GPT-2からgpt-ossへ:アーキテクチャの進化を分析
Sebastian Raschka は、OpenAI が GPT-2 以来初めて公開した大規模オープンウェイトモデル「gpt-oss」シリーズのアーキテクチャを分析し、ローカル実行の実現可能性や Qwen3 との比較を通じて業界への影響を解説している。
キーポイント
OpenAI のオープンウェイト戦略転換
2019 年の GPT-2 以来、OpenAI が大規模モデルの重みを公開するのは初めてであり、gpt-oss-20b と gpt-oss-120b のリリースは業界に大きな衝撃を与えている。
ローカル実行を可能にする最適化技術
MXFP4 などの巧妙な最適化技術により、これらの大規模モデルが単一の GPU で動作可能となり、エッジや個人環境での利用が現実味を帯びている。
アーキテクチャのトレードオフ分析
幅(Width)と深さ(Depth)のバランスやアテンションバイアスなどの詳細な技術的比較が行われ、Qwen3 や GPT-5 との性能差が議論されている。
業界標準アーキテクチャの確認
分析の結果、最新モデルも Transformer ベースの改良版であり、画期的な新構造ではなく、既存の成功した設計への微調整と人材流動の影響が示唆されている。
LLM における Dropout の非推奨
大規模言語モデルは大量データ上で単一エポックのみ訓練されるため過学習のリスクが低く、Dropout はむしろ下流タスクのパフォーマンスを低下させることが示されている。
RoPE の採用と絶対位置埋め込みの置換
2023 年の Llama モデル以降、トランスフォーマー型 LLM は計算効率が高く柔軟な RoPE(回転位置埋め込み)を採用し、従来の学習された絶対位置埋め込みベクトルを置き換えた。
活性化関数の GELU から Swish/SwiGLU へ
Swish は GELU に比べて計算コストがわずかに低く、モデル性能における差は統計誤差の範囲内であるため、主に計算効率を理由に採用されている。
影響分析・編集コメントを表示
影響分析
この記事は、OpenAI の戦略的転換点である「オープンウェイトモデル公開」を技術的に裏付け、単なるニュース報道を超えた実装レベルでの分析を提供しています。特にローカル実行への道筋を示す MXFP4 などの最適化技術の解説は、開発者や研究者にとって即座に活用可能な知見であり、次世代 LLM のデプロイメント戦略に影響を与える可能性があります。
編集コメント
OpenAI の長年の「クローズド」姿勢からの転換を示す歴史的なリリースを、技術的な深さで解き明かした貴重な分析記事です。ローカル環境での大規模モデル運用を検討しているエンジニアにとって必読のコンテンツと言えます。
GPT-2からgpt-ossへ:アーキテクチャの進化を分析する
そして、それらがQwen3とどう比べられるか
 Sebastian Raschka, PhDAug 09, 20256194755ShareOpenAIは今週、新しいオープンウェイトのLLM、gpt-oss-120bとgpt-oss-20bをリリースしました。これは2019年のGPT-2以来、初めてのオープンウェイトモデルです。そして、いくつかの巧妙な最適化のおかげで、ローカルで実行できるようになっています(これについては後ほど詳しく説明します)。
Sebastian Raschka, PhDAug 09, 20256194755ShareOpenAIは今週、新しいオープンウェイトのLLM、gpt-oss-120bとgpt-oss-20bをリリースしました。これは2019年のGPT-2以来、初めてのオープンウェイトモデルです。そして、いくつかの巧妙な最適化のおかげで、ローカルで実行できるようになっています(これについては後ほど詳しく説明します)。
GPT-2以来、OpenAIが大規模で完全なオープンウェイトモデルを共有するのはこれが初めてです。初期のGPTモデルは、トランスフォーマーアーキテクチャがどのようにスケールするかを示しました。2022年のChatGPTのリリースは、文章作成や知識(そして後にコーディング)タスクにおける具体的な有用性を示すことで、これらのモデルを主流のものにしました。そして今、彼らは長らく待ち望まれていたウェイトモデルを共有し、そのアーキテクチャには興味深い詳細があります。
私は過去数日間、コードと技術レポートを読み込み、最も興味深い詳細をまとめました。(そのわずか数日後、OpenAIはGPT-5も発表しました。この記事の最後で、gpt-ossモデルの文脈の中で簡単に触れます。)
以下は、この記事でカバーする内容の簡単なプレビューです。より簡単にナビゲートするために、記事ページ左側の目次を使用することをお勧めします。
GPT-2とのモデルアーキテクチャ比較
単一GPUにgpt-ossモデルを収めるためのMXFP4最適化
幅と深さのトレードオフ(gpt-oss vs Qwen3)
アテンションのバイアスとシンク
ベンチマークとGPT-5との比較
お役に立てれば幸いです!
