P-EAGLE: vLLMにおける並列投機的デコーディングによる高速なLLM推論
AWSが発表したP-EAGLEは、推測デコーディングの並列化によりLLM推論を最大1.69倍高速化し、vLLM統合と事前学習済みモデルを提供することで実用性が高い技術革新である。
キーポイント
推測デコーディングの並列化による性能向上
従来のEAGLEの逐次処理ボトルネックを解消し、すべてのドラフトトークンを単一フォワードパスで生成することで、NVIDIA B200上で最大1.69倍の高速化を実現した。
vLLMへの統合と即時利用可能な実装
vLLM v0.16.0以降で統合されており、parallel_draftingフラグを設定するだけで利用可能で、実装のハードルが低い。
事前学習済みモデルの公開
HuggingFaceでGPT-OSS 120B、GPT-OSS 20B、Qwen3-Coder 30BのP-EAGLEヘッドが公開されており、すぐに実験や導入が可能。
実用的なワークロードでの検証
理論的な性能だけでなく、実際のワークロードで評価されており、実環境での有効性が示されている。
影響分析・編集コメントを表示
影響分析
この技術はLLM推論のコスト削減とレイテンシ改善に直接寄与し、大規模モデルの実用化を加速させる。特にvLLMとの統合と事前学習モデルの公開により、研究段階から実運用段階への移行が容易になり、業界全体の推論効率向上に貢献する可能性が高い。
編集コメント
理論的な革新性だけでなく、すぐに使える実装とモデルを提供している点が実用的で評価できる。LLMサービスの運用コスト削減に直接結びつく技術として注目。
EAGLE は、大規模言語モデル(LLM)推論におけるスペキュレーティブ・ディコーディングのための最先端手法ですが、その自己回帰的なドラフティングには隠れたボトルネックが存在します:推測するトークン数が増えるほど、ドラフターが必要とする順方向パスの回数も増え、最終的にはそのオーバーヘッドが得られる速度向上を食いつぶしてしまいます。P-EAGLE は、K 個のドラフトトークンを単一の順方向パスで生成することでこの天井を取り払い、NVIDIA B200 上の実ワークロードにおいて従来の EAGLE-3 と比較して最大 1.69 倍の高速化を実現します。
この性能向上を達成するには、並列処理対応のドラフターヘッドをダウンロード(またはトレーニング)し、vLLM サービングパイプラインに「parallel_drafting": true」を追加してください。GPT-OSS 120B https://huggingface.co/amazon/gpt-oss-120b-p-eagle、GPT-OSS 20B https://huggingface.co/amazon/GPT-OSS-20B-P-EAGLE、Qwen3-Coder 30B https://huggingface.co/amazon/Qwen3-Coder-30B-A3B-Instruct-P-EAGLE のための事前学習済み P-EAGLE ヘッドはすでに HuggingFace で利用可能なので、今日からすぐに開始できます。
本記事では、P-EAGLE がどのように動作するか、v0.16.0(PR#32887)以降の vLLM への統合方法、および事前学習済みチェックポイントを用いたサービング方法を解説します。以下に使用されるアーティファクトの一覧を示します:
- ArXiv Paper
- HuggingFace Models (GPT-OSS 120B, GPT-OSS 20B, Qwen3-Coder-30B-A3B-Instruct)
- vLLM Integration Unified Parallel Drafting
- vLLM-Speculators (RFC, PR)
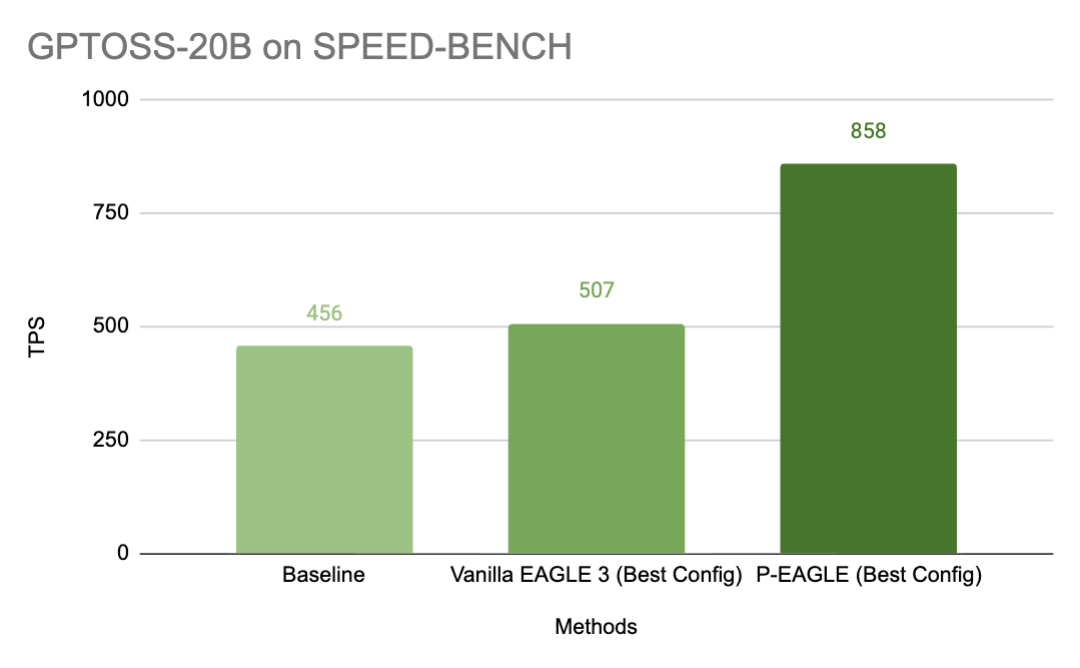
Figure 1: P-EAGLE over other methods on SPEED-BENCH with Concurrency of 1 on one NVIDIA B200 card.
