Tritonにおけるインライン要素別アセンブリによる命令レベルの制御
Tritonが提供するInline Elementwise ASM機能により、Pythonの抽象化層を維持しつつGPU固有のPTXアセンブリ命令を直接注入できる手法と、その適用範囲が解説されている。
キーポイント
Tritonのコンパイルパイプラインと限界
PythonからPTX、CUBINへの lowered 過程において、Tritonはメモリ階層や同期処理を自動最適化するが、ビットパックや特殊命令など「特定のデバイス固有アセンブリ」への完全な制御は提供していない。
Inline Elementwise ASMによる中間解法
Tritonは `inline_elementwise_asm` APIを提供し、Pythonコードから離脱せずに要素ごとのGPUアセンブリ命令を注入できる「中間層」を実現しており、これにより高度な最適化が可能になる。
実装例と引数の詳細
浮動小数点行列の除算演算など、特定の計算パターンにおいて `rcp` などの単一命令を注入する例を示し、asm文字列、制約条件、引数、データ型などの関数シグネチャについて解説している。
除算の高速近似手法
通常の `div` 命令ではなく、逆数計算 (`rcp.approx`) と乗算を組み合わせることで、浮動小数点除算の高速な近似計算が可能である。
Inline Elementwise ASM の実装
`tl.inline_asm_elementwise` を使用して PTX 命令を直接記述し、入力テンソル `b` から逆数 `multiplier` を生成して `a` と乗算する。
PTX 命令の詳細と制約
`rcp.approx.ftz.f32` 命令を用い、`constraints` で入出力レジスタの形式を指定し、`args` で Python のテンソル値を PTX レジスタに渡す。
浮動小数点除算の最適化
浮動小数点除算(div.full.f32)を逆数近似(rcp.approx.ftz.f32)と乗算に置き換えることで、PTXレベルで最適化され、わずかながら実行速度の向上が見られる。
影響分析・編集コメントを表示
影響分析
この機能は、高性能計算や推論パイプラインの最適化を追求する開発者にとって、Tritonの適用範囲を広げる重要な進展です。Pythonの高生産性と低レベルなハードウェア制御を両立できるため、特定のGPUアーキテクチャに特化した最適化コストを削減できます。ただし、可読性や移植性のトレードオフがあるため、標準的なカーネル開発ではなく、ボトルネック解消のための最終手段として位置づけられるでしょう。
編集コメント
Tritonの進化により、Pythonエコシステム内でより細粒度なGPU最適化が可能になりました。ただし、アセンブリ命令の直接注入はデバッグ難易度を高めるため、ベンチマークによる明確な性能向上が確認できる場合に限定して使用すべきです。

Triton は、Python で高速な GPU カーネルを書くことを欺瞞的に容易にする DSL(ドメイン固有言語)です。これは、純粋な GPU カーネルをゼロから書く際の微妙なニュアンス、つまり手動のメモリ階層処理、同期、低レベルな起動設定などを抽象化しつつも、高度に最適化された GPU コードを生成します。
しかし、Triton カーネルが生成しない可能性のあるデバイス固有のアセンブリ命令(ビットのパッキングや、特殊/高速な命令の使用など)に対して正確な制御を行いたい瞬間に、壁にぶつかります。この壁は通常、より低いレベルへ降りて、任意のアセンブリ命令を書き込める場所へと人々を導く地点です。
この壁を克服するために、Triton は中間的な API を提供しています:インライン要素別アセンブリ(Inline Elementwise ASM)
この記事では、Python の快適な環境から一度も離れることなく、どのようにして Triton で要素別 GPU アセンブリ命令を注入できるか、そしてこのアプローチが実際に価値があるのはどのような場合かを紹介します。まず、Triton カーネルが実際には何にコンパイルされるのかを簡単に理解しましょう。なお、本記事は NVIDIA GPU に焦点を当てており、デバイス固有のアセンブリも PTX と呼ばれます。
Python から PTX へ
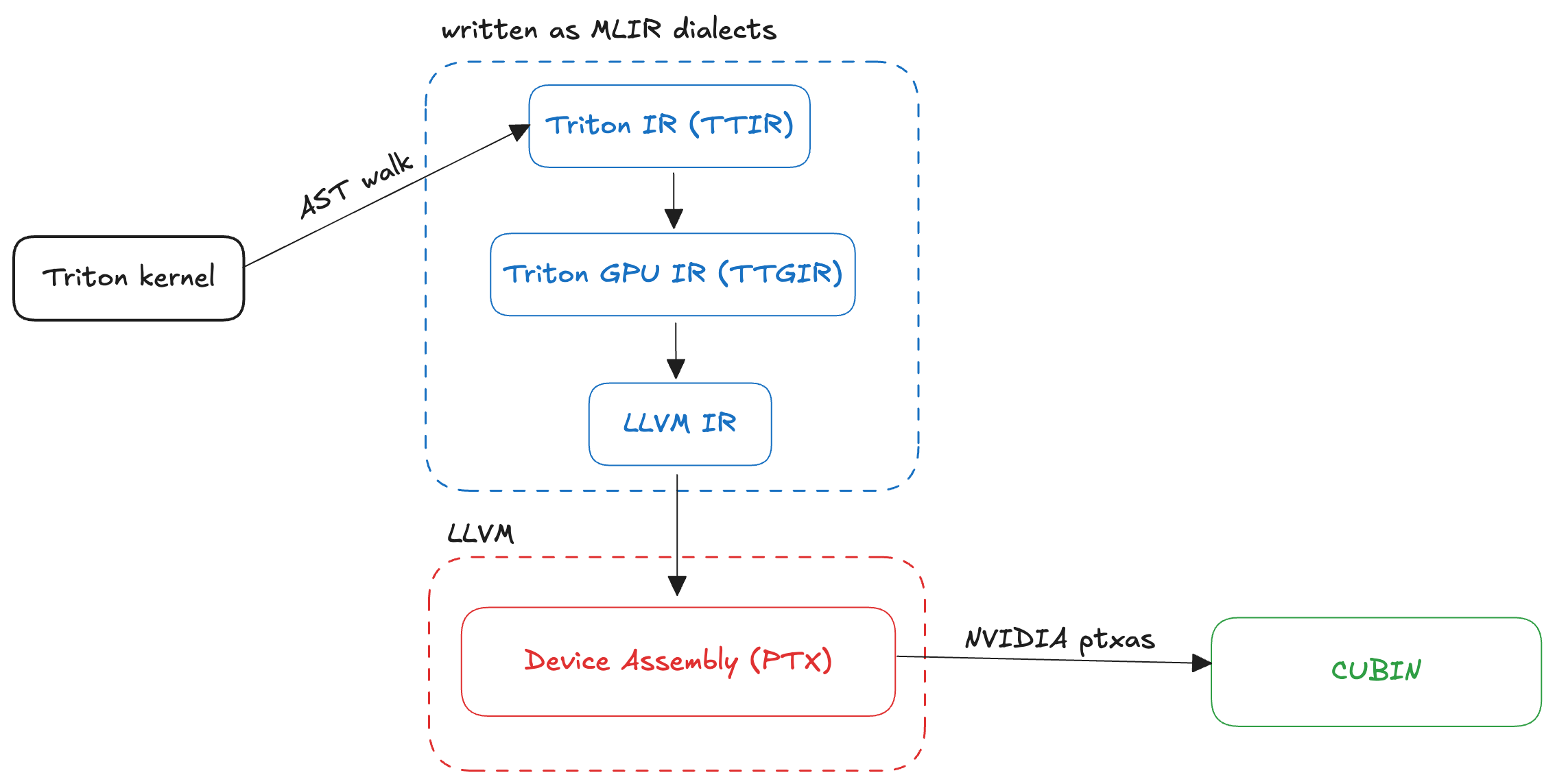
Triton は、多くの lowering ステージを経て Python からデバイス固有のアセンブリへと変換されます。Kapil Sharma による素晴らしい記事が、Triton カーネルのコンパイル中に実際に何が起こるかを要約しています:
Python カーネルは、テンソルとカーネルのセマンティクスを表す高レベルな Triton IR へパースされます。
この IR は、MLIR ダイアレクト(Triton -> TritonGPU -> TritonNVIDIAGPU)を通じて段階的に低レベル化され、タイル処理、ベクトル化、共通部分式除去 (CSE)、定数畳み込みといったドメイン固有の最適化が適用されます。
最適化された Triton IR は LLVM IR へさらに低レベル化され、追加のコンパイラ最適化を可能にします。
LLVM IR は、NVIDIA の GPU 中間表現である PTX へと翻訳されます。
PTX は NVIDIA のツールチェーンによって JIT コンパイルされ CUBIN となり、GPU で実行されます。
