NVIDIA Nemotron 3 SuperがAmazon Bedrockで利用可能に
NVIDIAは120BパラメータのハイブリッドMoEモデル「Nemotron 3 Super」をAmazon Bedrock上でサーバーレスフルマネージドモデルとして提供開始し、推論効率とエージェントタスクの精度を大幅に向上させた。
キーポイント
ハイブリッドMoEアーキテクチャと仕様
Transformer-Mambaを融合したMoE方式を採用し、120B総パラメータのうち12Bのみがアクティブ。最大256Kトークンのコンテキスト長に対応し、マルチエージェントシステムに最適化されている。
推論効率と高精度なベンチマーク実績
前モデル比で最大5倍のスループットを実現し、Token Budget機能により推論トークンを最小限に抑えつつ高精度な推論が可能。AIME 2025やSWE Benchなどの主要ベンチマークで最高水準を達成している。
AWS Bedrockでのサーバーレス提供と実装
フルマネージドかつサーバーレスな推論環境として提供され、インフラ構築やスケーリングの複雑さを排除。開発者はBedrockのツール群を活用して生成AIアプリケーションを迅速に実装できる。
オープンウェイトとカスタマイズ flexibility
モデル重み、学習データセット、レシピが公開されており、企業はプライバシーとセキュリティ要件に応じて独自インフラへの展開やファインチューニングを柔軟に選択可能。
モデルアーキテクチャとBedrockの統合メリット
Hybrid Transformer-Mamba構造とLatent MoEを組み合わせ、Bedrockのサーバーレスインフラでバックエンド管理の手間なくスケーラブルな高推論アプリケーションを構築可能。
ChatCompletionsAPIの実装コード例
モデルID、システム/ユーザーメッセージ、温度パラメータなどを指定してAPIを呼び出し、生成されたレスポンスを抽出・出力する基本的な実装手順を示している。
影響分析・編集コメントを表示
影響分析
この発表は、ハイブリッドMoEモデルの計算効率性とオープンソースの柔軟性を主要クラウドプラットフォームで統合した実用的な展開を示している。開発者はインフラ管理の手間を省きつつ、高度な推論性能とエージェント機能を活用できるため、実務レベルの生成AIアプリケーション普及に寄与する。ただし、大規模モデルのクラウド利用におけるデータプライバシーとコスト管理の最適化は引き続き組織側の課題となる。
編集コメント
クラウドベンダー間のモデル競争が激化する中、ハイブリッドアーキテクチャとオープンウェイト戦略を組み合わせるNVIDIAの姿勢は、開発者の選択肢拡大に直結する。今後はBedrock上の利用料金体系とコンテキスト長活用法が実装の鍵となるだろう。
Nemotron 3 Super が、Amazon Bedrock で完全に管理されサーバーレスのモデルとして利用可能になりました。これは、すでに Amazon Bedrock 環境内で利用可能な Nemotron Nano モデルに加わるものです。
Amazon Bedrock 上で NVIDIA Nemotron オープンモデルを利用することで、インフラストラクチャの複雑さを管理することなく、イノベーションを加速し、具体的なビジネス価値を提供できます。Nemotron を通じて、Amazon Bedrock の完全な推論機能とその広範な機能やツールを活用し、生成 AI アプリケーションを構築・運用することが可能です。
本記事では、Nemotron 3 Super モデルの技術的特徴を探り、潜在的なアプリケーションユースケースについて議論します。また、Amazon Bedrock 環境内で生成 AI アプリケーションにこのモデルを使用を開始するための技術的なガイダンスも提供します。
Nemotron 3 Super について
Nemotron 3 Super は、マルチエージェントアプリケーションおよび専門的なエージェント AI システム向けに、最先端の計算効率と精度を備えたハイブリッド型 Expert の混合 (MoE) モデルです。このモデルは、オープンウェイト、データセット、レシピと共にリリースされており、開発者はプライバシーとセキュリティを強化するために、自社のインフラ上でモデルのカスタマイズ、改善、デプロイを行うことができます。
モデル概要:
- アーキテクチャ:
