全身条件付き自己中心視点動画予測
Berkeley AI Research が、人間の全身動作を条件として第一人称視点の未来映像を予測する「PEVA」モデルを発表し、具身知能のための世界モデル構築に重要な進展をもたらした。
キーポイント
PEVA モデルの概要と機能
過去の動画フレームと 3D ポーズの変化を指定するアクションを入力とし、次のフレームを予測する「Predict Ego-centric Video from human Actions (PEVA)」モデルを開発した。
具身知能のための世界モデルの必要性
既存の世界モデルは抽象的な制御信号に依存しがちだが、真の具身エージェントには物理的に根ざした複雑な動作空間と多様な実世界のシナリオ、そして第一人称視点が必要である。
全身条件付けによる予測精度の向上
人間の関節階層構造に基づいた運動学的ポーズ軌道を条件とし、足(移動)や手(操作)を含む全身動作が環境に与える影響をシミュレーションする。
大規模データセット「Nymeria」の活用
実世界の第一人称動画と身体姿勢キャプチャをペアにした大規模データセット「Nymeria」を用いて、自己回帰型条件付き拡散トランスフォーマーを訓練した。
高次元な構造化アクション表現
全身のダイナミクスと関節の詳細な動きを捉えるため、3D空間内の根元変位と15個の上部体節回転を用いた48次元のアクション空間を定義しています。
CDiTアーキテクチャの拡張
短期・長期の動きパターン学習のためにランダムタイムスキップ、シーケンス全体への損失適用、そして高次元全身運動のためのアクション埋め込みを統合しています。
PEVAモデルと評価プロトコル
PEVAは人間の動作から視覚的帰結を学習する自己回帰型条件付き拡散トランスフォーマーであり、階層的な評価で複雑な環境におけるエージェントの予測・制御能力を検証します。
影響分析・編集コメントを表示
影響分析
この研究は、単なる映像生成を超え、ロボットや自律システムが実世界で動作するための「世界モデル」構築に向けた重要な一歩です。人間の脳が行うような視覚シミュレーションと身体動作の統合を模倣することで、より自然で安全な具身知能の実現に寄与します。特に複雑な環境下での長期的な計画立案や反事実的推論において、既存技術との決定的な差を生む可能性があります。
編集コメント
Berkeley AI Research のこの成果は、AI が単に映像を生成するだけでなく、物理法則や人間の動作特性を理解した上で未来を推論する「世界モデル」の方向性を示しています。特に第一人称視点と全身動作を結びつけた点は、実社会でのロボット制御への応用において極めて重要な技術的ブレイクスルーと言えます。
全身条件付きエゴセントリック動画予測
 人間の行動からのエゴセントリック動画予測 (PEVA)。過去の動画フレームと、望ましい3D姿勢の変化を指定する行動が与えられると、PEVAは次の動画フレームを予測します。結果は、最初のフレームと一連の行動が与えられた場合、我々のモデルが個別行動の動画を生成し(a)、反事実的シミュレーションを行い(b)、長い動画生成を可能にする(c)ことを示しています。
人間の行動からのエゴセントリック動画予測 (PEVA)。過去の動画フレームと、望ましい3D姿勢の変化を指定する行動が与えられると、PEVAは次の動画フレームを予測します。結果は、最初のフレームと一連の行動が与えられた場合、我々のモデルが個別行動の動画を生成し(a)、反事実的シミュレーションを行い(b)、長い動画生成を可能にする(c)ことを示しています。
近年、計画と制御のための未来の結果をシミュレートすることを学習する世界モデルにおいて、大きな進展がありました。直感的物理学から多段階の動画予測まで、これらのモデルはますます強力で表現力豊かになってきています。しかし、真に具現化されたエージェントのために設計されたものはほとんどありません。具現化エージェントのための世界モデルを作成するには、実世界で行動する実際の具現化エージェントが必要です。実際の具現化エージェントは、抽象的な制御信号とは対照的に、物理的に接地された複雑な行動空間を持ちます。また、多様な実生活のシナリオで行動し、美的なシーンや固定カメラとは対照的に、エゴセントリックな視点を備えていなければなりません。
💡 ヒント: 画像をクリックするとフル解像度で表示されます。
行動と視覚は、文脈に大きく依存します。同じ視界が異なる動きにつながることもあれば、その逆もあります。これは、人間が複雑で、具現化され、目標指向の環境で行動するためです。
人間の制御は高次元で構造化されています。全身の動きは、階層的で時間依存のダイナミクスを持つ48以上の自由度に及びます。
エゴセントリックな視界は意図を明らかにしますが、身体を隠します。一人称視点の視覚は目標を反映しますが、動きの実行は反映せず、モデルは見えない身体的行動から結果を推論しなければなりません。
知覚は行動に遅れます。視覚的フィードバックはしばしば数秒後にやってくるため、長期的な予測と時間的推論が必要となります。
具現化エージェントのための世界モデルを開発するには、これらの基準を満たすエージェントに我々のアプローチを基盤としなければなりません。人間は通常、まず見て次に行動します——目は目標に固定され、脳は結果の短い視覚的「シミュレーション」を実行し、その後に初めて身体が動きます。あらゆる瞬間において、我々のエゴセントリックな視界は、環境からの入力として機能すると同時に、次の動きの背後にある意図/目標を反映しています。身体の動きを考えるとき、足の行動(移動とナビゲーション)と手の行動(操作)の両方、あるいはより一般的には全身制御を考慮すべきです。
我々は何をしたか?

