AnthropicのProject Glasswing - Claude Mythosをセキュリティ研究者に限定提供 - は必要だと考える
Anthropic社は、サイバーセキュリティ研究能力が非常に高いとされる最新LLM「Claude Mythos」の一般公開を控え、セキュリティ研究者に限定した「Project Glasswing」を通じて制限付きで提供を開始した。
キーポイント
危険性を理由とした制限付きリリース
Anthropic社は、Claude Mythosが数千もの重大な脆弱性を発見する高いセキュリティ研究能力を持つため、ソフトウェア業界全体が準備する時間が必要として、一般公開を見送り、限定パートナーにのみ提供した。
Project Glasswingの目的
Project Glasswingは、パートナー企業が自社の基幹システムの脆弱性を発見・修正するためにClaude Mythos Previewへのアクセスを提供するプログラムであり、ローカル脆弱性検出やペネトレーションテストなどに活用される。
AIによるセキュリティ研究の質的変化
LinuxカーネルのGreg Kroah-HartmanやcurlのDaniel Stenbergは、AI生成のセキュリティレポートが数か月前の「低品質なもの」から「本物で優れたレポート」へと急速に変化したと指摘している。
業界関係者の懸念の高まり
記事の著者は、信頼できるセキュリティ専門家が現代のLLMの脆弱性研究能力の高さに警鐘を鳴らす事例が増えており、Anthropicの警戒は正当であると評価している。
影響分析・編集コメントを表示
影響分析
この発表は、AIモデルの能力が特定の分野(ここではセキュリティ研究)で社会に重大なリスクをもたらしうる水準に達したことを示す重要なマイルストーンである。これは、AI開発における「責任ある公開」の概念を具体化し、業界全体が強力なAIツールの普及とその悪用防止のバランスをどう取るかという課題に直面していることを浮き彫りにしている。
編集コメント
AIの能力が「危険すぎる」と判断され、開発元自らが公開を制限するという事態は、技術の進歩が新たな倫理的・実用的なジレンマを生み出していることを如実に示している。業界の転換点を報じる重要なニュースだ。
Anthropic は最新のモデル、Claude Mythos(システムカード PDF)を本日公開しませんでした。その代わりに、新たに発表された Project Glasswing の下、非常に限られたプレビューパートナーのセットに対して利用可能にしています。
このモデルは Claude Opus 4.6 に類似した汎用モデルですが、Anthropic はそのサイバーセキュリティ研究能力が十分に強力であるため、ソフトウェア業界全体に準備する時間を必要としていると主張しています。
**
Mythos Preview はすでに数千件の高重大度脆弱性を見つけ出しており、その中には*主要なすべてのオペレーティングシステムおよびウェブブラウザ*に含まれるものもあります。AI の進歩の速度を考慮すれば、そのような能力が普及するまでそう長くはかからず、安全に導入することにコミットしたアクター以外の者によって利用される可能性もあります。
[...]
Project Glasswing のパートナーは、Claude Mythos Preview へのアクセス権を得て、基盤システム(世界の共有サイバー攻撃表面の非常に大きな部分を構成するシステム)における脆弱性や弱点の発見と修正を行います。この作業は、ローカル脆弱性の検出、バイナリのブラックボックステスト、エンドポイントの保護、システムに対するペネトレーションテストなどのタスクに焦点を当てるものと予想されます。
「私たちのモデルは公開するには危険すぎる」と言うのは、新しいモデルの話題性を高める優れた方法ですが、この場合、彼らの慎重さは正当化されるものだと私は予想します。
数日前(先週金曜日)に、このブログで新しいai-security-researchタグを作成しました。これは、現代のLLM(大規模言語モデル)が脆弱性調査においてどれほど優秀になったかについて、信頼性の高いセキュリティ専門家たちが警鐘を鳴らすケースが増えていることを認めるためです。
LinuxカーネルのGreg Kroah-Hartmanより:
数ヶ月前、私たちは「AIスロップ」と呼ばれるものを得ていました。これは明らかに誤っていたり低品質だったりする、AI生成のセキュリティレポートです。それはちょっと面白かったですね。本当に心配することではありませんでした。
1ヶ月前に何かが起こり、世界が一変しました。今では本物のレポートがあります。すべてのオープンソースプロジェクトには、AIを使って作成された本物のレポートがありますが、それらは質が高く、真実です。
オープンソースセキュリティにおけるAIの課題は、AIスロップの津波から、より……単なるセキュリティレポートの津波へと移行しました。スロップは減りましたが、レポートの数は依然として多いです。それらの多くは本当に素晴らしいものです。
今では1日に数時間をこれに費やしています。非常に集中力が必要です。
そしてThomas Ptacekは、AnthropicのNicholas Carliniとのポッドキャスト会話に触発された、Vulnerability Research Is Cookedという投稿を公開しました。