以下の画像は、Triton カーネルのコンパイル中に何が起こるかの視覚的な表現を示しています:
次に、Triton カーネル内で単一の要素ごとの PTX 命令を注入する例を見てみましょう。
例 1: 単一命令 (rcp)
Triton は、与えられた引数に対して要素ごとに動作する PTX 命令を注入できる inline_elementwise_asm 関数を提供しています。この関数のシグネチャは以下の通りです:
triton.language.inline_asm_elementwise(asm: str, constraints: str, args: Sequence, dtype: dtype | Sequence[dtype], is_pure: bool, pack: int, _semantic=None)
このブログ記事では、この関数が受け取る引数について順に説明していきますが、まずは以下の例に焦点を当てましょう。
仮に、形状 (M, N) の 2 つの float32 行列 A と B が与えられており、同じ形状を持つ別の行列 C を計算したいとします。ここで、C は次のように定義されます:
ci = ai / bi
この演算は、float32 データ型に対して Triton で容易に利用可能です。しかし、別の方法でも結果を計算できます:
ci = ai * (1 / bi)
ここで (1 / bi) は、bi 値の逆数(reciprocal)です。これを覚えておいてください。
この演算に対する、インライン PTX を含まない通常の Triton カーネルは、以下のようなものになります:
@triton.jit
def _kernel(
a_ptr, b_ptr, c_ptr, N,
BLOCK_SIZE: tl.constexpr = 1024
):
pid = tl.program_id(0)
offs = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offs < N
a = tl.load(a_ptr + offs, mask=mask, other=0.0)
b = tl.load(b_ptr + offs, mask=mask, other=1.0)
c = a / b
tl.store(c_ptr + offs, c, mask=mask)
このカーネルに対するホスト関数は以下のようになります:
def div(a: torch.Tensor, b: torch.Tensor, version=1):
numel = a.numel()
out = torch.empty_like(a)
grid = lambda meta: (triton.cdiv(numel, meta['BLOCK_SIZE']), )
K = _kernelgrid
return out, K
このカーネルの Triton によってコンパイルされた PTX を、K.asm['ptx'] をファイルにダンプすることで確認できます。そうすると、Triton が PTX で ai / bi を計算するために以下の命令を使用していることがわかります:
div.full.f32 d, a, b;
ここで、値 ai は 32 ビットレジスタ a に格納され、値 bi は 32 ビットレジスタ b に格納され、結果は d に格納されます。
PTX のドキュメントを確認すると、与えられた float32 値の高速な近似逆数(reciprocal)を計算する命令が見つかります:
rcp.approx{.ftz}.f32 d, a;
したがって、必要であれば、bi 値の高速な近似逆数を計算し、その結果を ai 値に掛けることができます。これを行うには、カーネルを以下のように更新する必要があります:
@triton.jit
def _kernel(
a_ptr, b_ptr, c_ptr, N,
BLOCK_SIZE: tl.constexpr = 1024
):
pid = tl.program_id(0)
offs = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offs < N
a = tl.load(a_ptr + offs, mask=mask, other=0.0)
b = tl.load(b_ptr + offs, mask=mask, other=1.0)
(multiplier,) = tl.inline_asm_elementwise(
asm="rcp.approx.ftz.f32 $0, $1;",
constraints="=r,r",
args=[b],
dtype=[tl.float32],
is_pure=True,
pack=1
)
c = a * multiplier
tl.store(c_ptr + offs, c, mask=mask)
本質的には、これはトリトンテンソルの要素に対するマップ演算であり、その関数はインライン PTX です。
asm: これはテンソルの要素に対して使用される文字列命令です。要素を 32 ビットレジスタとしてアクセスするには、プレースホルダーの $0, $1, $2 などを使用できます。
constraints: これは、入力および出力テンソルとデータ型の数に基づいて、トリトンに出力および入力レジスタの数を伝える文字列です。より詳しく理解するためには、ASM LLVM フォーマットドキュメントをご覧ください。出力レジスタは =r で識別され、入力レジスタは r です。