我々は、全身条件付きエゴセントリック動画予測のために、人間の行動からのエゴセントリック動画予測 (PEVA) モデルを訓練しました。PEVAは、身体の関節階層によって構造化された運動学的姿勢軌跡を条件とし、物理的な人間の行動が一人称視点から環境をどのように形作るかをシミュレートすることを学習します。実世界のエゴセントリック動画と身体姿勢キャプチャを組み合わせた大規模データセットNymeriaを用いて、自己回帰的条件付き拡散トランスフォーマーを訓練しました。我々の階層的評価プロトコルは、次第に難しくなるタスクをテストし、モデルの具現化予測と制御能力の包括的分析を提供します。この研究は、人間視点の動画予測を通じて、複雑な実世界環境と具現化エージェントの行動をモデル化する最初の試みを表しています。
動きからの構造化された行動表現
人間の動きとエゴセントリック視覚を橋渡しするために、各行動を、全身のダイナミクスと詳細な関節運動の両方を捉えた、豊かで高次元のベクトルとして表現します。単純化された制御を使用する代わりに、身体の運動学的ツリーに基づいて、大域的な並進と相対的な関節回転を符号化します。動きは3D空間で表現され、根元の並進に3自由度、上半身の15関節を使用します。相対的な関節回転にオイラー角を使用することで、48次元の行動空間(3 + 15 × 3 = 48)が得られます。モーションキャプチャデータはタイムスタンプを用いて動画と同期され、その後、位置と方向の不変性のために、大域座標から骨盤中心の局所座標系に変換されます。すべての位置と回転は、安定した学習を保証するために正規化されます。各行動はフレーム間の動きの変化を捉え、モデルが時間の経過とともに物理的運動と視覚的結果を結びつけることを可能にします。
PEVAの設計:自己回帰的条件付き拡散トランスフォーマー
