NVIDIA Nemotron 3 NanoがAmazon Bedrockで完全管理サーバレスモデルとして利用可能に
NVIDIAの小型言語モデル「Nemotron 3 Nano」がAmazon Bedrock上でフルマネージド・サーバーレスモデルとして利用可能になり、開発者はインフラ管理の複雑さなしに生成AIアプリケーションを構築できるようになった。
キーポイント
Nemotron 3 NanoのAmazon Bedrock提供開始
NVIDIAの小型言語モデルNemotron 3 NanoがAmazon Bedrockでフルマネージド・サーバーレスモデルとして利用可能になった。これにより、開発者はインフラ管理の複雑さなしに生成AIアプリケーションを構築できる。
モデルの技術的特徴
Nemotron 3 Nanoは30Bパラメータ(アクティブ3B)の小型言語モデルで、ハイブリッドMixture-of-Expertsアーキテクチャを採用し、256Kのコンテキスト長をサポートする。
優れた性能と実用性
コーディング、科学的推論、数学、ツール呼び出しなどのタスクで優れた精度を発揮し、SWE Bench、AIME 2025、Arena Hard v2などのベンチマークでリードしている。
オープンモデルの利点
オープンウェイト、データセット、レシピを提供する完全なオープンモデルであり、開発者や企業にとって透明性と信頼性を高めている。
Amazon BedrockでのNVIDIA Nemotron 3 Nanoの呼び出し方法
boto3クライアントを使用してBedrock Runtimeからモデルを呼び出す方法と、OpenAI SDKを使用してChatCompletionsエンドポイント経由で呼び出す方法の2種類が提供されている。
モデル呼び出しの基本設定
推論設定としてmaxTokens、temperature、topPのパラメータを指定でき、エラーハンドリングも実装されている。
Amazon Bedrock Guardrailsの活用
有害コンテンツのフィルタリング、個人情報の編集、特定トピックのブロックなど、責任あるAIを実現するための安全層として機能する。具体的な例として、住宅ローンアシスタントで「株式」という単語を含むプロンプトをブロックする設定が紹介されている。
影響分析・編集コメントを表示
影響分析
この発表は、クラウドプラットフォームとAIモデルプロバイダーの連携強化を示しており、開発者が複雑なインフラ管理なしに高性能な生成AIモデルを利用できる環境が整備された。特にオープンモデルのクラウド提供は、企業のAI導入障壁を下げ、より広範なAI応用を促進する可能性がある。
編集コメント
AWSとNVIDIAの連携強化が進み、開発者向けのAIツールチェーンがさらに充実。オープンモデルのクラウド提供は、企業のAI導入を加速させる重要な動きと言える。
# 使用したいAWSリージョンでBedrock Runtimeクライアントを作成します。
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# モデルIDを設定します。
model_id = "nvidia.nemotron-nano-3-30b"
# ユーザーメッセージで会話を開始します。
user_message = "Type_Your_Prompt_Here"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# 基本的な推論設定を使用してメッセージをモデルに送信します。
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
)
# 応答テキストを抽出して表示します。
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)Amazon BedrockのOpenAI互換ChatCompletionsエンドポイントを通じてモデルを呼び出すには、OpenAI SDKを使用できます:
# OpenAI SDKをインポート
from openai import OpenAI
# 環境変数を設定
os.environ["OPENAI_API_KEY"] = "<insert your bedrock API key>"
os.environ["OPENAI_BASE_URL"] = "https://bedrock-runtime.<AWS region>.amazon.com/openai/v1"
# モデルIDを設定
model_id = "nvidia.nemotron-nano-3-30b"
# プロンプトを設定
system_prompt = "Type_Your_System_Prompt_Here"
user_message = "Type_Your_User_Prompt_Here"
# ChatCompletions APIを使用
response = client.chat.completions.create(
model=model_id,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
