急速に進化するAI製品のフィールドガイド
著者のハメル・フサインは、AI プロダクト開発においてツール選定に固執するのではなく、エラー分析と測定に基づく反復プロセスを最優先すべきであると説き、成功チームの具体的な運用パターンを提示しています。
キーポイント
「ツール第一」思考の罠
複雑なアーキテクチャや最新のフレームワークへの投資に熱中する一方、実際の成果を測定・分析するプロセスがおろそかになる傾向が指摘されています。
汎用指標の危険性
ダッシュボード上の「親切度スコア」などの一般化された指標に最適化しても、ユーザーの実質的な課題解決には寄与せず、進捗の錯覚を生むと警告しています。
エラー分析の重要性
プロジェクトを成功させる鍵は、失敗事例(エラー)を詳細に分析し、最も ROI の高い改善点を見極めるプロセスにあります。
ドメイン専門家の巻き込み
エンジニアだけでなく、業務の専門家も評価システムに参加させ、データビューアーを活用して継続的な改善を可能にする体制が推奨されています。
エラー分析の重要性と効果
複数の指標に目を向けるのではなく、実際の会話ログを調査し失敗モードを分類する「エラー分析」が最もROIの高い活動であり、日付処理の成功率を33%から95%へ向上させる結果をもたらしました。
ボトムアップ型アプローチの有効性
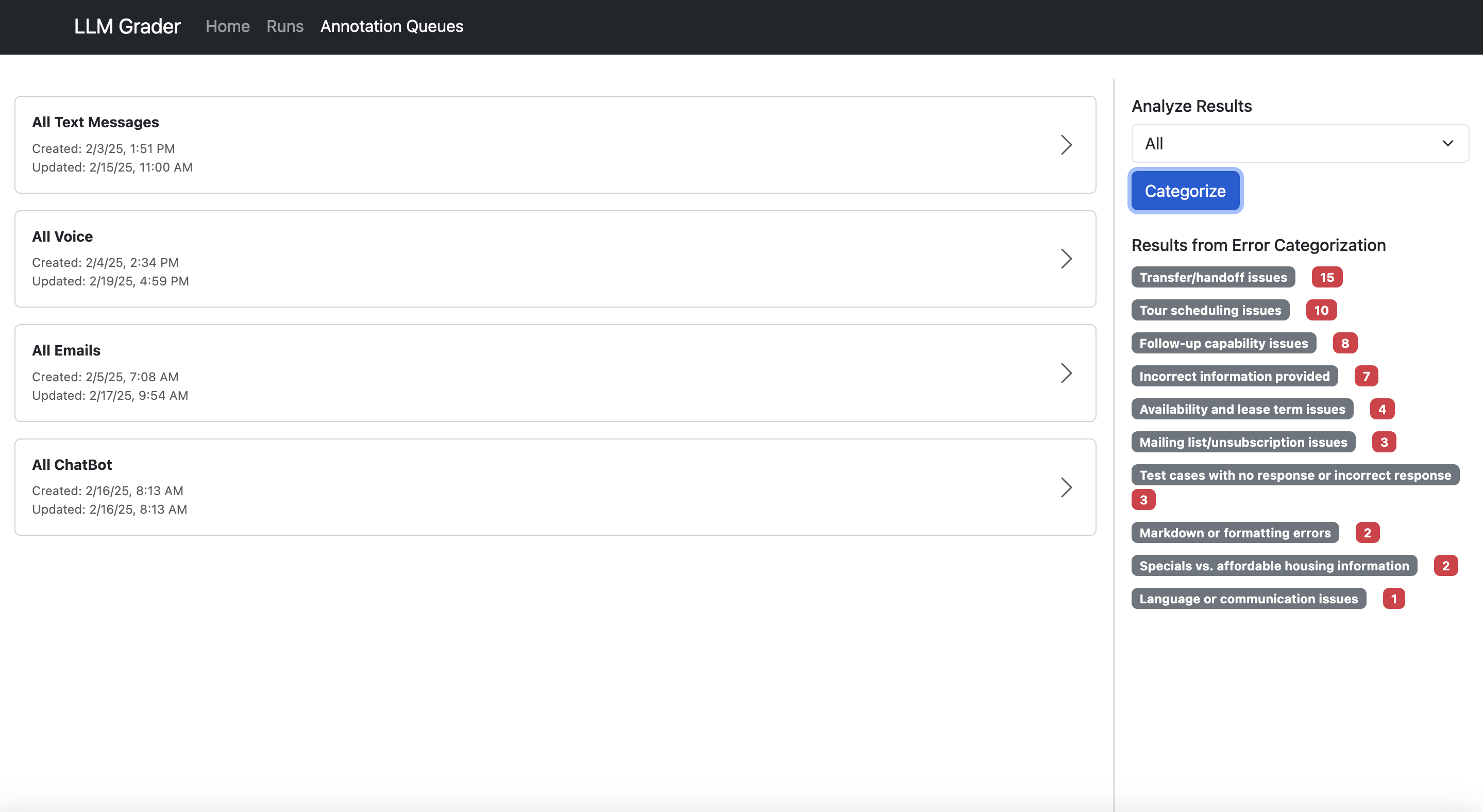
事前定義された指標に頼るトップダウン分析よりも、実際のデータから自然に出現するメトリクスを導き出すボトムアップ分析が優れており、これにより全問題の60%以上を占める3つの主要な課題(会話フロー、ハンドオフ失敗、再スケジュール)を特定できました。
簡易データビューアの投資価値
チームがデータを容易に閲覧・分析できるようになる「シンプルなデータビューア」の構築は、AI チームが行うべき最も重要な投資です。
影響分析・編集コメントを表示
影響分析
この記事は、AI 開発現場における「技術選定偏重」から「データドリブンな改善プロセス重視」へのパラダイムシフトを促す重要な提言です。多くの組織が陥っている指標の錯覚や分析不足という根本的な課題を指摘し、ROI の高い改善を実現するための具体的なフレームワークを提供することで、AI プロダクト開発の成功率向上に大きく寄与するでしょう。
編集コメント
技術的なツールの導入競争が激化する中、開発プロセスの本質である「測定と学習」を見直すよう促す非常に現実的なアドバイスです。特に、一般化されたメトリクスへの依存を戒める指摘は、多くの現場で即座に実践すべき課題と言えます。
ほとんどの AI チームは、間違ったことに注力しています。私のコンサルティング業務からよくある光景をご紹介します。
AI チーム
「こちらが私たちのエージェントアーキテクチャです – ここに RAG(Retrieval-Augmented Generation:検索拡張生成)があり、あちらにはルーターがあり、この新しいフレームワークを使って…
私
[熱心な技術責任者の話を止めるために手を上げる]
「これが実際に機能しているかどうかを、どのように測定していますか?」
… 部屋が静まり返る
この光景は、過去 2 年間で数十回繰り返されてきました。チームは何週間もかけて複雑な AI システムを構築しますが、その変更が役立っているのか悪影響を与えているのかを説明できません。
これは驚くべきことではありません。毎週新しいツールやフレームワークが登場する中で、私たちがコントロールできる具体的なものに注力するのは自然なことです – どのベクトルデータベースを使うか、どの LLM(Large Language Model:大規模言語モデル)プロバイダーを選ぶか、どのエージェントフレームワークを採用するかといった点です。しかし、30 社以上の企業で AI プロダクトの構築を支援してきた経験から、成功するチームはほとんどツールについて話さないことがわかりました。むしろ、彼らは測定と反復(イテレーション)に没頭しています。
本稿では、これらの成功したチームがどのように運営しているかを具体的に示します。あなたは以下のことを学びます:
エラー分析がいかにして最も ROI(投資対効果)の高い改善点を明らかにするか
なぜシンプルなデータビューアーが最も重要な AI 投資となるのか
ドメインエキスパート(エンジニアだけでなく)を動員して AI を改善する方法
なぜ合成データはあなたが考える以上に効果的なのか
評価システムへの信頼を維持する方法
なぜ AI ロードマップでは機能ではなく実験の数を数えるべきか
これらの各トピックについて、実際の事例を交えて説明します。すべての状況はユニークですが、ドメインやチーム規模に関わらず適用できるパターンが見えてくるでしょう。
まず、チームが犯す最も一般的なミスを検討してみましょう。これは AI プロジェクトが始まる前にさえもプロジェクトを頓挫させるものです。
- 最も一般的なミス:エラー分析の省略
「ツール最優先」という考え方が、AI 開発における最も一般的なミスです。チームはアーキテクチャ図やフレームワーク、ダッシュボードに夢中になるあまり、実際に何が機能していて何が機能していないのかを理解するプロセスを怠りがちです。
あるクライアントが誇らしげにこの評価用ダッシュボードを見せてくれました:
