Amazon Nova 2 Sonicでリアルタイム会話型ポッドキャストを構築
AWSは、低遅延で人間のような会話を実現する音声理解・生成モデル「Amazon Nova 2 Sonic」を発表し、リアルタイムの自動ポッドキャスト生成など音声ファーストアプリケーションの構築を可能にした。
キーポイント
Amazon Nova 2 Sonicの概要
人間のような自然な会話を低遅延で実現する最先端の音声理解・生成モデルであり、ストリーミング音声理解、指示追従、ツール呼び出し、音声とテキストのクロスモーダル相互作用を提供する。
自動ポッドキャスト生成の実証
記事では、2人のAIホスト間で任意のトピックについて魅力的な会話を生成する自動ポッドキャストジェネレーターの構築手順を紹介し、Nova Sonicのストリーミング機能、ステージ対応コンテンツフィルタリング、リアルタイム音声生成を実証している。
主要な機能と仕様
ストリーミング音声理解、指示追従、ツール呼び出し、クロスモーダル相互作用、7言語サポート(英語、フランス語、イタリア語、ドイツ語、スペイン語、ポルトガル語、ヒンディー語)、最大100万トークンのコンテキストウィンドウを備える。
Amazon Bedrockとの統合
Amazon Nova 2 SonicはAmazon Bedrockを通じてアクセス可能であり、Guardrails、Agents、マルチモーダルRAG、Knowledge Basesなどの主要機能と統合され、プラットフォーム全体でのシームレスな相互運用性を実現する。
リアクティブストリーミングパイプライン
RxPyを使用したリアクティブアーキテクチャにより、Amazon Nova Sonicからの音声チャンクとテキストトークンをリアルタイムで処理し、完全な応答を待たずに即時フィードバックを提供する。
ステージ対応コンテンツフィルタリング
Amazon Nova 2 Sonicが生成するSPECULATIVE(予備的)とFINAL(完成)の複数ステージを監視し、FINALステージのコンテンツのみをキャプチャすることで、重複や予備的な音声を除去し、クリーンで自然な出力を実現する。
フィルタリングの3段階
コンテンツの品質を確保するため、中断マーカーの除去、テキストの重複排除、オーディオハッシュによる重複排除の3段階でフィルタリングを行う。
重要な引用
Amazon Nova 2 Sonic is a state-of-the-art speech understanding and generation model that delivers natural, human-like conversational AI with low latency and industry-leading price-performance.
It provides streaming speech understanding, instruction following, tool invocation, and cross-modal interaction that seamlessly switches between voice and text.
Amazon Nova 2 Sonic processes speech input and delivers speech output and text transcriptions, creating human-like conversations with rich contextual understanding.
The model is accessible through Amazon Bedrock and can be integrated with key Amazon Bedrock features, including Guardrails, Agents, multimodal RAG, and Knowledge Bases for seamless interoperability across the platform.
This reactive architecture processes audio chunks and text tokens as they arrive from Amazon Nova Sonic, rather than waiting for complete responses.
The application implements an intelligent filtering logic that monitors contentStart events for generation stage metadata. It captures only FINAL stage content to remove duplicate or preliminary audio, and prevents audio artifacts for clean, natural-sounding output.
影響分析・編集コメントを表示
影響分析
この発表は、音声AIの実用性を大幅に向上させる重要な進展であり、従来のポッドキャスト制作の課題(時間、コスト、リソース)を解決する可能性がある。リアルタイムの音声対話システムの構築が容易になることで、カスタマーサポート、インタラクティブラーニング、音声対応アシスタントなど、多様な分野への応用が期待される。
編集コメント
AWSが音声AI分野で本格的な参入を果たしたことを示す重要な発表。従来のテキスト中心のLLMから、実用的な音声対話システムへの進化を象徴しており、コンテンツ制作業界に大きな影響を与える可能性がある。
今日のコンテンツクリエイターや組織が直面している共通の課題は、大規模な高品質なオーディオコンテンツの制作です。従来のポッドキャスト制作には、リサーチ、スケジュール調整、録音、編集といった大幅な時間的投資に加え、スタジオスペース、機材、声優などの多額の資源が必要です。これらの制約により、組織が新しいトピックに対応したりコンテンツ制作を拡大したりする速度は限られてしまいます。Amazon Nova 2 Sonic は、低レイテンシと業界トップクラスの価格パフォーマンスを実現する最先端の音声理解・生成モデルであり、自然で人間のような会話型 AI を提供します。ストリーミング音声理解、指示のフォロー、ツール呼び出し、音声とテキストをシームレスに切り替えるマルチモーダルインタラクションをサポートしており、最大 100 万トークンのコンテキストウィンドウを持つ 7 か国語に対応しています。開発者は、Amazon Nova 2 Sonic を活用して、カスタマーサポート、インタラクティブな学習、音声対応アシスタント向けのボイスファーストアプリケーションを構築できます。
この投稿では、あらゆるトピックについて 2 人の AI ホスト間の魅力的な会話を生成する自動化されたポッドキャストジェネレーターの構築方法を示し、Nova Sonic のストリーミング機能、ステージ別コンテンツフィルタリング、リアルタイムオーディオ生成のデモンストレーションを行います。
Amazon Nova 2 Sonic とは?