],
temperature=0,
max_completion_tokens=1000
)
# 応答テキストを抽出して表示
print(response.choices[0].message.content)Amazon Bedrock機能と共にNVIDIA Nemotron 3 Nanoを使用する
Nemotron 3 NanoとAmazon Bedrockのマネージドツールを組み合わせることで、生成AIアプリケーションを強化できます。Amazon Bedrock Guardrailsを使用して保護策を実装し、Amazon Bedrock Knowledge Basesを使用して堅牢な検索拡張生成(RAG)ワークフローを作成できます。
Amazon Bedrock Guardrails
Guardrailsはマネージドな安全レイヤーで、有害なコンテンツのフィルタリング、機密情報(PII)の編集、プロンプトと応答全体での特定トピックのブロックを通じて、責任あるAIの実施を支援します。複数のモデルにわたって機能し、プロンプトインジェクション攻撃や幻覚の検出を支援します。
使用例: 住宅ローンアシスタントを構築している場合、一般的な投資アドバイスを提供しないように防止できます。「stocks」という単語のフィルターを設定することで、その用語を含むユーザープロンプトを即座にブロックし、カスタムメッセージを受け取ることができます。
ガードレールを設定するには、以下の手順を完了します:
- Amazon Bedrockコンソールで、左側のBuildセクションに移動し、Guardrailsを選択します。
- 新しいガードレールを作成し、ユースケースに必要なフィルターを設定します。
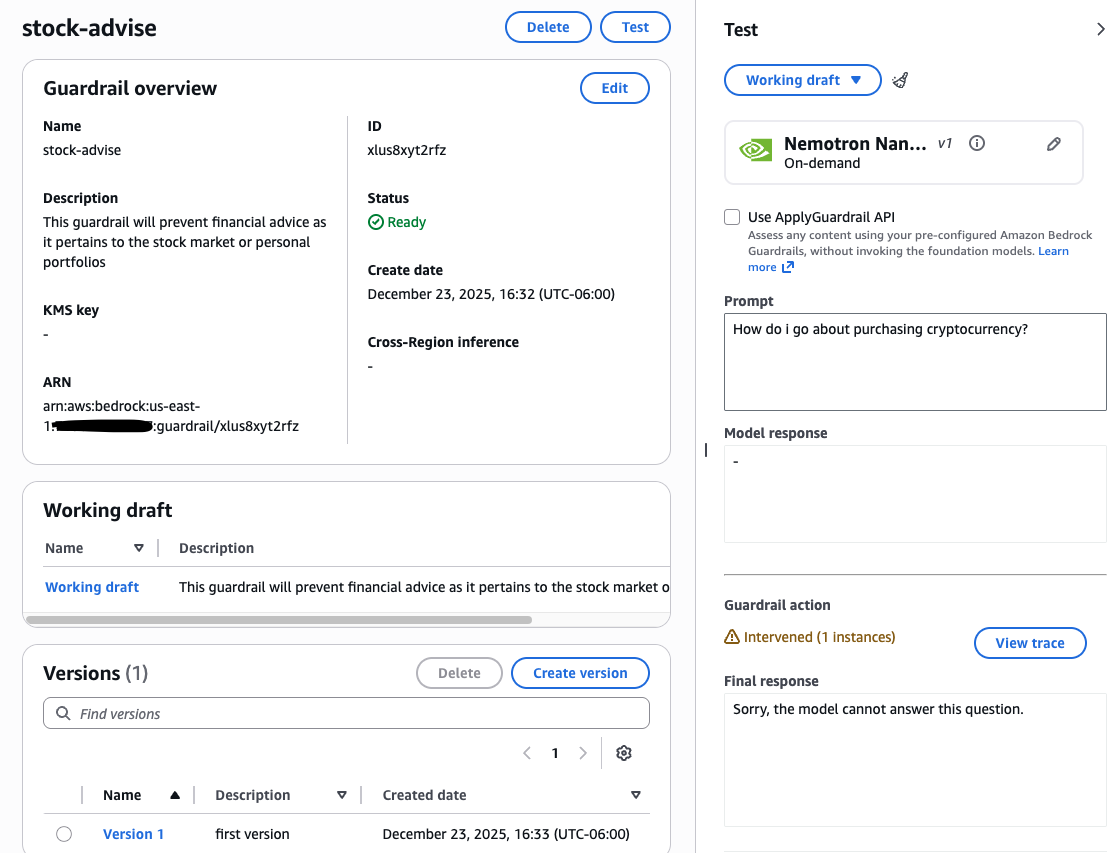
設定後、さまざまなプロンプトでガードレールをテストし、その性能を確認します。その後、拒否トピック、単語フィルター、PII編集などの設定を微調整して、特定の安全要件に合わせることができます。詳細については、ガードレールの作成を参照してください。
Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Basesは、完全なRAGワークフローを自動化します。データソースからのコンテンツの取り込み、検索可能なセグメントへの分割、ベクトル埋め込みへの変換、ベクトルデータベースへの保存を処理します。その後、ユーザーがクエリを送信すると、システムは入力と保存されたベクトルを照合して意味的に類似したコンテンツを見つけ、それを基盤モデルに送信されるプロンプトを拡張するために使用します。
この例では、PDF(例:Buying a New Home、Home Loan Toolkit, Shopping for a Mortgage)をAmazon Simple Storage Service(Amazon S3)にアップロードし、Amazon OpenSearch Serverlessをベクトルストアとして選択しました。以下のコードは、RetrieveAndGenerate APIを使用してこのナレッジベースをクエリする方法を示し、特定のGuardrail IDを通じて安全コンプライアンスの整合を自動的に促進します。
import boto3
bedrock_agent_runtime_client = boto3.client('bedrock-agent-runtime')
response = bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': 'I am interested in purchasing a home. What steps should I take to make sure I am prepared to take on a mortgage?'
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'generationConfiguration': {
'guardrailConfiguration': {
'guardrailId': '<INSERT GUARDRAIL ID>',
'guardrailVersion': '1'
}
},
'knowledgeBaseId': '<INSERT KNOWLEDGE BASE ID>',
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/nvidia.nemotron-nano-3-30b',
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": (
"You are a helpful assistant that answers questions about mortgages"
"search results.\n\n"
"Search results:\n$search_results$\n\n"
"User query:\n$query$\n\n"
"Answer clearly and concisely."
