GitHub Copilot エージェント型ハッチのモデル・タスク間での性能と効率の評価
GitHub は、Copilot エージェントの基盤となる「ハルネス」の性能と効率性を評価するベンチマーク結果を公開し、主要な 4 つのモデル(Claude 4.6/4.7, GPT-5.4/5.5)間の比較分析を行った。
キーポイント
エージェント・ハルネスの重要性と設計思想
GitHub は、モデル自体の知能だけでなく、それを適用する「ハルネス」が効率性を決定づけるとし、高速性、トークン効率、予測可能性を重視した設計方針を示している。
多角的なベンチマーク評価手法
業界標準の SWE-bench や SkillsBench と併せ、GitHub 内部のコードベースに基づく独自ベンチや Windows コンテナ環境での検証など、多面的な評価体系を構築している。
主要モデル間の性能比較データ
Claude Sonnet 4.6, Opus 4.7 および GPT-5.4, GPT-5.5 の 4 つの最新モデルを対象に、バグ修正や複雑なエンジニアリングタスクでのパフォーマンスを定量的に比較した。
公平な比較条件の徹底
モデルプロバイダのハルネスとの比較において、同じモデル、同じベンチマーク課題、コンテキストウィンドウ、推論コスト、ツール選択、MCP サーバーなどを統制し、ハルネス固有の影響を抽出した。
トークン効率とタスク完了の両立
GitHub Copilot CLI は、他のベンダー製ハッチングと同等のタスク完了率を維持しつつ、多くの設定でより低いトークン消費量を示す。
統計的変動範囲内の性能均等性
異なるモデルやタスク間でのパフォーマンス差は、モデルの確率的性質による変動範囲内であり、実質的な性能差はないと判断される。
モデル選択の柔軟性とコスト効率
GitHub Copilot は GPT、Claude、Gemini など 20 以上のモデルをサポートし、タスクごとに最適なパフォーマンスとコストのバランスを選べるほか、Auto モデル選択機能でトークン効率を最適化します。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェント開発において「モデルそのもの」だけでなく「制御・調整層(ハルネス)」の重要性を浮き彫りにしており、業界全体が単なる推論能力競争から、システム全体の効率化と実用性への転換期にあることを示唆しています。GitHub が公開する詳細なベンチマークデータは、開発者が最適なモデルや構成を選択するための重要な指針となり、エージェント技術の成熟度を客観的に評価する基準として機能すると考えられます。
編集コメント
モデルの性能比較だけでなく、それを動かす「ハルネス」の評価に焦点を当てた点は非常に示唆に富んでいます。今後の AI エージェント開発においては、推論エンジンそのものよりも、いかに効率的にリソースを配分しタスクを遂行する制御層が競争優位性を決定づける時代へと移行していることが伺えます。
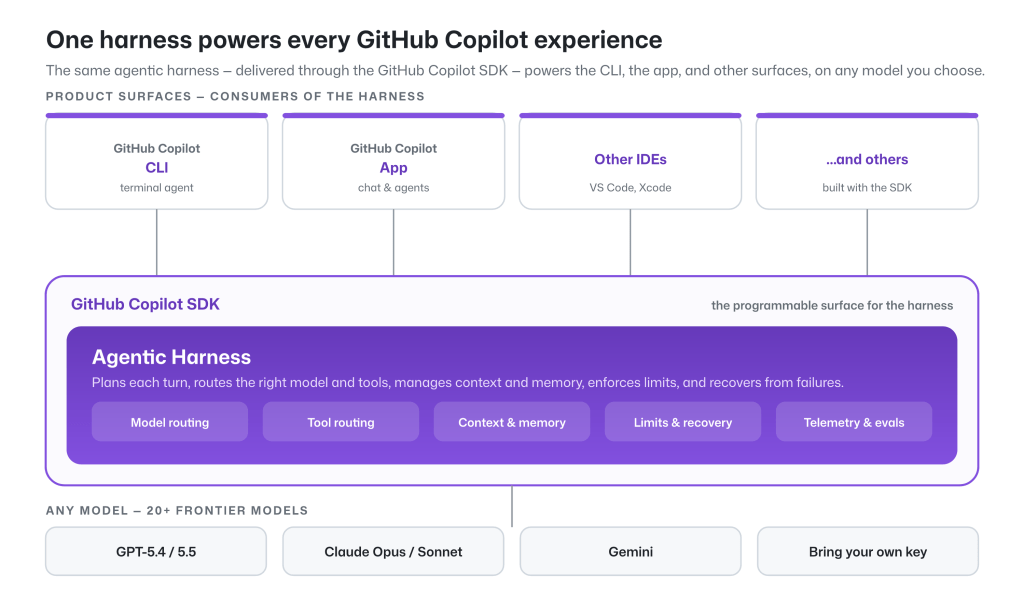
モデルが生み出す生来の知能を提供する一方で、ハネスはその知能をいかに効果的に適用するかを形作ります。GitHub Copilot エージェント型ハネスは、GitHub Copilot CLI、GitHub Copilot アプリ、Copilot コードレビュー、および GitHub および Microsoft 全体にわたる多様なエクスペリエンスを支える GitHub Copilot SDK の単一の共有コンポーネントです。このハネスを改善すれば、すべての表面(インターフェースや機能)が恩恵を受けます。
 imageGitHub Copilot エージェント型ハネスは、GitHub Copilot のエクスペリエンスを支えています。
