Amazon Bedrock が生成 AI を利用したフィッシング攻撃を検知する方法
Amazon Bedrock は、従来の文法やフォーマットに依存しない検出手法により、生成 AI を活用した高度なフィッシング攻撃の文脈と行動パターンを分析する新たなセキュリティ層を提供します。
キーポイント
AI 化されたフィッシングの進化
現代の攻撃者は生成 AI と OSINT(公開情報収集)を活用し、文法が完璧で対象者に合わせた個人情報を盛り込んだ高度なメールを大量に作成するため、従来のフィルタリングでは検出不能となっている。
Amazon Bedrock の新たな検出手法
Bedrock は既存のセキュリティインフラに追加される層として、文書の表面的な特徴ではなく、メールが送信された背景や行動パターンに基づいてフィッシングを識別する。
コンテキスト理解と適応型攻撃への対抗
生成 AI を用いた攻撃は組織構造や人間関係を把握し、返信に応じてトーンや詳細をリアルタイムで調整するため、Bedrock はこうした文脈の整合性を検証する能力を持つ。
コンテキスト統合による分析精度の向上
Amazon Bedrock Knowledge Bases を活用し、メールの内容に送信者の通信パターンや組織文脈、既知のフィッシング事例を組み合わせることで、孤立した評価ではなく包括的な分析を行います。
ガードレールによる安全な AI 運用
AI モデルが不審なコンテンツを詳細に調査する一方で、ガードレールが機密情報の漏洩を防ぎ、定義されたセキュリティ境界内で分析を実行します。
多要素リスクスコアリングと自動ルーティング
コンテンツ異常、行動の逸脱、文脈整合性の 3 つの指標を加重平均して 0-100 のリスクスコアを算出し、このスコアに基づいてメールの配信、隔離、またはブロックを自動的に決定します。
動的フィードバックループによる精度向上
セキュリティチームからのフィードバックを即座に反映し、動的プロンプトエンジニアリングと少ショット学習(few-shot learning)を通じてモデルの評価能力を継続的に改善します。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI の進展によってサイバー脅威の質が劇的に変化したことを示唆し、企業セキュリティ対策におけるパラダイムシフトを迫っています。従来のルールベースや文法チェックに依存した防御策ではもはや不十分であり、AI が生成するコンテンツの「意図」や「文脈」を理解できる次世代の分析ツールへの投資が不可欠であることを強調しています。
編集コメント
生成 AI を悪用した攻撃が日常化している現在、セキュリティ対策も「見た目」から「文脈と意図」の解析へとシフトする必要があるという重要な警鐘です。AWS の新機能紹介ですが、業界全体における防御戦略の見直しを促す内容となっています。
フィッシングを通じた社会的エンジニアリングは、サイバー攻撃を仕掛ける最も一般的な戦術の一つであり続けています。AI 生成のフィッシングメールメッセージは、メールシステムを管理するセキュリティチームにとって新たな課題となっており、その高度な洗練さによりリスクが大幅に高まっています。現代の社会的エンジニアは、生成 AI とオープンソースインテリジェンス(OSINT)を活用して、完璧な文法、適切なコンテキスト、そしてパーソナライズされた詳細を備えた数千通もの一意のメッセージを作成します。今日では、フィッシングメールの指標となるのは、完璧に書かれ、プロフェッショナルにフォーマットされたメッセージであるかもしれません。
フィッシングの進化
中規模企業の IT セキュリティエンジニアであるジョンのような人にとって、フィッシング検出のルールはかつて明確でした:誤字をフラグ付けし、一般的な挨拶文を検出し、送信者ドメインが一致しないものを隔離する。これらは、攻撃者が量産された大量のメールを送り込み、精度よりもボリュームに頼って被害者を狙っていたフィッシングの初期時代における特徴的な要素でした。セキュリティフィルタはまさにこれらの脅威のために構築されており、長年にわたり効果的でした。不十分な文法、一般的な挨拶、不一致のロゴが攻撃者を見破る指標となっていました。
ジョンが今日監視している脅威の状況は、かつてこれらのフィルタが検出するために設計されたものとは全く異なります。生成 AI はフィッシングの手口そのものを変えました。攻撃文は現在、文法的に正しく、文脈的に正確であり、ターゲットに合わせて個別化されています。これらのメッセージは従来のフィルタをトリガーしません。なぜなら、それらのフィルタはこれらを検出するために設計されていないからです。