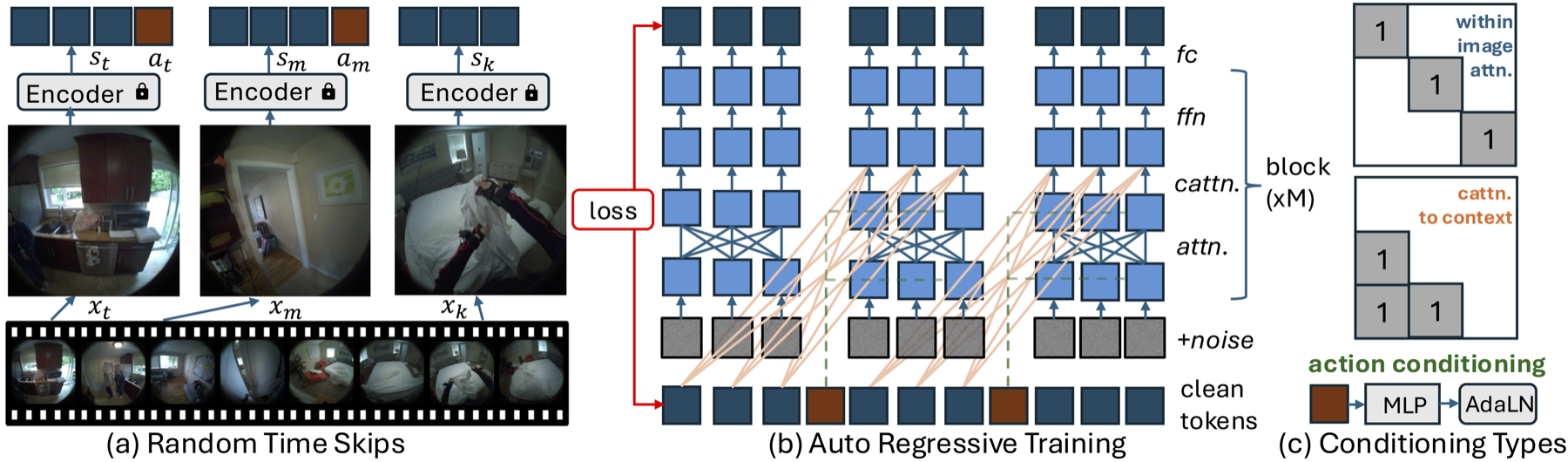
Navigation World Modelsの条件付き拡散トランスフォーマー (CDiT) が速度や回転のような単純な制御信号を使用するのに対し、全身の人間の動きをモデル化することはより大きな課題を提示します。人間の行動は高次元で、時間的に延長され、物理的に制約されています。これらの課題に対処するために、我々はCDiT法を3つの方法で拡張します:
ランダムタイムスキップ: モデルが短期的な運動ダイナミクスと長期的な活動パターンの両方を学習することを可能にします。
シーケンスレベル訓練: 各フレームのプレフィックスに損失を適用することで、動きシーケンス全体をモデル化します。
行動埋め込み: 時間tにおけるすべての行動を1Dテンソルに連結し、各AdaLN層を条件付けることで、高次元の全身運動に対応します。
サンプリングとロールアウト戦略
テスト時には、過去の一連のコンテキストフレームを条件として将来のフレームを生成します。これらのフレームを潜在状態に符号化し、ターゲットフレームにノイズを加え、その後、我々の拡散モデルを使用して段階的にノイズ除去します。推論を高速化するために、アテンションを制限します。画像内アテンションはターゲットフレームにのみ適用され、コンテキストのクロスアテンションは最後のフレームにのみ適用されます。行動条件付き予測では、自己回帰的ロールアウト戦略を使用します。コンテキストフレームから始め、VAEエンコーダーを使用してそれらを符号化し、現在の行動を追加します。モデルは次のフレームを予測し、それをコンテキストに追加しながら最も古いフレームを削除し、このプロセスをシーケンス内の各行動に対して繰り返します。最後に、VAEデコーダーを使用して予測された潜在変数をピクセル空間にデコードします。
