AWS で現代的なデータメッシュ戦略を用いたエージェント型 AI アプリケーションの構築
AWS は、自律型 AI エージェントのガバナンス課題に対処するため、S3 Vectors や S3 Tables を活用した現代的なデータメッシュ戦略を提案し、コスト削減と高レベルのセキュリティを両立するアーキテクチャを示した。
キーポイント
自律型 AI のガバナンス課題の特定
従来の RAG(検索拡張生成)モデルでは対応できない、AI エージェントがデータベースを自律的に探索・クエリ実行する際のガバナンスギャップを指摘し、ツール発見から応答合成までの全レイヤーでの制御が必要であると論じている。
コスト最適化と高性能なデータ基盤
Amazon OpenSearch Serverless に代わり S3 Vectors を採用してベクトルストレージ・クエリコストを最大 90% 削減し、S3 Tables(Apache Iceberg 対応)と Lake Formation を組み合わせることで、自己管理型テーブルより 10 倍高いトランザクション性能を実現する。
MCP ツールとしてのデータメッシュ公開
データメッシュを Model Context Protocol (MCP) ツールとして AgentCore Gateway を通じて公開し、AWS Lambda によるインタセプターでエージェントとツールの呼び出しごとに決定論的なアクセス制御を適用する仕組みを提案している。
影響分析・編集コメントを表示
影響分析
この記事は、自律型 AI エージェントの実用化における最大の障壁である「データガバナンスとセキュリティ」に対する具体的な解決策を示しており、大規模組織が安全に AI エージェントを運用するための標準アーキテクチャとして注目される。特に S3 ベースのベクトル検索と Iceberg テーブルの統合は、コスト効率と機能性を両立させる画期的なアプローチであり、クラウドネイティブなデータ戦略の新たな基準となる可能性がある。
編集コメント
自律型 AI の普及には「機能」だけでなく「ガバナンス」が不可欠であり、AWS がその課題に対して S3 エコシステムを拡張して包括的な解決策を提供した点は非常に示唆に富んでいます。特にコスト削減効果が明確な点は、大規模導入を検討する企業にとって即座に価値を感じられる内容です。
顧客サービス担当者が自律的に注文データベースを照会し、返品ポリシーを取得し、回答を合成する場合、組織内の複数のデータソースに対する統制されたアクセスが必要です。モダンなデータメッシュ上でエージェント型 AI アプリケーションを構築するには、データ相互作用チェーンのすべての層で強制されるきめ細かいアクセス制御が求められます。データベーススキーマを自律的に発見し、SQL クエリを構築し、複数のソースからデータを合成する AI エージェントは、検索拡張生成(RAG)のために構築された単一チェックポイントモデルでは対応できないガバナンス上の隙間を露呈させます。組織には、ツールの発見からクエリ実行、回答の合成に至るまでの制御が必要です。
以前の投稿 AWS サーバーレスデータレイクで安全な RAG アプリケーションを構築する では、ビジネスドメインやセキュリティ分類などのメタデータを使用してベクトル検索結果をフィルタリングすることで、RAG に対するきめ細かいアクセス制御(FGAC)をどのように強制するかを示しました。このアプローチが機能したのは、RAG のデータ相互作用が単純だったからです:事前に構築されたベクトルインデックスからチャンクを取得し、メタデータでフィルタリングして結果を表示するだけです。
本稿では、生産環境のエージェント型 AI が必要とする安全かつスケーラブルなデータ基盤を提供する、AWS 上の統制されたサーバーレスデータメッシュを構築する方法を示します。このアーキテクチャは、元の設計に以下の 3 つの主要な変更を加えて拡張されています:
- 中程度のクエリ頻度のワークロードにおいて、専門的なベクトルデータベースソリューションと比較して、ベクトルストレージおよびクエリコストを最大 90% 削減できるコスト最適化型のナレッジベースとして、Amazon OpenSearch Serverless を Amazon S3 Vectors に置き換えること。
- 汎用の Amazon Simple Storage Service (Amazon S3) を、AWS Lake Formation によって管理され、組み込みの Apache Iceberg サポートを備えた Amazon S3 Tables に置き換えること。これにより、自己管理型の Iceberg テーブルと比較して 1 秒あたりのトランザクション数が最大 10 倍向上し、行レベル、列レベル、セルレベルの詳細なセキュリティを実現します。
- AgentCore Gateway を通じてデータメッシュを Model Context Protocol (MCP) ツールとして公開すること。AWS Lambda ベースのインターセプターにより、エージェントからツールへの各呼び出しにおいて決定論的なアクセス制御を提供します。
