Rocket CloseがAmazon BedrockとAmazon Textractで住宅ローン書類処理を変革
Rocket CloseはAmazon TextractとAmazon Bedrockを活用した文書処理自動化ソリューションを開発し、住宅ローン書類の処理時間を15倍高速化し、年間50万件以上の処理に対応できるようになった。
キーポイント
業務効率の劇的改善
手動処理では1パッケージあたり平均10時間かかっていた住宅ローン書類処理を、自動化ソリューションにより15倍高速化した。
AWS生成AI技術の実用化
Amazon TextractによるOCR処理とAmazon Bedrockの基盤モデルを組み合わせ、文書のセグメンテーション、分類、フィールド抽出で90%の精度を達成した。
大規模処理への対応
1日2,000パッケージ(各平均75ページ)という膨大な文書処理を、年間50万件以上の規模に拡張可能なシステムとして構築した。
業界への影響
住宅ローン業界における文書集約型プロセスの変革事例として、生成AIの実用的な応用可能性を示した。
影響分析・編集コメントを表示
影響分析
この事例は、生成AIが特定業界(住宅ローン)の具体的な業務課題を解決する実用的な応用を示しており、AI技術の産業への浸透が進んでいることを示唆している。特に、大量の構造化・非構造化文書処理が必要な金融業界において、自動化ソリューションの導入モデルとして参考になる。
編集コメント
PR要素を含むが、具体的な数値(15倍高速化、90%精度、年間50万件処理)と実用的な課題解決事例として、AI技術の実用化段階を示す重要なケーススタディと言える。
本記事は、Rocket Closeのジェレミー・リトルとクリス・デイによって共同で執筆されました。
Detroitを拠点とするタイトルおよびアプレイザル管理会社のRocket Closeは、Rocket Companiesの一環として、時間のかかる手作業のプロセスを効率的な自動化ソリューションへと変革することで、モルゲージ文書の処理を強化しました。1日あたり約2,000の抽象パッケージファイルを処理し、各ファイルは平均75ページに及ぶ同社にとって、手動での抽出にはパッケージあたり平均10時間を要するという重大な運用上の課題があり、リソース配分の負担とワークフローのボトルネックを大幅に生じていました。
AWSジェネレーティブAIイノベーションセンター(GenAIIC)との戦略的パートナーシップを通じて、Rocket Closeは処理時間を大幅に短縮し、プロセスを15倍高速化したインテリジェントなドキュメント処理ソリューションを開発しました。OCR処理にはAmazon Textractを、ファウンデーションモデル(FMs: Foundation Models)にはAmazon Bedrockを使用するこのソリューションは、ドキュメントのセグメンテーション、分類、およびフィールド抽出において90%という高い総合精度を実現しています。Amazon Bedrockは、サーバーレスでより安全な方法でジェネレーティブAIアプリケーションを構築およびスケーリングできるフルマネージドサービスです。複数のAI企業からの主要なFMsにアクセスするための単一APIを提供します。年間50万件以上のドキュメントに対応できるスケーラビリティを備え、この変革によりRocket Closeはモーゲージ業界における技術革新の最前線に位置し、より迅速な顧客サービスと持続可能なビジネス成長を支えています。
この投稿では、このソリューションが開発および実装された方法を探り、ジェネレーティブAIがモーゲージ業界のドキュメント集約型プロセスを変革する方法を示します。
大規模な手動処理の課題
Rocket Closeは、タイトルおよび鑑定管理サービスの一環として、複雑な文書の大量処理を行っています。Rocket Closeは、テクノロジー駆動型のソリューションを通じて複雑なプロセスを簡素化し、クライアントが住宅所有と経済的自由という夢を実現するのを支援することに専念しています。広範なデータポイントを検証することで、Rocket Closeは融資に関連するリスクを迅速かつ正確に評価し、より情報に基づいた融資判断を行い、クライアントが必要な資金調達を提供することができます。しかし、Rocket Closeは成長と収益性を脅かす重大なボトルジネックに直面していました。
- 過大な処理量 – 毎日2,000件の抽象パッケージ(要約書セット)を処理し、各パッケージは平均75ページに及ぶ
- 時間がかかるワークフロー – 最近の処理量増加により、パッケージごとに10時間を要し、実際の手動処理作業はパッケージあたり約30分と見積もられている
- 財務への影響 – ファイルごとのコストが莫大であり、複雑なケースではさらに高額となり、年間処理コストは数百万ドルに達する
- スケーラビリティの限界 – 手動プロセスは増大する需要に追いつくことができなかった
- 品質への懸念 – データ抽出における人間のミスや不整合
毎日約1,000時間の手動処理作業が必要となる中、Rocket Closeは正確性を維持しつつ処理時間を劇的に削減できるソリューションを必要としていました。
抽象文書パッケージの理解
