Amazon EC2上でのNVIDIA Nemotron Speech ASRのドメイン適応のためのファインチューニング
AWSとNVIDIA、Heidi Healthの連携により、医療分野向けに合成音声データを用いてNVIDIA Nemotron ASRモデルをAmazon EC2上でドメイン適応(ファインチューニング)するエンドツーエンドのMLOpsアーキテクチャと実装手順を解説している。
キーポイント
医療ASRの課題と合成データ活用
既存モデルが専門用語やアクセント、コードスイッチングに対応できない課題に対し、合成音声データを用いて高精度な転写を実現するファインチューニング手法を提示。
AWSインフラとオープンソースAIツールの統合
NVIDIA A100搭載EC2 GPUインスタンス上でNeMoとDeepSpeedを組み合わせ、メモリ効率の高い分散学習環境を構築する具体的な構成を示している。
Heidi Healthの実装事例とビジネス価値
週240万件の相談を処理するAIケアパートナーにおいて、臨床記録の正確性を保ちながら医師の業務負荷を軽減する実証事例を提供。
実験管理からスケーラブル推論までのMLOpsパイプライン
MLflow/TensorBoardによる追跡、EKS/Fsx for Lustreによる展開、AI Gateway/LangfuseによるAPI管理までを統合し、本番環境向けの安定性と可観測性を担保する。
Docker環境の初期化設定
ENVディレクティブでDEBIAN_FRONTENDとTZを固定し、コンテナビルド時の対話プロンプトやタイムゾーンの違いによるエラーを防いでいます。
NeMoおよびPyTorch Lightningの依存関係構築
Cythonのインストールと、特定ブランチ(bug_fix)のpytorch-lightningを編集可能モードでインストールすることで、Nemotron ASRの動作環境を最適化しています。
リソース要件とインフラ構成
p4d.24xlarge(A100 GPU 8基)またはP5インスタンス、8ノード(計64GPU)、ノードあたり500GB以上のストレージを推奨し、予算やデータ規模に応じてg6eなどへスケールダウン可能。
影響分析・編集コメントを表示
影響分析
この記事は、医療現場のような専門用語やアクセントが複雑な領域において、ASRモデルの精度を現実的に向上させるための実装ロードマップを提供している。AWSとNVIDIAのコラボレーションにより、オープンソースAIとクラウドインフラのシームレスな統合がビジネスレベルで実現可能であることを示唆しており、業界全体のドメイン特化型AI構築の標準パターンを確立する可能性がある。
編集コメント
技術ブログ特有の実践的なアーキテクチャ図と構成要素が明示されており、医療現場のような厳格な精度要求を持つ分野のAI実装において、インフラ選定とMLOps設計の参考になる貴重な事例である。
*この投稿は、AWS、NVIDIA、および Heidi による共同制作です。*
自動音声認識(ASR)、通称音声テキスト変換(STT)は、ヘルスケア、カスタマーサービス、メディア制作など、さまざまな業界においてますます重要な役割を果たしています。事前学習済みモデルは一般的な音声処理に強力な能力を発揮しますが、特定のドメインやユースケース向けにファインチューニングを施すことで、精度とパフォーマンスをさらに向上させることができます。
本稿では、リーダーボード首位の NVIDIA Nemotron Speech 自動音声認識(ASR)モデルである Parakeet TDT 0.6B V2 のファインチューニング方法について探ります。合成音声データを用いて専門的なアプリケーション向けに優れた文字起こし結果を実現するため、AWS インフラストラクチャと以下の人気オープンソースフレームワークを組み合わせたエンドツーエンドのワークフローを順を追って解説します:
- Amazon Elastic Compute Cloud (Amazon EC2) の GPU インスタンス(NVIDIA A100 GPU を搭載した p4d.24xlarge)を用いた、大規模な分散トレーニング
- ASR モデルのファインチューニングと最適化のための NVIDIA NeMo フレームワーク
- 複数のノードにわたるメモリ効率の高い分散トレーニングを実現する DeepSpeed
- 包括的な実験追跡のための MLflow と TensorBoard
- スケーラブルなモデル推論サービスを提供するための Amazon Elastic Kubernetes Services (Amazon EKS)
- 高性能なモデル重み(ウェイト)の保存のための Amazon FSx for Lustre
- 本番環境レベルの API 管理と観測性を実現する AI Gateway と Langfuse
- トレーニングから推論まで一貫性があり再現可能な環境を構築するための Docker
このアーキテクチャは、AWS のマネージドサービスと最高水準のオープンソース AI ツールを組み合わせて、初期のファインチューニングから弾力的で観測可能なデプロイに至るまで、測定可能なビジネス価値をもたらす本番対応型のドメイン適応型 ASR システムを構築する方法を示しています。
ソリューション概要:ヘイディ AI ケアパートナー
Heidi は、ケアの周回業務(ドキュメント作成、臨床エビデンスの整理、患者とのコミュニケーション対応など)を代行する AI ケアパートナーです。これにより、医療従事者は患者に集中できます。同プラットフォームは週に 240 万件以上の診療相談を、190 カ国・110 の言語でサポートしています。救急外来、一般診療科、専門クリニックなどで活用されており、ヘイディは臨床記録の精度と完全性を維持しつつ、医療従事者が毎日数時間を取り戻す手助けをしています。
標準搭載の音声認識(ASR: Automatic Speech Recognition)モデルは、医学用語、地域特有のアクセント、および臨床用語と会話語との間のコードスイッチング(言語の切り替え)に対して苦戦します。これらの制限により、誤記や文脈の欠落が生じ、認知負荷が増大します。その結果、本来時間を節約すべき医療従事者が、誤りの修正に時間を割かざるを得なくなります。医療従事者にとって正確な記録は単なる利便性ではなく、臨床安全の確保、法的責任からの保護、そしてツールへの信頼を意味します。誤りを含むメモはこれら三つの要素すべてを損なうことになります。
これに対処するため、Heidi は AWS Generative AI Innovation Center (GenAIIC) と協力し、モデルを微調整して、現実世界の臨床環境特有の言語的・音響的・文脈的なニュアンスに適応させました。これにより、大規模な展開においても正確で信頼性の高いパフォーマンスが可能になりました。テキストから音声への変換(TTS)モデルにおける最近の進展を活用し、Heidi は大規模言語モデル(LLM)を用いてシミュレーションされた会話からの現実世界のノイズを織り交ぜた高品質な多言語合成音声を生成しました。このアプローチにより、チームは患者のプライバシーを損なうことなく、幅広いアクセントや医療文脈にわたってトレーニングをスケールさせることができました。合成データを使用することで、オープンデータセットで不足している低リソース言語や稀な医療用語に焦点を当てた標的型拡張も可能になりました。