脅威はもはや外見ではなく、何を「知っているか」によって識別されます。現代の AI システムは OSINT(オープンソース情報収集)オペレーションを実行し、プロフェッショナルネットワーク、企業ウェブサイト、および公的に利用可能なデジタルフットプリントからデータを抽出して、組織の階層構造や人間関係をマッピングします。この知見を用いて、ソーシャルエンジニアは大量のデータセットをスケーラブルに処理し、組織に合わせて文脈的に正確な個別化メッセージを生成できます。これらの通信は、あなたの応答に基づいてリアルタイムで適応し、トーンを変えたり詳細を調整したりして、会話の一貫性を保つこともあります。
Amazon Bedrock は、主要な AI 企業から提供される高性能なファウンデーションモデル(FMs)を統一された API を通じて利用可能にする完全管理型サービスであり、セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築するために必要な機能も提供します。Amazon Bedrock は、従来の表面レベルのフィルタリングを超えて、既存のセキュリティインフラストラクチャに追加的な分析層を加えます。これは文法の質やフォーマットではなく、行動パターンに基づいて文脈を理解し、フィッシング試行を検出するものです。これを具体的に理解するために、Amazon Bedrock がメールが受信トレイに届いた瞬間からどのように分析を行うのかを段階的に解説しましょう。
Amazon Bedrock は膨大な量のデータで事前学習された大規模な汎用 AI モデルを利用しています。ファウンデーションモデルは、メールコンテンツ内の行動パターンを分析し、文脈的な関係を理解し、メッセージがフィッシング試行である可能性を示す異常を検出できます。実際には、これらの機能は多段階の分析パイプラインとして構成されます。各メールは、ユーザーの受信トレイに到達する前に、認証、行動分析、リスクスコアリングの各工程を通過します。
Amazon Bedrock は、AI を駆使したフィッシング対策を強化するために、2 つの統合機能を備えています。事前学習済みファウンデーションモデルは、ルールベースシステムでは検出できない微妙な操作、文脈的な異常、なりすましパターンを検知できる高度な自然言語理解を提供します。もう一つの機能である Amazon Bedrock Guardrails は、カスタム検出ロジックを必要とせず、ファウンデーションモデルの対話を組織の責任ある AI ポリシーやアプリケーション要件に適合させるための構成可能な保護措置を提供します。これら 2 つの機能を組み合わせることで、多段階のメール分析パイプラインに統合することが可能です。
Amazon Bedrock を活用したインテリジェントフィッシング対策ワークフロー
このワークフローソリューションでは、各メッセージはまず標準的な認証チェック(Sender Policy Framework (SPF)、DomainKeys Identified Mail (DKIM)、Domain-based Message Authentication, Reporting and Conformance (DMARC))を受けます。これらのプロトコルにより、送信サーバーがドメインに代わって送信する権限を持っていること、およびメッセージが転送中に改ざんされていないことが確認されます。Amazon Bedrock のファウンデーションモデルによって駆動されるフィッシング検出ワークフローは、メッセージを3 つの主要な要因に対して分析します:語彙の選択、コミュニケーションスタイルの逸脱、および要求の文脈上の適切性です。書き方の微妙な不一致や整合性の取れない要求を検出することは、従来のセキュリティ制御の上にさらに深い分析層を追加するものです。AI による分析には、責任ある運用と定義された範囲内での動作を確認するための慎重なガバナンスも必要です。Amazon Bedrock Guardrails は、入力プロンプトとモデルの出力の両方をフィルタリングします。これらは、意図せず機密データを漏洩する可能性のある応答を防ぎ、分析結果が設定したポリシーに準拠しているかを確認します。ガードレールはアプリケーションの要件を満たすために慎重な設定と較正が必要である点にご注意ください。
Amazon Bedrock Guardrails の分析への実装
Amazon Bedrock Guardrails を使用すると、コンテンツフィルター、拒否トピック、単語フィルター、機密情報フィルターを通じて、基盤モデルがメールコンテンツを処理する方法について細粒度の制御が可能になります。例えば、セキュリティエンジニアのジョンは、メール分析中に発見された機密性の高い個人識別情報(PII)を自動的に赤塗りするよう Guardrails を構成でき、これにより基盤モデルが機密データを無意に漏洩させる可能性のある応答を生成することを防ぐことができます。