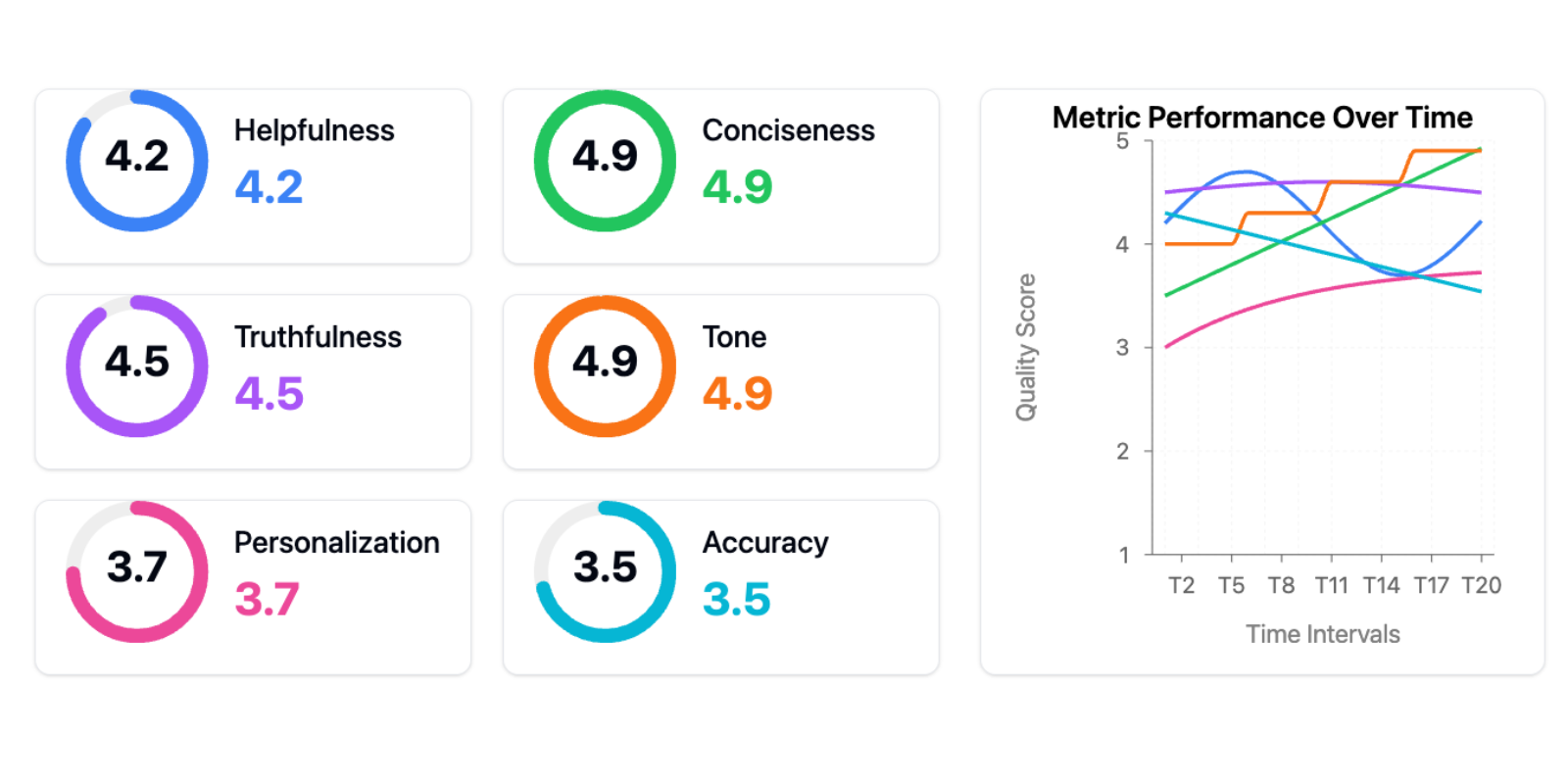
これは失敗を予兆させるようなダッシュボートです。
これが「ツールの罠」です。適切なツールやフレームワーク(今回は汎用的な指標)を採用すれば AI の問題が解決すると信じる考え方です。汎用的な指標は単に無効というだけでなく、2 つの点で進捗を積極的に阻害します:
第一に、測定と進歩に対する誤った安心感を生み出します。チームはダッシュボードを持っているためデータ駆動型だと考えがちですが、実際のユーザーの問題と相関しない「見栄えだけの指標」を追跡しているだけです。私は、「支援性スコア」が 10% 向上したことを祝うチームを目撃しましたが、その実際のユーザーたちは基本的なタスクでまだ苦労していました。これは、チェックアウトプロセスが壊れているのにウェブサイトの読み込み時間を最適化しているようなものです——間違ったものをより良くしようとしているのです。
第二に、指標が多すぎると注意散漫になります。特定のユースケースにおいて重要な少数の指標に焦点を当てるべきところを、複数の次元を同時に最適化しようとしてしまいます。すべてが重要であれば、何も重要ではありません。
では、代替案は何か?エラー分析です。これは AI 開発において最も価値のある活動であり、一貫して ROI(投資対効果)が最も高い活動です。実際の実践において、効果的なエラー分析がどのようなものかをお見せしましょう。
エラー分析のプロセス
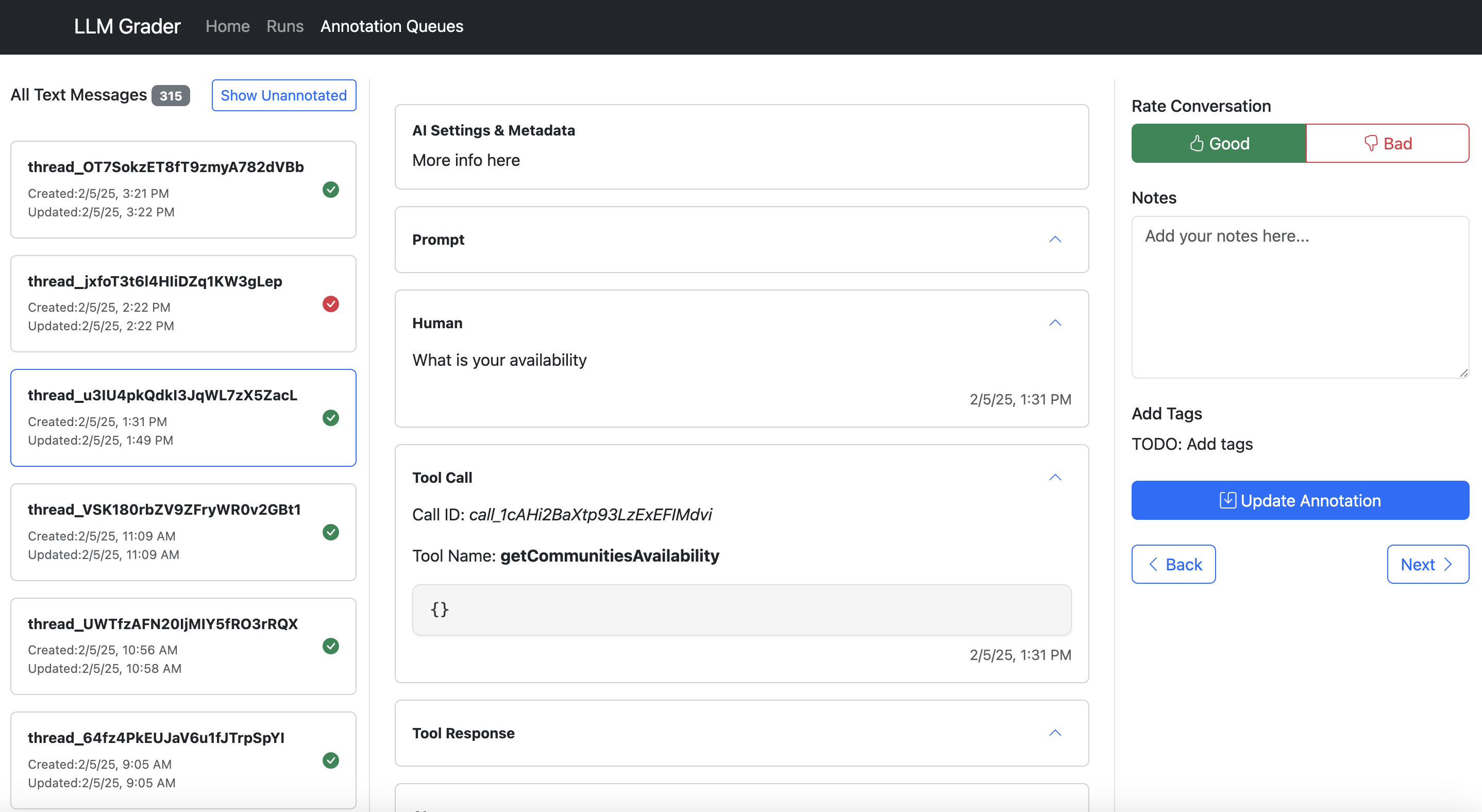
Nurture Boss の創設者である Jacob は、アパート業界向け AI アシスタントを改善する必要に迫られた際、チームは AI とユーザー間の会話を検証するためのシンプルなビューアーを構築しました。各会話の隣には、失敗モードに関する自由記述型のメモを入れるスペースがありました。
数十件の会話を注釈付けした後、明確なパターンが浮かび上がりました。彼らの AI は日付処理で苦戦しており、「今から 2 週間後にツアーを予約しよう」といった発言に対しては 66% の確率で失敗していました。
新しいツールに頼るのではなく、彼らは以下の手順を実行しました:1. 実際の会話ログを確認する 2. 日付処理の失敗タイプの分類を行う 3. これらの問題を検出するための特定のテストを構築する 4. これらの指標における改善度を測定する
その結果?日付処理の成功率は 33% から 95% に向上しました。
Jacob 自身がこのプロセスについて説明している様子を以下に示します:
ボトムアップ分析とトップダウン分析
エラータイプの特定においては、「トップダウン」アプローチか「ボトムアップ」アプローチのいずれかを選択できます。
トップダウンアプローチは、「ハルシネーション」や「毒性」といった一般的な指標に、タスク固有の指標を加えることから始まります。便利ではあるものの、ドメイン特有の問題を見逃すことが多いです。
より効果的なボトムアップアプローチは、実際のデータを見ることを強制し、指標が自然に浮かび上がるようにします。NurtureBoss では、各行が会話に対応するスプレッドシートから始めました。望ましくない行動については、自由記述のメモを書き込みました。その後、LLM を使用して一般的な失敗モードの分類体系を構築しました。最後に、各行を特定の失敗モードラベルにマッピングし、各問題の頻度をカウントしました。
結果は驚くべきものでした。たった 3 つの問題が全問題の 60% 以上を占めていたのです:
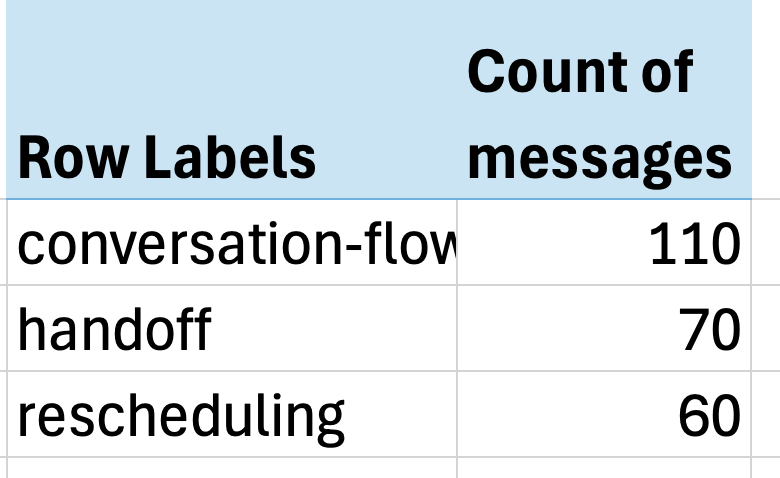
Excel のピボットテーブルはシンプルなツールですが、機能します!
会話フローの問題(文脈の欠如、不自然な応答)
ハンドオフの失敗(人間への引き継ぎが必要なタイミングの認識不足)
再スケジュールの問題(日付処理での苦戦)
その影響は即座に現れました。Jacob のチームは、すでに発見した問題に対する修正を実装するだけでも数週間を要するような、多くの実行可能な洞察を発見したのです。
エラー分析の実践例をご覧になりたい場合は、ライブのウォークスルーをこちらで録画しています。
ここで重要な質問が浮かび上がります:どうすればチームがデータを容易に確認できるか?その答えは、私が AI チームが行うべき最も重要な投資と考えるものへと導いてくれます…
- 最も重要な AI 投資:シンプルなデータビューアー
私が AI チームに見てきた中で、最もインパクトのある投資は、洗練された評価ダッシュボードの構築ではなく、誰でも AI が実際に何をしているかを検証できるカスタムインターフェースを構築することです。私は「カスタム」と強調します。なぜなら、各ドメインには独自のニーズがあり、市販のツールではそれらをほとんどカバーできないからです。
アパートメント賃貸に関する会話を見直す場合、完全なチャット履歴とスケジューリングのコンテキストを確認する必要があります。不動産に関する問い合わせの場合、その場で物件の詳細情報やソースドキュメントが必要になります。メタデータの配置場所やどのフィルターを公開するかといった小さな UX 上の判断一つでさえ、実際に使われるツールと避けられるツールの違いを生むのです。
