2025年の大規模言語モデルの現状:進歩、課題、予測
Sebastian Raschka は、2025 年の LLM 業界における推論能力の飛躍的進化と、DeepSeek R1 が示したトレーニングコスト劇的な低下という事実を分析し、業界のパラダイムシフトを指摘している。
キーポイント
推論モデル(Reasoning Models)の台頭
2025 年は「スケーリング」から「推論能力」への転換期であり、DeepSeek R1 の発表により、強化学習(RLVR, GRPO)を用いて中間ステップを生成する推論モデルが実用化された。
トレーニングコストの劇的低下
DeepSeek V3/R1 の成功により、最先端モデルのトレーニングコストは従来の数億ドルから約 500 万ドル(V3)および追加 29.4 万ドル(R1)へと桁違いに低下したと再評価された。
オープンウェイトとプロプライエタリモデルの逆転
DeepSeek R1 はオープンウェイトでありながら、ChatGPT や Gemini などの最高峰プロプライエタリモデルに匹敵する性能を発揮し、市場競争の構造を変えた。
RLVR と GRPO アルゴリズムの登場
DeepSeek R1 は、数学やコードなどの正解が確定するタスクに対して「検証可能な報酬(Verifiable Rewards)」を用いた RLVR と GRPO アルゴリズムを提案し、高品質なラベル作成のボトルネックを解消しました。
計算リソースによるスケーリングの可能性
従来の SFT や RLHF が人手や合成データの質に依存していたのに対し、RLVR は大量のデータで後学習(post-training)を行い、利用可能な計算リソースに基づいてモデル能力を拡張・解き放つことを可能にします。
コスト見積もりの限界
DeepSeek R1 のトレーニングコストが 500 万ドルと推定されていますが、これは計算リソースのクレジットコストのみを含んでおり、研究者の人件費やハイパーパラメータ調整などの開発費用は含まれていません。
2025年のLLM開発の主流は推論モデル
DeepSeek R1の影響を受け、主要なオープンウェイトおよびプロプライエタリなLLM開発者がRLVR(Reinforcement Learning from Verifiable Rewards)とGRPOを用いた「思考」バリアントを相次いでリリースしている。
影響分析・編集コメントを表示
影響分析
この記事は、2025 年の LLM 業界における決定的な転換点を示しており、技術的進歩(推論能力)と経済的現実(コスト低下)の両面で業界構造を根本から変える内容です。特にトレーニングコストの桁違いな低下は、AI 開発民主化を加速させ、今後数年間で市場参入プレイヤーが爆発的に増加する要因となると予測されます。
編集コメント
2025 年の LLM 進化を要約した本記事は、単なる技術レビューを超え、AI 開発の経済モデルそのものが書き換えられたことを示唆しています。特に「推論」と「低コスト」が同時に実現された点は、今後の産業応用におけるゲームチェンジャーとなるでしょう。
LLMの現状 2025:進展、課題、予測