しかし、セキュリティ分析のための Guardrail 設定には慎重な調整が必要です。コンテンツフィルターは不適切な入力や出力から保護しますが、過度に制限的な設定では、評価が必要な疑わしいコンテンツの分析自体が妨げられる可能性があります。ソーシャルエンジニアがフィルターの回避を試みるためにメールメッセージに攻撃的な言語を含める場合でも、Guardrails はセキュリティシステムがそのコンテンツを分析できるようにする必要があります。同時に、Guardrails は他の文脈における不適切な入力や出力から引き続き保護しなければなりません。また、Guardrails はコンテキストの根拠チェックも提供し、モデルの応答が分析対象のメールコンテンツに事実上基づくように保ち、モデルの幻覚によって引き起こされる偽陽性を削減します。これにより、AI による分析は定義された範囲内で動作しつつも、複雑なパターンを検出することが可能になります。
本稿では、送信者の行動パターン、文脈の適切さ、および通信上の異常を評価する Amazon Bedrock 基盤モデルを活用し、AI 生成フィッシング攻撃がユーザーに到達する前に検出するための多段階メール分析パイプラインの実装方法について解説します。
実装フレームワーク
以下のフレームワークは、既存のメールセキュリティインフラストラクチャ内でこの仕組みを実践する方法を示しており、ジョンのような立場の人が受動的なフィルタリングから能動的な検知へと移行するための指針となります。標準的な認証チェック(SPF, DKIM, DMARC)によってメールが正規のメールサーバーから送信されたことが確認された後、フィッシング検出ワークフローはさらに一歩進み、行動分析を層状に追加します。システムは「サーバーが許可されているか」を確認する段階から、「メッセージが同僚の通常のコミュニケーション様式と一致しているか」を評価する段階へと移行します。
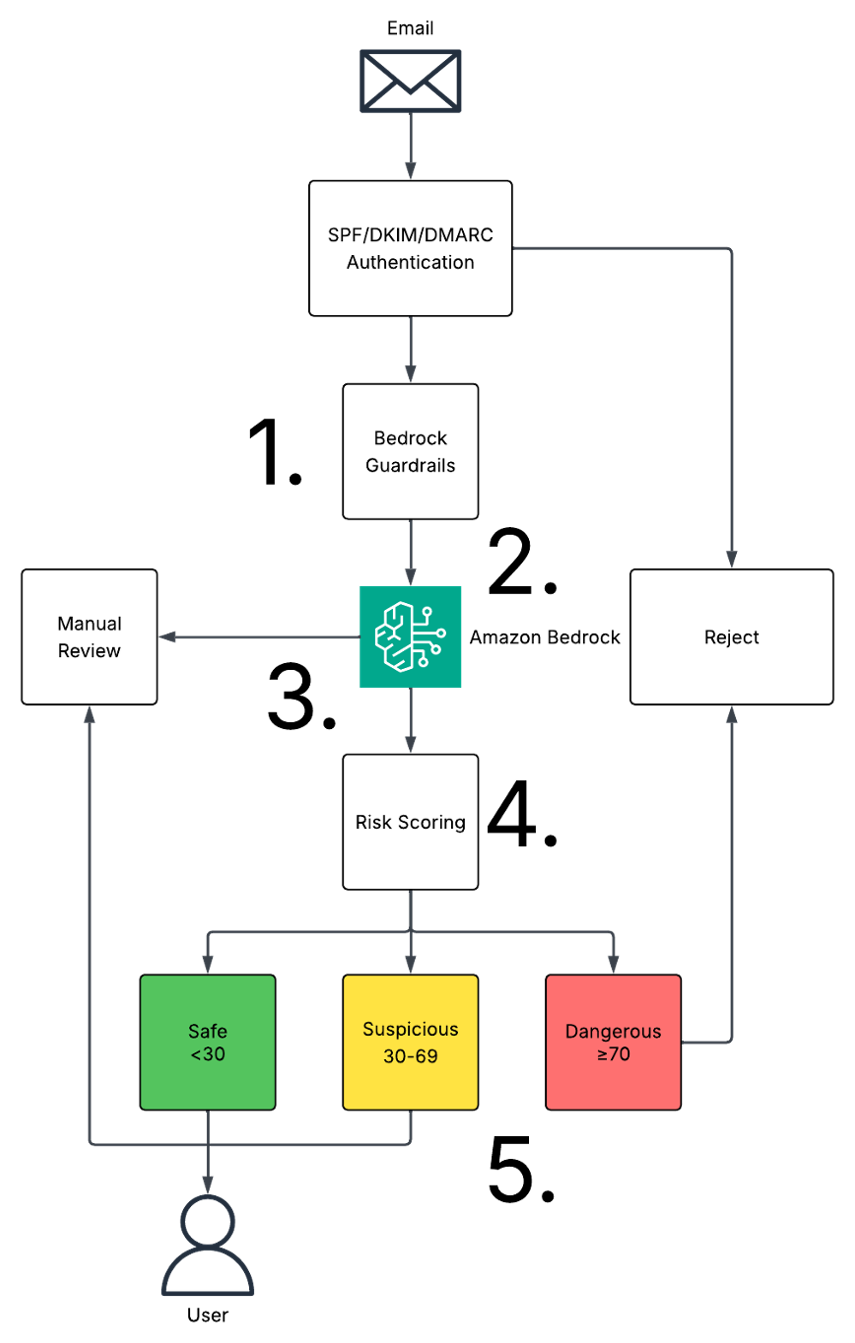
図 1 は、初期のガードレールスクリーニングから AI 分析、リスクスコアリング、そして最終的なルーティング決定に至るまでの 5 つのステップからなるメールセキュリティ分析ワークフローをマッピングしたものです。
実装の詳細に入る前に、各コンポーネントの役割を明確にしておきましょう。行動分析は、あなたにメールを送信する各人物のプロファイルである「送信者ベースライントラッカー」から始まります。このトラッカーは、従業員の通常の書き方を記録しており、Amazon Bedrock の分析パイプラインが比較するための基準点となります。
継続的な利用を通じて、フィッシング検出ワークフローは、従業員が使用する単語や、その文体がフォーマルかカジュアルかの傾向、通常求める内容、そして通常コミュニケーションを行う相手などを理解していきます。ジョンの環境を例に挙げましょう。普段は簡潔な一言でやり取りする同僚から、突然、緊急の振込を要求する正式なメールが届いたとします。分析パイプラインはこの変化を検知し、ジョンのチームがより詳しく確認するようフラグを立てます。
これにより、誤検知(false alarms)を減らし、実際には脅威ではないと判明したメールメッセージを仕分けするためにジョンのチームが費やす時間を節約することができます。
メールがフィッシング検出ワークフローに入力された際に、これらのコンポーネントがどのように連携して動作するかの高レベルな概要は以下の通りです:
ステップ 1: 入力ガードレールと前処理
INITIALIZE EmailSecurityAnalyzer:
- Amazon Bedrock クライアントを設定(Claude Sonnet 4.5 モデル)
- PII 保護およびコンテンツフィルタリングのために Amazon Bedrock Guardrails を構成
- フィッシング事例のナレッジベースを初期化
- 送信者ベースライントラッカーを初期化
- リスク閾値を設定(安全 = 70)
FUNCTION analyze_email(email):
// Step 1: Pre-process with guardrails
processed_email = apply_input_guardrails(email)
IF content_blocked:
RETURN manual_review_required
The phishing detection workflow first runs incoming email messages through Amazon Bedrock Guardrails, which screen for sensitive content and flag anything that should go to manual review before the analysis begins.