抽象文書パッケージは、不動産所有権および取引に関連する法的文書の包括的なコレクションです。これらのパッケージには通常、50〜100ページにわたるさまざまな種類の文書が含まれており、一貫性のないフォーマット、ばらつきのある品質、複雑な構造を伴うことが多く、これらが束ねられています。各パッケージは、不動産所有権、留保権(lien)、抵当権、法的ステータスに関する重要な情報を抽出するために徹底的な検討が必要です。これらのパッケージは多様な性質のため、自動化された処理において特有の課題を提示します。単一のパッケージ内の文書には、タイプされたテキスト、レイアウト、手書きのメモ、表、フォーム、署名、印鑑などが含まれる可能性があります。さらに、特定の文書の順序や存在はパッケージ間で大きく異なる場合があり、高度な文書セグメンテーション(分割)および分類機能が必要です。
このソリューションは、いくつかの主要カテゴリに属する60以上の異なる文書クラスを処理します。
- 抵当権関連文書:これには、住宅ローン契約書、信託証書、担保設定書類など、主要な抵当権設定文書が含まれます。これらの文書は不動産を担保とするローンの条件を定め、借入金額、金利、返済期間など重要な情報を記載しています。
- 所有権移転履歴文書:このカテゴリには、保証付譲渡証書(warranty deed)、放棄譲渡証書(quitclaim deed)、特別保証付譲渡証書(special warranty deed)など、さまざまな種類の譲渡証書が含まれます。これらは不動産所有権の歴史的な移転を記録する文書であり、適正な所有権を確認するために不可欠です。
- 裁判所判決文書:これには、民事判決、判決抄録、および不動産所有権に影響を与える可能性のある各種の留保通知(notice of lien)が含まれます。これらの文書は、所有権の状態に影響を及ぼす可能性のある不動産所有者に対する法的請求を記録します。
- 税務関連文書:このカテゴリには、連邦税留保通知(notice of federal tax lien)や州税留保通知(notice of state tax lien)など、未納税金に対する潜在的な請求を表す税務関連の届出書類が含まれます。
- 法的文書:これには、係争中の訴訟、抵当権実行の訴状、相続人の身分証明書(affidavits of heirship)、および不動産所有権の状態に影響を与える可能性のあるその他の裁判所文書など、さまざまな法的届出書類が含まれます。
ソリューションアーキテクチャ
AWS GenAIIC チームと Rocket Close チームは共同で、生成 AI の機能を活用して抽象的なパッケージ処理ワークフローを自動化するソリューションを開発しました。以下の図は、Amazon Textract を OCR 処理に使用し、Amazon Bedrock を知能情報抽出に使用する二段階プロセスの全体ソリューションパイプラインを示しています。
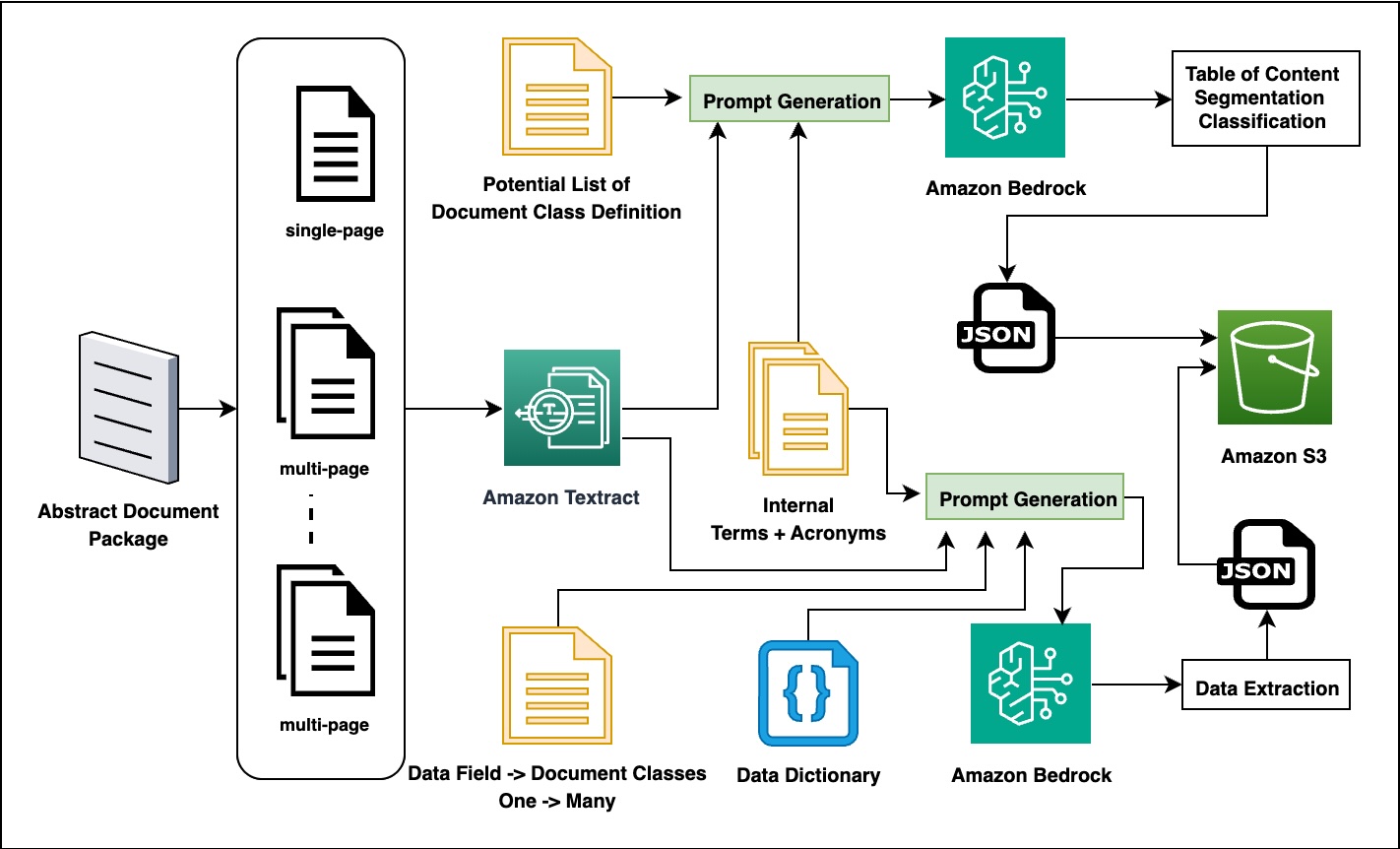
パイプラインの第一段階では、Amazon Textract を使用してドキュメント画像を機械可読なテキストに変換します。システムは、レイアウト、テーブル、フォーム、署名を検出しながらドキュメントの構造的階層を保持する高度な OCR 機能を通じて PDF ドキュメントを処理します。抽出されたコンテンツは、人間の可読性と機械による処理可能性の両方を維持したマークダウン形式に変換され、後続の処理のために Amazon Simple Storage Service (Amazon S3) およびローカルに保存されます。
第2段階では、Amazon BedrockのFMs(Foundation Models:基盤モデル)を使用して包括的な文書分析とデータ抽出を行います。システムは、まずドメイン固有の知識リソースを用いて文書の内容を分析し、目次を作成することで文書の分類とセグメンテーションを行います。その後、文書の種類に基づき、ドメイン知識を組み合わせた専門的なプロンプトを用いて関連するデータフィールドを抽出します。抽出された情報は、他のシステムとのシームレスな統合のために標準化されたJSON形式に変換されます。
このソリューションの有効性は、いくつかの革新的な技術的アプローチに依存しています。
- 高度なプロンプトエンジニアリング – チームは、異なる文書処理タスクに対して大規模言語モデル(LLM)の動作を戦略的に誘導する専門的なプロンプトを開発しました。文書分析用プロンプトは、コンテンツと分類ガイドラインを組み合わせることで、正確な文書分割を可能にします。また、情報抽出用プロンプトにはフィールド定義とドメイン知識を組み込み、文書内の特定のデータ要素をターゲットにしています。これらの慎重に設計されたプロンプトには、例示的なサンプルと正確な書式指定の指示が含まれており、さまざまな文書タイプやフォーマットにわたって一貫性のある構造化された出力を生成することを可能にしています。