原子行動への分解
複雑な人間の動きを、手の動き(上、下、左、右)や全身の動き(前進、回転)などの原子行動に分解し、特定の関節レベルの動きがエゴセントリックな視界にどのように影響するかについてのモデルの理解をテストします。ここにいくつかのサンプルを示します:
身体移動行動
左手行動
右手行動
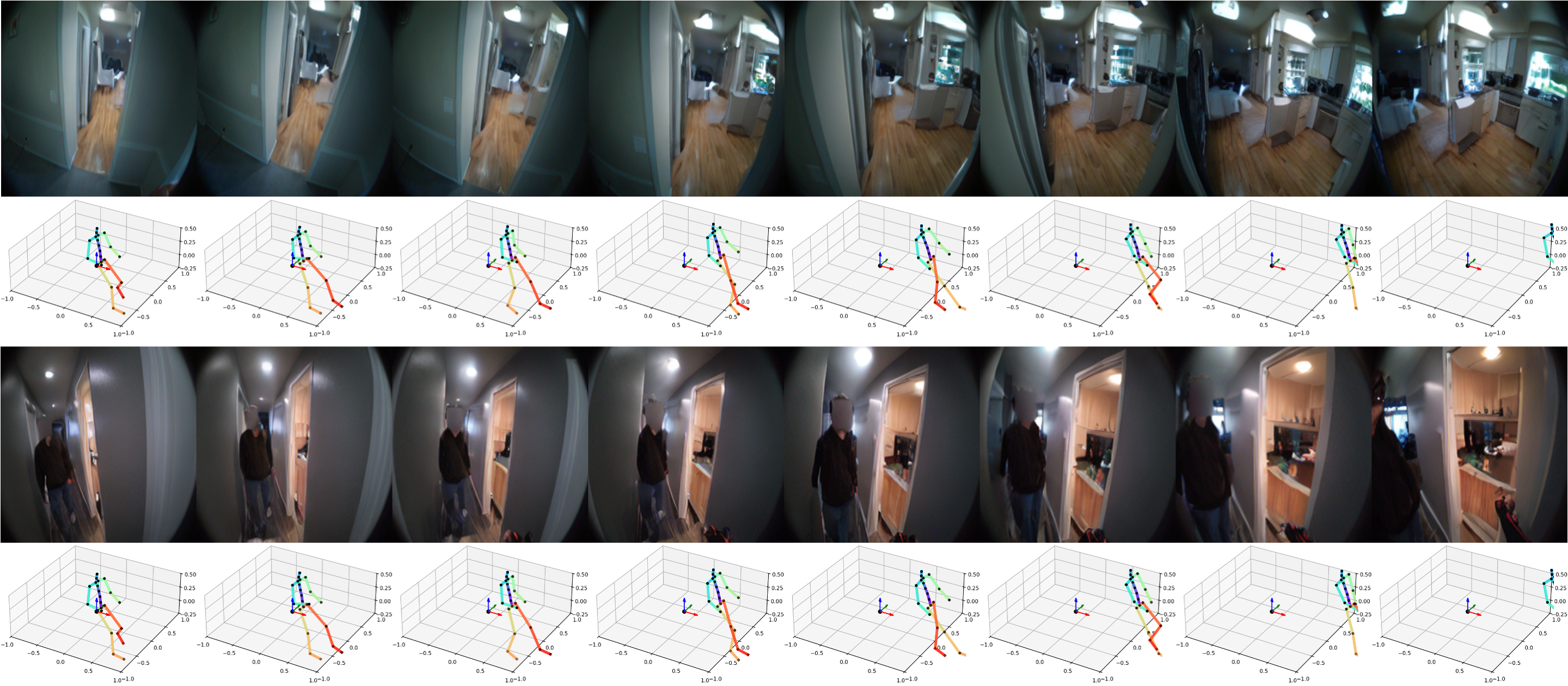
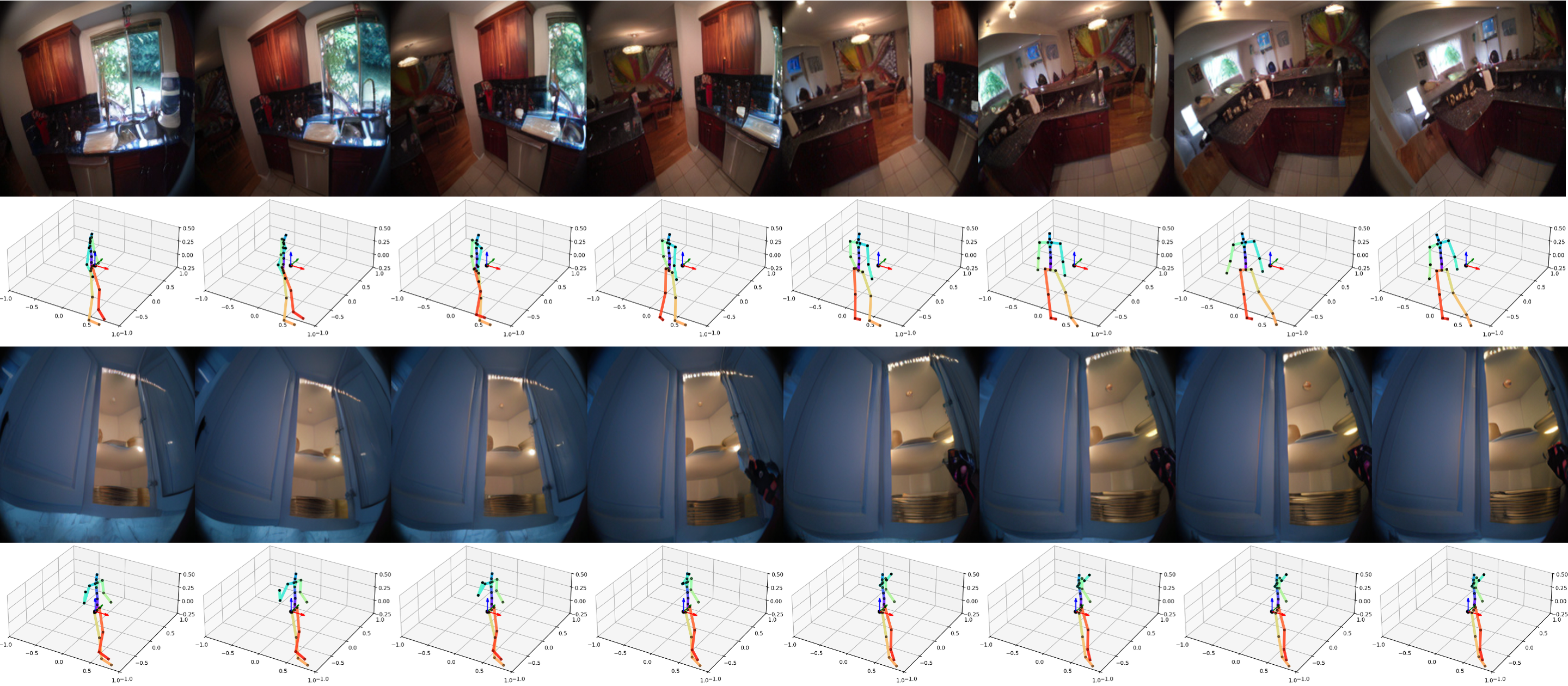
長期的な動画生成
ここでは、モデルが長期的な予測期間にわたって視覚的および意味的一貫性を維持する能力を見ることができます。PEVAが全身の動きを条件として一貫性のある16秒のロールアウトを生成するいくつかのサンプルを示します。より詳細に見るためのいくつかの動画サンプルと画像サンプルをここに含めます:
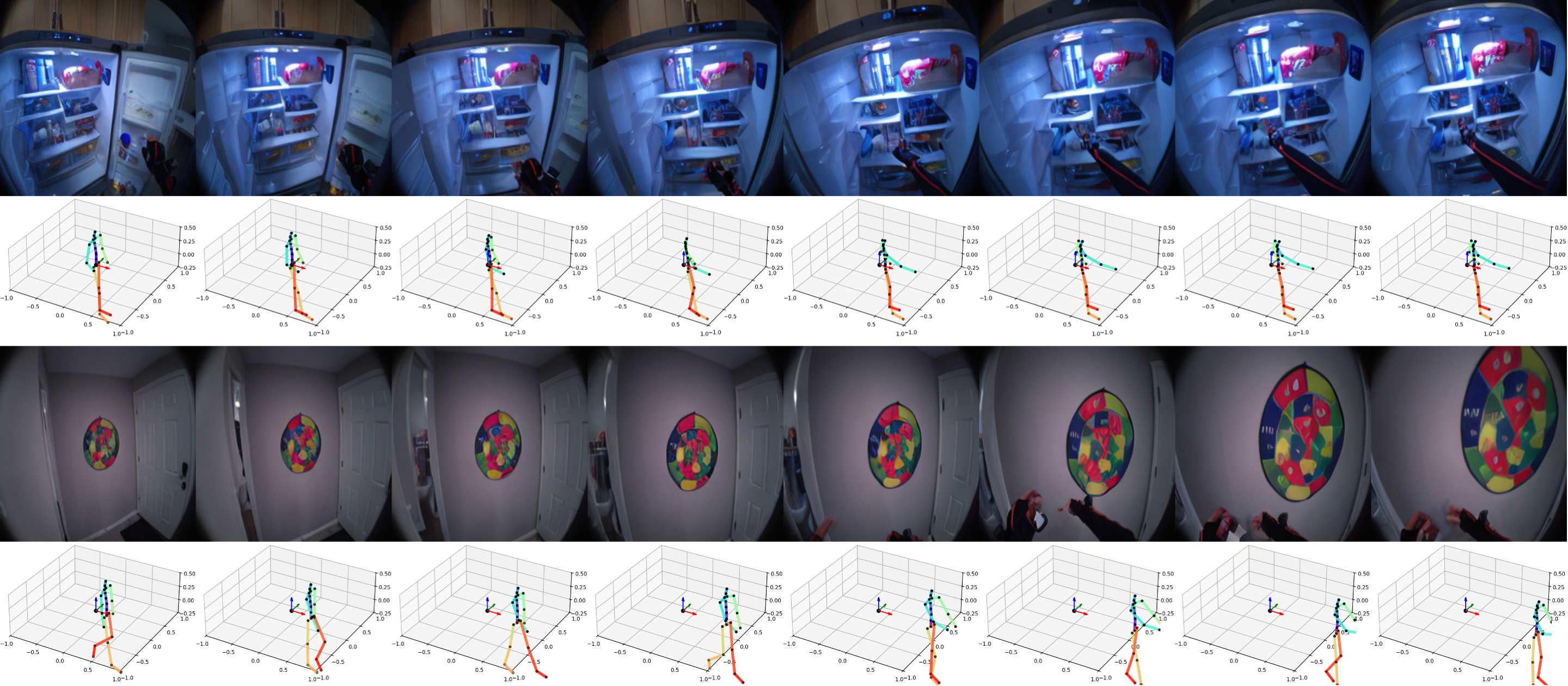
反事実的シミュレーション
PEVAは、複数の行動候補をシミュレートし、LPIPSで測定された目標との知覚的類似性に基づいてそれらをスコアリングすることで、計画に使用することができます。
 この例では、流し台や屋外につながる経路を排除し、冷蔵庫を開ける正しい経路を見つけています。
この例では、流し台や屋外につながる経路を排除し、冷蔵庫を開ける正しい経路を見つけています。
 この例では、近くの植物をつかんだりキッチンに行ったりする経路を排除しながら、棚につながる合理的な一連の行動を見つけています。
この例では、近くの植物をつかんだりキッチンに行ったりする経路を排除しながら、棚につながる合理的な一連の行動を見つけています。
視覚的計画能力を可能にする
計画をエネルギー最小化問題として定式化し、Navigation World Models [arXiv:2412.03572] で導入されたアプローチに従って、交差エントロピー法 (CEM) を使用して行動最適化を実行します。具体的には、他の身体部位を固定したまま、左腕または右腕のいずれかの行動シーケンスを最適化します。結果として得られる計画の代表的な例を以下に示します:
 この場合、右腕をかき混ぜ棒まで上げる一連の行動を予測することができます。我々の方法の限界として、右腕のみを予測するため、それに応じて左腕を下げる動きは予測されません。
この場合、右腕をかき混ぜ棒まで上げる一連の行動を予測することができます。我々の方法の限界として、右腕のみを予測するため、それに応じて左腕を下げる動きは予測されません。
 この場合、やかんに向かって手を伸ばす一連の行動を予測することができます。
この場合、やかんに向かって手を伸ばす一連の行動を予測することができます。
原文を表示
Predicting Ego-centric Video from human Actions (PEVA). Given past video frames and an action specifying a desired change in 3D pose, PEVA predicts the next video frame. Our results show that, given the first frame and a sequence of actions, our model can generate videos of atomic actions (a), simulate counterfactuals (b), and support long video generation (c).