args: 値がインラインアセンブリブロックへ 32 ビットレジスタとして渡される入力トリトンテンソルです。
dtype: 返されるテンソルの要素型です。出力レジスタとその dtype を正しく設定して誤った結果を避けることはプログラマの責任です。
is_pure: true の場合、Triton コンパイラは ASM ブロックに副作用がないと仮定し、インライン ASM はそのまま動作します。
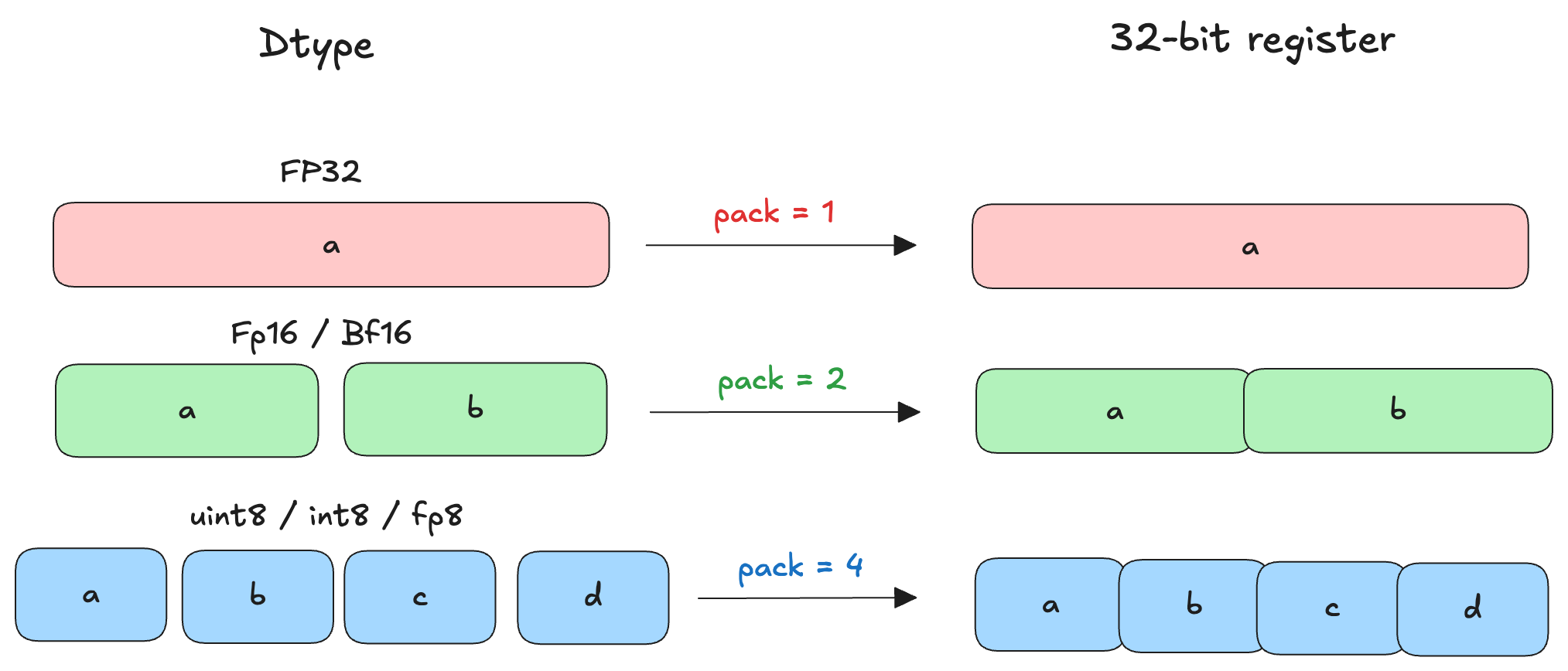
pack: インライン ASM の各呼び出しでは、一度にパックされた要素が処理されます。ブロックがどの入力セットを受け取るかは指定されていません。4 バイト(32 ビット)未満のサイズの要素は、4 バイト(32 ビット)レジスタにパッキングされます。
この例では float32 dtype のみを扱っているため、パッキングは不要であり、一度に 1 つの要素のみを処理します。
両方のバージョンを実行すると出力に違いは見られませんが、Triton が生成した PTX を検査してみると以下のようになります:
version 1 で生成された PTX
div.full.f32 %r33, %r1, %r17;
div.full.f32 %r34, %r2, %r18;
div.full.f32 %r35, %r3, %r19;
div.full.f32 %r36, %r4, %r20;
div.full.f32 %r37, %r9, %r25;
div.full.f32 %r38, %r10, %r26;
div.full.f32 %r39, %r11, %r27;
div.full.f32 %r40, %r12, %r28;
実行時間:0.12382 ms
version 2 で生成された PTX
rcp.approx.ftz.f32 %r33, %r34;
rcp.approx.ftz.f32 %r35, %r36;
rcp.approx.ftz.f32 %r37, %r38;
rcp.approx.ftz.f32 %r39, %r40;
rcp.approx.ftz.f32 %r41, %r42;
rcp.approx.ftz.f32 %r43, %r44;
rcp.approx.ftz.f32 %r45, %r46;
rcp.approx.ftz.f32 %r47, %r48;
mul.f32 %r49, %r33, %r1;
mul.f32 %r50, %r35, %r2;
mul.f32 %r51, %r37, %r3;
mul.f32 %r52, %r39, %r4;
mul.f32 %r53, %r41, %r9;
mul.f32 %r54, %r43, %r10;
mul.f32 %r55, %r45, %r11;
mul.f32 %r56, %r47, %r12;
実行時間:0.12375 ミリ秒
実際、2 番目のバージョンの方が 1 番目のバージョンよりわずかに高速です!それ以外にも、ビットパッキングや特殊命令などを操作する必要がある場合、通常の Triton に比べて要素ごとの PTX(Program Thread eXecution)を注入することで、はるかに多くの柔軟性が得られます。
例 2:パッキングと複数の命令
形状が (N,) の float16 配列 A と B が 2 つあり、C と D を以下のように計算したいとします。
ci = ai * bi + 1.0
ci = clamp(ci, 0.0, 6.0)
di = ci * ci
ここでデータ型が float16 の場合、要素ごとのアセンブリ関数を使用して一度に 2 つの要素を処理できます。Triton は自動的に 32 ビットレジスタ内に 2 つの float16 値をパッキングします。これに加えて、C と D を計算するために以下の f16x2 PTX 命令を使用できます。
fma.rnd{.ftz}{.sat}.f16x2 d, a, b, c;
max{.ftz}{.NaN}{.xorsign.abs}.f16x2 d, a, b;
mul{.rnd}{.ftz}{.sat}.f16x2 d, a, b;
通常のカーネルと PTX を注入したカーネルは以下のようになります。
@triton.jit
def kernel_fp16_normal(A, B, C, D, BLOCK: tl.constexpr):
offs = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
a = tl.load(A + offs)
b = tl.load(B + offs)
y = a * b + 1.0
y = tl.clamp(y, 0.0, 6.0)
tl.store(C + offs, y)
tl.store(D + offs, y * y)
and,
@triton.jit
def kernel_fp16_pack2(A, B, C, D, BLOCK: tl.constexpr):
offs = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
a = tl.load(A + offs)
b = tl.load(B + offs)
(c, d) = tl.inline_asm_elementwise(
asm="""
{
.reg .b32 tmp<3>;