Quick start P-EAGLE:
You can enable parallel drafting with a single configuration change in the SpeculativeConfig class:
# vllm/config/speculative.py
parallel_drafting: bool = True
Here's an example command in vLLM to enable parallel drafting with P-EAGLE as drafter:
vllm serve openai/gpt-oss-20b \
--speculative-config '{"method": "eagle3", "model": "amazon/gpt-oss-20b-p-eagle", "num_speculative_tokens": 5, "parallel_drafting": true}'
EAGLE's Drafting Bottleneck
EAGLE achieves 2–3× speedups over standard autoregressive decoding and is widely deployed in production inference frameworks including vLLM, SGLang, and TensorRT-LLM. EAGLE drafts tokens autoregressively. To produce K draft tokens, it requires K forward passes through the draft model. As drafter models get better at drafting long outputs, this drafting overhead becomes significant—the drafter's latency scales linearly with speculation depth, constraining how aggressively we can speculate.
私たちのアプローチ:Parallel-EAGLE (P-EAGLE)
私たちは P-EAGLE を発表します。これは EAGLE を自己回帰型から並列ドラフト生成へと変換するものです。B200 GPU 上で、P-EAGLE は GPT-OSS 20B モデルにおける MT-Bench、HumanEval、SpeedBench の各ベンチマークで、従来の EAGLE-3 と比較して 1.05 倍から 1.69 倍の高速化を達成しました。現在、並列推測デコーディング(speculative decoding)の可能性を開くために vLLM に統合されており、実世界での展開を加速する準備ができています。
P-EAGLE は、K 個のドラフトトークンを単一の順方向パスで生成します。図 2 はそのアーキテクチャを示しており、以下の 2 つのステップから構成されています。
ステップ 1:プリフィリング。ターゲットモデルはプロンプトを処理し、通常の推論時と同様に新しいトークンを生成します。この過程で、P-EAGLE はモデルの内部隠れ状態(hidden states)を捕捉します。具体的には、各プロンプト位置に対する h_prompt と、新たに生成されたトークンに対する h_context です。これらの隠れ状態は、ターゲットモデルが各位置で「知っている」内容を符号化したものであり、ドラフターの予測を導く役割を果たします。このステップは自己回帰型 EAGLE と同じです。
ステップ 2:P-EAGLE ドラフター。ドラフターは、各位置に対する入力を並列に構築します。各入力は、トークン埋め込みと隠れ状態を連結したものです。
プロンプト位置については、入力ペアが各プロンプトトークンの埋め込み emb(p) と、ターゲットモデルからの対応する h_prompt を組み合わせています。自己回帰型 EAGLE と同じ規約に従い、位置は 1 つずらされます。位置 i は、位置 i-1 のトークンと隠れ状態を受け取り、位置 i のトークンを予測可能にします。
位置 1 の Next-Token-Prediction (NTP) では、新たに生成されたトークンの埋め込み emb(new) と h_context をペアにして入力します。この位置は、標準的な自己回帰型 EAGLE と同様に動作します。
位置 2 から K までの Multi-Token-Prediction (MTP) では、必要な入力であるトークン埋め込みと隠れ状態がまだ存在しません。P-EAGLE はこれらに、学習可能なパラメータとして、共有されるマスクトークンの埋め込み emb(mask) と共有される隠れ状態 h_shared を割り当てます。これらはトレーニング中に学習された固定ベクトルであり、ニュートラルなプレースホルダーとして機能します。