微調整は、深層学習ワークロード向けに最適化された Amazon EC2 GPU インスタンスを使用して実施されました。事前設定済みの AWS Deep Learning AMIs を使用することで、チームはパフォーマンスとセキュリティを維持しながら、実験とモデルの反復を加速させることができました。スケーラブルなコンピューティング能力と密接に統合された AWS サービスの組み合わせにより、厳格な規制環境内でも迅速かつ費用対効果の高い開発が可能になりました。
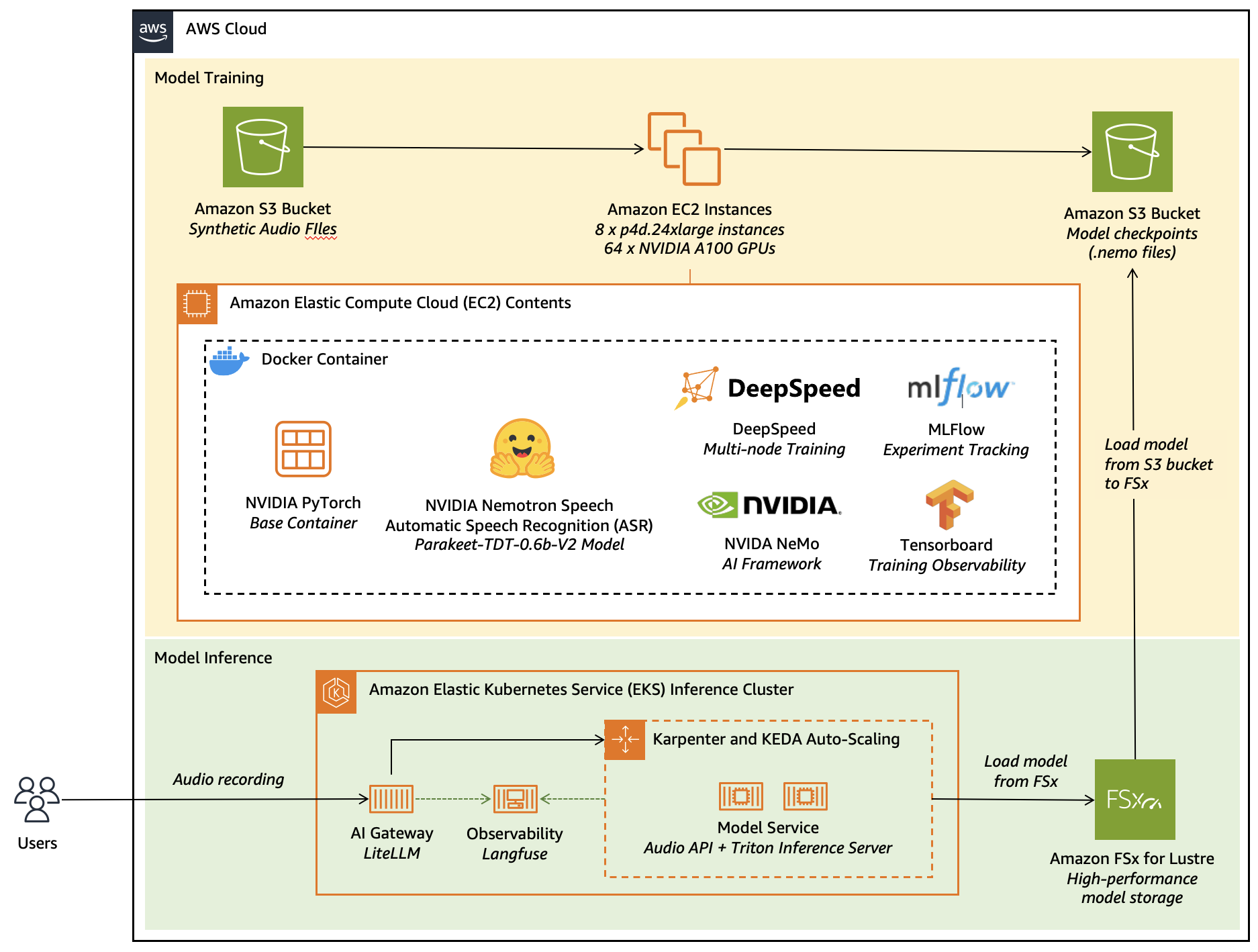
*図 1:この図は、AWS サービス上で NVIDIA Parakeet TDT 0.6B V2 モデルをファインチューニングしてデプロイする様子を示したダイアグラムです。*
ドメイン固有データの合成
NVIDIA Parakeet TDT 0.6B V2 の医療専門用語における性能を向上させるため、大規模言語モデル(LLM)、ニューラルテキスト音声合成(TTS)合成、およびノイズ拡張を組み合わせたターゲット型の合成データ生成パイプラインを開発しました。このプロセスはまず、過去の評価ランで再現率が低かった薬品名、解剖学的実体、手順に関するフレーズなどからなる医療用語の辞書を作成することから始まります。これらの用語は、ドメイン適応型 LLM に対する条件入力として使用され、現実世界の臨床での口述筆記に似た意味的に整合性があり文脈的に多様な転写テキストを生成します。プロンプトは、医療音声で頻繁に観察される多様な言語構造や自然なコードスイッチングパターンを引き出すように設計されています。例えば、略語、ラテン語由来の単語、および口語的な表現を混在させるようなものです。
生成されたトランスクリプトは後で、特定のアクセントと自然なプロソディ(韻律)に設定されたニューラル TTS システムを使用して音声に変換されました。データの多様性とリアリズムを高めるため、多段階のオーディオ拡張パイプラインを採用しました。これには、オープンな音響データセットからサンプリングした背景会話、機械のアラーム、病院や診療所の環境音などの、病院や診療所の環境ノイズ録音をオーバーレイする作業が含まれます。また、現実世界のマイクや環境条件をシミュレートするために、ランダムなゲイン調整、リバーブフィルター、加算ガウスノイズといった制御された摂動も適用しました。各合成発話には、明瞭さと真正性のバランスを取るため、10〜25 dB の間でランダムに割り当てられた信号対雑音比(SNR)が設定されました。
NVIDIA Parakeet TDT 0.6B V2 モデルの紹介
NVIDIA Parakeet TDT 0.6B V2 は、高品質な英語トランスクリプションのために設計された、6 億パラメータの自動音声認識(ASR)モデルです。NVIDIA NeMo の FastConformer アーキテクチャを基盤とし、トークンと持続時間トランシーダ(TDT: Token-and-Duration Transducer)デコーダーを搭載しています。このモデルは、優れた音声認識機能を提供するだけでなく、以下のような貴重な特徴も備えています:
- 自動句読点付与と大文字化
- 単語レベルのタイムスタンプ予測
- 発話される数字や歌詞に対する堅牢な性能
- 1 回のパスで最大 24 分までの音声セグメントをサポート
このオープンモデルは、Hugging Face Open-ASR リーダーボード の各種ベンチマークデータセット全体で平均単語誤り率 (WER: Word Error Rate) が 6.05% という驚異的な結果を達成しており、汎用的な英語音声認識におけるその有効性を示しています。
なぜモデルのファインチューニングを行うのか?
