Algomatic がノーコード環境「LeLab」で模倣学習を開始
Algomatic のエンジニアが、低コストロボットアーム SO-101 を用いて LeLab でデータ収集し、ACT アルゴリズムで模倣学習を実行する一連の実験プロセスを報告している。
キーポイント
LeLab と ACT の活用による実機学習
シミュレーション環境から脱却し、LeLab を用いて人間の手本データを収集し、ACT (Action Chunking with Transformers) アルゴリズムで模倣学習を実行する具体的な手法が紹介されている。
低コストハードウェア SO-101 の活用
SO-101 という低価格なロボットアームをプラットフォームとして選択し、個人レベルでもシミュレーションから実機までの学習フローを完結可能であることを示している。
強化学習と模倣学習の継続的な探求
過去の RLPD や Gemini Robotics ER 1.6 を用いた実験の続きとして、実機制御におけるデータ収集からモデル適用までのワークフローを体系化している。
SO-101 と LeLab の役割分担
低コストなオープンソースロボットアーム SO-101 をリーダー(人間操作)とフォロワー(追従)の 2 本構成で使い、LeLab はそのデータ収集から学習・推論までをブラウザ上で管理する操作画面として機能します。
模倣学習による動作データの取得
人間がリーダーアームを手動で動かすことで、フォロワーアームの追従動きを記録し、そのままロボット学習のためのお手本データ(デモデータ)として生成できます。
模倣学習の初期導入メリット
報酬関数の設計不要かつ、実機での危険な試行錯誤を回避できるため、ロボット開発の最初のステップとして適している。
実験環境と構成
SO-101 リーダー/フォロワーロボットに Web カメラ 1 台、LeLab と LeRobot を用い、Mac (Apple Silicon) で ACT モデルを学習させた最小構成。
影響分析・編集コメントを表示
影響分析
この記事は、ロボット工学における模倣学習のハードルを下げ、個人開発者や小規模チームでも実機での AI 実験を可能にする具体的なワークフローを示しています。特に LeLab と ACT の組み合わせによる実践例は、シミュレーションから実世界への転移(Sim-to-Real)の実現に向けた有益な知見を提供します。
編集コメント
シミュレーション中心の議論が多い中、低コストハードウェアを用いた実機での模倣学習フローを具体的に示した点は非常に価値があります。

初めまして、Algomatic AIエンジニアのYusuke(https://x.com/yusuke_post)です。普段は、現場で活躍するAIを開発する案件に取り組んでいます。
『Algomatic 初夏のアドベントカレンダー』と題して、メンバーそれぞれが好きな技術を好きに語る会の19日目です。
昨日の記事は「Claude Code / Codex Hooks と nvim --server で作る terminal-native IDE」でした。
はじめに
最近、個人では SO-101 という低コストなロボットアームを題材に、シミュレーションから実機まで一通り触っていました。これまではシミュレーション上で、強化学習や模倣学習、Gemini Robotics ER 1.6を使った「言葉で対象を選んでつかむ」実験などを試してきました。
オフラインデータを活用してオンライン強化学習を効率化する手法、RLPD(Reinforcement Learning with Prior Data)も試した。 https://t.co/WhYtEMAqbe pic.twitter.com/rd5lP7YAMz
— Yusuke (@yusuke_post) June 15, 2026
— Yusuke (@yusuke_post) June 16, 2026
Gemini ER 1.6による、障害物を回避する軌道の生成 pic.twitter.com/cd1r6b367X
— Yusuke (@yusuke_post) June 14, 2026
今回はその続きです。実機の SO-101 を用意して、LeLab で人のお手本を集め、ACT で模倣学習させ、最後に実機で動かすところまでやってみました。
- はじめに
- SO-101とLeLab
- 模倣学習
- 実験環境
- お手本データ
- ACT
- 実機で動かす
- やって分かったこと
- 次にやりたいこと
- 採用しています
SO-101とLeLab