位置はまとめて N 個のトランスフォーマー層を通過し、その後言語モデルヘッドを経て、単一の順方向パスでドラフトトークン t1, t2, t3, t4 を予測します。
図 2: P-EAGLE アーキテクチャの概要。
長文シーケンスにおける P-EAGLE のトレーニング
現代の推論モデルは長い出力を生成します。図 3 に示すように、GPT-OSS 120B は UltraChat データセット上で、プロンプトを含むシーケンスの中央値が 3,891 トークン、P90 が 10,800 トークンとなります。効果的な推論を行うためには、ドラフトモデルは同等のコンテキスト長でトレーニングされる必要があります。
図 3: GPT-OSS 120B を用いた UltraChat データセット上のシーケンス長(プロンプト+生成)の分布。推論レベル:ミディアム。
重要な課題の一つは、並列ドラフト作成がトレーニング中にメモリ要件を増幅させることです。長さ N のシーケンスに対して K 個の並列グループをトレーニングすると、合計で N × K の位置が生じます。N = 8,192、K = 8 の場合、単一のトレーニング例には 65,536 個の位置が含まれます。アテンション(attention)では各位置がすべての有効な位置にアテンションを向ける必要があるため、65K × 65K は 40 億要素以上となり、bf16 で計算すると 8GB のメモリを消費します。
Position sampling [An et al., 2025] はランダムに位置をスキップすることでメモリ削減を実現しますが、過度なスキップはドラフトの品質を低下させます。勾配累積(gradient accumulation)はメモリ制約下でのトレーニングにおける標準的な解決策ですが、これは異なるトレーニング例間で分割されるものです。単一のシーケンスがメモリ容量を超えた場合、分割できる対象が存在しません。
P-EAGLE は、シーケンス内分割のためのシーケンス分割アルゴリズムを導入しています。このアルゴリズムは N × K の位置シーケンスを連続するチャンクに分割し、チャンクの境界間でも正しいアテンション依存関係を維持しながら、同一シーケンス内の複数のチャンク間で勾配を累積します。詳細については P-EAGLE paper を参照してください。
vLLM における実装
並列ドラフト作成の課題
多くの推測デコーディング(speculative decoding)設定では、ドラフティングと検証が同じリクエストごとのトークンレイアウトを共有しています。これは主に EAGLE に当てはまります:ドラフターは、検証者が確認する予定のウィンドウ(K 個のドラフトされたトークンと 1 つの追加サンプリングトークン)を既に消費しているためです。
並列ドラフト生成はこの一貫性を崩します。1 つのドラフター順次パスで K トークンを予測するために、MASK プレースホルダー(例:[token, MASK, MASK, …])を付加します。これらの追加位置はドラフト生成専用であり、その結果、ドラフトバッチの形状が検証バッチの形状と一致しなくなります。検証メタデータを再利用できないため、バッチメタデータを再構築する必要があります。入力トークン ID、隠れ状態(hidden states)、および位置情報を拡張してマスクトークン/埋め込み用のスロットを挿入し、各リクエストごとに位置を増分させた後、更新された位置からスロットマッピングと各リクエストの開始インデックスを再計算します。
The Triton Kernel
バッチメタデータの再構築に伴うオーバーヘッドを相殺するため、ターゲットモデルバッチをコピーして拡張することでドラフターの入力バッチを GPU 上で直接作成する融合された Triton カーネルを実装しました。このカーネルは 1 回のパスで、ターゲットバッチから前のトークン ID と位置情報を新しい宛先スロットにコピーし、ターゲットモデルによってサンプリングされた各リクエストごとのボーナストークンを挿入します。その後、追加の並列ドラフト生成スロットを特別な MASK トークン ID で埋めます。最後に、軽量のメタデータを生成します。これには、拒否されたトークンのマスク、並列ドラフト生成スロット用のマスク済みトークンのマスク、ドラフトトークンのサンプリング用新しいトークンインデックス、および隠れ状態のマッピングが含まれます。
このロジックは本来、多数の GPU 演算(コピー/散乱 + 挿入 + 埋め込み + マスク + リマッピング)を必要とします。これを 1 つのカーネルに融合することで、起動オーバーヘッドと追加メモリアクセスを削減し、ドラフト生成の設定コストを低く抑えています。