私は、一般的なラベリングインターフェースに苦しみ、単一のインタラクションを理解するために複数のシステムをさまようチームを見てきました。この摩擦は蓄積します:コンテキストを確認するために別々のシステムをクリックして移動する、エラー記述をコピーして別の追跡シートに貼り付ける、情報を検証するためにツール間を行き来する。この摩擦はチームの速度を遅らせるだけでなく、微妙な問題を発見するための体系的な分析そのものを積極的に阻害します。
思慮深く設計されたデータビューアを持つチームは、持たないチームよりも 10 倍も速く反復できます。そしてここが重要な点ですが、これらのツールは AI を活用した開発(Cursor や Loveable など)を用いれば数時間で構築可能です。その投資対効果は極めて高いものです。
私が何を意味しているかお見せしましょう。以下は、以前議論した NurtureBoss のために構築されたデータビューアです:
画像:https://hamel.dev/blog/posts/field-guide/images/nboss_filter.png
セッションの検索とフィルタリング
画像:https://hamel.dev/blog/posts/field-guide/images/nboss_annotate.png
注釈の追加とメモの記録
画像:https://hamel.dev/blog/posts/field-guide/images/nboss_analysis.png
エラーの集計とカウント
優れたデータアノテーションツールには、以下の要素が必要です。
すべてのコンテキストを一つの場所で表示してください。何が起きたのかを理解するために、ユーザーが異なるシステム間を行き来させないでください。
フィードバックの収集を極めて容易にしてください。長々としたフォームよりも、ワンクリックで「正解/不正解」を選択できるボタンの方が優れています。
自由記述形式のフィードバックも受け付けてください。これにより、事前に定義された分類体系には収まらない微妙な問題やニュアンスを含んだ課題を捉えることができます。
迅速なフィルタリングとソート機能を備えてください。チームは特定のエラータイプにすばやくアクセスできる必要があります。上記の例では、NurtureBoss はチャネル(音声、テキスト、チャット)や、素早く確認したい特定のプロパティで簡単にフィルタリングできます。
ユーザーがクリックせずにデータサンプル間を移動し、アノテーションを行えるホットキーを提供してください。
使用する Web フレームワークは何でも構いません。自分が慣れているものを使えばよいのです。私は Python 開発者なので、現在の好みの Web フレームワークは FastHTML に MonsterUI を組み合わせたものです。これにより、バックエンドとフロントエンドのコードを一つの小さな Python ファイルで定義できるからです。
技術用語注記:
- データアノテーション (data annotation)
- フィルタリング (filtering)
- ソート (sorting)
- フレームワーク (framework)
鍵は、たとえ単純なものでもどこかから始めることにあります。私はカスタム Web アプリが最高の体験を提供できると感じていますが、もしあなたがまだ始めたばかりなら、スプレッドシートを使うことさえも何もしないよりはマシです。ニーズが高まるにつれて、ツールもそれに応じて進化させることができます。
これは、AI システムの改善に最も適しているのは、往々にして AI についてほとんど知らない人々であるという、もう一つの直感に反する教訓につながります。
- ドメイン専門家にプロンプト作成を任せる
私は最近、LLM を活用したインタラクティブな学習プラットフォームを構築していた教育系スタートアップと仕事をしていました。そのプロダクトマネージャーは学習デザインのエキスパートであり、教育的原則や例示的な対話について説明する詳細な PowerPoint デッキを作成していました。彼女はそれをエンジニアチームに提示し、彼らが彼女の専門知識をプロンプトに変換するという流れでした。
しかし、ここで重要なのは、プロンプトとは単なる英語であるということです。学習のエキスパートが PowerPoint を通じて教育原則を伝え、それをエンジニアが再び英語のプロンプトに戻すというプロセスは、不必要な摩擦を生み出していました。最も成功しているチームはこのモデルを逆転させ、ドメイン専門家が直接プロンプトを作成し、反復改善できるツールを提供します。
ゲートキーパーではなく橋渡し役を構築する
このための素晴らしい出発点は、プロンプトプレイグラウンドです。Arize、Langsmith、Braintrust といったツールを使えば、チームは異なるプロンプトを迅速にテストしたり、例示データセットを入力したり、結果を比較したりできます。これらのツールのスクリーンショットを以下に示します:
Arize Phoenix
LangSmith
Braintrust