SO-101 は、低コストなオープンソースのロボットアームです。今回の実験ではアームを2本使います。
 imageフォロワー(左側)とリーダー(右側)
imageフォロワー(左側)とリーダー(右側)
- リーダー:人が手で動かすアーム
- フォロワー:リーダーの動きに追従するアーム
人がリーダーを動かすと、フォロワーが同じように動きます。この追従を記録すると、人間の操作をそのままお手本データにできます。
今回使った LeRobot は、ロボットのデータ収集、学習、推論を扱うためのフレームワークです。
LeLab は、その LeRobot をブラウザから操作するための画面です。キャリブレーション、テレオペ、データ収集、学習、推論を画面上で進められます。実際に制御や学習をしているのは LeRobot で、LeLab はその操作画面、という理解が近いです。
模倣学習
模倣学習は、人間のお手本を使ってロボットを学習させる方法です。
Monday mornings at the @virtuals_io office just hit different. pic.twitter.com/Ca3vkZeMMk
— DonJohnson (@DonJohnsonSays) 2026 年 6 月 22 日
強化学習(Reinforcement Learning)では、ロボットが試行錯誤を繰り返しながら報酬を最大化します。一方、模倣学習(Imitation Learning)では、まず人間が動作を見せます。モデルはそのデータを見て、同じように動くことを学びます。
実機ロボットの最初の一歩としては、模倣学習のほうが入りやすいです。報酬関数(Reward Function)を作らなくてよく、実機に危険な試行錯誤を大量にさせずに済むからです。もちろん、お手本が雑だと雑な動きもそのまま学びます。ここはまあ、当たり前ですが結構効きます。
実験環境
今回使った環境です。
- ロボット: SO-101 リーダー / フォロワー
- カメラ: Webカメラ 1 台
- 操作画面:LeLab
- 学習・推論基盤:LeRobot
- 学習モデル:ACT
- 実行環境:Mac / Apple Silicon / MPS / メモリ24GB
 imageカメラの位置は手前から斜めに見下ろすようにおいた
imageカメラの位置は手前から斜めに見下ろすようにおいた
カメラは手前から斜めに見下ろす位置に置きました。今回は最小構成で試したかったのでカメラは 1 台です。あとから振り返ると、ここは最初から複数カメラでもよかったかもしれません。
お手本データ
最初にやるのはデモ収集です。人がリーダーを動かし、フォロワーがそれに追従します。そのときのカメラ画像、関節状態、行動を LeRobot のデータセットとして記録します。
LeLabでのデータ作成の様子はこちら
こちらの動画は今回学習させたタスクそのものではありませんが、LeLab でデータを作る雰囲気は伝わるかなと思います。
 image模倣学習用のデータをLeLabで作成する様子
image模倣学習用のデータをLeLabで作成する様子
LeLabを使うと、データセットの作り方を指示してくれます。
「タスクを実行してください」「環境をリセットしてください」
みたいなことを画面に表示してくれるのでそれに従ってリーダーの方を動かしてデータセットを作ります。
今回やったのは、緑のブロックを持ち上げて落とすタスクです。ロボットを動かして記録し、スペースキーを押して、手で環境をリセットする。それを繰り返します。
条件はこのくらいです。
- 80エピソード
- 緑のブロックを持ち上げて落とす
- リセットは手作業
- LeLab で記録
このデータを、次の ACT 学習に使いました。
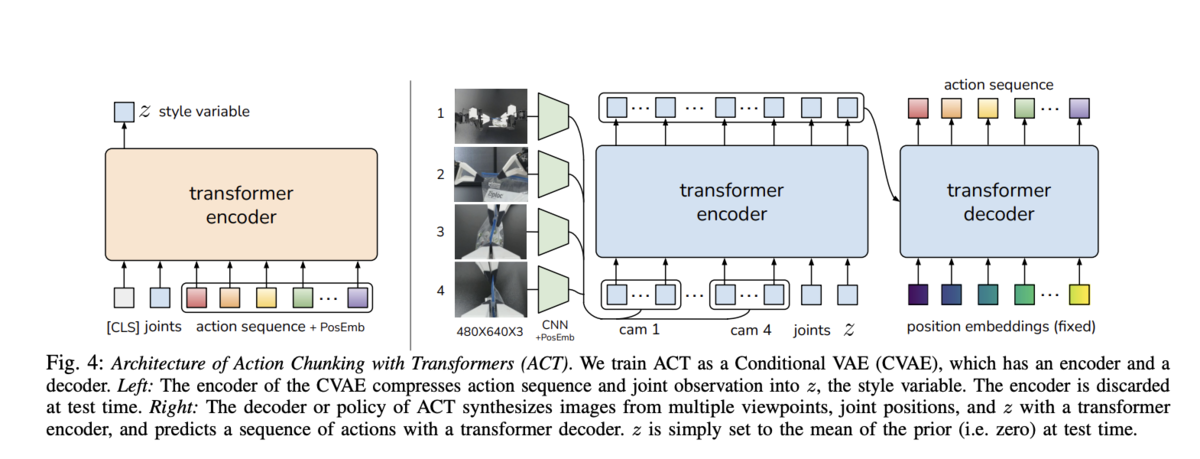
ACT
集めたデモを使って、ACT を学習します。ACT は Action Chunking Transformer の略で、ロボット模倣学習でよく使われるモデルのひとつです。
 imageLearning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
imageLearning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
https://arxiv.org/pdf/2304.13705
ACT はカメラ画像と現在の関節状態を入力として受け取り、次に出す行動列を予測します。1回の推論で次の1手だけを出すのではなく、短い動作のまとまりを出します。このまとまりが action chunk です。