imageGitHub Copilot エージェント型ハネスは、GitHub Copilot のエクスペリエンスを支えています。
ツール、コンテキスト、ワークフローはハネスによってオーケストレーションされます。ハネスは開発者にとって高速で、トークン効率的かつ予測可能であるべきです。まさにそれが、私たちが GitHub Copilot のエージェント型ハネスに設計した目的です。
本稿では、多様なエージェント型ソフトウェアエンジニアリングタスクにわたる GitHub Copilot エージェント型ハネスの効率性とパフォーマンスに関するデータをご紹介します。
さらに進化する最適化について
各トークンを最大限に活用するための最新コンテキスト処理およびモデルルーティングの最適化については、こちらをご覧ください。また、委譲(デレゲーション)に関する実験と最適化、そしてそれが現在開発者にどのような恩恵をもたらすかについても詳しく共有しています。
ベンチマークを用いた反復プロセス
GitHub Copilot エージェントハッチの能力と効率性は、公開および社内開発ベンチマークを組み合わせて継続的に評価されています。私たちの公開ベンチマークには業界標準が含まれており、いくつかの社内ベンチマークは GitHub および Microsoft 内の大規模コードベースから派生しています。これに実世界での指標やオンライン実験を組み合わせることで、制御された環境におけるハッチのパフォーマンスと、エージェントによる問題解決およびタスク完了への実践的な影響を理解できるようにしています。
GitHub Copilot のハッチとモデルプロバイダーのハッチのパフォーマンスを比較評価する際、可能な限り多くの変数を統制します。具体的には、同じモデル、同じベンチマークタスク(文脈ウィンドウで正規化)、推論努力量、ツール選択、および MCP サーバーを使用します。
以下に、4 つの主要モデル(Claude Sonnet 4.6、Claude Opus 4.7、GPT‑5.4、GPT‑5.5)にわたる、追跡しているベンチマークの一部における最新の結果を報告します。
ベンチドメイン:目的
SWE-bench Verified: オープンソースの Python リポジトリから検証された 500 のバグ修正タスク。コーディングエージェントのための確立された業界標準ベンチマーク。
SWE-bench Pro: より困難で多段階のエンジニアリングタスク。より深い推論と広範なコード変更を必要とする。複雑な実世界のソフトウェアエンジニアリング作業をよりよく反映する。
SkillsBench: エージェントがスキルをタスク解決にどの程度効果的に使用するか。拡張性とスキルの使用、トリガー能力を評価する。
TerminalBench Agent performance on terminal-based tasks Measures effectiveness in command-line workflows used by developers
Win-Hill Internal benchmark for tasks running inside Windows containers Validates that performance generalizes across operating systems and environments
Throughout, we compare GitHub Copilot CLI against the model-vendor harnesses that ship those models natively: Claude Code for Sonnet 4.6 and Opus 4.7, and Codex CLI for GPT‑5.4 and GPT‑5.5.