前提条件
このアーキテクチャを実装するには、以下の要素が必要です:
- 管理者権限を持つ AWS アカウント。
- ロール、ポリシー、Lambda 関数、S3 Tables テーブルバケット、Amazon Athena ワークグループ、Lake Formation 設定を作成するための AWS Identity and Access Management (IAM) 権限。
- AWS Lake Formation の概念(データレイク管理者、LF-Tags、データフィルター)に関する知識。
- モデルアクセスが構成された Amazon Bedrock が有効化されたアカウント。
- アカウント内で Amazon Bedrock AgentCore アクセスが構成されていること。
- インストールおよび設定が完了した AWS Command Line Interface (AWS CLI) v2。
アーキテクチャの概要
以下の図は、顧客からのリクエストから統制されたデータアクセスを経て戻るまでのエンドツーエンドの流れを示しています。各レイヤーは独自の認可制御を適用するため、単一の障害点が不正なデータの露出を引き起こすことはありません。アーキテクチャ図には 4 つの層が表示されています:AgentCore ランタイムと LangGraph エージェントを備えたエージェント層、リクエストおよびレスポンスインターセプターを備えたゲートウェイ層、get_user_tables、get_schema、run_query、kb_search の 4 つの Lambda ベース MCP ツール(MCP: Model Context Protocol)を備えたツール層、そして S3 テーブル、Athena、Lake Formation、S3 Vectors を備えた統制されたデータメッシュです。矢印は、顧客からエージェントを経て統制されたデータソースへ向かうデータフローを示しています。
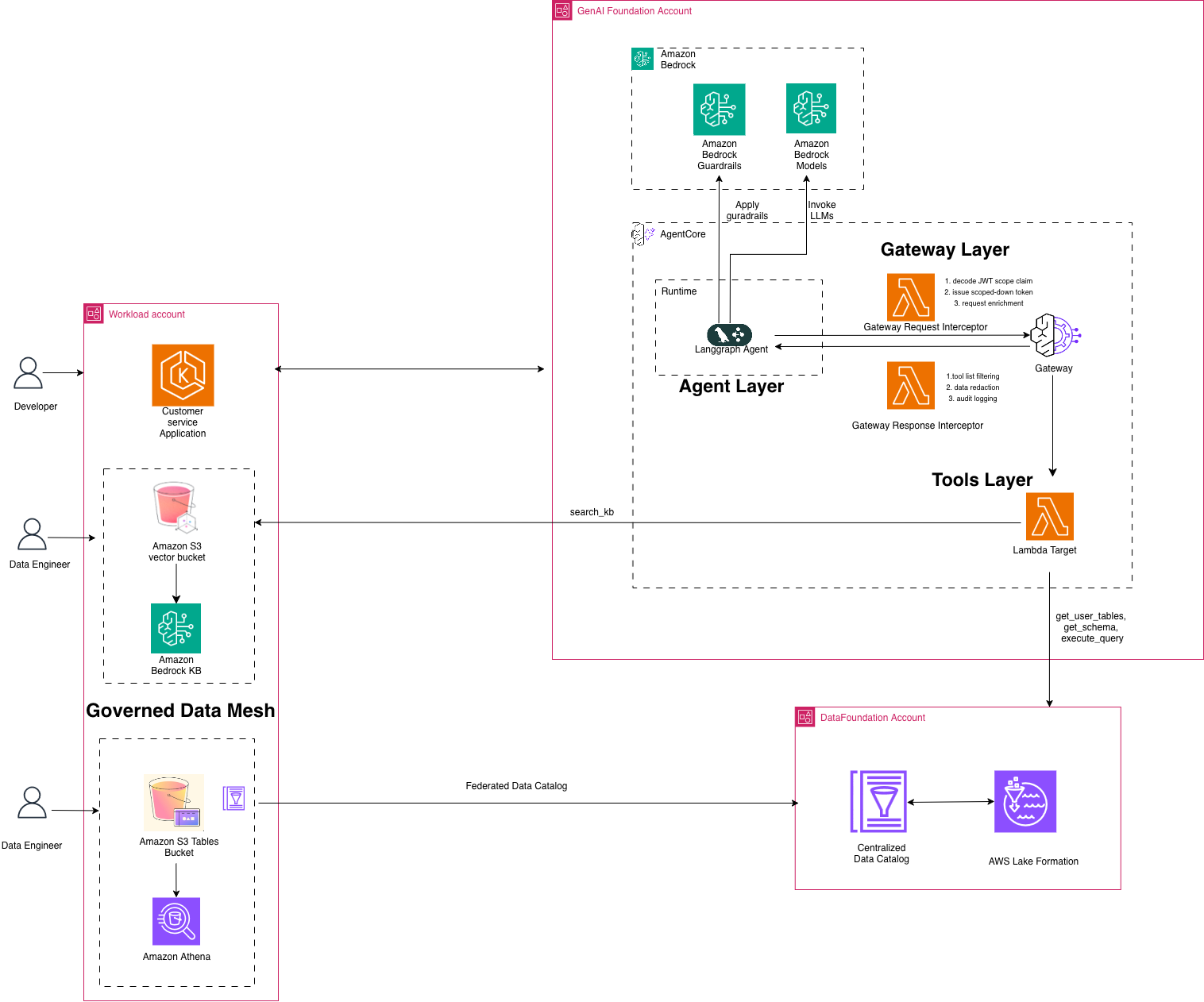
- エージェントレイヤー – カスタマーは、エージェントを分離されたマイクロ VM 環境でセッション隔離しながらデプロイする安全なサーバーレスホスティング環境である AgentCore Runtime と対話します。エージェントは LangGraph フレームワーク内で実行され、MCPClient クラスを通じて MCP ツールと統合されます。
- ゲートウェイレイヤー – ゲートウェイには、JSON Web Token (JWT) の検証とスコープの強制を行うリクエストインターセプター、ツールフィルタリング、データ削除、監査ログ処理を担当するレスポンスインターセプターが含まれます。また、AgentCore Policy と Bedrock Guardrails は、プロンプトインジェクション、有害コンテンツ、機密情報の露出について、すべてのツール呼び出しの入力と出力をリアルタイムで評価します。
- ツールレイヤー – get_user_tables, get_schema, run_query, kb_search の 4 つの Lambda ベース MCP ツールが、統制されたデータアクセスを提供します。
- 統制されたデータメッシュ – AWS Glue データカタログ (s3tablescatalog) に登録された S3 Tables (Iceberg)、ワークグループごとのコスト制御を備えた Amazon Athena、行/列/セルレベルのセキュリティを強制する Lake Formation、および Amazon Bedrock Knowledge Bases を支える S3 Vectors。
なぜアジェンティック AI に新しいガバナンスモデルが必要なのか
RAG アーキテクチャは、メタデータフィルタ付きベクトル検索という単一のチェックポイントでガバナンスを強制していました。このアプローチは RAG ワークロードにはよく機能しました。しかし、アジェンティックなパターンでは追加のステップが導入され、各ステップごとに独自の承認判断が必要な多段階チェーンが生成されます。RAG では、システムは取得時にメタデータフィルタを適用して事前に構築されたベクトルインデックスにクエリを実行します。一方、アジェンティック AI では、システムが存在するテーブルの発見、スキーマの理解、SQL の構築、ベクトルストアからの取得、そして結果の合成という一連の処理を行います。
単一の取得境界におけるメタデータフィルタでは、この 5 つのステップからなるチェーンを統制することはできません。ベクトルデータベースは権限を定期的に同期するため、権限剥奪が即座に反映されません。エージェントがデータに対して自律的に行動する際には、これは許容できないギャップです。ロール階層や属性ベースアクセス制御(ABAC)、行レベルフィルタといった複雑なアイデンティティ権限は、ベクトルチャンク上の単純なメタデータキーバリューペアとして表現することができません。