mov.b32 tmp0, 0x3C003C00; // 1.0
mov.b32 tmp1, 0x00000000; // 0.0
mov.b32 tmp2, 0x46004600; // 6.0
// y = a * b + 1
fma.rn.f16x2 $0, $2, $3, tmp0;
// clamp
max.f16x2 $0, $0, tmp1;
min.f16x2 $0, $0, tmp2;
// d = y * y
mul.rn.f16x2 $1, $0, $0;
}
""",
constraints="=r,=r,r,r",
args=[a, b],
dtype=(tl.float16, tl.float16),
is_pure=True,
pack=2,
)
tl.store(C + offs, c)
tl.store(D + offs, d)
Here, we pass the two Triton tensors as arguments. We use the value of pack as 2 so that Triton can pack two float16 elements in one 32-bit register which we can use with the f16x2 instruction. For the outputs, Triton also unpacks the 32-bit register containing the f16x2 value (32-bit register) to the given output dtype.
以下の画像は、異なるデータ型(dtypes)において要素をパッキングする方法を示しています:
出力を比較すると違いは見られませんが、両方のカーネルが達成した実効メモリ帯域幅(GB/s)を見ると、以下のようになります:
Normal Triton : 6502.08 GB/s
Inline PTX f16x2: 6514.12 GB/s
この例では、インライン PTX を使用する二番目のカーネルの方が、最初のカーネルより 12 GB/s 高速であることがわかります!
上記の簡易な例では、Triton はすでに必要な演算をサポートしています。しかし、ここでは実際の事例を見て、Triton が標準で明示的なサポートを提供していない場合でも PTX 命令を使用できることを理解しましょう。
例 3: Blackwell GPU における NVFP4 量子化
NVFP4 は、形状 (M, N) の与えられた行列 X を FP4 e2m1 データ型へ量子化するブロックスケーリング量子化のレシピです。FP4 の狭い精度を考慮し、量子化誤差を緩和するためにここでは二つのスケールファクタを使用します:グローバルなテンソル全体のスケール(データ型 fp32)と、ローカルなブロックごとのスケール(データ型 FP8 e4m3)です。ここでいうブロックスケールのサイズは 16 で、つまり連続する 16 個の要素が共通のローカルスケーリングファクタを共有します。
形状 (M, N) の行列 X を NVFP4 すなわち fp4 e2m1 データ型へ正確に量子化する方法の詳細には立ち入りませんが、要点は以下の通りです:
テンソル全体を通じての絶対最大値(amax_x)を計算する。
グローバルエンコードスケールを (6 × 448) / amax_x として計算し、その逆数を FP32 でグローバルデコードスケールとして保存します。
テンソルを Tensor Core の粒度に一致する連続ブロックに分割します。
各ブロックに対して、ブロック絶対最大値 (amax_b) を計算し、ローカルデコードスケールを amax_b / 6 として算出します。
ローカルデコードスケールにグローバルエンコードスケールを乗算し、偶数への丸めを用いて FP8 (E4M3) に量子化します。
量子化された FP8 デコードスケールの逆数を適用し、グローバルデコードスケールを乗じることで、有効なローカルエンコードスケールを復元します。
ブロック内の各値をローカルエンコードスケールでスケーリングし、FP4 に量子化して保存します。GEMM には FP4 の値とともに、FP8 のローカルデコードスケールと FP32 のグローバルデコードスケールも併せて格納します。
ここで重要なのは、この量子化レシピを PyTorch で記述する場合、ビット操作やビットパッキング演算を工夫して行う必要があるということです。以下の疑似コードは、その関数がどのような見た目になるかを示しています:
function QUANT_NVFP4(x):
assert last_dim(x) % 16 == 0
x_blocks <- reshape x into (..., N/16, 16) as FP32
if global_scale not provided:
global_scale <- (FP4_AMAX * FP8_AMAX) / max(|x_blocks|)
s_decb <- max(|x_blocks| over last dim) / FP4_AMAX
xs <- clamp(s_decb * global_scale, ±FP8_AMAX)
xs <- cast xs to FP8
s_encb <- global_scale / xs
s_encb <- expand s_encb to shape (..., N/16, 1)
x_scaled <- x_blocks * s_encb