- ドメイン固有の知識統合 – システムは、複数の補完的なアプローチを通じて抽出精度を向上させるために、業界固有の知識を組み込んでいます。データフィールドから文書クラスへのマッピングにより、システムが各文書タイプにおいて適切な情報をターゲットにすることが保証され、包括的なデータ辞書は抽出のための明確なフィールド定義と期待されるフォーマットを提供します。住宅ローン業界の用語集は、金融分野で一般的な専門用語や略語を正確に解釈するのを支援します。このドメイン知識は処理中にプロンプトに動的に組み込まれ、複雑な文書から正確な情報を抽出するシステムの能力を大幅に向上させます。
- ドメイン認識型評価フレームワーク – プロジェクトの成功は、基本的な精度指標を超えた洗練された評価システムに依存していました。このソリューションには、異なるフィールドタイプに合わせて調整された指標を含む包括的なフレームワークが含まれており、住宅ローン領域全体にわたる抽出品質の正確な評価を可能にしています。
チームは、厳密な文字列マッチングとあいまいな文字列マッチング、構成可能な許容範囲を持つ数値比較、および州コード、譲渡証書の種類、取引の種類、文書参照に関する住宅ローン固有の指標など、専門的なアプローチを実装しました。ドメイン固有のマッチング関数は専門コンテンツの変動性を処理し、フィールドタイプ固有の指標は適切な比較方法を適用します。
結果と影響
概念実証(Proof of Concept)は、期待を上回る強力な結果を示し、Rocket Close の文書処理ニーズに対するこのアプローチの有効性を裏付けました。
このソリューションは、複数の評価ラウンドにわたる厳格なパフォーマンステストを受けました。最初の検証フェーズでは、655 のデータフィールドを含む 28 のランダムなサンプルをテストし、全体の精度は 90.53% を達成しました。この初期の成功は、アプローチの実現可能性を示し、より広範なテストへ進むための自信をもたらしました。
2 回目のラウンドは、正解データ(Ground Truth Data)と 1:1 のマッピングを持つ 52 のサンプルを用いたターゲットテストに焦点を当て、計 2,249 のデータフィールドを対象としました。このフェーズにおいてシステムは 91.28% の精度を達成し、異なる文書タイプにわたって一貫したパフォーマンスを確認し、検証済みのベースラインデータに対して抽出方法論を検証しました。このフェーズは、Amazon Textract とカスタム処理パイプラインが多様な文書フォーマットを扱える能力に対する信頼を確立する上で特に重要でした。
最終的な評価では、44,000 を超えるデータフィールドを含む 1,792 のサンプルを処理する大規模な検証が行われ、全体の精度は 89.71% を達成しました。この広範なテストにより、Rocket Close の文書ボリュームの代表的なサンプル全体において、ソリューションのスケーラビリティと信頼性が検証されました。これにより、AWS インフラストラクチャが、多様な文書の大量バッチを並列処理する場合でも高い精度を維持することが示されました。
このソリューションは AWS を活用しており、複数の側面から大きなビジネス価値を提供します。自動化されたシステムにより、パッケージあたりの処理時間が 30 分から 2 分未満に短縮され、処理速度は 15 倍向上しました。この高速化により、顧客サービスの迅速化とスループットの向上が実現します。財務面では、このソリューションは処理コストを大幅に削減し、ファイルごとに顕著な節約を実現します。毎日数千件(約 2,000 ファイル)のファイルを処理しているため、これは企業規模での年間節約可能性を意味します。また、自動化されたシステムは品質と一貫性を向上させ、全体の精度を 90% に維持しつつ人的エラーを削減し、出力フォーマットを標準化します。この一貫性は下流プロセスと意思決定を改善し、ビジネス運用のための信頼性の高いデータを可能にします。さらに、クラウドベースのアーキテクチャは、人的資源の比例増加なしに増大する文書量に対応することでスケーラビリティを向上させ、線形コストの増加なしにビジネス成長をサポートします。このシステムは年間 50 万件以上の文書に対応できるよう設計されており、ピーク処理期間中に自動的にスケールする能力を備え、インフラストラクチャの制約なしに Rocket Close の将来の拡大に対応しています。
教訓
概念実証(Proof of Concept)の取り組みにより、AWS 上での同様の文書処理実装を導くことができる、いくつかの貴重な洞察が明らかになりました。
ドメイン知識を組み込んだ慎重に設計されたプロンプトは抽出精度を大幅に向上させることが証明され、プロンプトエンジニアリングが極めて重要であることが示されました。チームは、ドキュメントの内容、分類ガイドライン、およびドメイン固有の知識を組み合わせる専門的なプロンプトを開発しました。
このユースケースにおいて、2段階のパイプラインアーキテクチャは高い有効性を示しました。OCR(光学文字認識)とLLM(大規模言語モデル)の処理を分離することで、各ステージの最適化が可能になります。Amazon Textractは、構造的な情報を保持しつつ、さまざまな形式のドキュメントからテキストを抽出するという複雑なタスクを担当し、Amazon Bedrock(AnthropicのClaudeを使用)はコンテンツの理解と関連情報の抽出に焦点を当てます。