 Sebastian Raschka, PhD 2025年12月30日 5023955 シェア
Sebastian Raschka, PhD 2025年12月30日 5023955 シェア
2025年が終わりに近づく中、今年の大規模言語モデルにおける最も重要な進展を振り返り、残されている限界と未解決の問題について考察し、今後起こりうることについての私見を共有したいと思います。
私が毎年言う傾向にあるように、2025年はLLMとAIにとって非常に出来事の多い年であり、今年も進歩が飽和したり鈍化したりする兆候は見られませんでした。
1. 推論、RLVR、GRPOの年
取り上げたい興味深いトピックは数多くありますが、まずは時系列で2025年1月から始めましょう。
スケーリングは依然として有効でしたが、実際のLLMの振る舞いや感覚を根本的に変えるものではありませんでした(唯一の例外は、推論の軌跡を追加したOpenAIの新モデルo1です)。したがって、2025年1月にDeepSeekがR1論文を発表し、強化学習によって推論的な振る舞いを発展させられることを示したとき、それは非常に大きな出来事でした。(LLMの文脈における「推論」とは、モデルが答えを説明し、その説明自体が答えの精度向上につながることを意味します。)
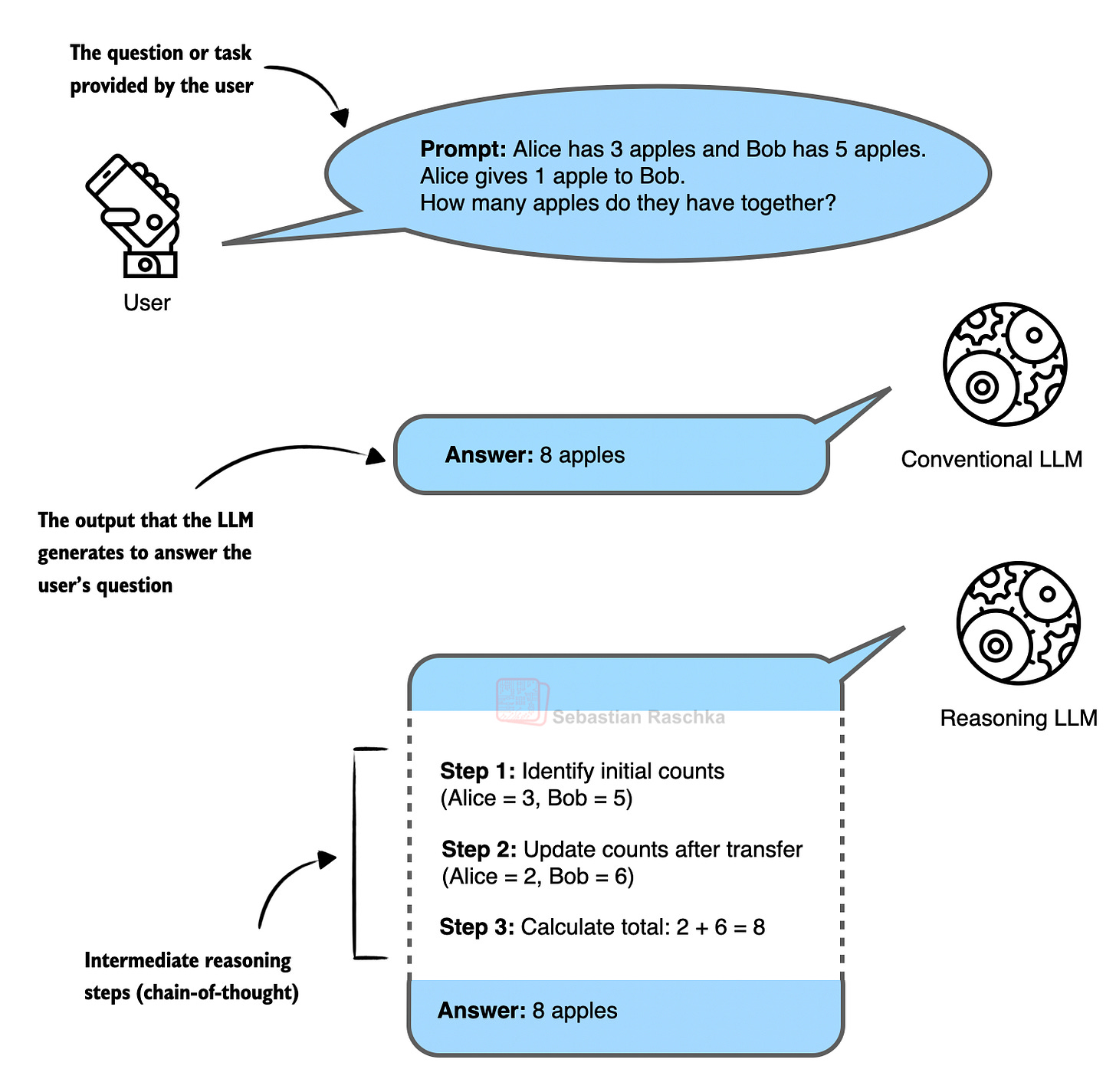 図1:推論モデルで典型的に生成される、短い応答と中間ステップを含む長い応答。
図1:推論モデルで典型的に生成される、短い応答と中間ステップを含む長い応答。
1.1 DeepSeekの瞬間
DeepSeek R1は様々な理由で大きな注目を集めました。
第一に、DeepSeek R1はオープンウェイトモデルとしてリリースされ、非常に優れた性能を発揮し、当時の最高のプロプライエタリモデル(ChatGPT、Geminiなど)に匹敵するものでした。
第二に、DeepSeek R1論文は、多くの人々、特に投資家やジャーナリストに、2024年12月の初期のDeepSeek V3論文を再検討するきっかけを与えました。これにより、最先端モデルのトレーニングは依然として高額ではあるものの、以前想定されていたよりも一桁安い可能性があり、その推定額は5000万ドルや5億ドルではなく、500万ドルに近いという修正された結論に至りました。
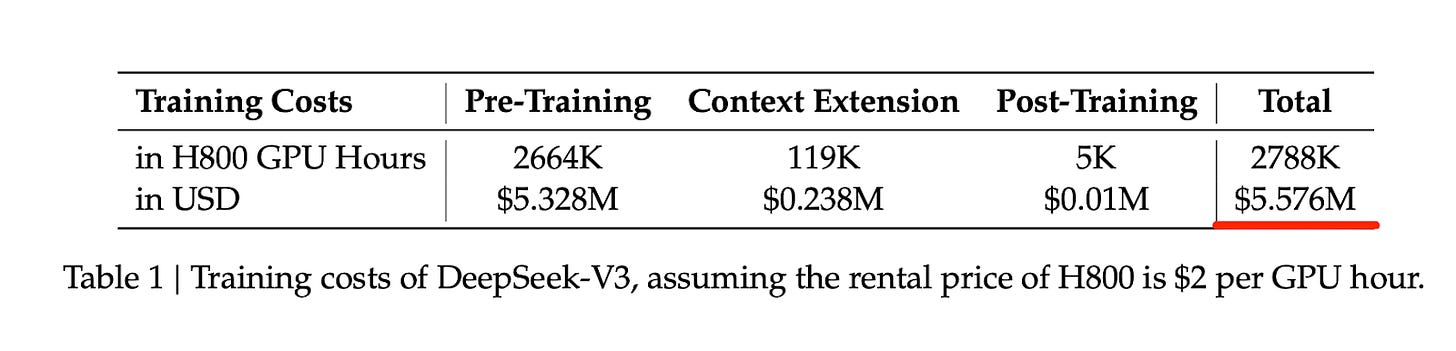 図2:671BパラメータのDeepSeek V3モデルのトレーニングコストを推定したDeepSeek V3論文の表。
図2:671BパラメータのDeepSeek V3モデルのトレーニングコストを推定したDeepSeek V3論文の表。
DeepSeek R1の補足資料では、DeepSeek V3の上にDeepSeek R1モデルをトレーニングするコストはさらに29万4000ドルと推定されており、これもまた誰もが信じていたよりもはるかに低いものです。
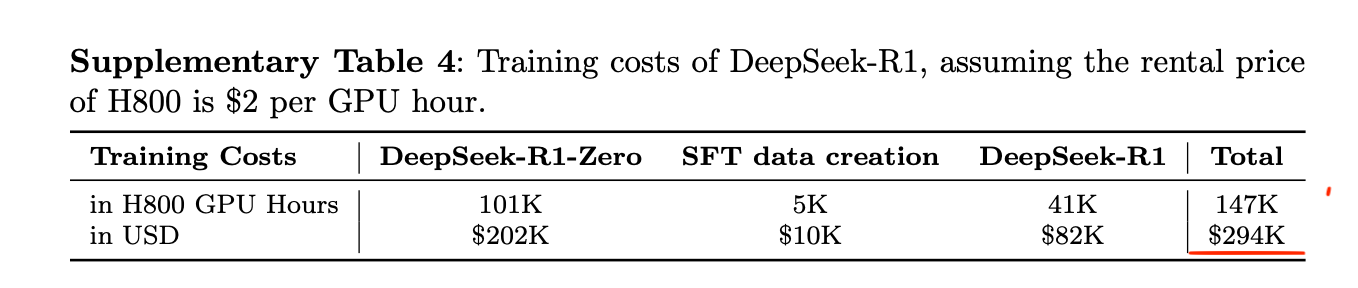 図3:DeepSeek V3上でR1モデルをトレーニングするコストを推定したDeepSeek R1論文補足資料の表。