)
},
},
"orchestrationConfiguration": {
"promptTemplate": {
"textPromptTemplate": (
"You are very knowledgeable on mortgages"
"Conversation so far:\n$conversation_history$\n\n"
"User query:\n$query$\n\n"
"$output_format_instructions$"
)
}
}
},
'type': 'KNOWLEDGE_BASE'
}
)
print(response)これは、NVIDIA Nemotron 3 Nanoモデルに、カスタムプロンプトテンプレートを使用して取得したドキュメントを明確で根拠に基づいた回答に統合するよう指示します。独自のパイプラインを設定するには、Amazon Bedrockユーザーガイドの完全なウォークスルーを確認してください。
結論
この記事では、完全マネージドなサーバーレス推論のためにAmazon Bedrock上でNVIDIA Nemotron 3 Nanoを始める方法を示しました。また、Amazon Bedrock Knowledge BasesおよびAmazon Bedrock Guardrailsと共にモデルを使用する方法も示しました。このモデルは現在、米国東部(バージニア北部)、米国東部(オハイオ)、米国西部(オレゴン)、アジアパシフィック(東京)、アジアパシフィック(ムンバイ)、南米(サンパウロ)、欧州(ロンドン)、および欧州(ミラノ)のAWSリージョンで利用可能です。将来の更新については完全なリージョンリストを確認してください。詳細については、NVIDIA Nemotronをチェックし、NVIDIA Nemotron
原文を表示
*This post is cowritten with Abdullahi Olaoye, Curtice Lockhart, Nirmal Kumar Juluru from NVIDIA.*
We are excited to announce that NVIDIA’s Nemotron 3 Nano is now available as a fully managed and serverless model in Amazon Bedrock. This follows our earlier announcement at AWS re:Invent supporting NVIDIA Nemotron 2 Nano 9B and NVIDIA Nemotron 2 Nano VL 12B models.
With NVIDIA Nemotron open models on Amazon Bedrock, you can accelerate innovation and deliver tangible business value without having to manage infrastructure complexities. You can power your generative AI applications with Nemotron’s capabilities through the inference capabilities of Amazon Bedrock and harness the benefit of its extensive features and tooling.
This post explores the technical characteristics of the NVIDIA Nemotron 3 Nano model and discusses potential application use cases. Additionally, it provides technical guidance to help you get started using this model for your generative AI applications within the Amazon Bedrock environment.
About Nemotron 3 Nano
NVIDIA Nemotron 3 Nano is a small language model (SLM) with a hybrid Mixture-of-Experts (MoE) architecture that delivers high compute efficiency and accuracy that developers can use to build specialized agentic AI systems. The model is fully open with open-weights, datasets, and recipes facilitating transparency and confidence for developers and enterprises. Compared to other similar sized models, Nemotron 3 Nano excels in coding and reasoning tasks, taking the lead on benchmarks such as SWE Bench Verified, AIME 2025, Arena Hard v2, and IFBench.
Model overview:
- Architecture:
Mixture-of-Experts (MoE) with Hybrid Transformer-Mamba Architecture
- Supports Token Budget for providing accuracy while avoiding overthinking
- Accuracy:
Leading accuracy on coding, scientific reasoning, math, tool calling, instruction following, and chat
- Nemotron 3 Nano leads on benchmarks such as SWE Bench, AIME 2025, Humanity Last Exam, IFBench, RULER, and Arena Hard (compared to other open language models with 30 billion or fewer MoE)
- Model size: 30 B with 3 B active parameters
- Context length: 256K
- Model input: Text
- Model output: Text
Nemotron 3 Nano combines Mamba, Transformer, and Mixture-of-Experts layers into a single backbone to help balance efficiency, reasoning accuracy, and scale. Mamba enables long-range sequence modeling with low memory overhead, while Transformer layers help add precise attention for structured reasoning tasks like code, math, and planning. MoE routing further boosts scalability by activating only a subset of experts per token, helping to improve latency and throughput. This makes Nemotron 3 Nano especially well-suited for agent clusters running many concurrent, lightweight workflows.
To learn more about Nemotron 3 Nano’s architecture and how it is trained, see Inside NVIDIA Nemotron 3: Techniques, Tools, and Data That Make It Efficient and Accurate.
Model benchmarks
The following image shows that Nemotron 3 Nano leads in the most attractive quadrant in Artificial Analysis Openness Index vs. Intelligence Index. Why openness matters: It builds trust through transparency. Developers and enterprises can confidently build on Nemotron with clear visibility into the model, data pipeline, and data characteristics, enabling straightforward auditing and governance.
