ウェイモとテスラの自動運転システムは、人々が考えるよりも似通っている
この記事は、Waymo と Tesla が従来の手法からトランスフォーマーベースの「エンドツーエンド」型自律走行モデルへ移行し、両社の技術的アプローチが思われているほど大きく異ならないことを示した。
キーポイント
業界のパラダイムシフト:モジュール型からエンドツーエンドへ
Wayve や Tesla が明示的なルールベースやモジュール型アプローチから、単一のトランスフォーマーモデルで運転全体を処理する「エンドツーエンド」アーキテクチャへと移行している。
Waymo の技術的進化と EMMA モデルの限界
Waymo も Gemini ベースの基礎モデル「EMMA」を開発したが、空間推論や計算コストの課題から研究段階にとどまり、現在は商業車隊向けに改良されたエンドツーエンドモデルを採用している。
Tesla と Waymo の技術的類似性の再評価
一般には Tesla が AI 先進派、Waymo がルールベースと見なされがちだが、実際には両社とも人間の価値観をコード化する難しさを克服するため、同様の深層学習アプローチを採用している。
LLM の限界とハイブリッドアプローチ
EMMAのようなLLMベースのモデルは複雑な状況判断に優れるが、応答速度(レイテンシ)や幾何学的推論(物体の正確な位置把握)に課題があり、Waymo はこれらに依存せず、センサー融合エンコーダーを組み合わせたハイブリッドシステムを採用している。
Gemini を活用した VLM モジュール
Waymo のシステムは Gemini 大規模言語モデルを基盤としたビジョン・ランゲージモデル(VLM)モジュールを含み、稀で複雑な文脈的な状況理解のために「広範な世界知識」を活用している。
競合他社との技術的類似性
Waymo の EMMA 型アプローチや Gemini を活用した VLM は、Tesla や Wayve が自社の自動運転システムで説明している手法と非常に似ており、多くの人が思っているほど他社とは大きく異なるわけではない。
データ駆動型オブジェクト表現の採用
Waymo は人間が手動で定義する変数に頼らず、学習プロセスを通じて運転に必要な情報を最も効果的に捉える「オブジェクトベクトル」を自動生成している。
影響分析・編集コメントを表示
影響分析
この報道は、自動運転業界における技術的コンセンサスが明確に「エンドツーエンド型 AI」へ収束しつつあることを示しており、従来のルールベース開発からの決別を裏付ける重要な証拠となる。これにより、Waymo の技術が陳腐化しているという誤解が払拭され、両社とも高度な深層学習モデルの競争において同等の立場にあることが浮き彫りになる。今後の業界動向は、単一のモデルでいかに安全性と汎用性を高めるかという点に焦点が移るだろう。
編集コメント
自動運転業界の技術的対立構造が再定義される重要な記事です。Waymo の技術革新性を過小評価する声に対し、実態に即した分析がなされています。
大規模言語モデルの基盤となるトランスフォーマーアーキテクチャは、非常に多用途です。研究者たちは、言語以外の多くのユースケースを見出しており、画像の理解からタンパク質の構造予測、ロボットアームの制御まで含まれています。
自動運転業界もこの潮流に乗り遅れていません。例えば昨年、自律走行車スタートアップのウェイブ(Wayve)は 10 億ドルを調達しました。ラウンド発表のプレスリリースにおいて、ウェイブは「自律のためのファウンデーションモデルを構築している」と述べています。