Hidden State Management
EAGLE ベースの手法において、隠れ状態をドラフトモデルに渡す場合、並列ドラフティングではこれらのフィールドを別々に埋める処理が行われます。隠れ状態は入力のバッチ残りの部分よりも大幅に大きいため、作業を分割します:Triton カーネルがマッピングを出力し、専用のコピーカーネルが学習された隠れ状態プレースホルダーをマスクトークンのスロットへブロードキャストします。
コピー対象の隠れ状態を新しい位置へ転送する
self.hidden_states[out_hidden_state_mapping] = target_hidden_states
学習された並列ドラフティング用隠れ状態でマスクされた位置を埋める
mask = self.is_masked_token_mask[:total_num_output_tokens]
torch.where(
mask.unsqueeze(1),
self.parallel_drafting_hidden_state_tensor,
self.hidden_states[:total_num_output_tokens],
out=self.hidden_states[:total_num_output_tokens],
)
parallel_drafting_hidden_state_tensor は、モデルの mask_hidden バッファから読み込まれ、これらの位置で将来のトークンを予測すべきであることをモデルに伝える学習された表現です。
KV キャッシュスロットマッピングについては、有効なトークンは通常のスロット割り当てを受け、拒否されたトークンは誤ったキャッシュ書き込みを防ぐために PADDING_SLOT_ID (-1) にマッピングされます。CUDA グラフにおいては、並列ドラフティングによって導入されるより大きなドラフトバッチに対応するため、キャプチャ範囲を K × max_num_seqs だけ拡張します。
P-EAGLE の vLLM ベンチマーク
P-EAGLE は GPT-OSS-20B 上でトレーニングされ、3 つのベンチマークで評価されました。これらは、多ターン指示追従のための MT-Bench、長期コード生成のための SPEED-Bench Code、および関数レベルのコード合成のための HumanEval です。P-EAGLE は、低同時実行性 (c=1) で 55–69% のスループット向上を実現し、高同時実行性 (c=64) でも 5–25% の向上を維持します。これは、公開されているバニラの EAGLE-3 チェックポイント と比較した結果です。これらの結果は図 4-6 に示されています。
P-EAGLE のドラフターは、最大 10 トークンを並列で予測するようにトレーニングされた軽量な 4 レイヤーモデルです。性能評価のため、同時実行性レベル C ∈ {1,2,4,8,16,32,64} にわたって推測深さ K ∈ {3,5,7} をスウィープします。私たちの目標は、P-EAGLE とバニラの EAGLE-3 の両方に対して最適なデプロイ構成を特定することです。線形ドラフティング (Linear drafting) は P-EAGLE とバニラの EAGLE-3 の両方に使用されます。この文脈において、「best P-EAGLE」と「best EAGLE-3」は、ピークスループットを実現する構成を指します。これらは、特定の推測深さ K における秒間トークン数 (TPS) で測定されます。各手法について、与えられたサービング条件下で TPS を最大化する K を選択します。
一貫したパターンが浮かび上がります。P-EAGLE は、すべての並列度レベルにおいて K=7 で TPS(1 秒あたりのトークン生成数)のピークに達します。一方、バニラ版 EAGLE-3 は K=3 で最高 TPS を達成し、その改善された深さは並列度に応じてより高い値へと時折シフトします。この振る舞いは、並列ドラフティング(草案作成)の本質的な優位性を反映しています。P-EAGLE はすべての K 個のドラフトトークンを単一の順方向パスで生成するため、追加の逐次的オーバーヘッドを伴うことなく、より深い推測の恩恵を受けることができます。一方、自己回帰型ドラフターは、推測トークンをステップごとに生成する必要があり、これがより大きな K 値への効率的なスケーリング能力を制限します。
すべての実験は、vLLM を用いた以下のサービング構成で、1 つの NVIDIA B200(Blackwell)GPU 上で実施されました。
VLLM_USE_FLASHINFER_MOE_MXFP4_MXFP8=1
vllm serve openai/gpt-oss-20b \