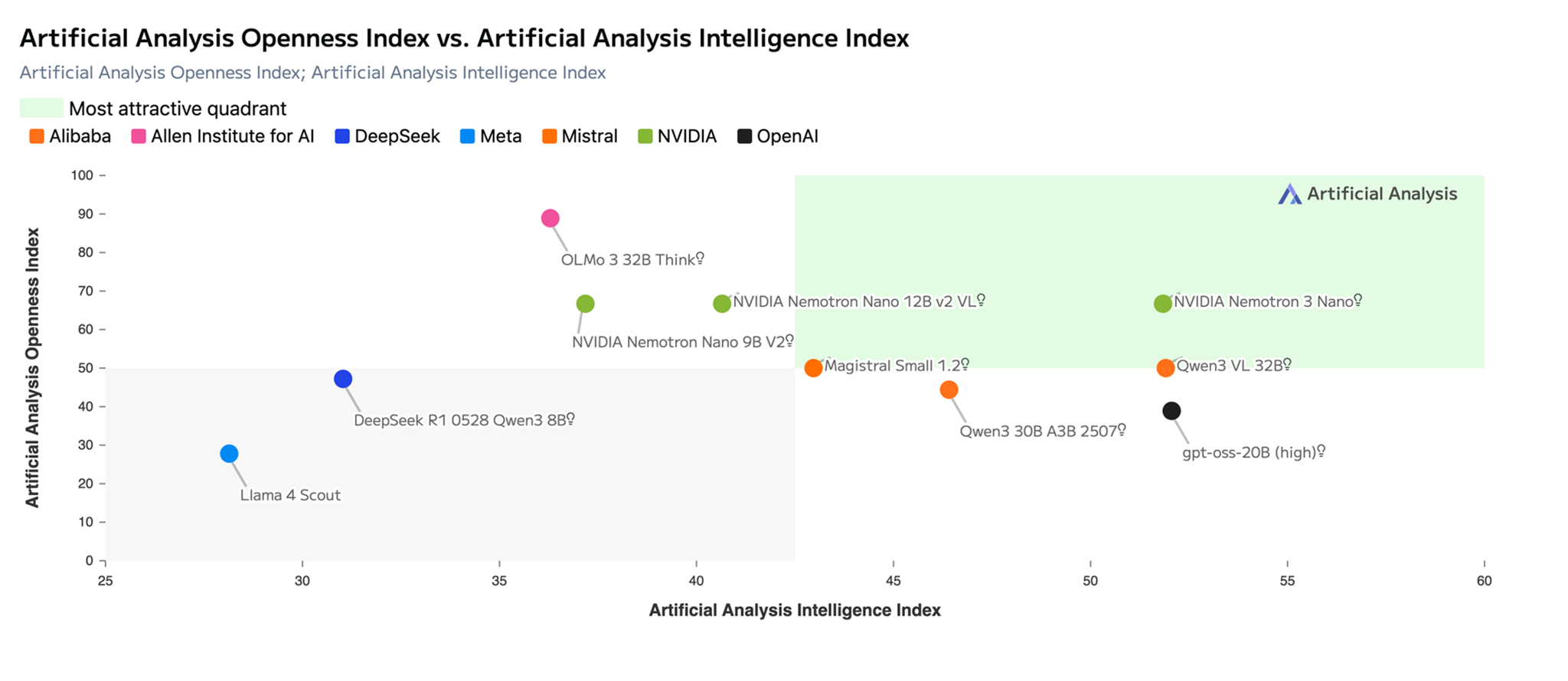
Title: Chart showing Nemotron 3 Nano in the most attractive quadrant in Artificial Analysis Openness vs Intelligence Index (Source: Artificial Analysis)
As shown in the following image, Nemotron 3 Nano provides leading accuracy with the highest efficiency among the open models and scores an impressive 52 points, a significant jump over the previous Nemotron 2 Nano model. Token demand is increasing due to agentic AI, so the ability to ‘think fast’ (arrive at the correct answer quickly while using fewer tokens) is critical. Nemotron 3 Nano delivers high throughput with its efficient Hybrid Transformer-Mamba and MoE architecture.
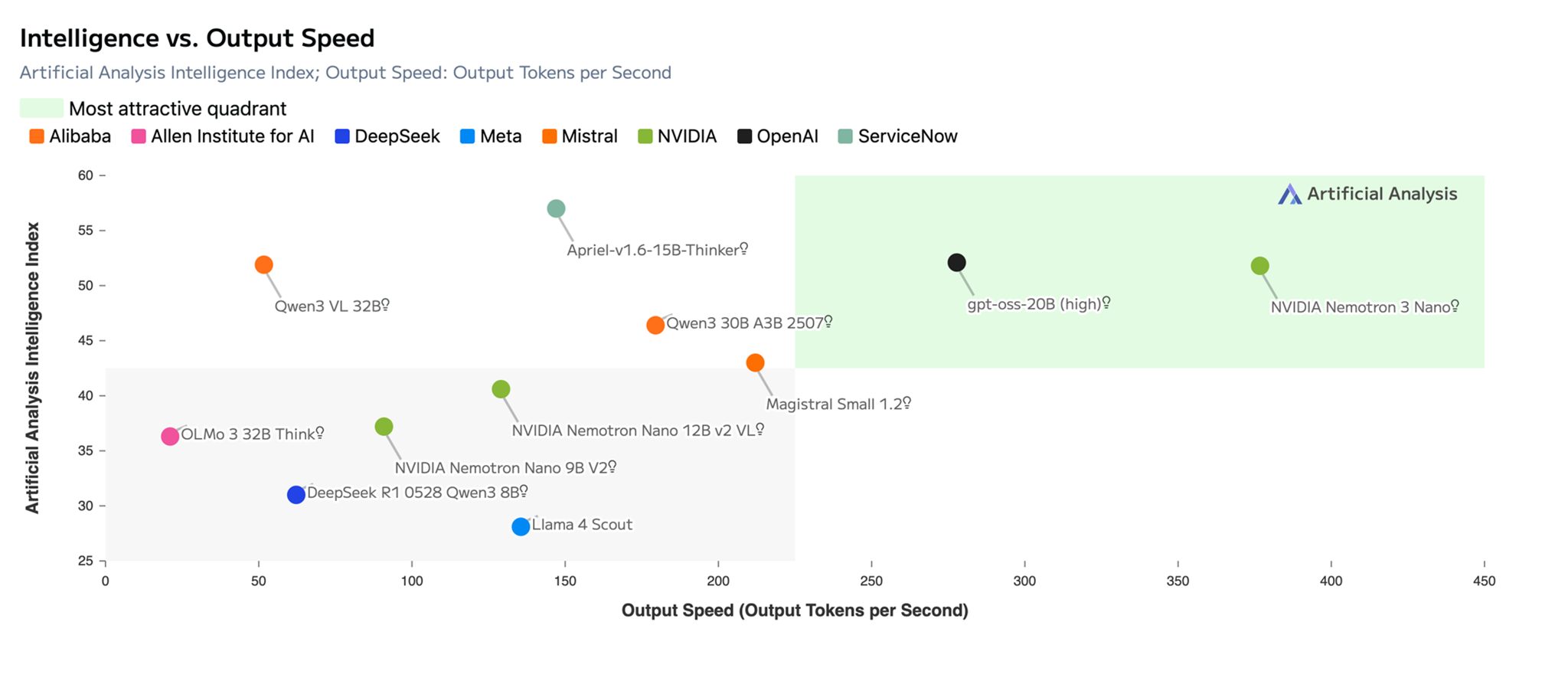
Title: NVIDIA Nemotron 3 Nano provides highest efficiency with leading accuracy among open models with an impressive 52 points score on Artificial Analysis Intelligence vs. Output Speed Index. (Source: Artificial Analysis)
NVIDIA Nemotron 3 Nano use cases
Nemotron 3 Nano helps power various use cases for different industries. Some of the use cases include
- Finance – Accelerate loan processing by extracting data, analyzing income patterns, detecting fraudulent operations, reducing cycle times, and risk.
