CORPGENが実務向けAIエージェントを進化させる
Microsoft Researchは、現実の職場環境を模したマルチタスク評価環境MHTEを開発し、その課題を解決する階層的計画・メモリ分離・経験学習を備えたAIエージェントフレームワーク「CORPGEN」を発表し、ベースライン比最大3.5倍のタスク完了率向上を実証した。
キーポイント
現実の職場環境を反映した新評価環境「MHTE」
従来の単一タスク評価では不十分な現実の職場環境を模倣するため、複数の複雑なタスクを同時に管理する必要がある「Multi-Horizon Task Environments(MHTE)」を開発した。
既存AIエージェントのマルチタスク課題の明確化
MHTEでの大規模テストにより、既存の先進的AIエージェントはマルチタスク環境下でメモリ不足、タスク間干渉、複雑な依存関係の管理、動的優先順位付けの4つの弱点を露呈し、タスク数増加に伴い完了率が16.7%から8.7%に急落した。
CORPGENの革新的アーキテクチャと性能
階層的計画、メモリ分離、経験学習を備えた「デジタル従業員」を導入するCORPGENは、アーキテクチャに依存しないモジュラー設計で、3つの独立したエージェントバックエンドでベースライン比最大3.5倍のタスク完了率向上を達成した。
実用性と将来性
CORPGENの性能向上は特定の基盤モデルではなくシステム設計に由来し、基盤モデルの改善に直接恩恵を受けるため、実用的な職場AIエージェントの開発に寄与する。
CORPGENのAIエージェントの特徴
LLMを活用したデジタル従業員は、永続的なアイデンティティ、役割特化の専門知識、現実的な勤務スケジュールを持ち、GUI自動化でMicrosoft Officeアプリケーションを操作し、長時間の連続活動でも一貫したパフォーマンスを発揮する。
並行タスク実行の課題解決メカニズム
階層的計画、分離されたサブエージェント、階層化メモリ、適応的サマリゼーションの4つのメカニズムにより、メモリ過負荷、タスク間干渉、依存関係の複雑さ、優先順位変更といった課題を体系的に対処している。
デジタル従業員間の協働方法
複数のデジタル従業員は、共有内部状態を持たず、メールやMicrosoft Teamsなどの標準的な通信チャネルを通じて協力し、独立した交換が時間とともに組織的なパターンを形成する。
影響分析・編集コメントを表示
影響分析
この研究は、AIエージェントの評価を現実の職場環境に近づける重要な一歩であり、単一タスク性能だけでなく複雑なマルチタスク管理能力の重要性を業界に認識させる。CORPGENのアーキテクチャに依存しない設計は、基盤モデルの進化を活かした実用的な職場AIエージェント開発の新たな方向性を示している。
編集コメント
AIエージェント研究が単体性能から実環境適応性へと進化していることを示す重要な研究。企業向けAI応用の実用化に向けた具体的な課題解決アプローチが提示されている。

一目でわかる要点
現在の AI エージェントのベンチマークは一度に一つのタスクのみをテストするが、実際の職場での生産性向上には、数十の相互依存するタスクを同時に管理することが必要である。この状況を反映させるため、私たちは「マルチ・ホライズン・タスク・環境(Multi-Horizon Task Environments: MHTEs)」と呼ばれる設定を作成した。
複数タスク負荷の下では、主要なコンピュータ操作型エージェントの性能は著しく低下し、完了率は 16.7% から 8.7% に減少する。
CORPGEN は、階層的計画、メモリ分離、経験学習を備えたデジタル従業員を導入し、3 つの独立したエージェントバックエンド全体で、ベースラインと比較して最大 3.5 倍の高い完了率を実現する。
CORPGEN はアーキテクチャに依存せずモジュール化されているため、その性能向上は特定の単一基盤モデルによるものではなくシステム設計によるものであり、基盤となるモデルが改善されるにつれて直接的な恩恵を受ける。
朝の半ば頃には、典型的な知識労働者はすでにクライアントからの報告書、予算スプレッドシート、プレゼンテーション資料、そしてメールのバックログを同時に処理しており、これらはすべて相互に関連し、同時に注意を要するものである。AI エージェントがそのような環境で真に有用となるためには、同様の方法で動作する必要があるが、現在の最良モデルは一度に一つのタスクとして評価されており、数十のタスクを同時に扱うことはできない。