--speculative-config '{
"method": "eagle3",
"model": "amazon/GPT-OSS-20B-P-EAGLE",
"num_speculative_tokens": 7,
"parallel_drafting": true}' \
--port 8000 \
--max-num-seqs 1024 \
--max-model-len 100000 \
--max-num-batched-tokens 100000 \
--max-cudagraph-capture-size 4096 \
--no-enable-prefix-caching \
--no-enable-chunked-prefill \
--kv-cache-dtype fp8 \
--async-scheduling \
--stream-interval 20
注意。現在、EAGLE ドラフターを使用して GPT-OSS-20B をサービングするには、1 行分の vLLM パッチが必要です (PR#36684)。起動前にこれを適用してください。この修正は、今後の vLLM リリースに組み込まれる見込みです。
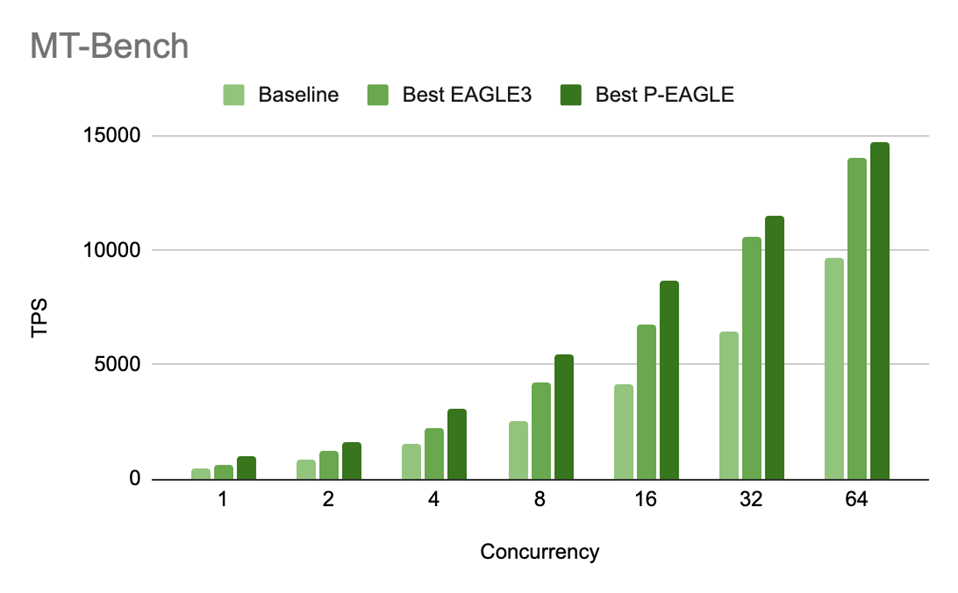
図 4: GPT-OSS-20B における P-EAGLE と EAGLE-3 の MT-Bench スループット (TPS) を並行度レベル別に比較した結果。P/E の速度向上比は以下の通りです:1.55 倍 (c=1)、1.29 倍 (c=2)、1.35 倍 (c=4)、1.28 倍 (c=8)、1.27 倍 (c=16)、1.09 倍 (c=32)、および 1.05 倍 (c=64)。
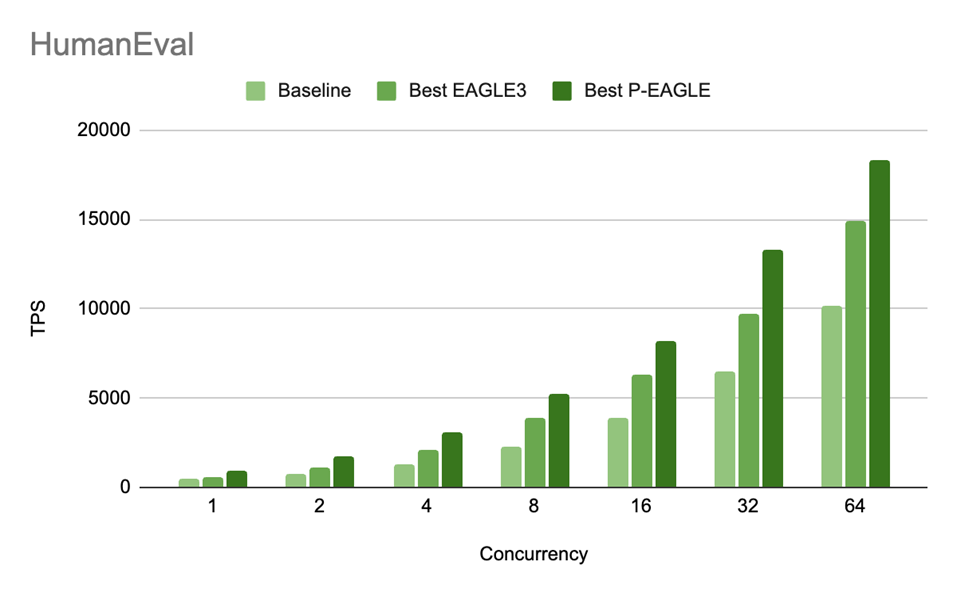
図 5: GPT-OSS-20B における P-EAGLE と EAGLE-3 の HumanEval スループット (TPS) を並行度レベル別に比較した結果。P/E の速度向上比は以下の通りです:1.55 倍 (c=1)、1.53 倍 (c=2)、1.45 倍 (c=4)、1.35 倍 (c=8)、1.31 倍 (c=16)、1.37 倍 (c=32)、および 1.23 倍 (c=64)。
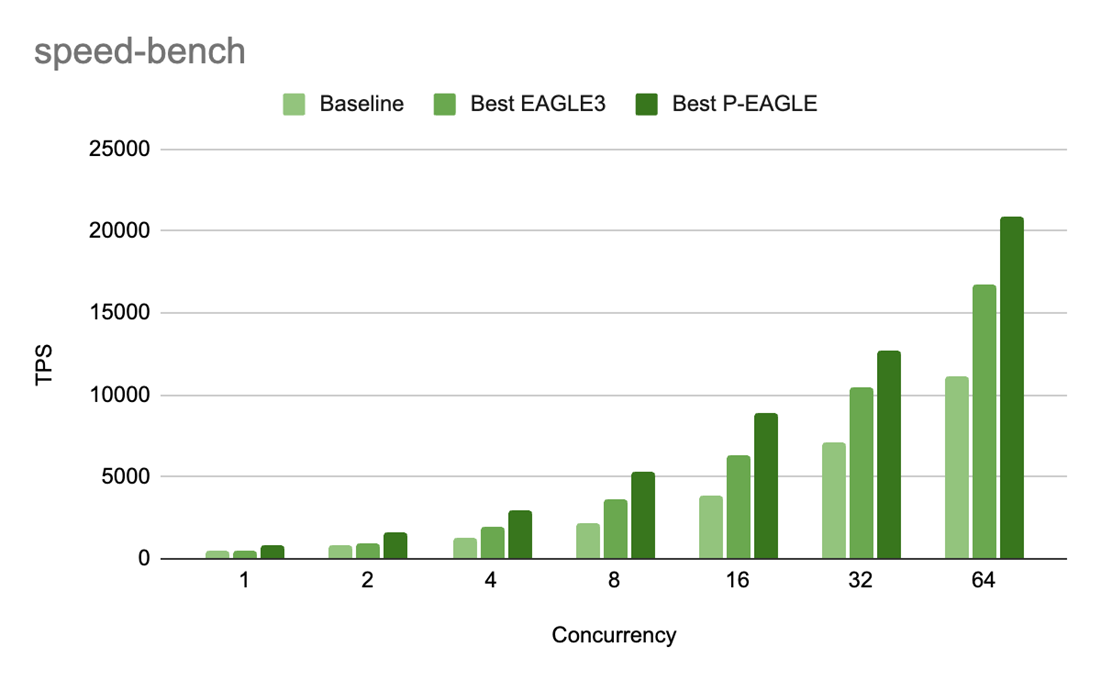
図 6: GPT-OSS-20B における P-EAGLE と EAGLE-3 の Speed-bench スループット (TPS) を並行度レベル別に比較した結果。P/E の速度向上比は以下の通りです:1.69 倍 (c=1)、1.61 倍 (c=2)、1.54 倍 (c=4)、1.45 倍 (c=8)、1.40 倍 (c=16)、1.22 倍 (c=32)、および 1.25 倍 (c=64)。
ドラフトのオーバーヘッドを削減するだけでなく、P-EAGLE のスループット向上は、推測ラウンドごとに検証者が受け入れる平均的なドラフトトークン数である「受容長(AL: Acceptance Length)」の改善によっても駆動されています。AL が高いほど、ドラフト作業のうち実際の出力となる割合が増え、結果として有効な OTPS/TPS が直接向上します。
以下の表は、GPT-OSS-20B における P-EAGLE とバニラ版 EAGLE-3 の AL を、3 つのベンチマークで比較したものです。
P-EAGLE (AL):
Config HumanEval SPEED-Bench MT-Bench
K=3 3.02 2.87 2.87
<td style="padding: 10px;border: 1px sol
原文を表示
EAGLE is the state-of-the-art method for speculative decoding in large language model (LLM) inference, but its autoregressive drafting creates a hidden bottleneck: the more tokens that you speculate, the more sequential forward passes the drafter needs. Eventually those overhead eats into your gains. P-EAGLE removes this ceiling by generating all K draft tokens in a single forward pass, delivering up to 1.69x speedup over vanilla EAGLE-3 on real workloads on NVIDIA B200.