優れた初期性能を備えているにもかかわらず、NVIDIA Parakeet TDT 0.6B V2 モデルを特定のドメイン向けにファインチューニングすることには、いくつかの compelling な利点があります:
- ドメイン固有の用語 – 一般的なトレーニングデータセットでは稀な場合がある専門用語や業界用語の認識精度向上
- アクセントと方言への適応 – 特定地域の発話パターンや言語的変容に対する性能の改善
- ノイズ耐性 – ドメイン固有の背景雑音や音響環境へのより優れた対応
- コスト効率 – 独自の最適化モデルにより、高価なサードパーティ製 API 呼び出しの必要性を低減
- カスタマイズされた最適化 – 特定のアプリケーション要件に合わせて、精度と推論速度のバランスを調整
モデルアーキテクチャ
NVIDIA Parakeet TDT 0.6B V2 モデルは、トークンと持続時間トランスデューサ(Token-and-Duration Transducer: TDT)アーキテクチャを採用しており、以下の主要コンポーネントで構成されています:
エンコーダーアーキテクチャ
エンコーダーは、複数の処理段階を通じて入力音声特徴を文脈表現へ変換します:
- Conformer Encoder(Conformer エンコーダー): 隠れ次元数 1024 の 24 レイヤーからなる Conformer レイヤー
- 畳み込みサブサンプリング(Convolutional Subsampling): 4 つの畳み込み層による初期特徴抽出
- 段階的なダウンサンプリングのためのストライド 2 の 3×3 コンボリューション
- 畳み込みスタック全体を通じてチャネル次元を 256 に維持
- 位置エンコーディング(Positional Encoding): ドロップアウト率 0.1 を伴う相対位置エンコーディング
Conformer レイヤー
各 Conformer レイヤーは以下の要素を含みます:
- フィードフォワードモジュール(Feed Forward Modules): 内部次元数 4096 の 2 つの FFN ブロック
- 畳み込みモジュール(Convolutional Module): 因果パディング、バッチ正規化、Swish 活性化関数を備えた 9×1 深層畳み込み
- マルチヘッドアテンション(Multi-Head Attention): 相対位置エンコーディングを伴う自己注意機構
- 正規化(Normalization): コンポーネント間のレイヤー正規化
- ドロップアウト(Dropout): 正則化のためのドロップアウト率 0.1
デコーダーおよびジョイントネットワーク
デコーダーとジョイントネットワークは、エンコーダーの出力と予測トークンを組み合わせて最終的な文字起こしを生成します:
RNN デコーダー(RNN Decoder):
- エンベディング層(Embedding layer): 語彙サイズ 1025、埋め込み次元数 640
- 2 レイヤー LSTM: 隠れユニット数 640、ドロップアウト率 0.2
ジョイントネットワーク(Joint Network):
- エンコーダーとデコーダーのための線形変換
- 0.2 のドロップアウトを伴う ReLU アクティベーション
- 1030 次元への出力投影
オーディオ処理と損失関数
モデルは、転写精度の最適化を支援するために、専用の前処理とトレーニング目的を採用しています:
- Mel スペクトログラム前処理:生オーディオをメルスケールスペクトログラムに変換します
- スペクトル拡張:堅牢性を高めるための時間および周波数マスキング
- TDT 損失 (Token-and-Duration Transducer loss):トークンとその持続時間の同時予測のための Token-and-Duration Transducer 損失
- Word Error Rate (WER): 転写品質の主要な評価指標
微調整用の環境設定
当社の微調整アプローチは、Amazon EC2 インスタンス上での分散トレーニングを活用しており、Amazon SageMaker AI への展開への道筋も用意されています。一貫性と再現性を促進するため、この環境は Docker コンテナにカプセル化されています。
Docker ベースの環境設定
Docker コンテナには、以下のコードスニペットに示すように微調整に必要な依存関係が含まれています。完全なファイルは、関連する GitHub リポジトリ こちら でアクセスできます:
FROM nvcr.io/nvidia/pytorch:24.01-py3
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=UTC
作業ディレクトリを設定する
WORKDIR /app
システム依存関係のインストール
RUN apt-get update && apt-get install -y \
libsox-fmt-mp3 \
gnupg \
&& rm -rf /var/lib/apt/lists/*
Cython のインストール(NeMo に必要)
RUN pip install Cython
pytorch-lightning リポジトリの指定されたブランチをクローンしてインストール
RUN git clone -b bug_fix https://github.com/athitten/pytorch-lightning.git && \
cd pytorch-lightning && \
PACKAGE_NAME=pytorch pip install -e .
最適化用の TransformerEngine のインストール
RUN git clone https://github.com/NVIDIA/TransformerEngine.git && \
cd TransformerEngine && \
git fetch origin 8c9abbb80dba196f086b8b602a7cf1bce0040a6a && \
git checkout FETCH_HEAD && \
git submodule init && git submodule update &&
このコンテナは以下の機能を提供します:
- NVIDIA 最適化版の PyTorch コンテナをベースイメージとして採用
- ASR モデル処理用の NeMo フレームワーク(NeMo)
- 効率的な分散学習のための DeepSpeed
- 実験追跡用の MLflow および TensorBoard
リソース要件
効率的なファインチューニングのため、以下を推奨します:
- EC2 インスタンスタイプ:p4d.24xlarge(1 インスタンスあたり 8 基の NVIDIA A100 GPU) – A100 GPU は、GPU あたり 80GB の高帯域幅メモリを搭載しており、Parakeet TDT 0.6B V2 モデルの 6 億パラメータを大きなバッチサイズで処理するために不可欠です。A100 のテンソルコアは混合精度トレーニング(mixed-precision training)を加速し、前世代の GPU に比べてトレーニング時間を短縮します。なお、より要求の高い要件に対応するため、P5 など、より新しくて高性能な EC2 インスタンスも利用可能です。
- クラスターサイズ:フルスケールのトレーニングには 8 ノード(GPU 合計 64 基) – 複数のノードにわたる分散トレーニング(distributed training)により、並列化を通じて大きなバッチサイズと高速な収束が可能となり、大規模なオーディオデータセットでの効率的なトレーニングがサポートされます。64 基の GPU を使用すれば、100 時間以上のオーディオを含む広範なデータセットを数日ではなく数時間でトレーニングでき、生産ラインのスケジュールに合わせて迅速な実験が行えます。
