量子化の基礎から解説
Sam Roseのインタラクティブな解説記事は、大規模言語モデルの量子化技術の仕組み、特に浮動小数点表現の視覚化、外れ値の重要性、および量子化レベルがモデル精度に与える影響について包括的に説明している。
キーポイント
量子化の基礎解説
記事は大規模言語モデルの量子化技術を基礎から説明し、特に浮動小数点数のバイナリ表現を視覚的に解説するインタラクティブツールを紹介している。
外れ値の重要性と処理
量子化において稀な「外れ値」がモデル品質に極めて重要であり、単一の「スーパーウェイト」を除去するとモデルが無意味な出力を生成する可能性があると指摘し、実用的な量子化スキームではこれらを特別に保護する方法を説明している。
量子化レベルと精度への影響
量子化がモデル精度に与える影響を、パープレキシティとKLダイバージェンスの概念を用いて分析し、Qwen 3.5 9Bモデルを用いた実験結果から、16ビットから8ビットへの量子化はほぼ品質低下がなく、4ビットへの量子化でも約90%の品質が維持されると結論付けている。
影響分析・編集コメントを表示
影響分析
この記事は、AIモデルの実用化とデプロイメントにおいて重要な量子化技術を、教育目的で分かりやすく解説しており、技術者や研究者の理解を深める教育的価値が高い。特に外れ値の重要性に関する知見は、実用的な量子化手法の設計に直接影響を与える可能性がある。
編集コメント
技術解説記事として非常に質が高く、複雑な量子化の概念を視覚的・インタラクティブに説明している点が秀逸。実務的な知見(外れ値の扱い)と教育的価値の両方を兼ね備えている。
Quantization from the ground up
Sam Rose は、彼の素晴らしい情報量の多いインタラクティブなエッセイの連続を続け、今回は大規模言語モデル(Large Language Models)の量子化(quantization)がどのように機能するかを説明しています。
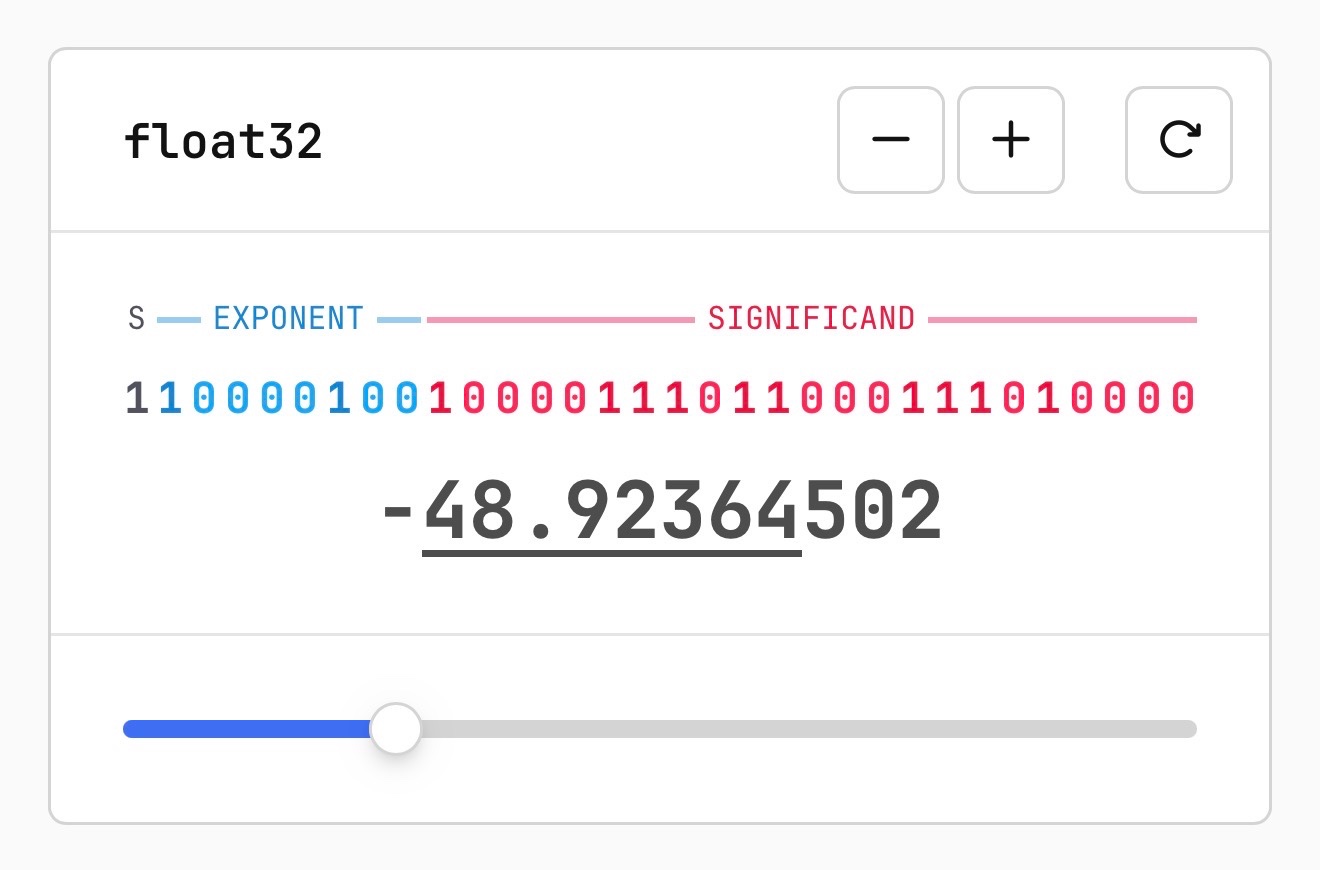
また、浮動小数点数(floating point numbers)が 2 進数字を用いてどのように表現されるかについての、私がこれまで見た中で最も優れた視覚的な解説も含まれています。
量子化における外れ値(outlier values)については聞いたことがありませんでした。これは通常の微小な値の分布の外側に存在する稀な浮動小数点数ですが、どうやら非常に重要であるようです:
**
なぜこれらの外れ値が存在するのか? [...] 要約:誰も決定的に知っていませんが、これらの外れ値のごく一部はモデルの品質にとって*非常に*重要です。Apple が「スーパーウェイト」と呼ぶような単一の「スーパーウェイト」を削除するだけで、モデルが完全な無意味な文字列を出力してしまう可能性があります。
その重要性を考慮すると、実世界の量子化スキームでは、これらの外れ値を保存するために追加の処理を行うことがあります。これには、それらを全く量子化しないか、あるいはその位置と値を別のテーブルに保存してから削除し、ブロックが破壊されないようにするといった方法が含まれます。**
また、Quantization がモデルの精度にどの程度影響するかというセクションもあります。サムはパープレキシティとKL 分散**の概念を説明した上で、llama.cpp のパープレキシティツールおよび GPQA ベンチマークの実行結果を用いて、異なる量子化レベルが Qwen 3.5 9B に与える影響を示しています。
彼の結論は以下の通りです:
16 ビットから 8 ビットへの量子化では品質の低下はほとんど見られません。16 ビットから 4 ビットへの変更はより顕著ですが、それでも元のモデルのちょうど四分の一の性能というわけではありません。測定方法にもよりますが、約 90% の性能を維持しています。