もう一つの特徴は CVAE(Conditional Variational Autoencoder)を使っていることです。同じ場面でも、人間の動かし方は一通りではありません。少し左から近づく、右から近づく、速くつかむ、ゆっくりつかむ。そういう揺れがあります。
ACT は、こうした複数の自然な動き方を扱いやすい形で学習します。単純に平均の動きを出すより、デモに含まれる動作のまとまりを覚えやすい、という理解をしています。
強化学習をいきなり実機で回す場合、報酬設計、安全性、試行回数が大変になります。ACT なら、人間が集めたデモを使ってまず真似るところから始められます。SO-101 の最初のモデルとしては、かなり現実的でした。
今回の学習では、50エピソード規模のデータを使い、10,000 step まで回しました。途中の checkpoint を保存し、その後の実機推論に使いました。
画像を選択してボタンをクリックするだけで、模倣学習を開始できます。
 imageLeLab で学習している様子
imageLeLab で学習している様子
実機で動かす
学習した ACT(Action Transformer)を LeLab からロードし、カメラ入力を見ながらフォロワーを動かしました。
 image学習したモデルをロードして実機で動かすことができる LeLab の画面。チェックポイントを指定できる。
image学習したモデルをロードして実機で動かすことができる LeLab の画面。チェックポイントを指定できる。
 image動作している様子①
image動作している様子①
 image動作している様子②
image動作している様子②
緑のブロックを持ち上げて落とす動きは出ています。完璧ではありませんが、人が集めたデータから学習したモデルを、実機に戻して動かすところまでは確認できました。
やって分かったこと
精度に影響を与えたのは、カメラとデータセットの質だと思いました。
カメラが 1 台だけだと、ロボットや物体の位置関係をうまく見られない場面があります。斜め前から見下ろすように置きましたが、手や物体が隠れる瞬間があります。次にやるなら、カメラ位置を変えるか、複数カメラにしたいです。
もう一つはデータセットの揃え方です。置く場所や物体の初期位置をどう変えるかをちゃんと決めないと、モデルが何を覚えたのか分かりにくくなります。ランダム性は必要ですが、雑にばらすと学習も評価も微妙になります。
次にやりたいこと
まず、タスクを少し難しくします。今回は緑のブロックを持ち上げて落とすだけでした。次は物体の位置を変える、つかんだ後に別の場所へ置く、複数の物体を扱う、くらいまではやりたいです。
過去のハッカソンの事例だと、こういうものがあります。
次に、さまざまなモデルを試したいと考えています。特に SmolVLA は試したいです。ACT で最小構成での実験はできたので、同じデータやタスクで別モデルを比べられるようにしたい。
最後に、Claude Code や Codex を使って学習自体を自動化したいです。
この方向の例として、最近の研究では NVIDIA の ENPIRE があります。実機ロボットの試行を自動で評価し、ログや失敗例をもとにコーディングエージェントが方策や学習コードを改善していく仕組みです。
個人的に面白かったのは、環境のリセットまで自動化しようとしているところです。
 imageNVIDIA の Claude Code を用いたロボットの学習の自動化の事例。https://research.nvidia.com/labs/gear/enpire/
imageNVIDIA の Claude Code を用いたロボットの学習の自動化の事例。https://research.nvidia.com/labs/gear/enpire/
NVIDIA の Jim Fan 氏のロボットの自律研究システム「ENPIRE」の解説。
・安全装置(Safety Harness)
ロボットが安全範囲を逸脱した瞬間にタスクを停止し自動リセット
・成功の定義を固定する(Definition of Done)… https://t.co/IXg0JcCV6n
— Yusuke (@yusuke_post) June 19, 2026
まずはカメラ画像から物体位置やグリッパー位置を読み、成功判定や距離ベースの報酬(リワード)を作るところからです。そこまでできれば、模倣学習で作った初期モデルを出発点にして、強化学習でさらに改善する流れに進めるのかなと思います。
採用しています
ここまで読んでいただきありがとうございました!