- Cybersecurity – Automatically triage vulnerabilities, perform in-depth malware analysis, and proactively hunt for security threats.
- Software development – Assist with tasks like code summarization.
- Retail – Optimize inventory management and help enhance in-store service with real-time, personalized product recommendations and support.
Get started with NVIDIA Nemotron 3 Nano in Amazon Bedrock
To test NVIDIA Nemotron 3 Nano in Amazon Bedrock, complete the following steps:
- Navigate to the Amazon Bedrock console and select Chat/Text playground from the left menu (under the Test section).
- Choose Select model in the upper-left corner of the playground.
- Choose NVIDIA from the category list, then select NVIDIA Nemotron 3 Nano.
- Choose Apply to load the model.
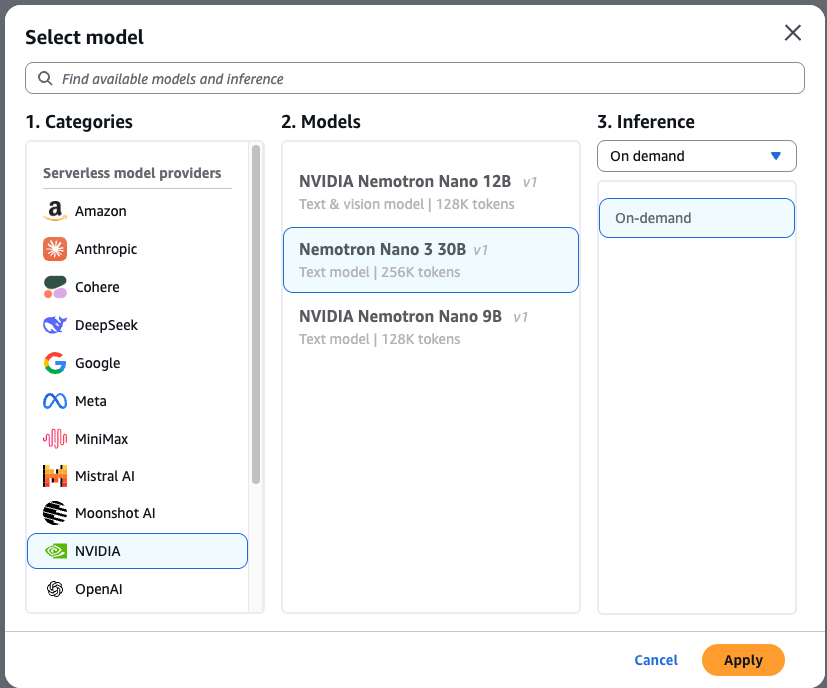
After selection, you can test the model immediately. Let’s use the following prompt to generate a unit test in Python code using the pytest framework:
Write a pytest unit test suite for a Python function called calculate_mortgage(principal, rate, years). Include test cases for: 1) A standard 30-year fixed loan 2) An edge case with 0% interest 3) Error handling for negative input values.
