LLMを活用したAmazon商品リストの改善
Amazonは、従来の専門機械学習モデルに加えて大規模言語モデル(LLM)を導入し、数百万規模の商品カタログの品質管理(正確性・完全性・一貫性の向上)を効率化する継続的改善ワークフローを構築した。
キーポイント
従来手法の限界とLLM導入の背景
Amazonは従来、商品カテゴリーごとに特化した機械学習モデルで商品データの品質管理を行っていたが、属性が複雑・微妙な商品についてはモデルの適用が難しく、手動レビューが必要だった。
LLMによるカタログ品質管理の適応
LLMはカタログの構造と語彙に適応できるため、プロンプトチューニングを通じて商品属性のセマンティクスと値を学習し、品質管理プロセスに統合されている。
継続的カタログ改善ワークフローの構築
商品タイプと属性値でカタログ全体を要約・整理し、LLMが正確な商品記述を生成・修正できる知識基盤を構築することで、大規模な品質向上を実現している。
実用規模での効果
このアプローチにより、Amazonストア全体の規模で商品属性の修正・更新が行われ、商品リストの正確性、信頼性、一貫性が向上している。
影響分析・編集コメントを表示
影響分析
この記事は、LLMが大規模eコマースプラットフォームの基盤業務に実装され、従来の専門AIモデルを補完・拡張する実用的なケースを示している。LLMの適応性と汎用性を活かした企業内業務効率化の先進例として、AI応用の新たな方向性を示唆する。
編集コメント
LLMの実ビジネス応用例として、技術の成熟度と実用性の高さを示す好例。大企業における内部業務効率化へのAI導入の具体的手法が詳細に説明されている。
タイトル: LLM(大規模言語モデル)を活用したAmazon商品リストの改善
LLM(大規模言語モデル)を活用したAmazon商品リストの改善
大規模言語モデル(LLM)により、製品カタログの正確性、信頼性、一貫性が大規模に向上しています。
会話型AI
Abhishek Agrawal November 28, 03:25 PM November 28, 03:25 PM Amazonのオンラインカタログには数億点の商品が掲載されており、毎日数百万件の商品リストが追加・編集されています。商品データ(画像、タイトル、説明、使用上の推奨事項)は、買い物客が求める商品を迅速に見つけられるよう、完全で正確で魅力的なものでなければなりません。
商品データの品質を確保するため、Amazonは従来、パティオ家具からヘッドフォンまで、独立した商品カテゴリーごとに最適化された専門的な機械学習(ML)モデルに依存してきました。これらのモデルは、情報の追加・更新、不正確な箇所の特定、情報の統合、テキストの多言語翻訳、そして第三者ソースからのデータ取り込みを行っています。
このようなモデルは、サイズ、形状、色、素材などで十分に記述できるディナープレートのように、属性リストが小さく構造化された商品で最も効果を発揮します。しかし、カタログには、はるかに複雑で微妙なニュアンスを持つ属性を持つ商品も多く、特別に訓練されたMLモデルや手動レビューが必要となります。
商品リストの品質が買い物客のニーズを満たすことを確実にするため、私たちは適応性と汎用性に優れた大規模言語モデル(LLM)に着目しました。カタログからの属性データをプロンプト(指示)として与えると、LLMはカタログの構造と語彙に適応し、品質管理プロセスに効果的に統合できるようになります。これらのカタログAIソリューションは、Amazonストア全体の規模で商品属性を修正・更新しています。
プロンプトチューニング
LLMをカタログ品質管理の課題に適応させるには、製品カタログに関する知識をLLMに与える必要がありました。言い換えれば、数百万点の製品と製品タイプを最も正確に記述する属性セマンティクスと値を、体系的に導入する必要があったのです。しかし、その前にまずその知識体系を構築する必要がありました。このプロセスは、製品タイプと属性値によってカタログ全体を要約・整理することから始まります。これは、非常に大きく複雑なスプレッドシートの行をグループ化する作業に、いくらか似ています。