論文「CORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments」において、私たちは AI に記憶、計画、学習の能力を付与し、そのギャップを埋めるためのエージェントフレームワークを提案します。
マルチホライズンタスク環境(Multi-Horizon Task Environments)の紹介
職場での多忙な現実を再現するには、新しい種類の評価環境が必要です。これに応えるため、私たちはマルチホライズンタスク環境(MHTEs: Multi-Horizon Task Environments)を開発しました。これは、エージェントが複数の複雑なタスクを同時に管理しなければならない設定です。各タスクは、5 時間にわたる単一のセッション内で、10 から 30 の依存関係を持つステップを必要とします。
ベンチマークが何をテストすべきかを決定するため、私たちは今日の主要な AI エージェントの一部で MHTEs を大規模に実行し、4 つの弱点を明らかにしました。第一に、メモリがいっぱいになることです。エージェントは一度に複数のアクティブなタスクの詳細を保持できません。第二に、あるタスクからの情報が別のタスクに関する推論を妨げることです。第三に、タスクが単純な順序で互いに依存しているわけではないことです。それらは複雑なネットワークを形成しており、エージェントは下流の作業に進む前に、上流の作業が完了したかどうかを常に確認する必要があります。第四に、すべてのアクションサイクルにおいて、エージェントが中断した場所から再開するのではなく、アクティブな全タスク間で優先順位を再設定することが必要となることです。
また、負荷が増加する条件下で 3 つの独立したエージェントシステムもテストしました。並行して実行されるタスク数が 12 から 46 に増加すると、すべてのシステムにおける完了率は 16.7% から 8.7% に低下しました。
CORPGEN のアーキテクチャ
CORPGEN はデジタル従業員を導入します。これは、永続的なアイデンティティ、役割固有の専門知識、そして現実的な勤務スケジュールを備えた、大規模言語モデル(LLM)駆動型 AI エージェントです。これらは GUI 自動化を通じて Microsoft Office アプリケーションを操作し、数時間にわたる連続した活動においても MHTEs(マルチホストタスク環境)内で一貫して動作します。図 1 は、デジタル従業員が一日の業務の流れをどのように遂行するかを示しています。
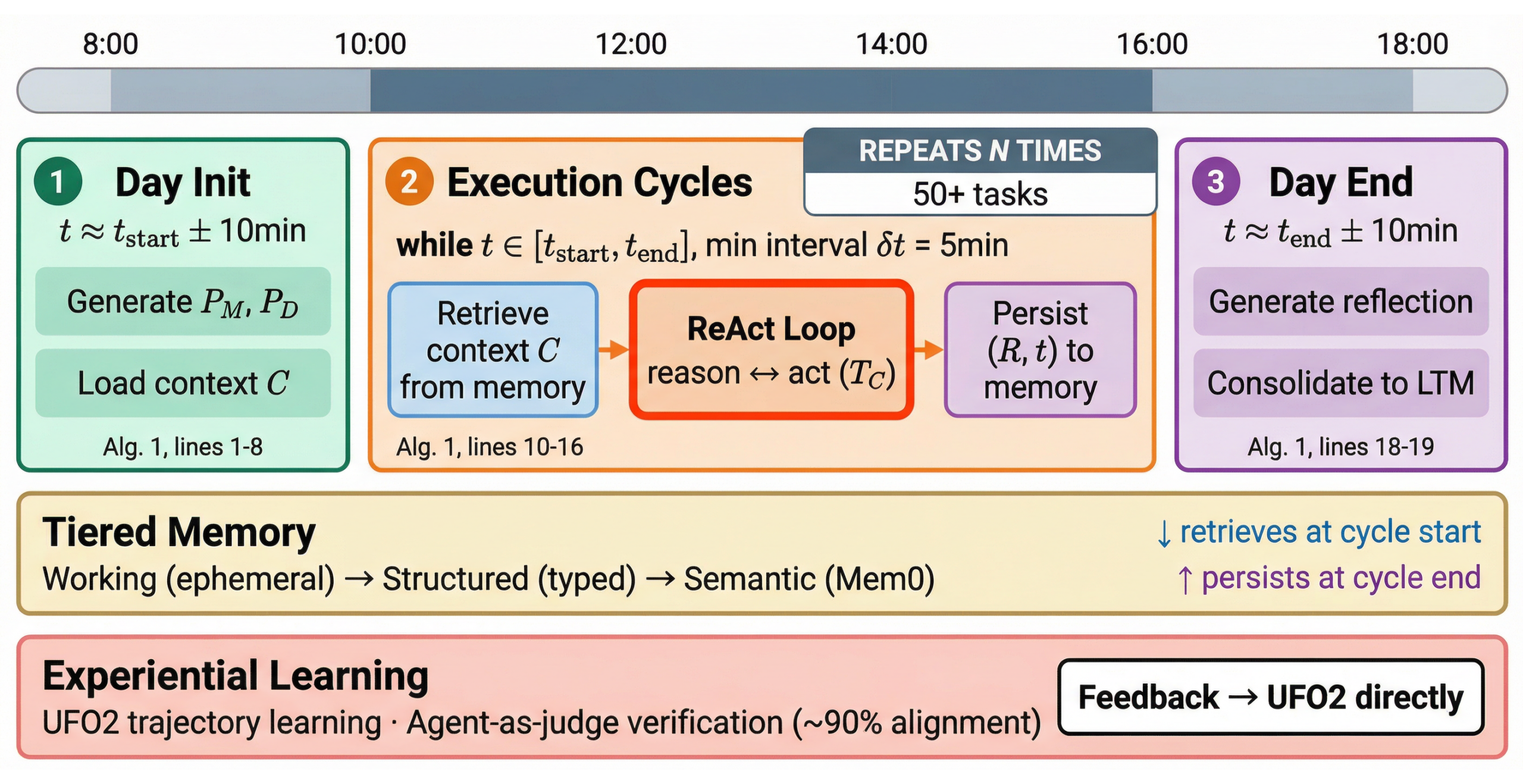 image図 1. 各日は、前回のセッションから読み込まれた構造化された計画とメモリをもって始まります。その後、エージェントは重複するタスクを繰り返しのサイクルで処理し、一日の終わりに重要な成果物を保存して次のセッションに反映させます。
image図 1. 各日は、前回のセッションから読み込まれた構造化された計画とメモリをもって始まります。その後、エージェントは重複するタスクを繰り返しのサイクルで処理し、一日の終わりに重要な成果物を保存して次のセッションに反映させます。
CORPGEN は、並行タスク実行における 4 つの弱点——メモリ過負荷、タスク間の干渉、依存関係の複雑さ、そして優先順位の再設定——をそれぞれ標的型のアプローチで解決します。階層的計画では、目標を日次ゴールに分解し、さらに瞬間ごとの意思決定へと細分化することで、エージェントが各ステップの前に利用可能なすべてのタスクを見直すのではなく、構造化された計画に基づいて行動できるようにしています。
サブエージェントは、ウェブ調査などの複雑な操作を隔離されたコンテキスト内で実行し、タスク間の汚染(クロス・タスク・コンタミネーション)を防ぎます。階層化されたメモリシステムにより、タスク関連情報の選択的な想起が可能となり、すべての情報をアクティブなコンテキストに保持する必要がなくなります。適応型要約は、日常的な観察を圧縮しつつ重要な情報を保持することで、メモリの成長を制御可能に保ちます。
これらのメカニズムは特定の基盤モデルに紐付いていないため、CORPGEN を 3 つの異なるエージェントでテストしました。どのケースでも一貫した改善が観測されました。この向上は、特定のモデルの強さによるものではなく、アーキテクチャ自体によるものです。図 2 は、これらが CORPGEN のアーキテクチャ内でどのように組み合わされているかを示しています。