「2017 年に会社を設立した際、シードデッキでの最初の提案は古典的なロボティクスアプローチに焦点を当てていました」と、ウェイブの CEO アレックス・ケンドール(Alex Kendall)氏は 11 月のインタビューで語っています。このアプローチとは、「自律の問題を多数の異なるコンポーネントに分解し、主に手作業で設計すること」でした。
一方、ウェイブは異なるアプローチを採用しました。単一のトランスフォーマーベースのファウンデーションモデル(foundation model)をトレーニングして、運転タスク全体を処理させるのです。ウェイブは、自社のネットワークが新しい都市や運転条件により容易に適応できると主張しています。
テスラも同じ方向へ進んでいます。
購読する
「以前はデバッグが非常に簡単だったため、明示的でモジュラーなアプローチに取り組んでいました」と、テスラの AI 責任者アショク・エラスワミ(Ashok Elluswamy)氏は最近の会議で語りました。「しかし、我々が見つかったのは、人間の価値をコード化することがいかに困難かということです」
そこで数年前、テスラは古いコードを廃棄し、エンドツーエンドアーキテクチャ(end-to-end architecture)を採用しました。以下はエラスワミ氏の 10 月のプレゼンテーションからのスライドです:
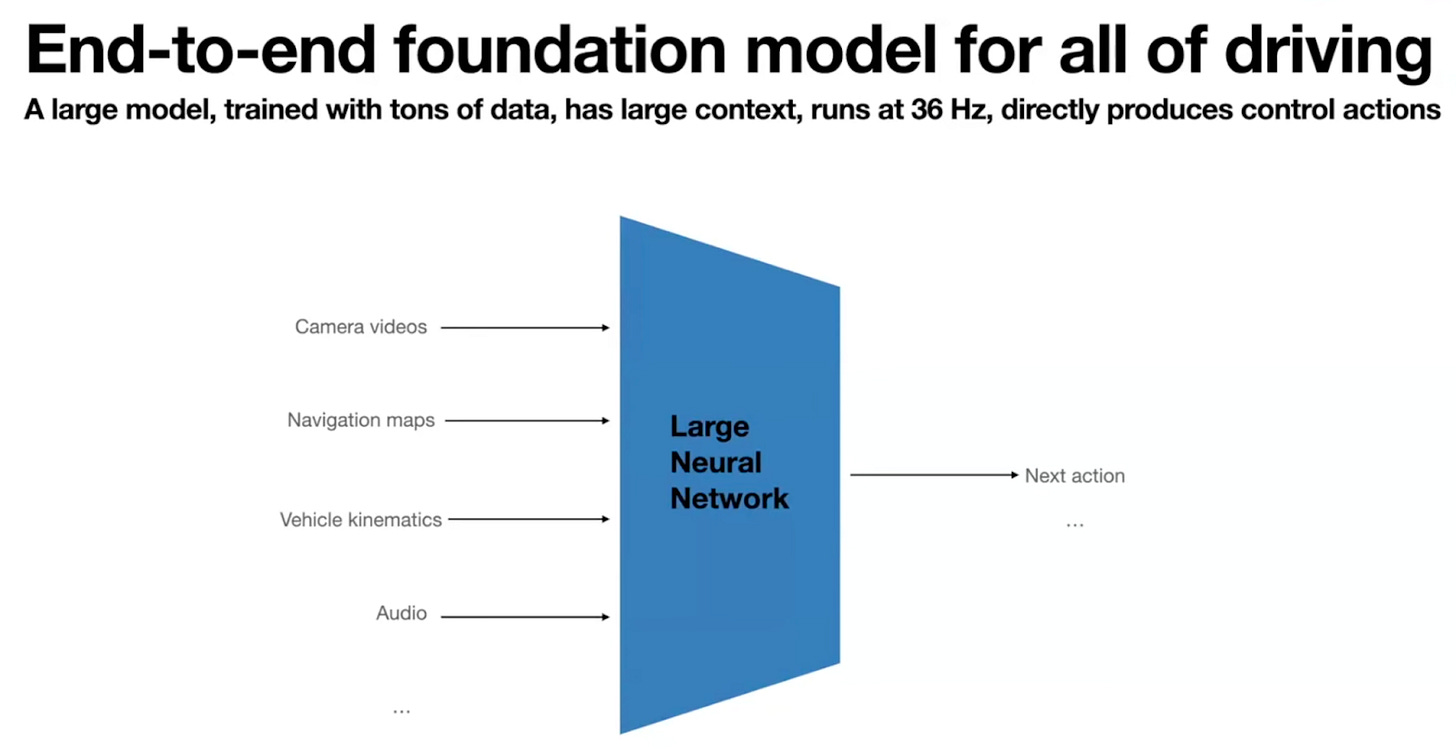
一般的な通説では、Waymo は劇的に異なるアプローチを採用しているとされています。多くの people、特に Tesla のファンたちは、Tesla の自動運転技術が最先端のエンドツーエンド AI モデルに基づいている一方、Waymo はまだ重厚な手書きルール集に依存していると考えています。
しかし、それは真実ではありません — あるいは少なくとも、その違いを大幅に誇張しています。
昨年、Waymo は Google の Gemini を基盤として構築された自動運転のファウンデーションモデルである EMMA に関する論文を発表しました。
「EMMA は、生カメラセンサーデータを直接、プランナー軌道、知覚オブジェクト、道路グラフ要素など、各種の運転固有の出力にマッピングします」と研究者らは記述しています。
EMMA モデルは一部の点で印象的でしたが、Waymo チームはそれが「実世界での展開において課題に直面している」こと、すなわち空間推論能力の低さと高い計算コストを指摘しました。つまり、EMMA の論文が記述したのは研究用プロトタイプであり、商用利用に適したアーキテクチャではないのです。
しかしウェイモはこのアプローチを継続的に改良し続けてきました。先週、ウェイモはブログ記事を通じて、自社の商用車隊に搭載された自動運転技術の内幕を明らかにしました。その結果、現在のウェイモ車両が、テスラやウェイブの車両と同様に、エンドツーエンドで訓練されたファウンデーションモデルによって制御されていることが明らかになりました。
この報道のために、私は複数のウェイモの研究論文を読み込み、ウェイモ、ウェイブ、テスラの経営陣によるプレゼンテーションやインタビューを視聴しました。また、ウェイモの共同 CEO であるドミトリ・ドルゴフ氏ともお話しする機会を得ました。以下では、ウェイモの技術がどのように機能しているのか、そしてなぜそれが多くの人が考えるよりも競合他社の技術とより類似しているのかについて、詳しく解説します。
