Nova Forge SDKの紹介:企業AI向けにNovaモデルをカスタマイズするシームレスな方法
AWSはNova Forge SDKを発表し、企業向けAIのためのNovaモデルをカスタマイズするための統合ツールキットを提供することで、LLMのカスタマイズの障壁を下げ、カタストロフィックフォゲッティングの問題に対処することを目指しています。
キーポイント
LLMカスタマイズの必要性と課題
汎用LLMはドメイン固有タスクに弱く、企業は独自データや業務プロセスに特化したモデルを必要としているが、カスタマイズには技術的複雑さやカタストロフィックフォゲッティング(基本能力の喪失)といった課題がある。
Nova Forge SDKの目的と機能
依存関係管理、イメージ選択、レシピ設定などの課題を解消し、LLMカスタマイズへの参入障壁を下げることを目的とした統合ツールキットを提供する。
カスタマイズ手法の包括的サポート
Amazon BedrockのSupervised Fine-Tuning(SFT)やReinforcement Fine Tuning(RFT)から、Amazon SageMaker AIのSFT、Direct Preference Optimization(DPO)、RFT、LoRAおよびフルランクベースのカスタマイズまで、幅広いオプションをサポートする。
開発者向け設計
開発者によって開発者向けに構築されたツールキットであり、Nova Forgeの機能を活用してAmazon BedrockからAmazon SageMaker AIまでのすべてのカスタマイズオプションをサポートする。
影響分析・編集コメントを表示
影響分析
この発表は、企業がLLMを自社業務に効果的に適用するための重要なインフラを提供するもので、AWSのAIエコシステムにおける競争力を強化する。特に、カスタマイズの複雑さを抽象化することで、より多くの企業が生成AIを採用する後押しとなり、業界全体の実用化を加速させる可能性がある。
編集コメント
AWSがLLMカスタマイズ市場で本格的に巻き返しを図る重要な発表。技術的複雑さを隠蔽するSDK提供は、競合に対する差別化ポイントとなり得る。
大規模言語モデル(LLM)は、AI との相互作用の方法を変革しましたが、一つのサイズですべてに対応できるわけではありません。箱出し状態の LLM は広範な一般知識でトレーニングされ、幅広いユースケース向けに改善されていますが、ドメイン固有のタスク、独自ワークフロー、または独自のビジネス要件においては、しばしば不十分となります。エンタープライズ顧客は、独自のデータ、ビジネスプロセス、およびドメイン固有の用語を深く理解する専門化された LLM をますます必要としています。カスタマイズを行わない場合、汎用的な応答を受け入れるか、過度なコンテキストエンジニアリングを伴う妥協点に落ち着くかの二者択一を迫られることになります。Nova Customization は、Amazon Bedrock のカスタマイズオプションである教師ありファインチューニング(SFT)や強化学習ファインチューニング(RFT)、および Amazon SageMaker AI のカスタマイズ機能である SFT、直接選好最適化(DPO)、RFT、さらに LoRA およびフルランクベースのカスタマイズの両方を含む一連の機能を提供します。
モデルが専門データセット上でファインチューニングされる際、指示従順能力、推論スキル、広範な知識の専門性など、基礎的な機能がしばしば失われます。この現象は壊滅的忘却とも呼ばれます。
AWS Amazon Nova Forge は、Nova を用いて独自の最先端モデルを構築できるようにすることで、このトレードオフを克服するツールを提供します。Nova Forge の顧客は、初期のモデルチェックポイントから開発を開始し、自社のデータセットを Amazon Nova が厳選したデータとブレンドして、カスタムモデルを AWS 上で安全にホストできます。
しかし、これらのカスタマイズワークフローは複雑化することがあり、技術的なインフラストラクチャの構築や多大な時間投資が必要となるため、参入障壁が高くなりがちです。
この課題に対処するため、私たちは Nova Forge SDK を立ち上げました。これにより、依存関係の管理、イメージの選択、レシピの設定といった課題に直面することなく、言語モデルの可能性を最大限に活用できるようチームを支援し、参入障壁を低下させます。
私たちはカスタマイズをスケーリングラダー内の連続体と捉えており、したがって Nova Forge SDK は、Amazon Bedrock から Amazon SageMaker AI まで、Nova Forge の機能を用いたあらゆるカスタマイズオプションをサポートします。
Nova Forge SDK:開発者によって開発者に作られた専用ツール