ドメイン固有の知識の統合は、もう一つの主要な成功要因として浮上しました。住宅ローン特有の用語やドキュメント理解を組み込むことで、結果が大幅に向上します。本ソリューションは、データ辞書、用語集、およびドキュメントクラスの定義を使用して、抽出精度の向上を支援しています。
本プロジェクトでは、評価の複雑さが重要な検討事項であることも強調されました。ドメインを考慮した洗練された評価指標を開発することは、パフォーマンスを正確に測定するために不可欠です。この評価フレームワークは、州コードの一致、譲渡証書の種類の一致、取引種類のマッチングなど、異なるフィールドタイプに特化した専門的な指標を採用しています。
最後に、スケーラビリティの考慮事項も初期設計段階から極めて重要であることが証明されました。このソリューションのアーキテクチャは、最初から大量のドキュメントを効率的に処理できるように設計する必要があります。Amazon Textract と Amazon Bedrock を用いた二段階パイプラインのアプローチは、必要なスケーラビリティを提供するのに役立ちます。
今後の展望
成功した概念実証(Proof of Concept、POC)に続き、Rocket Close は本番環境での実装へ進む準備が整いました。
次のフェーズでは、エンタープライズ規模のドキュメント処理を扱えるコンテナ化されたアーキテクチャを用いて、POC から本番デプロイメントへ移行します。チームは抽出精度を時間とともに向上させるフィードバックループを作成し、継続的な改善プロセスを確立する計画です。この反復的なアプローチにより、システムは処理結果から学習し、進化するドキュメントのパターンに適応することができます。
長期的な成功にとって重要な考慮事項は、モデル更新戦略の開発です。Rocket Close は、Amazon Bedrock から新しいバージョンの LLM(Large Language Model)が利用可能になるたびに LLM モデルを更新する戦略を作成し、最新の言語モデルの機能の進歩からソリューションが恩恵を受けるようにします。
最後に、実証済みのアプローチは、初期の範囲を超えた追加ワークフローへ拡大されます。Rocket Close は、このソリューションをローンおよび住宅ローンの完済処理、購入契約の処理、タイトルクリアランス(所有権確認)ドキュメントに適用する計画であり、自動化されたドキュメント処理の恩恵をより多くの業務領域へ広げていきます。
結論
Rocket CloseとAWSジェネレーティブAIイノベーションセンターの協業は、文書処理が集中する業界におけるジェネレーティブAI(生成AI)の革新的な可能性を示しています。抽象パッケージ処理という複雑なタスクを自動化することで、Rocket Closeは運用効率の大幅な向上、コスト削減、そして拡張性の改善を実現する立場を確立しました。このソリューションは90%という高い総合精度と、処理時間を数時間から数分に劇的に短縮した実績を誇り、ジェネレーティブAIがモーゲージおよびタイトル業界における現実的なビジネス課題をどのように解決し得るかを示しています。
Rocket Closeが本番環境への実装へ向けて進むにつれて、この概念実証(Proof of Concept)の段階で確立された基盤は、文書処理ワークフロー全体における継続的なイノベーションとプロセス最適化を可能にします。
著者について

Jeremy Little
Jeremy LittleはRocket Closeのシニアソリューションアーキテクト(上級ソリューションアーキテクト)です。彼は、モーゲージサービス業界における運用効率の向上と顧客体験の改善を目的とした技術ソリューションの設計および実装 overseeing を担当しています。

Chris Day
Chris DayはRocket Closeのエンジニアリング担当副社長です。彼は、タイトルおよび評価管理プロセスを効率化する技術ソリューションの開発と実装を担当するエンジニアリングチームを率いています。

Sirajus Salekin
Sirajus SalekinはAWSジェネレーティブAIイノベーションセンターの応用科学者です。彼は、さまざまな業界の企業顧客向けに機械学習およびジェネレーティブAIソリューションの開発を専門としています。

Ahsan Ali
Ahsan AliはAWSジェネレーティブAIイノベーションセンターのシニア応用科学者です。彼は、複雑なビジネス問題を解決するために機械学習およびジェネレーティブAIソリューションの実装に注力しています。

Ujwala Bitla
Ujwala BitlaはAWSジェネレーティブAIイノベーションセンターのディープラーニングアーキテクトです。彼女は企業顧客向けにスケーラブルなAIアーキテクチャの設計を行っています。

Sandy Farr
Sandy Farr は、AWS 生成 AI イノベーションセンターの応用科学マネージャーです。彼女は AWS の顧客向けに革新的な生成 AI ソリューションを開発するチームを率いています。
原文を表示
*This post is cowritten by Jeremy Little and Chris Day from Rocket Close.*