xq <- cvt_1xfp32_2xfp4(x_scaled)
xs_tiled <- tile_scales_128x4_to_32x16(xs)
return xq, xs_tiled, global_scale
このヘルパー関数 cvt_1xfp32_2xfp4 は以下のように見えます:
thresholds = [
(5.0, 0b0110), (3.5, 0b0101), (2.5, 0b0100), (1.75, 0b0011), (1.25, 0b0010), (0.75, 0b0001), (0.25, 0b0000),
]
function cvt_1xfp32_2xfp4(x):
sign_bit = MSB(x)
x_abs = abs(x)
mag_code = 0b0111
for i, (threshold, code) in enumerate(thresholds):
if i is even:
if x_abs <= threshold:
mag_code = code
else:
if x_abs < threshold:
mag_code = code
# pack 8 FP4 values into one 32-bit word
fp4 = (sign_bit << 3) | mag_code
packed = 0
for j in 0..7:
packed |= fp4[j] << (4 * j)
return reinterpret_as_fp4_dtype(packed)
もしこれを Triton カーネルとして記述する場合、カーネル内で Triton テンソルに対してビット操作演算を使用することも可能です。しかし、より賢明な方法として、以下の PTX 命令を使用して float32 を float4 e2m1 に変換することができます:
cvt.rn.satfinite{.relu}.e2m1x2.f32 d, a, b;
この命令は、2 つの float32 値を 8 ビット(つまり 1 つの uint8 または int8 値)にパッキングされた 2 つの float4 e2m1 値に変換します。この要素ごとの演算を Triton カーネル内で使用することで、複数のビット操作演算を使用する必要がなくなります。実際、Flashinfer や TensorRT-LLM などのライブラリの量子化カーネルでは、float32 値の変換と量子化にこの命令が使用されています。PTX ドキュメントによると:
e2m1x2 データ形式への変換を行う際、目的演算子 d は .b8 型となります。2 つの .f32 入力値を .e2m1x2 形式に変換する場合、各入力は指定された形式に変換され、変換後の値は目的演算子 d にパッキングされます。具体的には、入力 a から変換された値が d の上位 4 ビットに格納され、入力 b から変換された値が d の下位 4 ビットに格納されます。
この命令を Triton カーネルで使用する場合の例は以下の通りです:
x_e2m1x2 = tl.inline_asm_elementwise(
asm="""
{
.reg .b8 tmp<4>;
cvt.rn.satfinite.e2m1x2.f32 tmp0, $5, $1;
cvt.rn.satfinite.e2m1x2.f32 tmp1, $6, $2;
cvt.rn.satfinite.e2m1x2.f32 tmp2, $7, $3;
cvt.rn.satfinite.e2m1x2.f32 tmp3, $8, $4;
mov.b32 $0, {tmp0, tmp1, tmp2, tmp3};
}
""",
constraints=(
"=r," # 出力 d = $0
"r,r,r,r," # 下位ビット b = $1-$4
"r,r,r,r" # 上位バイト a = $5-$8
),
args=x_blocks_reshaped_split,
dtype=tl.int8,
is_pure=True,
pack=4,
)
ここで、Triton は 32 ビットレジスタを扱うため、mov.b32 命令を使用して tmp0-3 で与えられる 4 つの 8 ビット値を 1 つの 32 ビットレジスタにパッキングしています。その後、最終的に出力を int8 データ型に変換します。これが、ここで pack の値が意図的に 4 に設定されている理由です。
100 行未満のコードで書かれたこの注入された PTX Triton カーネルと、2000 行を超える Flashinfer や TensorRT-LLM などのライブラリの量子化カーネルを比較すると、以下の結果が得られます。
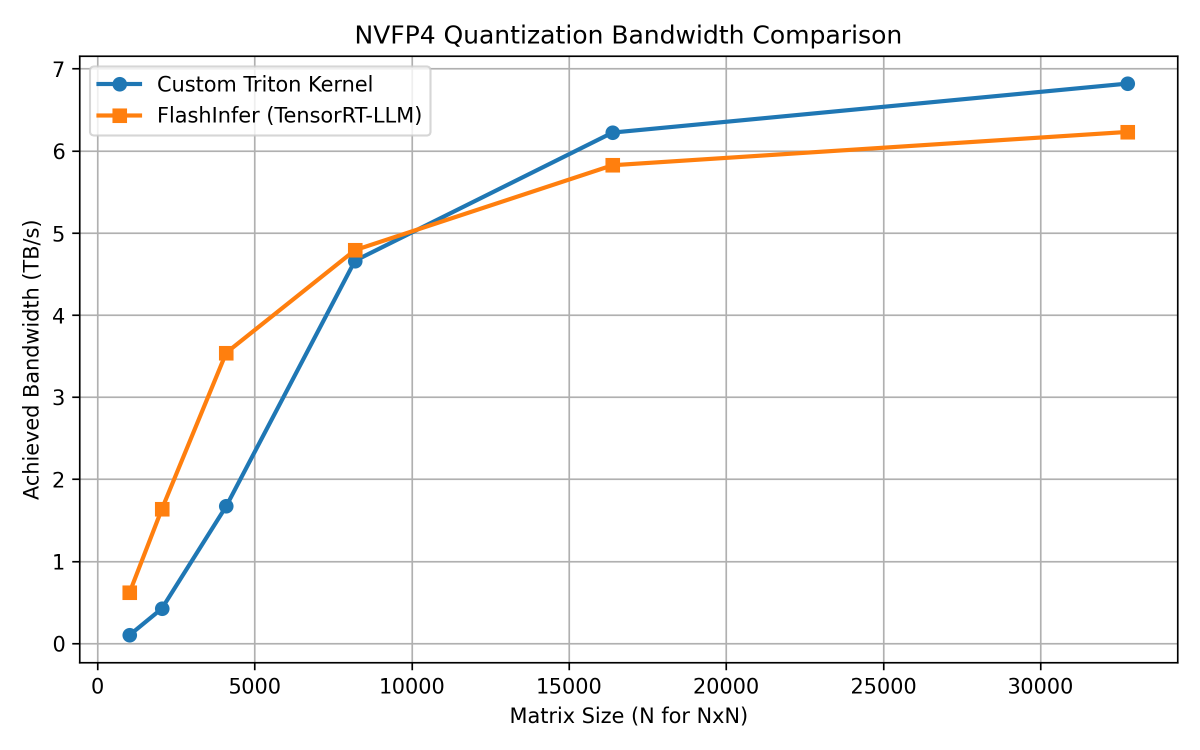
ご覧の通り、B200 で比較した場合、Triton カーネルは最適化された CUDA カーネルと肩を並べる性能を発揮します。より小さな形状では CUDA カーネルの方が高速ですが、より大きな形状では Triton カーネルが CUDA カーネルを上回り、メモリ帯域幅でほぼ 7 TB/s に達します。
この例は、インライン PTX を用いたわずか 100 行未満の注意深く設計された Triton カーネルによって、最適化された CUDA カーネルと同等の性能、あるいは場合によってはそれを超える性能を、少なくとも GEMM ベースではないワークロードにおいて達成できることを示しています。とても素晴らしい不是吗?
