Google、Gemini 3.1 Flash-Lite を一般提供開始
Google は低遅延と高スループットに特化した「Gemini 3.1 Flash-Lite」を一般提供開始し、ソフトウェアエンジニアリングや金融サービス分野でのリアルタイム処理能力を強化した。
キーポイント
グローバル展開と性能指標
Google Cloud を通じて全世界で利用可能となり、p95 レイテンシが約 1.8 秒、サブ秒応答を実現する設計となっている。
ターゲット業界の特定
ソフトウェアエンジニアリングや金融サービスなど、高速な処理と大規模なトランザクションを要する分野に最適化されている。
コストと認知性能の向上
速度とコスト効率を改善しつつ、マルチモーダルタスクへの対応も強化され、開発者やカスタマーサービスの運用に適している。
影響分析・編集コメントを表示
影響分析
この発表は、LLM の導入において「速度」と「コスト」のトレードオフを解消する重要な一歩であり、特にリアルタイム性が求められる業務プロセスへの AI 統合を加速させる可能性があります。企業にとっては、高負荷なタスクでも低遅延で安定したサービスを提供できるため、顧客体験や開発効率の劇的な向上が期待されます。
編集コメント
「Lite」モデルの一般提供は、コスト効率を重視しつつ高性能な AI を実装したい企業にとって即戦力となるニュースです。特に金融や開発現場など、レイテンシがクリティカルな分野での採用拡大が予想されます。
Google は、Gemini 3 シリーズモデルの最新作である Gemini 3.1 Flash-Lite の一般提供を正式に開始しました。このモデルは現在、一般利用可能となっており、開発者や企業は Google Cloud プラットフォームを通じて世界中でアクセスできるようになりました。今回のリリースは特に、ソフトウェアエンジニアリング、カスタマーサービス、クリエイティブ産業、金融サービスなどにおいて、超低遅延と高ボリューム処理を要求する組織やチームを対象としています。Flash-Lite は、Gemini 3 モデルの中で最もコスト効率が高く、最速のモデルとして位置づけられており、分類タスクではサブ秒応答時間を提供し、重度の同時負荷下でも完全な回答生成における p95 レイテンシを約 1.8 秒に維持します。
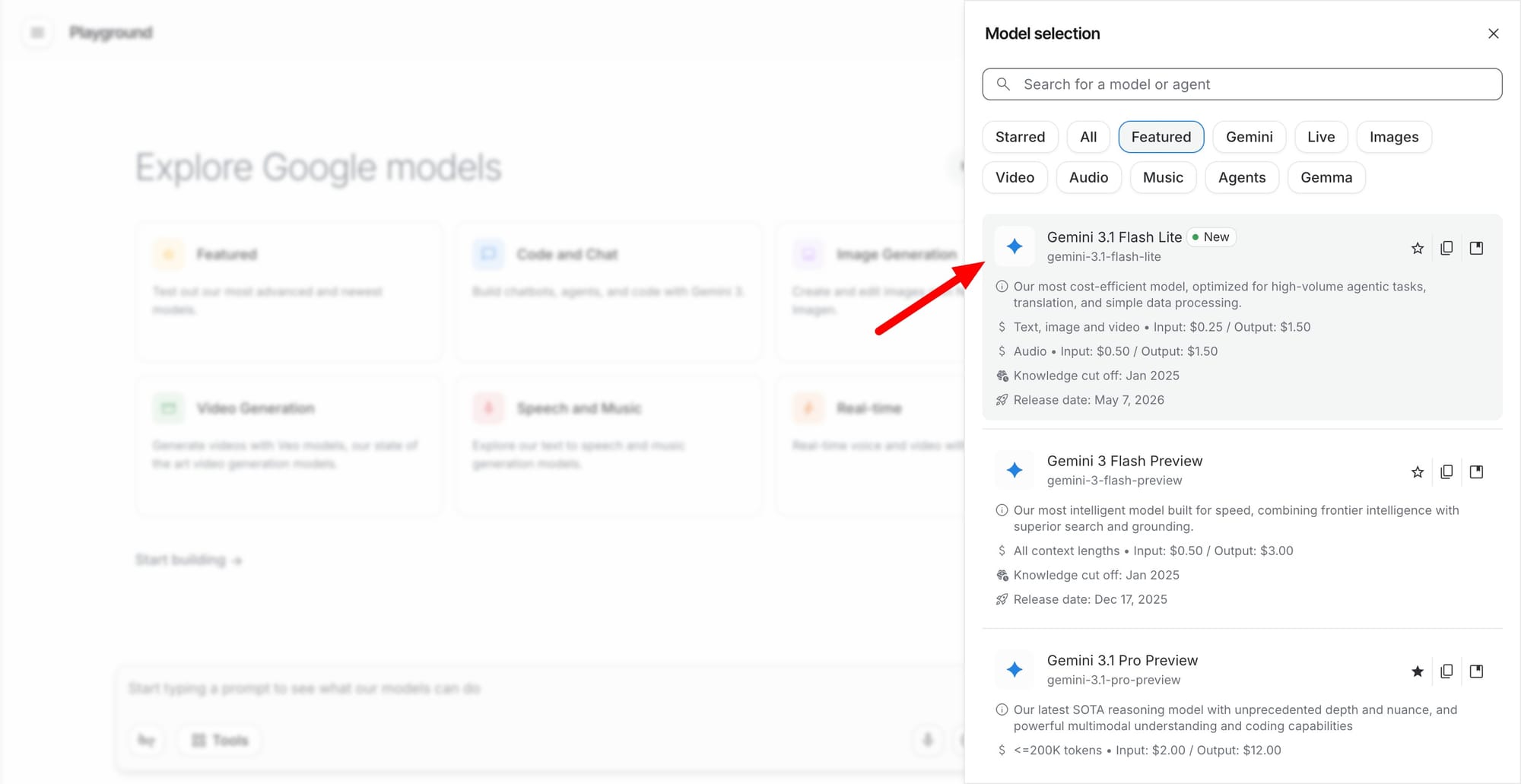 imageGemini 3.1 Flash-Lite はマルチモーダル機能(multimodal capabilities)を導入し、テキストと画像の両方の処理をサポートします。初期採用者からは、ツール呼び出しやオーケストレーションといったエージェントタスク(agentic tasks)を処理する能力や、リアルタイムの開発環境および高ボリュームのカスタマーサービス運用におけるパフォーマンスが評価されています。以前のバージョンと比較して、Flash-Lite は速度、コスト、認知性能の間により鋭いトレードオフを実現し、JetBrains、Gladly、Ramp などの企業が品質を犠牲にすることなくスケールした運用を行えるようにしています。業界専門家や技術リーダーは、即時のデータ処理と意思決定が重要なシナリオにおいて、その信頼性と費用対効果の高さを特に高く評価しています。
imageGemini 3.1 Flash-Lite はマルチモーダル機能(multimodal capabilities)を導入し、テキストと画像の両方の処理をサポートします。初期採用者からは、ツール呼び出しやオーケストレーションといったエージェントタスク(agentic tasks)を処理する能力や、リアルタイムの開発環境および高ボリュームのカスタマーサービス運用におけるパフォーマンスが評価されています。以前のバージョンと比較して、Flash-Lite は速度、コスト、認知性能の間により鋭いトレードオフを実現し、JetBrains、Gladly、Ramp などの企業が品質を犠牲にすることなくスケールした運用を行えるようにしています。業界専門家や技術リーダーは、即時のデータ処理と意思決定が重要なシナリオにおいて、その信頼性と費用対効果の高さを特に高く評価しています。