図3:DeepSeek V3上でR1モデルをトレーニングするコストを推定したDeepSeek R1論文補足資料の表。
もちろん、500万ドルという推定には多くの注意点があります。例えば、それは最終モデル実行のためのコンピュートクレジットコストのみを捉えており、研究者の給与やハイパーパラメータ調整と実験に関連する他の開発コストは考慮されていません。
第三に、そして最も興味深いことに、この論文は、検証可能な報酬を用いた強化学習(RLVR)とGRPOアルゴリズムを、いわゆる推論モデルを開発し、ポストトレーニング中にLLMを改善するための新しい(あるいは少なくとも修正された)アルゴリズム的アプローチとして提示しました。
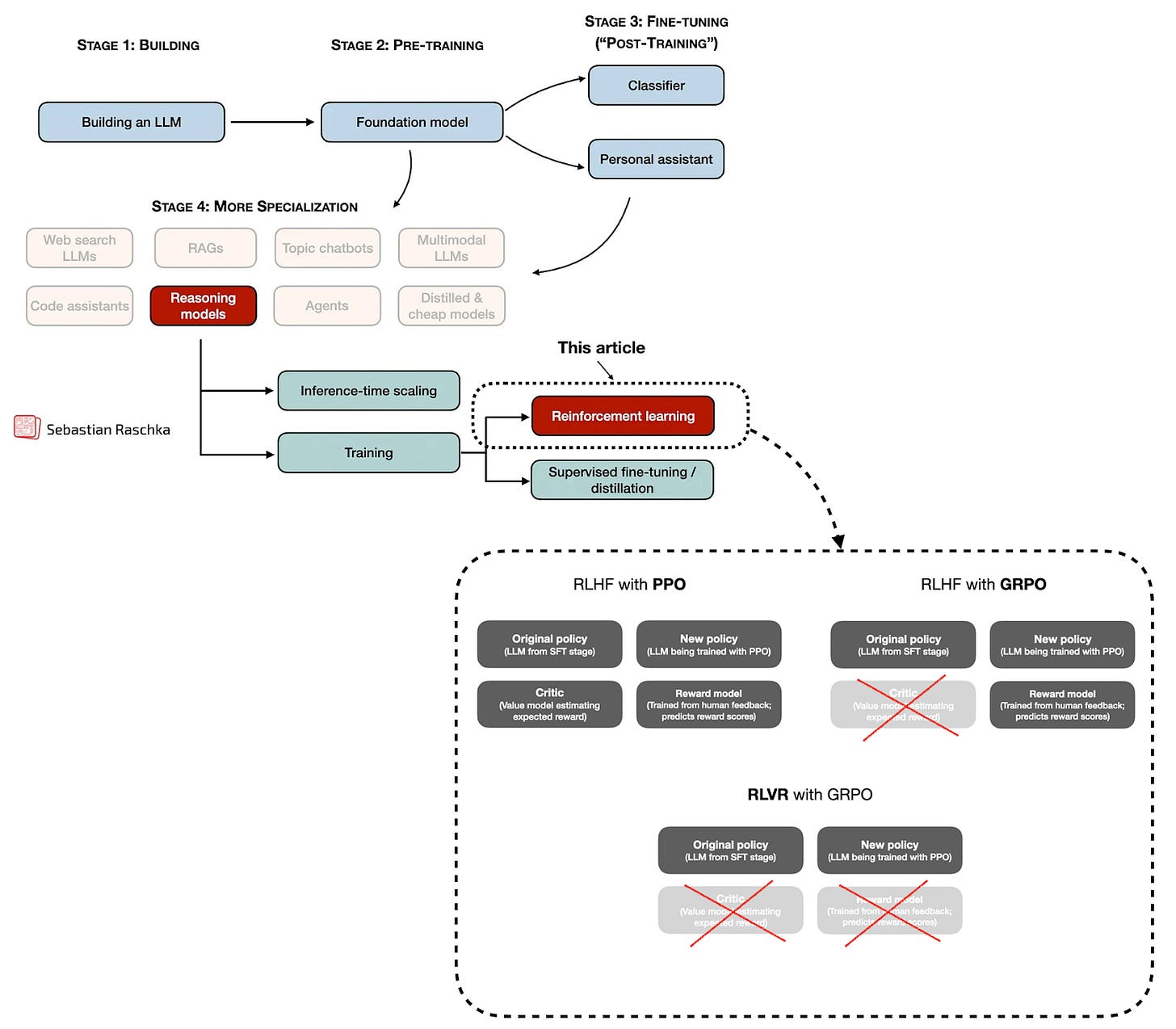 図4:強化学習がいつ/どのように適用されるかの大まかな概要。この概要では多くの詳細を省略していますが、興味のある読者は私の記事「The State of Reinforcement Learning for LLM Reasoning」でさらに詳しく読むことができます。
図4:強化学習がいつ/どのように適用されるかの大まかな概要。この概要では多くの詳細を省略していますが、興味のある読者は私の記事「The State of Reinforcement Learning for LLM Reasoning」でさらに詳しく読むことができます。
これまで、教師あり指示ファインチューニング(SFT)や人間のフィードバックによる強化学習(RLHF)のようなポストトレーニング手法(これらは依然としてトレーニングパイプラインの重要な部分です)は、高価な記述応答や選好ラベルを必要とするためボトルネックとなっていました。(もちろん、他のLLMで合成的に生成することもできますが、それは少し鶏と卵の問題です。)
DeepSeek R1とRLVRの非常に重要な点は、大量のデータでLLMをポストトレーニングできるようにすることで、(利用可能なコンピュート予算があれば)ポストトレーニング中のコンピュートスケーリングを通じて能力を向上・解放するための有力な候補となることです。
RLVRの「V」は「検証可能」を意味し、決定論的アプローチを使用して正解ラベルを割り当てることができ、これらのラベルはLLMが複雑な問題解決を学習するのに十分であることを意味します。(典型的なカテゴリーは数学とコードですが、この考え方を他の領域に拡張することも可能です。)
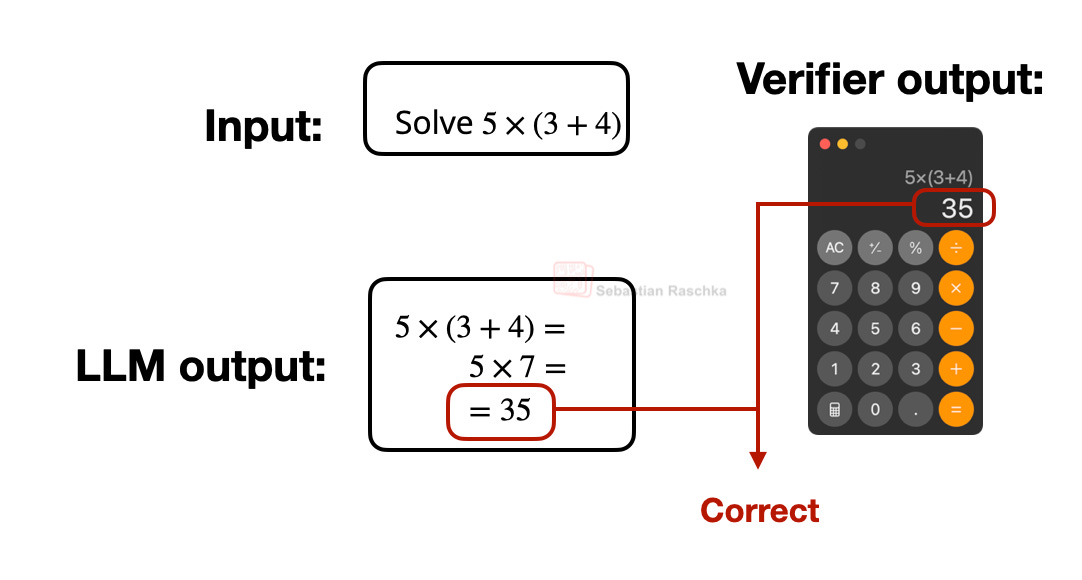 図5:検証可能な報酬の簡単な例。
図5:検証可能な報酬の簡単な例。
この年次レビュー記事では他の側面も取り上げたいので、ここで技術的な詳細に深入りしすぎたくはありません。推論LLMとRLVRについては記事や本が丸ごと書けるほどです。例えば、もっと知りたい方は、私の以前の記事を参照してください。
 Understanding Reasoning LLMs
Understanding Reasoning LLMs
 The State of Reinforcement Learning for LLM Reasoning