Amazon Nova 2 Sonic は、音声入力を処理し、音声出力およびテキスト文字起こしを提供することで、豊かな文脈理解に基づく人間のような会話を可能にします。Amazon Nova 2 Sonic は、リアルタイムで低遅延のマルチターン会話を実現するストリーミング API を提供しており、開発者は音声によるアプリナビゲーション、ワークフローの自動化、タスク完了を駆動する「ボイスファースト」アプリケーションを構築できます。
このモデルは Amazon Bedrock を通じてアクセス可能であり、Guardrails(ガードレール)、Agents(エージェント)、マルチモーダル RAG(Retrieval-Augmented Generation:検索拡張生成)、Knowledge Bases(ナレッジベース)といった主要な Amazon Bedrock の機能と統合でき、プラットフォーム全体でシームレスな相互運用性を確保します。
主な機能:
- ストリーミング音声理解 – 低遅延でリアルタイムに音声を処理し、応答する
- インストラクションフォロー – 複雑なマルチステップの音声コマンドを実行する
- ツール呼び出し – 会話中に外部関数や API を呼び出す
- クロスモーダルインタラクション – 音声とテキストの入出力をシームレスに切り替える
- マルチリンガルサポート – 英語、フランス語、イタリア語、ドイツ語、スペイン語、ポルトガル語、ヒンディー語をネイティブサポート
- 大規模コンテキストウィンドウ – 最大 1M トークンで、長期にわたる会話の文脈を維持可能
課題の理解
ポッドキャストは爆発的な成長を遂げ、ニッチなメディアからメインストリームのコンテンツ形式へと進化しました。この急増は、ポッドキャストがマルチタスクの活動(通勤、運動、家事など)中に情報を提供するという独自の能力に起因し、視覚コンテンツでは到底及ばないアクセシビリティの優位性を提供しています。
しかし、従来のポッドキャスト制作には構造的な課題が存在します:
コンテンツのスケーラビリティ(拡張性): 人間のホストは、リサーチ、スケジュール調整、録音、ポストプロダクションに多額の時間を要するため、出力の頻度と量が制限されます。
一貫性: 人間のホストはスケジュールの衝突、病気、エネルギーレベルの変動、利用可能な時間の制約に直面し、不規則な公開スケジュールを生み出します。
パーソナライズ(個別最適化): 従来のポッドキャストは画一的なモデルに従っており、関心や知識レベルに応じてリスナー一人ひとりにコンテンツをリアルタイムで調整することができません。
リソース効率: 高品質な制作には、タレント、機器、編集ソフトウェア、運用オーバーヘッドに対する継続的な多額の投資が必要です。
専門家のアクセス: 多様なトピックに精通したホストを確保することは依然として困難で高コストであり、コンテンツの幅と深さを制限しています。
Amazon Nova Sonic の会話型 AI 機能を活用することで、組織はこれらの制約に対処し、従来の人的リソースの制約なく世界的にスケーリング可能な、新しいインタラクティブでパーソナライズされたオーディオコンテンツの形式を実現できます。
ソリューションの概要
Nova Sonic Live Podcast Generator は、Amazon Nova Sonic の音声対音声モデルを使用して、あらゆるトピックについて AI ホスト間の自然な会話を生成する方法を示すデモンストレーションです。ユーザーは Web インターフェースを通じてトピックを入力し、アプリケーションはリアルタイムでストリーミングされる交替する話者による複数ラウンドの対話を生成します。
主な機能
- 低レイテンシでのリアルタイムストリーミングオーディオ生成
- 複数回の会話ターンにわたる自然な往復の対話
- 重複するオーディオを除去するステージ認識型コンテンツフィルタリング
- 会話の更新をリアルタイムで表示するシンプルな Web インターフェース
- AsyncIO アーキテクチャによる同時ユーザーサポート
- さまざまなユースケースに対応する複数の音声ペルソナの提供
前提条件
このソリューションを実装するには、以下の要件を満たす必要があります。
- Amazon Bedrock および Amazon Nova 2 Sonic モデルへのアクセス権限を持つ AWS アカウント
- Python 3.8 以降
- Flask Web フレームワークと AsyncIO
- AWS 認証情報の設定(アクセスキー、シークレットキー、AWS リージョン)
- pip パッケージマネージャーを備えた開発環境
実装の詳細
詳細なコードサンプルおよび完全な実装ガイドについては、GitHub で表示 してください。
アーキテクチャの概要
本ソリューションは、Flaskベースのアーキテクチャを採用しており、ストリーミングとリアクティブイベント処理を特徴としています。これは、Amazon Nova Sonicの機能を概念実証(Proof of Concept)および教育目的でデモンストレーションするために設計されています。
システムアーキテクチャ図
以下の図は、リアルタイムストリーミングアーキテクチャを示しています:
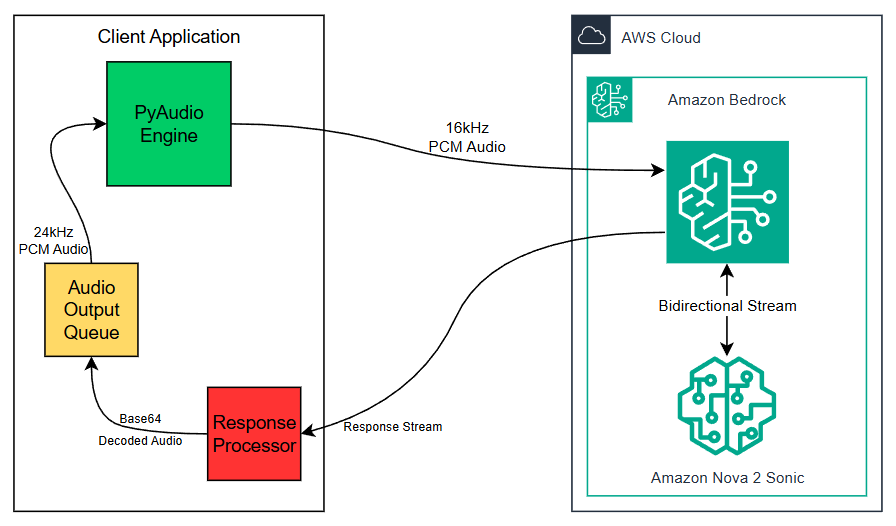
アーキテクチャの構成要素
このアーキテクチャは、関心の明確な分離を持つ階層型アプローチに従っています:
クライアントアプリケーションは、オーディオの全ライフサイクルを管理する3つの密接に結合されたコンポーネントをホストしています:
- PyAudioエンジン(PyAudio Engine)は、16kHz PCMでマイク入力をキャプチャし、Amazon Bedrockにストリーミングします。また、24kHz PCMの再生準備が整ったオーディオをAudio Output Queueから受信し、リアルタイムでスピーカー出力を処理します。