Recent years have brought significant advances in world models that learn to simulate future outcomes for planning and control. From intuitive physics to multi-step video prediction, these models have grown increasingly powerful and expressive. But few are designed for truly embodied agents. In order to create a World Model for Embodied Agents, we need a real embodied agent that acts in the real world. A real embodied agent has a physically grounded complex action space as opposed to abstract control signals. They also must act in diverse real-life scenarios and feature an egocentric view as opposed to aesthetic scenes and stationary cameras.
💡 Tip: Click on any image to view it in full resolution.
Action and vision are heavily context-dependent. The same view can lead to different movements and vice versa. This is because humans act in complex, embodied, goal-directed environments.
Human control is high-dimensional and structured. Full-body motion spans 48+ degrees of freedom with hierarchical, time-dependent dynamics.
Egocentric view reveals intention but hides the body. First-person vision reflects goals, but not motion execution, models must infer consequences from invisible physical actions.
Perception lags behind action. Visual feedback often comes seconds later, requiring long-horizon prediction and temporal reasoning.
To develop a World Model for Embodied Agents, we must ground our approach in agents that meet these criteria. Humans routinely look first and act second—our eyes lock onto a goal, the brain runs a brief visual “simulation” of the outcome, and only then does the body move. At every moment, our egocentric view both serves as input from the environment and reflects the intention/goal behind the next movement. When we consider our body movements, we should consider both actions of the feet (locomotion and navigation) and the actions of the hand (manipulation), or more generally, whole-body control.
What Did We Do?
We trained a model to Predict Ego-centric Video from human Actions (PEVA) for Whole-Body-Conditioned Egocentric Video Prediction. PEVA conditions on kinematic pose trajectories structured by the body’s joint hierarchy, learning to simulate how physical human actions shape the environment from a first-person view. We train an autoregressive conditional diffusion transformer on Nymeria, a large-scale dataset pairing real-world egocentric video with body pose capture. Our hierarchical evaluation protocol tests increasingly challenging tasks, providing comprehensive analysis of the model’s embodied prediction and control abilities. This work represents an initial attempt to model complex real-world environments and embodied agent behaviors through human-perspective video prediction.
Structured Action Representation from Motion
To bridge human motion and egocentric vision, we represent each action as a rich, high-dimensional vector capturing both full-body dynamics and detailed joint movements. Instead of using simplified controls, we encode global translation and relative joint rotations based on the body’s kinematic tree. Motion is represented in 3D space with 3 degrees of freedom for root translation and 15 upper-body joints. Using Euler angles for relative joint rotations yields a 48-dimensional action space (3 + 15 × 3 = 48). Motion capture data is aligned with video using timestamps, then converted from global coordinates to a pelvis-centered local frame for position and orientation invariance. All positions and rotations are normalized to ensure stable learning. Each action captures inter-frame motion changes, enabling the model to connect physical movement with visual consequences over time.
Design of PEVA: Autoregressive Conditional Diffusion Transformer
While the Conditional Diffusion Transformer (CDiT) from Navigation World Models uses simple control signals like velocity and rotation, modeling whole-body human motion presents greater challenges. Human actions are high-dimensional, temporally extended, and physically constrained. To address these challenges, we extend the CDiT method in three ways:
Random Timeskips: Allows the model to learn both short-term motion dynamics and longer-term activity patterns.
Sequence-Level Training: Models entire motion sequences by applying loss over each frame prefix.
Action Embeddings: Concatenates all actions at time t into a 1D tensor to condition each AdaLN layer for high-dimensional whole-body motion.
Sampling and Rollout Strategy
At test time, we generate future frames by conditioning on a set of past context frames. We encode these frames into latent states and add noise to the target frame, which is then progressively denoised using our diffusion model. To speed up inference, we restrict attention, where within image attention is applied only to the target frame and context cross attention is only applied for the last frame. For action-conditioned prediction, we use an autoregressive rollout strategy. Starting with context frames, we encode them using a VAE encoder and append the current action. The model then predicts the next frame, which is added to the context while dropping the oldest frame, and the process repeats for each action in the sequence. Finally, we decode the predicted latents into pixel-space using a VAE decoder.
