Bark.comとAWSがスケーラブルな動画生成ソリューションを構築する方法
Bark.comはAWSのSageMakerとBedrockを活用し、マーケティング用動画コンテンツの制作を数週間から数時間に短縮するスケーラブルなAI生成ソリューションを構築した。
キーポイント
制作時間の劇的短縮
従来の手動ワークフローでは数週間かかった動画制作を、AI活用により数時間単位に削減するパイプラインを実現した。
パーソナライゼーションのスケールアップ
キャンペーンごとに複数の顧客マイクロセグメントに対応可能な高ボリュームのクリエイティブ生成を可能にし、A/Bテストの高速化を支えた。
ブランド一貫性と品質基準の維持
生成されたコンテンツでも音声・視覚的なブランドアイデンティティを保持し、専門制作に匹敵する品質スコアを達成した。
影響分析・編集コメントを表示
影響分析
本記事は、大規模言語モデルやマルチモーダルAIを既存のクラウドインフラと統合し、マーケティング業務に実装する実践的なロードマップを示している。企業にとって、AI導入を「実験段階」から「スケーラブルな運用フェーズ」へ移行する際の具体的な設計指針となるため、クラウドベンダーやエンタープライズDX推進企業に広く影響を与える可能性がある。
編集コメント
AWS公式ブログ特有の最適化された事例ではあるものの、SageMakerとBedrockを連携させた動画生成パイプラインの設計思想は、実務でのAI活用検討に十分参考になる。技術詳細が省略されている点は補完が必要だが、ビジネス要件とAIアーキテクチャの橋渡しとして価値が高い。
*この投稿は、Bark.com の Hammad Mian と Joonas Kukkonen と共著です。*
動画コンテンツの作成をスケールする際、多くの企業が品質を維持しながら制作時間を短縮するという課題に直面します。本稿では、Bark.com と AWS がこの問題如何解决に取り組んだ様子を紹介し、AI 駆動型コンテンツ生成のための再現可能なアプローチを示します。Bark.com は Amazon SageMaker および Amazon Bedrock を活用して、マーケティングコンテンツのピップラインを数週間から数時間に短縮しました。
Bark は毎週、庭園管理から在宅介護まで、複数のカテゴリにわたって専門サービスを提供する人々を何千人もの人と結びつけています。Bark のマーケティングチームがミドルファネル(検討段階)のソーシャルメディア広告への展開機会を見出した際、スケールに関する課題に直面しました。効果的なソーシャルキャンペーンには迅速な A/B テストのために大量のパーソナライズされたクリエイティブコンテンツが必要ですが、手動での制作ワークフローではキャンペーンごとに数週間を要し、複数の顧客セグメント向けの変種に対応できませんでした。
同様のコンテンツスケールの課題にお困りの場合、このアーキテクチャパターンが有用な出発点となり得ます。AWS 生成 AI イノベーションセンターと連携して Bark が開発した AI 駆動型コンテンツ生成ソリューションは、実験的な試行において制作時間の大幅な短縮とコンテンツ品質スコアの向上を実証しました。この協力の目標は以下の 4 つでした:
- 制作期間 – 数週間から数時間に短縮
- パーソナライゼーションの規模拡大 – キャンペーンごとに複数の顧客マイクロセグメントに対応可能
- ブランドの一貫性 – 生成されたコンテンツ全体で声質やビジュアルアイデンティティを維持
- 品質基準 – 専門的に制作された広告に匹敵する品質を実現
本記事では、私たちが構築した技術アーキテクチャ、成功に寄与した主要な設計判断、そして達成可能な測定結果について詳しく解説します。これにより、同様のソリューションを実装するための青写真を提供します。
ソリューション概要
Bark は AWS 生成 AI イノベーションセンターと協力し、これらのコンテンツスケーリング課題に対処できるソリューションを開発しました。チームは AWS サービスとカスタマイズされた AI モデルを活用したシステムを設計しました。以下の図にソリューションアーキテクチャを示します。
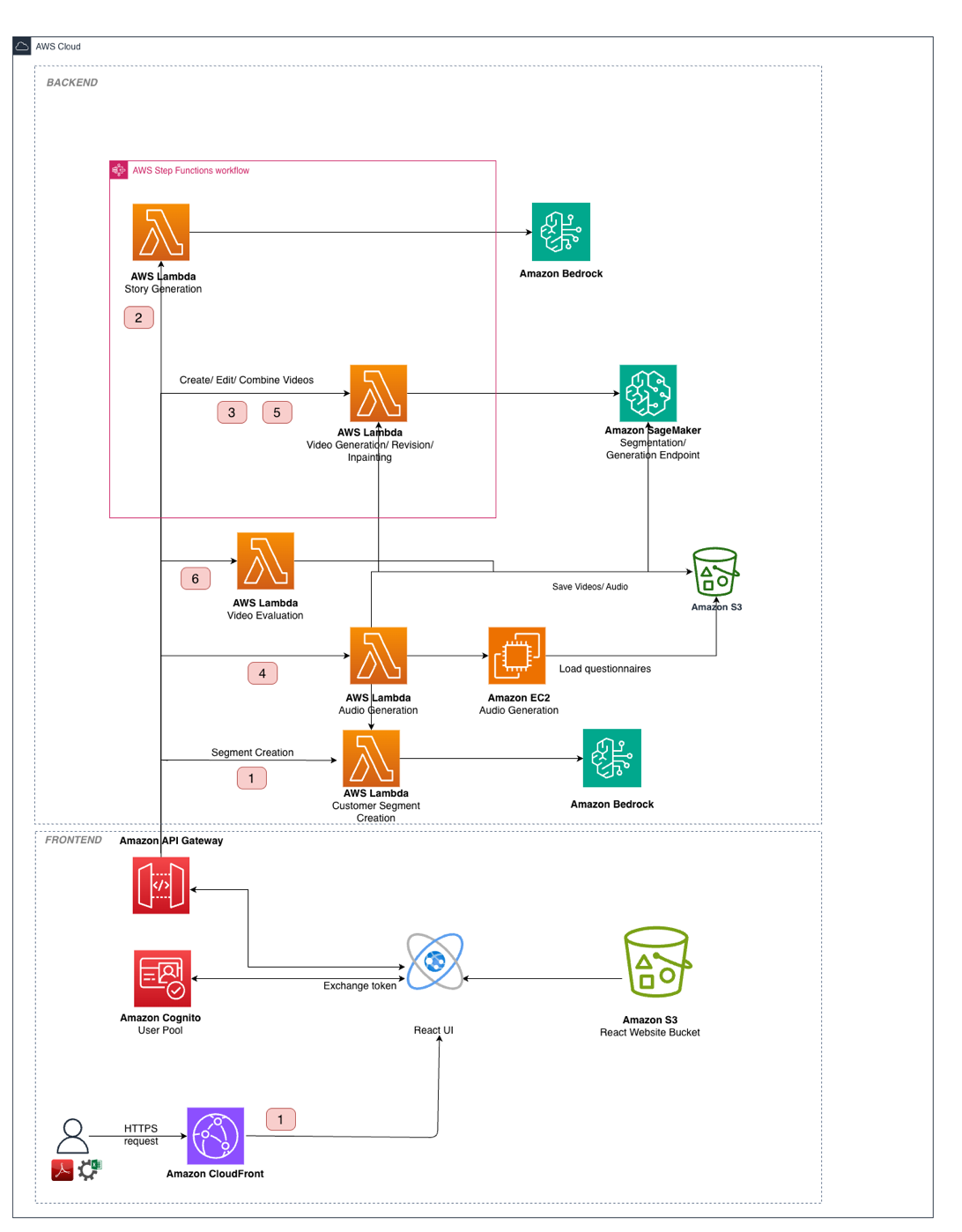
本ソリューションアーキテクチャは、以下の統合レイヤーで構成されています。
- データおよびストレージ層 – Amazon Simple Storage Service (Amazon S3) は、トレーニングデータ、生成されたビデオセグメント、参照画像、最終出力などのアセットを保存します。モデルアーティファクトとカスタム推論コンテナは、Amazon Elastic Container Registry (Amazon ECR) に保存されます。
- 処理層 – AWS Lambda が多段階パイプラインをオーケストレーションし、AWS Step Functions が7ステップの生成プロセス全体にわたってワークフロー状態を管理します。Anthropic の Claude Sonnet 3.7 を備えた Amazon Bedrock は、顧客セグメンテーション、ストーリー生成、品質評価を含むテキスト生成タスクを担当します。