Anthropic は、Glasswing プロジェクトについて説明する 5 分間の トークンヘッド動画 を公開しています。ニコラス・カリーニがそのトークンヘッドの一人として登場し、彼は次のように述べています(強調部分は私によるものです):
「このモデルには、脆弱性を連鎖させる能力があります。つまり、2 つの脆弱性を見つけますが、それぞれ単独ではほとんど成果が得られません。しかし、このモデルは 3 つ、4 つ、あるいは場合によっては 5 つの脆弱性を組み合わせて、複雑な最終的な結果をもたらすエクスプロイトを作成することができます。[...]」
「過去数週間で発見したバグの数は、それまでの人生で発見したバグの合計を超えています。私たちはこのモデルを使用して、多くのオープンソースコードをスキャンしました。最初に狙ったのはオペレーティングシステムでした。なぜなら、それはインターネットインフラの基盤となるコードだからです。OpenBSD については、27 年間存在していたバグを発見しました。これは、任意の OpenBSD サーバーに対していくつかのデータを送信するだけでクラッシュさせることができるものです。Linux については、権限のないユーザーとして、マシン上で特定のバイナリを実行するだけで管理者権限を昇格できる複数の脆弱性を見つけました。これらのバグのそれぞれについて、実際にソフトウェアを運用しているメンテナに通知し、彼らはそれらを修正し、パッチを展開しました。これにより、そのソフトウェアを使用する誰もがこれらの攻撃に対して脆弱ではなくなりました。」
OpenBSD 7.8 のエラー修正ページ で以下の記述を見つけました:
**
025: 信頼性修正:2026年3月25日** *全アーキテクチャ*
無効な SACK オプションを含む TCP パケットにより、カーネルがクラッシュする可能性があります。
OpenBSD の CVS リポジトリの GitHub ミラー(なんとまだ CVS を使用しているようです!)でこの変更を追跡し、git blame を使用して以下のコミットを見つけました:
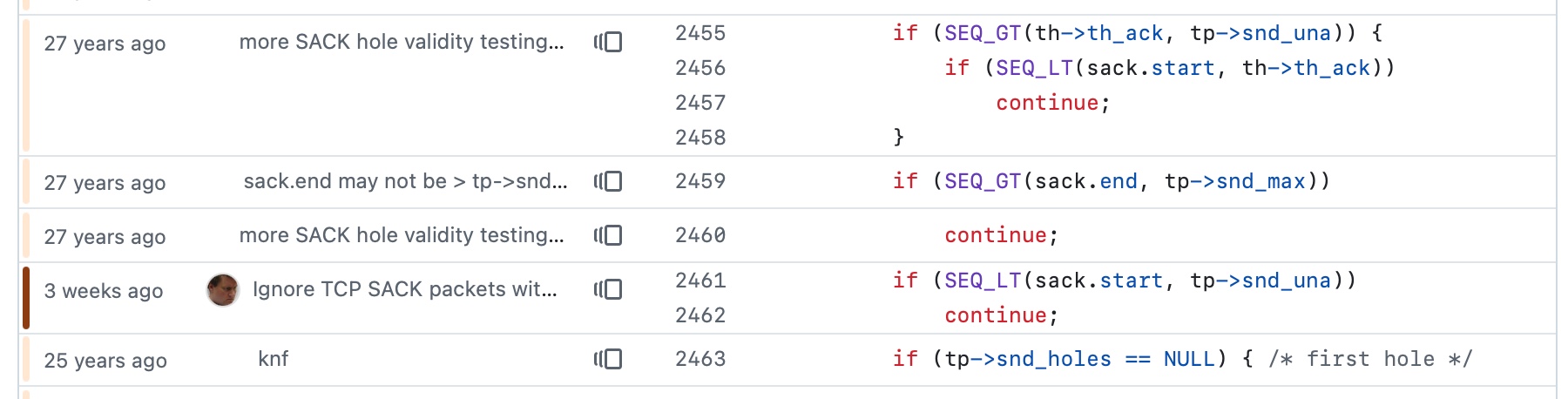 imageth_ack, tp->snd_una, sack.start, sack.end, tp->snd_max、および tp->snd_holes。ほとんどのコミットは 25〜27 年前のもので、「more SACK hole validity testin...」や「knf」といったメッセージが付いています。一方、3 週間前の最近のコミット(「Ignore TCP SACK packets wit...」)は、新しいガード条件
imageth_ack, tp->snd_una, sack.start, sack.end, tp->snd_max、および tp->snd_holes。ほとんどのコミットは 25〜27 年前のもので、「more SACK hole validity testin...」や「knf」といったメッセージが付いています。一方、3 週間前の最近のコミット(「Ignore TCP SACK packets wit...」)は、新しいガード条件 if (SEQ_LT(sack.start, tp->snd_una)) continue; を追加したもので、オレンジ色の左ボーダーで強調表示されています。" style="max-width: 100%;" />
確かに、周囲のコードは 27 年前に作成されたものです。
Nicholas が説明していた Linux の脆弱性がどれを指すのかは不明ですが、おそらく最近 Michael Lynch によって取り上げられた この NFS 関連の脆弱性 ではないでしょうか。
ここには十分な「煙」があるため、火事があると信じています。数十年にわたる古いソフトウェアに脆弱性が見つかるのは驚くべきことではありませんが、それらが主にC言語で書かれていることを考慮しても、最新の前線LLMによって駆動されるコーディングエージェントがこれらの問題を発見し続ける能力を持っているという事実は新しいものです。
私は金曜日に、これが業界全体の清算の最中にあるように思え、必然的な脆弱性の攻撃の前に先手を打つために多大な時間と資金を投資する価値があるかもしれないと考えました。Project Glasswingは「1億ドル分の使用クレジット……およびオープンソースのセキュリティ組織への400万ドルの直接寄付」を組み込んでいます。パートナーにはAWS、Apple、Microsoft、Google、Linux Foundationが含まれます。OpenAIも参加しているのを見てみたいものです。GPT-5.4はすでにセキュリティ脆弱性の発見において強い評判を持っており、より強力なモデルが間もなく登場する予定です。
私たち「信頼されたパートナー」ではない者にとっての悪いニュースはこれです:
Claude Mythos Previewを一般公開する予定はありませんが、最終的な目標は、ユーザーがサイバーセキュリティ目的だけでなく、そのような高度に能力の高いモデルがもたらす無数の他の利点のためにも、Mythosクラスモデルを大規模に安全にデプロイできるようにすることです。そのために、最も危険な出力を検出しブロックするサイバーセキュリティ(およびその他の)安全対策の開発において進展を遂げる必要があります。今後のClaude Opusモデルで新しい安全対策をリリースする予定であり、これによりMythos Previewと同じレベルのリスクをもたらさないモデルを用いて安全対策を改善・洗練させることができます。