速い思考と遅い思考
一部の運転シナリオでは、複雑で包括的な推論が必要です。例えば、警察官が事故車両の周囲で交通整理を行っている状況を想像してください。この状況に対応するには、警官の手信号を解釈するだけでなく、混乱した状況の中を走行する他の車両の目的や予想される行動についても推論する必要があります。EMMA 論文(注:End-to-end Multimodal Model for Autonomous driving)では、LLM ベースのモデルが、従来のモジュラーアプローチよりもはるかに複雑な状況を処理できることが示されました。
しかし、EMMA のようなファウンデーションモデルにも現実的な欠点があります。その一つがレイテンシ(遅延)です。一部の運転シナリオでは、数分の 1 秒の差が生と死を分けます。ジェミニのようなモデルのトークンごとの推論スタイルは、長く予測不能な応答時間を招く可能性があります。
従来のファウンデーションモデルも幾何学的推論にはあまり得意ではありません。画像内の物体の正確な位置を常に判断できるわけではありません。また、物体を見落としたり、存在しない物体を幻覚のように生成したりすることもあります。
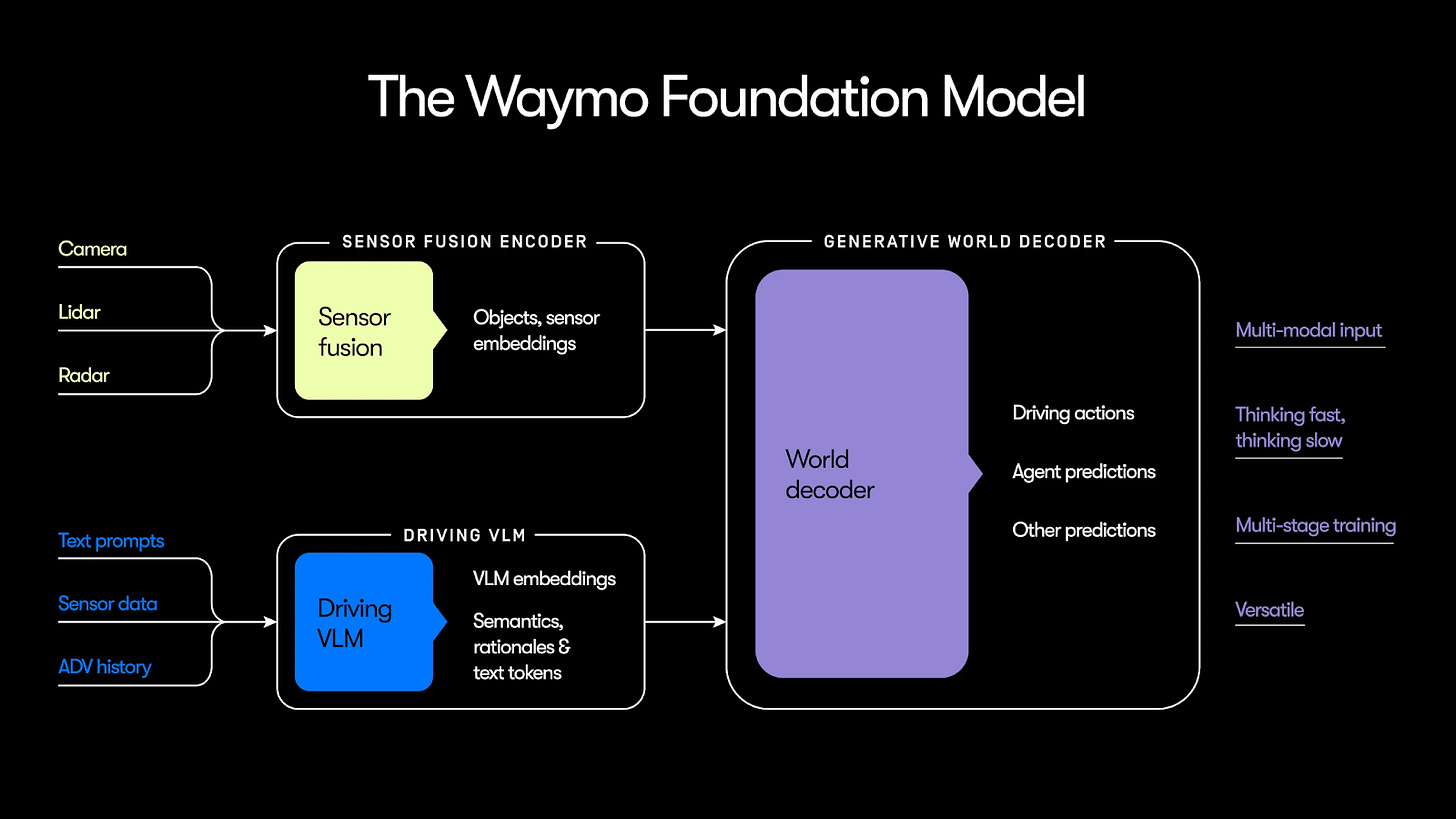
そのため、Waymo は EMMA 型のビジョン・ランゲージモデル(VLM)に完全に依存するのではなく、2 つのニューラルネットワークを並列に配置しました。以下は Waymo のブログ記事からの図です:
まず、図の左下部分を拡大してみましょう:
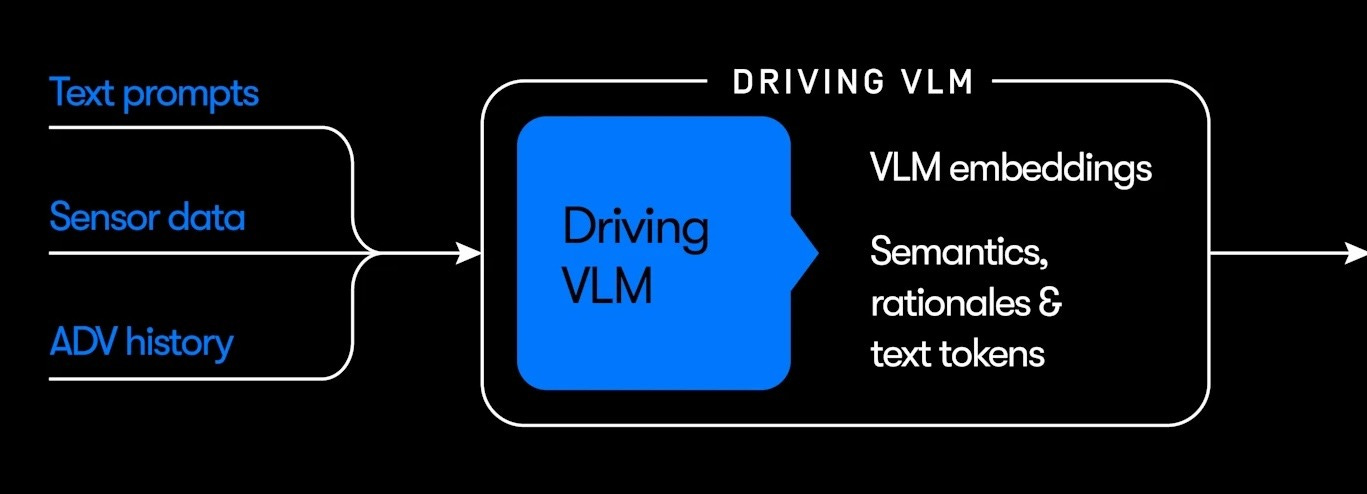
ここで VLM とはビジョン・ランゲージモデル(Vision-Language Model)の略で、具体的には画像とテキストの両方を処理できる Google の AI モデルである Gemini を指します。Waymo によると、このシステム部分は「Gemini を用いて訓練され」、道路における稀な、新規な、および複雑な意味論的シナリオをよりよく理解するために「Gemini の広範な世界知識を活用している」とのことです。
これと比較すると、EMMA は Gemini などの事前学習済み大規模言語モデル(Large Language Models)からの「世界知識の有用性」を最大化するものとして Waymo が説明しています。この 2 つのアプローチは非常に似ており、どちらも Tesla や Wayve が自走システムについて述べている方法と類似しています。
「ミリ秒の差が本当に重要なのです」
しかし、今日の Waymo 車両に搭載されているモデルは、EMMA に似たビジョン・ランゲージ・モデル(Vision-Language Model)だけではありません。それは、Waymo の図の左上隅に描かれている「センサー融合エンコーダー」と呼ばれるモジュールも組み込んだハイブリッドシステムです。
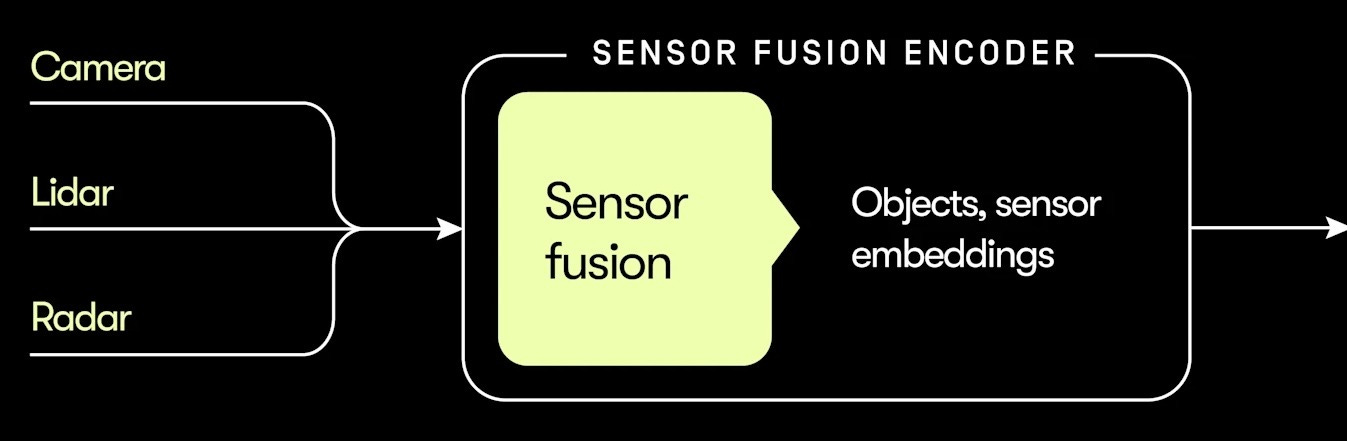
このモジュールは、速度と精度のために最適化されています。
「おそらく駐車車両の背後から何かが現れるような、遅延が致命的な安全性シナリオを想像してみてください」と Waymo の共同 CEO である Dmitri Dolgov は私に語りました。「ミリ秒の差が本当に重要なのです。精度もまた重要です。」