ハイブリッド Transformer-Mamba アーキテクチャを持つ MoE (Mixture of Experts)。
- 最小限の推論トークン生成で精度を向上させるためのトークンバジェットをサポートします。
- 精度:
サイズカテゴリにおいて最高クラスのスループット効率を実現し、以前の Nemotron Super モデルと比較して最大 5 倍の性能を発揮します。
- 主要なオープンモデルの中で推論およびエージェントタスクにおける最先端の精度を有し、前バージョンと比較して最大 2 倍高い精度を達成しています。
- AIME 2025、Terminal-Bench、SWE Bench (検証済み)、多言語対応、RULER など、主要なベンチマークにおいて高い精度を実現します。
- NVIDIA NeMo を用いたマルチ環境強化学習 (RL) 訓練により、10 以上の環境全体で最先端の精度を達成しました。
- モデルサイズ: 120 B (1200 億パラメータ)、アクティブパラメータは 12 B
- コンテキスト長: 最大 256K トークン
- モデル入力: テキスト
- モデル出力: テキスト
- 対応言語: 英語、フランス語、ドイツ語、イタリア語、日本語、スペイン語、中国語
Latent MoE
Nemotron 3 Super は、エキスパートが出力をトークン空間に投影する前に共有された潜在表現上で動作する「Latent MoE(潜在型混合専門家モデル)」を採用しています。このアプローチにより、推論コストは同じままにしながら、4 倍の数のエキスパートを活用できるようになり、微妙な意味構造やドメイン抽象化、あるいは多段推論パターンに対する専門性をより高めることが可能になります。
Multi-token prediction (MTP)
MTP(マルチトークン予測)により、モデルは単一の順方向パスで複数の未来トークンを予測できるようになり、長い推論シーケンスや構造化された出力におけるスループットが大幅に向上します。計画策定、軌道生成、拡張された chain-of-thought(思考連鎖)、またはコード生成においては、MTP がレイテンシを低減し、エージェントの応答性を改善します。
Nemotron 3 Super のアーキテクチャとトレーニング方法について詳しく知りたい場合は、Introducing Nemotron 3 Super: an Open Hybrid Mamba Transformer MoE for Agentic Reasoning をご覧ください。
NVIDIA Nemotron 3 Super use cases
Nemotron 3 Super は、さまざまな業界における多様なユースケースを推進する原動力となります。主なユースケースには以下が含まれます
- ソフトウェア開発:コードの要約などのタスクを支援します。
- 金融:データの抽出、収入パターンの分析、不正取引の検出により融資処理を加速し、サイクルタイムとリスクの低減に貢献できます。
- サイバーセキュリティ:問題のトリアージ(優先度付け)、詳細なマルウェア解析、およびセキュリティ脅威への積極的な狩り活動に活用できます。
- 検索:ユーザーの意図を理解して適切なエージェントを起動するのを支援します。
- リテール:リアルタイムでパーソナライズされた製品推薦とサポートを提供することで、在庫管理の最適化や店内サービスの向上を支援します。
- マルチエージェントワークフロー:計画、ツール使用、検証、ドメイン実行などタスク固有のエージェントをオーケストレーションし、複雑なエンドツーエンドのビジネスプロセスを自動化します。
Amazon Bedrock で NVIDIA Nemotron 3 Super を使い始めるには、以下の手順に従ってテストを行ってください。
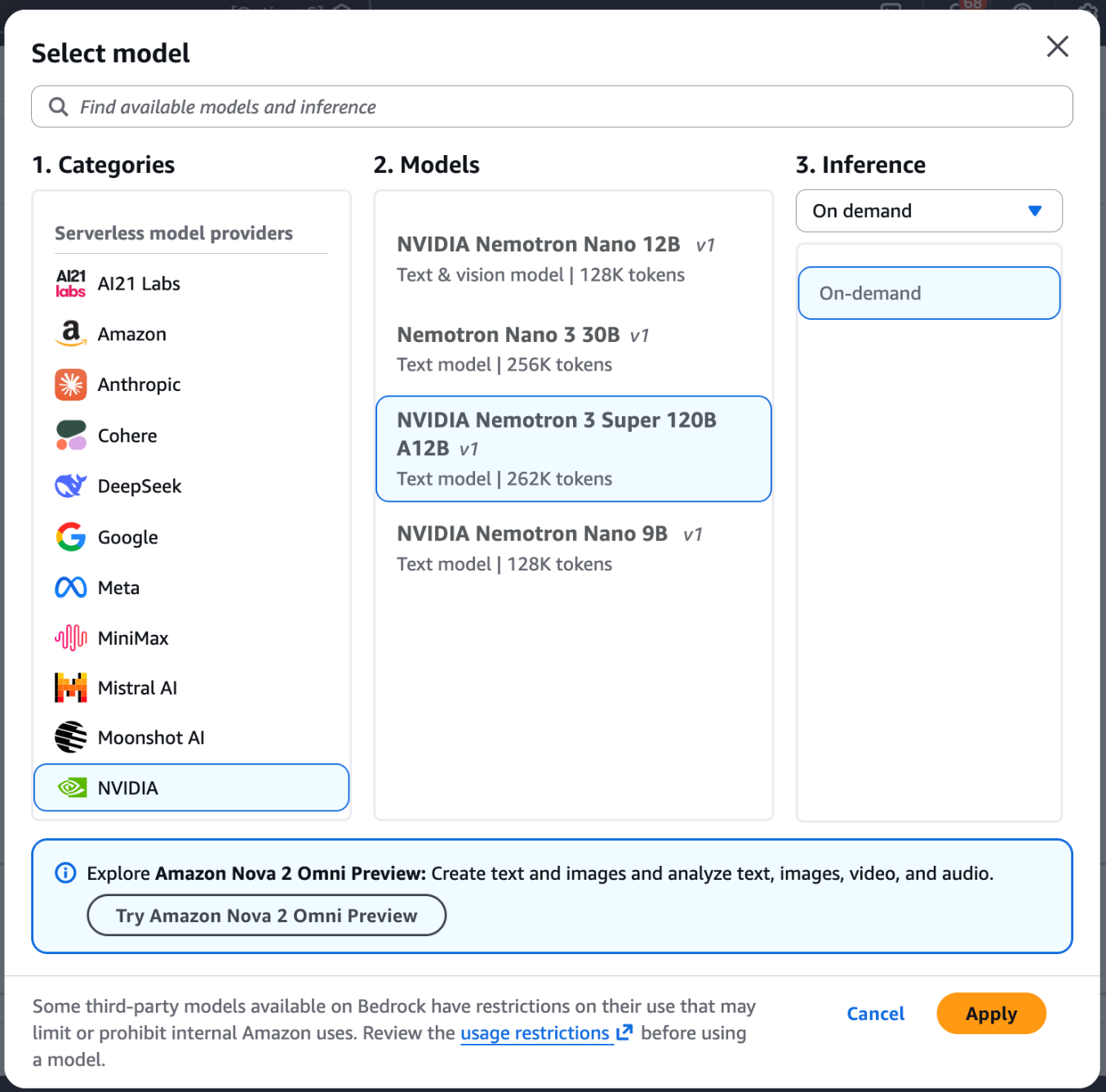
- Amazon Bedrock コンソールにアクセスし、左側のメニュー(Test セクション内)から Chat/Text playground を選択します。
- プレイグラウンドの左上隅にある Select model を選択します。
- カテゴリリストから NVIDIA を選び、NVIDIA Nemotron 3 Super を選択します。
- Apply を選択してモデルを読み込みます。