これらの制限が、各データアクセスレイヤーでネイティブに承認を強制するガバナンス付きデータメッシュアーキテクチャへの移行を促す動機となっています。
ガバナンスされたサーバーレスデータメッシュの構築
データメッシュは、データの所有権をドメインチームに分散させつつ、ガバナンスと発見可能性を中央集権化します。AWS においては、ドメインチームがエンドツーエンドで自社のデータプロダクトを管理し、AWS Glue Data Catalog が中央集権的なメタデータの発見を提供し、Lake Formation がデータベース、テーブル、列、行、セルにわたる付与・取り消しのセマンティクスを通じて権限を強制します。
各プロデューサードメインは独自の AWS アカウント内に存在します。プロデューサーは、組織全体の信頼できる AWS Glue Data Catalog と Lake Formation 権限ポリシーをホストする専用アカウントである中央ガバナンスアカウントにデータプロダクトを登録します。データ共有は Lake Formation のクロスアカウント共有 を通じて行われます。データのコピーは一切行われません。消費側カタログ内のリソースリンクを通じてメタデータのみがリンクされます。クエリ実行時には、Lake Formation が権限を検証し、クエリエンジンに対して一時的な認証情報を発行します。タグベースアクセス制御 (LF-TBAC) はこれを動的にスケーリングします。管理者は、classification=PII や department=customer_service などの LF タグをリソースに割り当て、これらのタグに基づいて権限を付与します。
以下の小節では、このメッシュの 2 つのデータ層を実装する方法について説明します。まず、Lake Formation の行および列セキュリティによって管理される構造化データ(注文記録、顧客プロファイル)のためのトランザクション対応 Iceberg テーブルを取り上げます。次に、セマンティック検索を可能にする非構造化知識(ポリシー、FAQ)のためのベクトルストアについて説明します。
トランザクションデータ用の Apache Iceberg を備えた S3 Tables
カスタマーサービスエージェント向けに、注文管理ドメインチームが Amazon S3 Tables を使用して注文および顧客データを公開しています。S3 Tables は、組み込みの Apache Iceberg サポートを備えた最初のクラウドオブジェクトストレージであり、汎用 S3 バケット上の自己管理型 Iceberg テーブルと比較して、1 秒あたりのトランザクション数が最大 10 倍向上します。また、コンパクション(圧縮統合)、スナップショット管理、未参照ファイルの削除を自動的に処理します。
S3 Tables は Amazon SageMaker Lakehouse と連携し、AWS Glue Data Catalog にデータを登録し、Lake Formation を通じてアクセスを連動させます。3 つのデータプロダクト(customer_orders, customer_profiles, interaction_history)は Amazon Athena からクエリ可能であり、Lake Formation の権限によって管理され、S3 Tables によって自動的にコンパクションされます。
Lake Formation の データフィルター は行レベルのセキュリティを強制するため、エージェントは認証された顧客に属するレコードのみへのアクセスが可能になります。customer_orders に対するデータフィルターでは、行フィルタ式 customer_id = :customer_id を設定することで、エージェントが SQL をどのように構築しようとも、すべてのクエリが現在の顧客のレコードに制限されます。run_query Lambda 関数は、Athena へクエリを提出する前に、認証された顧客の ID をセッションパラメータとして注入します。カラムレベルのセキュリティにより、payment_method や billing_address といった機密フィールドはクエリ結果から完全に隠蔽されます。
Amazon S3 Vectors を用いたナレッジベースの構築
構造化データだけでは不十分です。顧客は、セマンティック検索機能が必要となる非構造化知識(製品マニュアル、返品ポリシー、よくある質問 (FAQ)、トラブルシューティングガイドなど)から引き出された回答を必要とします。
Amazon S3 Vectors は、フルサーバーレスサービスとしてネイティブなベクトルストレージおよびクエリ機能を提供します。インデックスあたり最大 20 億個のベクトルをサポートし、強力な書き込み一貫性を提供するため、新たに追加されたベクトルは即座にクエリ可能です。
