CAMのSREユニットで学んだ、クラウドネイティブ基盤を「安全に運用し続ける」ための視点と設計
CAMのSRE Unitでのインターン経験を通じ、Argo CDのメジャーアップデートとcert-managerの監視自動化により、Cloud Native環境における「安全な運用」のためのSRE的視点と設計力を習得した事例。
キーポイント
Argo CD v2からv3へのメジャーアップデート
公式ガイドに基づきリポジトリ設定をSecretへ移行し、Helm Chartの更新と差分分析を行うことで、破壊的変更を最小限に抑えた安全なアップグレードを実現した。
TLS証明書の期限監視とアラート設計
Datadogを用いてcert-managerのメトリクスを監視し、更新失敗を検知するアラート閾値を「残り14日」に設定することで、オオカミ少年アラートを防ぎつつ確実な予兆検知を実現した。
SREとしての「安全」の定義と言語化
手動確認に依存していた状態から、自動化された監視基盤へ移行するプロセスを通じて、技術導入が組織にもたらす安心感とSREの役割を再定義する重要性を学んだ。
Helmによる抽象化と運用設計の習得
単一マニフェストからHelmパッケージ管理へ移行し、テンプレート化による抽象化を通じて、Argo CD を介した宣言的デプロイメントや大規模マニフェスト管理のベストプラクティスを理解した。
実務レベルのドメイン・証明書運用の実践
Cluster Issuer と Let’s Encrypt を用いた自動証明書発行・格納フローの構築に加え、Route53 レコード変更前の外部疎通確認など、サービス移管時の検証手順を習得した。
SRE の本質と組織文化の体感
SLO 指標に基づく運用だけでなく、開発スピードと信頼性の両立による組織価値最大化という SRE の役割を学び、技術以外の面でも社員の熱量や文化を深く理解できた。
影響分析・編集コメントを表示
影響分析
この記事は、大規模なCloud Native環境においてSREが直面する実務的な課題(アップグレードリスク、監視の盲点)に対する具体的な解決策を示しています。特に、単なるツール導入ではなく「運用負荷と検知精度のバランス」や「安全の定義」といったSREのマインドセットに言及している点は、現場のエンジニアにとって非常に参考になる実践的な知見です。
編集コメント
インターン生による実践的なレポートですが、Argo CDのメジャーアップデート手順や監視閾値の設定ロジックは、既存のKubernetes運用チームにとって即座に適用可能な有用な知見を含んでいます。
東京科学大学情報理工学院情報工学系修士1年の千代丸怜央と申します。
2025年2月7日から2月27日までの3週間、株式会社CAMのSRE UnitにCA Tech JOB生として参加させていただきました。
本記事では、株式会社CAMのSREとして取り組んだタスクの詳細とそこから学び得たことについてご紹介いたします。
実際の現場で求められる SRE の能力を身につけるために、Cloud Native な技術に触れ、プラットフォームの改善を行うという題目で、以下の目的をもって参加しました。
・Argo CDのアップグレードやTLS証明書監視などを通じ、プラットフォームを「安全に運用し続ける」ためのSRE的視点
・既存Kubernetesクラスタの調査を通じた、インフラ構成の最適解を導き出す設計力
CDツールである Argo CD のバージョンアップグレード
SRE Unit でのメインタスクの一つとして、プラットフォームの継続的な運用のために、CDツールである、Argo CD のバージョンアップグレード(v2 → v3)に取り組みました。
検証環境(central-load-testing)で利用していた Argo CD は v2 系(v2.14.19)であり、最新の機能追従やセキュリティメンテナンスの観点から v3 系(v3.3.0)へのメジャーアップデートが必要な状態でした。