Rocket Close, a Detroit-based title and appraisal management company within the Rocket Companies environment, has enhanced mortgage document processing by transforming a time-consuming manual process into an efficient automated solution. Processing approximately 2,000 abstract package files daily, with each file averaging 75 pages, the company faced a major operational challenge: manual extraction took on average 10 hours per package, creating considerable resource allocation burdens and workflow bottlenecks.
Through a strategic partnership with the AWS Generative AI Innovation Center (GenAIIC), Rocket Close developed an intelligent document processing solution that has significantly reduced processing time, making the process 15 times faster. The solution, which uses Amazon Textract for OCR processing and Amazon Bedrock for foundation models (FMs), achieves a strong 90% overall accuracy in document segmentation, classification, and field extraction. Amazon Bedrock is a fully managed service that provides a serverless and more secure way to build and scale generative AI applications. It offers a single API to access a choice of leading FMs from various AI companies. Designed to scale to over 500,000 documents annually, this transformation positions Rocket Close at the forefront of technological innovation in the mortgage industry, supporting faster customer service and sustainable business growth.
This post explores how this solution was developed and implemented, demonstrating how generative AI can transform document-intensive processes in the mortgage industry.
Challenges of manual processing at scale
Rocket Close processes a high volume of complex documentation as part of its title and appraisal management services. Rocket Close is dedicated to helping clients realize their dream of homeownership and financial freedom by making complex processes simpler through technology-driven solutions. By analyzing a wide range of data points, Rocket Close can quickly and accurately assess the risk associated with a loan, so they can make more informed lending decisions and get their clients the financing they need.Rocket Close faced a critical bottleneck that threatened their growth and profitability:
- Volume overload – 2,000 abstract packages daily, each averaging 75 pages
- Time-intensive workflow – 10 hours per package due to recent volume spikes, with an estimated 30 minutes of actual manual processing effort per package
- Financial impact – Considerable costs per file, with complex cases resulting in even higher expenses, totaling millions in annual processing costs
- Scalability limits – Manual processes couldn’t keep pace with growing demand
- Quality concerns – Human error and inconsistencies in data extraction
With approximately 1,000 hours of manual processing effort required daily, Rocket Close needed a solution that could maintain accuracy while dramatically reducing processing time.
Understanding abstract document packages
Abstract document packages are comprehensive collections of legal documents related to property ownership and transactions. These packages typically contain 50–100 pages of various document types bundled together, often with inconsistent formatting, varying quality, and complex structures. Each package requires thorough examination to extract critical information about property ownership, liens, mortgages, and legal status. The packages present unique challenges for automated processing due to their heterogeneous nature. Documents within a single package might include typed texts, layouts, handwritten notes, tables, forms, signatures, and stamps. Additionally, the ordering and presence of specific documents can vary significantly between packages, requiring sophisticated document segmentation and classification capabilities.
The solution handles over 60 different document classes that fall into several major categories:
- Mortgage documents – These include primary mortgage instruments such as mortgage agreements, deeds of trust, and security instruments. These documents establish the terms of loans secured by real property and contain critical information about loan amounts, interest rates, and repayment terms.
- Chain of title documents – This category encompasses various deed types (warranty deed, quitclaim deed, special warranty deed) that document the historical transfers of property ownership. These documents establish the legal chain of title and are essential for verifying clean ownership.