- Response Processorは、Amazon Nova Sonicから返される生のレスポンスストリームを受信し、Base64エンコードされたオーディオペイロードをデコードして、デコードされたオーディオをAudio Output Queueに転送します。
- Audio Output Queueは、Response ProcessorとPyAudioエンジンの間のバッファとして機能し、可変のレイテンシ(遅延)を持つレスポンスを吸収し、24kHz PCMでの滑らかで途切れないオーディオ再生を保証します。
AWS Cloud – すべてのモデル通信はAmazon Bedrockを通じて実行され、Amazon Nova Sonicとの間で双方向イベントストリーム(bidirectional event stream)を仲介します:
- Amazon Bedrock は PyAudio エンジンからの送信側 16kHz PCM オーディオストリームを受信し、モデルへルーティングします。また、モデルからの応答ストリームをクライアントへも伝送します。
- Amazon Nova Sonic は双方向ストリームを通じてオーディオ入力を受信し、リアルタイムの音声から音声への推論を実行して、Base64 PCM 形式でエンコードされた合成オーディオを含む応答ストリームを 24kHz で返します。
*Production Architecture Note:** この実装はデモンストレーション目的で Flask と PyAudio を使用しています。PyAudio にはビルトインのエコーキャンセレーション機能がないため、サーバーサイドでのオーディオ再生に最も適しています。本番環境の Web ベースクライアントアプリケーションには、より優れたエコーキャンセレーションと低レイテンシを実現するブラウザネイティブのオーディオ処理のために、JavaScript ベースのオーディオライブラリ(Web Audio API)または WebRTC を使用することが推奨されます。本番環境のアーキテクチャパターンについては、GitHub リポジトリを参照してください。
Key technical innovations
Amazon Bedrock 統合
システムの中心には、Amazon Nova 2 Sonic モデルへの永続的な接続を管理するカスタムコンポーネントである BedrockStreamManager が位置しています。このマネージャーは、初期化、メッセージ送信、レスポンス処理を含むストリーミング API 相互作用の複雑な処理を担います。環境変数を通じて構成された AWS 認証情報は、基盤モデル(FM)への安全なアクセスを維持します。完全なコードは GitHub リポジトリ にあります。
各会話ターンに対して BedrockStreamManager を初期化
manager = BedrockStreamManager(
model_id='amazon.nova-sonic-v1:0',
region='us-east-1'
)
音声ペルソナ(Matthew または Tiffany)を設定
manager.START_PROMPT_EVENT = manager.START_PROMPT_EVENT.replace(
'"matthew"', f'"{voice}"'
)
ストリーミング接続を初期化
await manager.initialize_stream()
反応型ストリーミングパイプライン
本アプリケーションは、リアルタイムのデータストリームを処理するための観測可能パターン(Observable Pattern)を実装するために RxPy(Python 用リアクティブ拡張ライブラリ)を採用しています。このリアクティブアーキテクチャは、Amazon Nova Sonic からの完全なレスポンスを待つのではなく、到着するたびにオーディオチャンクやテキストトークンを処理します。
BedrockStreamManager からのストリーミングイベントを購読
manager.output_subject.subscribe(on_next=capture)
キャプチャ関数はイベントをリアルタイムで処理
def capture(event):
if 'textOutput' in event['event']:
text = event['event']['textOutput']['content']
text_parts.append(text)
if 'audioOutput' in event['event']:
audio_chunks.append(event['event']['audioOutput']['content'])
The output_subject in the BedrockStreamManager acts as the central event bus, so multiple subscribers can react to streaming events simultaneously. This design choice reduces latency and improves the user experience by providing immediate feedback.
Stage-aware content filtering
One of the key technical innovations in this implementation is the stage-aware filtering mechanism. Amazon Nova 2 Sonic generates content in multiple stages: SPECULATIVE (preliminary) and FINAL (polished). The application implements an intelligent filtering logic that monitors contentStart events for generation stage metadata. It captures only FINAL stage content to remove duplicate or preliminary audio, and prevents audio artifacts for clean, natural-sounding output.