VLM(青いボックス)が全体像としてシーン全体を考慮するのに対し、センサー融合モジュール(黄色いボックス)は、そのシーンを他の車両、歩行者、消火栓、交通コーン、路面などといった数十個の個別オブジェクトに分解します。
Waymo の車両にはすべて、レーザーを物体に反射させて近くの物体までの距離を測定する LiDAR センサー(Light Detection and Ranging)が搭載されています。Waymo のソフトウェアは、これらの LiDAR 測定値をカメラ画像内の対応するピクセルと照合します。このプロセスは「センサー融合」と呼ばれています。これにより、システムは各オブジェクトを三次元空間内で正確に位置特定することが可能になります。
初期の自動運転システムでは、各オブジェクトをどのように表現するかは人間のプログラマーが決定していました。例えば、車両を表すデータ構造には、車両の種類、移動速度、そして方向指示器が点灯しているかどうかといった情報が記録されます。
しかし、このような手動でコーディングされたシステムが最適である可能性は低いです。あまり有用ではない情報を保存する一方で、極めて重要な情報を捨ててしまうことになるでしょう。
「運転というタスクは、優れたドライバーになるために十分な変数のセットを列挙すればよいようなものではありません」とドロゴフ氏は私に語りました。「そこには、エンジニアリングするのが非常に難しい多くの豊かさがあります。」

ウェイモの共同CEO、ドミトリ・ドロゴフ氏。(画像提供:ウェイモ)
そのため、ウェイモのモデルは、データ駆動型のトレーニングプロセスを通じて、各オブジェクトを表現する最良の方法を学習します。ウェイモはこの仕組みについて詳細な情報を私に提供しませんでしたが、2024年に発表された「MoST: Multi-modality Scene Tokenization for Motion Prediction(多様性シーントークン化による運動予測)」という論文で記述されている技術と類似しているのではないかと推測しています。
MoST 論文で記述されているシステムは、依然として運転シーンを、古い自動運転システムと同様に個々のオブジェクトに分割します。ただし、これは人間のプログラマーが選定した一連の属性を捉えるわけではありません。むしろ、運転にとって最も関連性の高い情報を捉えた「オブジェクトベクトル」を計算し、このベクトルの形式は学習プロセスを通じて獲得されます。
"ベクトルのいくつかの次元は、それが消防車か、停止標識か、木の幹か、あるいは他の何かを示す可能性があります」と私は昨年の記事で書きました。「他の次元は、オブジェクトのより微妙な属性を表します。例えば、対象が歩行者である場合、ベクトルには歩行者の頭部、腕、脚の位置に関する情報が符号化されるかもしれません」。
ここには大規模言語モデル(LLM)との類似点があります。LLM は、次のトークンを予測する際に最も関連性の高い情報を捉える「トークンベクトル」を用いて各トークンを表現します。同様に、MoST システムは運転にとって最も関連性の高いオブジェクトに関する情報を捉える方法を学習します。
Waymo が上記の図でそのセンサー融合モジュールが"objects, sensor embeddings"(オブジェクト、センサー埋め込み)を出力すると述べている際、これは MoST に似たシステムを指しているのではないかと私は推測しています。
このシステムは、これらのオブジェクトベクトルにどの情報を含めるべきかをどのように知るのでしょうか?もちろん、エンドツーエンドの学習を通じてです!