Algomatic では、変化の速い領域でも学びと試行錯誤を続けられるエンジニアを募集しています。
少しでも気になったら、カジュアル面談でお話ししましょう。
原文を表示
はじめまして、Algomatic AIエンジニアのYusuke(https://x.com/yusuke_post)です。普段は、現場で活躍するAIを開発する案件に取り組んでいます。
『Algomatic 初夏のアドベントカレンダー』と題して、メンバーそれぞれが好きな技術を好きに語る会の19日目です。
昨日の記事は「Claude Code / Codex Hooks と nvim --server で作る terminal-native IDE」でした。
はじめに
最近、個人では SO-101 という低コストなロボットアームを題材に、シミュレーションから実機まで一通り触っていました。
これまではシミュレーション上で、強化学習や模倣学習、Gemini Robotics ER 1.6を使った「言葉で対象を選んでつかむ」実験などを試してきました。
オフラインデータを活用してオンライン強化学習を効率化する手法、RLPD(Reinforcement Learning with Prior Data)も試した。 https://t.co/WhYtEMAqbe pic.twitter.com/rd5lP7YAMz— Yusuke (@yusuke_post) June 15, 2026
— Yusuke (@yusuke_post) June 16, 2026
Gemini ER 1.6による、障害物を回避する軌道の生成 pic.twitter.com/cd1r6b367X— Yusuke (@yusuke_post) June 14, 2026
今回はその続きです。実機の SO-101 を用意して、LeLab で人のお手本を集め、ACT で模倣学習させ、最後に実機で動かすところまでやってみました。
- はじめに
- SO-101とLeLab
- 模倣学習
- 実験環境
- お手本データ
- ACT
- 実機で動かす
- やって分かったこと
- 次にやりたいこと
- 採用しています
SO-101とLeLab
SO-101 は、低コストなオープンソースのロボットアームです。今回の実験ではアームを2本使います。
- リーダー: 人が手で動かすアーム
- フォロワー: リーダーの動きに追従するアーム
人がリーダーを動かすと、フォロワーが同じように動きます。この追従を記録すると、人間の操作をそのままお手本データにできます。
今回使った LeRobot は、ロボットのデータ収集、学習、推論を扱うためのフレームワークです。
LeLab は、その LeRobot をブラウザから操作するための画面です。キャリブレーション、テレオペ、データ収集、学習、推論を画面上で進められます。実際に制御や学習をしているのは LeRobot で、LeLab はその操作画面、という理解が近いです。
模倣学習
模倣学習は、人間のお手本を使ってロボットを学習させる方法です。
Monday mornings at the @virtuals_io office just hit different. pic.twitter.com/Ca3vkZeMMk— DonJohnson (@DonJohnsonSays) June 22, 2026
強化学習では、ロボットが試行錯誤しながら報酬を最大化します。模倣学習では、まず人間が動作を見せます。モデルはそのデータを見て、同じように動くことを学びます。
実機ロボットの最初の一歩としては、模倣学習のほうが入りやすいです。報酬関数を作らなくてよく、実機に危ない試行錯誤を大量にさせずに済むからです。もちろん、お手本が雑だと雑な動きもそのまま学びます。ここはまあ、当たり前ですが結構効きます。
実験環境
今回使った環境です。
- ロボット: SO-101 リーダー / フォロワー
- カメラ: Webカメラ 1台
- 操作画面: LeLab
- 学習・推論基盤: LeRobot
- 学習モデル: ACT
- 実行環境: Mac / Apple Silicon / MPS / メモリ24GB
カメラは手前から斜めに見下ろす位置に置きました。今回は最小構成で試したかったのでカメラは1台です。あとから振り返ると、ここは最初から複数カメラでもよかったかもしれません。
お手本データ
最初にやるのはデモ収集です。人がリーダーを動かし、フォロワーがそれに追従します。そのときのカメラ画像、関節状態、行動を LeRobot のデータセットとして記録します。
LeLabでのデータ作成の様子はこちら
こちらの動画は今回学習させたタスクそのものではありませんが、LeLab でデータを作る雰囲気は伝わるかなと思います。
LeLabを使うと、データセットの作り方を指示してくれます。
「タスクを実行してください」「環境をリセットしてください」
みたいなことを画面に表示してくれるのでそれに従ってリーダーの方を動かしてデータセットを作ります。