def capture(event):
nonlocal is_final_stage
if 'event' in event:
コンテンツ開始イベントから生成ステージを検出
if 'contentStart' in event['event']:
content_start = event['event']['contentStart']
if 'additionalModelFields' in content_start:
additional_fields = json.loads(content_start['additionalModelFields'])
stage = additional_fields.get('generationStage', 'FINAL')
is_final_stage = (stage == 'FINAL')
FINAL ステージでのみコンテンツを取得
if is_final_stage:
if 'textOutput' in event['event']:
text = event['event']['textOutput']['content']
if text and '{ "interrupted" : true }' not in text:
text_parts.append(text)
if 'audioOutput' in event['event']:
audio_chunks.append(event['event']['audioOutput']['content'])
フィルタリングは3つのレベルで実行されます:
- 中断コンテンツフィルタ – 中断マーカーを確認することで、キャンセルされたコンテンツを削除します。
- テキストの重複排除 – SPECULATIVE(推論)ステージと FINAL(最終)ステージ間で、完全に一致するテキストをフィルタリングします。
- オーディオハッシュの重複排除 – ハッシュ指紋(フィンガープリント)を使用して、重複するオーディオチャンクをフィルタリングします。
このフィルタリングは、出力ストリームを購読し、生成ステージに基づいてイベントを選択的に処理するキャプチャコールバック関数内でリアルタイムで行われます。
注記: 表示されているコードスニペットは明確さを簡略化したものです。is_final_stage変数は、外側のスコープで定義されている必要があります。完全な本番環境対応の実装については、GitHubリポジトリを参照してください。
会話管理
システムは、複数の対話ラウンドを持つターンベースの会話モデルを実装しています。各ターンは、自然な会話の流れに従った一貫したパターンに従います。
- 会話履歴 – アプリケーションは、話者固有の変数を通じて会話の文脈を維持し、各話者が以前に何が発言したかを参照できるようにします。
- 動的プロンプト生成 – プロンプトは、話者の役割と会話の文脈に基づいて動的に構築されます。例えば、マシュー(ホスト)はトピックを提示しフォローアップ質問を投げかけ、一方、ティファニー(専門家)は情報に基づいた回答を提供します。
- ターンごとの新規ストリーム – アプリケーションは、各話者のターンごとに新しいBedrockStreamManagerインスタンスを作成し、クリーンなオーディオストリームのためにターン間の状態汚染を防ぎます。
非同期実行モデル
オーディオ再生やモデルAPI呼び出しのブロッキング性質に対処するため、アプリケーションは各ポッドキャスト生成リクエストに対して新しいasyncioイベントループを作成します。これにより、複数のユーザーが互いをブロックすることなく同時にポッドキャストを生成できます。このループは、ストリームの初期化、プロンプトの送信、オーディオ再生の調整、およびクリーンアップを管理し、ユーザーセッション間の明確な分離を維持しながら並行使用をサポートします。
データフローの概要
このシステムは、ユーザー入力から音声出力に至るまで、簡素化されたフローに従います。ユーザーがトピックを入力すると、バックエンドがダイナミックなプロンプト生成により会話のターンを調整し、Amazon Nova 2 Sonic がストリーミング API を通じて音声応答を生成します。さらに、ステージ固有のフィルタリングにより、最終的に完成されたコンテンツのみがオーディオパイプラインへ送られ、再生が行われます。
詳細なコードサンプルおよび完全な実装ガイドについては、GitHub で確認してください。
使用例
Amazon Nova 2 Sonic のアーキテクチャは、複数の業界にわたって自動化されたインタラクティブなオーディオコンテンツの作成を可能にします。対話形式で会話型 AI インスタンスを調整することで、組織は規模の大きい、魅力的で自然な音声コンテンツを生成できます。
インタラクティブな学習と知識共有
学生向け教育や従業員研修など、人々が情報を学び、保持するのに役立つ魅力的なコンテンツの作成に課題を抱えている組織は多くあります。Amazon Nova 2 Sonic のインスタンスは、教室でのディスカッションやソクラテス式対話をシミュレートでき、一方のインスタンスが質問を投げかけ、もう一方のインスタンスが説明や具体例を提供します。
教育機関にとって、これは異なる学習スタイルやペースに対応する動的な学習体験を生み出します。企業にとっては、社内コミュニケーション(ポリシー、手順、組織変更)を、従業員がマルチタスク中に消費できる会話形式に変換します。Retrieval Augmented Generation (RAG) および Amazon Bedrock Knowledge Bases との統合により、コンテンツを最新の状態に保ち、カリキュラムや組織の要件と整合させつつ、会話形式は情報の保持率を高め、フォローアップ質問を削減します。