しかし、多くのチームが見落としがちな重要な次のステップがあります。それは、プロンプト開発をアプリケーションの文脈に統合することです。ほとんどの AI アプリケーションは単なるプロンプトではなく、知識ベースから情報を引き出す RAG システム(Retrieval-Augmented Generation)、複数のステップを調整するエージェントオーケストレーション、そしてアプリケーション固有のビジネスロジックを一般的に含むものです。私がこれまで携わってきた最も効果的なチームは、スタンドアローンのプレイグラウンドを超えた活動を行います。彼らが構築するのは、私が統合型プロンプト環境と呼ぶものです。これは実質的に、プロンプト編集機能を公開した実際のユーザーインターフェースの管理用バージョンです。
以下に、不動産 AI アシスタントにおける統合型プロンプト環境の例を示します:
不動産エージェントがユーザーとして見る UI です。
同じ UI ですが、エンジニアリングチームと製品チームがプロンプトの反復改善やデバッグに使用する「管理モード」を備えたものです。
ドメイン専門家とのコミュニケーションに関するヒント
ドメインエキスパートが効果的に貢献することを妨げるもう一つの障壁は、不要な専門用語です。私は教育系スタートアップで働いていましたが、エンジニア、プロダクトマネージャー、学習専門家たちが会議で互いの話を聞き取れずにいました。エンジニアたちは「XYZ を行うエージェントを構築する」と言い続けましたが、実際にはやるべきことはプロンプトを書くことでした。これにより人工的な障壁が生まれ、実際のドメインエキスパートである学習専門家は、「エージェント」という用語を理解できないため貢献できないと感じてしまいました。
これはあらゆる場所で起こっています。法テック企業の弁護士、メンタルヘルススタートアップの心理学者、医療機関の医師たちでも同じ光景を見てきました。LLM の真価は、自然言語を通じて AI を誰もが使えるようにすることですが、私たちは往々にしてすべてのことを技術用語で包み込むことで、その利点を自ら壊してしまっています。
一般的な AI 専門用語を翻訳する簡単な例を示します:
~と言う代わりに…
~と言うべきです:
「RAG アプローチを実装する」
「モデルが質問に答えるために適切なコンテキスト(文脈)を持っていることを確認する」
「プロンプトインジェクションを防ぐ必要がある」
「ユーザーが AI にルールを無視させるようなトリックをかけられないようにする必要がある」
「モデルはハルシネーション(幻覚)の問題に悩まされている」
「AI は時折でたらめなことを言うので、回答を確認する必要がある」
これは物事を単純化することを意味するのではなく、実際に行っていることを正確に定義することを意味します。「エージェントを構築している」と言うとき、具体的にどのような機能を追加しているのでしょうか?関数呼び出しでしょうか、ツール利用でしょうか、それともより良いプロンプトでしょうか。具体的であることは、実際に何が起こっているのかを全員が理解するのに役立ちます。
ここには微妙なニュアンスがあります。専門用語が存在するのには理由があり、他の技術ステークホルダーと話す際に精度を提供します。鍵となるのは、聴衆に合わせて言語を適応させることです。
多くのチームがこの時点で抱える課題は次のようなものです。「すべて素晴らしいように聞こえますが、まだデータがない場合はどうすればよいのでしょうか?これから始めようとしている段階で、例を見たりプロンプトを反復したりできるでしょうか?」これについては次にお話しします。
- 合成データを用いた AI のブートストラップは効果的である(ユーザーゼロでも)
私がチームからよく耳にする最も一般的な障壁の一つは、「まだ十分な実ユーザーデータがないため、適切な評価ができない」というものです。これは鶏と卵の問題を生み出します。AI を改善するにはデータが必要ですが、そのデータを生成するユーザーを獲得するには、それなりの AI が必要です。
幸いにも、驚くほどよく機能する解決策があります。それが合成データです。大規模言語モデル(LLM)は、AI が遭遇する可能性のあるシナリオの範囲をカバーする現実的なテストケースを生成できます。
私が「LLM をジャッジとして用いる」というブログ記事で書いたように、合成データは評価において非常に効果的である可能性があります。Hex の元 AI 責任者であったブライアン・ビシュコフ(Bryan Bischof)氏はこれを完璧に表現しています:
「LLM は、驚くほど優れた、かつ多様なユーザープロンプトの例を生成するのが得意です。これはアプリケーション機能の強化に役立ちますし、ひそかに Evals(評価システム)の構築にも利用できます。これが少し『巨大言語蛇が自分の尻尾を食べる』ような状況に見えるなら、私もあなたと同じくらい驚いています!私が言えるのはただ一つ:これは機能します、実装しましょう。」
現実的なテストデータ生成のためのフレームワーク
効果的な合成データの鍵は、テストする適切な次元(dimesions)を選ぶことにあります。これらの次元は特定のニーズによって異なりますが、私は 3 つの広範なカテゴリについて考えることが役立つと感じています:
機能(Features): あなたの AI がサポートすべき能力は何ですか?
シナリオ(Scenarios): それはどのような状況に遭遇するでしょうか?
ユーザーペルソナ(User Personas): 誰がどのようにそれを使用するのでしょうか?