Nova Forge SDK は、Nova の顧客と開発者のために特別に設計された統一された ツールキット を提供します。これはデータ準備ツールの構築からトレーニングジョブの管理、モデルのデプロイに至るまで、完全なカスタマイズライフサイクルをカバーし、必要なソリューションを一つの場所で提供します。Nova Forge SDK は、大規模言語モデル(LLM)のカスタマイズにおける差別化されない重労働を取り除く試みであり、ユーザーが実験に集中できるようにすることを目的としています。既存のツールを補完するものとして、インテリジェントなデフォルトとガイダンスを持つワークフローを提供しつつも、必要に応じて上級者が基盤となるサービス SDK の全機能をアクセスできる柔軟性を維持しています。これにより、顧客は一般的なタスクには streamlined なワークフローを、高度なユースケースには完全な柔軟性を得ることができます。

この SDK は、以下の 3 つのレイヤーとして理解することができます:
- Input Layer: これは入力として渡される層であり、RuntimeManager オブジェクト(使用するハードウェア、プラットフォーム、権限観点での IAM ロールを含む)、トレーニング方法、トレーニングデータ、オーバーライドする任意のハイパーパラメータ、およびカスタマイズ対象のモデルが含まれます。
- Customizer Layer: この中間層はこれらの入力を受け取り、裏側で適切なレシピ設定を構築し、渡された入力値を使用してジョブを開始します。
- Output Layer: 出力層は、Amazon CloudWatch Logs、ML Flow メトリクス、tensor board ログ、および最終的なトレーニング済みモデルアーティファクトを含む出力アーティファクトを生成します。このモデルは、反復的な微調整(fine tuning)を使用してモデルをさらにチューニングするか、または推論のために Amazon SageMaker AI または Amazon Bedrock にデプロイするために使用できます。
以下の画像は、これらのコンポーネントの概要を示しています。
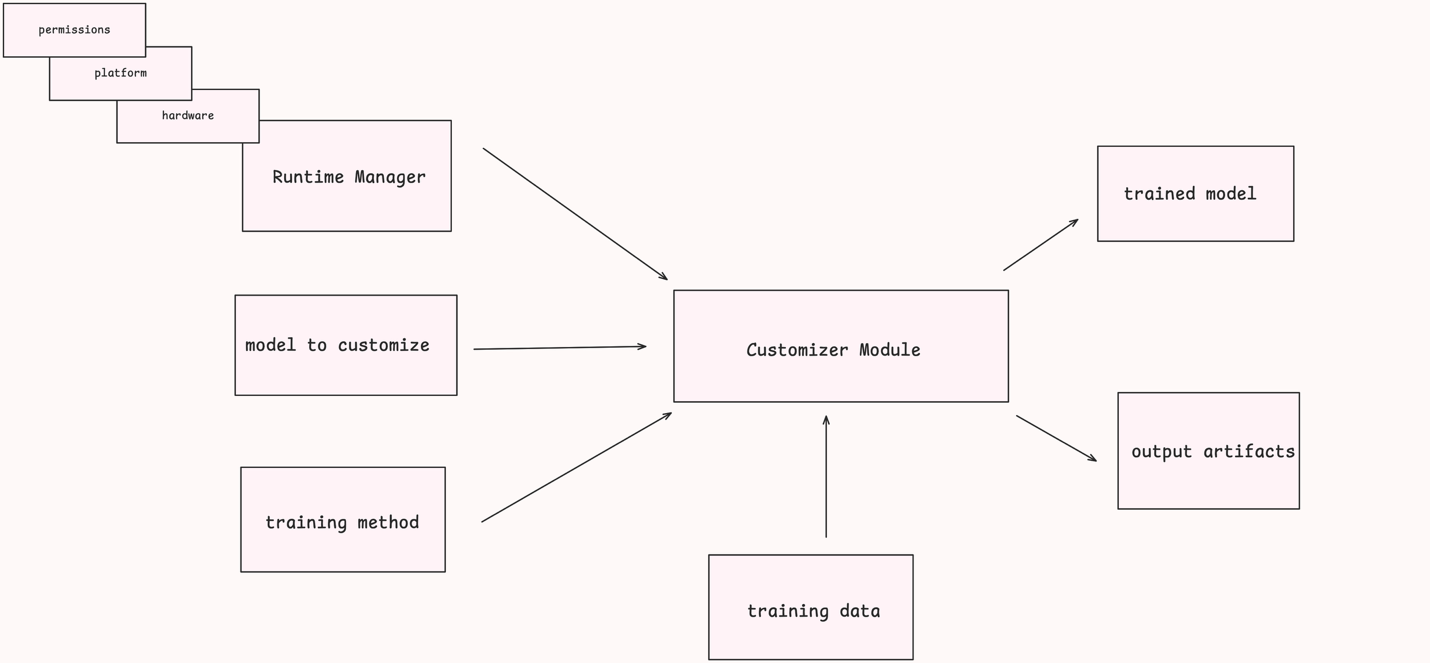
Nova Forge SDK のユーザーは、初期化された NovaModelCustomizer の API メソッドのいずれかに、設定済みの RuntimeManager、カスタマイズ対象のモデル、およびトレーニング手法を提供します。Customizer の初期化には、トレーニングデータを取得する場所を指定することが含まれます。これは通常、Amazon Simple Storage Service (Amazon S3) の場所です。これらの設定に基づいて、Customizer モデルは指定されたタスクを実行するために Amazon SageMaker AI ジョブの構成と開始を処理します。最後に、完了したタスクは出力アーティファクトを生成し(「train」API の場合)、トレーニング済みモデルも生成します。これらはその後、SDK を介してまたは直接 Amazon SageMaker API を使用して参照することができます。
前提条件:
カスタマイズワークフローを開始する前に、環境に以下のセットアップがあることを確認してください。このブログ記事では、計算プラットフォームとして Amazon SageMaker Training Jobs (SMTJ) を使用します(追従するために Amazon SageMaker HyperPod クラスターは必要ありません)。
本記事では Amazon Nova Forge のセットアップは不要です。これは、Amazon SageMaker AI を用いた Nova カスタマイズのために利用可能な基本的な機能を確認するためです。
注: Amazon SageMaker Training Jobs に関心があるだけの場合は、Amazon SageMaker HyperPod のセットアップを完全にスキップできます。
AWS アカウントと CLI
AWS アカウントが必要です。お持ちでない場合は、サインアップ手順に従ってください。
その後、AWS Command Line Interface (AWS CLI) のインストール手順に従い、認証情報で設定してください。これはセットアップに使用される初期 API 呼び出しに用いられ、AWS CLI の認証チェーンは Nova Forge SDK でも共有されます。
最後に、Nova Forge SDK が Amazon Nova モデルおよびカスタマイズ機能へのアクセスを提供するために使用する SageMaker AI プラットフォームへのアクセス設定 を、公開ドキュメントに従って行ってください。
IAM ロール
Nova Forge SDK と連携するには、ユーザーロールと実行ロールの 2 つの IAM ロールを作成する必要があります。Nova Forge SDK は実行時に両方のロールを検証して必要な最小限の権限があることを確認しますが、以下のセットアップ手順を完了することを推奨します:
- ユーザーロール — SDK と AWS CLI を実行する際に、お使いのマシン上で引き受ける役割です。このロールには、Amazon SageMaker AI(CreateTrainingJob, DescribeTrainingJob)、Amazon S3(データバケットへの読み書き)、Amazon CloudWatch Logs(読み取り)、IAM(PassRole)の権限が必要です。完全なポリシーについては SDK のドキュメントをご覧ください。
- 実行ロール — Amazon SageMaker AI が、代わりにトレーニングジョブを実行する際に引き受ける役割です。その信頼ポリシーには、sagemaker.amazonaws.com がこのロールを引き受けられるようにする記述が含まれている必要があります。推奨される権限の完全なセットについては、SageMaker の実行ロールドキュメントをご覧ください。詳細な設定手順については、SMTJ ジョブを実行するための前提条件に従ってください。
サービスクォータ
本記事では、トレーニングと評価の両方に ml.p5.48xlarge インスタンスを使用します。Nova Lite 2.0 では、SFT トレーニングに最低でも4 つのインスタンスが必要です。トレーニングジョブと評価ジョブを並行して実行している場合は、少なくとも 5 つのインスタンスが必要になる可能性があります。
Amazon SageMaker Training Jobs の Service Quotas コンソール を通じて、トレーニングジョブの使用に必要な ml.p5.48xlarge のクォータを十分にリクエストしてください。
S3 バケット
トレーニングジョブと同じ AWS リージョンに Amazon Simple Storage Service (Amazon S3) バケット を作成してください(本記事全体で us-east-1 を使用します)。また、ユーザーおよび実行用の IAM ロールがそのバケットに対して読み取り・書き込みアクセス権を持っていることを確認してください。ここでは、本記事のトレーニングデータと出力アーティファクトを保存します。
Amazon SageMaker HyperPod (オプション)
Amazon SageMaker Training Jobs (SMTJ) に加え、Nova Forge SDK は Amazon SageMaker HyperPod (SMHP) 上でのジョブ実行もサポートしています。本記事では SMHP のカスタマイズに焦点を当てていませんが、SMHP でトレーニングを実行する場合は、Amazon Nova モデルと連携するために、制限付きインスタンスグループ (RIGs) を備えた Amazon SageMaker HyperPod クラスターを設定する必要があります。
HyperPod RIG セットアップワークショップ の手順に従い、Amazon Nova カスタマイズに適した RIG を備えたクラスターを設定してください。
Nova Forge SDK のセットアップ
前提条件の準備が完了したら、以下のガイダンスを使用して環境を構築し、Nova Forge SDK の使用を開始できます。
Python 環境
Nova Forge SDK には Python 3.12 以降が必要です。依存関係を分離し、システム内の他のパッケージとの競合を防ぐために、仮想環境の作成をお勧めします:
python3.12 -m venv nova-sdk-env
source nova-sdk-env/bin/activate *# Windows の場合:nova-sdk-env\Scripts\activate*
SDK のインストール
以下の Pip コマンドを使用して、SDK をインストールできます。
pip install amzn-nova-forge
サンプル Python ファイルで主要なモジュールをインポートすることで、インストールが成功したことを確認します。
from amzn_nova_forge import (
NovaModelCustomizer,
SMTJRuntimeManager,
TrainingMethod,
EvaluationTask,
CSVDatasetLoader,
Model,
)
各モジュールの簡単な説明は以下の通りです。
- NovaModelCustomizer: Nova Forge SDK と対話するための主要クラスです。API のコアメソッドを含み、トレーニング設定の多くを初期化するために使用されます。
- SMTJRuntimeManager: カスタマイズジョブに選択されたインスタンスタイプや数など、SMTJ カスタマイズに必要な AWS インフラストラクチャを管理します。