多言語コンテンツのローカライゼーション
グローバル企業は、市場間で一貫したメッセージングを提供しつつ、文化的なニュアンスを尊重する必要があります。Amazon Nova Sonic が 英語、フランス語、イタリア語、ドイツ語、スペイン語、ポルトガル語、ヒンディー語 をサポートしているため、ネイティブのような会話を含むローカライズされたオーディオコンテンツを作成できます。このモデルは、言語、文化的参照、コミュニケーションスタイルを適応させた市場固有の議論を生成し、単なる翻訳を超えて、現地視聴者に響く文化的に関連性の高いコンテンツを生み出します。
多言語対応の音声機能(同じ会話内で言語を切り替えることができる個別の声)は、混合言語の文を自然に処理する高度なコードスイッチング機能を実現します。これは、多言語のカスタマーサポートやグローバルチームのコラボレーションにおいて特に価値があります。
商品解説とレビュー
ECプラットフォームは、複雑な製品を理解してもらうための魅力的な手法を必要としています。Amazon Nova 2 Sonic インスタンスは、会話形式の商品レビューを生成できます。一方のインスタンスが顧客からよく寄せられる質問を投げかけ、もう一方のインスタンスは仕様書、ユーザーレビュー、技術文書に基づいて回答します。これにより、自然な対話を通じて製品を評価できるアクセシブルなコンテンツが作成され、商品カタログとの連携により正確性が確保されます。
Thought leadership(業界における指導的立場)と業界分析
プロフェッショナルサービス企業は、定期的なコンテンツ制作を通じて Thought leadership(業界における指導的立場)を確立する必要がありますが、分析コンテンツの作成には多大な時間投資が必要です。Amazon Nova 2 Sonic インスタンスは、業界動向や市場分析に関する専門家レベルの議論を行うことができます。一方が仮定に異議を唱え、もう一方がデータを用いて立場を擁護します。これにより、組織は既存の研究リソースを活用し、オーディオ形式を好む多忙な経営層に届くアクセシブルなオーディオコンテンツとして再利用することができます。
パフォーマンス特性
- レイテンシ:即時音声再生を可能にする低レイテンシのストリーミング
- ポッドキャストの長さ:会話のターンに基づいた柔軟な長さ(通常は2〜5分)
- 同時ユーザー数:AsyncIOを通じて複数の並列ポッドキャスト生成をサポート
- 音声品質:自然なイントネーションとペースを持つプロフェッショナルグレードの音声合成
- 言語サポート:英語、フランス語、イタリア語、ドイツ語、スペイン語、ポルトガル語、ヒンディー語
- コンテキストウィンドウ:拡張された会話コンテキストに対応する最大100万トークン
結論
Amazon Nova 2 Sonicは、自然で人間のような対話型AI体験を可能にする最先端の音声理解および生成モデルです。本稿で概説したアーキテクチャは、対話型AIアプリケーションを構築するための実用的な基盤を提供します。カスタマーサポートの効率化、教育コンテンツの作成、あるいは思考リーダーシップ資料の生成など、ここで示されたパターンはあらゆるユースケースに適用可能です。
拡張された言語サポート、多言語対応の音声機能、強化されたテレフォニー統合、そしてマルチモーダル相互作用により、Amazon Nova 2 Sonicは組織が大規模なグローバルかつ音声ファーストのアプリケーションを構築するためのツールを提供します。
Amazon Nova Sonicでの構築を開始するには、
原文を表示
Content creators and organizations today face a persistent challenge: producing high-quality audio content at scale. Traditional podcast production requires significant time investment (research, scheduling, recording, editing) and substantial resources including studio space, equipment, and voice talent. These constraints limit how quickly organizations can respond to new topics or scale their content production. Amazon Nova 2 Sonic is a state-of-the-art speech understanding and generation model that delivers natural, human-like conversational AI with low latency and industry-leading price-performance. It provides streaming speech understanding, instruction following, tool invocation, and cross-modal interaction that seamlessly switches between voice and text. Supporting seven languages with up to 1M token context windows, developers can use Amazon Nova 2 Sonic to build voice-first applications for customer support, interactive learning, and voice-enabled assistants.