S3 Vectors のコストメリット
Amazon Bedrock のナレッジベース機能を利用している顧客は、ベクトルストアとして S3 Vectors を選択できます。これにより、中程度のクエリ頻度のワークロードにおいて、専用のベクトルデータベースソリューションと比較して最大 90 パーセントのコスト削減が可能になります。1 秒あたりのクエリ数(QPS)が高く、ミリ秒単位の低遅延が求められるワークロードにおいては、Amazon OpenSearch Serverless が依然としてより適した選択肢です。AWS では、S3 Vectors のパフォーマンスプロファイルを超えたワークロード向けに、S3 Vectors から Amazon OpenSearch Serverless コレクションへのワンステップエクスポートを提供しています。
S3 Vectors は、フィルタ可能なメタデータ(文字列、数値、ブール型、リスト型で、$eq, $ne, $gt, $in, $and, $or などの演算子を使用可能)と、結果とともに返される大規模なコンテキストデータ用のフィルタ不可能なメタデータをサポートしています。今回のユースケースでは、文書は product_category や document_type といったフィルタ可能なメタデータキーと共に保存されており、ターゲットを絞った意味検索をサポートします。以下の例は、電子機器の返品ポリシーのみを取得するメタデータフィルタを示しています:
{"$and": [{"product_category": {"$eq": "electronics"}}, {"document_type": {"$eq": "return_policy"}}]}
エージェントコアゲートウェイによるデータメッシュの公開
統制されたデータメッシュとナレッジベースが整備された後、次の課題は、これらの機能を AI エージェントに対して安全に、発見可能かつ標準化された方法で公開することです。このセクションでは、これを実現するためのツール、インターセプター、およびアイデンティティ伝播パターンについて解説します。
AgentCore Gateway は、AI エージェントがツールに接続する方法を管理するための集中型レイヤーを提供します。認証、観測性(オバザビリティ)、ポリシー適用を単一のエンドポイントに統合しています。ゲートウェイは、Lambda 関数、API、既存の MCP サーバーを、プロトコル変換、インバウンド OAuth 認証、アウトバウンド資格情報管理を通じて MCP 互換ツールに変換します。エージェントは、OAuth Bearer トークンを使用したストリーミング HTTP 転送を介して接続されます。
4 つのコアデータツール
ゲートウェイを介した統制されたデータアクセスを提供する、Lambda ベースの MCP ツールが 4 つあります。get_user_tables は、Lake Formation の権限でフィルタリングされた AWS Glue データカタログを照会し、許可されたテーブルを返します。get_schema は、指定されたテーブルのカラム名、型、説明を取得します。run_query は、SQL を読み取り専用ホワイトリストに対して検証し、行レベルのフィルタリングのために顧客アイデンティティを注入し、バイトスキャンコスト制限付きで Athena を介して実行します。kb_search は、Amazon Bedrock のナレッジベースに対してメタデータフィルタ付きのセマンティック検索を実行します。
Amazon Bedrock Managed Knowledge Base のリリースに伴い、ナレッジベースは now AgentCore Gateway においてネイティブの事前構築済みターゲットタイプとして利用可能になりました。これは、カスタム Lambda 関数を経由せずに Gateway を通じてナレッジベースを公開できることを意味します。Gateway は自動的に IAM ロールを生成し、組み込みの観測性と評価指標を提供し、AgentCore Policy を介してポリシーを強制執行します。本アーキテクチャでは、Gateway インターセプターがツール呼び出し境界においてきめ細かい権限管理とメタデータフィルタリングをどのように実行するかを示すため、カスタム Lambda 基盤の kb_search ツールを使用しています。カスタムインターセプターロジックを必要としない本番環境ワークロードにおいては、ネイティブの Managed KB ターゲットタイプは MCP 互換性と AgentCore Policy の強制執行を維持したまま、Lambda 関数を完全に排除することで運用オーバーヘッドを削減します。
以下の JSON は、run_query のツールスキーマ登録を示しています。
{
"name": "run_query",