これらがあなたが関心を持つ唯一の次元ではありません。異なるトーン、技術的な洗練度のレベル、さらには異なる地域や言語をテストしたい場合もあるでしょう。重要なのは、特定のユースケースにとって意味のある次元を特定することです。
Rechat と共同で取り組んだ不動産 CRM AI アシスタントでは、これらの次元を以下のように定義しました:
features = [
"property search", # 条件に一致する物件リストの検索
"market analysis", # トレンドと価格の分析
"scheduling", # 物件見学のスケジュール設定
"follow-up" # 見学後のコミュニケーション
]
scenarios = [
"exact match", # One perfect listing match
"multiple matches", # Need to help user narrow down
"no matches", # Need to suggest alternatives
"invalid criteria" # Help user correct search terms
]
personas = [
"first_time_buyer", # Needs more guidance and explanation
"investor", # Focused on numbers and ROI
"luxury_client", # Expects white-glove service
"relocating_family" # Has specific neighborhood/school needs
]
しかし、これらの次元を定義しただけでは戦いの半分です。真の課題は、生成された合成データが実際にテストしたいシナリオを引き起こすことを保証することにあります。これには2つの要素が必要です。
- シナリオをサポートするのに十分な多様性を持つテストデータベース
- 生成されたクエリが意図したシナリオを本当に引き起こしているかを確認する方法
Rechat では、異なるエッジケースを引き起こすことがわかっている物件リストのテストデータベースを維持していました。一部のチームは、本番環境データの匿名化コピーを使用することを好みますが、いずれにせよ、関心のあるシナリオを実行するためにテストデータに十分な多様性があることを保証する必要があります。
以下は、プロパティ検索機能のテストケースを生成する際に、これらの次元を実際のデータとどのように組み合わせて使用するかを示す例です(これは擬似コードであり、非常に示唆的なものです):
def generate_search_query(scenario, persona, listing_db):
"""リスト物件に関する現実的なユーザークエリを生成する"""
# 生成の根拠とするために、実際のリスト物件データを取得
sample_listings = listing_db.get_sample_listings(
price_range=persona.price_range,
location=persona.preferred_areas
)
# シナリオをトリガーする物件があるか検証
if scenario == "multiple_matches" and len(sample_listings) < 2:
raise ValueError("このシナリオには複数の物件が必要")
if scenario == "no_matches" and len(sample_listings) > 0:
raise ValueError("一致なしシナリオのテスト中に物件が見つかった")
prompt = f"""
あなたはリスト物件を検索する不動産エージェントの専門家です。顧客タイプとシナリオが与えられます。
あなたの仕事は、これらの物件を検索するために使用する自然言語によるクエリを生成することです。
コンテキスト:
- 顧客タイプ: {persona.description}
- シナリオ: {scenario}
これら実際のリスト物件を参照として使用してください:
{format_listings(sample_listings)}
クエリは、顧客タイプとシナリオを反映したものであるべきです。
例のクエリ: 投資家向けに、75019 郵便番号エリアで、3 部屋・2 バスルーム、価格帯$750k〜$1M の住宅を探す。
"""
return generate_with_llm(prompt)
これにより、以下のような現実的なクエリが生成されました:
機能
シナリオ
ペルソナ
生成されたクエリ
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
property search
multiple matches
first_time_buyer
「リバーサイドエリアで 50 万ドル以下の 3 ベッドルームの住宅を探しています。子供が小さいので、公園に近い物件だと嬉しいです。」
market analysis
no matches
investor
「123 Oak St の比較対象(コンプ)が必要です。特に、半径 2 マイル以内の類似物件との賃貸利回り比較に関心があります。」
有用な合成データを作る鍵は、それを実際のシステム制約に根ざさせることです。不動産 AI アシスタントの場合、これは以下を意味します:
データベースから実際のリスト ID と住所を使用する
実際のエージェントのスケジュールと利用可能時間を組み込む
表示制限や通知期間といったビジネスルールを尊重する
HOA(住宅所有者協会)要件や地域規制など、市場固有の詳細を含める
その後、これらのテストケースを Lucy に通してインタラクションをログ記録します。これにより、実際のシステム制約下で AI が異なる状況にどう対応するかを正確に示す、分析用の豊富なデータセットが得られます。このアプローチにより、実ユーザーに影響が出る前に問題を修正することができました。
時には本番データベースへのアクセスができない場合があり、特に新製品の場合にその傾向が強まります。そのような場合は、LLM(大規模言語モデル)を使用してテストクエリと基盤となるテストデータの両方を生成してください。不動産向け AI アシスタントの例では、市場価格範囲に合致する価格、実在する道路名を含む有効な住所、各物件タイプに適した設備など、現実的な属性を持つ合成された物件リストを作成することを意味します。重要なのは、合成データを現実世界の制約に基づかせることで、テストに有用なものにすることです。堅牢な合成データベースを生成する具体的な方法は、本稿の範囲を超えています。
合成データの使用ガイドライン
合成データを生成する際は、その効果を確保するために以下の主要な原則に従ってください:
データセットの多様化:広範な機能、シナリオ、ペルソナをカバーする例を作成してください。私が「LLM-as-a-Judge(LLM を審査員として用いる)」という記事で述べたように、この多様性は、通常では予測できないエッジケースや失敗モードを特定するのに役立ちます。
出力ではなくユーザー入力を生成:LLM を使用して、期待される AI の応答ではなく、現実的なユーザークエリまたは入力を作成してください。これにより、合成データが生成モデルのバイアスや制限を引き継ぐことを防ぎます。
Inc
原文を表示
Most AI teams focus on the wrong things. Here’s a common scene from my consulting work:
AI TEAM
Here’s our agent architecture – we’ve got RAG here, a router there, and we’re using this new framework for…
ME
[Holding up my hand to pause the enthusiastic tech lead.]
“Can you show me how you’re measuring if any of this actually works?”
… Room goes quiet
This scene has played out dozens of times over the last two years. Teams invest weeks building complex AI systems, but can’t tell me if their changes are helping or hurting.
This isn’t surprising. With new tools and frameworks emerging weekly, it’s natural to focus on tangible things we can control – which vector database to use, which LLM provider to choose, which agent framework to adopt. But after helping 30+ companies build AI products, I’ve discovered the teams who succeed barely talk about tools at all. Instead, they obsess over measurement and iteration.
In this post, I’ll show you exactly how these successful teams operate. You’ll learn:
How error analysis consistently reveals the highest-ROI improvements
Why a simple data viewer is your most important AI investment
How to empower domain experts (not just engineers) to improve your AI
Why synthetic data is more effective than you think
How to maintain trust in your evaluation system
Why your AI roadmap should count experiments, not features
I’ll explain each of these topics with real examples. While every situation is unique, you’ll see patterns that apply regardless of your domain or team size.
Let’s start by examining the most common mistake I see teams make – one that derails AI projects before they even begin.
- The Most Common Mistake: Skipping Error Analysis
The “tools first” mindset is the most common mistake in AI development. Teams get caught up in architecture diagrams, frameworks, and dashboards while neglecting the process of actually understanding what’s working and what isn’t.
One client proudly showed me this evaluation dashboard:
The kind of dashboard that foreshadows failure.
This is the “tools trap” – the belief that adopting the right tools or frameworks (in this case, generic metrics) will solve your AI problems. Generic metrics are worse than useless – they actively impede progress in two ways:
First, they create a false sense of measurement and progress. Teams think they’re data-driven because they have dashboards, but they’re tracking vanity metrics that don’t correlate with real user problems. I’ve seen teams celebrate improving their “helpfulness score” by 10% while their actual users were still struggling with basic tasks. It’s like optimizing your website’s load time while your checkout process is broken – you’re getting better at the wrong thing.
Second, too many metrics fragment your attention. Instead of focusing on the few metrics that matter for your specific use case, you’re trying to optimize multiple dimensions simultaneously. When everything is important, nothing is.
The alternative? Error analysis - the single most valuable activity in AI development and consistently the highest-ROI activity. Let me show you what effective error analysis looks like in practice.
The Error Analysis Process
When Jacob, the founder of Nurture Boss, needed to improve their apartment-industry AI assistant, his team built a simple viewer to examine conversations between their AI and users. Next to each conversation was a space for open-ended notes about failure modes.