Argo CD はそれ自身も Helm Chart で管理されており、今回は単なるイメージタグの差し替えではなく、自分自身を更新する Argo CD の挙動を考慮したアップデートが求められました。
作業は大きく分けて「影響調査」と「実作業・検証」の 2 ステップで進めました。
- 破壊的変更(Breaking Changes)の調査
メジャーアップデートに伴い、既存の設定が動かなくなるリスクを最小限にするため、公式のアップグレードガイドを徹底的に調査しました。特に以下の 2 点に注目しました。
リポジトリ設定の移行: v3.0 から argocd-cm(ConfigMap)でのリポジトリ定義が廃止され、Secret ベースへの移行が必須となった点。
RBAC の変更: ログ閲覧権限が明示的に必要になるなど、既存の権限周りへの影響を確認しました。
Helm チャートの更新と差分分析
helmfile template を活用し、クラスターの現在の状態(LIVE)と適用後の状態(MERGED)の差分を詳細に分析しました。
調査に基づき、リポジトリ設定を Secret へ移行した上で Helm Chart のバージョンを 7.x から 9.x へ引き上げ、適用を実施しました。
正常稼働の確認: 全ての Pod が正常に Ready となり、管理画面へのアクセスも問題ないことを確認しました。
Sync 状態の遷移: 各 Application で一度 Sync を実行することで、期待通りに動作することを確認しました。
今回、事前に kubectl diff やテンプレートの展開結果を Cursor などのツールも活用して徹底的に読み解いたことで、メジャーアップデートという大きな変更に対しても、自信を持ってリリースを行うことができたかなと思います。Desired Stateをコードで管理する GitOps の恩恵を少し感じることができました。
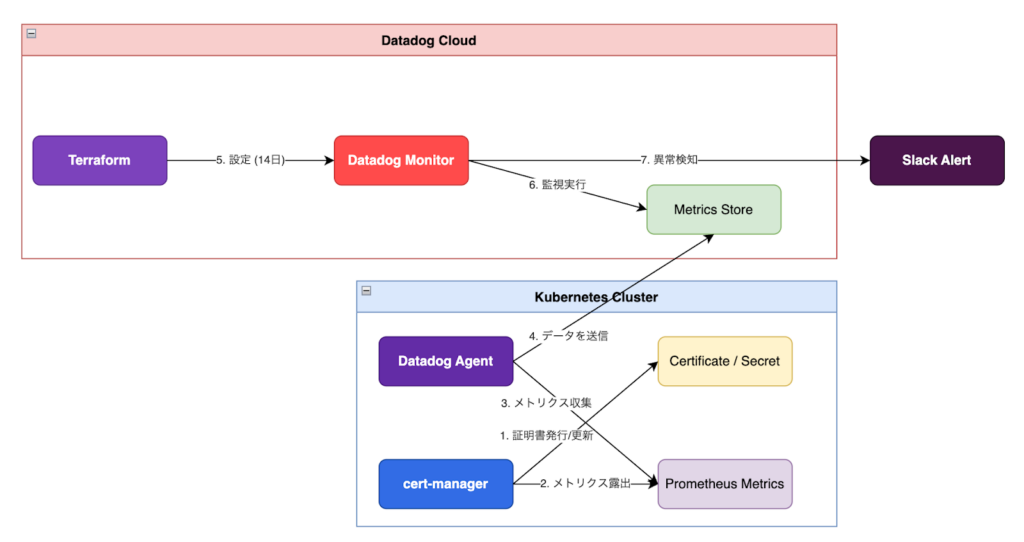
cert-manager が発行する TLS 証明書の有効期限を監視し、期限切れを未然に防ぐためのモニターの追加(Datadog)
もう一つのタスクとして、cert-manager が発行する TLS 証明書の有効期限監視の自動化に取り組みました。Terraform を用いて、Datadog 上に適切なモニターを設定する一連のフローを構築しました。
現状、証明書の状態確認は主に Argo CD の App Health や kubectl コマンドによる手動確認に依存していました。しかし、以下のリスクがあると考え、監視の強化を提案・実施しました。
「Healthy」だけでは不十分: Argo CD の Health 状態は「リソースが正しく同期されているか」を示しますが、「証明書の期限がいつ切れるか」「更新プロセスが内部で滞っていないか」までは可視化できません。
不可避な更新失敗リスク: Let's Encrypt のレート制限、Route53 との連携不調、ClusterIssuer の認証情報(AWS キー)の期限切れなど、証明書更新には多くの不確実性が伴います。
高いユーザー影響: 証明書の期限切れは即座に HTTPS 通信の遮断(サービスダウン)に繋がるため、「切れる前に気づく」予兆検知が不可欠です。
実装内容:Datadog x cert-manager の連携
具体的には、cert-manager が露出するメトリクスを収集し、以下の観点で Datadog モニターを Terraform 経由で設定しました。
・有効期限(Expiry)の監視: cert-manager は通常、デフォルトで有効期限の約 1/3 前(90日間の証明書なら残り 30 日前)から自動更新を試みるという仕様があります。今回、アラートのしきい値を残り 14 日以内に設定したのは、オオカミ少年アラート(不必要な通知)を防ぐためです。30 日前からアラートを鳴らしてしまうと、正常な更新プロセス中のものまで検知してしまいますが、14 日を切った段階であれば確実に自動更新が失敗している異常事態と判断できるため、アラートの信頼性と運用性を両立させることができます。