- GPU コンピューティング層 – Wan 2.1 Text2Video-14B を確実に提供するために、単一の p4de.24xlarge SageMaker インスタンス上の8つの GPU にモデルをシャードするマルチ GPU 推論コンテナを実行しています。これはテンソル並列化 (tensor parallelism) を使用して実現されています。リクエスト処理には TorchServe がエンドポイントとして前面に配置され、torchrun は各 GPU ごとに1つのワーカープロセスを開始します。テキストエンコーダーと拡散トランスフォーマーには、Fully Sharded Data Parallel (FSDP) シャーディング—a technique for splitting the model components across GPUs—を採用しています。これはモデルコンポーネントを GPU に分割する技術であり、重みを CPU へオフロードすることなく GPU メモリ制限内に収めるために使用されます。ビデオ拡散は長時間実行されるため、エンドポイントはモデルの読み込み時間を許容し、 premature restarts (早期再起動) を防ぐために、拡張された推論タイムアウトとより長いコンテナ起動ヘルスチェックウィンドウでチューニングされています。Amazon Elastic Container Service (Amazon ECS) コンテナは、GPU 対応の g5.2xlarge インスタンス上でナレーター音声生成のための音声合成を処理し、アイドル期間中はゼロまでスケールダウンします。
- ユーザーインターフェース層 – Amazon Cognito 認証を備えた React フロントエンドにより、マーケティングチームが自然言語コマンドを通じて生成されたコンテンツのレビュー、編集、承認を行えるビデオスタジオインターフェースが提供されます。
クリエイティブ・アイデア生成パイプライン
全体のアーキテクチャについてご理解いただけたところで、ご自身の環境においてこのクリエイティブ・アイデア生成パイプラインを実装する方法を見ていきましょう。このパイプラインは、顧客のアンケートデータを基に、3 つの段階を経て制作可能なストーリーボードへと変換します。
第 1 ステージ:顧客セグメントの生成
パイプラインは、Amazon Bedrock を用いて Anthropic の Claude Sonnet 3.7(大規模言語モデル)で Bark の顧客アンケートデータを分析することから始まります。この大規模言語モデル(LLM: Large Language Model)が調査回答を処理し、人口統計、動機、課題、意思決定の要因といった構造化された属性を持つ明確な顧客ペルソナを特定します。例えば、在宅介護カテゴリーでは、以下のようなセグメントが特定されました:
- 圧倒される家族介護者 – 仕事と高齢の親の介護の両立に追われる 40~50 代の成人で、信頼性と安心感を最優先する
- 自立志向の高齢者 – 自律性を維持したいと考えているが、時折の支援が必要であることを認識している高齢者
各セグメントのプロファイルは、人間が関与するプロセス(ヒューマン・イン・ザ・ループ)を通じて UI でレビューされ、特定された聴衆の特徴に共鳴する広告を作成するための、後のクリエイティブ・アイデア生成への入力として機能します。
ステージ 2:クリエイティブ・ブリーフの生成
ビジネスカテゴリとターゲットセグメントに基づき、システムは抽象度の異なる 4〜6 のクリエイティブコンセプトを生成します。これには、直訳的なアプローチと比喩的なアプローチの両方を促すことが含まれます。発散的思考を促進するため、モデルには高温サンプリング(0.8〜1)を設定しています。モデルは思考連鎖推論を採用し、ブリーフを生成する前に、コンセプトの関連性、エンゲージメントの可能性、そして娯楽価値を明示的に評価します。これにより、同じ商業的目標に対して多様な物語アプローチが生まれます。具体的には、ストレートな証言形式や、感情的に共鳴する比喩的なストーリーなどが挙げられます。
ステージ 3:ストーリーボードの洗練
最終段階では、汎用的なクリエイティブ・ブリーフをセグメント固有のストーリーボードへと変換します。どの属性を強調するかをランダムに決定する確率的特徴サンプリング機構が機能し、特定の動機や課題に対応しつつも多様性を維持しながら、どの顧客セグメントの属性を強調すべきかを特定します。システムは、最終的なストーリーボード(完全なオーディオビジュアル仕様を含む:シーン記述、カメラ指示、ナレーションテキスト、タイミング)を生成する前に、プロンプトによる推論を通じてブリーフとセグメントの明示的なマッチングを実行します。この段階での人間によるレビューにより、制作開始前のブランド適合性が確認されます。
