LLM. To curate training data, we use another language model to generate synthetic “user captions” from long captions: shorter, more conversational, semi-instructional prompts that intentionally omit many visual details present in the target caption. This produces paired data of the form underspecified user prompt -> expanded, model-friendly caption. We also synthesize thinking traces to preserve the model’s reasoning ability, as we find that an intermediate intent-reconstruction step improves downstream behavior. Beyond this, we apply a small amount of targeted distribution shaping. At a high level, we oversample visually rich and artistic imagery to give the expander broader coverage of creative and aesthetic prompt styles, and add a lightweight photographic-medium bias for prompts that should expand into photorealistic descriptions. The goal is not to impose a house style, but to ensure that the expanded-prompt distribution covers both expressive, art-directed imagery and straightforward photorealistic requests.
SFT brings the expander close to the desired caption distribution, but matching synthetic targets is not the same as improving the final image. We therefore use RL to optimize the expander directly through the generations it produces. At this stage, the objective shifts from imitating the target caption to producing expansions that improve image quality while preserving the user’s intent. We train with GDPO under a multi-reward objective: image-level rewards measure the quality and preference of the resulting generations, while prompt-level verifiable rewards check whether the expansion remains faithful to the original request. We also include safety and constraint checks to prevent the expander from introducing clearly unprompted or unacceptable content. Since these checks are sparse by nature, we use them as gates on the overall reward rather than as dense optimization signals.
We sought to balance matching a realistic distribution of user inputs with ensuring that each group contained a high-contrast mix of good and bad rollouts. To this end, the RL prompt mix combines realistic user-like traffic with mined hard cases. The realistic side includes actual prompts and previously observed failures, supplemented with hand-curated failures and synthetic augmentations of known failure modes. Curated examples come from internal downvotes, bug reports, and manually rewritten prompts, and are bucketed so that every known failure class remains represented. Synthetic examples start from hand-authored reward-trigger probes, are expanded into many variants, and are scored offline with the same reward schema used during RL. We select prompts that are “hard but not hopeless,” producing groups with intermediate composite scores and real reward variance, so that GDPO receives a meaningful preference signal rather than only obvious wins or total failures.
One failure mode we explicitly optimize against is diversity collapse. Prompt expanders can learn a single safe, high-reward house style, especially when image rewards dominate. To counter this, we add a simple DINOv3 embedding diversity score over prompt groups, rewarding intra-group visual diversity alongside quality and alignment. We briefly experiment with annealing the diversity reward, but find that once its weight becomes too small, the model quickly collapses toward less varied generations. In practice, keeping the diversity reward active throughout training is necessary to preserve variation.
Style reference system
Our style-reference system builds on the base model. It allows users to generate images from text while using one or more reference images to guide the output style. We designed the system to support (1) smooth semantic mixing of multiple styles, (2) continuous control over the strength of each style reference, and (3) state-of-the-art adherence to complex styles.
Style transfer is difficult because of the ambiguity in what constitutes “style” versus “content” in an image. One of the most common failure modes was the leakage of content and subject matter from the style image into the final image. Furthermore, unlike conventional editing tasks, whose data can be mined from sources such as video, style-transfer data is significantly harder to obtain in large quantities at the fidelity we targeted.
To address these challenges, we devised a novel self-supervised technique for training the style-reference module, followed by a preference-optimization step to further align the outputs.
Training infrastructure
Our distributed training framework is built from scratch on PyTorch. We rely primarily on the DTensor abstraction and the torch-native features supported by the torchtitan project. For most of our pretraining and post-training runs, we use FSDP2 together with Megatron-LM-style tensor parallelism. For settings with a TP size larger than 2, we enable async-TP via a torch.compile flag, which offers a moderate speedup over naive TP. Since the autoencoder parameters add minimal memory overhead, we leave them replicated across all devices and shard only the text encoder and the main MMDiT backbone. For intra-node connections, we use NVLinkSharp, and for inter-node connections we use InfiniBand.
For training efficiency, we use a slightly wider model with larger hidden dimensions, for two reasons. First, a larger hidden size increases the computational intensity of each layer, which makes it easier to hide latency with FSDP2 prefetching; reducing the number of layers also reduces the number of all-gather and reduce-scatter operations. This change significantly reduced NCCL-related errors throughout our pretraining runs. Second, larger matrix-multiplication sizes help amortize the quantization and dequantization overhead of 8-bit training.