- ストレージ:モデルのチェックポイントとデータ用に、ノードあたり最低 500GB。この容量は、頻繁なチェックポイントの保存、トレーニング途中の状態の保持、および前処理済みオーディオ特徴のローカルキャッシュに対応できます。十分なストレージ容量を確保することで、トレーニング中に高価な GPU リソースがアイドル状態になることを防ぐ I/O ボトルネックを回避できます。
小規模なデータセットや予算制約がある場合は、トレーニングはノード数や g6e.2xlarge などの GPU インスタンス数を減らしてスケーリングダウンすることも可能です。
ファインチューニングのためのデータ準備
Parakeet TDT 0.6B V2 モデルを使用するには、NeMo の JSONL マニフェスト形式で音声データと対応する文字起こし(トランスクリプト)が必要です。これらのファイルの各行は、合成された音声ファイルと、その音声が合成された元のテキストを示しています。
{
"audio_filepath": "/path/to/audio.wav",
"duration": 5.2,
"text": "句読点と大文字を含む文字起こし。"
}
トレーニング用マニフェストの作成
当社のファインチューニング手法では、3 つの別々のマニフェストファイルを使用します:
- トレーニング用マニフェスト:モデル学習用のデータの大部分を含みます
- 検証用マニフェスト:トレーニング中のモデル性能を評価するために使用されます
- テスト用マニフェスト:ファインチューニング後のモデルの最終評価に使用されます
データセットには、パフォーマンス向上のために、対象ドメインに関連する多様な話者、アクセント、音響条件が含まれていることが理想的です。
ファインチューニング設定の詳細解説
当社のファインチューニング設定は包括的であり、Parakeet TDT 0.6B V2 モデル向けに慎重に調整されています:
モデル構成
この構成では、17 の Conformer ブロック(Conformer blocks)を持つ Parakeet TDT 0.6B V2 アーキテクチャを指定しています:
model:
sample_rate: 16000
normalize_text: true
symbols_to_keep: ["'"]
encoder:
_target_: nemo.collections.asr.modules.ConformerEncoder
feat_in: ${model.preprocessor.features}
n_layers: 17
d_model: 512
subsampling: dw_striding
subsampling_factor: 8
subsampling_conv_channels: 256
トークンと持続時間トランスデューサ (TDT) の設定
TDT アーキテクチャは、トークンの発話タイミングを予測するために特定の持続時間値で構成されています:
model:
model_defaults:
tdt_durations: [0, 1, 2, 3, 4]
num_tdt_durations: 5
loss:
loss_name: "tdt"
tdt_kwargs:
durations: \${model.max_duration}
sigma: 0.02
omega: 0.1
オーディオ前処理
オーディオ前処理は、最適な特徴抽出のために構成されています:
preprocessor:
_target_: nemo.collections.asr.modules.AudioToMelSpectrogramPreprocessor
sample_rate: \${model.sample_rate}
normalize: "per_feature"
window_size: 0.025
window_stride: 0.01
features: 128
n_fft: 512
dither: 0.00001
データ拡張
モデルの堅牢性を向上させるため、スペクトログラム拡張などの複数の拡張技法が適用されます:
train_ds:
augmentor:
speed:
prob: 0.4
min_speed_rate: 0.9
max_speed_rate: 1.1
spec_augment:
_target_: nemo.collections.asr.modules.SpectrogramAugmentation
freq_masks: 2
time_masks: 10
freq_width: 27
time_width: 0.05
ノイズ拡張やシフト摂動などの追加の拡張戦略も、設定ファイル内のコメント付きオプションとして利用可能です。
分散トレーニング戦略
トレーニングは、複数の GPU およびノードにわたる効率的な分散のために構成されています:
trainer:
devices: 8
num_nodes: 8
strategy:
_target_: "lightning.pytorch.strategies.DeepSpeedStrategy"
stage: 2
offload_optimizer: true
partition_activations: true
gradient_as_bucket_view: true
cpu_checkpointing: true
contiguous_gradients: true
overlap_comm: true
この DeepSpeed 設定は、GPU 間のメモリ使用量と通信を最適化し、最大限のトレーニング効率を実現します。
フィンチューニングプロセスの実装
私たちの実装では、専用の ASRTrainer クラスを用いたモジュラーアプローチを採用しています:
モデルの初期化と凍結解除
def get_base_model(self, trainer):
"""設定に基づいてトレーニング開始用のベースモデルを取得する。"""
pretrained_name = self.config.init_from_pretrained_model
# マルチ GPU 環境での効率的なダウンロード処理
num_ranks = trainer.num_devices * trainer.num_nodes
if num_ranks > 1 and is_global_rank_zero():
logging.info(f"メインプロセスで事前学習済みモデル '{pretrained_name}' をダウンロード中")
asr_model = ASRModel.from_pretrained(model_name=pretrained_name)
else:
# メインプロセスでのモデルダウンロード完了を待機
wait_time = 1 if is_global_rank_zero() else 60
logging.info(f"モデルのダウンロード完了まで {wait_time}秒待機")
time.sleep(wait_time)
asr_model = ASRModel.from_pretrained(model_name=pretrained_name)
asr_model.to(f"cuda:{int(os.environ.get('LOCAL_RANK', 0))}")
原文を表示
*This post is a collaboration between AWS, NVIDIA and Heidi. *
Automatic speech recognition (ASR), often called speech-to-text (STT) is becoming increasingly critical across industries like healthcare, customer service, and media production. While pre-trained models offer strong capabilities for general speech, fine-tuning for specific domains and use cases can enhance accuracy and performance.