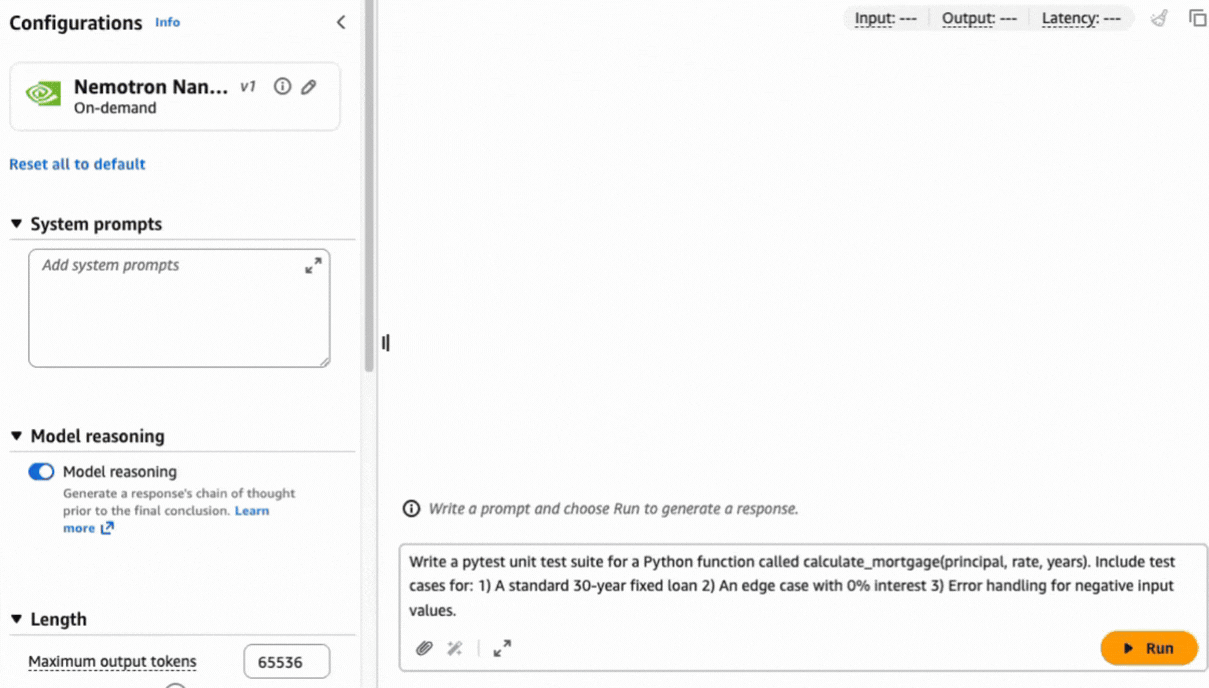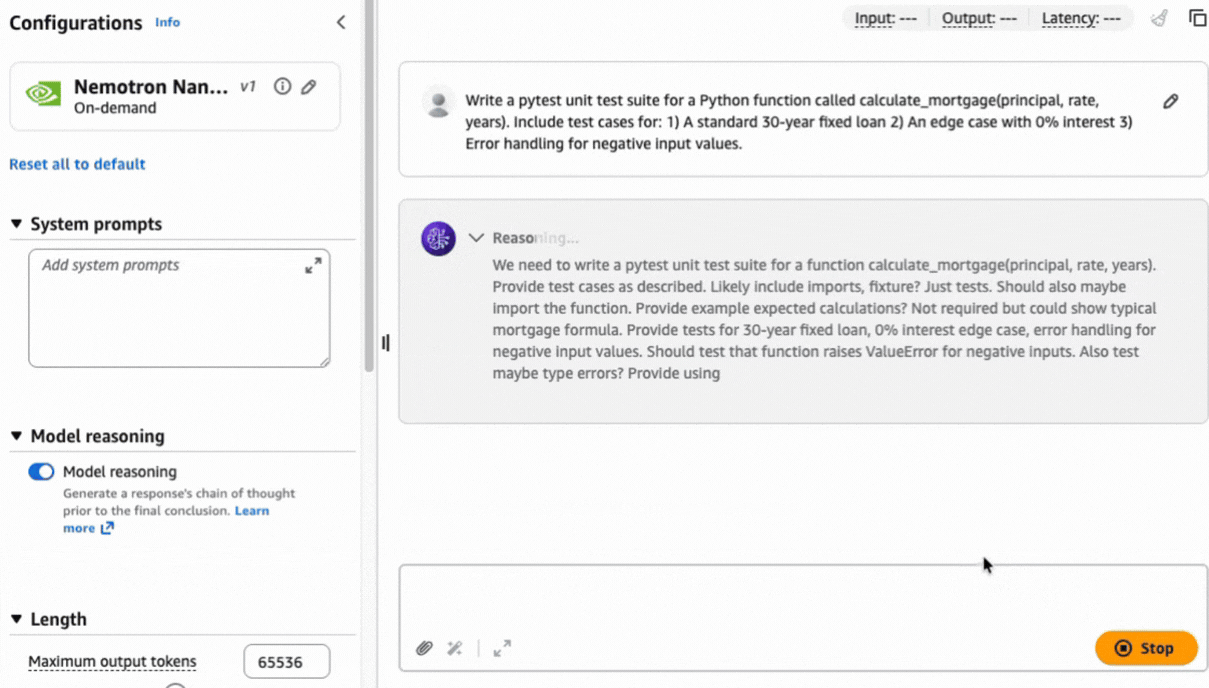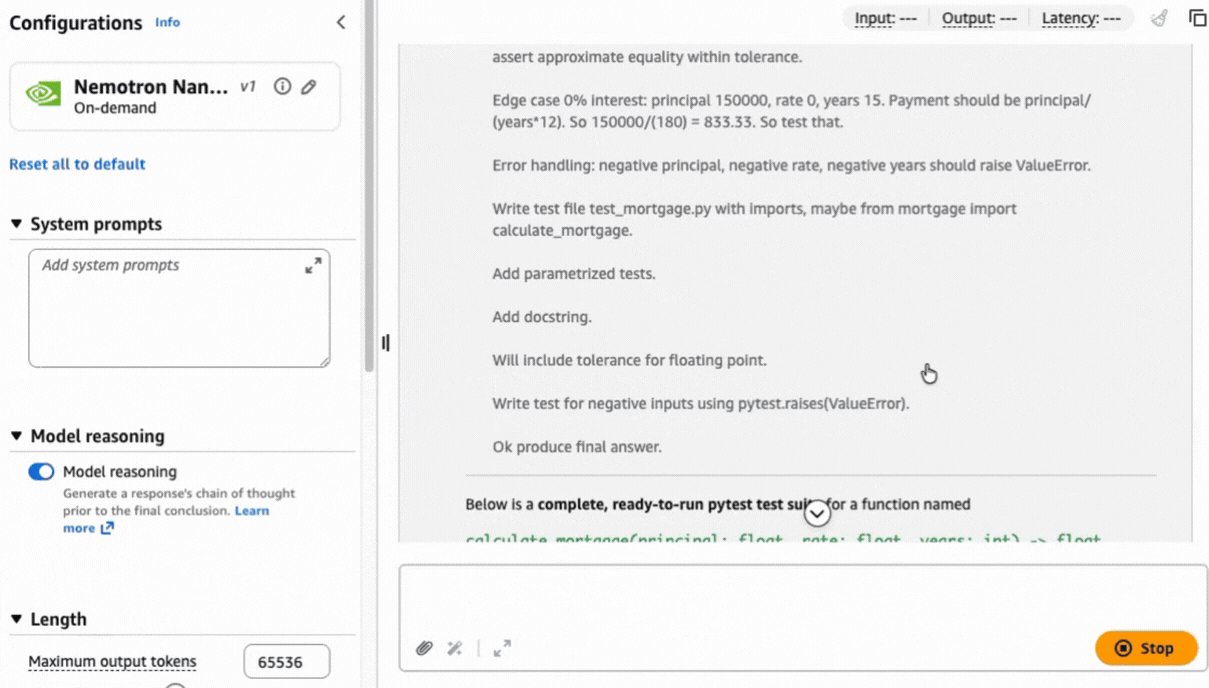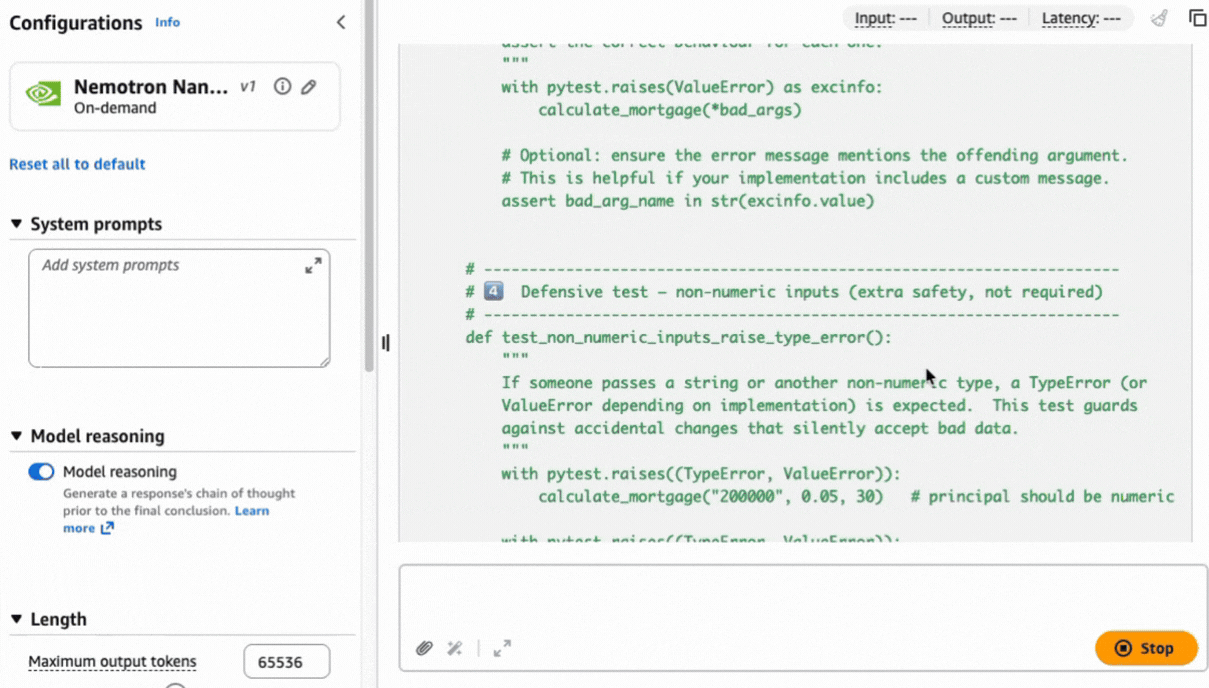
Complex tasks like this prompt can benefit from a chain of thought approach to help produce a precise result based on the reasoning capabilities built natively into the model.
Using the AWS CLI and SDKs
You can access the model programmatically using the model ID *nvidia.nemotron-nano-3-30b*. The model supports both the InvokeModel and Converse APIs through the AWS Command Line Interface (AWS CLI) and AWS SDK with *nvidia.nemotron-nano-3-30b* as the model ID. Further, it supports the Amazon Bedrock OpenAI SDK compatible API.