今回やったのは、緑のブロックを持ち上げて落とすタスクです。ロボットを動かして記録し、スペースキーを押して、手で環境をリセットする。それを繰り返します。
条件はこのくらいです。
- 80エピソード
- 緑のブロックを持ち上げて落とす
- リセットは手作業
- LeLab で記録
このデータを、次の ACT 学習に使いました。
ACT
集めたデモを使って、ACT を学習します。ACT は Action Chunking Transformer の略で、ロボット模倣学習でよく使われるモデルのひとつです。

ACT はカメラ画像と現在の関節状態を入力として受け取り、次に出す行動列を予測します。1回の推論で次の1手だけを出すのではなく、短い動作のまとまりを出します。このまとまりが action chunk です。
もう一つの特徴は CVAE(Conditional Variational Autoencoder)を使っていることです。同じ場面でも、人間の動かし方は一通りではありません。少し左から近づく、右から近づく、速くつかむ、ゆっくりつかむ。そういう揺れがあります。
ACT は、こうした複数の自然な動き方を扱いやすい形で学習します。単純に平均の動きを出すより、デモに含まれる動作のまとまりを覚えやすい、という理解をしています。
強化学習をいきなり実機で回す場合、報酬設計、安全性、試行回数が大変になります。ACT なら、人間が集めたデモを使ってまず真似るところから始められます。SO-101 の最初のモデルとしては、かなり現実的でした。
今回の学習では、50エピソード規模のデータを使い、10,000 step まで回しました。途中の checkpoint を保存し、その後の実機推論に使いました。
実機で動かす
学習した ACT を LeLab からロードし、カメラ入力を見ながらフォロワーを動かしました。
緑のブロックを持ち上げて落とす動きは出ています。完璧ではないですが、人が集めたデータから学習したモデルを、実機に戻して動かすところまでは確認できました。
やって分かったこと
精度に影響を与えたのは、カメラとデータセットの質だと思いました。
カメラが1台だけだと、ロボットや物体の位置関係をうまく見られない場面があります。斜め前から見下ろすように置きましたが、手や物体が隠れる瞬間があります。次にやるなら、カメラ位置を変えるか、複数カメラにしたいです。
もう一つはデータセットの揃え方です。置く場所や物体の初期位置をどう変えるかをちゃんと決めないと、モデルが何を覚えたのか分かりにくくなります。ランダム性は必要ですが、雑にばらすと学習も評価も微妙になります。
次にやりたいこと
まず、タスクを少し難しくします。今回は緑のブロックを持ち上げて落とすだけでした。次は物体の位置を変える、つかんだ後に別の場所へ置く、複数の物体を扱う、くらいまではやりたいです。
過去のハッカソンの事例だと、こういうものがあります。
次に、さまざまなモデルを試したいと考えています。特に SmolVLA は試したいです。ACT で最小構成での実験はできたので、同じデータやタスクで別モデルを比べられるようにしたい。
最後に、Claude Code や Codex を使って学習自体を自動化したいです。
この方向の例として、最近の研究ではNVIDIA の ENPIRE があります。実機ロボットの試行を自動で評価し、ログや失敗例をもとにコーディングエージェントが方策や学習コードを改善していく仕組みです。
個人的に面白かったのは、環境のリセットまで自動化しようとしているところです。
NVIDIAのClaude Codeを用いたロボットの学習の自動化の事例。[https://research.nvidia.com/labs/gear/enpire/](https://cdn-ak.f.st-hatena.com/images/fotolife/m/mikami_algomatic/20260623/20260623235914.png)
NVIDIAのJim Fan氏のロボットの自律研究システム「ENPIRE」の解説。・安全装置(Safety Harness)ロボットが安全範囲を逸脱した瞬間にタスクを停止し自動リセット・成功の定義を固定する(Definition of Done)… https://t.co/IXg0JcCV6n— Yusuke (@yusuke_post) June 19, 2026
まずはカメラ画像から物体位置やグリッパー位置を読み、成功判定や距離ベースの報酬を作るところからです。そこまでできれば、模倣学習で作った初期モデルを出発点にして、強化学習でさらに改善する流れに進めるのかなと思います。
採用しています
ここまで読んでいただきありがとうございました!
Algomatic では、変化の速い領域でも学びと試行錯誤を続けられるエンジニアを募集しています。
少しでも気になったら、カジュアル面談でお話ししましょう。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み