"description": "Amazon Athena を介して管理された Iceberg テーブルに対して、バイトスキャン制限と Lake Formation の行レベルセキュリティを適用した読み取り専用 SQL クエリを実行します。",
"inputSchema": {
"type": "object",
"properties": {
"sql": {"type": "string", "description": "読み取り専用の SQL SELECT ステートメント。"},
"database": {"type": "string", "description": "Glue Data Catalog のデータベース名。"}
},
"required": ["sql", "database"]
}
}
MCP ツールとインターセプターのデプロイ:
- AgentCore Gateway のインターセプターサンプルリポジトリをクローンします。
- 各 Lambda 関数(get_user_tables、get_schema、run_query、kb_search、リクエストインターセプター、レスポンスインターセプター)について、AWS CLI を使用して関数を作成します:
aws lambda create-function --function-name get_user_tables \
--runtime python3.12 --handler lambda_function.lambda_handler \
--role arn:aws:iam::ACCOUNT_ID:role/mcp-tool-role \
--zip-file fileb://function.zip
- リポジトリの policies ディレクトリに定義されている IAM ポリシーを、各関数の実行ロールにアタッチします。
- Lambda 関数を AgentCore Gateway の MCP ツールターゲットとして登録します。手順については、「ツールターゲットの登録」を参照してください。
- リクエストおよびレスポンスインターセプターをゲートウェイにアタッチします。手順については、AgentCore Gateway インターセプターサンプルを参照してください。
注:4 つの MCP ツールと両方のインターセプターに関する完全な Lambda 関数のソースコード、IAM ポリシー、およびデプロイ手順については、AgentCore Gateway インターセプターサンプルを参照してください。
決定論的アクセス制御のためのインターセプター
AgentCore Gateway インターセプター は、リクエスト・レスポンスライフサイクルの 2 つの段階で認可を強制するカスタム Lambda 関数です。インターセプターは、ゲートウェイを通過して流れるリクエストやレスポンスを検査、変換、またはブロックするミドルウェアとして機能します。リクエストインターセプターは、ゲートウェイがターゲット Lambda を呼び出す前に実行され、レスポンスインターセプターは、ターゲットからの応答後だが結果が呼び出し元に到達する前に実行されます。
インターセプターのパターンは、各段階で異なるセキュリティ課題を解決します:
パターン
解決される課題
仕組み
JWT スコープベースのツール呼び出し制御
不正なツールのアクセス
リクエストインターセプターが JWT スコームクレームをデコードし、不正なツールや呼び出しをブロックする
ダイナミックツールフィルタリング
ツール発見情報の漏洩
原文を表示
When a customer service agent autonomously queries order databases, retrieves return policies, and synthesizes answers, it needs governed access to multiple data sources across your organization. Building agentic AI applications on a modern data mesh requires fine-grained access control enforced at every layer of the data interaction chain. AI agents that autonomously discover database schemas, construct SQL queries, and synthesize data from multiple sources expose governance gaps that the single-checkpoint model built for Retrieval Augmented Generation (RAG) can’t address. Organizations need controls from tool discovery through query execution to response synthesis.