The State of Reinforcement Learning for LLM Reasoning
以上を踏まえると、今年のLLM開発は本質的に、RLVRとGRPOを使用した推論モデルが支配的だったと言えます。
基本的に、すべての主要なオープンウェイトまたはプロプライエタリなLLM開発者は、DeepSeek R1に続いて、自社モデルの推論(しばしば「思考」と呼ばれる)バリアントをリリースしました。
1.2 LLMの焦点ポイント
アーキテクチャと事前トレーニングのコンピュートをスケーリングするだけではなく、各年のLLM開発の焦点ポイントを簡潔にまとめると、私のリストは次のようになります。
2022年 RLHF + PPO
2024年 ミッドトレーニング
2025年 RLVR + GRPO
事前トレーニングは依然としてすべての基礎となる必要条件です。それに加えて、RLHF(PPOアルゴリズム経由)は、もちろん、2022年に最初のChatGPTモデルをもたらしたものでした。
2023年には、小さなカスタムLLMをトレーニングするための、LoRAおよびLoRAに似たパラメータ効率的なファインチューニング技術に多くの焦点が当てられました。
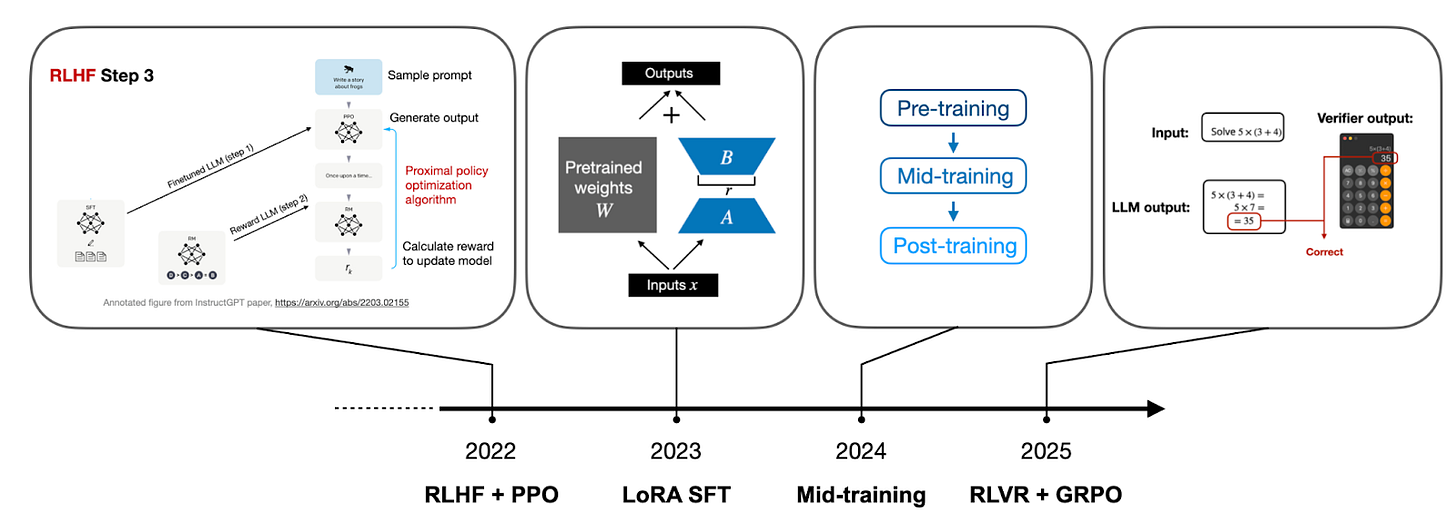 図6:長年にわたるプロプライエタリおよびオープンウェイトLLM開発の焦点領域の一部。これは累積的であることに注意してください。つまり、例えばRLHF + PPOは依然として関連性があり使用されています。しかし、もはや最も熱く議論されているトピックではありません。
図6:長年にわたるプロプライエタリおよびオープンウェイトLLM開発の焦点領域の一部。これは累積的であることに注意してください。つまり、例えばRLHF + PPOは依然として関連性があり使用されています。しかし、もはや最も熱く議論されているトピックではありません。
その後、2024年には、すべての主要な研究所が、合成データに焦点を当て、データミックスを最適化し、ドメイン固有のデータを使用し、専用の長文脈トレーニング段階を追加することによって、(事前)トレーニングパイプラインをより洗練されたものにし始めました。私はこれらのd
原文を表示
The State Of LLMs 2025: Progress, Problems, and Predictions
Sebastian Raschka, PhDDec 30, 20255023955ShareAs 2025 comes to a close, I want to look back at some of the year’s most important developments in large language models, reflect on the limitations and open problems that remain, and share a few thoughts on what might come next.