After annotating dozens of conversations, clear patterns emerged. Their AI was struggling with date handling – failing 66% of the time when users said things like “let’s schedule a tour two weeks from now.”
Instead of reaching for new tools, they: 1. Looked at actual conversation logs 2. Categorized the types of date-handling failures 3. Built specific tests to catch these issues 4. Measured improvement on these metrics
The result? Their date handling success rate improved from 33% to 95%.
Here’s Jacob explaining this process himself:
Bottom-Up vs. Top-Down Analysis
When identifying error types, you can take either a “top-down” or “bottom-up” approach.
The top-down approach starts with common metrics like “hallucination” or “toxicity” plus metrics unique to your task. While convenient, it often misses domain-specific issues.
The more effective bottom-up approach forces you to look at actual data and let metrics naturally emerge. At NurtureBoss, we started with a spreadsheet where each row represented a conversation. We wrote open-ended notes on any undesired behavior. Then we used an LLM to build a taxonomy of common failure modes. Finally, we mapped each row to specific failure mode labels and counted the frequency of each issue.
The results were striking - just three issues accounted for over 60% of all problems:
Excel Pivot Tables are a simple tool, but they work!
Conversation flow issues (missing context, awkward responses)
Handoff failures (not recognizing when to transfer to humans)
Rescheduling problems (struggling with date handling)
The impact was immediate. Jacob’s team had uncovered so many actionable insights that they needed several weeks just to implement fixes for the problems we’d already found.
If you’d like to see error analysis in action, we recorded a live walkthrough here.
This brings us to a crucial question: How do you make it easy for teams to look at their data? The answer leads us to what I consider the most important investment any AI team can make…
- The Most Important AI Investment: A Simple Data Viewer
The single most impactful investment I’ve seen AI teams make isn’t a fancy evaluation dashboard – it’s building a customized interface that lets anyone examine what their AI is actually doing. I emphasize customized because every domain has unique needs that off-the-shelf tools rarely address. When reviewing apartment leasing conversations, you need to see the full chat history and scheduling context. For real estate queries, you need the property details and source documents right there. Even small UX decisions – like where to place metadata or which filters to expose – can make the difference between a tool people actually use and one they avoid.
I’ve watched teams struggle with generic labeling interfaces, hunting through multiple systems just to understand a single interaction. The friction adds up: clicking through to different systems to see context, copying error descriptions into separate tracking sheets, switching between tools to verify information. This friction doesn’t just slow teams down – it actively discourages the kind of systematic analysis that catches subtle issues.
Teams with thoughtfully designed data viewers iterate 10x faster than those without them. And here’s the thing: these tools can be built in hours using AI-assisted development (like Cursor or Loveable). The investment is minimal compared to the returns.
Let me show you what I mean. Here’s the data viewer built for NurtureBoss (which we discussed earlier):
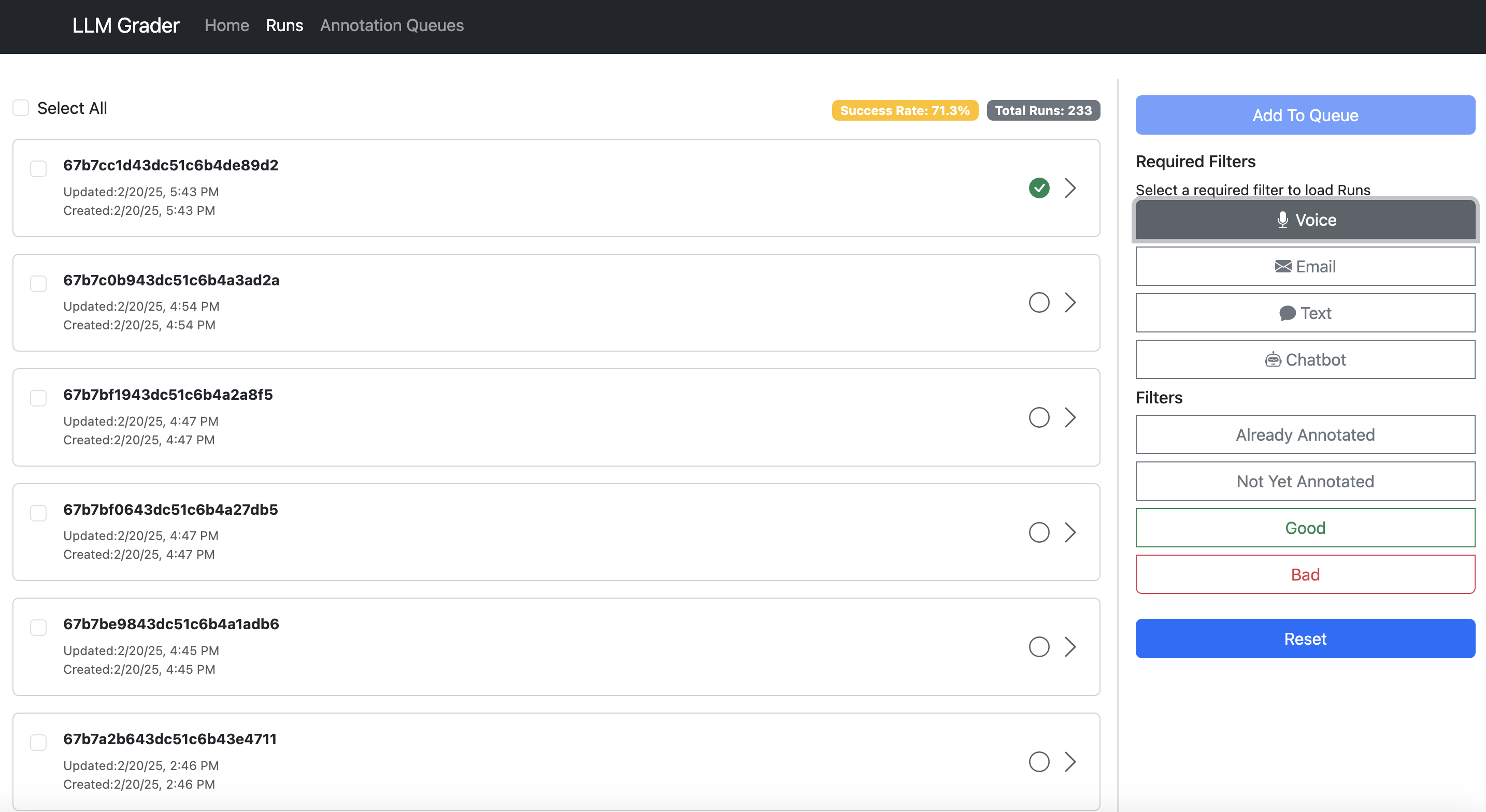
Search and filter sessions
Annotate and add notes
Aggregate and count errors
Here’s what makes a good data annotation tool:
Show all context in one place. Don’t make users hunt through different systems to understand what happened.
Make feedback trivial to capture. One-click correct/incorrect buttons beat lengthy forms.
Capture open-ended feedback. This lets you capture nuanced issues that don’t fit into a pre-defined taxonomy.
Enable quick filtering and sorting. Teams need to easily dive into specific error types. In the example above, NurtureBoss can quickly filter by the channel (voice, text, chat) or the specific property they want to look at quickly.
Have hotkeys that allow users to navigate between data examples and annotate without clicking.
It doesn’t matter what web frameworks you use - use whatever you are familiar with. Because I’m a python developer, my current favorite web framework is FastHTML coupled with MonsterUI, because it allows me to define the back-end and front-end code in one small python file.
The key is starting somewhere, even if it’s simple. I’ve found custom web apps provide the best experience, but if you’re just beginning, a spreadsheet is better than nothing. As your needs grow, you can evolve your tools accordingly.
This brings us to another counter-intuitive lesson: the people best positioned to improve your AI system are often the ones who know the least about AI.