シーン全体での視覚的一貫性の維持
30 秒の広告には通常 4〜6 の異なるシーンが含まれており、これらは個別に生成するのが最適です。注意深い調整を行わない場合、AI モデルは*意味的ドリフト*(semantic drift)を示し、キャラクターの外見が変化したり、背景が予期せず変わったり、ブランド要素が一貫性を失ったりします。私たちのソリューションでは、2 段階の一貫性フレームワークを実装しています。
意味的一貫性の確保
クリエイティブブリーフを動画プロンプトに変換するには、3 つの工程を経るプロセスが必要です:
- エレメント抽出 – LLM(大規模言語モデル)がストーリーボードを分析し、アクター、小道具、オブジェクト、場所といった原子レベルの装飾要素を特定し、シーン間で一貫性を保つ必要があるものをフラグ付けします。
- ブループリン生成 – 各繰り返し出現するエレメントについて、システムは詳細な仕様ブループリント(設計図)を生成し、標準的な視覚的表現を確立します。
- プロンプト変換 – 高レベルのシーン記述を、詳細な動画生成プロンプトに変換します。これには、物語への忠実性を保つための元のクリエイティブブリーフと、視覚的一貫性のための標準化された装飾仕様の両方が組み込まれます。
視覚的一貫性の確保
詳細なプロンプトによる意味的一貫性はドリフトを大幅に削減しますが、動画生成モデルは同じプロンプト仕様であってもなお解釈の余地を示すことがあります。この制限に対処するため、以下の図に示すように、参照画像の抽出と伝播パイプラインを実装しています。
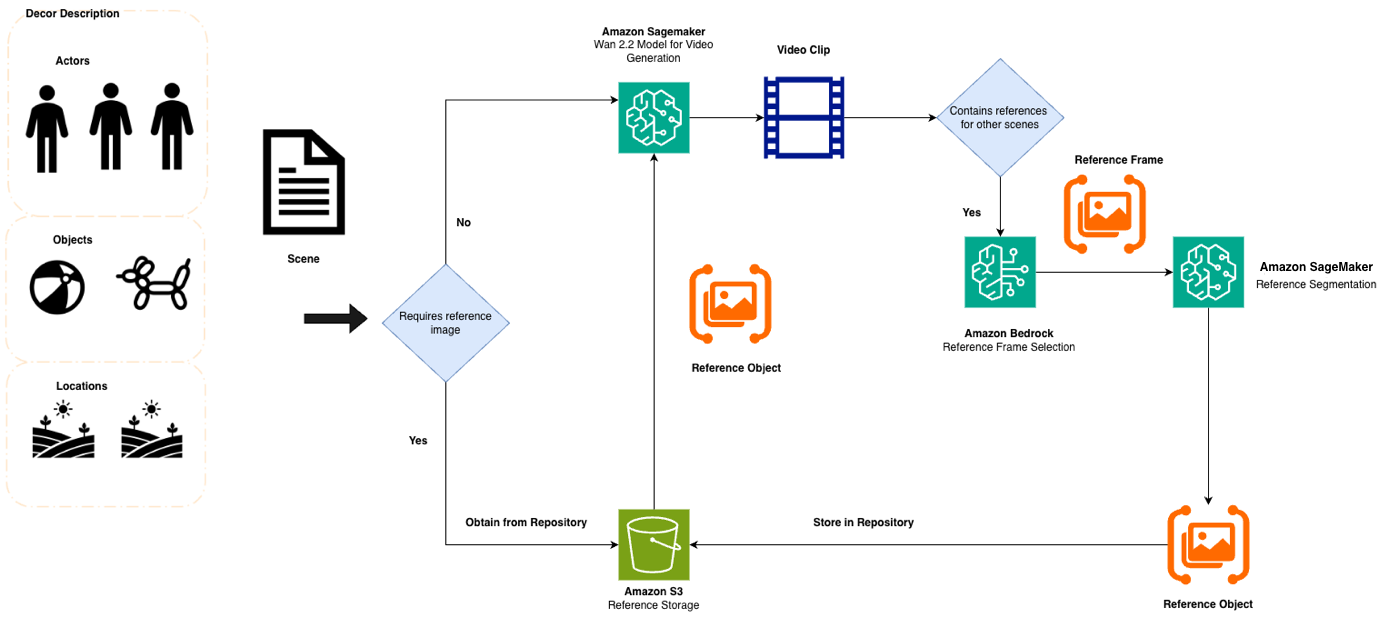
パイプラインは以下のステージで構成されています:
- 最適フレームの特定 – Amazon Nova Premier が生成されたシーンを分析し、ターゲット要素が最も明確に現れるフレームを特定します。
- エレメントセグメンテーション – オープンソースの Segment Anything Model を Amazon ECS にデプロイして、背景からターゲット要素を分離します。
- リファレンス伝播 – 抽出されたリファレンス画像は、Wan 2.2 のリファレンス・トゥ・ビデオ機能を使用して、後続の動画生成呼び出しに供給されます。
この二重制約アプローチ——詳細なプロンプトによる意味指定とリファレンス画像による視覚的指定を組み合わせるもの——は、体系的なアブレーションスタディを通じて検証された堅牢な一貫性フレームワークを生み出します。
動画生成パイプライン
このパイプラインは、テキスト、画像、動画、音声、オーバーレイグラフィックスの 5 つのモダリティをオーケストレーションし、シーンの要件に基づいて戦略的にモデルを選択します:
- リファレンス・トゥ・ビデオ合成 – 視覚的連続性が必要なシーンでは、抽出されたリファレンス画像と共に Wan 2.1 VACE-14B を使用します。
- テキスト・トゥ・ビデオ生成 – 新しい要素を導入するシーンでは、Wan 2.1 Text2Video-14B を使用します。
Step Functions ワークフローが生成シーケンスを制御し、依存するシーンの開始前にリファレンス画像が利用可能であることを確認します。
音声合成とグラフィック
音声合成には、GPU対応のECSインスタンス(g5.2xlarge)上でSesame AI LabのConversational Speech Modelを使用しています。ボイスクローニングには、Barkのブランドナレーターによる10秒間のリファレンスサンプルが必要であり、このモデルは話者エンベッディングを抽出して、その後の生成プロセスを条件付けます。Amazon ECSはアイドル期間中はゼロまでスケールするため、アクティブな生成ウィンドウ以外のコストを抑制できます。さらに、テキストオーバーレイとアクション誘導グラフィックには、Barkのブランドガイドラインとのタイポグラフィ的一貫性をサポートするテンプレートシステムが使用されており、これらの要素は最終組み立て時に合成されます。
品質評価ループ
Lambda内のLLM-as-a-judge(LLMを審査員として用いた)評価ループでは、各シーンを以下の3つの次元で評価します:
- ナラティブ準拠 – ストーリーボード記述への正確性
- ビジュアル品質 – アーティファクトや不整合の欠如
- ブランドコンプライアンス – ブランドガイドラインとの整合性
設定可能な品質閾値を下回るシーンは、ビジュアルリファレンス要素を保持したまま自動再生成がトリガーされます。この反復的な改良は、シーンが品質基準を満たすか、または人間のレビューが要求されるまで継続されます。
一貫性のあるメッセージングランディングページ
生成された動画と顧客セグメントを基盤として、パーソナライズされたランディングページを生成するエージェントシステムを作成しました。Strandsエージェントを使用して、以下のアクションを実行します:
- ページ用の TypeScript コードを生成する