In this post, we explore how to fine-tune a leaderboard-topping, NVIDIA Nemotron Speech Automatic Speech Recognition (ASR) model; Parakeet TDT 0.6B V2. Using synthetic speech data to achieve superior transcription results for specialised applications, we’ll walk through an end-to-end workflow that combines AWS infrastructure with the following popular open-source frameworks:
- Amazon Elastic Compute Cloud (Amazon EC2) GPU instances (p4d.24xlarge with NVIDIA A100 GPUs) for distributed training at scale
- NVIDIA NeMo framework for ASR model fine-tuning and optimization
- DeepSpeed for memory-efficient distributed training across multiple nodes
- MLflow and TensorBoard for comprehensive experiment tracking
- Amazon Elastic Kubernetes Services (Amazon EKS) for scalable model serving
- Amazon FSx for Lustre for high-performance model weight storage
- AI Gateway and Langfuse for production-grade API management and observability
- Docker for consistent, reproducible environments across training and inference
This architecture demonstrates how to use the managed services of AWS alongside best-in-class open-source AI tools to build production-ready, domain-adapted ASR systems that deliver measurable business value—from initial fine-tuning through to elastic, observable deployment.
Solution Overview: Heidi’s AI Care Partner
Heidi is an AI Care Partner that removes the work around care—handling documentation, clinical evidence, and patient communications so clinicians can stay focused on patients. The platform supports over 2.4 million consultations per week in 110 languages across 190 countries. Used across emergency departments, general practice, and specialist clinics, Heidi helps clinicians reclaim hours each day while maintaining the accuracy and integrity of the clinical record.
Out-of-the-box ASR models struggle with medical terminology, regional accents, and code-switching between clinical and conversational language. These limitations lead to transcription errors, lost context, and increased cognitive load which forces clinicians to spend time correcting what should have saved them time. For clinicians, accurate documentation isn’t just convenience. It’s clinical safety, liability protection, and trust in the tool. A note with errors undermines all three.
To address this, Heidi collaborated with AWS Generative AI Innovation Center (GenAIIC) to fine-tune and adapt the model to the unique linguistic, acoustic, and contextual nuances of real-world clinical environments—enabling accurate and reliable performance at scale. Using recent advancements in text-to-speech (TTS) models, Heidi generated high-quality, multilingual synthetic speech interleaved with real-world noises from conversations emulated with large language models (LLMs). This approach allowed the team to scale training across a wide range of accents, and medical contexts without compromising patient privacy. Using synthetic data also enabled targeted augmentation with focus on low-resource languages and rare medical terms that are underrepresented in open datasets.
Fine-tuning was conducted using Amazon EC2 GPU instances optimized for deep learning workloads. By usings pre-configured AWS Deep Learning AMIs, the team was able to accelerate experimentation and model iteration while maintaining control over performance and security. The combination of scalable compute and tightly integrated AWS services enabled fast, cost-effective development within a highly regulated environment.
*Figure 1: This figure shows the diagram for fine-tuning and deploying NVIDIA Parakeet TDT 0.6B V2 model on AWS services.*
Synthesizing domain-specific data
To help improve NVIDIA Parakeet TDT 0.6B V2‘s performance on medically specialized terminology, we developed a targeted synthetic data generation pipeline combining large language models (LLMs), neural text-to-speech (TTS) synthesis, and noise augmentation. The process began by compiling a lexicon of medical terms, primarily drug names, anatomical entities, and procedural phrases that exhibited low recall in prior evaluation runs. These terms were used as conditioning inputs for a domain-adapted LLM, which generated semantically coherent and contextually diverse transcripts resembling real-world clinical dictations. The prompts were designed to elicit varied linguistic structures and natural code-switching patterns that are frequently observed in medical speech. For example, intermixing abbreviations, Latin-origin words, and colloquial phrasing.
The generated transcripts were later transformed into speech using a neural TTS system, configured for specific accents and natural prosody. To increase data diversity and realism, we employed a multi-stage audio augmentation pipeline. This involved overlaying hospital and clinic ambient noise recordings such as background conversations, machine alarms, and hospital ambient noises sampled from open acoustic datasets. We also applied controlled perturbations, including random gain adjustments, reverberation filters, and additive Gaussian noise to simulate real-world microphone and environment conditions. Each synthetic utterance was assigned a randomized signal-to-noise ratio (SNR) between 10–25 dB to balance clarity and authenticity.