Step 2: Prompt construction with context
// Step 2: Build analysis prompt
prompt = construct_prompt(
email_content,
sender_baseline_patterns,
organizational_context,
known_phishing_examples
)
After an email clears that check, the workflow constructs an analysis prompt by combining the email's content with the sender's baseline communication patterns, organizational context, and known phishing examples by using Amazon Bedrock Knowledge Bases. That way, the model is evaluating the message against a full picture, not in a vacuum.
Step 3: AI-powered analysis with guardrails
// Step 3: Invoke AI model with guardrails
analysis = bedrock_invoke_with_guardrails(prompt)
IF guardrail_intervened:
RETURN blocked_with_reasons
基盤モデルは構築されたプロンプトを使用してメールを処理し、ガードレールは分析を定義されたセキュリティ境界内に保ちます。基盤モデルは不審なコンテンツを徹底的に調査できますが、その過程で機密情報を露出する出力を生成しないようガードレールが制御します。
ステップ 4: マルチファクターリスクスコアリング
// ステップ 4: リスクスコアの計算
risk_score = weighted_average(
content_anomaly_score,
behavioral_deviation_score,
context_alignment_score
)
この分析から、Amazon Bedrock パイプラインは3 つのスコアを生成します。1 つ目はコンテンツ異常に関するスコア、2 つ目は行動逸脱に関するスコア、3 つ目は文脈整合性に関するスコアです。パイプラインはこれらを統合して 0~100 の単一のリスクスコアを作成し、それに基づいてメールのルーティング先を決定します。
ステップ 5: 分類と自動ルーティング
// ステップ 5: 分類とルーティング
risk_level = classify_risk(risk_score)
action = route_email(risk_level) // DELIVER, QUARANTINE, or BLOCK
RETURN analysis_result
FUNCTION route_email(risk_level):
IF risk_level == SAFE: deliver_to_inbox
IF risk_level == SUSPICIOUS: quarantine_for_review
IF risk_level == DANGEROUS: block_and_alert_security
安全なメッセージは通常通り従業員の受信トレイに届きます。不審なメールメッセージはセキュリティチームによるレビューのために隔離されます。危険なメッセージは即座にブロックされます。
フィードバックを通じた継続的な学習
FUNCTION process_feedback(email, is_phishing):
IF is_phishing:
add_to_phishing_knowledge_base(email)
ELSE:
update_sender_baseline(email)
add_to_legitimate_examples(email)
これらの手順は、メッセージがルーティングシステムを通過する際にミリ秒単位で実行されます。既存のインフラストラクチャは依然としてメッセージのルーティングと配信を担当します。分析はその横で行われる検査レイヤーとして機能し、メッセージがユーザーの受信トレイに到達する前に行動上のリスクを評価します。
継続的な利用を通じて、フィッシング検出ワークフローは、いくつかの補完的な技術によってこれらの判断の精度を高めていきます。動的プロンプトエンジニアリングとは、現実世界の結果に基づいて基盤モデルに送信される指示を反復的に洗練させる実践であり、セキュリティチームからのフィードバックを取り込んで分析用プロンプトに直接組み込み、モデルが潜在的な問題をどのように評価するかを徐々に微調整します。このフィードバックループはまた、検証済みの例の蓄積されたナレッジベースにも貢献し、確認されたフィッシング試行と正当なメッセージがカタログ化され、将来的なプロンプトにおける少数ショット学習(few-shot learning)のデモンストレーションとして利用されます。したがって、新しいメールが届いた際、モデルはゼロから作業するわけではありません。類似のパターンに一致する実際の以前に検証済みの例を参照し、より情報に基づいた判断を下します。
例:AI 生成フィッシングメールの分析
以下の AI 生成フィッシングメールメッセージは、現代におけるフィッシングの手口の高さを示しています。完璧な文法、正当なビジネスコンテキスト、そして実際の購入注文 (PO) フォーマットへの言及に注意してください。これらはいずれも従来のスパムフィルタでは検知されません。メールメッセージの後に続くのは、Amazon Bedrock が送信者ベースラインや既知のフィッシングパターンに対してメッセージを分析する様子を示す簡略化されたプロンプト構造です。このプロンプトは、表面レベルのフィルタリングを超えた行動分析をサポートするために、メールコンテンツと歴史的コンテキストを組み合わせています。最後に、ベンダーなりすまし試行を特定したサンプルリスク評価出力を示します。Amazon Bedrock パイプラインは、従来の認証チェックで見逃されたドメインの不整合に加え、初となる支払い変更要求といった行動上の異常を検知しました。
サンプルフィッシングメール
こんにちはサラさん、
先週火曜日の第 3 四半期決算に関するお電話の続きです。
当社の財務チームは、Example Banking Inc. への移行の一環として、銀行口座情報を更新いたしました。
PO-2024-089 の支払い情報をご更新いただけますでしょうか?11 月 15 日の期限までにお願いいたします。新しい詳細情報は添付ファイルをご覧ください。
よろしくお願いいたします、
マイケル・チェン | Example Inc.