これはウェイモの自動運転システムの3つ目の、そして最後のモジュールである「ワールドデコーダ」です。
このシステムは、センサー融合エンコーダ(シーンを個々のオブジェクトに分解する高速思考モジュール)と、運転用VLM(全体としてシーンを理解しようとする低速思考モジュール)の両方から入力を受け取ります。これらのモジュールから提供される情報に基づき、ワールドデコーダは車両が取るべき最良の行動を決定しようとします。
トレーニング中、情報の流れは逆方向になります。システムは実際の現場からのデータを用いて訓練されます。もしデコーダがトレーニング例で実行された行動を正しく予測できれば、ネットワークには正の強化信号が与えられます。逆に誤った予測をした場合は、負の強化信号が与えられます。
これらの信号はその後、他の2つのモジュールへ逆伝播されます。デコーダが適切な選択を行った場合、黄色と青のボックスに対して、現在の行動を継続するよう促す信号が送り返されます。一方、デコーダが不適切な選択をした場合は、行動を変更するよう促す信号が送り返されます。
これらのシグナルに基づき、センサー融合モジュールは、オブジェクトベクトルに含めるべき情報と、安全に省略できる情報を学習します。これもまた、各トークンを表すベクトルに含める最も有用な情報を学習する大規模言語モデル(LLM)と密接に類似しています。
購読する
モジュラーネットワークはエンドツーエンドで訓練可能
3 つの自動運転企業のリーダーたちは、これを自社の自動運転システムにおける重要なアーキテクチャ上の違いとして描いています。ウェイモは、そのハイブリッドシステムがより高速かつ正確な結果をもたらすと主張します。一方、ウェイブとテスラは、モノリス型のエンドツーエンドアーキテクチャの単純さを強調しています。彼らは、この「苦い教訓(Bitter Lesson)」—すなわち、最良の結果は往々にして単純なアーキテクチャをスケールアップすることから得られるという洞察—のおかげで、自社のモデルが最終的に勝利すると信じています。
3 月のインタビューで、ポッドキャスターのサム・シャリンガートンは、ウェイモのドラゴミル・アンゲロフにハイブリッドシステムを構築する選択について尋ねました。
「私たちは実用主義的な立場にあります」とアンゲロフは言いました。「最もよく機能するものを選びます。」
アンゲロフは、「エンドツーエンド」という用語はモデルアーキテクチャではなく、訓練戦略を記述するものであると指摘しました。エンドツーエンド訓練とは単に、勾配がネットワーク全体を通じて伝播されることを意味します。前述の通り、ウェイモのネットワークもこの意味でエンドツーエンドです:訓練中、誤差信号は紫色のボックスから黄色および青色のボックスへと後方へ伝播されます。
「モジュールを維持しつつ、エンドツーエンドで学習することも可能です」とアンゲロフ氏は 3 月に述べています。「時間とともに学んだのは、可能であれば少数の大きなコンポーネントを持つべきだということです。それによって開発が簡素化されます。」しかし、彼は続けて、「それが単一のコンポーネントであるべきかどうかについては、まだ合意に至っていません」と付け加えました。
これまでにウェイモは、3 つのモジュールからなる自社のモジュラーアプローチ(単一ではなく)の方が、商業展開には適していると見出しています。
ウェイモの共同 CEO であるドミトリ・ドルゴフ氏は、EMMA のようなモノリス型アーキテクチャ(monolithic architecture)は「始めるのが非常に簡単ですが、安全かつ大規模に完全な自律走行を実現するには全く不十分です」と語りました。
私はすでにレイテンシ(遅延)と精度を 2 つの主要な懸念事項として挙げました。もう一つの課題は検証です。自動運転システムは単に安全であるだけでなく、それを開発する企業が高レベルの信頼性をもってその安全性を証明できる必要があります。これは、システムがブラックボックス状態にある場合、実行するのが困難です。
ウェイモのハイブリッド型アーキテクチャの下では、各モジュールが果たすべき機能をエンジニアが把握しているため、個別にテストおよび検証を行うことが可能になります。例えば、シーン内の物体を特定する機能が分かっている場合、センサー融合(sensor fusion)モジュールの出力を確認し、対象となるすべての物体を正しく識別できているかを確認できます。
これらのアーキテクチャ上の違いは過大評価されているように思われます
私の疑念は、実際の違いは双方が認めようとするよりも小さいのではないかということです。ウェイモが手動でコーディングされたルールに基づく時代遅れのシステムに縛られているというのは事実ではありません。同社は現代の AI 技術を幅広く活用しており、そのシステムは新しい都市への一般化も十分に可能であるように見えます。
確かに、もしウェイモが図から黄色いボックスを削除すれば、結果として得られるモデルはテスラやウェイブのものとは非常に類似したものになるでしょう。ウェイモはこのトランスフォーマーベースのモデルに、速度と幾何学的精度のために調整されたセンサー融合モジュールを追加しています。しかし、ウェイモがそのセンサー融合モジュールがあまり価値をもたらしていないと判断すれば、いつでもそれを削除することも可能です。したがって、このモジュールがウェイモを重大な不利な立場に追いやることは想像しにくいのです。
同時に、ウェイブやテスラが自社のシステムのモジュラー性をマーケティング目的で過小評価しているのではないかとも思います。彼らが投資家に対して提示する主張は、ウェイモのような既存企業とは根本的に異なるアプローチを開拓しているというものであり、そのアプローチは OpenAI や Anthropic といったフロンティア研究所にインスパイアされたものです。この提案に投資家は深く感銘を受け、昨年はウェイブに 10 億ドルの資金を提供しました。また、テスラの自動運転プロジェクトへの楽観視が、近年同社の株価を押し上げる要因となっています。
例えば、ウェイブは自社のアーキテクチャを以下のように描いています:
一見すると、これは「純粋」なエンドツーエンド・アーキテクチャに見えます。しかし、よく見てみると、Wayve のモデルには「安全性専門家サブシステム」が含まれていることに気づくでしょう。それは何でしょうか?私はこの仕組みがどのように機能し、何を果たすのかについて詳細を見つけることができませんでした。ただし、2024 年のブログ投稿で Wayve は、そのモデルに「本能的な安全反応(innate safety reflex)」を持たせるための取り組みについて言及しています。
Wayve によると、同社はシミュレーションを用いて「緊急反応サブシステムの潜在表現を最適に強化する」そうです。Wayve はさらに、「緊急反応を超充放電するために、他のセンサーモダリティなどの追加情報源を取り入れることができる」と付け加えています。
これは少なくとも、Waymo のセンサー融合モジュール(sensor fusion module)と少し似ているように聞こえます。両システムが同一である、あるいは非常に類似しているとは主張しません。しかし、自動運転企業は Waymo と同じ基本的な課題に対処する必要があります:大規模で単一の巨大言語モデルは遅く、誤りやすく、デバッグが困難であるという点です。Wayve がその技術を商業化するために準備を整えるにつれ、コアとなるエンドツーエンド・モデルを補完し、よりテストと検証が容易な追加情報源を追加する必要があると考えられます——もし既にそうしていないとしても。
⟦CODE_0⟧
原文を表示
The transformer architecture underlying large language models is remarkably versatile. Researchers have found many use cases beyond language, from understanding images to predicting the structure of proteins to controlling robot arms.