As I tend to say every year, 2025 was a very eventful year for LLMs and AI, and this year, there was no sign of progress saturating or slowing down.
- The Year of Reasoning, RLVR, and GRPO
There are many interesting topics I want to cover, but let’s start chronologically in January 2025.
Scaling still worked, but it didn’t really change how LLMs behaved or felt in practice (the only exception to that was OpenAI’s freshly released o1, which added reasoning traces). So, when DeepSeek released their R1 paper in January 2025, which showed that reasoning-like behavior can be developed with reinforcement learning, it was a really big deal. (Reasoning, in the context of LLMs, means that the model explains its answer, and this explanation itself often leads to improved answer accuracy.)
Figure 1: A short response and a longer response including intermediate steps that is typically generated by reasoning models.
1.1 The DeepSeek Moment
DeepSeek R1 got a lot of attention for various reasons:
First, DeepSeek R1 was released as an open-weight model that performed really well and was comparable to the best proprietary models (ChatGPT, Gemini, etc.) at the time.
Second, the DeepSeek R1 paper prompted many people, especially investors and journalists, to revisit the earlier DeepSeek V3 paper from December 2024. This then led to a revised conclusion that while training state-of-the-art models is still expensive, it may be an order of magnitude cheaper than previously assumed, with estimates closer to 5 million dollars rather than 50 or 500 million.
Figure 2: Table from the DeepSeek V3 paper estimating the cost of training the 671B parameter DeepSeek V3 model.
The DeepSeek R1 supplementary materials estimate that training the DeepSeek R1 model on top of DeepSeek V3 costs another $294,000, which is again much lower than everyone believed.
Figure 3: Table from the DeepSeek R1 paper’s supplementary materials estimating the cost of training the R1 model on top of DeepSeek V3.
Of course, there are many caveats to the 5-million-dollar estimate. For instance, it captures only the compute credit cost for the final model run, but it doesn’t factor in the researchers’ salaries and other development costs associated with hyperparameter tuning and experimentation.
Third, and most interestingly, the paper presented Reinforcement Learning with Verifiable Rewards (RLVR) with the GRPO algorithm as a new (or at least modified) algorithmic approach for developing so-called reasoning models and improving LLMs during post-training.
Figure 4: Broad overview of how / when reinforcement learning is applied. There are many details that I am skipping in this overview, but interested readers can read more in my The State of Reinforcement Learning for LLM Reasoning article.