プロンプト構造とリスク評価出力
=== メールコンテンツ ===
{email_content}
=== 送信者ベースライン ===
- ドメイン:example.com(検証済みベンダー)
- 履歴:月 2〜3 通、支払い変更を要求したことは一度もない
- トーン:プロフェッショナル、請求書/契約に関する議論
=== 既知のイベントパターン ===
- 類似ドメインを使用したベンダーなりすまし
- 有効な PO(Purchase Order)リスク評価を参照した支払い詳細変更要求
=== タスク ===
スコア (0-100): コンテンツ異常、行動逸脱、文脈整合性
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "=== 既知のイベントパターン ===\n- 類似ドメインを使用したベンダーなりすまし\n- 有効な PO(Purchase Order)リスク評価を参照した支払い詳細変更要求\n\n=== タスク ===\nスコア (0-100): コンテンツ異常、行動逸脱、文脈整合性"}
翻訳全文
継続的なフィードバックループ
これらの事例の背後にあるフィッシング検知システムは、データベース内で動的な送信者ベースラインを維持しており、各送信者の典型的な通信パターン、語彙、トーン、およびリクエストタイプを追跡しています。ジョンのセキュリティチームによって誤って検出された偽陽性はフィッシング検知パイプラインにフィードバックされ、送信者がどのようにコミュニケーションを行うかにおける正当な変容を考慮してベースラインが更新されます。確認されたフィッシングパターンはこれらのベースラインと共にカタログ化され、将来のプロンプトコンテキストに最新のインテリジェンスを追加します。その結果、すべての修正と確認された脅威が分析の精度を高めるというフィードバックループが形成されます。
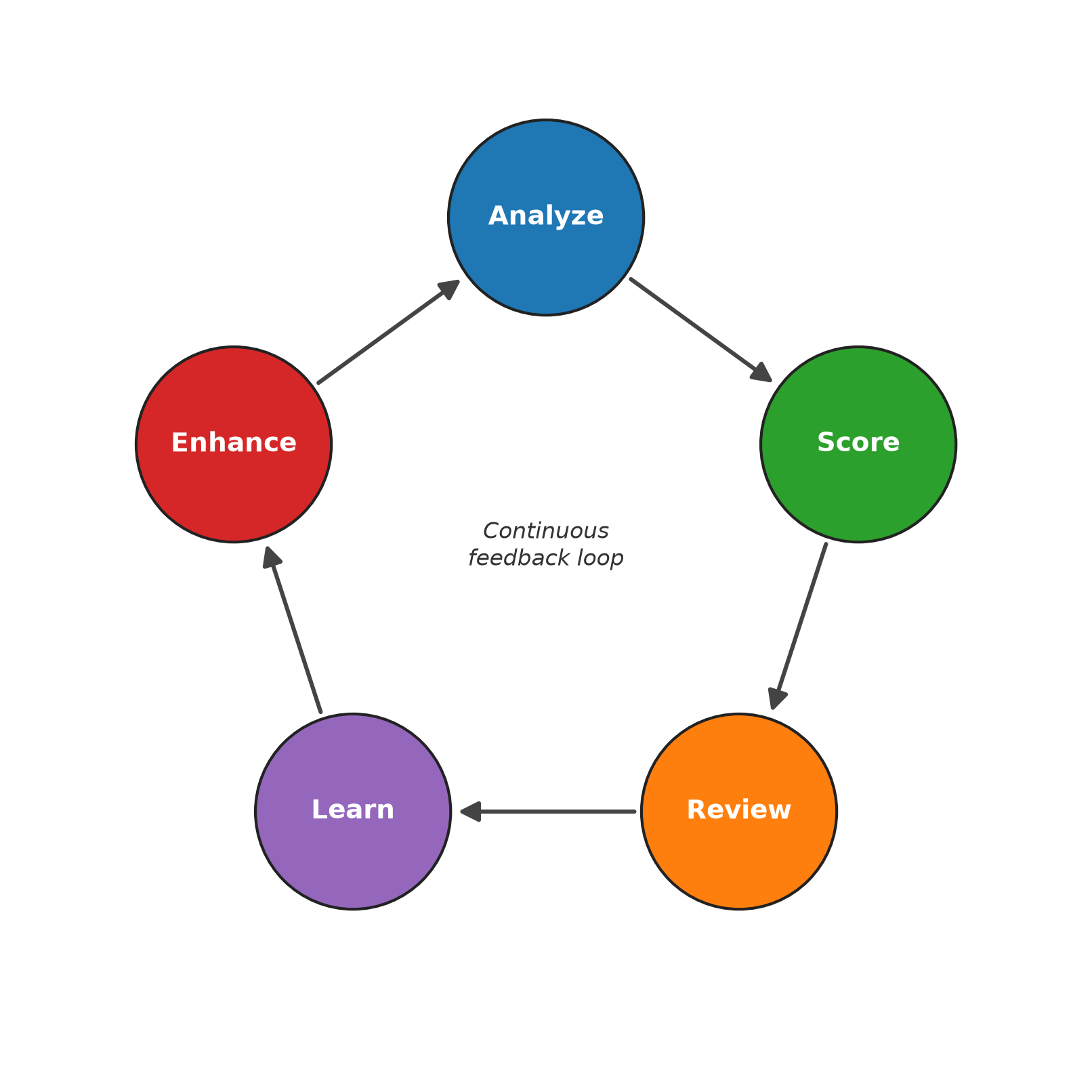
継続的なフィードバックパイプラインは、以下の 5 つの段階にわたって実行されます:
1. 分析 – ファウンデーションモデルは、蓄積されたフィッシング試行の知見と送信者の文脈から構築された動的プロンプトを用いて、受信したメールメッセージを評価します。
2. スコアリング – その分析に基づき、0~100 のリスクスコアが割り当てられ、不審なメッセージはセキュリティチームによるレビューのために隔離されます。
3. 確認 – フラグ付けされたメッセージは、確実なフィッシング試行か誤検知(false positive)のいずれかに分類されます。
4. 学習 – これらの分類結果がシステムにフィードバックされ、例ライブラリ、送信者行動のベースライン、および新興パターンのカタログが更新されます。
5. 強化 – 新しい例と確認されたフィッシング試行のパターンが分析プロンプトに取り込まれ、次のサイクルにおける検出精度が向上します。
初期のサイクルでは、システムが基礎的な理解を構築する過程で、より多くの手動レビューが必要となります。ジョンにとっては、チームが当初は分類作業により多くの時間を割くことになりますが、その投資はすぐに成果として現れます。例ライブラリと送信者プロファイルが成長するにつれ、モデルは正当な通信とフィッシング試行を区別する精度を段階的に高めていきます。ジョンは常にプロセスに関与し続けますが、彼の注力はノイズの選別から、本当に不審なメッセージに焦点を当てることへとシフトしていきます。
このループを1サイクル通過するごとに、検出対象となるフィッシング攻撃に同期して進化し、より強力で適応性の高い防御が構築されます。この継続的な改善こそが、本フィードバック駆動型検出モデルを静的なシグネチャベースの検出と区別する要因です。
結論
フィッシング検出はもはや、誤字や不自然な表現といった表面的な指標に頼ることはできません。本稿で提示したフレームワークは、Amazon Bedrock のファウンデーションモデルと行動分析、文脈的根拠を組み合わせることで、この変化に対応するものです。
原文を表示
Social engineering through phishing remains one of the most common tactics for launching cyberattacks. AI-generated phishing email messages now pose a new challenge for security teams managing email systems, significantly raising the risk because of their advanced sophistication. Modern social engineers use generative AI and open source intelligence (OSINT) to craft thousands of unique messages with perfect grammar, appropriate context, and personalized details. Today, an indicator of a phishing email message might be a perfectly written, professionally formatted message.
The evolution of phishing
For someone like John, an IT security engineer at a mid-sized firm, the rules of phishing detection were once straightforward: flag the typos, catch the generic salutations, and quarantine anything with a mismatched sender domain. These were the defining characteristics of an earlier era of phishing, when attacks sent millions of generic, error-riddled email messages at scale, relying on volume rather than precision to find victims. Security filters were built exactly for these threats, and for years, they were effective. Poor grammar, generic greetings, and mismatched logos were indicators that gave attackers away.