これにより、分散した namespace にある多数のワイルドカード証明書やサービス単位の証明書を一元的に監視できる基盤を整えました。
マネージドサービスへの移行とトレードオフ
cert-manager 運用の他の選択肢として Google Cloud の Certificate Manager についても考えましたが、現状は Route53 や Istio との複雑な連携があるため、Datadog に監視を集約した方がいいと考えました。しかし、段階的な移行で将来の選択肢にはなると思います。
現状 kubectl コマンドによる手動確認で見えているから大丈夫という状態に対し、SRE として何をもって安全と言えるのかを自ら言語化し、改善案を提示するプロセスの重要性を学びました。単にツールを導入するだけでなく、その技術が組織にどのような安心をもたらすのかを考えさせられた貴重な経験になりました。
プラットフォームの安全な運用のためのタスク(Argo CD アップグレード等)と並行して、SRE としての基礎的な知識である、Kubernetes(k8s)のエコシステムを深く理解するための Boot Camp 形式の課題にも取り組みました。
普段利用している AWS Fargate 等のフルマネージド環境とは異なる、k8s 特有の作法や柔軟性を実戦形式で習得することができ、特に以下の観点がメインタスクの理解を大いに助けてくれました。
Helm を用いた抽象化と運用設計
単一のマニフェスト管理から、Helm を用いたパッケージ管理へとステップアップしました。テンプレート化による抽象化を学んだことで、Argo CD を介した宣言的なデプロイメント管理や、大規模なマニフェスト群を扱う際のベストプラクティスを構造的に理解することができました。
現場視点でのドメイン・証明書運用
実際のサービス公開に近いフローを自ら手を動かして経験しました。Cluster Issuer を用いて、Let's Encrypt による証明書発行から Secret への自動格納までの一連の流れを構築しました。また、Route53 へのレコード反映前に外部から疎通を確認する手法など、サービス移管などでレコードの向き先を変える前に動作確認する方法などの現場ならではの検証手順を習得できたことは大きな収穫でした。
短い期間でしたが、安全に運用し続けるための SRE 的視点とインフラを最適化する設計力の両面をバランスよく学ぶことができました。
また SRE の役割は、SLO 等の指標に基づいたインフラ運用にとどまらず、開発スピードと信頼性を両立させる基盤を提供し、組織の価値を最大化することにあると学びました。現場の課題に直接触れることで、画一的ではない、組織に最適化された SRE の在り方を体感しました。特に、今回取り組んだ Argo CD のアップグレードや証明書監視の自動化は、一つひとつがサービスの安定稼働と開発効率の向上に直結しており、プロの現場における設計の意図や未来への投資の重要性を学べたことは、今後のエンジニア人生において大きな財産になりました。
また、技術以外の面でも非常に濃密な時間を過ごせました。ランチや交流を通じて、社員の皆さんの仕事に対する熱量や、組織全体で技術を楽しんでいる空気感に触れることができました。キャリアのアドバイスから現場での苦労話まで、多岐にわたるお話を聞くことができ、インターンの課題以上にサイバーエージェントの魅力的な文化を深く理解することができました。
最後になりますが、未経験の技術も多かった私を温かく迎え入れ、丁寧に導いてくださったメンターさん、CAM の SRE Unit の皆さん、そして関わってくださった全ての皆さんに心から感謝いたします。3 週間、本当にありがとうございました!