結びの言葉
Triton におけるインライン要素演算 PTX は、非常に優れたバランス点に到達します。一方では、Python の内部で全てを維持できます:最初に Triton を選んだ理由である生産性、組み合わせ可能性、そして迅速な反復です。他方では、ビットパッキングやベクトル化された f16x2 演算、近似逆数計算、あるいは今日では Triton が直接公開していない cvt.e2m1x2.f32 などの特殊変換操作など、命令選択に対する外科的な制御力を取り戻すことができます。
ただし、これは万能薬ではありません。無視できないいくつかのトレードオフを伴います:
正しさの責任はあなたにあります:レジスタ制約、パッキング係数、データ型は完璧に一致させる必要があります。
デバッグが困難になります:誤った指定された制約は、静かに間違った結果を生み出す可能性があります。
抽象化の漏れが発生します:あなたのカーネルはアーキテクチャ依存となり、ベンダー間や将来の NVIDIA アーキテクチャ間での移植性を確保するには、PTX(Parallel Thread Execution)を見直す必要があるかもしれません。
要素ごとのセマンティクスに制限されます:共有メモリも明示的な同期もワープレベルの制御も利用できません。
最大限の柔軟性が必要で、メモリアーキテクチャ全体への完全な制御やワープレベルの高度な操作などが求められる場合は、CUDA や NVIDIA の CuTe DSL(Domain Specific Language)に降りるのが依然として適切なツールです。実際には、最も効果的なアプローチはハイブリッド型であることが多く、カーネルの大部分をクリーンな Triton で記述し、PTX を本当に重要な箇所にのみ注入します。このように使用することで、インライン要素ごとの PTX は Triton を「高レベル DSL」から、手動最適化された CUDA と競合しつつも Python でコードを書き続けることができる驚くほど鋭い低レベルツールへと変えることができます。
お読みいただきありがとうございます!
原文を表示
Triton is a DSL (Domain-Specific Language) which makes it deceptively easy to write fast GPU kernels in Python since it abstracts all the nuances of writing a pure GPU kernel from scratch, such as manual memory hierarchy handling, synchronization, and low-level launch configuration while still producing highly optimized GPU code.
However, the moment you want exact control over the device specific assembly instructions that a Triton kernel might not generate like packing bits, using special/faster instructions, and so on, you hit a wall. This wall is usually where people drop down to a lower level where one can write any kind of assembly instruction they want.
To overcome this wall, Triton provides a middle ground API: inline elementwise assembly
In this blog post, I'll show how Triton lets you inject elementwise GPU assembly instructions without ever leaving the comfort of Python and when this approach is actually worth it. Let's first understand, in short, what a Triton kernel actually compiles to. Note, this post will focus purely on NVIDIA GPUs where the device specific assembly is also called PTX.
From Python to PTX
Triton lowers from Python to device specific assembly through many lowering stages. A brilliant article by Kapil Sharma summarizes what exactly happens during a Triton kernel compilation:
Python kernels are parsed into a high-level Triton IR representing tensor and kernel semantics.
The IR is progressively lowered through MLIR dialects (Triton -> TritonGPU -> TritonNVIDIAGPU), where domain-specific optimizations such as tiling, vectorization, CSE, and constant folding are applied.
The optimized Triton IR is lowered to LLVM IR, enabling further compiler optimizations.
LLVM IR is translated to PTX, NVIDIA’s GPU intermediate representation.
PTX is JIT-compiled by NVIDIA’s toolchain into a CUBIN, which is executed on the GPU.
The image below gives a visual representation of what happens during Triton kernel compilation:
imageNext, let's see an example of injecting a single elementwise PTX instruction within a Triton kernel.
Example 1: single instruction (rcp)
Triton provides us with the inline_elementwise_asm function through which we can inject a PTX instruction that works in an elementwise manner on some given arguments. The signature of the function is as follows:
triton.language.inline_asm_elementwise(asm: str, constraints: str, args: Sequence, dtype: dtype | Sequence[dtype], is_pure: bool, pack: int, _semantic=None)
I'll explain the arguments this function takes throughout this blog post but let's focus on the following example.
Suppose, we are given two float32 matrices A and B of shape (M, N) and we want to compute another matrix C of the same shape where:
ci = ai / bi
This operation is readily available in Triton for the float32 data type. However, we can compute the result in another way too:
ci = ai * (1 / bi)
Here (1 / bi) is just the reciprocal of the bi value. Keep this in mind.
A normal Triton kernel, without any inline PTX, for this operation will look something like:
@triton.jit
def _kernel(
a_ptr, b_ptr, c_ptr, N,
BLOCK_SIZE: tl.constexpr = 1024
):
pid = tl.program_id(0)
offs = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offs < N
a = tl.load(a_ptr + offs, mask=mask, other=0.0)
b = tl.load(b_ptr + offs, mask=mask, other=1.0)
c = a / b
tl.store(c_ptr + offs, c, mask=mask)
The host function for this kernel will be:
def div(a: torch.Tensor, b: torch.Tensor, version=1):
numel = a.numel()
out = torch.empty_like(a)
grid = lambda meta: (triton.cdiv(numel, meta['BLOCK_SIZE']), )
K = _kernelgrid
return out, K
We can inspect the Triton compiled PTX of this kernel by dumping K.asm['ptx'] in a file. When we do that, we see Triton uses the following instruction to compute ai / bi in the PTX:
div.full.f32 d, a, b;
Here, the value ai is stored in the 32-bit register a, value bi is stored in the 32-bit register b, and the result in d.
When we look at the PTX docs we find an instruction that computes a fast approximate reciprocal of a given float32 value:
rcp.approx{.ftz}.f32 d, a;
So, if we want, we can compute a fast approximate reciprocal of the bi value and then multiply the result with the ai value. To do this, we need to update the kernel as follows:
@triton.jit
def _kernel(
a_ptr, b_ptr, c_ptr, N,
BLOCK_SIZE: tl.constexpr = 1024
):
pid = tl.program_id(0)
offs = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask = offs < N
a = tl.load(a_ptr + offs, mask=mask, other=0.0)
b = tl.load(b_ptr + offs, mask=mask, other=1.0)
(multiplier,) = tl.inline_asm_elementwise(
asm="rcp.approx.ftz.f32 $0, $1;",
constraints="=r,r",
args=[b],
dtype=[tl.float32],
is_pure=True,
pack=1
)
c = a * multiplier
tl.store(c_ptr + offs, c, mask=mask)
In essence, this is a map over the elements of a Triton tensor where the function is inline PTX.
asm: This is the string instruction which will be used over the elements of a tensor. To access the elements as 32-bit registers, we can use the placeholders $0, $1, $2 and so on.
constraints: This is a string which tells Triton the number of output and input registers based on the number of input and output tensors and dtypes respectively. To get more idea, take a look at ASM LLVM format documentation. Output registers are identified with =r and input registers are r.
args: The input Triton tensors, whose values are passed to the inline assembly block as 32-bit registers.
dtype: The element type(s) of the returned tensors. It is on the programmer to correctly configure the output registers and their dtypes to avoid incorrect results.
is_pure: If true, the Triton compiler assumes the ASM block has no side-effects and the inline ASM works as it is.
pack: Each invocation of the inline asm processes pack elements at a time. Exactly which set of inputs a block receives is unspecified. Input elements of size less than 4 bytes (32-bits) are packed into 4-byte (32-bit) registers.