Introduction to NVIDIA Parakeet TDT 0.6B V2 model
The NVIDIA Parakeet TDT 0.6B V2 is a 600-million parameter automatic speech recognition (ASR) model designed for high-quality English transcription. Built on NVIDIA NeMo’s FastConformer architecture with a Token-and-Duration Transducer (TDT) decoder, this model helps provide exceptional speech recognition capabilities along with valuable features like:
- Automatic punctuation and capitalization
- Word-level timestamp predictions
- Robust performance on spoken numbers and song lyrics
- Support for audio segments up to 24 minutes in a single pass
The open model achieves an impressive 6.05% average Word Error Rate (WER) across various benchmark datasets on the Hugging Face Open-ASR Leaderboard, demonstrating its effectiveness for general English speech recognition.
Why fine-tune the model?
Despite its strong out-of-the-box performance, fine-tuning the NVIDIA Parakeet TDT 0.6B V2 model for specific domains offers several compelling advantages:
- Domain-specific terminology – Enhanced recognition of specialized vocabulary and jargon that can be rare in general training datasets
- Accent and dialect adaptation – Improved performance for specific regional speech patterns or linguistic variations
- Noise resilience – Better handling of domain-specific background noises and acoustic environments
- Cost efficiency – Reduced need for expensive third-party API calls with your own optimized model
- Customized optimization – Balance between accuracy and inference speed tailored to your specific application requirements
Model architecture
The NVIDIA Parakeet TDT 0.6B V2 model uses a Token-and-Duration Transducer (TDT) architecture with these key components:
Encoder architecture
The encoder transforms input audio features into contextual representations through multiple processing stages:
- Conformer Encoder: 24 conformer layers with 1024 hidden dimensions
- Convolutional Subsampling: Initial feature extraction with four convolutional layers
3×3 convolutions with stride 2 for progressive downsampling
- Channel dimension of 256 throughout the convolutional stack
- Positional Encoding: Relative positional encoding with dropout (0.1)
Conformer layers
Each conformer layer includes:
- Feed Forward Modules: Two FFN blocks with 4096 inner dimension
- Convolutional Module: 9×1 depthwise convolution with causal padding, batch normalization, and Swish activation
- Multi-Head Attention: Self-attention mechanism with relative positional encoding
- Normalization: Layer normalization between components
- Dropout: 0.1 dropout rate for regularization
Decoder & Joint Network
The decoder and joint network combine encoder outputs with predicted tokens to generate final transcriptions:
RNN Decoder:
- Embedding layer (1025 vocabulary size, 640 embedding dimension)
- 2-layer LSTM with 640 hidden units and 0.2 dropout
Joint Network:
- Linear transformations for encoder and decoder
- ReLU activation with 0.2 dropout
- Output projection to 1030 dimensions
Audio processing and loss function
The model employs specialized preprocessing and training objectives to help optimize transcription accuracy:
- Mel Spectrogram Preprocessing: Converts raw audio to mel-scale spectrograms
- Spectral Augmentation: Time and frequency masking to help enhance robustness
- TDT Loss: Token-and-Duration Transducer loss for simultaneous prediction of tokens and their durations
- Word Error Rate (WER): Primary evaluation metric for transcription quality
Setting up your environment for fine-tuning
Our fine-tuning approach leverages distributed training on Amazon EC2 instances, with a path to deployment on Amazon SageMaker AI. The environment is encapsulated in a Docker container to facilitate consistency and reproducibility.
Docker-based environment setup
The Docker container includes the necessary dependencies for fine-tuning as shown in the following code snippet. You can access the complete file in the associated GitHub repository here:
FROM nvcr.io/nvidia/pytorch:24.01-py3
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=UTC
# Set the working directory
WORKDIR /app
# Install system dependencies
RUN apt-get update && apt-get install -y \
libsox-fmt-mp3 \
gnupg \
&& rm -rf /var/lib/apt/lists/*
# Install Cython (needed for NeMo)
RUN pip install Cython
# Clone the specified branch of the pytorch-lightning repository and install it
RUN git clone -b bug_fix https://github.com/athitten/pytorch-lightning.git && \
cd pytorch-lightning && \
PACKAGE_NAME=pytorch pip install -e .
# Install TransformerEngine for optimization
RUN git clone https://github.com/NVIDIA/TransformerEngine.git && \
cd TransformerEngine && \
git fetch origin 8c9abbb80dba196f086b8b602a7cf1bce0040a6a && \
git checkout FETCH_HEAD && \
git submodule init && git submodule update && \
This container provides:
- NVIDIA’s optimized PyTorch container as the base
- NeMo framework for ASR model handling
- DeepSpeed for efficient distributed training
- MLflow and TensorBoard for experiment tracking
Resource requirements
For efficient fine-tuning, we recommend:
- EC2 instance type: p4d.24xlarge (8 NVIDIA A100 GPUs per instance) – The A100 GPUs provide 80GB of high-bandwidth memory per GPU, essential for handling the Parakeet TDT 0.6B V2 model’s 600 million parameters with large batch sizes. A100 tensor cores accelerate mixed-precision training, reducing training time compared to previous-generation GPUs. Note that there are newer, more powerful EC2 instances such as P5 that are also available to cater for more demanding requirements.