Token efficiency
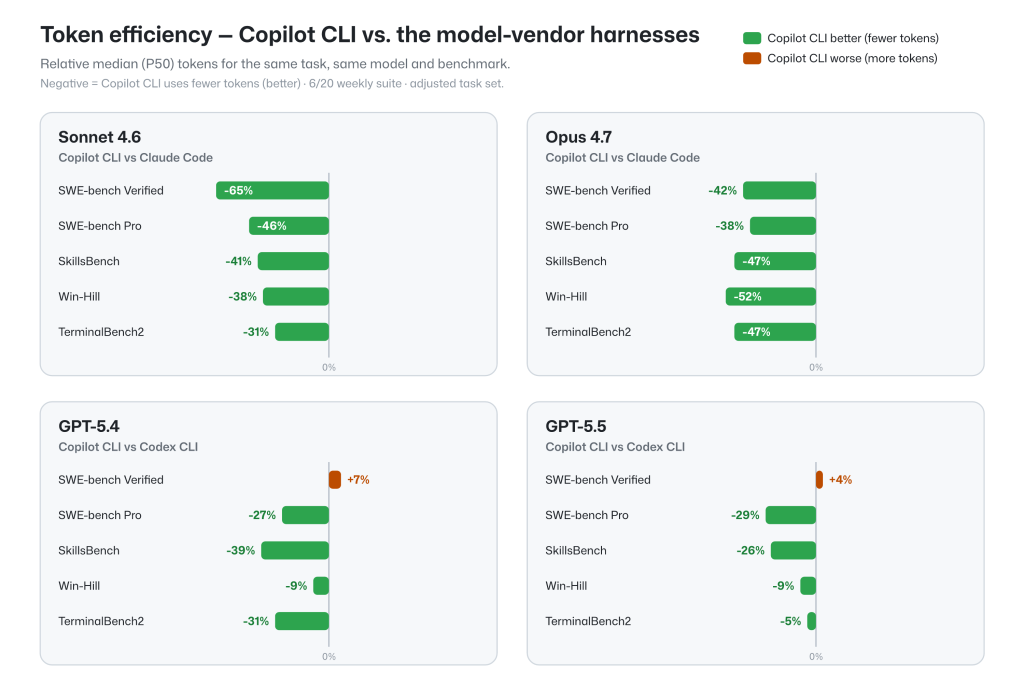
Holding the model and task fixed, across multiple benchmark results, the GitHub Copilot harness achieves task completion rates on par with other model-vendor harnesses, while showing lower token consumption across most configurations.
 imageToken efficiency: GitHub Copilot CLI vs. other model-vendor harnesses
imageToken efficiency: GitHub Copilot CLI vs. other model-vendor harnesses
Task resolution
Token efficiency only matters if the work actually gets done.