This post walks through building an automated podcast generator that creates engaging conversations between two AI hosts on any topic, demonstrating the streaming capabilities of Nova Sonic, stage-aware content filtering, and real-time audio generation.
What is Amazon Nova 2 Sonic?
Amazon Nova 2 Sonicprocesses speech input and delivers speech output and text transcriptions, creating human-like conversations with rich contextual understanding. Amazon Nova 2 Sonic provides a streaming API for real-time, low-latency multi-turn conversations, so developers can build voice-first applications where speech drives app navigation, workflow automation, and task completion.
The model is accessible through Amazon Bedrock and can be integrated with key Amazon Bedrock features, including Guardrails, Agents, multimodal RAG, and Knowledge Bases for seamless interoperability across the platform.
Key capabilities:
- Streaming Speech Understanding – Process and respond to speech in real-time with low latency
- Instruction Following – Execute complex multi-step voice commands
- Tool Invocation: Call external functions and APIs during conversations
- Cross-Modal Interaction – Seamlessly switch between voice and text I/O
- Multilingual Support – Native support for English, French, Italian, German, Spanish, Portuguese, and Hindi
- Large Context Window – Up to 1M tokens for maintaining extended conversation context
Understanding the challenge
Podcasts have experienced explosive growth, evolving from a niche medium to mainstream content format. This surge comes from podcasts’ unique ability to deliver information during multitasking activities (commuting, exercising, household tasks) providing an accessibility advantage that visual content can’t match.
However, traditional podcast production faces structural challenges:
Content Scalability: Human hosts require extensive time for research, scheduling, recording, and post-production, limiting output frequency and volume.
Consistency: Human hosts face scheduling conflicts, illness, varying energy levels, and availability constraints that create irregular publishing schedules.
Personalization: Traditional podcasts follow a one-size-fits-all model, unable to tailor content to individual listeners for interests or knowledge levels in real-time.
Resource Efficiency: Quality production requires significant ongoing investment in talent, equipment, editing software, and operational overhead.
Expert Access: Securing knowledgeable hosts across diverse topics remains challenging and expensive, restricting content breadth and depth.
By using the conversational AI capabilities of Amazon Nova Sonic, organizations can address these limitations and enable new interactive and personalized audio content formats that scale globally without traditional human resource constraints.
Solution overview
The Nova Sonic Live Podcast Generator demonstrates how to create natural conversations between AI hosts about any topic using the speech-to-speech model of Amazon Nova Sonic. Users enter a topic through a web interface, and the application generates a multi-round dialogue with alternating speakers streamed in real-time.
Key features
- Real-time streaming audio generation with low latency
- Natural back-and-forth dialogue across multiple conversational turns
- Stage-aware content filtering that removes duplicate audio
- Simple web interface with live conversation updates
- Concurrent user support through AsyncIO architecture
- Provides multiple voice personas for different use cases.
Prerequisites
To implement this solution, the following requirements must be met:
- AWS account with access to Amazon Bedrock and Amazon Nova 2 Sonic model
- Python 3.8 or later
- Flask web framework and AsyncIO
- AWS credentials are configured (access key, secret key, AWS Region)
- Development environment with pip package manager
Implementation details
For detailed code samples and complete implementation guidance, view in GitHub.
Architecture overview
The solution follows a Flask-based architecture with streaming and reactive event processing, designed to demonstrate the capabilities of Amazon Nova Sonic for proof-of-concept and educational purpose.