- Empower Domain Experts To Write Prompts
I recently worked with an education startup building an interactive learning platform with LLMs. Their product manager, a learning design expert, would create detailed PowerPoint decks explaining pedagogical principles and example dialogues. She’d present these to the engineering team, who would then translate her expertise into prompts.
But here’s the thing: prompts are just English. Having a learning expert communicate teaching principles through PowerPoint, only for engineers to translate that back into English prompts, created unnecessary friction. The most successful teams flip this model by giving domain experts tools to write and iterate on prompts directly.
Build Bridges, Not Gatekeepers
Prompt playgrounds are a great starting point for this. Tools like Arize, Langsmith and Braintrust let teams quickly test different prompts, feed in example datasets, and compare results. Here are some screenshots of these tools:
Arize Phoenix
LangSmith
Braintrust
But there’s a crucial next step that many teams miss: integrating prompt development into their application context. Most AI applications aren’t just prompts – They commonly involve RAG systems pulling from your knowledge base, agent orchestration coordinating multiple steps, and application-specific business logic. The most effective teams I’ve worked with go beyond standalone playgrounds. They build what I call integrated prompt environments – essentially admin versions of their actual user interface that expose prompt editing.
Here’s an illustration of what an integrated prompt environment might look like for a real estate AI assistant:
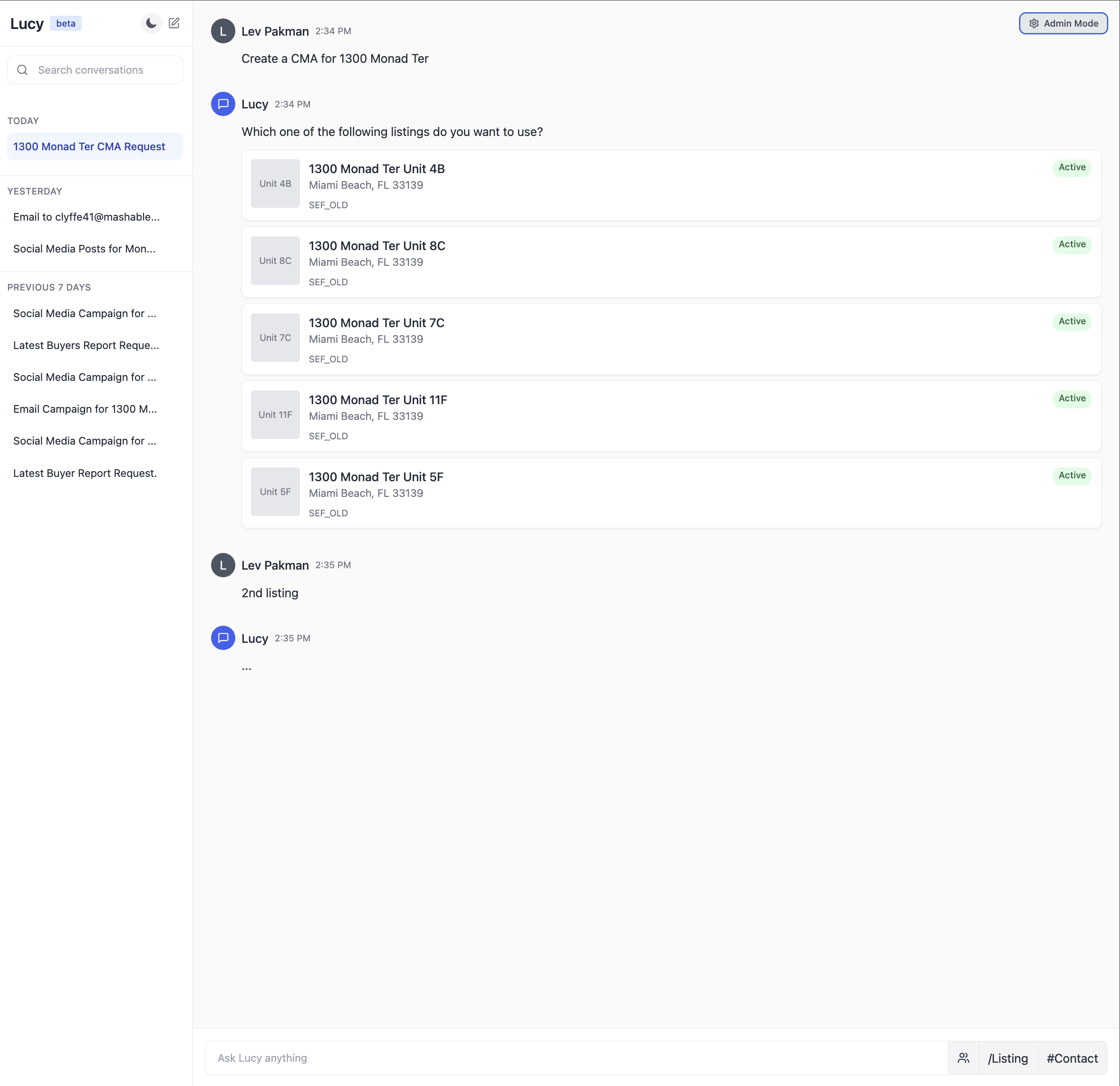
The UI that users (real estate agents) see.
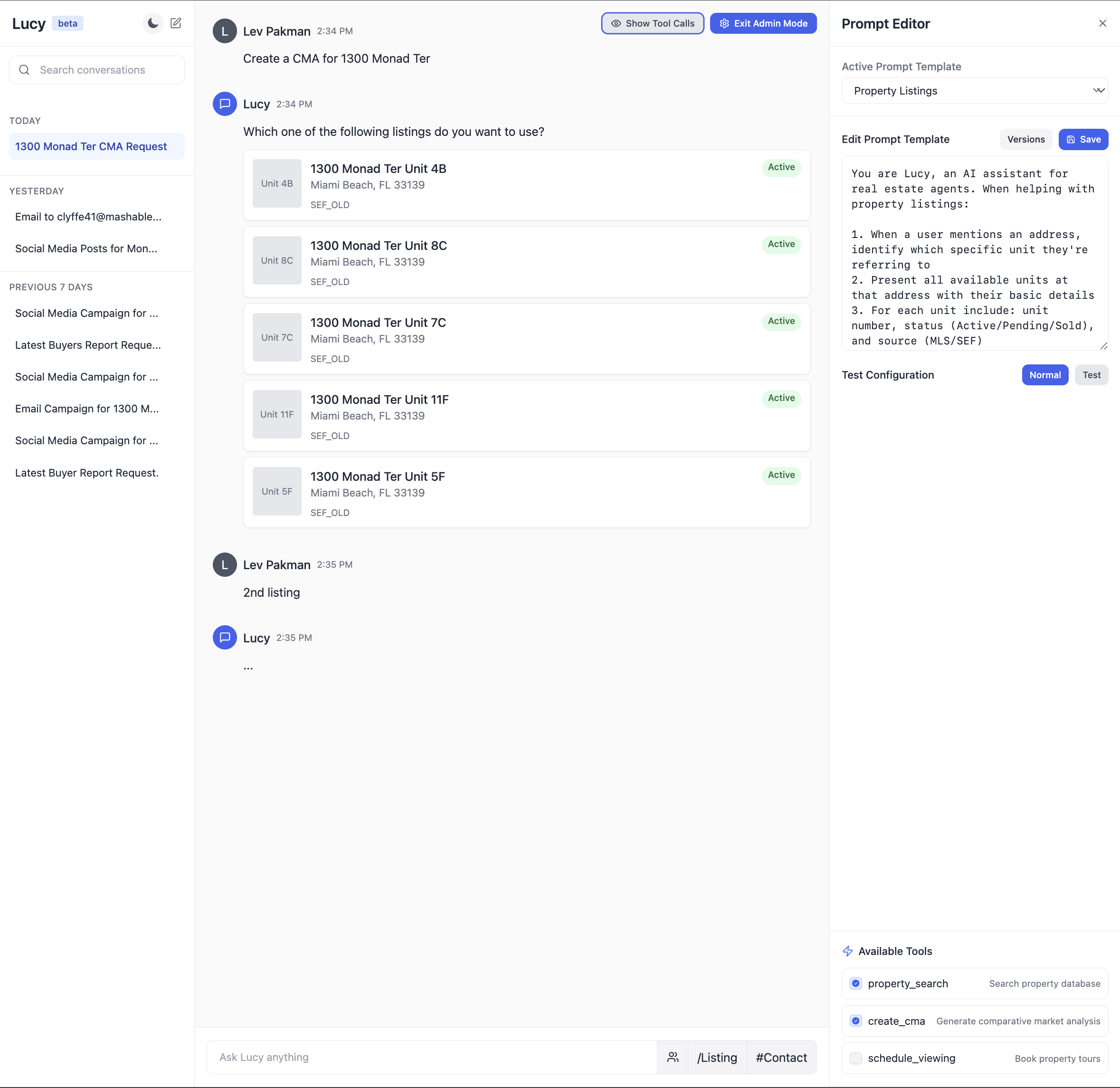
The same UI, but with an “admin mode”used by the engineering & product team to iterate on the prompt and debug issues.