Google が Gemini 3.1 Flash-Lite をリリースしたことは、同社がエントプライズ規模での展開に最適化された AI モデル(AI models)の提供に引き続き注力していることを示しており、レイテンシ(latency)、費用対効果、そして堅牢なエージェント機能(agentic capabilities)への強い重点を置いています。本製品はすべての Google Cloud 顧客が利用可能であり、厳しいビジネスアプリケーションにおける AI ドライブ型自動化(AI-driven automation)の新たな基準を設定しています。
原文を表示
Google has officially rolled out Gemini 3.1 Flash-Lite, the latest addition to its Gemini 3 series models. The model is now generally available, making it accessible to developers and enterprises globally through Google Cloud platforms. This release specifically targets organizations and teams demanding ultra-low latency and high-volume processing, such as those in software engineering, customer service, creative industries, and financial services. Flash-Lite is positioned as the most cost-efficient and fastest Gemini 3 model, offering sub-second response times for classification tasks and maintaining a p95 latency around 1.8 seconds for full reply generation under heavy concurrent loads.
Gemini 3.1 Flash-Lite introduces multimodal capabilities, supporting both text and image processing. Early adopters highlight its ability to handle agentic tasks like tool calling and orchestration, and its performance in real-time developer environments and high-volume customer service operations. Compared to previous versions, Flash-Lite delivers a sharper trade-off among speed, cost, and cognitive performance, enabling enterprises such as JetBrains, Gladly, and Ramp to operate at scale without sacrificing quality. Industry experts and technical leads have praised its reliability and affordability, especially in scenarios where instant data processing and decision-making are critical.
Google’s release of Gemini 3.1 Flash-Lite demonstrates the company’s continued focus on delivering AI models optimized for enterprise-scale deployments, with a strong emphasis on latency, affordability, and robust agentic capabilities. The product is available to all Google Cloud customers, setting a new standard for AI-driven automation in demanding business applications.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み