- TrainingMethod: NovaModelCustomizer を設定するために使用できる、可能なトレーニングタイプの列挙型(Enum)です。
- EvaluationTask: NovaModelCustomizer を設定するために使用できる、可能な評価タイプの列挙型(Enum)です。
- CSVDatasetLoader: Nova Forge SDK で使用するデータを CSV ファイルから読み込むために使用されます。
- Model: Nova Forge SDK がサポートする Amazon Nova モデルの列挙型(Enum)です。
注: SDK の異なる機能に関する詳細については、仕様書 を参照してください。コーディング作業に LLM エージェントを使用している場合は、リポジトリ内の AGENTS.md ファイルをレビューさせて、SDK について学習させることができます。
結論
この SDK の統一されたインターフェースは、データフォーマットやプラットフォーム固有の設定に関する複雑さを抽象化するため、開発者は自らのデータ、ドメイン、そしてビジネス目標に集中することができます。Amazon SageMaker Training Jobs でファインチューニングから始める場合でも、Amazon SageMaker Hyperpod を使用してカスタマイズを実行する計画を立てている場合でも、SDK はカスタマイズの連続体全体を通じて一貫した体験を提供します。
従来の LLM(大規模言語モデル)カスタマイズの障壁、技術的専門知識の要件、および時間投資を排除することで、Nova Forge SDK は、基盤モデルが持つ価値ある汎用能力を犠牲にすることなく、組織が独自の文脈を真に理解するモデルを構築できる力を付与します。SDK は計算リソースの設定、カスタマイズパイプライン全体のオーケストレーション、トレーニングジョブの監視、エンドポイントのデプロイメントを処理します。その結果、専門化されつつも知的であり、ドメインの専門家でありながら広範な能力を持つエンタープライズ AI が実現されます。
ご自身で Nova モデルのカスタマイズを開始したいですか?GitHub 上の Nova Forge SDK で始め、完全なドキュメント を探索して、貴社の企業ニーズに合わせたモデルの構築を始めてください。
著者について
 image
image
Mahima Chaudhary
Mahima Chaudhary は、Amazon Nova Training Experience チームに所属する機械学習エンジニアです。同チームでは Nova Forge SDK と強化学習ファインチューニング(Reinforcement Fine-Tuning: RFT)に取り組んでおり、顧客が AWS 上で Nova モデルをカスタマイズおよびファインチューニングできるよう支援しています。彼女は MLOps および LLMOps の専門知識を持ち、Amazon 入社前には航空、医療、保険、金融の各分野で、スケーラブルかつ本番環境対応型の機械学習システム構築の実績があります。カリフォルニア州在住で、モデルのリリースに追われている合間には、新しいハイキングコースで夕日を追いかける姿や、キッチンでの実験、ドキュメンタリーの世界に没頭している様子を見つけることができます。

Anupam Dewan
Anupam Dewan は、Amazon Nova チームでシニアソリューションアーキテクトとして勤務しており、生成 AI とその実世界への応用に情熱を注いでいます。彼は Nova のカスタマイズと Nova Forge に焦点を当て、企業がカスタマイズの力を活用して大規模言語モデル(LLM)の真の可能性を引き出すことを支援しています。また、データサイエンスや分析の教育にも情熱を持っており、企業のビジネスに役立つ LLM の構築をサポートしています。仕事以外では、ハイキングやボランティア活動、自然を楽しむ姿を見つけることができます。

Swapneil Singh
Swapneil Singh は、Amazon Nova Training Experience チームに所属するソフトウェア開発エンジニアです。同チームでは、Amazon Nova モデルのカスタマイズ向けに開発者向けツールを構築しています。彼は Nova Forge SDK および Amazon Nova ユーザーガイドの主要コントリビューターであり、顧客が AWS 上でカスタム Nova モデルのファインチューニングとデプロイを支援しています。それ以前は、AWS Elastic Container Services においてテレメトリおよびログ処理を担当していました。仕事以外では、AI オーケストレーションやプログラミング言語に触れるか、ボストンの図書館で過ごす姿を見かけます。
原文を表示