You can unlock this performance gain by downloading (or training) a parallel-capable drafter head, adding “parallel_drafting”: true on you vLLM serving pipeline. Pre-trained P-EAGLE heads are already available on HuggingFace for GPT-OSS 120B, GPT-OSS 20B, and Qwen3-Coder 30B, so you can start today.
In this post, we explain how P-EAGLE works, how we integrated it into vLLM starting from v0.16.0 (PR#32887), and how to serve it with our pre-trained checkpoints. Here is the list of artifacts used:
- ArXiv Paper
- HuggingFace Models (GPT-OSS 120B, GPT-OSS 20B, Qwen3-Coder-30B-A3B-Instruct)
- vLLM Integration Unified Parallel Drafting
- vLLM-Speculators (RFC, PR)
Figure 1: P-EAGLE over other methods on SPEED-BENCH with Concurrency of 1 on one NVIDIA B200 card.
Quick start P-EAGLE:
You can enable parallel drafting with a single configuration change in the SpeculativeConfig class:
# vllm/config/speculative.py
parallel_drafting: bool = TrueHere’s an example command in vLLM to enable parallel drafting with P-EAGLE as drafter:
vllm serve openai/gpt-oss-20b \
--speculative-config '{"method": "eagle3", "model": "amazon/gpt-oss-20b-p-eagle", "num_speculative_tokens": 5, "parallel_drafting": true}'EAGLE’s Drafting Bottleneck
EAGLE achieves 2–3× speedups over standard autoregressive decoding and is widely deployed in production inference frameworks including vLLM, SGLang, and TensorRT-LLM.EAGLE drafts tokens autoregressively. To produce K draft tokens, it requires K forward passes through the draft model. As drafter models get better at drafting long outputs, this drafting overhead becomes significant—the drafter’s latency scales linearly with speculation depth, constraining how aggressively we can speculate.
Our Approach: Parallel-EAGLE (P-EAGLE)
We present P-EAGLE, which transforms EAGLE from autoregressive to parallel draft generation. On B200 GPUs, P-EAGLE achieves 1.05×–1.69× speedup over vanilla EAGLE-3 on GPT-OSS 20B over MT-Bench, HumanEval, and SpeedBench. It is now integrated into vLLM to unlock parallel speculative decoding, and ready to accelerate real-world deployments.