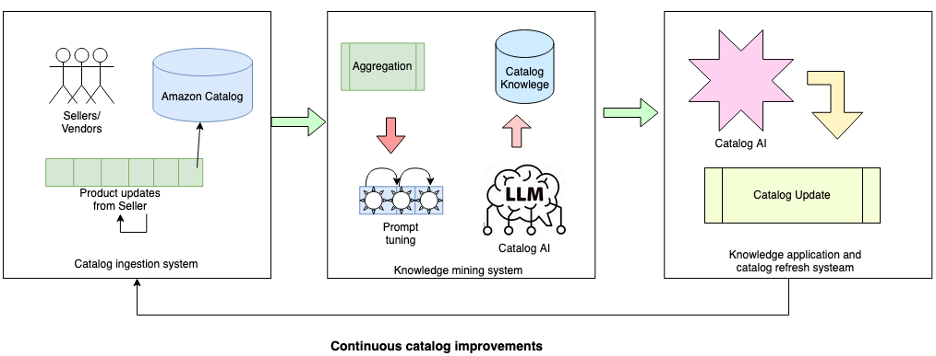 image Amazonの新しい継続的カタログ改善ワークフロー。この再編成により、様々な製品タイプに対する出品者提供の属性値の範囲、そして重要なことに、それらの値がどのくらいの頻度で、どこに出現するかの統計を把握できます。これらの統計は、値の正確性を判断する上でかなり優れた指標となります。例えば、あるカテゴリーでより多くの製品が特定の属性値を使用している場合、または特定の属性値を持つ製品が顧客により頻繁に閲覧されている場合、その属性は正しいと信頼できます。ワイヤレスヘッドフォンの属性が「Bluetooth」、「BT」、「BT 5.1」、「Bluetooth version 5.1」などと表記される可能性があっても、統計は「Bluetooth」がLLMに教えるべき最適な候補であることを示してくれるでしょう。
image Amazonの新しい継続的カタログ改善ワークフロー。この再編成により、様々な製品タイプに対する出品者提供の属性値の範囲、そして重要なことに、それらの値がどのくらいの頻度で、どこに出現するかの統計を把握できます。これらの統計は、値の正確性を判断する上でかなり優れた指標となります。例えば、あるカテゴリーでより多くの製品が特定の属性値を使用している場合、または特定の属性値を持つ製品が顧客により頻繁に閲覧されている場合、その属性は正しいと信頼できます。ワイヤレスヘッドフォンの属性が「Bluetooth」、「BT」、「BT 5.1」、「Bluetooth version 5.1」などと表記される可能性があっても、統計は「Bluetooth」がLLMに教えるべき最適な候補であることを示してくれるでしょう。
属性統計は多くの属性で有効ですが、すべてに機能するわけではありません。特に、より微妙なニュアンスが関わる場合です。一部の属性における課題の一つが「粒度」、つまり製品をどれだけ詳細に記述するかです。例えば、外科用器具の属性値が「ステンレス鋼」または「440ステンレス鋼」である場合が挙げられます。後者の方が粒度が細かい(詳細な)記述です。「ステンレス鋼」の方が一般的な属性値であっても、「440ステンレス鋼」という情報を排除したくはありません。
このような詳細な粒度をカタログに保持する方法が、プロンプトチューニングと呼ばれる反復プロセスです。これは、汎用LLMを、それが使用される環境に存在する特定のスキーマ、ルール、用語に繰り返し触れさせることで行います。LLMに粒度の概念を追加するため、「返される値は、候補リスト内の値の粒度(詳細さ)と一致しなければならない」といったフレーズでプロンプトを与えるかもしれません。また、LLMにその応答の背後にある推論を求めると、その性能が向上する傾向があるだけでなく、エンジニアがプロンプトをさらに微調整するための洞察も得られます。
プロンプトチューニングは、製品説明における他の微妙な違いを扱う方法でもあります。例えば、「men's shirt」と「men shirt」のような表現の一貫性を確保することや、テレビの「4K」という表記よりも情報量の多い「4K UHD HDR」といった、意味のある値表現を維持することが含まれます。
何度にもわたるプロンプトチューニングを経て、LLMはカタログ全体を処理する準備が整います。そこでは主に3つのタスクを実行します:(1) 標準的な属性値を認識して正確性を確立すること、(2) 標準値の代替表現や同義語を収集すること、(3) 誤ったまたは無意味なデータエントリを検出することです。
この新しいプロセスにより、出品者によって提供された最新の値がより迅速に(数日以内に)カタログに反映されることが保証され、人的レビューに要する数千時間が節約されます。さらに、LLMを活用することで、監視・更新可能な言語の数を増やすこともできました。私たちのLLMベースの手法により、品質管理プロセスをカタログの最も辺境な領域まで拡張することが可能になりました。これは、以前のプロセスではコスト的に実行が困難だった領域です。
研究分野: 会話型AI
タグ: 大規模言語モデル(LLM)
原文を表示
Using LLMs to improve Amazon product listings
Large language models are increasing the accuracy, reliability, and consistency of the product catalogue at scale.