The threat landscape John monitors today looks nothing like the ones those filters were designed to catch. Generative AI changed how phishing works. Attacks are now grammatically correct, contextually accurate, and personalized to the target. These messages don’t trigger traditional filters because those filters weren’t designed to catch them.
The threat is no longer identifiable by what it looks like, but what it knows. Modern AI systems run OSINT operations that pull data from professional networks, corporate websites, and publicly available digital footprints to map out organizational hierarchies and relationships. With that intelligence, social engineers can process massive datasets at scale to generate contextually accurate messages personalized to your organization. These communications can even adapt in real time based on your responses, shifting tone or adjusting details to stay consistent with the conversation.
Amazon Bedrock is a fully managed service that makes high-performing foundation models (FMs) from leading AI companies available through a unified API, along with capabilities needed to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock adds an additional layer of analysis to your existing security infrastructure that goes beyond traditional surface-level filtering. It understands context and detects phishing attempts based on behavioral patterns, not grammar quality or formatting. To put that into practice, let’s break down how Amazon Bedrock analyzes an email from the moment it hits your inbox.
Amazon Bedrock uses large-scale general-purpose AI models pre-trained on vast amounts of data. Foundation models can analyze behavioral patterns in email content, understand contextual relationships, and identify anomalies that signal a message might be a phishing attempt. In practice, these capabilities can be structured as a multi-stage analysis pipeline. Each email passes through authentication, behavior analysis, and risk scoring before reaching your users’ inboxes.
Amazon Bedrock offers two integrated capabilities to power your AI-driven phishing defense. Pre-trained foundation models bring sophisticated natural language understanding that can detect nuanced manipulation, contextual anomalies, and impersonation patterns invisible to rule-based systems. The second capability, Amazon Bedrock Guardrails, provides configurable safeguards that help align foundation model interactions with your organization’s responsible AI policies and application requirements, without requiring custom detection logic. Together, these capabilities can be integrated into a multi-stage email analysis pipeline.