In this example, since we are only dealing with float32 dtype, we don't need any packing and we only handle one element at a time.
When we run both the versions, we see no difference in the outputs but when we inspect the PTX generated by Triton here's what we see:
PTX generated by version 1
div.full.f32 %r33, %r1, %r17;
div.full.f32 %r34, %r2, %r18;
div.full.f32 %r35, %r3, %r19;
div.full.f32 %r36, %r4, %r20;
div.full.f32 %r37, %r9, %r25;
div.full.f32 %r38, %r10, %r26;
div.full.f32 %r39, %r11, %r27;
div.full.f32 %r40, %r12, %r28;
Execution time: 0.12382 ms
PTX generated by version 2
rcp.approx.ftz.f32 %r33, %r34;
rcp.approx.ftz.f32 %r35, %r36;
rcp.approx.ftz.f32 %r37, %r38;
rcp.approx.ftz.f32 %r39, %r40;
rcp.approx.ftz.f32 %r41, %r42;
rcp.approx.ftz.f32 %r43, %r44;
rcp.approx.ftz.f32 %r45, %r46;
rcp.approx.ftz.f32 %r47, %r48;
mul.f32 %r49, %r33, %r1;
mul.f32 %r50, %r35, %r2;
mul.f32 %r51, %r37, %r3;
mul.f32 %r52, %r39, %r4;
mul.f32 %r53, %r41, %r9;
mul.f32 %r54, %r43, %r10;
mul.f32 %r55, %r45, %r11;
mul.f32 %r56, %r47, %r12;
Execution time: 0.12375 ms
Infact, the second version is a bit faster than the first one! Apart from that, injecting elementwise PTX gives us a lot more flexibility when we need to play with bit packing, special instructions, and so on than regular Triton.
Example 2: packing and multiple instructions
Suppose we have two float16 arrays A and B of shape (N,) and we want to compute C and D as follows:
ci = ai * bi + 1.0
ci = clamp(ci, 0.0, 6.0)
di = ci * ci
Since the dtype here is float16 we can use the elementwise assembly function to handle 2 elements at once. Triton will implicitly pack two float16 values in one 32-bit register. Along with this, we can use the following f16x2 PTX instructions to compute C and D:
fma.rnd{.ftz}{.sat}.f16x2 d, a, b, c;
max{.ftz}{.NaN}{.xorsign.abs}.f16x2 d, a, b;
mul{.rnd}{.ftz}{.sat}.f16x2 d, a, b;
The normal and PTX injected kernels look like:
@triton.jit
def kernel_fp16_normal(A, B, C, D, BLOCK: tl.constexpr):
offs = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
a = tl.load(A + offs)
b = tl.load(B + offs)
y = a * b + 1.0
y = tl.clamp(y, 0.0, 6.0)
tl.store(C + offs, y)
tl.store(D + offs, y * y)
and,
@triton.jit
def kernel_fp16_pack2(A, B, C, D, BLOCK: tl.constexpr):
offs = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
a = tl.load(A + offs)
b = tl.load(B + offs)
(c, d) = tl.inline_asm_elementwise(
asm="""
{
.reg .b32 tmp<3>;
mov.b32 tmp0, 0x3C003C00; // 1.0
mov.b32 tmp1, 0x00000000; // 0.0
mov.b32 tmp2, 0x46004600; // 6.0
// y = a * b + 1
fma.rn.f16x2 $0, $2, $3, tmp0;
// clamp
max.f16x2 $0, $0, tmp1;
min.f16x2 $0, $0, tmp2;
// d = y * y
mul.rn.f16x2 $1, $0, $0;
}
""",
constraints="=r,=r,r,r",
args=[a, b],
dtype=(tl.float16, tl.float16),
is_pure=True,
pack=2,
)
tl.store(C + offs, c)
tl.store(D + offs, d)
Here, we pass the two Triton tensors as arguments. We use the value of pack as 2 so that Triton can pack two float16 elements in one 32-bit register which we can use with the f16x2 instruction. For the outputs, Triton also unpacks the 32-bit register containing the f16x2 value (32-bit register) to the given output dtype.
The below image shows how packing elements will work with different dtypes:
imageWhen we compare the outputs, we see no difference but when we look at the effective memory bandwidth (in GB/s) achieved by both the kernels, we get:
Normal Triton : 6502.08 GB/s
Inline PTX f16x2: 6514.12 GB/s
The second kernel that uses inline PTX seems to be 12 GB/s faster than the first kernel in this example!
In the above toy examples, Triton already provides support for the operations we want. However, let's look at a real-world example now to understand that we can use PTX instructions even when Triton does not provide an explicit support for them out of the box.
Example 3: NVFP4 quantization on Blackwell GPUs
NVFP4 is a block-scaled quantization recipe that quantizes a given matrix X of shape (M, N) to FP4 e2m1 dtype. Given the narrow precision of FP4, to mitigate the quantization error we use two scale factors here: Global tensorwise scale (with dtype fp32) and Local block scale (with dtype FP8 e4m3). The block scale size here is 16 i.e. every consecutive 16 elements share a local scaling factor.
I won't be going into the details of how exactly to quantize a matrix X of shape (M, N) to NVFP4 i.e. fp4 e2m1 dtype but the gist is:
Compute the global absolute maximum value across the tensor (amax_x).
Compute the global encode scale as (6 × 448) / amax_x, and store its inverse as the global decode scale in FP32.
Split the tensor into contiguous blocks matching Tensor Core granularity.