- モデルアーキテクチャ概要
アーキテクチャについてより詳細に議論する前に、まずは下記の図1に示す、2つのモデルgpt-oss-20bとgpt-oss-120bの概要から始めましょう。
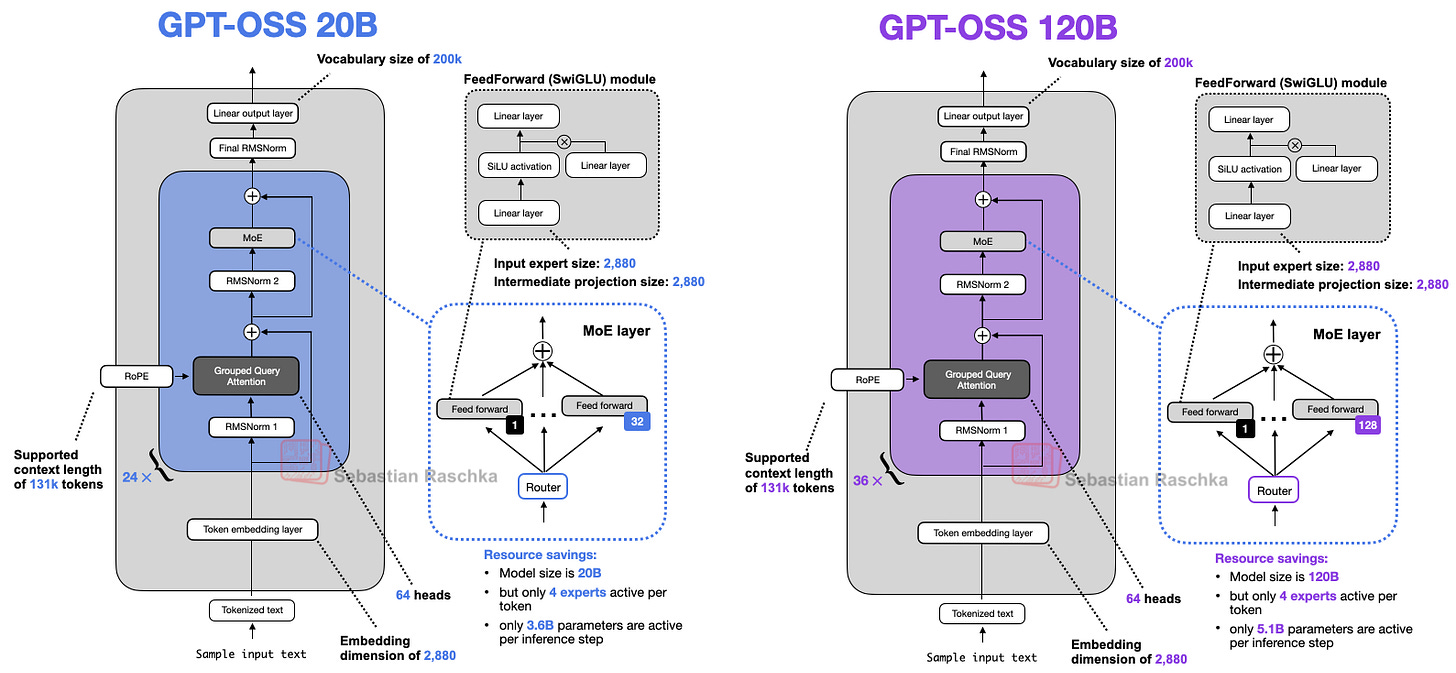 図1:2つのgpt-ossモデルを並べて表示。
図1:2つのgpt-ossモデルを並べて表示。
最近のLLMアーキテクチャ図を見たことがある方や、私の以前の「大規模アーキテクチャ比較」記事を読んだことがある方は、一見したところ目新しい点や珍しい点は何もないことに気づくかもしれません。
 大規模LLMアーキテクチャ比較
大規模LLMアーキテクチャ比較
これは驚くべきことではありません。なぜなら、主要なLLM開発者は同じ基本アーキテクチャを使用し、その後、小さな調整を加える傾向があるからです。これは私の純粋な推測ですが、その理由は以下の通りだと考えています。
これらの研究所間では、従業員の大きな流動性がある。
トランスフォーマーアーキテクチャよりも優れたものを、我々はまだ見つけていない。状態空間モデルやテキスト拡散モデルは存在するが、私の知る限り、この規模でトランスフォーマーと同等の性能を発揮することを示した者はいない。(私が見つけた比較のほとんどは、ベンチマーク性能のみに焦点を当てている。現実世界のマルチターンの文章作成やコーディングタスクをモデルがどれだけうまく処理するかは、まだ不明である。