- ユーザーが視聴した動画広告と直接関連していることを理解してもらうために、動画から最適なスクリーンショットを取得してページに含める
- 顧客セグメントに合わせて文言やデザインを修正する
結果
AI 生成コンテンツを Bark の既存キャンペーンライブラリと比較評価しました。以下の表にその結果をまとめます。
評価項目
AI 生成広告
既存キャンペーンライブラリ
ストーリー構造の整合性 (Story Structure Coherence)
6.9 ± 0.49
6.4 ± 0.74
独自性とエンゲージメント (Originality Engagement)
6.5 ± 1.23
5.2 ± 1.22
視覚的・空間的一貫性 (Visual Spatial Consistency)
6.9 ± 0.74
6.6 ± 0.75
*スコアは 10 点満点で、95% 信頼区間を示す*
これらの結果は、AI 生成コンテンツがより高い物語的整合性スコアを達成したことを示しており、階層的シーン計画アプローチの有効性が裏付けられました。独自性スコアの 25% の向上は、クリエイティブなアイデア創出パイプラインが新規性と商業的実現可能性のバランスに成功していることを示唆しています。参照画像伝播システムは、手動制作と比較して、キャラクターおよび環境の一貫性を測定可能なほど高いレベルで達成しました。
エンドツーエンドのこのパイプラインは、ml.p4d.24xlarge SageMaker インスタンス上で、15〜30 秒の広告を約 12〜15 分で生成します。これには、オーケストレーション(参照抽出/セグメンテーション)、自動品質チェック、再生成ループが含まれており、単なる単一のモデル呼び出しではありません。マルチ GPU シャーディング(8 ウェイトンネル並列)により、14B モデルを GPU メモリに完全に収めつつ、重いアテンション計算やデノイジング処理を加速することで、シーンごとの生成時間を数秒から数分の範囲に抑えています。SageMaker リアルタイムエンドポイントの背後で実行することで、リクエスト間のモデルウォームアップが保たれ、繰り返しモデルを読み込むことによるレイテンシを防ぎます。また、長時間の推論タイムアウトと起動時のヘルスチェックにより、長期実行型の拡散呼び出しにおける失敗や再試行を減らすことができます。
アブレーションスタディ
各アーキテクチャ上の決定を検証するため、体系的なアブレーションスタディ(比較実験)を実施しました。以下の表に結果をまとめます。
| 構成 | ストーリーの整合性 | エンゲージメント | 視覚的一貫性 |
|---|---|---|---|
| 完全システム | 6.9 | 6.5 | 6.9 |
| 参照画像伝播なし | 7.5 | 4.8 | 6.7 |
| ナラティブ要素抽出なし | 7.6 | 4.5 | 6.4 |
| 階層的シーンプランニングなし | 7.0 | 4.5 | 6.5 |
結果から、参照画像の伝播を除去するとエンゲージメントスコアに大きな影響(6.5 から 4.8)が生じることが明らかになり、一貫したキャラクター表現がより洗練された物語展開を支えていることが示唆されます。一方、物語要素の抽出機能を無効化すると最も深刻なエンゲージメントの低下を招きつつ、構造的スコアはわずかに向上しました。これは、構造化された物語分析が創造的なリスクテイクを可能にしつつも、一貫したストーリーラインを維持する上で支えとなっていることを示唆しています。
これが実装に与える意味
当社の経験に基づき、貴社の動画生成プロジェクトに向けた具体的なガイドラインを以下に示します:
- ヒューマン・イン・ザ・ループ(人間を介在させるプロセス)は不可欠です – システムが生産時間の大部分を自動化する一方で、クリエイティブブリーフの承認と最終レビューにおける人間の介入がブランドとの整合性を確認します。
- 参照画像の質は量よりも重要です – 私たちの適応型参照抽出システムは、多角的な評価(視覚的な明瞭さ、照明条件、要素の目立ちやすさ)を通じて最適なフレームを動的に特定します。質の低い参照画像を使用すると、そのエラーがビデオシーケンス全体に波及してしまいます。
- LLM-as-a-judge(LLM を審査員として活用する手法)は迅速な反復を支援します – 従来のビデオ評価は高価で時間がかかります。Anthropic の Claude を用いて生成されたコンテンツを構造化された基準に対して評価させることで、異なる生成アプローチとの迅速な実験が可能になりました。
- 複合的な一貫性の課題に設計で対応してください – 単一のキャラクターの一貫性については深く研究されていますが、より困難な問題は、家具付きの部屋など複数の視覚的属性が共存しなければならない複合要素の一貫性を維持することです。これらの複雑なケースを中心にアーキテクチャを計画してください。
クリーンアップ
ご自身の環境でこのソリューションを再現する場合は、実験終了時にリソースを削除して継続的なコストが発生しないように注意してください:
- SageMaker エンドポイントを削除します。
- 生成されたアセットを含む S3 バケットを削除します。
- Amazon ECS サービスとタスク定義を終了します。
- Lambda 関数および Step Functions ステートマシンを削除します。
結論
この協働により、AWS サービスを活用した AI 支援型クリエイティブ制作のための再現可能なパターンが確立されました。階層的なプロンプト計画による意味的一貫性と、参照画像の伝播による視覚的一貫性を組み合わせるという核心的なアーキテクチャ上の洞察は、広告に限定されない、一貫性のある拡張されたナラティブを必要とする多様な分野にも及ぶ、マルチシーン動画生成における根本的な課題に対処するものです。Bark にとって、このソリューションはビジネス評価において、パーソナライズされたソーシャルメディアキャンペーンの迅速な実験をサポートし、ミドルファネルマーケティングチャネルへの展開を支える可能性を秘めています。
同様のソリューション構築を開始するには、以下の次のステップを検討してください:
- 生成 AI アプリケーションの構築には Amazon Bedrock を探索する
- カスタムモデルのホスティングについては Amazon SageMaker AI について学ぶ
AWS Gene へお問い合わせください
原文を表示
*This post is cowritten with Hammad Mian and Joonas Kukkonen from Bark.com.*
When scaling video content creation, many companies face the challenge of maintaining quality while reducing production time. This post demonstrates how Bark.com and AWS collaborated to solve this problem, showing you a replicable approach for AI-powered content generation. Bark.com used Amazon SageMaker and Amazon Bedrock to transform their marketing content pipeline from weeks to hours.
Bark connects thousands of people each week with professional services, from landscaping to domiciliary care, across multiple categories. When Bark’s marketing team identified an opportunity to expand into mid-funnel social media advertising, they faced a scaling problem: effective social campaigns require high volumes of personalized creative content for rapid A/B testing, but their manual production workflow took weeks per campaign and couldn’t support multiple customer segment variations.
If you’re facing similar content scaling challenges, this architecture pattern can be a useful starting point. Working with the AWS Generative AI Innovation Center, Bark developed an AI-powered content generation solution that demonstrated a substantial reduction in production time in experimental trials while improving content quality scores. The collaboration targeted four objectives:
- Production time – Reduce from weeks to hours
- Personalization scale – Support multiple customer micro-segments per campaign
- Brand consistency – Maintain voice and visual identity across generated content