Amazon Bedrock workflow for intelligent phishing defense
In the workflow solution, each message first undergoes standard authentication checks (Sender Policy Framework (SPF), DomainKeys Identified Mail (DKIM), Domain-based Message Authentication, Reporting and Conformance (DMARC)). These protocols confirm that the sending server is authorized to send on behalf of the domain and that the message hasn’t been tampered with in transit. The phishing detection workflow, powered by the Amazon Bedrock foundation models, analyzes the message against three key factors: word choice, communication style deviations, and contextual appropriateness of requests. Detecting these subtle inconsistencies in writing style and misaligned requests adds a deeper layer of analysis on top of traditional security controls. AI analysis also requires careful governance to confirm it operates responsibly and within your defined boundaries. Amazon Bedrock Guardrails help filter both input prompts and model outputs. They prevent responses that could inadvertently leak confidential data, and they check that analysis results adhere to the policies you set. Keep in mind that guardrails need careful configuration and calibration to meet your application requirements.
Implementing Amazon Bedrock Guardrails for analysis
Amazon Bedrock Guardrails give you granular control over how foundation models process email content through content filters, denied topics, word filters, and sensitive information filters. For example, John the security engineer can configure guardrails to automatically redact sensitive personally identifiable information (PII) discovered during email analysis, helping to prevent the foundation model from generating responses that could inadvertently leak confidential data.
However, guardrail configurations for security analysis require careful calibration. While content filters protect against inappropriate inputs and outputs, overly restrictive settings can prevent the model from analyzing suspicious content that legitimately needs to be evaluated. If a social engineer includes offensive language in an email message to bypass filters, your guardrails must allow the security system to analyze that content. At the same time, the guardrails must still protect against inappropriate inputs and outputs in other contexts. Guardrails also provide contextual grounding checks that keep model responses factually anchored to the email content being analyzed, reducing false positives caused by model hallucination. This allows the AI-powered analysis to operate within defined boundaries while still detecting intricate patterns.
In this post, you will learn how to implement a multi-stage email analysis pipeline using Amazon Bedrock foundation models that evaluate sender behavior patterns, contextual appropriateness, and communication anomalies to identify AI-generated phishing attempts before they reach your users.
Implementation framework
The following framework shows how to put this into practice within your existing email security infrastructure, so that someone in John’s position can move from reactive filtering to proactive detection. After your standard authentication checks (SPF, DKIM, DMARC) confirm an email comes from a legitimate mail server, the phishing detection workflow goes a step further by layering in behavioral analysis. Your system moves from checking whether a server is authorized to evaluating whether a message matches how your coworker normally communicates.
Figure 1 maps the five-step email security analysis workflow, from initial guardrail screening through AI analysis, risk scoring, and final routing decisions.
Before diving into the implementation, let’s clarify what each component does. Behavioral analysis starts with a sender baseline tracker, which is a profile of each person who sends email to you. The sender baseline tracker logs how your employees normally write, so the Amazon Bedrock analysis pipeline has a reference point to compare against.
Over continued use, the phishing detection workflow will understand the words your employees use, how formal or casual they are, what they usually ask for, and who they normally communicate with. Consider John’s environment: A coworker who usually sends quick one-liners suddenly writes a formal email requesting an urgent wire transfer. The analysis pipeline catches that shift and flags it for John’s team to take a closer look.
This can help reduce false alarms and save time that John’s team might otherwise spend sorting through flagged email messages that turn out not to be real threats.
Here’s a high-level outline on how these components work together when an email enters your phishing detection workflow:
Step 1: Input guardrails and pre-processing
INITIALIZE EmailSecurityAnalyzer:
- Set up Amazon Bedrock client (Claude Sonnet 4.5 model)
- Configure Amazon Bedrock Guardrails for PII protection and content filtering
- Initialize knowledge base for phishing examples
- Initialize sender baseline tracker
- Set risk thresholds (safe = 70)
FUNCTION analyze_email(email):
// Step 1: Pre-process with guardrails
processed_email = apply_input_guardrails(email)
IF content_blocked:
RETURN manual_review_requiredThe phishing detection workflow first runs incoming email messages through Amazon Bedrock Guardrails, which screen for sensitive content and flag anything that should go to manual review before the analysis begins.
Step 2: Prompt construction with context
// Step 2: Build analysis prompt
prompt = construct_prompt(
email_content,
sender_baseline_patterns,
organizational_context,
known_phishing_examples
)After an email clears that check, the workflow constructs an analysis prompt by combining the email’s content with the sender’s baseline communication patterns, organizational context, and known phishing examples by using Amazon Bedrock Knowledge Bases. That way, the model is evaluating the message against a full picture, not in a vacuum.
Step 3: AI-powered analysis with guardrails
// Step 3: Invoke AI model with guardrails
analysis = bedrock_invoke_with_guardrails(prompt)
IF guardrail_intervened:
RETURN blocked_with_reasonsThe foundation model processes the email using the constructed prompt while guardrails keep the analysis within your defined security boundaries. The foundation model can examine suspicious content thoroughly while the guardrails keep it from generating outputs that expose sensitive information in the process.
Step 4: Multi-factor risk scoring
// Step 4: Calculate risk scores
risk_score = weighted_average(
content_anomaly_score,
behavioral_deviation_score,
context_alignment_score
)From that analysis, the Amazon Bedrock pipeline generates three scores: one for content anomalies, one for behavioral deviations, and one for contextual alignment. The pipeline combines them into a single risk score from 0–100, which determines where the email is routed.