In an earlier post, Build secure RAG applications with AWS serverless data lakes, we showed how to enforce fine-grained access control (FGAC) over RAG by filtering vector search results using metadata such as business domain and security classification. That approach worked because RAG’s data interaction was simple: retrieve chunks from a pre-built vector index, filter by metadata, and present results.
This post shows how to build a governed, serverless data mesh on AWS that provides the secure, scalable data foundation production agentic AI requires. The architecture extends the original with three key changes:
- Replacing Amazon OpenSearch Serverless with Amazon S3 Vectors for cost-optimized knowledge bases, which can reduce vector storage and query costs by up to 90% compared to specialized vector database solutions in moderate query-frequency workloads.
- Replacing general-purpose Amazon Simple Storage Service (Amazon S3) with Amazon S3 Tables (with built-in Apache Iceberg support) governed by AWS Lake Formation, delivering up to 10 times higher transactions per second compared to self-managed Iceberg tables, with fine-grained row, column, and cell-level security.
- Exposing the data mesh as Model Context Protocol (MCP) tools through AgentCore Gateway with AWS Lambda-backed interceptors for deterministic access control at every agent-to-tool invocation.
Prerequisites
To implement this architecture, you need the following:
- An AWS account with administrator access.
- AWS Identity and Access Management (IAM) permissions to create roles, policies, Lambda functions, S3 Tables table buckets, Amazon Athena workgroups, and Lake Formation configurations.
- Familiarity with AWS Lake Formation concepts (data lake administrator, LF-Tags, data filters).
- An Amazon Bedrock enabled account with model access configured.
- Amazon Bedrock AgentCore access configured in your account.
- The AWS Command Line Interface (AWS CLI) v2 installed and configured.
Architecture overview
The following diagram illustrates the end-to-end flow from customer request through governed data access and back. Each layer enforces its own authorization controls, so no single point of failure can expose unauthorized data. The architecture diagram shows four layers: Agent Layer with AgentCore Runtime and LangGraph agent, Gateway Layer with request and response interceptors, Tools Layer with four Lambda-backed MCP tools (get_user_tables, get_schema, run_query, kb_search), and Governed Data Mesh with S3 Tables, Athena, Lake Formation, and S3 Vectors. The arrows show data flow from customer through agent to governed data sources.
- Agent Layer – The customer interacts with AgentCore Runtime, a secure, serverless hosting environment that deploys agents in isolated microVM environments with session isolation. The agent runs within the LangGraph framework, which integrates with MCP tools through the MCPClient class.
- Gateway Layer – The Gateway includes a request interceptor that performs JSON Web Token (JWT) validation and scope enforcement, a response interceptor that handles tool filtering, data redaction, and audit logging, and AgentCore Policy with Bedrock Guardrails that evaluates inputs and outputs of every tool invocation for prompt injection, harmful content, and sensitive information exposure in real time.
- Tools Layer – Four Lambda-backed MCP tools (get_user_tables, get_schema, run_query, and kb_search) provide governed data access.
- Governed Data Mesh – S3 Tables (Iceberg) registered in the AWS Glue Data Catalog (s3tablescatalog), Amazon Athena with workgroup cost controls, Lake Formation enforcing row/column/cell-level security, and S3 Vectors powering the Amazon Bedrock Knowledge Bases.