- Quality standards– Match professionally produced advertisements
In this post, we walk you through the technical architecture we built, the key design decisions that contributed to success, and the measurable results achieved, giving you a blueprint for implementing similar solutions.
Solution overview
Bark collaborated with the AWS Generative AI Innovation Center to develop a solution that could tackle these content scaling challenges. The team designed a system using AWS services and tailored AI models. The following diagram illustrates the solution architecture.
The solution architecture consists of the following integrated layers:
- Data and storage layer – Amazon Simple Storage Service (Amazon S3) stores assets including training data, generated video segments, reference images, and final outputs. Model artifacts and custom inference containers are stored in Amazon Elastic Container Registry (Amazon ECR).
- Processing layer – AWS Lambda orchestrates the multi-stage pipeline, with AWS Step Functions managing the workflow state across the seven-step generation process. Amazon Bedrock with Anthropic’s Claude Sonnet 3.7 handles text generation tasks, including customer segmentation, story generation, and quality evaluation.
- GPU compute layer – To serve Wan 2.1 Text2Video-14B reliably, we run a multi-GPU inference container that shards the model across eight GPUs on a single p4de.24xlarge SageMaker instance using tensor parallelism. TorchServe fronts the endpoint for request handling, and torchrun launches one worker process per GPU. We use Fully Sharded Data Parallel (FSDP) sharding—a technique for splitting the model components across GPUs—for the text encoder and the diffusion transformer to stay within GPU memory limits without offloading weights to CPU. Because video diffusion is long-running, the endpoint is tuned with an extended inference timeout and a longer container startup health-check window to accommodate model load time and help avoid premature restarts. Amazon Elastic Container Service (Amazon ECS) containers on GPU-enabled g5.2xlarge instances handle speech synthesis for narrator voice generation, scaling to zero during idle periods.