原文を表示
東京科学大学情報理工学院情報工学系修士1年の千代丸怜央と申します。
2025年2月7日から2月27日までの3週間、株式会社CAMのSRE UnitにCA Tech JOB生として参加させていただきました。
本記事では、株式会社CAMのSREとして取り組んだタスクの詳細とそこから学び得たことについてご紹介いたします。
実際の現場で求められる SRE の能力を身につけるために、Cloud Native な技術に触れ、プラットフォームの改善を行うという題目で、以下の目的をもって参加しました。
・Argo CDのアップグレードやTLS証明書監視などを通じ、プラットフォームを「安全に運用し続ける」ためのSRE的視点
・既存Kubernetesクラスタの調査を通じた、インフラ構成の最適解を導き出す設計力
CDツールである Argo CD のバージョンアップグレード
SRE Unit でのメインタスクの一つとして、プラットフォームの継続的な運用のために、CDツールである、Argo CD のバージョンアップグレード(v2 → v3)に取り組みました。
検証環境(central-load-testing)で利用していた Argo CD は v2 系(v2.14.19)であり、最新の機能追従やセキュリティメンテナンスの観点から v3 系(v3.3.0)へのメジャーアップデートが必要な状態でした。
Argo CD はそれ自身も Helm Chart で管理されており、今回は単なるイメージタグの差し替えではなく、自分自身を更新する Argo CDの挙動を考慮したアップデートが求められました。
作業は大きく分けて「影響調査」と「実作業・検証」の 2 ステップで進めました。
- 破壊的変更(Breaking Changes)の調査
メジャーアップデートに伴い、既存の設定が動かなくなるリスクを最小限にするため、公式のアップグレードガイドを徹底的に調査しました。特に以下の 2 点に注目しました。
リポジトリ設定の移行: v3.0 から argocd-cm(ConfigMap)でのリポジトリ定義が廃止され、Secret ベースへの移行が必須となった点。
RBAC の変更: ログ閲覧権限が明示的に必要になるなど、既存の権限周りへの影響を確認しました。
Helm チャートの更新と差分分析
helmfile template を活用し、クラスターの現在の状態(LIVE)と適用後の状態(MERGED)の差分を詳細に分析しました。
調査に基づき、リポジトリ設定を Secret へ移行した上で Helm Chart のバージョンを 7.x から 9.x へ引き上げ、適用を実施しました。
正常稼働の確認: 全ての Pod が正常に Ready となり、管理画面へのアクセスも問題ないことを確認しました。
Sync 状態の遷移: 各 Application で一度 Sync を実行することで、期待通りに動作することを確認しました。
今回、事前に kubectl diff やテンプレートの展開結果を Cursor などのツールも活用して徹底的に読み解いたことで、メジャーアップデートという大きな変更に対しても、自信を持ってリリースを行うことができたかなと思います。Desired Stateをコードで管理する GitOps の恩恵を少し感じることができました。
cert-manager が発行する TLS証明書の有効期限を監視し、期限切れを未然に防ぐためのモニターの追加(Datadog)
もう一つのタスクとして、cert-manager が発行する TLS 証明書の有効期限監視の自動化に取り組みました。Terraform を用いて、Datadog 上に適切なモニターを設定する一連のフローを構築しました。
現状、証明書の状態確認は主に Argo CD の App Health や kubectl コマンドによる手動確認に依存していました。しかし、以下のリスクがあると考え、監視の強化を提案・実施しました。
「Healthy」だけでは不十分: Argo CD の Health 状態は「リソースが正しく同期されているか」を示しますが、「証明書の期限がいつ切れるか」「更新プロセスが内部で滞っていないか」までは可視化できません。
不可避な更新失敗リスク: Let’s Encrypt のレート制限、Route53 との連携不調、ClusterIssuer の認証情報(AWSキー)の期限切れなど、証明書更新には多くの不確実性が伴います。
高いユーザー影響: 証明書の期限切れは即座に HTTPS 通信の遮断(サービスダウン)に繋がるため、「切れる前に気づく」予兆検知が不可欠です。