前工程を完了した後、すぐにモデルのテストを行うことができます。Nemotron 3 Super の能力を真に示すためには、単純な構文を超えて、複雑なエンジニアリング課題に取り組む必要があります。高度な推論モデルは、「システムレベル」の思考において卓越しており、アーキテクチャ上のトレードオフ、並行処理、分散状態管理のバランスを取る必要があります。
以下のプロンプトを使用して、グローバルに分散されたサービスの設計を行いましょう:
"Python で 100,000 リクエスト/秒を複数の地理的リージョンでサポートする分散型レート制限サービスを設計してください。
- トークンバケット方式と固定ウィンドウ方式など、高レベルのアーキテクチャ戦略を提供し、グローバルスケールでの選択理由を説明してください。2. バッキングストアとして Redis を使用したスレッドセーフな実装を書いてください。3. 複数のインスタンスが同じカウンターを更新する際の「競合状態」の問題に対処してください。4. アプリと Redis の間のネットワーク遅延をシミュレートする pytest スイートを含めてください。"
このプロンプトは、モデルにシニアの分散システムエンジニアとして動作させることを要求します。トレードオフについての推論、スレッドセーフなコードの生成、障害モードの予測、そして現実的なテストによる検証を、すべて一つの整合性のある回答の中で行う必要があります。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
AWS CLI および SDK を使用した利用
モデル ID *nvidia.nemotron-super-3-120b* を用いて、プログラムからモデルにアクセスすることができます。このモデルは、AWS Command Line Interface (AWS CLI) および AWS SDK を通じて、モデル ID に *nvidia.nemotron-super-3-120b* を指定することで、InvokeModel および Converse の両 API をサポートしています。さらに、Amazon Bedrock OpenAI SDK 互換 API もサポートしています。
AWS Command Line Interface (AWS CLI) および InvokeModel API を使用して、ターミナルから直接モデルを呼び出すには、以下のコマンドを実行してください:
aws bedrock-runtime invoke-model \
--model-id nvidia.nemotron-super-3-120b \
--region us-west-2 \
--body '{"messages": [{"role": "user", "content": "Type_Your_Prompt_Here"}], "max_tokens": 512, "temperature": 0.5, "top_p": 0.9}' \
--cli-binary-format raw-in-base64-out \
invoke-model-output.txt
AWS SDK for Python (Boto3) を通じてモデルを呼び出したい場合は、Converse API を使用してプロンプトを送信するための以下のスクリプトを使用してください:
import boto3
from botocore.exceptions import ClientError
利用したい AWS リージョンで Bedrock Runtime クライアントを作成します。
client = boto3.client("bedrock-runtime", region_name="us-west-2")
モデル ID を設定する
model_id = "nvidia.nemotron-super-3-120b"
ユーザーメッセージで会話を開始する。
user_message = "Type_Your_Prompt_Here"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# 基本的な推論設定を使用して、メッセージをモデルに送信する。
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
)
# 応答テキストを抽出して出力する。
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: '{model_id}' を呼び出せません。理由:{e}")