The self-driving industry has jumped on the bandwagon too. Last year, for example, the autonomous vehicle startup Wayve raised $1 billion. In a press release announcing the round, Wayve said it was “building foundation models for autonomy.”
“When we started the company in 2017, the opening pitch in our seed deck was all about the classical robotics approach,” Wayve CEO Alex Kendall said in a November interview. That approach was to “break down the autonomy problem into a bunch of different components and largely hand-engineer them.”
Wayve took a different approach, training a single transformer-based foundation model to handle the entire driving task. Wayve argues that its network can more easily adapt to new cities and driving conditions.
Tesla has been moving in the same direction.
Subscribe now
“We used to work on an explicit, modular approach because it was so much easier to debug,” said Tesla AI chief Ashok Elluswamy at a recent conference. “But what we found out was that codifying human values was really difficult.”
So a couple of years ago, Tesla scrapped its old code in favor of an end-to-end architecture. Here’s a slide from Elluswamy’s October presentation:
Conventional wisdom holds that Waymo has a dramatically different approach. Many people — especially Tesla fans — believe that Tesla’s self-driving technology is based on cutting-edge, end-to-end AI models, while Waymo still relies on a clunky collection of handwritten rules.
But that’s not true — or at least it greatly exaggerates the differences.
Last year, Waymo published a paper on EMMA, a self-driving foundation model built on top of Google’s Gemini.
“EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements,” the researchers wrote.
Although the EMMA model was impressive in some ways, the Waymo team noted that it “faces challenges for real-world deployment,” including poor spatial reasoning ability and high computational costs. In other words, the EMMA paper described a research prototype — not an architecture that was ready for commercial use.
But Waymo kept refining this approach. In a blog post last week, Waymo pulled back the curtain on the self-driving technology in its commercial fleet. It revealed that Waymo vehicles today are controlled by a foundation model that’s trained in an end-to-end fashion — just like Tesla and Wayve vehicles.
For this story, I read several Waymo research papers and watched presentations by (and interviews with) executives at Waymo, Wayve, and Tesla. I also had a chance to talk to Waymo co-CEO Dmitri Dolgov. Read on for an in-depth explanation of how Waymo’s technology works, and why it’s more similar to rivals’ technology than many people think.
Thinking fast and slow
Some driving scenarios require complex, holistic reasoning. For example, suppose a police officer is directing traffic around a crashed vehicle. Navigating this scene not only requires interpreting the officer’s hand signals, it also requires reasoning about the goals and likely actions of other vehicles as they navigate a chaotic situation. The EMMA paper showed that LLM-based models can handle these complex situations much better than a traditional modular approach.
But foundation models like EMMA also have real downsides. One is latency. In some driving scenarios, a fraction of a second can make the difference between life and death. The token-by-token reasoning style of models like Gemini can mean long and unpredictable response times.
Traditional foundation models are also not very good at geometric reasoning. They can’t always judge the exact locations of objects in an image. They might also overlook objects or hallucinate ones that aren’t there.
So rather than relying entirely on an EMMA-style vision-language model (VLM), Waymo placed two neural networks side by side. Here’s a diagram from Waymo’s blog post:
Let’s start by zooming in on the lower-left of the diagram:
VLM here stands for vision-language model — specifically Gemini, the Google AI model that can handle images as well as text. Waymo says this portion of its system was “trained using Gemini” and “leverages Gemini’s extensive world knowledge to better understand rare, novel, and complex semantic scenarios on the road.”
Compare that to EMMA, which Waymo described as maximizing the “utility of world knowledge” from “pre-trained large language models” like Gemini. The two approaches are very similar — and both are similar to the way Tesla and Wayve describe their self-driving systems.
“Milliseconds really matter”
But the model in today’s Waymo vehicles isn’t just an EMMA-like vision-language model — it’s a hybrid system that also includes a module called a sensor fusion encoder that is depicted in the upper-left corner of Waymo’s diagram:
This module is tuned for speed and accuracy.
“Imagine a latency-critical safety scenario where maybe an object appears from behind a parked car,” Waymo co-CEO Dmitri Dolgov told me. “Milliseconds really matter. Accuracy matters.”
Whereas the VLM (the blue box) considers the scene as a whole, the sensor fusion module (the yellow box) breaks the scene into dozens of individual objects: other vehicles, pedestrians, fire hydrants, traffic cones, the road surface, and so forth.
It helps that every Waymo vehicle has lidar sensors that measure the distance to nearby objects by bouncing lasers off of them. Waymo’s software matches these lidar measurements to the corresponding pixels in camera images — a process called sensor fusion. This allows the system to precisely locate each object in three-dimensional space.
In early self-driving systems, a human programmer would decide how to represent each object. For example, the data structure for a vehicle might record the type of vehicle, how fast it’s moving, and whether it has a turn signal on.
But a hand-coded system like this is unlikely to be optimal. It will save some information that isn’t very useful while discarding other information that might be crucial.
“The task of driving is not one where you can just enumerate a set of variables that are sufficient to be a good driver,” Dolgov told me. “There’s a lot of richness that is very hard to engineer.”
Waymo co-CEO Dmitri Dolgov. (Image courtesy of Waymo)
So instead, Waymo’s model learns the best way to represent each object through a data-driven training process. Waymo didn’t give me a ton of information about how this works, but I suspect it’s similar to the technique described in the 2024 Waymo paper called “MoST: Multi-modality Scene Tokenization for Motion Prediction.”
The system described in the MoST paper still splits a driving scene up into distinct objects as in older self-driving systems. But it doesn’t capture a set of attributes chosen by a human programmer. Rather, it computes an “object vector” that captures information that’s most relevant for driving — and the format of this vector is learned during the training process.