実装内容:Datadog x cert-manager の連携
具体的には、cert-manager が露出するメトリクスを収集し、以下の観点で Datadog モニターを Terraform 経由で設定しました。
・有効期限(Expiry)の監視: cert-manager は通常、デフォルトで有効期限の約 1/3 前(90日間の証明書なら残り30日前)から自動更新を試みるという仕様があります。今回、アラートのしきい値を残り14日以内に設定したのは、オオカミ少年アラート(不必要な通知)を防ぐためです。30日前からアラートを鳴らしてしまうと、正常な更新プロセス中のものまで検知してしまいますが、14日を切った段階であれば確実に自動更新が失敗している異常事態と判断できるため、アラートの信頼性と運用性を両立させることができます。
これにより、分散した namespaceにある多数のワイルドカード証明書やサービス単位の証明書を一元的に監視できる基盤を整えました。
マネージドサービスへの移行とトレードオフ
cert-manager 運用の他の選択肢として選択肢としてGoogle Cloud の Certificate Manager についても考えましたが、現状は Route53 や Istio との複雑な連携があるため、Datadogに監視を集約した方がいいと考えました。しかし、段階的な移行で将来の選択肢にはなると思います。
現状kubectl コマンドによる手動確認で見えているから大丈夫という状態に対し、SRE として何をもって安全と言えるのかを自ら言語化し、改善案を提示するプロセスの重要性を学びました。単にツールを導入するだけでなく、その技術が組織にどのような安心をもたらすのかを考えさせられた貴重な経験になりました。
プラットフォームの安全な運用のためのタスク(Argo CDアップグレード等)と並行して、SREとしての基礎的な知識である、Kubernetes(k8s)のエコシステムを深く理解するためのBoot Camp形式の課題にも取り組みました。
普段利用している AWS Fargate 等のフルマネージド環境とは異なる、k8s特有の作法や柔軟性を実戦形式で習得することができ、特に以下の観点がメインタスクの理解を大いに助けてくれました。
Helmを用いた抽象化と運用設計
単一のマニフェスト管理から、Helmを用いたパッケージ管理へとステップアップしました。 テンプレート化による抽象化を学んだことで、Argo CD を介した宣言的なデプロイメント管理や、大規模なマニフェスト群を扱う際のベストプラクティスを構造的に理解することができました。
現場視点でのドメイン・証明書運用
実際のサービス公開に近いフローを自ら手を動かして経験しました。Cluster Issuer を用いて、Let’s Encrypt による証明書発行から Secret への自動格納までの一連の流れを構築しました。また、Route53 へのレコード反映前に外部から疎通を確認する手法など、サービス移管などでレコードの向き先を変える前に動作確認する方法などの現場ならではの検証手順を習得できたことは大きな収穫でした。
短い期間でしたが、安全に運用し続けるための SRE 的視点とインフラを最適化する設計力の両面をバランスよく学ぶことができました。
またSREの役割は、SLO等の指標に基づいたインフラ運用にとどまらず、開発スピードと信頼性を両立させる基盤を提供し、組織の価値を最大化することにあると学びました。現場の課題に直接触れることで、画一的ではない、組織に最適化されたSREの在り方を体感しました。特に、今回取り組んだArgo CDのアップグレードや証明書監視の自動化は、一つひとつがサービスの安定稼働と開発効率の向上に直結しており、プロの現場における設計の意図や未来への投資の重要性を学べたことは、今後のエンジニア人生において大きな財産になりました。
また、技術以外の面でも非常に濃密な時間を過ごせました。ランチや交流を通じて、社員の皆さんの仕事に対する熱量や、組織全体で技術を楽しんでいる空気感に触れることができました。キャリアのアドバイスから現場での苦労話まで、多岐にわたるお話を聞くことができ、インターンの課題以上にサイバーエージェントの魅力的な文化を深く理解することができました。
最後になりますが、未経験の技術も多かった私を温かく迎え入れ、丁寧に導いてくださったメンターさん、CAMのSRE Unitの皆さん、そして関わってくださった全ての皆さんに心から感謝いたします。3週間、本当にありがとうございました!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み