Large language models (LLMs) have transformed how we interact with AI, but one size doesn’t fit at all. Out-of-the-box LLMs are trained with broad, general knowledge and improved for a wide range of use cases, but they often fall short when it comes to domain-specific tasks, proprietary workflows, or unique business requirements. Enterprise customers increasingly need specialized LLMs that deeply understand their proprietary data, business processes, and domain-specific terminology. Without customization, you’re forced to choose between accepting generic responses or settling for a middle ground with excessive context engineering. Nova Customization provides a suite of features, ranging from Amazon Bedrock customization options such as Supervised Fine-Tuning (SFT) and Reinforcement Fine Tuning (RFT) to Amazon SageMaker AI customization capabilities, including SFT, Direct Preference Optimization (DPO), RFT, along with both LoRA and full rank based customization.
As models are fine-tuned on specialized datasets, they frequently, loose some base capabilities including instruction-following abilities, reasoning skills, and broad knowledge expertise, this phenomenon is also calledcatastrophic forgetting. Amazon Nova Forgeprovides a tool to overcome this tradeoff by enabling you to build your own frontier models using Nova. Nova Forge customers can start their development from early model checkpoints, blend their datasets with Amazon Nova-curated and host their custom models securely on AWS. Sometime these customization workflows can get complex and necessitates technical, infrastructure setup, and considerable time investment making them a high barrier to entry.
To combat this issue we are launching Nova Forge SDK that makes LLM customization accessible, empowering teams to harness the full potential of language models without the challenges of dependency management, image selection, and recipe configuration and eventually lowering the barrier of entry. We view customization as a continuum within the scaling ladder, and therefore, the Nova Forge SDK supports all customization options, ranging from Amazon Bedrock all the way to Amazon SageMaker AI using Amazon Nova Forge capabilities.