 image図 2. CORPGEN における並行タスク実行を支える 4 つのメカニズム:階層型プランニング、孤立したサブエージェント、階層化されたメモリ、適応的サマライゼーション。
image図 2. CORPGEN における並行タスク実行を支える 4 つのメカニズム:階層型プランニング、孤立したサブエージェント、階層化されたメモリ、適応的サマライゼーション。
デジタル従業員間の協働
複数のデジタル従業員が同じ環境で動作する場合、事前定義された調整ルールなしに、標準的な通信チャネルを通じて協働が形作られます。ある従業員がデータ要求のメールを送信し、別の従業員が次のサイクルでそれを受け取り、自身のメモリを使用して処理した上で返信します。このやり取りは、実際の職場でのコミュニケーションを模倣しています。
エージェント間には共有された内部状態はありません。調整は、多くの労働者が使用するのと同じチャネルであるメールと Microsoft Teams を通じて完全に実施されます。時間の経過とともに、これらの独立したやり取りは認識可能な組織パターンを形成します。一部のエージェントがリーダーシップ役割を引き受け、他のエージェントがサポートを提供し、共有ドキュメントが結合組織として機能します。
通信経路が切断された場合、例えばメールの配信エラーが発生した場合、エージェントは代替チャネルを介してメッセージを転送し、作業の継続を図ります。その結果、明示的にそうプログラムされていないにもかかわらず、実組織のように振る舞う仮想組織が実現されます。
CORPGEN の評価
私たちは、最大 46 のタスクを単一の 6 時間セッションに統合したマルチタスクベンチマークにおいて CORPGEN を評価しました。3 つの重要な知見が浮かび上がりました。
負荷が増加するとベースラインは性能が低下しますが、CORPGEN はそうではありません。すべての 3 つのベースラインエージェントシステムは、タスク負荷の上昇に伴って着実に性能が低下しました。一方、CORPGEN は高い負荷下でも完了率を維持し、あるいは向上させました。46 のタスクという条件下では、CORPGEN はタスクの 15.2% を完了したのに対し、ベースラインは 4.3% であり、約 3.5 倍の差がありました。
経験学習が最大の成果をもたらします。私たちは CORPGEN の構成要素を順次導入しました:まずオーケストレーション層(orchestration layer)、次に認知ツール(cognitive tools)、最後に経験学習です。最初の 2 つは中程度の改善をもたらしましたが、完了したタスクの記録を保存し、構造的に類似した作業に出会った際にそれらを再利用する経験学習が最大の向上をもたらしました。これにより、完了率は 8.7% から 15.2% に引き上げられました。
評価方法論の変化が状況を大きく変えます。エージェントが実際に生成した出力ファイルを精査したところ、その結果は人間の判断と約 90% の確率で一致しました。一方、スクリーンショットやアクションログに基づく評価では、一致するのは約 40% に留まりました。この乖離は、一般的な評価手法が、実務においてエージェントが実際に達成している成果を過小評価している可能性を示唆しています。
Spotlight: Event Series

Microsoft Research Forum
一般 AI の時代における研究について、継続的なアイデアの交換にご参加ください。最初の 4 エピソードはオンデマンドで視聴可能です。
オンデマンドで視聴
新しいタブで開く
示唆と今後の展望
この結果は、エージェントを実世界で機能させる上で、単なるモデルの能力だけでなく、記憶(memory)や検索(retrieval)が重要なボトルネックとなり得ることを示唆しています。最も大きな改善が見られたのは経験学習によるものでした。過去の成功事例から学び、構造的に類似したタスクに対してそのパターンを適用するエージェントは、各タスクを孤立して処理するシステムよりも優位性を築くことができます。
CORPGEN は、AI エージェントがどのように協力するかという点にも新たな視点をもたらします。今後のステップとしては、エージェントが複数の勤務日を超えて記憶を維持できるか、またチームで作業する際にどのように調整を行うかを検証することが含まれます。私たちはまた、ソフトウェアとの相互作用における異なる手法を組み合わせて、エージェントの速度と信頼性を高める方法も探求しています。