- Judgment documents – These include civil judgments, abstracts of judgment, and various notices of lien that might affect property ownership. These documents record legal claims against property owners that might impact title status.
- Tax documents – This category includes tax-related filings such as notice of federal tax lien and notice of state tax lien that represent potential claims against the property for unpaid taxes.
- Legal documents – These encompass various legal filings, including pending lawsuits, complaints for foreclosure, affidavits of heirship, and other court documents that might affect property ownership status.
Solution architecture
The AWS GenAIIC and Rocket Close teams collaboratively developed a solution that uses generative AI capabilities to automate the abstract package processing workflow. The following diagram shows the overall solution pipeline of the two-stage process using Amazon Textract for OCR processing and Amazon Bedrock for intelligent information extraction.
The first stage of the pipeline uses Amazon Textract to convert document images into machine-readable text. The system processes PDF documents through advanced OCR features that detect layout, tables, forms, and signatures while preserving the document’s structural hierarchy. The extracted content is then converted to markdown format, maintaining both human readability and machine processability, and stored in Amazon Simple Storage Service (Amazon S3) and locally for further processing.
The second stage uses Amazon Bedrock FMs to perform comprehensive document analysis and data extraction. The system first classifies and segments documents by analyzing their content and creating a table of contents, using domain-specific knowledge resources. Then, based on the document type, it extracts relevant data fields using specialized prompts combined with domain knowledge. The extracted information is converted into standardized JSON format for seamless integration with other systems.
The solution’s effectiveness relies on several innovative technical approaches:
- Advanced prompt engineering – The team developed specialized prompts that strategically guide the behavior of the large language model (LLM) for different document processing tasks. Document analysis prompts combine content with classification guidelines to facilitate accurate document segmentation, and information extraction prompts incorporate field definitions and domain knowledge to target specific data elements within documents. These carefully crafted prompts include illustrative examples and precise formatting instructions that enable the model to produce consistent, structured outputs across various document types and formats.
- Domain-specific knowledge integration – The system incorporates industry-specific knowledge to help enhance extraction accuracy through several complementary approaches. A data field to document class mapping makes sure the system targets the appropriate information in each document type, and comprehensive data dictionaries provide clear field definitions and expected formats for extraction. Mortgage industry glossaries help the system accurately interpret specialized terminology and acronyms common in the financial domain. This domain knowledge is dynamically incorporated into prompts during processing, significantly improving the system’s ability to extract accurate information from complex documents.
- Domain-aware evaluation framework – The project’s success hinged on a sophisticated evaluation system that used more than basic accuracy metrics. The solution includes a comprehensive framework with metrics tailored to different field types, facilitating accurate assessment of extraction quality across the mortgage domain.
The team implemented specialized approaches including exact and fuzzy string matching, numeric comparisons with configurable tolerance, and mortgage-specific metrics for state codes, deed types, transaction types, and document references. Domain-specific matching functions handle variations in specialized content, and field-type specific metrics apply appropriate comparison methods.
Results and impact
The proof of concept demonstrated strong results that exceeded expectations and validated the approach’s effectiveness for Rocket Close’s document processing needs.
The solution underwent rigorous performance testing across multiple evaluation rounds. The initial validation phase tested 28 random samples containing 655 data fields, achieving an overall accuracy of 90.53%. This early success demonstrated the viability of the approach and provided confidence to proceed with more extensive testing.
The second round focused on targeted testing with 52 samples that had 1:1 mapping to ground truth data, encompassing 2,249 data fields. The system achieved 91.28% accuracy during this phase, confirming consistent performance across different document types and validating the extraction methodology against verified baseline data. This phase was particularly important for establishing confidence in the Amazon Textract and custom processing pipeline’s ability to handle diverse document formats.
The final evaluation involved large-scale verification that processed 1,792 samples containing over 44,000 data fields, achieving an overall accuracy of 89.71%. This extensive testing validated the solution’s scalability and reliability across a representative sample of Rocket Close’s document volume, demonstrating that the AWS infrastructure maintains high accuracy even when processing large batches of diverse documents in parallel.