Step 5: Classification and automated routing
// Step 5: Classify and route
risk_level = classify_risk(risk_score)
action = route_email(risk_level) // DELIVER, QUARANTINE, or BLOCK
RETURN analysis_result
FUNCTION route_email(risk_level):
IF risk_level == SAFE: deliver_to_inbox
IF risk_level == SUSPICIOUS: quarantine_for_review
IF risk_level == DANGEROUS: block_and_alert_securitySafe messages land in your employees’ inboxes as usual. Suspicious email messages get quarantined for your security team to review. Dangerous messages are blocked outright.
Continuous learning through feedback
FUNCTION process_feedback(email, is_phishing):
IF is_phishing:
add_to_phishing_knowledge_base(email)
ELSE:
update_sender_baseline(email)
add_to_legitimate_examples(email)These steps happen in milliseconds as messages move through your routing system. Your existing infrastructure still handles message routing and delivery. The analysis runs alongside it as an inspection layer that evaluates behavioral risk before messages reach your users’ inboxes.
Over continued use, the phishing detection workflow improves its accuracy in making these calls through a few complementary techniques. Dynamic prompt engineering, the practice of iteratively refining the instructions sent to the foundation model based on real-world results, takes feedback from the security team and incorporates it directly into your analysis prompts, gradually fine-tuning how the model evaluates potential issues. That feedback loop also feeds into a growing knowledge base of validated examples, where confirmed phishing attempts and legitimate messages are cataloged and later used as few-shot learning demonstrations in future prompts. So, when a new email comes in, the model isn’t working from scratch. It references your real, previously verified examples that match similar patterns to make a more informed judgment.
Example: AI-generated phishing email analysis
The following AI-generated phishing email message demonstrates modern phishing sophistication. Notice the perfect grammar, legitimate business context, and reference to a real purchase order (PO) format. None of these would trigger traditional spam filters. Following the email message is a simplified prompt structure showing how Amazon Bedrock analyzes messages against sender baselines and known phishing patterns. The prompt combines email content with historical context to support behavioral analysis beyond surface-level filtering. Last is a sample risk assessment output identifying a vendor impersonation attempt. The Amazon Bedrock pipeline flagged behavioral anomalies, including a first-ever payment change request, along with domain inconsistencies that traditional authentication checks missed.
Sample phishing email
Hi Sarah,
Following up on our last call Tuesday about the Q3 reconciliation.
Our finance team has updated our banking details as part of our transition to Example Banking Inc.
Could you update the payment info for PO-2024-089? Before the November 15th deadline? New details attached.
Best,
Michael Chen | Example Inc.Prompt structure and risk assessment output
=== EMAIL CONTENT ===
{email_content}
=== SENDER BASELINE ===
- Domain: example.com (verified vendor)
- History: 2-3 emails/month, never requested payment changes
- Tone: Professional, invoice/contract discussions
=== KNOWN EVENT PATTERNS ===
- Vendor impersonation with lookalike domains
- Payment detail change requests referencing valid POs risk assessment
=== Task ===
Score (0-100): content anomalies, behavioral deviation, context alignment
{
"risk_score": 78,
"risk_level": "DANGEROUS",
"key_findings": [
"Domain mismatch: 'example-website.com' vs 'example.com'",
"First-ever payment change request from this sender",
"Phone number doesn't match vendor records"
]
}The continuous feedback loop
Behind these examples, the phishing detection system maintains dynamic sender baselines in a database that tracks each of your sender’s typical communication patterns, vocabulary, tone, and request types. False positives flagged by John’s security team are fed back into the phishing detection pipeline, updating baselines to account for legitimate variations in how senders communicate. Confirmed phishing patterns are cataloged alongside these baselines to enrich future prompt context with current intelligence. The result is a feedback loop where every correction and every confirmed threat make the analysis more accurate.
The continuous feedback pipeline runs across five stages:
1. Analyze – The foundation model evaluates your incoming email messages using dynamic prompts built from accumulated phishing attempt intelligence and sender context.
2. Score – Based on that analysis, a risk score from 0–100 is assigned, and suspicious messages are quarantined for your security team’s review.
3. Review – Flagged messages get classified as either a confirmed phishing attempt or a false positive.
4. Learn – Those classifications feed back into your system, updating the example library, sender behavior baselines, and emerging patterns catalog.
5. Enhance – New examples and confirmed phishing attempt patterns get incorporated into the analysis prompts, improving detection accuracy for the next cycle.
Early cycles will require more hands-on review as your system creates its baseline understanding. For John, that means his team initially spends more time classifying flagged messages, but the investment pays off quickly. As the example library and sender profiles grow, the model becomes progressively more accurate at distinguishing legitimate communications from phishing attempts. John stays in the loop throughout, but his attention shifts from sifting through noise to focusing on genuinely suspicious messages.
Each cycle through this loop creates a stronger, more adaptive defense that evolves alongside the phishing attempts it was designed to catch. That continuous improvement is what separates this feedback-driven detection model from static, signature-based detection.
Conclusion
Phishing detection can no longer rely on surface-level indicators such as typos and awkward phrasing. The framework in this post addresses that shift by combining the Amazon Bedrock foundation models with behavioral analysis, contextual grounding, and
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み