- Cluster size: 8 nodes (64 GPUs total) for full-scale training – Distributed training across multiple nodes enables larger batch sizes and faster convergence through parallelization, supporting efficient training on large-scale audio datasets. With 64 GPUs, you can train on extensive datasets (100+ hours of audio) in hours rather than days, enabling rapid experimentation for production timelines.
- Storage: At least 500 GB per node for model checkpoints and data. This capacity accommodates frequent checkpoint saving, intermediate training states, and local caching of preprocessed audio features. Adequate storage prevents I/O bottlenecks that could idle expensive GPU resources during training.
For smaller datasets or budget constraints, the training can scale down to fewer nodes or GPU instances like g6e.2xlarge.
Data preparation for fine-tuning
The Parakeet TDT 0.6B V2 model requires audio data and corresponding transcriptions in NeMo’s JSONL manifest format. Each line in these files points to the synthesized audio and the corresponding transcript that it was synthesized from.
{ "audio_filepath": "/path/to/audio.wav", "duration": 5.2,
"text": "The transcription with punctuation and capitalization."
}Creating training manifests
Our fine-tuning approach uses three separate manifest files:
- Training manifest: Contains the bulk of your data for model training
- Validation manifest: Used to evaluate model performance during training
- Test manifest: Used for final evaluation of the fine-tuned model
The dataset should ideally include diverse speakers, accents, and acoustic conditions relevant to your domain for improved performance.
Fine-Tuning configuration deep dive
Our fine-tuning configuration is comprehensive and carefully tailored for the Parakeet TDT 0.6B V2 model:
Model configuration
The configuration specifies the Parakeet TDT 0.6B V2 architecture with 17 conformer blocks:
model:
sample_rate: 16000
normalize_text: true
symbols_to_keep: ["'"]
encoder:
_target_: nemo.collections.asr.modules.ConformerEncoder
feat_in: \${model.preprocessor.features}
n_layers: 17
d_model: 512
subsampling: dw_striding
subsampling_factor: 8
subsampling_conv_channels: 256Token-and-Duration Transducer (TDT) settings
The TDT architecture is configured with specific duration values to predict token emission timing:
model:
model_defaults:
tdt_durations: [0, 1, 2, 3, 4]
num_tdt_durations: 5
loss:
loss_name: "tdt"
tdt_kwargs:
durations: \${model.max_duration}
sigma: 0.02
omega: 0.1Audio preprocessing
Audio preprocessing is configured for optimal feature extraction:
preprocessor:
_target_: nemo.collections.asr.modules.AudioToMelSpectrogramPreprocessor
sample_rate: \${model.sample_rate}
normalize: "per_feature"
window_size: 0.025
window_stride: 0.01
features: 128
n_fft: 512
dither: 0.00001Data augmentation
To help improve model robustness, multiple augmentation techniques such as Spectrogram augmentation are applied:
train_ds:
augmentor:
speed:
prob: 0.4
min_speed_rate: 0.9
max_speed_rate: 1.1
spec_augment:
_target_: nemo.collections.asr.modules.SpectrogramAugmentation
freq_masks: 2
time_masks: 10
freq_width: 27
time_width: 0.05Additional augmentation strategies like noise augmentation and shift perturbation are available as commented options in the configuration file.
Distributed training strategy
The training is configured for efficient distribution across multiple GPUs and nodes:
trainer:
devices: 8
num_nodes: 8
strategy:
_target_: "lightning.pytorch.strategies.DeepSpeedStrategy"
stage: 2
offload_optimizer: true
partition_activations: true
gradient_as_bucket_view: true
cpu_checkpointing: true
contiguous_gradients: true
overlap_comm: trueThis DeepSpeed configuration improves memory usage and communication between GPUs for maximum training efficiency.
Implementing the fine-tuning process
Our implementation uses a modular approach with a dedicated ASRTrainer class:
Model initialization and unfreezing
def get_base_model(self, trainer):
"""Get the base model to start training from based on config settings."""
pretrained_name = self.config.init_from_pretrained_model
Handle multi-GPU download efficiently
num_ranks = trainer.num_devices * trainer.num_nodes
if num_ranks > 1 and is_global_rank_zero():
logging.info(f"Downloading pretrained model '{pretrained_name}' on main process")
asr_model = ASRModel.from_pretrained(model_name=pretrained_name)
else:
Wait for model download to complete on main process
wait_time = 1 if is_global_rank_zero() else 60
logging.info(f"Waiting {wait_time}s for model download")
time.sleep(wait_time)
asr_model = ASRModel.from_pretrained(model_name=pretrained_name)
asr_model.to(f"cuda:{int(os.environ.get('LOCAL_RANK', 0))}")
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み