Up to this point, post-training methods like supervised instruction fine-tuning (SFT) and reinforcement learning with human feedback (RLHF), which still remain an important part of the training pipeline, are bottlenecked by requiring expensive written responses or preference labels. (Sure, one can also generate them synthetically with other LLMs, but that’s a bit of a chicken-egg problem.)
What’s so important about DeepSeek R1 and RLVR is that they allow us to post-train LLMs on large amounts of data, which makes them a great candidate for improving and unlocking capabilities through scaling compute during post-training (given an available compute budget).
The V in RLVR stands for “verifiable,” which means we can use deterministic approaches to assign correctness labels, and these labels are sufficient for the LLM to learn complex problem-solving. (The typical categories are math and code, but it is also possible to expand this idea to other domains.)
Figure 5: A simple example of a verifiable reward.
I don’t want to get too lost in technical details here, as I want to cover other aspects in this yearly review article. And whole articles or books can be written about reasoning LLMs and RLVR. For instance, if you are interested to learn more, check out my previous articles:
Understanding Reasoning LLMs
The State of Reinforcement Learning for LLM Reasoning
All that being said, the takeaway is that LLM development this year was essentially dominated by reasoning models using RLVR and GRPO.
Essentially, every major open-weight or proprietary LLM developer has released a reasoning (often called “thinking”) variant of their model following DeepSeek R1.
1.2 LLM Focus Points
If I were to summarize the LLM development focus points succinctly for each year, beyond just scaling the architecture and pre-training compute, my list would look like this:
2022 RLHF + PPO
2024 Mid-Training
2025 RLVR + GRPO
Pre-training is still the required foundation for everything. Besides that, RLHF (via the PPO algorithm) was, of course, what brought us the original ChatGPT model in the first place back in 2022.
In 2023, there was a lot of focus on LoRA and LoRA-like parameter-efficient fine-tuning techniques to train small custom LLMs.
Figure 6: Some of the focus areas of proprietary and open-weight LLM development over the years. Note that this is cumulative, meaning that RLHF + PPO, for example, is still relevant and being used. However, it’s no longer the most hotly discussed topic.
Then, in 2024, all major labs began making their (pre-)training pipelines more sophisticated by focusing on synthetic data, optimizing data mixes, using domain-specific data, and adding dedicated long-context training stages. I summarized these different approaches in my 2024 article back then (I grouped the techniques under pre-training, because the term “mid-training” hadn’t been coined yet back then):
Back then, I considered these as pre-training techniques, since they use the same pre-training algorithm and objective. Today, these slightly more specialized pre-training stages, which follow the regular pre-training on general data, are often called “mid-training” (as a bridge between regular pre-training and post-training, which includes SFT, RLHF, and now RLVR).
So, you may wonder what’s next?
I think we will see (even) more focus on RLVR next year. Right now, RLVR is primarily applied to math and code domains.
The next logical step is to not only use the final answer’s correctness as a reward signal but also judge the LLM’s explanations during RLVR training. This has been done before, for many years in the past, under the research label “process reward models” (PRMs). However, it hasn’t been super successful yet. E.g., to quote from the DeepSeek R1 paper:
4.2. Unsuccessful Attempts
[...] In conclusion, while PRM demonstrates a good ability to rerank the top-N responses generated by the model or assist in guided search (Snell et al., 2024), its advantages are limited compared to the additional computational overhead it introduces during the large-scale reinforcement learning process in our experiments.
However, looking at the recent DeepSeekMath-V2 paper, which came out last month and I discussed in my previous article From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates, I think we will see more of “explanation-scoring” as a training signal in the future.
The way the explanations are currently being scored involves a second LLM. This leads to the other direction I am seeing for RLVR: an extension into other domains beyond math and code.
So, if you asked me today what I see on the horizon for 2026 and 2027, I’d say the following:
2026 RLVR extensions and more inference-time scaling
2027 Continual learning
Besides the aforementioned RLVR extensions, I think there will be more focus on inference-time scaling in 2026. Inference-time scaling means we spend more time and money after training when we let the LLM generate the answer, but it goes a long way.
Inference scaling is not a new paradigm, and LLM platforms already use certain techniques under the hood. It’s a trade-off between latency, cost, and response accuracy. However, in certain applications, where accuracy matters more than latency and cost, extreme inference-scaling can totally be worth it. For instance, as the recent DeepSeekV2-Math paper showed, it pushed the model to gold-level performance on a challenge math competition benchmark.