- User interface layer – A React frontend with Amazon Cognito authentication provides a video studio interface where marketing teams can review, edit, and approve generated content through natural language commands.
Creative ideation pipeline
Now that you understand the overall architecture, let’s examine how you can implement the creative ideation pipeline in your own environment. The pipeline transforms customer questionnaire data into production-ready storyboards through three stages.
Stage 1: Customer segment generation
The pipeline begins by analyzing Bark’s customer questionnaire data using Amazon Bedrock with Anthropic’s Claude Sonnet 3.7. The large language model (LLM) processes survey responses to identify distinct customer personas with structured attributes including demographics, motivations, pain points, and decision-making factors. For example, in the domiciliary care category, the system identified segments such as:
- The Overwhelmed Family Caregiver – Adults in their 40s–50s balancing work responsibilities with caring for aging parents, prioritizing reliability and trust
- The Independence-Focused Senior – Elderly individuals seeking to maintain autonomy while acknowledging the need for occasional assistance
Each segment profile is reviewed in the UI through a human-in-the-loop process and serves as input to subsequent creative ideation, creating advertisements that resonate with identified audience characteristics.
Stage 2: Creative brief generation
Given the business category and target segment, the system generates 4–6 creative concepts with varying degrees of abstraction—encouraging both literal and metaphorical approaches. We configure the model with high temperature sampling (0.8–1) to encourage divergent thinking. The model employs chain-of-thought reasoning, explicitly evaluating concept relevance, engagement potential, and entertainment value before generating briefs. This produces diverse narrative approaches to the same commercial objective, such as straightforward testimonial formats or emotionally resonant metaphorical stories.
Stage 3: Storyboard refinement
The final stage transforms generic creative briefs into segment-specific storyboards. A stochastic feature sampling mechanism—which randomly determines which attributes to highlight—identifies which customer segment attributes to emphasize, maintaining diversity while addressing specific motivations and pain points. The system performs explicit brief-to-segment matching through prompted reasoning before generating the final storyboard with complete audiovisual specifications—including scene descriptions, camera directions, narration text, and timing. Human review at this stage confirms brand alignment before production begins.
Maintaining visual consistency across scenes
A 30-second advertisement contains 4–6 distinct scenes, which are best generated individually. Without careful orchestration, AI models exhibit *semantic drift*—characters change appearance, backgrounds shift unexpectedly, and brand elements become inconsistent. Our solution implements a two-tier consistency framework.
Semantic consistency
You can transform creative briefs into video prompts through a three-stage process:
- Element extraction – An LLM analyzes the storyboard to identify atomic decor elements—actors, props, objects, and locations—and flags those requiring consistency across scenes.
- Blueprint generation – For each recurring element, the system generates detailed specification blueprints, establishing canonical visual representations.
- Prompt transformation – High-level scene descriptions are transformed into detailed video generation prompts, incorporating both the original creative brief (for narrative adherence) and standardized decor specifications (for visual consistency).
Visual consistency
Although semantic consistency through detailed prompts significantly reduces drift, video generation models still exhibit interpretive latitude even under identical prompt specifications. To address this limitation, we implement a reference image extraction and propagation pipeline, as illustrated in the following diagram.
The pipeline consists of the following stages:
- Optimal frame identification – Amazon Nova Premier analyzes generated scenes to identify frames where target elements appear most clearly.
- Element segmentation – The open-source Segment Anything Model, deployed on Amazon ECS, isolates target elements from backgrounds.
- Reference propagation – Extracted reference images are fed to subsequent video generation calls using Wan 2.2’s reference-to-video capabilities.
This dual-constraint approach—combining semantic specification through detailed prompts with visual specification through reference images—creates a robust consistency framework that we validated through systematic ablation studies.
The video generation pipeline
The pipeline orchestrates five modalities—text, image, video, audio, and overlay graphics—with strategic model selection based on scene requirements:
- Reference-to-video synthesis – Scenes requiring visual continuity use Wan 2.1 VACE- 14B with extracted reference images
- Text-to-video generation – Scenes introducing new elements use Wan 2.1 Text2Video-14B
A Step Functions workflow sequences generation to verify reference images are available before dependent scenes begin.
Speech synthesis and graphics
Speech synthesis uses Sesame AI Lab’s Conversational Speech Model on GPU-enabled ECS instances (g5.2xlarge). Voice cloning requires a 10-second reference sample of Bark’s brand narrator; the model extracts speaker embeddings that can be used to condition subsequent generation. Amazon ECS scales to zero during idle periods, alleviating costs outside active generation windows. In addition, text overlays and call-to-action graphics use template systems that support typographic consistency with Bark’s brand guidelines. These elements are composited during final assembly.