Nova Forge SDK: Purpose built for developers by developers
Nova Forge SDK delivers a unified toolkit purpose-built for Nova customers and developers. It spans the complete customization lifecycle, providing solutions in one place from data preparation tooling, training job management, through model deployment. Nova Forge SDK represents an attempt to remove undifferentiated heavy lifting from LLM customization, so you can focus on experimenting. It complements the existing tools by offering workflows with intelligent defaults and guidance, while still allowing advanced users to access the full power of the underlying service SDKs when needed. This gives customers both streamlined workflows for common tasks and full flexibility for advanced use cases.
The SDK can be understood in three layers:
- Input Layer: This is the layer that you pass as the inputs, this can include RuntimeManager object (including what hardware to use, what platform to use and what IAM role to use from a permissions standpoint), along with training method, training data and any hyperparameters that you choose to override, along with the model of choice to customize.
- Customizer Layer: This is the middle layer that takes in these inputs and behind the scenes build the right recipe configurations and launches the job with the passed in input values.
- Output Layer: The output layer emits the output artifacts including Amazon CloudWatch Logs, ML Flow metrics, tensor board logs along with the final trained model artifact that can be used to either further tune the model using iterative fine tuning or deploying the model on Amazon SageMaker AI or Amazon Bedrock for inference.
The following image shows a high-level breakdown of these components.
The user of the Nova Forge SDK provides a configured RuntimeManager, a model to customize, and a training method to one of the API methods in an initialized NovaModelCustomizer. The initialization of the Customizer includes specifying the location from which it can retrieve training data. This is typically an Amazon Simple Storage Service (Amazon S3) location. Based on these configurations, the Customizer model handles configuring and starting an Amazon SageMaker AI job to execute the specified task. Finally, the completed task generates output artifacts and (for the “train” API) a trained model, which you can then reference through the SDK or directly using Amazon SageMaker APIs.
Prerequisites:
Before beginning the customization workflow, make sure that you have the following setup in your environment. This blog post uses Amazon SageMaker Training Jobs (SMTJ) as the compute platform (you do not need an Amazon SageMaker HyperPod cluster to follow along)
Amazon Nova Forge setup is not required for this post, as we are reviewing the fundamental features available for Nova customization using Amazon SageMaker AI.
Note: If you are only interested in Amazon SageMaker Training Jobs, you can skip the Amazon SageMaker HyperPod setup entirely.
AWS Account and CLI
You will need an AWS account. If you don’t have one, follow the sign-up instructions.
Afterwards, follow the instructions to install the AWS Command Line Interface (AWS CLI) and configure it with your credentials. This is used for the initial API calls used for the setup, and the AWS CLI credential chain is shared by the Nova Forge SDK.
Finally, follow the public documentation to set up your access to the SageMaker AI platform, which the Nova Forge SDK uses to give you access to Amazon Nova models and customization capabilities.
IAM roles
You must create two IAM roles to work with the Nova Forge SDK, the User role, and the Execution role. The Nova Forge SDK validates both roles during execution to make sure that they have the minimum required permissions, however, we recommend that you complete the following setup steps:
- User role — the role you assume on your machine when running the SDK and the AWS CLI. This role needs permissions for Amazon SageMaker AI (CreateTrainingJob, DescribeTrainingJob), Amazon S3 (read/write to your data bucket), Amazon CloudWatch Logs (read), and IAM (PassRole). See the SDK documentation for the full policy.
- Execution role — the role that Amazon SageMaker AI assumes to run training jobs on your behalf. Its trust policy must allow sagemaker.amazonaws.com to assume it. For the full set of recommended permissions, see the SageMaker execution role documentation. Follow the prerequisites to run SMTJ jobs for detailed setup instructions.
Service quotas
This post uses ml.p5.48xlarge instances for both training and evaluation. Nova Lite 2.0 requires a minimum of 4 instances for SFT training; if you are running training and evaluation jobs concurrently, you might need at least 5 instances.
Request sufficient quotas for ml.p5.48xlarge for training job usage through the Service Quotas console for Amazon SageMaker Training Jobs.
S3 Bucket
Create an Amazon Simple Storage Service (Amazon S3) bucket in the same AWS Region as your training jobs (we use us-east-1 throughout this post) and make sure that your user and execution IAM roles have read and write access to the bucket. This is where we will store training data and output artifacts for this post.
Amazon SageMaker HyperPod (Optional)
In addition to Amazon SageMaker Training Jobs (SMTJ), the Nova Forge SDK also supports running jobs on Amazon SageMaker HyperPod (SMHP). While this post does not focus on SMHP customization, if you want to run training on SMHP you must set up an Amazon SageMaker HyperPod cluster with Restricted Instance Groups (RIGs) to work with Amazon Nova models.