Why agentic AI requires a new governance model
The RAG architecture enforced governance at a single checkpoint: metadata-filtered vector retrieval. That approach served RAG workloads well. Agentic patterns introduce additional steps, creating a multi-step chain where each step requires its own authorization decision. In RAG, the system queries one pre-built vector index with metadata filters at retrieval time. In agentic AI, the system discovers which tables exist, understands schemas, constructs SQL, retrieves from vector stores, and synthesizes results.
A metadata filter at a single retrieval boundary cannot govern this five-step chain. Vector databases synchronize permissions periodically, meaning revocations aren’t immediately reflected. This is an unacceptable gap when an agent is autonomously acting on data. Complex identity permissions such as role hierarchies, attribute-based access, and row-level filters can’t be expressed as straightforward metadata key-value pairs on vector chunks.
These limitations motivate the shift to a governed data mesh architecture where authorization is enforced natively at each data access layer.
Building a governed serverless data mesh
A data mesh decentralizes data ownership to domain teams while centralizing governance and discoverability. On AWS, domain teams own their data products end-to-end, the AWS Glue Data Catalog provides centralized metadata discovery, and Lake Formation enforces permissions with grant/revoke semantics across databases, tables, columns, rows, and cells.
Each producer domain resides in its own AWS account. Producers register data products in a central governance account, a dedicated AWS account that hosts the authoritative AWS Glue Data Catalog and Lake Formation permission policies for the entire organization. Data is shared through Lake Formation cross-account sharing. No data is copied. Only metadata is linked through resource links in consumer catalogs. At query time, Lake Formation verifies permissions and issues temporary credentials to the query engine. Tag-based access control (LF-TBAC) scales this dynamically. Administrators assign LF-Tags like classification=PII or department=customer_service to resources and grant permissions based on those tags.
The following subsections describe how we implement the two data layers of this mesh. First, we cover transactional Iceberg tables for structured data (order records, customer profiles) governed by Lake Formation row and column security. Then, we describe the vector store for unstructured knowledge (policies, FAQs) that powers semantic search.
S3 Tables with Apache Iceberg for transactional data
For our customer service agent, the Order Management domain team publishes order and customer data using Amazon S3 Tables. S3 Tables is the first cloud object store with built-in Apache Iceberg support, delivering up to 10 times higher transactions per second compared to self-managed Iceberg tables on general-purpose S3 buckets. It automatically handles compaction, snapshot management, and unreferenced file removal.
S3 Tables integrates with Amazon SageMaker Lakehouse, which populates the AWS Glue Data Catalog and federates access through Lake Formation. The three data products (customer_orders, customer_profiles, and interaction_history) are queryable from Amazon Athena, governed by Lake Formation permissions, and automatically compacted by S3 Tables.
Lake Formation data filters enforce row-level security so the agent can only access records belonging to the authenticated customer. A data filter on customer_orders with the row filter expression customer_id = :customer_id restricts every query to the current customer’s records, regardless of how the agent constructs its SQL. The run_query Lambda function injects the authenticated customer’s identity as a session parameter before submitting queries to Athena. Column-level security hides sensitive fields like payment_method and billing_address from query results entirely.
Building a knowledge base with Amazon S3 Vectors
Structured data alone is not enough. Customers need answers drawn from unstructured knowledge (product manuals, return policies, frequently asked questions (FAQs), and troubleshooting guides) that require semantic search capabilities.
Amazon S3 Vectors provides native vector storage and querying support as a fully serverless service. It supports up to 2 billion vectors per index and provides strong write consistency, meaning newly added vectors are immediately queryable.
Cost advantages of S3 Vectors
Customers who use the knowledge base feature in Amazon Bedrock can select S3 Vectors as a vector store, which can reduce costs by up to 90 percent compared to specialized vector database solutions in moderate query-frequency workloads. For high queries-per-second (QPS) workloads requiring single-digit millisecond latency, Amazon OpenSearch Serverless remains the better fit. AWS provides single-step export from S3 Vectors to Amazon OpenSearch Serverless collections for workloads that outgrow the S3 Vectors performance profile.
S3 Vectors supports filterable metadata (string, number, boolean, list types with operators like $eq, $ne, $gt, $in, $and, $or) and non-filterable metadata for larger contextual data returned with results. In our use case, documents are stored with filterable metadata keys like product_category and document_type, which supports targeted semantic search. The following example shows a metadata filter that retrieves only electronics return policies:
{"$and": [{"product_category": {"$eq": "electronics"}}, {"document_type": {"$eq": "return_policy"}}]}Exposing the data mesh with AgentCore Gateway
With the governed data mesh and knowledge base in place, the next challenge is exposing these capabilities to the AI agent in a secure, discoverable, and standardized way. This section covers the tools, interceptors, and identity propagation patterns that make this possible.