Tips For Communicating With Domain Experts
There’s another barrier that often prevents domain experts from contributing effectively: unnecessary jargon. I was working with an education startup where engineers, product managers, and learning specialists were talking past each other in meetings. The engineers kept saying, “We’re going to build an agent that does XYZ,” when really the job to be done was writing a prompt. This created an artificial barrier – the learning specialists, who were the actual domain experts, felt like they couldn’t contribute because they didn’t understand “agents.”
This happens everywhere. I’ve seen it with lawyers at legal tech companies, psychologists at mental health startups, and doctors at healthcare firms. The magic of LLMs is that they make AI accessible through natural language, but we often destroy that advantage by wrapping everything in technical terminology.
Here’s a simple example of how to translate common AI jargon:
Instead of saying…
Say…
“We’re implementing a RAG approach”
“We’re making sure the model has the right context to answer questions”
“We need to prevent prompt injection”
“We need to make sure users can’t trick the AI into ignoring our rules”
“Our model suffers from hallucination issues”
“Sometimes the AI makes things up, so we need to check its answers”
This doesn’t mean dumbing things down – it means being precise about what you’re actually doing. When you say “we’re building an agent,” what specific capability are you adding? Is it function calling? Tool use? Or just a better prompt? Being specific helps everyone understand what’s actually happening.
There’s nuance here. Technical terminology exists for a reason – it provides precision when talking with other technical stakeholders. The key is adapting your language to your audience.
The challenge many teams raise at this point is: “This all sounds great, but what if we don’t have any data yet? How can we look at examples or iterate on prompts when we’re just starting out?” That’s what we’ll talk about next.
- Bootstrapping Your AI With Synthetic Data Is Effective (Even With Zero Users)
One of the most common roadblocks I hear from teams is: “We can’t do proper evaluation because we don’t have enough real user data yet.” This creates a chicken-and-egg problem – you need data to improve your AI, but you need a decent AI to get users who generate that data.
Fortunately, there’s a solution that works surprisingly well: synthetic data. LLMs can generate realistic test cases that cover the range of scenarios your AI will encounter.
As I wrote in my LLM-as-a-Judge blog post, synthetic data can be remarkably effective for evaluation. Bryan Bischof, the former Head of AI at Hex, put it perfectly:
“LLMs are surprisingly good at generating excellent - and diverse - examples of user prompts. This can be relevant for powering application features, and sneakily, for building Evals. If this sounds a bit like the Large Language Snake is eating its tail, I was just as surprised as you! All I can say is: it works, ship it.”
A Framework for Generating Realistic Test Data
The key to effective synthetic data is choosing the right dimensions to test. While these dimensions will vary based on your specific needs, I find it helpful to think about three broad categories:
Features: What capabilities does your AI need to support?
Scenarios: What situations will it encounter?
User Personas: Who will be using it and how?
These aren’t the only dimensions you might care about – you might also want to test different tones of voice, levels of technical sophistication, or even different locales and languages. The important thing is identifying dimensions that matter for your specific use case.
For a real estate CRM AI assistant I worked on with Rechat, we defined these dimensions like this:
features = [
"property search", # Finding listings matching criteria
"market analysis", # Analyzing trends and pricing
"scheduling", # Setting up property viewings
"follow-up" # Post-viewing communication
]
scenarios = [
"exact match", # One perfect listing match
"multiple matches", # Need to help user narrow down
"no matches", # Need to suggest alternatives
"invalid criteria" # Help user correct search terms
]
personas = [
"first_time_buyer", # Needs more guidance and explanation
"investor", # Focused on numbers and ROI
"luxury_client", # Expects white-glove service
"relocating_family" # Has specific neighborhood/school needs
]
But having these dimensions defined is only half the battle. The real challenge is ensuring your synthetic data actually triggers the scenarios you want to test. This requires two things:
A test database with enough variety to support your scenarios
A way to verify that generated queries actually trigger intended scenarios
For Rechat, we maintained a test database of listings that we knew would trigger different edge cases. Some teams prefer to use an anonymized copy of production data, but either way, you need to ensure your test data has enough variety to exercise the scenarios you care about.
Here’s an example of how we might use these dimensions with real data to generate test cases for the property search feature (this is just pseudo-code, and very illustrative):
def generate_search_query(scenario, persona, listing_db):
"""Generate a realistic user query about listings"""
# Pull real listing data to ground the generation
sample_listings = listing_db.get_sample_listings(
price_range=persona.price_range,
location=persona.preferred_areas
)
# Verify we have listings that will trigger our scenario
if scenario == "multiple_matches" and len(sample_listings) < 2:
raise ValueError("Need multiple listings for this scenario")
if scenario == "no_matches" and len(sample_listings) > 0:
raise ValueError("Found matches when testing no-match scenario")
prompt = f"""
You are an expert real estate agent who is searching for listings. You are given a customer type and a scenario.
Your job is to generate a natural language query you would use to search these listings.
Context:
- Customer type: {persona.description}
- Scenario: {scenario}
Use these actual listings as reference:
{format_listings(sample_listings)}
The query should reflect the customer type and the scenario.
Example query: Find homes in the 75019 zip code, 3 bedrooms, 2 bathrooms, price range $750k - $1M for an investor.
"""
return generate_with_llm(prompt)
This produced realistic queries like:
Feature
Scenario
Persona
Generated Query
property search
multiple matches
first_time_buyer
“Looking for 3-bedroom homes under $500k in the Riverside area. Would love something close to parks since we have young kids.”
market analysis
no matches
investor
“Need comps for 123 Oak St. Specifically interested in rental yield comparison with similar properties in a 2-mile radius.”
The key to useful synthetic data is grounding it in real system constraints. For the real-estate AI assistant, this means:
Using real listing IDs and addresses from their database
Incorporating actual agent schedules and availability windows
Respecting business rules like showing restrictions and notice periods
Including market-specific details like HOA requirements or local regulations
We then feed these test cases through Lucy and log the interactions. This gives us a rich dataset to analyze, showing exactly how the AI handles different situations with real system constraints. This approach helped us fix issues before they affected real users.
Sometimes you don’t have access to a production database, especially for new products. In these cases, use LLMs to generate both test queries and the underlying test data. For a real estate AI assistant, this might mean creating synthetic property listings with realistic attributes – prices that match market ranges, valid addresses with real street names, and amenities appropriate for each property type. The key is grounding synthetic data in real-world constraints to make it useful for testing. The specifics of generating robust synthetic databases are beyond the scope of this post.
Guidelines for Using Synthetic Data
When generating synthetic data, follow these key principles to ensure it’s effective:
Diversify your dataset: Create examples that cover a wide range of features, scenarios, and personas. As I wrote in my LLM-as-a-Judge post, this diversity helps you identify edge cases and failure modes you might not anticipate otherwise.
Generate user inputs, not outputs: Use LLMs to generate realistic user queries or inputs, not the expected AI responses. This prevents your synthetic data from inheriting the biases or limitations of the generating model.
Inc
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み