謝辞
本研究成果は、Microsoft の CTO 室と Microsoft AI Development Accelerator Program (MAIDAP) との協力によるものです。本研究を支援するリソースを提供してくれた Microsoft Security Research チームに感謝いたします。また、CORPGEN アーキテクチャの中核コンポーネントを実現可能にしたオープンソースへの貢献に対して、Microsoft UFO2 (新しいタブで開く) チームおよび Mem0 (新しいタブで開く) プロジェクトのメンバーにも謝意を表します。さらに、マルチタスク評価の基盤となったベンチマークを提供してくれた OSWorld チームにも感謝いたします。
最後に、本研究に多大な貢献をされた多くの方々に心から感謝申し上げます:Anjel Shaileshbhai Patel 氏、Dayquan Julienne 氏、Charlotte Siska 氏、Manuel Raúl Meléndez Luján 氏、Anthony Twum-Barimah 氏、Mauricio Velazco 氏、そして Tianwei Chen 氏。
新しいタブで開くこの投稿「CORPGEN advances AI agents for real work」は、Microsoft Research で最初に発表されました。
原文を表示
At a glance
Today’s AI agent benchmarks test one task at a time, while real workplace productivity requires managing dozens of interdependent tasks at once. To reflect this, we created a setting called Multi-Horizon Task Environments (MHTEs).
Under multi-task loads, leading computer-using agents degrade sharply, with completion rates dropping from 16.7% to 8.7%.
CORPGEN introduces digital employees, with hierarchical planning, memory isolation, and experiential learning, delivering up to 3.5 times higher completion rates than baselines across three independent agent backends.
Because CORPGEN is architecture-agnostic and modular, its gains come from system design rather than any single base model, and it benefits directly as underlying models improve.
By mid-morning, a typical knowledge worker is already juggling a client report, a budget spreadsheet, a slide deck, and an email backlog, all interdependent and all demanding attention at once. For AI agents to be genuinely useful in that environment, they will need to operate the same way, but today’s best models are evaluated one task at a time, not dozens at once.