System architecture diagram
The following diagram illustrates the real-time streaming architecture:
Architecture components
The architecture follows a layered approach with clear separation of concerns:
Client Application hosts three tightly coupled components that manage the full audio lifecycle:
- PyAudio Engine captures microphone input at 16kHz PCM and streams it to Amazon Bedrock. It also receives playback-ready audio from the Audio Output Queue at 24kHz PCM, handling speaker output in real time.
- Response Processor receives the raw response stream returned by Amazon Nova Sonic, decodes the Base64-encoded audio payload, and forwards the decoded audio to the Audio Output Queue.
- Audio Output Queue acts as a buffer between the Response Processor and the PyAudio Engine, absorbing variable-latency responses and ensuring smooth, uninterrupted audio playback at 24kHz PCM.
AWS Cloud – all model communication runs through Amazon Bedrock, which brokers a bidirectional event stream with Amazon Nova Sonic:
- Amazon Bedrock receives the outbound 16kHz PCM audio stream from the PyAudio Engine and routes it to the model. It also carries the model’s response stream back to the client.
- Amazon Nova Sonic receives the audio input through the bidirectional stream, performs real-time speech-to-speech inference, and returns a response stream containing synthesized audio encoded as Base64 PCM at 24kHz.
*Production Architecture Note:** This implementation uses Flask with PyAudio for demonstration purposes. PyAudio does not provide built-in echo cancellation and is best suited for server-side audio playback. For production web-based client applications, JavaScript-based audio libraries (Web Audio API) or WebRTC are recommended for browser-native audio handling with better echo cancellation and lower latency. See the GitHub repository for production architecture patterns.*
Key technical innovations
Amazon Bedrock integration
At the heart of the system is the BedrockStreamManager, a custom component that manages persistent connections to the Amazon Nova 2 Sonic model. This manager handles the complexities of streaming API interactions, including initialization, message sending, and response processing. AWS credentials that are configured through environment variables maintains secure access to the foundation model (FM). The full code is in the GitHub Repository
# Initialize BedrockStreamManager for each conversation turn
manager = BedrockStreamManager(
model_id='amazon.nova-sonic-v1:0',
region='us-east-1'
)
# Configure voice persona (Matthew or Tiffany)
manager.START_PROMPT_EVENT = manager.START_PROMPT_EVENT.replace(
'"matthew"', f'"{voice}"'
)
# Initialize streaming connection
await manager.initialize_stream()Reactive streaming pipeline
The application employs RxPy (Reactive Extensions for Python) to implement an observable pattern for handling real-time data streams. This reactive architecture processes audio chunks and text tokens as they arrive from Amazon Nova Sonic, rather than waiting for complete responses.
# Subscribe to streaming events from BedrockStreamManager
manager.output_subject.subscribe(on_next=capture)
# Capture function processes events in real-time
def capture(event):
if 'textOutput' in event['event']:
text = event['event']['textOutput']['content']
text_parts.append(text)
if 'audioOutput' in event['event']:
audio_chunks.append(event['event']['audioOutput']['content'])The output_subject in the BedrockStreamManager acts as the central event bus, so multiple subscribers can react to streaming events simultaneously. This design choice reduces latency and improves the user experience by providing immediate feedback.
Stage-aware content filtering
One of the key technical innovations in this implementation is the stage-aware filtering mechanism. Amazon Nova 2 Sonic generates content in multiple stages: SPECULATIVE (preliminary) and FINAL (polished). The application implements an intelligent filtering logic that monitors contentStart events for generation stage metadata. It captures only FINAL stage content to remove duplicate or preliminary audio, and prevents audio artifacts for clean, natural-sounding output.
def capture(event):
nonlocal is_final_stage
if 'event' in event:
# Detect generation stage from contentStart event
if 'contentStart' in event['event']:
content_start = event['event']['contentStart']
if 'additionalModelFields' in content_start:
additional_fields = json.loads(content_start['additionalModelFields'])
stage = additional_fields.get('generationStage', 'FINAL')
is_final_stage = (stage == 'FINAL')
# Only capture content in FINAL stage
if is_final_stage:
if 'textOutput' in event['event']:
text = event['event']['textOutput']['content']
if text and '{ "interrupted" : true }' not in text:
text_parts.append(text)
if 'audioOutput' in event['event']:
audio_chunks.append(event['event']['audioOutput']['content'])The filtering operates at three levels:
- Interrupted Content Filter – Removes canceled content by checking for interruption markers.
- Text Deduplication – Filters exact duplicate text across SPECULATIVE and FINAL stages.
- Audio Hash Deduplication – Filters duplicate audio chunks using hash fingerprinting.
This filtering happens in real-time within the capture callback function, which subscribes to the output stream and selectively processes events based on generation stage.