We rely heavily on torch.compile as our main optimization strategy. For attention, we default to the latest cuDNN kernel and use FlexAttention or FlashAttention 3 as needed. At low resolution we use selective activation checkpointing, and at higher resolution, where activations begin to dominate memory, we use full activation checkpointing.
For dataloading, we use Parquet as our primary format. For each row, we store a reference to the image (for example, a local path or S3 location), the crop and resize dimensions, the captions, and any other relevant metadata. For large runs, we shuffle and pack the rows ahead of time so that each dataloader worker loads a batch of images with the same aspect ratio. This packing allows us to encode the latents in a single autoencoder pass.
This implementation has several benefits. By preshuffling the data, we can perform a sequential scan over disk for performant dataloading while ensuring proper global shuffling. Preshuffling is also essential for reproducibility and debugging, since the data can be replayed in exact order to identify any sample that may have caused a loss spike.
During our largest pretraining runs, we encountered various infrastructure and fault-tolerance challenges. Conventional large-scale distributed training introduces many global synchronization points across the cluster (for example, the gradient all-reduce across DP replicas) and is inherently flaky: a single GPU failure or straggler can bring down the entire run. Fault-tolerance solutions such as torch-ft and decoupled DiLoCo exist, but at our scale we found that optimizing for mean time between failures (MTBF) and mean time to recovery (MTTR) through fast, frequent checkpointing and improved startup time was a satisfactory solution.
Another crucial factor for reliability was maintaining homogeneous load on I/O, CPU, and GPU across the training devices. We explicitly design the dataloader so that each CPU and GPU is under approximately equal load. In our initial large runs, a high-resolution image used during a low-resolution stage would be cropped and resized to low resolution on the fly; for our largest runs, however, this added uneven CPU and I/O load across devices depending on whether the original image was high resolution. To mitigate this, we crop and resize all images to the target training resolution ahead of time. We further ensure that every GPU receives a tensor input padded to exactly the same shape, which evens out the load.
For our RL infrastructure, we disaggregate reward-model inference from the main training process. Since Krea 2 was our first major RL iteration, we use a simple design in which the training and rollout GPUs are shared. In the near future, we plan to implement a disaggregated training and inference setup to support techniques such as PipelineRL for asynchronous RL training.
Systems Infrastructure
Our research ran within a single Kubernetes cluster in which GPUs were shared with production inference. The system was designed so that research could claim the entire GPU pool when required: if every GPU in the cluster was allocated to a training run, Krea’s inference workload would automatically migrate elsewhere. This allowed us to disregard production capacity when launching training runs, as the system handled traffic failover and kept production responsive even when no GPUs remained available locally.
This capability was not present from the outset. The scheduling and management systems evolved alongside the research team’s needs over the course of the research cycle. In the following sections we describe the main components: workload scheduling with Kueue, scaling inference outside the cluster, the scheduling policy that ties the two together, our training launch procedure, and the observability stack that proved essential for large-scale pretraining.
Scheduling with Kueue
Kueue has been central to our setup, although our usage has changed substantially. It provides a two-tier priority system that combines Kueue’s Workload priority with Kubernetes’ Pod priority. When configured correctly, this two-tier design yields useful scheduling semantics.
We considered custom schedulers such as Volcano, as well as modifying the kube-scheduler directly, which would have offered additional desirable properties. Ultimately, the default Kubernetes scheduler combined with Kueue was sufficient for our requiremen
関連記事
Engram の紹介:コンテキスト上で計算リソースをスケーリングする技術
TLDR AI は、コンテキスト内で計算リソースを拡張可能にする新技術「Engram」を発表した。この手法により、AI モデルの処理能力を文脈に応じて柔軟に拡大できることが示された。
NVIDIA と AWS が大規模な AI の実用化に向けて協力
NVIDIA と Amazon Web Services(AWS)が、AI を大規模に生産環境で運用するための協力を開始した。両社はインフラと技術の統合により、企業による AI の実装を加速させる方針を示している。
ソフトウェアの品質における新時代が今日始まる(5 分読了)
TLDR AI は、ソフトウェア開発の品質管理において新たな転換点となる重要な発表を行い、業界全体に影響を与える可能性があると示唆している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み