In our paper, “CORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments,” we propose an agent framework that equips AI with the memory, planning, and learning capabilities to close that gap.
Introducing Multi-Horizon Task Environments
Replicating the reality of workplace multitasking requires a new kind of evaluation environment. In response, we developed Multi-Horizon Task Environments (MHTEs), settings where an agent must manage multiple complex tasks simultaneously. Each task requires 10 to 30 dependent steps within a single session spanning five hours.
To determine what a benchmark would need to test, we ran MHTEs at scale on some of today’s leading AI agents, exposing four weaknesses. First, memory fills up. An agent cannot hold details for multiple active tasks at once. Second, information from one task interferes with reasoning about another. Third, tasks don’t depend on each other in simple sequences. They form complex webs where an agent must constantly check whether upstream work is finished before it can move forward on anything downstream. Fourth, every action cycle requires reprioritizing across all active tasks, not simply resuming where the agent left off.
We also tested three independent agent systems under increasing loads. As the number of concurrent tasks rose from 12 to 46, completion rates fell from 16.7% to 8.7% across all systems.
CORPGEN’s architecture
CORPGEN introduces digital employees: LLM-powered AI agents with persistent identities, role-specific expertise, and realistic work schedules. They operate Microsoft Office applications through GUI automation and perform consistently within MHTEs over hours of continuous activity. Figure 1 illustrates how a digital employee moves through a full workday.
imageFigure 1. Each day begins with a structured plan and memory loaded from previous sessions. The agent then works through overlapping tasks in repeated cycles, storing key outcomes at day’s end to inform the next session.