“Some dimensions of the vector will likely indicate whether it’s a fire truck, a stop sign, a tree trunk, or something else,” I wrote in an article last year. “Other dimensions will represent subtler attributes of objects. If the object is a pedestrian, for example, the vector might encode information about the position of the pedestrian’s head, arms, and legs.”
There’s an analogy here to LLMs. An LLM represents each token with a “token vector” that captures the information that’s most relevant to predicting the next token. In a similar way, the MoST system learns to capture the information about objects that are most relevant for driving.
I suspect that when Waymo says its sensor fusion module outputs “objects, sensor embeddings” in the diagram above, this is a reference to a MoST-like system.
How does the system know which information to include in these object vectors? Through end-to-end training of course!
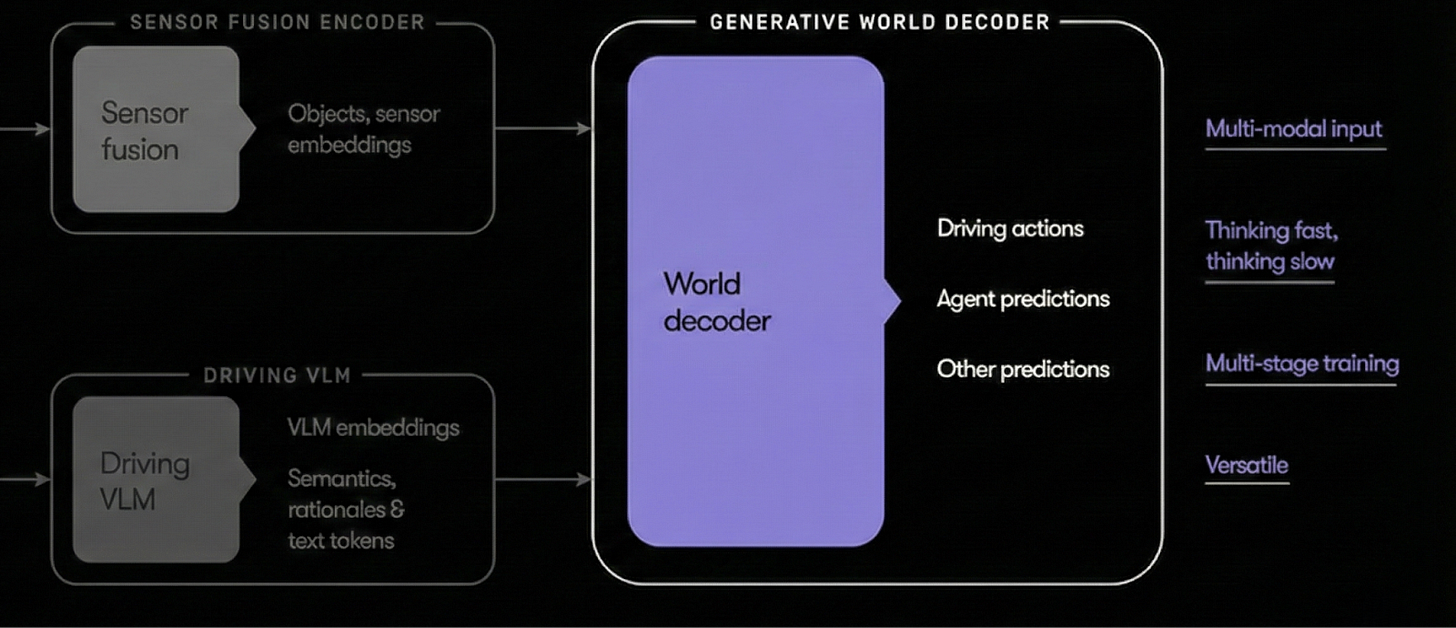
This is the third and final module of Waymo’s self-driving system, called the world decoder.
It takes inputs from both the sensor fusion encoder (the fast-thinking module that breaks the scene into individual objects) and the driving VLM (the slow-thinking module that tries to understand the scene as a whole). Based on information supplied by these modules, the world decoder tries to decide the best action for a vehicle to take.
During training, information flows in the opposite direction. The system is trained on data from real-world situations. If the decoder correctly predicts the actions taken in the training example, the network gets positive reinforcement. If it guesses wrong, then it gets negative reinforcement.
These signals are then propagated backward to the other two modules. If the decoder makes a good choice, signals are sent back to the yellow and blue boxes encouraging them to continue doing what they’re doing. If the decoder makes a bad choice, signals are sent back to change what they’re doing.
Based on these signals, the sensor fusion module learns which information is most helpful to include in object vectors — and which information can be safely left out. Again, this is closely analogous to LLMs, which learn the most useful information to include in the vectors that represent each token.
Subscribe now
Modular networks can be trained end-to-end
Leaders at all three self-driving companies portray this as a key architectural difference between their self-driving systems. Waymo argues that its hybrid system delivers faster and more accurate results. Wayve and Tesla, in contrast, emphasize the simplicity of their monolithic end-to-end architectures. They believe that their models will ultimately prevail thanks to the Bitter Lesson — the insight that the best results often come from scaling up simple architectures.
In a March interview, podcaster Sam Charrington asked Waymo’s Dragomir Anguelov about the choice to build a hybrid system.
“We’re on the practical side,” Anguelov said. “We will take the thing that works best.”
Anguelov pointed out that the phrase “end-to-end” describes a training strategy, not a model architecture. End-to-end training just means that gradients are propagated all the way through the network. As we’ve seen, Waymo’s network is end-to-end in this sense: during training, error signals propagate backward from the purple box to the yellow and blue boxes.
“You can still have modules and train things end-to-end,” Anguelov said in March. “What we’ve learned over time is that you want a few large components, if possible. It simplifies development.” However, he added, “there is no consensus yet if it should be one component.”
So far, Waymo has found that its modular approach — with three modules rather than just one — is better for commercial deployment.
Waymo co-CEO Dmitri Dolgov told me that a monolithic architecture like EMMA “makes it very easy to get started, but it’s wildly inadequate to go to full autonomy safely and at scale.”