P-EAGLE generates the K draft tokens in a single forward pass. Figure 2 shows the architecture, which consists of two steps.
Step 1: Prefilling. The target model processes the prompt and generates a new token, as it would during normal inference. Along the way, P-EAGLE captures the model’s internal hidden states: h_prompt for each prompt position, and h_context for the newly generated token. These hidden states encode what the target model “knows” at each position and will guide the drafter’s predictions. This step is identical to autoregressive EAGLE.
Step 2: P-EAGLE Drafter. The drafter constructs inputs for each position in parallel. Each input consists of a token embedding concatenated with a hidden state.
For prompt positions, the input pairs each prompt token embedding emb(p) with its corresponding h_prompt from the target model. Following the same convention as autoregressive EAGLE, positions are shifted by one. Position i receives the token and hidden state from position i-1, enabling it to predict the token at position i.
For position 1, Next-Token-Prediction (NTP), the input pairs the newly generated token embedding emb(new) with h_context. This position operates identically to the standard autoregressive EAGLE.For positions 2 through K, Multi-Token-Prediction (MTP), the required inputs—the token embedding and hidden state—do not yet exist. P-EAGLE fills these with two learnable parameters: a shared mask token embedding emb(mask) and a shared hidden state h_shared. These are fixed vectors learned during training that serve as neutral placeholders.
Positions pass together through N transformer layers, then through the language model head to predict draft tokens t1, t2, t3, and t4 in a single forward pass.
Figure 2: P-EAGLE architecture overview.
Training P-EAGLE on Long Sequences
Modern reasoning models produce long outputs. As shown in Figure 3, GPT-OSS 120B generates sequences (including prompts) with a median length of 3,891 tokens and P90 of 10,800 tokens on the UltraChat dataset. Draft models must be trained on matching context lengths to be effective at inference.
Figure 3: Sequence length (prompt + generation) distribution on UltraChat dataset with GPT-OSS 120B. Reasoning level: Medium.
A key challenge is that parallel drafting amplifies memory requirements during training. Training K parallel groups on a sequence of length N creates N × K total positions. With N = 8,192 and K = 8, a single training example contains 65,536 positions. Attention requires each position to attend to every valid position—65K × 65K means over 4 billion elements, consuming 8GB in bf16.
Position sampling [An et al., 2025] reduces memory by randomly skipping positions, but skipping too aggressively degrades draft quality. Gradient accumulation is the standard solution for memory-constrained training, but it splits across different training examples. When a single sequence exceeds memory, there’s nothing to split.
P-EAGLE introduces a sequence partition algorithm for intra-sequence splitting. The algorithm divides the N × K position sequence into contiguous chunks, maintains correct attention dependencies across chunk boundaries, and accumulates gradients across chunks of the same sequence. For details, see the P-EAGLE paper.
Implementation in vLLM
Parallel drafting challenges
In many speculative decoding setups, drafting and verification share the same per-request token layout. That’s mostly true for EAGLE: the drafter consumes a window that already matches what the verifier will check; K drafted tokens and one additional sampled token.
Parallel drafting breaks that consistency. To predict K tokens in one drafter forward pass, we append MASK placeholders (for example, [token, MASK, MASK, …]). Those extra positions exist only for drafting, so the draft batch shape no longer matches the verification batch shape. Because we can’t reuse verification metadata, we must rebuild the batch metadata. We expand the input token IDs, hidden states, and positions to insert slots for mask tokens/embeddings, increment positions per request, then recompute the slot mapping and per-request start indices from the updated positions.
The Triton Kernel
To offset the overhead of rebuilding the batch metadata, we implement a fused Triton kernel that populates the drafter’s input batch on-GPU by copying and expanding the target-model batch. In one pass, the kernel copies the previous token IDs and positions from the target batch into new destination slots and inserts the per-request bonus token sampled by the target model. It then fills the extra parallel-drafting slots with a special MASK token ID. Finally, it generates lightweight metadata: a rejected-token mask, a masked-token mask for parallel drafting slots, new-token indices for sampling draft tokens, and a hidden-state mapping.
This logic would otherwise be many GPU ops (copy/scatter + insert + fill + mask + remap). Fusing it into one kernel reduces launch overhead and extra memory traffic, keeping the drafting setup cheap.
Hidden State Management
For EAGLE-based methods that pass hidden states to the draft model, parallel drafting handles populating these fields separately. Since hidden states are significantly larger than the rest of the input batch, we split the work: the Triton kernel outputs a mapping, and a dedicated copy kernel broadcasts the learned hidden state placeholder into the mask token slots.