私はそれで構いません。ここでのセキュリティリスクは本当に信頼できるものだと考えており、信頼されたチームがそれらに対処する時間をさらに得られることは、合理的なトレードオフだと思います。
タグ: security, thomas-ptacek, ai, generative-ai, llms, anthropic, nicholas-carlini, ai-ethics, llm-release, ai-security-research
原文を表示
Anthropic *didn't* release their latest model, Claude Mythos (system card PDF), today. They have instead made it available to a very restricted set of preview partners under their newly announced Project Glasswing.
The model is a general purpose model, similar to Claude Opus 4.6, but Anthropic claim that its cyber-security research abilities are strong enough that they need to give the software industry as a whole time to prepare.
Mythos Preview has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser. Given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors who are committed to deploying them safely.
[...]
Project Glasswing partners will receive access to Claude Mythos Preview to find and fix vulnerabilities or weaknesses in their foundational systems—systems that represent a very large portion of the world’s shared cyberattack surface. We anticipate this work will focus on tasks like local vulnerability detection, black box testing of binaries, securing endpoints, and penetration testing of systems.
Saying "our model is too dangerous to release" is a great way to build buzz around a new model, but in this case I expect their caution is warranted.
Just a few days (last Friday) ago I started a new ai-security-research tag on this blog to acknowledge an uptick in credible security professionals pulling the alarm on how good modern LLMs have got at vulnerability research.
Greg Kroah-Hartman of the Linux kernel:
Months ago, we were getting what we called 'AI slop,' AI-generated security reports that were obviously wrong or low quality. It was kind of funny. It didn't really worry us.
Something happened a month ago, and the world switched. Now we have real reports. All open source projects have real reports that are made with AI, but they're good, and they're real.
Daniel Stenberg of curl:
The challenge with AI in open source security has transitioned from an AI slop tsunami into more of a ... plain security report tsunami. Less slop but lots of reports. Many of them really good.
I'm spending hours per day on this now. It's intense.