Follow the instructions in the HyperPod RIG setup workshop to set up a cluster with RIGs suitable for Amazon Nova customization.
Setting up the Nova Forge SDK
After you are done with prerequisites, you can use the following guidance to get your environment set up to start using Nova Forge SDK.
Python environment
The Nova Forge SDK requires Python 3.12 or later. We recommend creating a virtual environment to isolate dependencies and avoid conflicts with other packages in your system:
python3.12 -m venv nova-sdk-env
source nova-sdk-env/bin/activate # On Windows: nova-sdk-env\Scripts\activateInstall the SDK
You can install the SDK with the following Pip command:
pip install amzn-nova-forgeVerify the installation by importing the key modules in a sample Python file:
from amzn_nova_forge import (
NovaModelCustomizer,
SMTJRuntimeManager,
TrainingMethod,
EvaluationTask,
CSVDatasetLoader,
Model,
)
The following are brief descriptions of each of these modules:
- NovaModelCustomizer: The primary class for interacting with the Nova Forge SDK. It contains the core methods for the API and is used to initialize much of the training configuration.
- SMTJRuntimeManager: Manages the AWS infrastructure required for SMTJ. customization, such as the selected instance type and count for a customization job.
- TrainingMethod: An Enum of the possible training types, which can be used to configure a NovaModelCustomizer.
- EvaluationTask: An Enum of the possible evaluation types, which can be used to configure a NovaModelCustomizer.
- CSVDatasetLoader: Used to load data from CSV files for use in the Nova Forge SDK.
- Model: An Enum of the Amazon Nova models supported by the Nova Forge SDK.
Note: For more information about the different functionalities of the SDK, see the specification document. If you use an LLM agent for coding work, you can have it review the AGENTS.md file in the repository to teach it about the SDK.
Conclusion
The SDK’s unified interface abstracts the complexity of data formatting and platform-specific configurations so that developers can focus on what matters: their data, their domain, and their business objectives. Whether you’re starting with fine-tuning on Amazon SageMaker Training Jobs or planning to run customization with Amazon SageMaker Hyperpod, the SDK provides a consistent experience across the entire customization continuum.
By removing the traditional barriers to LLM customization, technical expertise requirements, and time investment, the Nova Forge SDK empowers organizations to build models that truly understand their unique context without sacrificing the general capabilities that make foundation models valuable. The SDK handles configuring compute resources, orchestrating the entire customization pipeline, monitoring training jobs, and deploying endpoints. The result is enterprise AI that’s both specialized and intelligent, domain-expert and broadly capable.
Ready to customize your own Nova models? Get started with the Nova Forge SDK on GitHub and explore the full documentation to begin building models tailored to your enterprise needs.
About the authors
Mahima Chaudhary
Mahima Chaudhary is a Machine Learning Engineer on the Amazon Nova Training Experience team, where she works on the Nova Forge SDK and Reinforcement Fine-Tuning (RFT), helping customers customize and fine-tune Nova models on AWS. She brings expertise in MLOps and LLMOps, with a track record of building scalable, production-grade ML systems across aviation, healthcare, insurance, and finance prior to Amazon. Based in California, when she’s not shipping models, you’ll find her chasing sunsets on a new hiking trail, experimenting in the kitchen, or deep in a documentary rabbit hole.
Anupam Dewan
Anupam Dewan is a Senior Solutions Architect working in Amazon Nova team with a passion for generative AI and its real-world applications. He focuses on Nova customization and Nova Forge, helping enterprises realize the true potential of LLMs with power of customization. He is also passionate about teaching data science, and analytics and helping Enterprise build LLMs that work for their businesses. Outside of work, you can find him hiking, volunteering or enjoying nature.
Swapneil Singh
Swapneil Singh is a Software Development Engineer on the Amazon Nova Training Experience team, where he builds developer tooling for Amazon Nova model customization. He is a core contributor to the Nova Forge SDK and the Amazon Nova User Guide, helping customers fine-tune and deploy custom Nova models on AWS. Previously, he worked on telemetry and log processing in AWS Elastic Container Services. Outside of work, you can find him tinkering with AI orchestrations and programming languages, or in the Boston library.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み