# Copy target hidden states to their new positions
self.hidden_states[out_hidden_state_mapping] = target_hidden_states
# Fill masked positions with the learned Parallel Drafting hidden state
mask = self.is_masked_token_mask[:total_num_output_tokens]
torch.where(
mask.unsqueeze(1),
self.parallel_drafting_hidden_state_tensor,
self.hidden_states[:total_num_output_tokens],
out=self.hidden_states[:total_num_output_tokens],
)The parallel_drafting_hidden_state_tensor is loaded from the model’s mask_hidden buffer, a learned representation that tells the model these positions should predict future tokens.
For KV cache slot mapping, valid tokens receive normal slot assignment while rejected tokens are mapped to PADDING_SLOT_ID (-1) to prevent spurious cache writes. For CUDA graphs, we extend the capture range by K × max_num_seqs to accommodate the larger draft batch introduced by parallel drafting.
vLLM Benchmarking on P-EAGLE
We train P-EAGLE on GPT-OSS-20B and evaluate across three benchmarks: MT-Bench for multi-turn instruction following, SPEED-Bench Code for long-term code generation, and HumanEval for function-level code synthesis. P-EAGLE delivers 55–69% higher throughput at low concurrency (c=1), with gains of 5–25% sustained at high concurrency (c=64), compared to the publicly available vanilla EAGLE-3 checkpoint. Results are shown in Figure 4-6.
The P-EAGLE drafter is a lightweight 4-layer model trained to predict up to 10 tokens in parallel. To evaluate performance, we sweep speculation depths K ∈ {3,5,7} across concurrency levels C ∈ {1,2,4,8,16,32,64}. Our goal is to identify the right deployment configuration for both P-EAGLE and vanilla EAGLE-3. Linear drafting is used for both P-EAGLE and vanilla EAGLE-3. In this context, “best P-EAGLE” and “best EAGLE-3” refer to the configurations that achieve peak throughput. These are measured in tokens per second (TPS), for a given speculation depth K. For each method, we select K that maximizes TPS under the given serving conditions.
A consistent pattern emerges. P-EAGLE achieves peak TPS at K=7 across all concurrency levels. In contrast, vanilla EAGLE-3 reaches its highest TPS at K=3, with its improved depth occasionally shifting toward higher values depending on concurrency. This behavior reflects a fundamental advantage of parallel drafting. P-EAGLE generates all K draft tokens in a single forward pass, allowing it to benefit from deeper speculation without incurring additional sequential overhead. Autoregressive drafters, by contrast, must generate speculative tokens step-by-step, which limits their ability to efficiently scale to larger K.
All experiments are conducted on one NVIDIA B200 (Blackwell) GPU using vLLM with the following serving configuration.
VLLM_USE_FLASHINFER_MOE_MXFP4_MXFP8=1 \
vllm serve openai/gpt-oss-20b \
--speculative-config '{
"method": "eagle3",
"model": "amazon/GPT-OSS-20B-P-EAGLE",
"num_speculative_tokens": 7,
"parallel_drafting": true}' \
--port 8000 \
--max-num-seqs 1024 \
--max-model-len 100000 \
--max-num-batched-tokens 100000 \
--max-cudagraph-capture-size 4096 \
--no-enable-prefix-caching \
--no-enable-chunked-prefill \
--kv-cache-dtype fp8 \
--async-scheduling \
--stream-interval 20Note. Serving GPT-OSS-20B with EAGLE drafters currently requires a one-line vLLM patch (PR#36684). Apply it before launching. This fix is expected to land in an upcoming vLLM release.
Figure 4: MT-Bench throughput (TPS) for P-EAGLE vs EAGLE-3 on GPT-OSS-20B across concurrency levels. The P/E speedup ratios are: 1.55x (c=1), 1.29x (c=2), 1.35x (c=4), 1.28x (c=8), 1.27x (c=16), 1.09x (c=32), and 1.05x (c=64).
Figure 5: HumanEval throughput (TPS) for P-EAGLE vs EAGLE-3 on GPT-OSS-20B across concurrency levels. The P/E speedup ratios are: 1.55x (c=1), 1.53x (c=2), 1.45x (c=4), 1.35x (c=8), 1.31x (c=16), 1.37x (c=32), and 1.23x (c=64).
Figure 6: Speed-bench throughput (TPS) for P-EAGLE vs EAGLE-3 on GPT-OSS-20B across concurrency levels. The P/E speedup ratios are: 1.69x (c=1), 1.61x (c=2), 1.54x (c=4), 1.45x (c=8), 1.40x (c=16), 1.22x (c=32), and 1.25x (c=64).
In addition to reducing drafting overhead, P-EAGLE’s throughput gains are also driven by better acceptance length (AL), the average number of draft tokens accepted by the verifier per speculation round. Higher AL means more of the draft work turns into real output, which directly boosts effective OTPS/TPS.
The following tables compare AL for P-EAGLE and vanilla EAGLE-3 on GPT-OSS-20B across our three benchmarks:
P-EAGLE (AL):
Config
HumanEval
SPEED-Bench
MT-Bench
K=3
3.02
2.87
2.87
<td style="padding: 10px;border: 1px sol
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み