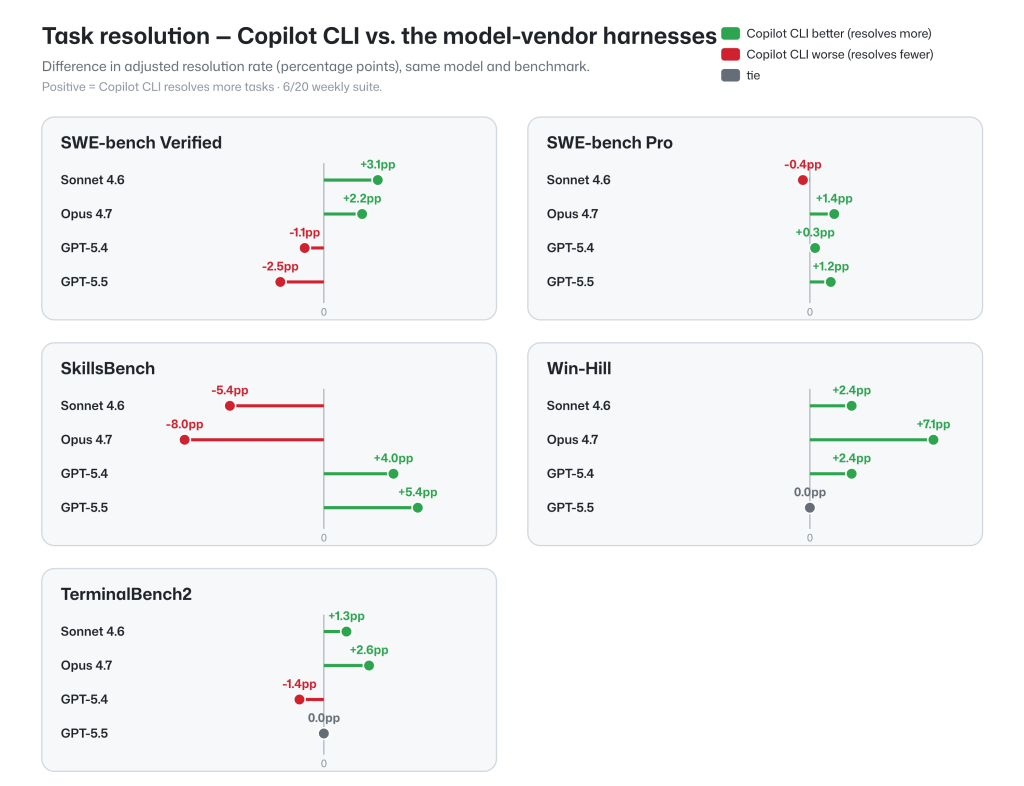
Task resolution rates for the GitHub Copilot agentic harness across these benchmarks are on-par with model-vendor harnesses when used with a fixed model and benchmark task. This ensures that the full potential of the underlying model is available, along with multi-model flexibility, token efficiency, and memory and context capabilities.
 imageTask resolution: GitHub Copilot CLI vs. the model-vendor harnesses
imageTask resolution: GitHub Copilot CLI vs. the model-vendor harnesses
これらの結果は、モデルの確率的性質に起因する変動範囲内であれば、どちらの方向への差異も有効な同等性を反映していることを示しており、クロス・ハーン間のパフォーマンスが同等であることを意味します。
TerminalBench: トークン効率性、タスク完了率、および変動
GitHub Copilot エージェント・ハーンのタスク完了率とトークン効率性の継続的な向上のため、私たちは定期的にベンチマーク全体で徹底的な分析を行っています。以下は TerminalBench 2.0 における変動分析の一例であり、これは GitHub Copilot のタスク完了率とトークン効率性における強みを浮き彫りにするだけでなく、このようなベンチマークに内在するランごとの変動も示しています。
 image解決率対タスクあたりのコスト。左上に行くほど優れています:より多くを解決し、より少なく費やす。
image解決率対タスクあたりのコスト。左上に行くほど優れています:より多くを解決し、より少なく費やす。
各マーカーは TerminalBench 2.0 上のエージェントとモデルの構成の一つであり、縦軸に解決率、横軸にタスクあたりのドルコストを示しています。各点周囲の塗りつぶされた楕円形は±1σ(シグマ)のランごとのばらつき範囲を示し、各構成がラン間でどの程度変動するかを表しています。
3 つの点が際立っています:
GitHub Copilot のエージェント型ハルネスは、評価したすべての構成において、タスク完了率とタスクあたりのコストの両面で他のエージェントに匹敵するか、あるいはそれを超えています。ほぼすべてのモデルにおいて、Copilot(紫色)のマーカーとその同モデル競合製品は、両軸上で重なり合う楕円内に位置しており、その差は実行ごとの変動範囲内です。Copilot は、完了率で競合を下回ることもなく、コストでも右側(高コスト)に位置することはありません。
実行ごとのばらつき。各エージェントとモデルの組み合わせを少なくとも 5 回実行しました。楕円はこれらの実行結果の 1σ(標準偏差)の範囲を示しており、チャート上で楕円が狭いほど再現性が高い結果であることを意味し、広い楕円はコストとタスク完了率の両面で実行ごとに結果が大きく変動することを示します。
GitHub Copilot のモデル選択における利点:このグラフは明確なトレードオフを示しています。GPT モデル(左側)は、最低のコストで高い解決能力を提供し、最も価値が高いです。Claude Opus(右上)は、プレミアム価格で最高レベルの解決能力を達成します。GitHub Copilot はこれら両方を提供するため、タスクごとに効率性を優先するか、最高品質を優先するかを選択できます。
一つのハルネス、多数のモデル
GitHub Copilot のエージェント型ハルネスは、GPT、Claude、Gemini、MAI ファミリーにわたる 20 以上の最先端モデルをサポートしており、オープンソースおよびローカルモデルについてはユーザーが自身のキー(API キー)を持参することも可能です。各タスクの機能要件とコストプロファイルに応じて適切なモデルを選択するか、Auto model selection(自動モデル選択)機能に任せて、タスクの意図とモデルの健全性をバランスさせながらトークン効率を最適化させることもできます。
マルチモデル・アーキテクチャは、モデルベンダーのハッチ単体では提供できないハッチレベルの機能も解放します。例えば Rubber Duck では、クロスモデルファミリー批判(cross-model-family critique)を採用しており、あるモデルが別のモデルの成果を検証することで、単一のモデルだけでは達成できない結果の向上を図っています。
結論
ベンチマークは複数のシグナルの一つに過ぎません。私たちは常に、ベンチマーク全体、実世界での使用指標、オンライン実験における品質を改善し続けると同時に、あらゆるトークンを効率的に最大限活用することを目指しています。
GitHub Copilot は、マルチモデル・アーキテクチャを通じて単一のモデルにロックインされることなく、複数の構成においてより少ないトークンで、主要なモデルベンダーのハッチと同等のタスク解決能力を提供します。開発者にとっては、より低いトークンコストで同等のタスク完了が可能となりながら、タスクに最も適したモデルを選択し続けることができます。