Conversational AI
Abhishek Agrawal November 28, 03:25 PM November 28, 03:25 PM Amazons online catalogue contains hundreds of millions of products, and millions of product listings are added and edited daily. Product data images, titles, descriptions, and usage recommendations must be complete, accurate, and appealing so that shoppers can find the products they are seeking quickly.
To ensure the quality of product data, Amazon has traditionally relied on specialized machine learning (ML) models, each optimized for an independent product category, from patio furniture to headphones. These models add or update information, identify inaccuracies, consolidate information, translate text into different languages, and incorporate data from third-party sources.
Such models work best for products with smaller, structured lists of attributes dinner plates, for instance, which are well described by size, shape, color, and material. But there are many products in the catalogue with attributes that are much more complicated or nuanced that require specially trained ML models or manual review.
To ensure that the quality of product listings meets shopper's needs, weve turned to more adaptable and generalizable large language models (LLMs). When prompted with attribute data from the catalogue, LLMs adapt to the catalogue structures and vocabulary, allowing them to be usefully integrated into the quality control process. These catalogue AI solutions are correcting and updating product attributes at the scale of the Amazon Stores.
Prompt tuning
To adapt an LLM to the challenge of catalogue quality control, we needed to expose it to knowledge about the product catalogue. In other words, we needed to systematically introduce it to the attribute semantics and values that most accurately describe millions of products and product types. But first we needed to build that knowledge. That process starts with summarizing and organizing the entire catalogue by product type and attribute value, similar, in some ways, to grouping the rows of a very large, very complex spreadsheet.
image Amazon's new continuous catalogue-improvement workflow. Through this reorganization, we can see the range of seller-provided attribute values for various product types and, importantly, the statistics on how often and where those values appear. These statistics are fairly good indicators of a values correctness. If a higher number of products in a category uses a certain attribute value, for instance, or if products with a certain attribute value are more frequently viewed by customers, we can trust that the attribute is correct. Wireless headphones might have attributes that could appear as Bluetooth, BT, BT 5.1, or Bluetooth version 5.1, but the statistics will say that Bluetooth is the best candidate to use to inform our LLM.
While attribute statistics work well for many attributes, they wont work for all of them, especially when theres more nuance involved. One challenge with some attributes is their granularity, or how precisely they describe their products. An example is a surgical instrument with an attribute that might have the value stainless steel or 440 stainless steel. The second is more granular; even though stainless steel is a more likely attribute value, we dont want to eliminate 440 stainless steel.
The way to keep such granularity in the catalogue is through an iterative process called prompt tuning, wherein general-purpose LLMs are exposed to particular schemas, rules, and terms that appear in the environment where they will be used. To add granularity to our LLM, we might prompt it with the phrase The values returned must match the granularity, or broadness, of the values in the candidate list. We can also ask an LLM for the reasoning behind its response, since this tends to improve its performance, as well as giving engineers insights that help them further fine-tune their prompts.
Prompt tuning is also how we handle other nuances of product description. These include ensuring consistency of representation, such as mens shirt versus "men shirt, and maintaining meaningful value representations, such as 4K UHD HDR for a TV, which is more informative than 4K.
After many rounds of prompt tuning, the LLM is ready to be exposed to the entire catalogue, where it performs three main tasks: recognizing standard attribute values, to establish correctness; collecting alternative representations of standard values, or synonyms; and detecting erroneous or nonsensical data entries.
The new process ensures that the latest seller values are included in the catalogue more quickly (within days) and saves thousands of hours in human reviews. Whats more, weve been able to use the LLM to increase the number of languages we can monitor and update. Our LLM-based method allows us to extend the quality control process into the furthest reaches of the catalogue, which would have been cost prohibitive to explore with our prior process.
Research areas: Conversational AI
Tags: Large language models (LLMs)
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み