AgentCore Gateway provides a centralized layer for managing how AI agents connect to tools. It consolidates authentication, observability, and policy enforcement into a single endpoint. The Gateway converts Lambda functions, APIs, and existing MCP servers into MCP-compatible tools with protocol translation, inbound OAuth authorization, and outbound credential management. Agents connect through streamable HTTP transport with an OAuth Bearer token.
Four core data tools
Four Lambda-backed MCP tools provide governed data access through the Gateway. get_user_tables queries the AWS Glue Data Catalog filtered by Lake Formation permissions to return authorized tables. get_schema retrieves column names, types, and descriptions for a specified table. run_query validates SQL against a read-only allowlist, injects customer identity for row-level filtering, and executes through Athena with byte-scan cost limits. kb_search performs metadata-filtered semantic search against the Knowledge Bases in Amazon Bedrock.
With the launch of Amazon Bedrock Managed Knowledge Base, knowledge bases are now available as a native pre-built target type in AgentCore Gateway. This means you can expose a knowledge base through the Gateway without a custom Lambda function thee Gateway automatically generates IAM roles, provides built-in observability and evaluation metrics, and enforces policies via AgentCore Policy. In this architecture, we use a custom Lambda-backed kb_search tool to demonstrate how Gateway interceptors enforce fine-grained authorization and metadata filtering at the tool invocation boundary. For production workloads where custom interceptor logic is not required, the native Managed KB target type reduces operational overhead by eliminating the Lambda function entirely while retaining MCP compatibility and AgentCore Policy enforcement.
The following JSON shows the tool schema registration for run_query.
{
"name": "run_query",
"description": "Executes a read-only SQL query against governed Iceberg tables via Amazon Athena with byte-scan limits and Lake Formation row-level security.",
"inputSchema": {
"type": "object",
"properties": {
"sql": {"type": "string", "description": "A read-only SQL SELECT statement."},
"database": {"type": "string", "description": "The Glue Data Catalog database name."}
},
"required": ["sql", "database"]
}
}Deploying the MCP tools and interceptors:
- Clone the AgentCore Gateway interceptor samples repository.
- For each Lambda function (get_user_tables, get_schema, run_query, kb_search, request interceptor, response interceptor), create the function using the AWS CLI:
aws lambda create-function --function-name get_user_tables \
--runtime python3.12 --handler lambda_function.lambda_handler \
--role arn:aws:iam::ACCOUNT_ID:role/mcp-tool-role \
--zip-file fileb://function.zip- Attach the IAM policies defined in the repository’s policies/ directory to each function’s execution role.
- Register the Lambda functions as MCP tool targets in AgentCore Gateway. For instructions, see Registering tool targets.
- Attach the request and response interceptors to the gateway. For instructions, see the AgentCore Gateway interceptor samples.
Note: For complete Lambda function source code, IAM policies, and deployment instructions for all four MCP tools and both interceptors, see the AgentCore Gateway interceptor samples.
Interceptors for deterministic access control
AgentCore Gateway interceptors are custom Lambda functions that enforce authorization at two stages in the request-response lifecycle. Interceptors act as middleware that inspects, transforms, or blocks requests and responses flowing through the Gateway. A request interceptor executes before the Gateway calls the target Lambda, and a response interceptor executes after the target responds but before results reach the caller.
Interceptor patterns solve distinct security challenges at each stage:
Pattern
Challenge solved
How
JWT scope-based tool invocation control
Unauthorized tool access
Request interceptor decodes JWT scope claim and blocks unauthorized tools/call invocations
Dynamic tool filtering
Tool discovery leakage
関連記事
SmithDB の全文検索用逆インデックス構築の仕組み
LangChain チームが、SmithDB で高速な全文検索を実現するために採用した逆インデックスの設計手法と実装プロセスを解説している。
最高の AI エージェントはシンプルである:Sierra の Zack Reneau-Wedeen が語る、Max Agency Podcast での議論
LangChain Blog は、Harrison Chase と Sierra の Zack Reneau-Wedeen が Max Agency Podcast で、AI エージェントの未来について話し合った内容を伝えています。彼らは、高パフォーマンスな顧客向け AI を構築するには、シンプルなアーキテクチャ、成果ベースの価格設定、および組織図をそのまま実装する行為を避けることが重要であると指摘しました。
2026 年に AI エンジニアになるためのロードマップ
KDnuggets が、2026 年までに AI エンジニアとして活躍するための学習ロードマップを提示している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み