exit(1)
To invoke the model through the Amazon Bedrock OpenAI-compatible ChatCompletions endpoint you can proceed as follows using the OpenAI SDK:
# OpenAI SDK をインポートする
from openai import OpenAI
環境変数を設定する
os.environ["OPENAI_API_KEY"] = ""
os.environ["OPENAI_BASE_URL"] = "https://bedrock-runtime..amazon.com/openai/v1"
モデル ID を設定する
model_id = "nvidia.nemotron-super-3-120b"
プロンプトを設定する
system_prompt = "Type_Your_System_Prompt_Here"
user_message = "Type_Your_User_Prompt_Here"
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
ChatCompletionsAPI の使用
response = client.chat.completions.create(
model= model _ID,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
],
temperature=0,
max_completion_tokens=1000
)
応答テキストの抽出と表示
print(response.choices[0].message.content)
結論
本稿では、次世代のエージェント型 AI アプリケーションを構築するために、Amazon Bedrock で NVIDIA Nemotron 3 Super を使い始める方法をご紹介しました。このモデルが持つ高度なハイブリッド Transformer-Mamba アーキテクチャと Latent MoE(潜在混合専門家)を、完全に管理されたサーバーレスインフラストラクチャである Amazon Bedrock と組み合わせることで、組織はバックエンド管理の重労働なしに、大規模で推論能力が高く効率的なアプリケーションを展開できるようになりました。このモデルが特定のワークフローにどのような効果をもたらすか、ぜひご確認ください。
- 今すぐお試しください:Amazon Bedrock コンソールへお越しください。モデルプレイグラウンドで NVIDIA Nemotron 3 Super を試すことができます。
- 構築する:AWS SDK を探索し、Nemotron 3 Super を既存の生成 AI パイプラインに統合してください。
著者について
 image
image
Aris Tsakpinis
Aris Tsakpinis は、Amazon Bedrock および広範な生成 AI オープンソース環境におけるオープンウェイトモデルに焦点を当てた、生成 AI 専門のシニアスペシャリストソリューションアーキテクトです。専門職に加えて、彼はレゲンスブルク大学で機械学習工学の博士号を取得しており、その研究は科学分野における応用生成 AI に焦点を当てています。

Abdullahi Olaoye
Abdullahi Olaoye は NVIDIA のシニア AI ソリューションアーキテクトであり、AI モデルのデプロイメント、推論、および生成 AI ワークフローを最適化するために、NVIDIA AI ライブラリ、フレームワーク、製品をクラウド AI サービスやオープンソースツールと統合することに専門知識を持っています。彼はクラウドプロバイダーと協力して、AI ワークロードのパフォーマンス向上を図り、NVIDIA 搭載の AI および生成 AI ソリューションの採用を推進しています
原文を表示
Nemotron 3 Super is now available as a fully managed and serverless model on Amazon Bedrock, joining the Nemotron Nano models that are already available within the Amazon Bedrock environment.