*Note:** The code snippets shown are simplified for clarity. The is_final_stage variable must be defined in the enclosing scope. See the GitHub repository for complete, production-ready implementations.*
Conversation management
The system implements a turn-based conversation model with multiple rounds of dialogue. Each turn follows a consistent pattern for natural conversation flow:
- Conversation History – The application maintains conversation context through speaker-specific variables, so each speaker can reference what was previously said.
- Dynamic Prompt Generation – Prompts are constructed dynamically based on speaker role and conversation contex, for example, Matthew (host) introduces topics and asks follow-up questions, while Tiffany (expert) provides informed responses.
- Fresh Stream Per Turn – The application creates a fresh BedrockStreamManager instance for each speaker turn, preventing state contamination between turns for clean audio streams.
Asynchronous execution model
To handle the blocking nature of audio playback and model API calls, the application creates a new asyncio event loop for each podcast generation request. This way, multiple users can generate podcasts simultaneously without blocking each other. The loop manages stream initialization, prompt sending, audio playback coordination, and cleanup, supporting concurrent usage while maintaining clean separation between user sessions.
Data flow overview
The system follows a streamlined flow from user input to audio output. Users enter a topic, the backend orchestrates conversation turns with dynamic prompt generation, Amazon Nova 2 Sonic generates speech responses through a streaming API, and stage-aware filtering makes sure that only polished FINAL content reaches the audio pipeline for playback.
For detailed code samples and complete implementation guidance, view in GitHub.
Use cases
The Amazon Nova 2 Sonic architecture enables automated, interactive audio content creation across multiple industries. By orchestrating conversational AI instances in dialogue, organizations can generate engaging, natural-sounding content at scale.
Interactive learning and knowledge sharing
Organizations struggle to create engaging content that helps people learn and retain information, whether for student education or employee training. Amazon Nova 2 Sonic instances can simulate classroom discussions or Socratic dialogues, with one instance posing questions while the other provides explanations and examples.
For educational institutions, this creates dynamic learning experiences that accommodate different learning styles and paces. For enterprises, it transforms internal communications (policies, procedures, organizational changes) into conversational formats that employees can consume while multitasking. Integration with Retrieval Augmented Generation (RAG) and Amazon Bedrock Knowledge Bases keeps content current and aligned with curriculum or organizational requirements, while the conversational format increases information retention and reduces follow-up questions.
Multilingual content localization
Global organizations need consistent messaging across markets while respecting cultural nuances. The Amazon Nova Sonic support for English, French, Italian, German, Spanish, Portuguese, and Hindi enables creation of localized audio content with native-sounding conversations. The model can generate market-specific discussions that adapt language, cultural references, and communication styles, going beyond simple translation to produce culturally relevant content that resonates with local audiences.
The polyglot voice capabilities – individual voices that can switch between languages within the same conversation – enable advanced code-switching capabilities that handle mixed-language sentences naturally. This is particularly valuable for multilingual customer support and global team collaboration.
Product commentary and reviews
Ecommerce platforms need engaging ways to help customers understand complex products. Amazon Nova 2 Sonic instances can generate conversational product reviews, with one asking common customer questions while the other provides answers based on specifications, user reviews, and technical documentation. This creates accessible content that helps customers evaluate products through natural dialogue, with integration to product catalogs ensuring accuracy.
Thought leadership and industry analysis
Professional services firms need to establish thought leadership through regular content but producing analysis requires significant time investment. Amazon Nova 2 Sonic instances can engage in expert-level discussions about industry trends or market analysis, with one challenging assumptions while the other defends positions with data. This allows organizations to repurpose existing research into accessible audio content that reaches busy executives who prefer audio formats.
Performance characteristics
- Latency: Low-latency streaming with immediate audio playback
- Podcast Duration: Flexible duration based on conversational turns (typically 2–5 minutes)
- Concurrent Users: Supports multiple simultaneous podcast generations through AsyncIO
- Audio Quality: Professional-grade speech synthesis with natural intonation and pacing
- Language Support: English, French, Italian, German, Spanish, Portuguese, and Hindi
- Context Window: Up to 1M tokens for extended conversation context
Conclusion
Amazon Nova 2 Sonic is a state-of-the-art speech understanding and generation model that enables natural, human-like conversational AI experiences. The architecture outlined in this post provides a practical foundation for building conversational AI applications. Whether streamlining customer support, creating educational content, or generating thought leadership materials, the patterns demonstrated here apply across use cases.
With expanded language support, polyglot voice capabilities, enhanced telephony integration, and cross-modal interaction, Amazon Nova 2 Sonic provides organizations with tools for building global, voice-first applications at scale.
To get started with building with Amazon Nova Sonic, visit the
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み