執筆時点で、LM Arenaで最もランキングの高い、純粋なトランスフォーマーベースではないモデルは、トランスフォーマーと状態空間モデルのハイブリッドであるJambaで、96位である。編集:親切な読者から、より上位のハイブリッドモデルがあると指摘があった:Hunyuan-TurboSが22位。)
大きなアーキテクチャの変更よりも、データとアルゴリズムの調整から得られる利益の方が大きい可能性が高い。
とはいえ、彼らの設計選択にはまだ多くの興味深い側面があります。そのいくつかは上の図に示されています(一方で、示されていないものもありますが、それらについても後で議論します)。この記事の残りの部分では、これらの特徴を強調し、他のアーキテクチャと一つずつ比較していきます。
また、私はOpenAIとは何の関係もないことを付記しておきます。私の情報は、公開されたモデルコードをレビューし、彼らの技術レポートを読むことから得ています。これらのモデルをローカルで使用する方法を学びたい場合は、OpenAIの公式モデルハブページから始めるのが最善です:
https://huggingface.co/openai/gpt-oss-20b
https://huggingface.co/openai/gpt-oss-120b
20Bモデルは、最大16GBのRAMを搭載したコンシューマー向けGPUで実行できます。120Bモデルは、80GBのRAMを搭載した単一のH100またはそれより新しいハードウェアで実行できます。これについては後で戻りますが、重要な注意点があります。