With NVIDIA Nemotron open models on Amazon Bedrock, you can accelerate innovation and deliver tangible business value without managing infrastructure complexities. You can power your generative AI applications with Nemotron through the fully managed inference of Amazon Bedrock, using its extensive features and tooling.
This post explores the technical characteristics of the Nemotron 3 Super model and discusses potential application use cases. It also provides technical guidance to get started using this model for your generative AI applications within the Amazon Bedrock environment.
About Nemotron 3 Super
Nemotron 3 Super is a hybrid Mixture of Experts (MoE) model with leading compute efficiency and accuracy for multi-agent applications and for specialized agentic AI systems. The model is released with open weights, datasets, and recipes so developers can customize, improve, and deploy the model on their infrastructure for enhanced privacy and security.
Model overview:
- Architecture:
MoE with Hybrid Transformer-Mamba architecture.
- Supports token budget for providing improved accuracy with minimum reasoning token generation.
- Accuracy:
Highest throughput efficiency in its size category and up to 5x over the previous Nemotron Super model.
- Leading accuracy for reasoning and agentic tasks among leading open models and up to 2x higher accuracy over the previous version.
- Achieves high accuracy across leading benchmarks, including AIME 2025, Terminal-Bench, SWE Bench verified and multilingual, RULER.
- Multi-environment RL training gave the model leading accuracy across 10+ environments with NVIDIA NeMo.
- Model size: 120 B with 12 B active parameters
- Context length: up to 256K tokens
- Model input: Text
- Model output: Text
- Languages: English, French, German, Italian, Japanese, Spanish, and Chinese
Latent MoE
Nemotron 3 Super uses latent MoE, where experts operate on a shared latent representation before outputs are projected back to token space. This approach allows the model to call on 4x more experts at the same inference cost, enabling better specialization around subtle semantic structures, domain abstractions, or multi-hop reasoning patterns.
Multi-token prediction (MTP)
MTP enables the model to predict several future tokens in a single forward pass, significantly increasing throughput for long reasoning sequences and structured outputs. For planning, trajectory generation, extended chain-of-thought, or code generation, MTP reduces latency and improves agent responsiveness.
To learn more about Nemotron 3 Super’s architecture and how it is trained, see Introducing Nemotron 3 Super: an Open Hybrid Mamba Transformer MoE for Agentic Reasoning.
NVIDIA Nemotron 3 Super use cases
Nemotron 3 Super helps power various use cases for different industries. Some of the use cases include
- Software development: Assist with tasks like code summarization.
- Finance: Accelerate loan processing by extracting data, analyzing income patterns, and detecting fraudulent operations, which can help reduce cycle times and risk.
- Cybersecurity: Can be used to triage issues, perform in-depth malware analysis, and proactively hunt for security threats.
- Search: Can help understand user intent to activate the right agents.
- Retail: Can help optimize inventory management and enhance in-store service with real-time, personalized product recommendations and support.
- Multi-agent Workflows: Orchestrates task‑specific agents—planning, tool use, verification, and domain execution—to automate complex, end‑to‑end business processes.
Get Started with NVIDIA Nemotron 3 Super in Amazon Bedrock. Complete the following steps to test NVIDIA Nemotron 3 Super in Amazon Bedrock
- Navigate to the Amazon Bedrock console and select Chat/Text playground from the left menu (under the Test section).