Quality evaluation loop
An LLM-as-a-judge evaluation loop in Lambda assesses each scene across three dimensions:
- Narrative adherence – Accuracy to storyboard description
- Visual quality – Absence of artifacts and inconsistencies
- Brand compliance – Alignment with brand guidelines
Scenes falling below configurable quality thresholds trigger automated regeneration while preserving visual reference elements. This iterative refinement continues until scenes meet quality standards or human review is requested.
Messaging consistent landing pages
Using generated videos and the customer segment as the base, we created an agentic system to generate personalized landing pages. We used a Strands agent to perform the following actions:
- Generate the TypeScript code for the page
- Take optimal screenshots from the video to include in the page (for the user to understand it’s related directly to the video ad they had viewed)
- Amend the wording and design to align with the customer segment
Results
We evaluated AI-generated content against Bark’s existing campaign library. The following table summarizes the results.
Evaluation Dimension
AI-Generated Ads
Existing Campaign Library
Story Structure C Coherence
6.9 ± 0.49
6.4 ± 0.74
Originality C Engagement
6.5 ± 1.23
5.2 ± 1.22
Visual C Spatial Consistency
6.9 ± 0.74
6.6 ± 0.75
*Scores on a 10-point scale with 95% confidence intervals*
The results demonstrate that AI-generated content achieved higher narrative coherence scores, validating the hierarchical scene planning approach. The 25% improvement in originality scores suggests the creative ideation pipeline successfully balances novelty with commercial viability. The reference image propagation system delivered measurably higher character and environment consistency than manual production.
End-to-end, the pipeline generates a 15–30 second ad in approximately 12–15 minutes on ml.p4d.24xlarge SageMaker instances; this includes orchestration (reference extraction/segmentation), automated quality checks, and regeneration loops—not just a single model call. Multi-GPU sharding (8-way tensor parallel) keeps per-scene generation in the seconds-to-a-few-minutes range by fitting the 14B model fully in GPU memory and accelerating the heavy attention/denoising compute. Running it behind a SageMaker real-time endpoint keeps the model warm between requests and helps avoid latency from repeated model loads, and long-inference timeouts and startup health checks reduce failures and retries for long-running diffusion calls.
Ablation study
To validate each architectural decision, we conducted systematic ablation studies. The following table summarizes the results.
Configuration
Story Coherence
Engagement
Visual Consistency
Full system
6.9
6.5
6.9
Without reference image propagation
7.5
4.8
6.7
Without narrative element extraction
7.6
4.5
6.4
Without hierarchical scene planning
7.0
4.5
6.5
The results reveal that removing reference image propagation significantly impacts engagement scores (from 6.5 to 4.8), indicating consistent character representation supports more sophisticated narrative development. Disabling narrative element extraction caused the most severe engagement degradation while slightly improving structural scores—suggesting structured narrative analysis supports creative risk-taking while maintaining coherent storylines.
What this means for your implementation
Based on our experience, the following are actionable guidelines for your own video generation projects:
- Human-in-the-loop is essential – Although the system automates the bulk of production time, human intervention at creative brief approval and final review confirms brand alignment.
- Reference image quality matters more than quantity – Our adaptive reference extraction system dynamically identifies optimal frames through multi-criteria assessment (visual clarity, lighting, element prominence). Poor reference images propagate errors throughout the video sequence.
- LLM-as-a-judge supports rapid iteration – Traditional video evaluation is expensive and slow. Using Anthropic’s Claude to evaluate generated content against structured criteria supported rapid experimentation with different generation approaches.
- Design for compound consistency challenges – Single-character consistency has been deeply researched; the harder problem is maintaining consistency of compound elements like furnished rooms where multiple visual attributes must coexist. Plan architecture around these complex cases.
Cleaning up
If you replicate this solution in your own environment, remember to delete resources when you’re done experimenting to avoid ongoing costs:
- Delete SageMaker endpoints.
- Remove S3 buckets containing generated assets.
- Terminate Amazon ECS services and task definitions.
- Delete Lambda functions and Step Functions state machines.
Conclusion
This collaboration establishes a replicable pattern for AI-assisted creative production using AWS services. The core architectural insight—combining semantic consistency through hierarchical prompt planning with visual consistency through reference image propagation—addresses fundamental challenges in multi-scene video generation that extend beyond advertising into various domains requiring coherent, extended narratives.For Bark, the solution, under business evaluation, has the potential to support rapid experimentation with personalized social media campaigns, supporting their expansion into mid-funnel marketing channels.
To get started building a similar solution, consider the following next steps:
- Explore Amazon Bedrock for building generative AI applications
- Learn about Amazon SageMaker AI for hosting custom models
Contact the AWS Gene
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み