For each block, compute the block absolute maximum (amax_b) and the local decode scale as amax_b / 6.
Multiply the local decode scale by the global encode scale and quantize it to FP8 (E4M3) using round-to-nearest-even.
Recover the effective local encode scale by inverting the quantized FP8 decode scale and applying the global decode scale.
Scale each value in the block using the local encode scale and quantize it to FP4; store FP4 values along with FP8 local decode scales and FP32 global decode scale for GEMM.
The thing is: if we were to write this quantization recipe in terms of PyTorch we would have to play around with bit manipulation and bit packing operations. The below pseudocode shows how the function would look like:
function QUANT_NVFP4(x):
assert last_dim(x) % 16 == 0
x_blocks <- reshape x into (..., N/16, 16) as FP32
if global_scale not provided:
global_scale <- (FP4_AMAX * FP8_AMAX) / max(|x_blocks|)
s_decb <- max(|x_blocks| over last dim) / FP4_AMAX
xs <- clamp(s_decb * global_scale, ±FP8_AMAX)
xs <- cast xs to FP8
s_encb <- global_scale / xs
s_encb <- expand s_encb to shape (..., N/16, 1)
x_scaled <- x_blocks * s_encb
xq <- cvt_1xfp32_2xfp4(x_scaled)
xs_tiled <- tile_scales_128x4_to_32x16(xs)
return xq, xs_tiled, global_scale
The helper function cvt_1xfp32_2xfp4 here looks like:
thresholds = [
(5.0, 0b0110), (3.5, 0b0101), (2.5, 0b0100), (1.75, 0b0011), (1.25, 0b0010), (0.75, 0b0001), (0.25, 0b0000),
]
function cvt_1xfp32_2xfp4(x):
sign_bit = MSB(x)
x_abs = abs(x)
mag_code = 0b0111
for i, (threshold, code) in enumerate(thresholds):
if i is even:
if x_abs <= threshold:
mag_code = code
else:
if x_abs < threshold:
mag_code = code
# pack 8 FP4 values into one 32-bit word
fp4 = (sign_bit << 3) | mag_code
packed = 0
for j in 0..7:
packed |= fp4[j] << (4 * j)
return reinterpret_as_fp4_dtype(packed)
If we were to write a Triton kernel for this, we can use bit manipulation operations on the Triton tensors within the kernel as well. But, we can be smarter and use the following PTX instruction to convert float32 to float4 e2m1:
cvt.rn.satfinite{.relu}.e2m1x2.f32 d, a, b;
This instruction converts two float32 values into two float4 e2m1 values packed into 8-bits i.e. one uint8 or int8 value. We can use this elementwise operation within the Triton kernel to eliminate the need to use more than one bit manipulation operations. Infact, the quantization kernels in libraries like Flashinfer and TensorRT-LLM use this instruction to convert and quantize the float32 values. From the PTX docs:
When converting to .e2m1x2 data formats, the destination operand d has .b8 type. When converting two .f32 inputs to .e2m1x2, each input is converted to the specified format, and the converted values are packed in the destination operand d such that the value converted from input a is stored in the upper 4 bits of d and the value converted from input b is stored in the lower 4 bits of d.
The usage of this instruction in a Triton kernel looks like:
x_e2m1x2 = tl.inline_asm_elementwise(
asm="""
{
.reg .b8 tmp<4>;
cvt.rn.satfinite.e2m1x2.f32 tmp0, $5, $1;
cvt.rn.satfinite.e2m1x2.f32 tmp1, $6, $2;
cvt.rn.satfinite.e2m1x2.f32 tmp2, $7, $3;
cvt.rn.satfinite.e2m1x2.f32 tmp3, $8, $4;
mov.b32 $0, {tmp0, tmp1, tmp2, tmp3};
}
""",
constraints=(
"=r," # output d = $0
"r,r,r,r," # low bits b = $1-$4
"r,r,r,r" # high bytes a = $5-$8
),
args=x_blocks_reshaped_split,
dtype=tl.int8,
is_pure=True,
pack=4,
)
Here, we pack the four 8-bit values (given by tmp0-3) into one 32-bit register by using the mov.b32 instruction since Triton works with 32-bit registers. Then finally, it converts the output to int8 dtype. This is why the value of pack here is deliberately chosen to be 4.
When we compare this injected PTX Triton kernel that has less than 100 lines of code, to the quantization kernel of libraries like Flashinfer and TensorRT-LLM that has more than 2000 lines of code, we get the following result:
imageAs you can see, the Triton kernel goes hand-in-hand with the optimized CUDA kernel when compared on a B200. For smaller shapes, the CUDA kernel is faster than Triton while for larger shapes, the Triton kernel outshines the CUDA kernel and almost touches 7 TB/s memory bandwidth.
This example goes to show that in less than 100 lines of carefully crafted Triton kernel with inline PTX, we can get to the same performance of an optimized CUDA kernel and sometimes even beat it, atleast for non-GEMM based workloads. Pretty cool, right?
Closing Thoughts
Inline elementwise PTX in Triton hits a really sweet spot. On one hand, you keep everything inside Python: the productivity, composability, and rapid iteration that made you choose Triton in the first place. On the other hand, you regain surgical control over instruction selection whether that’s bit packing, vectorized f16x2 math, approximate reciprocals, or special conversion operations like cvt.e2m1x2.f32 that Triton doesn’t expose directly today.
That said, this is not a silver bullet. It comes with some not-so-ignorable tradeoffs:
You are responsible for correctness: register constraints, packing factors, and dtypes must line up perfectly.
Debugging is harder: mis-specified constraints can silently produce wrong results.
The abstraction leaks: your kernel becomes architecture-aware, and portability across vendors or even future NVIDIA architectures may require revisiting the PTX.
You are limited to elementwise semantics: no shared memory, no explicit synchronization, no warp-level control.
If you need maximum flexibility, full control over memory hierarchies, warp-level gymnastics and so on, then dropping down to CUDA or NVIDIA’s CuTe DSL is still the right tool for the job. In practice, the most effective approach is often hybrid: write the bulk of the kernel in clean Triton, and inject PTX only where it truly matters. When used this way, inline elementwise PTX can turn Triton from a “high-level DSL” into a surprisingly sharp low-level tool, one that lets you compete with hand-optimized CUDA while still writing Python.
Thanks for reading!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み