実際に試してみましょう
お好みのモデルで GitHub Copilot を試し、毎日実行するタスクで各アプローチを比較し、異なるモデルやエージェント戦略があなたの環境でどのように機能するかを確認してください。
詳細はこちら:
GitHub Copilot CLI
GitHub Copilot app
GitHub Copilot SDK
これらの体験を支えているのは同じエージェント・ハッチです。私たちはその品質、効率性、柔軟性の向上を継続しています。
方法論
比較を可能な限り統制され再現可能にするため、各エージェントをモデル、タスク、環境全体で同等の設定条件下で実行しました。
すべての実行には2時間のタイムアウトが設定されています。すべてのエージェントは非対話型の単一ターンで実行され、ウェブツールは無効化され、すべてのツールが許可されています。
TerminalBench2分析:推論努力を中程度に設定したデフォルト設定が有効化されています(例:Claude Codeではツール検索が有効化され、Copilot CLIはgithub-mcp-serverを使用)。CodexとClaude Codeは、それぞれAnthropicおよびOpenAIのエンドポイントに直接接続します。完全かつ信頼性の高い結果を確保するため、欠落しているデータやインフラ関連の障害については、89のTerminalBench2タスクすべてが結果を生成するまで再実行を行いました。モデルによって生成されたエラーは保持され、分析から除外されることはありませんでした。各モデルは5回の独立した実行で評価され、CopilotはClaude CodeおよびCodexとの比較を可能にするため、2つの別々の評価バッチでテストされました。
すべてのベンチマーク:すべてのエージェント・モデルペアは、同じコンテキストウィンドウサイズ、同じプロンプトトークン制限、推論努力(中程度)、および設定に正規化されています。ツール検索やMCPサーバーは使用されず、ハッチスデフォルトの組み込みツールのみが保持されます。公平な比較を確保するため、インフラ関連の異常やネットワークアクセスの影響はすべてのエージェントでベンチマークから除外されます。実行間の変動性が小規模ベンチマーク(100インスタンス未満)に与える影響を低減するため、5回の独立した実行が行われ、最高スコアの実行結果が報告されます。すべての指標はpass@1として提示されています。これらの正規化により、公的なベンチマーク提出値とは異なる結果となります。公的提出では通常、より高い推論努力や他の調整された設定が使用されるためです。
GitHub Copilot エージェントハッチのモデルおよびタスク間におけるパフォーマンスと効率の評価に関する投稿は、The GitHub Blog で最初に公開されました。
原文を表示
While the model provides the raw intelligence, the harness shapes how effectively that intelligence is applied. The GitHub Copilot agentic harness is a single shared component of the GitHub Copilot SDK, which powers the GitHub Copilot CLI, GitHub Copilot app, and Copilot code review, along with a wide variety of experiences across GitHub and Microsoft. Improve the harness, and every surface benefits.
imageThe GitHub Copilot agentic harness powers GitHub Copilot experiences.
The tools, context, and workflow are orchestrated by the harness. A harness should be fast, token-efficient, and predictable for developers. That’s what we designed GitHub Copilot’s agentic harness to do.
In this post, we’ll present data showing the efficiency and performance of the GitHub Copilot agentic harness across a wide range of agentic software engineering tasks.
More optimizations we are making
Read more about our latest optimizations on context handling and model routing to get the most out of each token. We have also shared more about experiments and optimizations around delegation, and how it benefits developers today.