We decompose complex human movements into atomic actions—such as hand movements (up, down, left, right) and whole-body movements (forward, rotation)—to test the model’s understanding of how specific joint-level movements affect the egocentric view. We include some samples here:
Body Movement Actions
Left Hand Actions
Right Hand Actions
Here you can see the model’s ability to maintain visual and semantic consistency over extended prediction horizons. We demonstrate some samples of PEVA generating coherent 16-second rollouts conditioned on full-body motion. We include some video samples and image samples for closer viewing here:
PEVA can be used for planning by simulating multiple action candidates and scoring them based on their perceptual similarity to the goal, as measured by LPIPS.
In this example, it rules out paths that lead to the sink or outdoors finding the correct path to open the fridge.
In this example, it rules out paths that lead to grabbing nearby plants and going to the kitchen while finding reasonable sequence of actions that lead to the shelf.
Enables Visual Planning Ability
We formulate planning as an energy minimization problem and perform action optimization using the Cross-Entropy Method (CEM), following the approach introduced in Navigation World Models [arXiv:2412.03572]. Specifically, we optimize action sequences for either the left or right arm while holding other body parts fixed. Representative examples of the resulting plans are shown below:
In this case, we are able to predict a sequence of actions that raises our right arm to the mixing stick. We see a limitation with our method as we only predict the right arm so we do not predict to move the left arm down accordingly.
In this case, we are able to predict a sequence of actions that reaches toward the kettle but does not quite grab it as in the goal.
 In this case, we are able to predict a sequence of actions that pulls our left arm in, similar to the goal.
In this case, we are able to predict a sequence of actions that pulls our left arm in, similar to the goal.
Quantitative Results
We evaluate PEVA across multiple metrics to demonstrate its effectiveness in generating high-quality egocentric videos from whole-body actions. Our model consistently outperforms baselines in perceptual quality, maintains coherence over long time horizons, and shows strong scaling properties with model size.
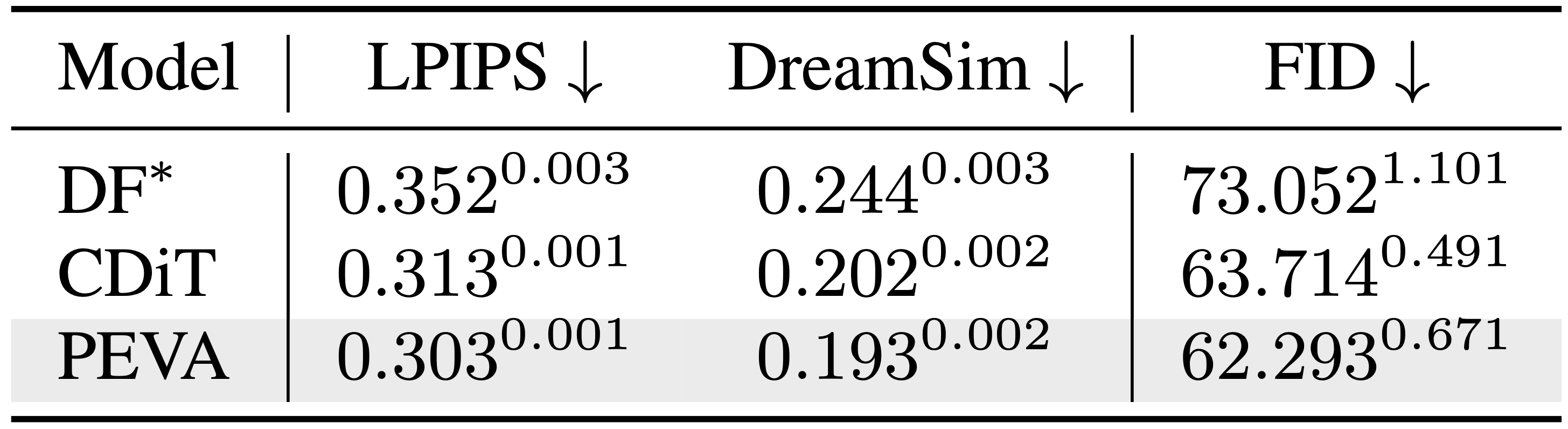
Baseline Perceptual Metrics
Baseline perceptual metrics comparison across different models.