- Choose Select model in the upper-left corner of the playground.
- Choose NVIDIA from the category list, then select NVIDIA Nemotron 3 Super.
- Choose Apply to load the model.
After completing the previous steps, you can test the model immediately. To truly showcase Nemotron 3 Super’s capability, we will move beyond simple syntax and task it with a complex engineering challenge. High-reasoning models excel at “system-level” thinking where they must balance architectural trade-offs, concurrency, and distributed state management.
Let’s use the following prompt to design a globally distributed service:
*"Design a distributed rate-limiting service in Python that must support 100,000 requests per second across multiple geographic regions.*
*1. Provide a high-level architectural strategy (e.g., Token Bucket vs. Fixed Window) and justify your choice for a global scale.* *2. Write a thread-safe implementation using Redis as the backing store.* *3. Address the 'race condition' problem when multiple instances update the same counter.* *4. Include a pytest suite that simulates network latency between the app and Redis."*
This prompt requires the model to operate as a senior distributed-systems engineer — reasoning about trade-offs, producing thread-safe code, anticipating failure modes, and validating everything with realistic tests, all in a single coherent response.
Using the AWS CLI and SDKs
You can access the model programmatically using the model ID *nvidia.nemotron-super-3-120b* . The model supports both the InvokeModel and Converse APIs through the AWS Command Line Interface (AWS CLI) and AWS SDK with nvidia.nemotron-super-3-120b as the model ID. Further, it supports the Amazon Bedrock OpenAI SDK compatible API.
Run the following command to invoke the model directly from your terminal using the AWS Command Line Interface (AWS CLI) and the InvokeModel API:
aws bedrock-runtime invoke-model \
--model-id nvidia.nemotron-super-3-120b \
--region us-west-2 \
--body '{"messages": [{"role": "user", "content": "Type_Your_Prompt_Here"}], "max_tokens": 512, "temperature": 0.5, "top_p": 0.9}' \
--cli-binary-format raw-in-base64-out \
invoke-model-output.txt If you want to invoke the model through the AWS SDK for Python (Boto3), use the following script to send a prompt to the model, in this case by using the Converse API:
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# Set the model ID
model_id = "nvidia.nemotron-super-3-120b"
# Start a conversation with the user message.
user_message = "Type_Your_Prompt_Here"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)To invoke the model through the Amazon Bedrock OpenAI-compatible ChatCompletions endpoint you can proceed as follows using the OpenAI SDK:
# Import OpenAI SDK
from openai import OpenAI
# Set environment variables
os.environ["OPENAI_API_KEY"] = ""
os.environ["OPENAI_BASE_URL"] = "https://bedrock-runtime..amazon.com/openai/v1"
# Set the model ID
model_id = "nvidia.nemotron-super-3-120b"
# Set prompts
system_prompt = “Type_Your_System_Prompt_Here”
user_message = "Type_Your_User_Prompt_Here"
# Use ChatCompletionsAPI
response = client.chat.completions.create(
model= model _ID,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
],
temperature=0,
max_completion_tokens=1000
)
# Extract and print the response text
print(response.choices[0].message.content)Conclusion
In this post, we showed you how to get started with NVIDIA Nemotron 3 Super on Amazon Bedrock for building the next generation of agentic AI applications. By combining the model’s advanced Hybrid Transformer-Mamba architecture and Latent MoE with the fully managed, serverless infrastructure of Amazon Bedrock, organizations can now deploy high-reasoning, efficient applications at scale without the heavy lifting of backend management. Ready to see what this model can do for your specific workflow?
- Try it now: Head over to the Amazon Bedrock Console to experiment with NVIDIA Nemotron 3 Super in the model playground.
- Build: Explore the AWS SDK to integrate Nemotron 3 Super into your existing generative AI pipelines.
About the authors
Aris Tsakpinis
Aris Tsakpinis is a Senior Specialist Solutions Architect for Generative AI focusing on open weight models on Amazon Bedrock and the broader generative AI open-source environment. Alongside his professional role, he is pursuing a PhD in Machine Learning Engineering at the University of Regensburg, where his research focuses on applied generative AI in scientific domains.
Abdullahi Olaoye
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open-source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with cloud providers to help enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み