How we iterate with benchmarks
We continuously evaluate the capability and efficiency of the GitHub Copilot agentic harness through a combination of public and internally developed benchmarks. Our public benchmarks include industry standards, while several internal benchmarks are derived from large codebases inside GitHub and Microsoft. We complement this with real-world metrics and online experiments to ensure we understand the harness’s performance in controlled environments and its practical impact on agentic problem solving and task completion.
We control as many variables as possible to evaluate the performance of GitHub Copilot’s harness compared to the model provider’s harness: use the same model, the same benchmark task, normalized on context window, reasoning efforts, tool selection, and MCP servers.
Below we report our latest results for a subset of the benchmarks we track, across four leading models: Claude Sonnet 4.6, Claude Opus 4.7, GPT‑5.4, and GPT‑5.5:
Benchmark Domain Purpose
SWE-bench Verified 500 human-validated bug-fix tasks from open-source Python repositories Established industry-standard benchmark for coding agents
SWE-bench Pro More difficult, multi-step engineering tasks requiring deeper reasoning and broader code changes Better reflects complex, real-world software engineering work
SkillsBench How effectively an agent uses skills to solve tasks Evaluates extensibility and skill use and triggering capabilities
TerminalBench Agent performance on terminal-based tasks Measures effectiveness in command-line workflows used by developers
Win-Hill Internal benchmark for tasks running inside Windows containers Validates that performance generalizes across operating systems and environments
Throughout, we compare GitHub Copilot CLI against the model-vendor harnesses that ship those models natively: Claude Code for Sonnet 4.6 and Opus 4.7, and Codex CLI for GPT‑5.4 and GPT‑5.5.
Token efficiency
Holding the model and task fixed, across multiple benchmark results, the GitHub Copilot harness achieves task completion rates on par with other model-vendor harnesses, while showing lower token consumption across most configurations.
imageToken efficiency: GitHub Copilot CLI vs. other model-vendor harnesses
Task resolution
Token efficiency only matters if the work actually gets done.