And Thomas Ptacek published Vulnerability Research Is Cooked, a post inspired by his podcast conversation with Anthropic's Nicholas Carlini.
Anthropic have a 5 minute talking heads video describing the Glasswing project. Nicholas Carlini appears as one of those talking heads, where he said (highlights mine):
It has the ability to chain together vulnerabilities. So what this means is you find two vulnerabilities, either of which doesn't really get you very much independently. But this model is able to create exploits out of three, four, or sometimes five vulnerabilities that in sequence give you some kind of very sophisticated end outcome. [...]
I've found more bugs in the last couple of weeks than I found in the rest of my life combined. We've used the model to scan a bunch of open source code, and the thing that we went for first was operating systems, because this is the code that underlies the entire internet infrastructure. For OpenBSD, we found a bug that's been present for 27 years, where I can send a couple of pieces of data to any OpenBSD server and crash it. On Linux, we found a number of vulnerabilities where as a user with no permissions, I can elevate myself to the administrator by just running some binary on my machine. For each of these bugs, we told the maintainers who actually run the software about them, and they went and fixed them and have deployed the patches patches so that anyone who runs the software is no longer vulnerable to these attacks.
I found this on the OpenBSD 7.8 errata page:
025: RELIABILITY FIX: March 25, 2026 All architectures
TCP packets with invalid SACK options could crash the kernel.
A source code patch exists which remedies this problem.
I tracked that change down in the GitHub mirror of the OpenBSD CVS repo (apparently they still use CVS!) and found it using git blame:
th_ack, tp->snd_una, sack.start, sack.end, tp->snd_max, and tp->snd_holes. Most commits are from 25–27 years ago with messages like "more SACK hole validity testin..." and "knf", while one recent commit from 3 weeks ago ("Ignore TCP SACK packets wit...") is highlighted with an orange left border, adding a new guard "if (SEQ_LT(sack.start, tp->snd_una)) continue;"" style="max-width: 100%;" />
Sure enough, the surrounding code is from 27 years ago.
I'm not sure which Linux vulnerability Nicholas was describing, but it may have been this NFS one recently covered by Michael Lynch.
There's enough smoke here that I believe there's a fire. It's not surprising to find vulnerabilities in decades-old software, especially given that they're mostly written in C, but what's new is that coding agents run by the latest frontier LLMs are proving tirelessly capable at digging up these issues.
I actually thought to myself on Friday that this sounded like an industry-wide reckoning in the making, and that it might warrant a huge investment of time and money to get ahead of the inevitable barrage of vulnerabilities. Project Glasswing incorporates "$100M in usage credits ... as well as $4M in direct donations to open-source security organizations". Partners include AWS, Apple, Microsoft, Google, and the Linux Foundation. It would be great to see OpenAI involved as well - GPT-5.4 already has a strong reputation for finding security vulnerabilities and they have stronger models on the near horizon.
The bad news for those of us who are *not* trusted partners is this:
We do not plan to make Claude Mythos Preview generally available, but our eventual goal is to enable our users to safely deploy Mythos-class models at scale—for cybersecurity purposes, but also for the myriad other benefits that such highly capable models will bring. To do so, we need to make progress in developing cybersecurity (and other) safeguards that detect and block the model’s most dangerous outputs. We plan to launch new safeguards with an upcoming Claude Opus model, allowing us to improve and refine them with a model that does not pose the same level of risk as Mythos Preview.
I can live with that. I think the security risks really are credible here, and having extra time for trusted teams to get ahead of them is a reasonable trade-off.
Tags: security, thomas-ptacek, ai, generative-ai, llms, anthropic, nicholas-carlini, ai-ethics, llm-release, ai-security-research
関連記事
2026年3月6日 Frontier Red TeamによるClaudeのCVE-2026-2796エクスプロイトのリバースエンジニアリング
Frontier Red Teamが、Claudeの脆弱性CVE-2026-2796を悪用するエクスプロイトをリバースエンジニアリングした。
フロンティア・レッドチーム、Firefoxのセキュリティ向上のためにMozillaと提携
フロンティア・レッドチームは、Firefoxのセキュリティを向上させるため、Mozillaと提携した。
59%のユーザーがより安価なモデルを選択:Sonnet 4.6の詳細解説
Anthropic社がClaude Sonnet 4.6をリリースし、Claude Codeテストで70%のユーザーが前世代モデルより好み、59%がフラッグシップモデルOpus 4.5よりも選択した。コーディング、コンピュータ利用、100万トークンコンテキストなど6次元で全面アップグレードされ、価格は据え置き。