タグ:computer-science, ai, explorables, generative-ai, llms, sam-rose, qwen
原文を表示
Quantization from the ground up
Sam Rose continues his streak of publishing spectacularly informative interactive essays, this time explaining how quantization of Large Language Models works.
Also included is the best visual explanation I've ever seen of how floating point numbers are represented using binary digits.
I hadn't heard about outlier values in quantization - rare float values that exist outside of the normal tiny-value distribution - but apparently they're very important:
Why do these outliers exist? [...] tl;dr: no one conclusively knows, but a small fraction of these outliers are very important to model quality. Removing even a single "super weight," as Apple calls them, can cause the model to output complete gibberish.
Given their importance, real-world quantization schemes sometimes do extra work to preserve these outliers. They might do this by not quantizing them at all, or by saving their location and value into a separate table, then removing them so that their block isn't destroyed.
Plus there's a section on How much does quantization affect model accuracy?. Sam explains the concepts of perplexity and KL divergence and then uses the llama.cpp perplexity tool and a run of the GPQA benchmark to show how different quantization levels affect Qwen 3.5 9B.
His conclusion:
It looks like 16-bit to 8-bit carries almost no quality penalty. 16-bit to 4-bit is more noticeable, but it's certainly not a quarter as good as the original. Closer to 90%, depending on how you want to measure it.
Tags: computer-science, ai, explorables, generative-ai, llms, sam-rose, qwen
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み