I’ve already mentioned latency and accuracy as two major concerns. Another issue is validation. A self-driving system doesn’t just need to be safe, the company making it needs to be able to prove it’s safe with a high level of confidence. This is hard to do when the system is a black box.
Under Waymo’s hybrid architecture, the company’s engineers know what function each module is supposed to perform, which allows them to be tested and validated independently. For example, if engineers know what objects are in a scene, they can look at the output of the sensor fusion module to make sure it identifies all the objects it’s supposed to.
These architectural differences seem overrated
My suspicion is that the actual differences are smaller than either side wants to admit. It’s not true that Waymo is stuck with an outdated system based on hand-coded rules. The company makes extensive use of modern AI techniques, and its system seems perfectly capable of generalizing to new cities.
Indeed, if Waymo deleted the yellow box from its diagram, the resulting model would be very similar to those at Tesla and Wayve. Waymo supplements this transformer-based model with a sensor fusion module that’s tuned for speed and geometric precision. But if Waymo finds the sensor fusion module isn’t adding much value, it can always remove it. So it’s hard to imagine the module puts Waymo at a major disadvantage.
At the same time, I wonder if Wayve and Tesla are downplaying the modularity of their own systems for marketing purposes. Their pitch to investors is that they’re pioneering a radically different approach than incumbents like Waymo — one that’s inspired by frontier labs like OpenAI and Anthropic. Investors were so impressed by this pitch that they gave Wayve $1 billion last year, and optimism about Tesla’s self-driving project has pushed up the company’s stock price in recent years.
For example, here’s how Wayve depicts its own architecture:
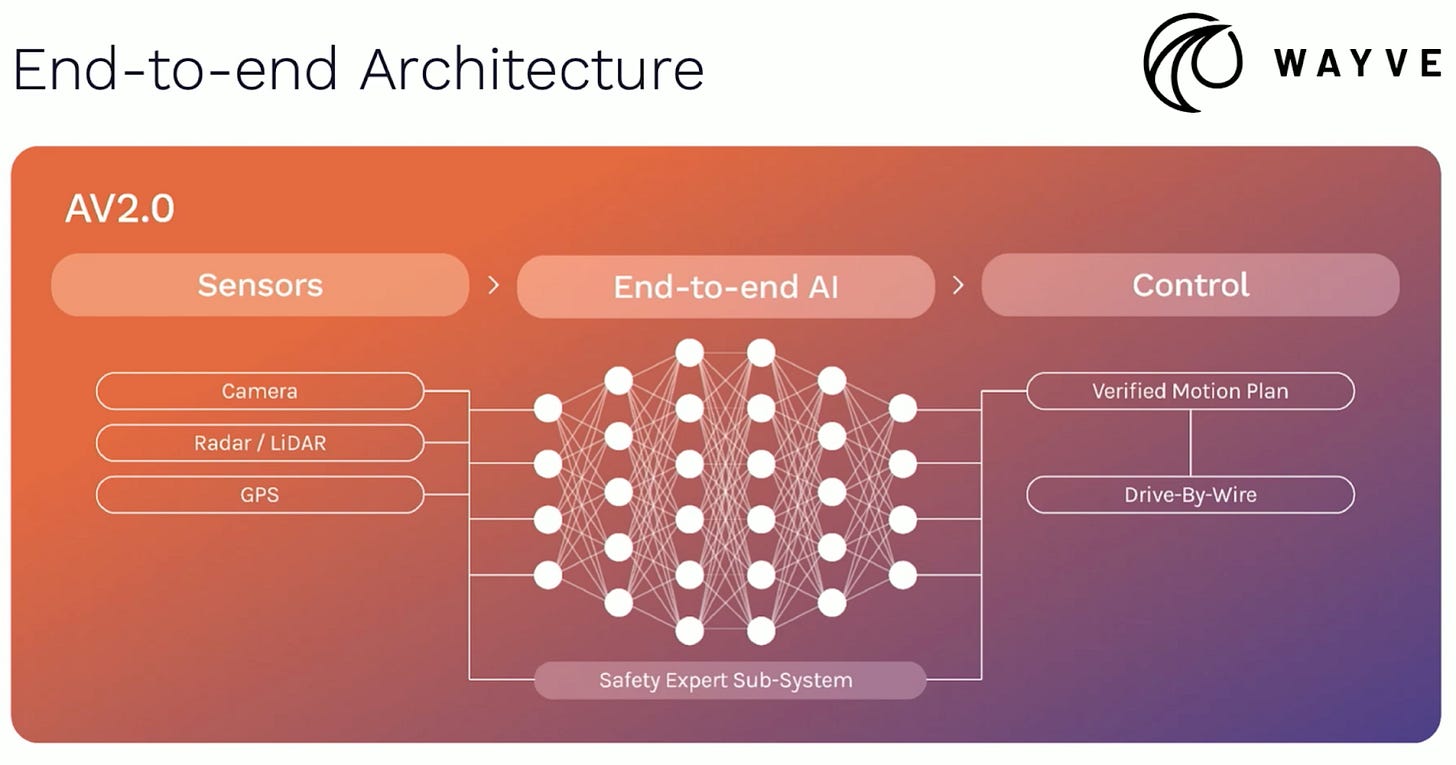
At first glance, this looks like a “pure” end-to-end architecture. But look closer and you’ll notice that Wayve’s model includes a “safety expert sub-system.” What’s that? I haven’t been able to find any details on how this works or what it does. But in a 2024 blog post, Wayve wrote about its effort to train its models to have an “innate safety reflex.”
According to Wayve, the company uses simulation to “optimally enrich our Emergency Reflex subsystem’s latent representations.” Wayve added that “to supercharge our Emergency Reflex, we can incorporate additional sources of information, such as other sensor modalities.”
This sounds at least a little bit like Waymo’s sensor fusion module. I’m not going to claim that the systems are identical or even all that similar. But any self-driving company has to address the same basic problem as Waymo: that large, monolithic language models are slow, error-prone, and difficult to debug. I expect that as it gets ready to commercialize its technology, Wayve will need to supplement the core end-to-end model with additional information sources that are easier to test and validate — if it isn’t doing so already.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み