Run the following command to invoke the model directly from your terminal using the AWS Command Line Interface (AWS CLI) and the InvokeModel API:
aws bedrock-runtime invoke-model \
--model-id nvidia.nemotron-nano-3-30b \
--region us-west-2 \
--body '{"messages": [{"role": "user", "content": "Type_Your_Prompt_Here"}], "max_tokens": 512, "temperature": 0.5, "top_p": 0.9}' \
--cli-binary-format raw-in-base64-out \
invoke-model-output.txtTo invoke the model through the AWS SDK for Python (boto3), use the following script to send a prompt to the model, in this case by using the Converse API:
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# Set the model ID
model_id = "nvidia.nemotron-nano-3-30b"
# Start a conversation with the user message.
user_message = "Type_Your_Prompt_Here"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)To invoke the model through the Amazon Bedrock OpenAI-compatible ChatCompletions endpoint, you can do so by using the OpenAI SDK:
# Import OpenAI SDK
from openai import OpenAI
# Set environment variables
os.environ["OPENAI_API_KEY"] = ""
os.environ["OPENAI_BASE_URL"] = "https://bedrock-runtime..amazon.com/openai/v1"
# Set the model ID
model_id = "nvidia.nemotron-nano-3-30b"
# Set prompts
system_prompt = “Type_Your_System_Prompt_Here”
user_message = "Type_Your_User_Prompt_Here"
# Use ChatCompletionsAPI
response = client.chat.completions.create(
model= model _ID,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_message}
],
temperature=0,
max_completion_tokens=1000
)
# Extract and print the response text
print(response.choices[0].message.content)Use NVIDIA Nemotron 3 Nano with Amazon Bedrock features
You can enhance your generative AI applications by combining Nemotron 3 Nano with the Amazon Bedrock managed tools. Use Amazon Bedrock Guardrails to implement safeguards and Amazon Knowledge Bases to create robust Retrieval Augmented Generation (RAG) workflows.
Amazon Bedrock guardrails
Guardrails is a managed safety layer that helps enforce responsible AI by filtering harmful content, redacting sensitive information (PII), and blocking specific topics across prompts and responses. It works across multiple models to help detect prompt injection attacks and hallucinations.
Example use case: If you’re building a mortgage assistant, you can help prevent it from offering general investment advice. By configuring a filter for the word “stocks”, user prompts containing that term can be immediately blocked and receive a custom message.
To set up a guardrail, complete the following steps:
- In the Amazon Bedrock console, navigate to the Build section on the left and select Guardrails.
- Create a new guardrail and configure the necessary filters for your use case.
After configured, test the guardrail with various prompts to verify its performance. You can then fine-tune settings, such as denied topics, word filters, and PII redaction, to match your specific safety requirements. For a deep dive, see Create your guardrail.
Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases automates the complete RAG workflow. It handles ingesting content from your data sources, chunking it into searchable segments, converting them into vector embeddings, and storing them in a vector database. Then, when a user submits a query, the system matches the input against stored vectors to find semantically similar content, which is then used to augment the prompt sent to the foundation model.
For this example, we uploaded PDFs (for example, Buying a New Home, Home Loan Toolkit, Shopping for a Mortgage) to Amazon Simple Storage Service (Amazon S3) and selected Amazon OpenSearch Serverless as the vector store. The following code demonstrates how to query this knowledge base using the RetrieveAndGenerate API, while automatically facilitating safety compliance alignment through a specific Guardrail ID.
import boto3
bedrock_agent_runtime_client = boto3.client('bedrock-agent-runtime')
response = bedrock_agent_runtime_client.retrieve_and_generate(
input={
'text': 'I am interested in purchasing a home. What steps should I take to make sure I am prepared to take on a mortgage?'
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'generationConfiguration': {
'guardrailConfiguration': {
'guardrailId': '',
'guardrailVersion': '1'
}
},
'knowledgeBaseId': '',
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/nvidia.nemotron-nano-3-30b',
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": (
"You are a helpful assistant that answers questions about mortgages"
"search results.\n\n"
"Search results:\n$search_results$\n\n"
"User query:\n$query$\n\n"
"Answer clearly and concisely."
)
},
},
"orchestrationConfiguration": {
"promptTemplate": {
"textPromptTemplate": (
"You are very knowledgeable on mortgages"
"Conversation so far:\n$conversation_history$\n\n"
"User query:\n$query$\n\n"
"$output_format_instructions$"
)
}
}
},
'type': 'KNOWLEDGE_BASE'
}
)
print(response)It directs the NVIDIA Nemotron 3 Nano model to synthesize the retrieved documents into a clear, grounded answer using your custom prompt template. To set up your own pipeline, review the full walkthrough in the Amazon Bedrock User Guide.
Conclusion
In this post, we showed you how to get started with NVIDIA Nemotron 3 Nano on Amazon Bedrock for fully managed serverless inference. We also showed you how to use the model with Amazon Bedrock Knowledge Bases and Amazon Bedrock Guardrails. The model is now available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Mumbai), South America (Sao Paulo), Europe (London), and Europe (Milan) AWS Regions. Check the full Region list for future updates. To learn more, check out NVIDIA Nemotron and give NVIDIA Nemotron
関連記事
NVIDIA Cosmos World Foundation Modelsによる合成データのスケーリングと物理AI推論
ロボット動画生成のための NVIDIA Cosmos Predict 2.5 の LoRA/DoRA を用いたファインチューニング(9 分読了)
ロボット動画生成のための NVIDIA Cosmos Predict 2.5 の LoRA/DoRA を用いたファインチューニング
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み