Task resolution rates for the GitHub Copilot agentic harness across these benchmarks are on-par with model-vendor harnesses when used with a fixed model and benchmark task. This ensures that the full potential of the underlying model is available, along with multi-model flexibility, token efficiency, and memory and context capabilities.
imageTask resolution: GitHub Copilot CLI vs. the model-vendor harnesses
These results reflect effective parity, since the differences in either direction are within the variance due to the stochastic nature of the models, making the cross-harness performance on-par.
TerminalBench: Token efficiency, task completion, and variance
To continuously improve the GitHub Copilot agentic harness on task completion and token efficiency, we regularly perform thorough analyses across benchmarks. Below is an example of variance analysis on TerminalBench 2.0, which not only highlights GitHub Copilot’s strength on task completion and token efficiency, but also shows the run-to-run variance intrinsic to this kind of benchmark.
imageResolution rate vs. cost per task. Up and to the left is better: solve more, spend less.
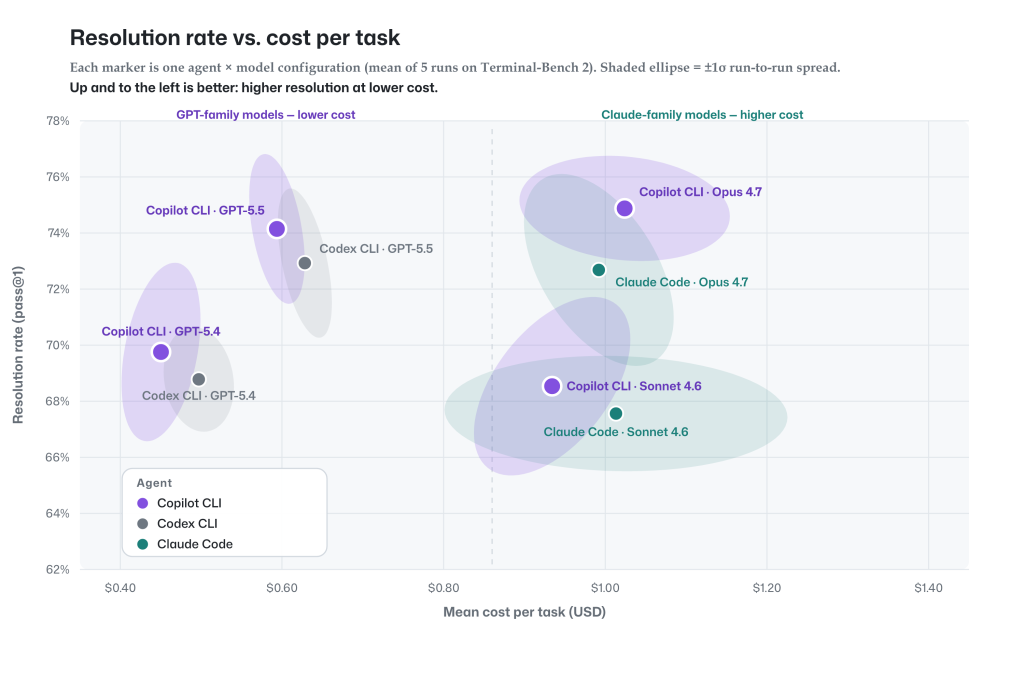
Every marker is one agent-and-model configuration on TerminalBench 2.0, with resolution rate on the vertical axis and dollar cost per task on the horizontal axis. The shaded ellipse around each point shows the ±1σ run-to-run spread, displaying how much each configuration varies between runs.
Three things stand out:
GitHub Copilot’s agentic harness is on par with or ahead of other agents on task completion and cost per task across the configurations we evaluated. Purple (Copilot) markers and their same-model competitors sit within overlapping ellipses on both axes for nearly every model—the differences are inside run-to-run variance. Copilot is never below a competitor on completion or to the right on cost.
Run-to-run variability. We ran each agent-model combination at least five times. The ellipse marks the 1σ spread of those runs; a tighter ellipse in the chart means more reproducible results, while a wider one shows results swinging further from run to run on both cost and task completion.