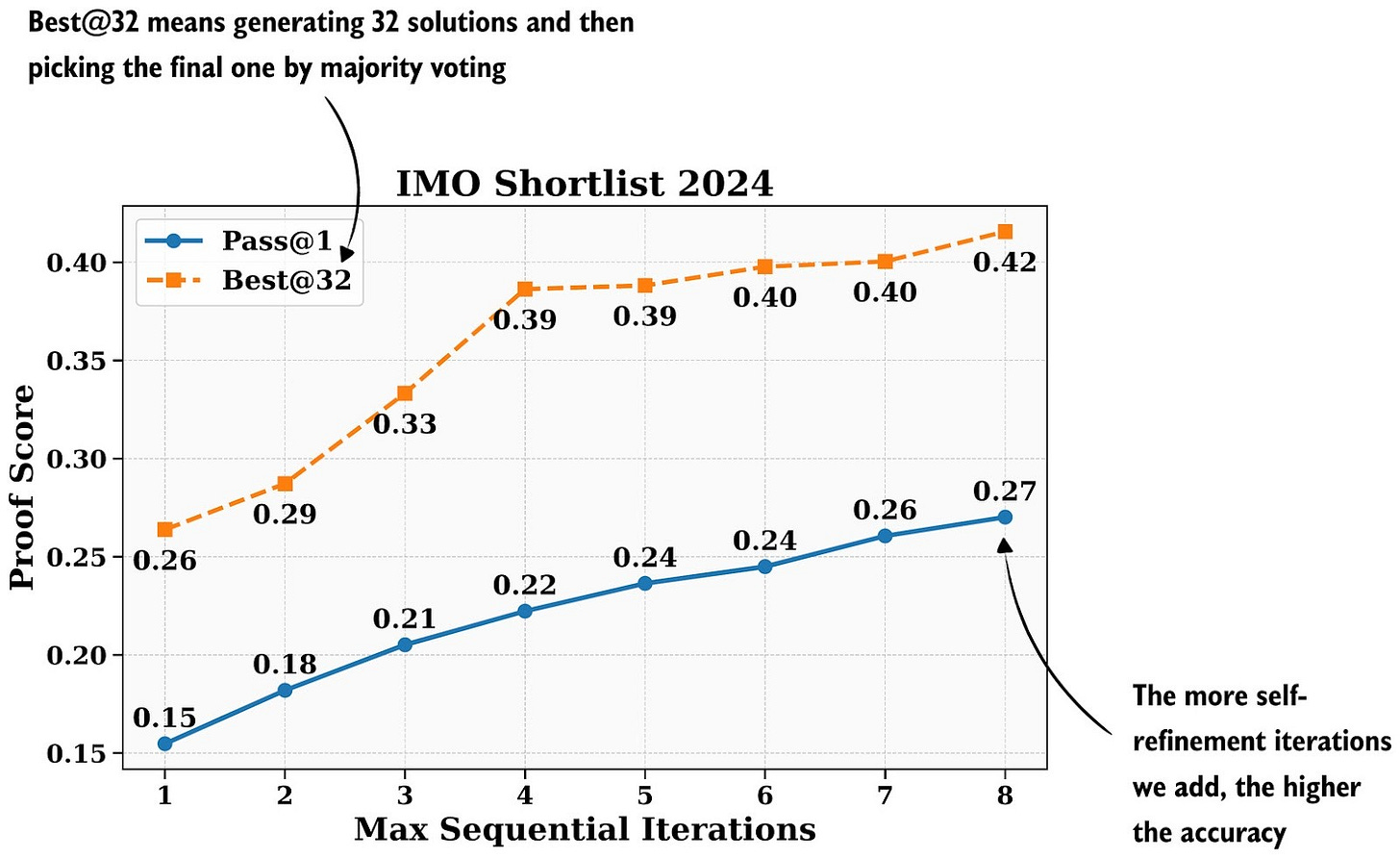 Figure 7: Combination of two inference-time scaling methods: self-consistency and self-refinement. Additional self-refinement iterations improve accuracy. Annotated figure from the DeepSeekMath-V2 paper. Self-consistency and self-refinement are covered in chapters 4 and 5 of my Build A Reasoning Model (From Scratch) book.
Figure 7: Combination of two inference-time scaling methods: self-consistency and self-refinement. Additional self-refinement iterations improve accuracy. Annotated figure from the DeepSeekMath-V2 paper. Self-consistency and self-refinement are covered in chapters 4 and 5 of my Build A Reasoning Model (From Scratch) book.
There’s also been a lot of talk among colleagues about continuous learning this year. In short, continual learning is about training a model on new data or knowledge without retraining it from scratch.
It’s not a new idea, and I wonder why it came up so much this year, since there hasn’t been any new or substantial breakthrough in continual learning at this point. The challenge to continual learning is catastrophic forgetting (as experiments with continued pre-training show, learning new knowledge means that the LLM is forgetting old knowledge to some extent).
Still, since this seems like such a hot topic, I do expect more progress towards minimizing catastrophic forgetting and making continua
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み