CORPGEN addresses each of the four weaknesses of concurrent task execution—memory overload, cross-task interference, dependency complexity, and reprioritization—in a targeted way. Hierarchical planning breaks objectives into daily goals and then into moment-to-moment decisions, allowing the agent to act from a structured plan instead of reviewing all available tasks before each step.
Subagents perform complex operations like web research in isolated contexts, preventing cross-task contamination. A tiered memory system enables selective recall of task-related information rather than retaining everything in active context. Adaptive summarization compresses routine observations while preserving critical information, keeping memory growth controlled.
Because these mechanisms are not tied to a specific base model, we tested CORPGEN across three different agents. In each case, we observed consistent gains. The improvements came from the architecture, not from the strength of any particular model. Figure 2 shows how they fit together within CORPGEN’s architecture.
imageFigure 2. Four mechanisms support concurrent task execution in CORPGEN: hierarchical planning, isolated subagents, tiered memory, and adaptive summarization.
How digital employees collaborate
When multiple digital employees operate in the same environment, collaboration takes shape through standard communication channels, without predefined coordination rules. One employee sends an email requesting data; another picks it up in the next cycle, uses its memory to process it, and responds. This exchange mirrors real workplace communication.
There is no shared internal state between agents. Coordination occurs entirely through email and Microsoft Teams, the same channels many workers use. Over time, these independent exchanges form recognizable organizational patterns. Some agents take on leadership roles; others provide support; shared documents become the connective tissue.
When a communication path breaks, such as an email delivery error, agents reroute messages through alternate channels to keep work moving. The result is a virtual organization that behaves like a real one without being explicitly programmed to do so.
Evaluating CORPGEN
We evaluated CORPGEN on a multi-task benchmark that combined up to 46 tasks into a single six-hour session. Three findings stood out.
Baselines degrade as load increases; CORPGEN does not. All three baseline agent systems showed steady performance declines as task load rose. CORPGEN, by contrast, maintained or improved its completion rates at higher loads. At 46 tasks, CORPGEN completed 15.2% of tasks, compared with 4.3% for the baselines, roughly 3.5 times more.
Experiential learning drives the largest gains. We introduced CORPGEN’s components sequentially: first the orchestration layer, then cognitive tools, and finally experiential learning. The first two produced moderate improvements. Experiential learning, in which agents store records of completed tasks and reuse them when they encounter structurally similar work, produced the largest increase, raising completion rates from 8.7% to 15.2%.
Evaluation methodology changes the picture. When we inspected the actual output files produced by agents, the results agreed with human judgements roughly 90% of the time. Evaluation based on screenshots and action logs agreed only about 40% of the time. This gap suggests that common evaluation approaches may underestimate what agents actually accomplish in practice.
Spotlight: Event Series
image
Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the first four episodes on demand.
Watch on-demand
Opens in a new tab
Implications and looking forward
The results suggest that memory and retrieval, not just raw model capability, may be a key bottleneck in getting agents to work in the real world. The largest gains came from experiential learning. Agents that learn from prior successes and apply those patterns to structurally similar tasks build an advantage over systems that respond to each task in isolation.
CORPGEN also opens a new lens on how AI agents collaborate. Next steps include testing whether agents can maintain memory across multiple workdays and how they coordinate when working in teams. We are also exploring ways to make agents faster and more reliable by combining different methods of interacting with software.
Acknowledgments
This work is a result of a collaboration between the Office of the CTO at Microsoft and the Microsoft AI Development Accelerator Program (MAIDAP). We would like to thank the Microsoft Security Research team for providing resources that supported this research. We also thank the members of the Microsoft UFO2 (opens in new tab) team and the Mem0 (opens in new tab) project for their open-source contributions, which enabled key components of the CORPGEN architecture, and the OSWorld team for the benchmark that served as the foundation for our multi-task evaluation.
Finally, we thank the many contributors to this research: Anjel Shaileshbhai Patel, Dayquan Julienne, Charlotte Siska, Manuel Raúl Meléndez Luján, Anthony Twum-Barimah, Mauricio Velazco, and Tianwei Chen.
Opens in a new tabThe post CORPGEN advances AI agents for real work appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み