This solution, powered by AWS, helps deliver considerable business value across multiple dimensions. The automated system reduces processing time from 30 minutes per package to under 2 minutes, making processing 15 times faster. This acceleration enables faster customer service and higher throughput. From a financial perspective, the solution considerably reduces processing costs, delivering notable savings per file. With thousands of files processed daily (approximately 2,000 files), this represents potential annual savings at an enterprise scale. The automated system also delivers enhanced quality and consistency, maintaining 90% overall accuracy while reducing human error and standardizing output formats. This consistency improves downstream processes and decision-making, facilitating reliable data for business operations. Furthermore, the cloud-based architecture provides improved scalability by handling increasing document volumes without proportional staffing increases, supporting business growth without linear cost increases. It’s designed to scale elastically to handle over 500,000 documents annually, with the ability to automatically scale during peak processing periods, positioning Rocket Close for future expansion without infrastructure constraints.
Lessons learned
The proof of concept engagement revealed several valuable insights that can guide similar document processing implementations on AWS.
Prompt engineering proved critical, because carefully crafted prompts that incorporate domain knowledge significantly improve extraction accuracy. The team developed specialized prompts that combine document content with classification guidelines and domain-specific knowledge.
The two-stage pipeline architecture demonstrated strong effectiveness for this use case. Separating OCR and LLM processing allows for better optimization of each stage. Amazon Textract handles the complex task of extracting text from various document formats while preserving structural information, and Amazon Bedrock (using Anthropic’s Claude) focuses on understanding the content and extracting relevant information.
Domain-specific knowledge integration emerged as another key success factor. Incorporating mortgage-specific terminology and document understanding significantly improves results. The solution uses data dictionaries, glossaries, and document class definitions to help enhance extraction accuracy.
The engagement also highlighted evaluation complexity as an important consideration. Developing sophisticated, domain-aware evaluation metrics is essential for accurately measuring performance. The evaluation framework employs specialized metrics tailored to different field types, including state code matching, deed type matching, and transaction type matching.
Finally, scalability considerations proved crucial from the initial design phase. The solution architecture must be designed from the start to handle high volumes of documents efficiently. The two-stage pipeline approach with Amazon Textract and Amazon Bedrock helps provide the necessary scalability.
What’s next
Following the successful proof of concept, Rocket Close is positioned to move forward with production implementation.
The next phase involves moving from POC to production deployment with a containerized architecture that can handle enterprise-scale document processing. The team plans to establish continuous improvement processes by creating feedback loops to improve extraction accuracy over time. This iterative approach allows the system to learn from processing results and adapt to evolving document patterns.
An important consideration for long-term success is developing a model update strategy. Rocket Close will create a strategy for updating LLM models as new versions become available from Amazon Bedrock, making sure the solution benefits from the latest advancements in language model capabilities.
Finally, the proven approach will be expanded to additional workflows beyond the initial scope. Rocket Close plans to apply the solution to loan and mortgage payoff processing, purchase agreement processing, and title clearance documentation, extending the benefits of automated document processing across more of their operations.
Conclusion
The Rocket Close and AWS Generative AI Innovation Center collaboration demonstrates the transformative potential of generative AI in document-intensive industries. By automating the complex task of abstract package processing, Rocket Close has positioned itself to achieve major operational efficiencies, cost savings, and improved scalability. The solution’s strong 90% overall accuracy, combined with the dramatic reduction in processing time from hours to minutes, showcases how generative AI can solve real-world business challenges in the mortgage and title industry.
As Rocket Close moves toward production implementation, the foundation established during this proof of concept will enable continued innovation and process optimization across their document processing workflows.
About the authors
Jeremy Little
Jeremy Little is a Lead Senior Solution Architect at Rocket Close. He designs and oversees the implementation of technical solutions that enhance operational efficiency and improve customer experience in the mortgage services industry.
Chris Day
Chris Day is Vice President of Engineering at Rocket Close. He leads the engineering teams responsible for developing and implementing technology solutions that streamline the title and appraisal management processes.
Sirajus Salekin
Sirajus Salekin is an Applied Scientist at the AWS Generative AI Innovation Center. He specializes in developing machine learning and generative AI solutions for enterprise customers across various industries.
Ahsan Ali
Ahsan Ali is a Senior Applied Scientist at the AWS Generative AI Innovation Center. He focuses on implementing machine learning and generative AI solutions to solve complex business problems.
Ujwala Bitla
Ujwala Bitla is a Deep Learning Architect at the AWS Generative AI Innovation Center. She designs scalable AI architectures for enterprise customers.
Sandy Farr
Sandy Farr is an Applied Science Manager at the AWS Generative AI Innovation Center. She leads teams developing innovative generative AI solutions for AWS customers.
<img loading="lazy" class="alignnone size-full wp-image-125756" src="https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b10
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み