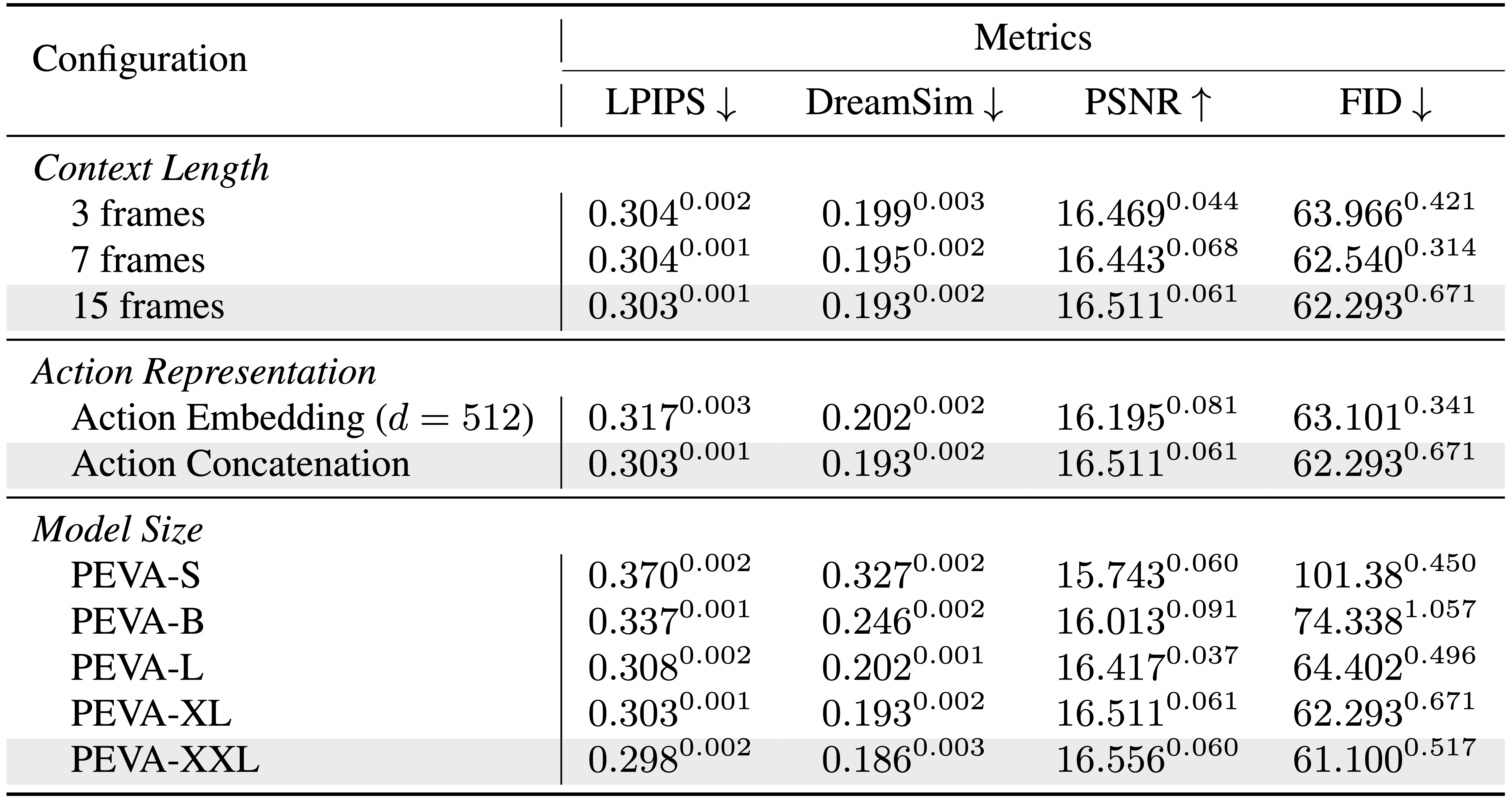
Atomic Action Performance
Comparison of models in generating videos of atomic actions.
FID comparison across different models and time horizons.
PEVA has good scaling ability. Larger models lead to better performance.
Future Directions
Our model demonstrates promising results in predicting egocentric video from whole-body motion, but it remains an early step toward embodied planning. Planning is limited to simulating candidate arm actions and lacks long-horizon planning and full trajectory optimization. Extending PEVA to closed-loop control or interactive environments is a key next step. The model currently lacks explicit conditioning on task intent or semantic goals. Our evaluation uses image similarity as a proxy objective. Future work could leverage combining PEVA with high-level goal conditioning and the integration of object-centric representations.
Acknowledgements
The authors thank Rithwik Nukala for his help in annotating atomic actions. We thank Katerina Fragkiadaki, Philipp Krähenbühl, Bharath Hariharan, Guanya Shi, Shubham Tulsiani and Deva Ramanan for the useful suggestions and feedbacks for improving the paper; Jianbo Shi for the discussion regarding control theory; Yilun Du for the support on Diffusion Forcing; Brent Yi for his help in human motion related works and Alexei Efros for the discussion and debates regarding world models. This work is partially supported by the ONR MURI N00014-21-1-2801.
For more details, read the full paper or visit the project website.















関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み