The benefit of GitHub Copilot’s model choice: The chart shows a real trade-off: GPT models (left) deliver the best value: strong resolution at the lowest cost. Claude Opus (upper right) reaches the highest resolution at a premium. GitHub Copilot puts both on the table, so you can pick efficiency or peak quality per task.
One harness, many models
The GitHub Copilot agentic harness supports 20+ frontier models across the GPT, Claude, Gemini, and MAI families, plus bring your own key for open‑source and local models. You can choose the right model for the capability and cost profile of each task, or let Auto model selection choose for you, balancing task intent and model health to optimize token efficiency.
A multi‑model architecture also unlocks harness‑level capabilities a model-vendor harness simply can’t offer. Rubber Duck, for example, uses cross‑model‑family critique, where one model reviews another’s work to improve outcomes beyond what any single model produces alone.
Conclusion
Benchmarks are just one signal among several. We are constantly working to improve quality across benchmarks, real-world usage metrics, and online experiments, while pushing to efficiently make the most out of every token.
GitHub Copilot delivers task‑resolution on par with leading model-vendor harnesses while using fewer tokens across several configurations, without locking you into a single model through its multi‑model architecture. For developers, this means you can get comparable task completion with lower token cost, while still choosing the model that best fits your task.
Try it yourself
Try GitHub Copilot with the model of your choice, compare approaches on the tasks you run every day, and see how different models and agent strategies perform in your environment.
Learn more about:
GitHub Copilot CLI
GitHub Copilot app
GitHub Copilot SDK
The same agentic harness powers these experience. We’re continuing to improve its quality, efficiency, and flexibility.
Methodology
To make the comparison as controlled and reproducible as possible, we run each agent with equivalent settings across models, tasks, and environments.
All runs have a two-hour timeout. All agents run non-interactively single-turn, with web-tools disabled, and all tools allowed.
TerminalBench2 analysis: Default settings enabled for agents with reasoning effort set to medium (e.g. tool search is enabled for Claude Code and Copilot CLI uses github-mcp-server). Codex and Claude Code use direct Anthropic and OpenAI endpoints. To ensure complete and reliable results, any missing data or infrastructure-related failures were re-run until all 89 TerminalBench2 tasks produced results. Model-generated errors were retained and not excluded from the analysis. Each model was evaluated across five independent runs, and Copilot was tested in two separate evaluation batches to enable comparison with Claude Code and Codex.
All benchmarks: All agent model pairs normalized to same context window size, same prompt token limits, reasoning effort (medium) and settings—no tool search, no MCP servers. Keeping the harness’s default built-in tools. Infrastructure-related anomalies and network-access effects are excluded across all agents for a benchmark to ensure fair comparisons. To reduce the impact of run-to-run variability on smaller benchmarks (<100 instances), five independent runs were conducted, and the best scored run is reported. All metrics are presented as pass@1. These normalizations mean results differ from public benchmark submissions, which typically use higher reasoning effort and other tuned settings.
The post Evaluating performance and efficiency of the GitHub Copilot agentic harness across models and tasks appeared first on The GitHub Blog.
関連記事
ホワイトハウス、安全性の懸念から OpenAI の新モデルリリースを徐々に行うよう要請
ホワイトハウスは、安全性への懸念から、OpenAI が開発中の新モデルのリリースペースを緩めるよう同社に要請した。
AI と法的責任
ブルース・シュナイアーは、ドイツの裁判所がグーグルの AI 概要における誤りについて同社に責任を課した判決を引用し、AI エージェントは導入する個人または組織の代理人であり、その結果に対する責任も負うべきだと論じています。
トランプ政権の要請により OpenAI、GPT-5.6 の公開を延期へ
セキュリティへの懸念からトランプ政権が要請し、OpenAI は CEO サム・アルトマンが従業員に伝えた通り、次期大型モデル GPT-5.6 の完全公開を延期し、限定的なプレビュー形式での提供を検討している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み