- GPT-2から来て
gpt-ossとより最近のアーキテクチャとの比較に飛びつく前に、タイムマシンに乗って、GPT-2(図2)を並べて見てみましょう。どれほど進歩したかを確認するためです。
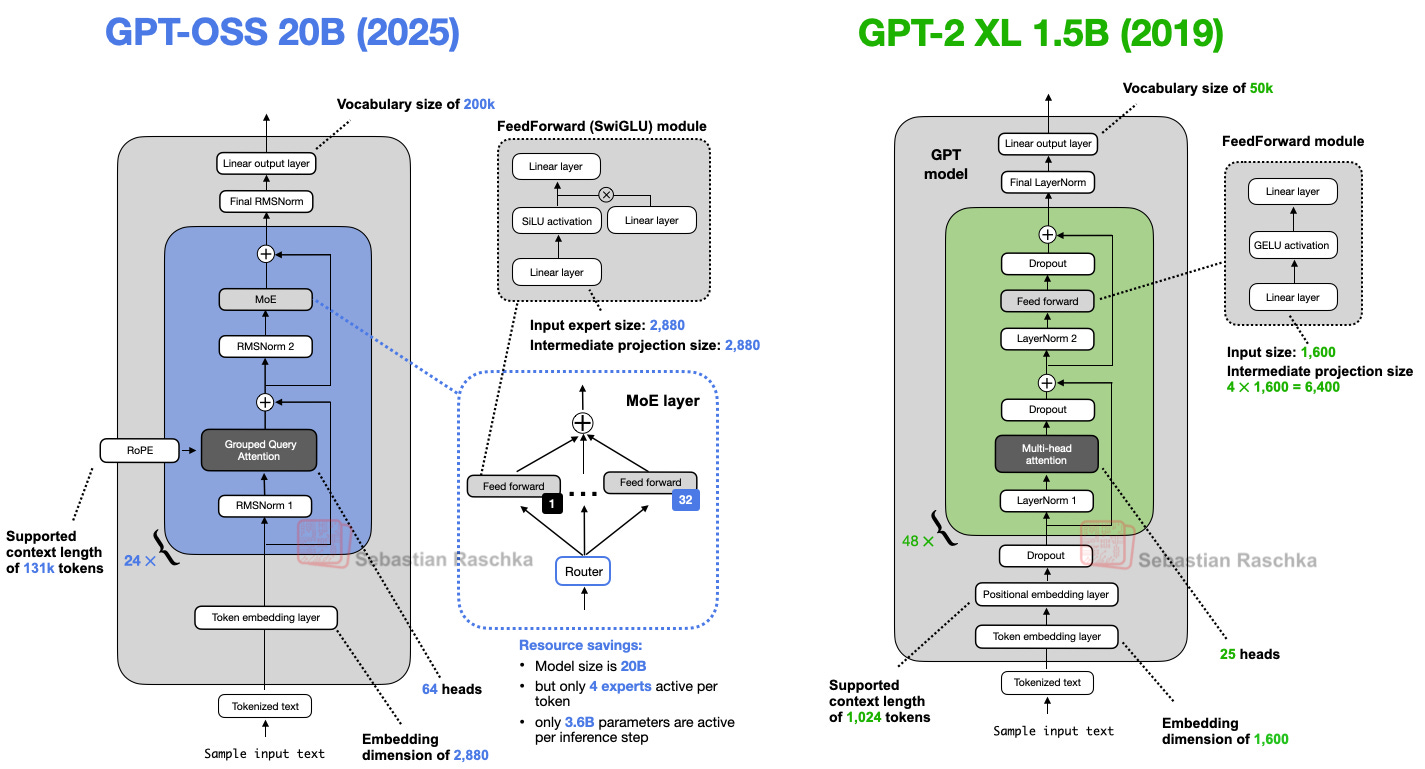 図2:gpt-oss-20bとGPT-2 XL 1.5Bの比較。
図2:gpt-oss-20bとGPT-2 XL 1.5Bの比較。
gpt-ossもGPT-2も、Attention Is All You Need(2017)論文で導入されたトランスフォーマーアーキテクチャを基にしたデコーダー専用LLMです。長年にわたり、多くの詳細が進化してきました。
しかし、これらの変更はgpt-ossに特有のものではありません。そして後で見るように、それらは他の多くのLLMにも現れます。これらの側面の多くは以前の「大規模アーキテクチャ比較」記事で議論したので、各サブセクションは簡潔に、焦点を絞って進めます。
2.1 ドロップアウトの除去
ドロップアウト(2012)は、訓練中に層の活性化やアテンションスコア(図3)の一部をランダムに「ドロップアウト」(つまりゼロに設定)することで過学習を防ぐ伝統的な技術です。しかし、ドロップアウトは現代のLLMではほとんど使用されておらず、GPT-2以降のほとんどのモデルでは(言葉遊びではありませんが)「落とされ」ました。
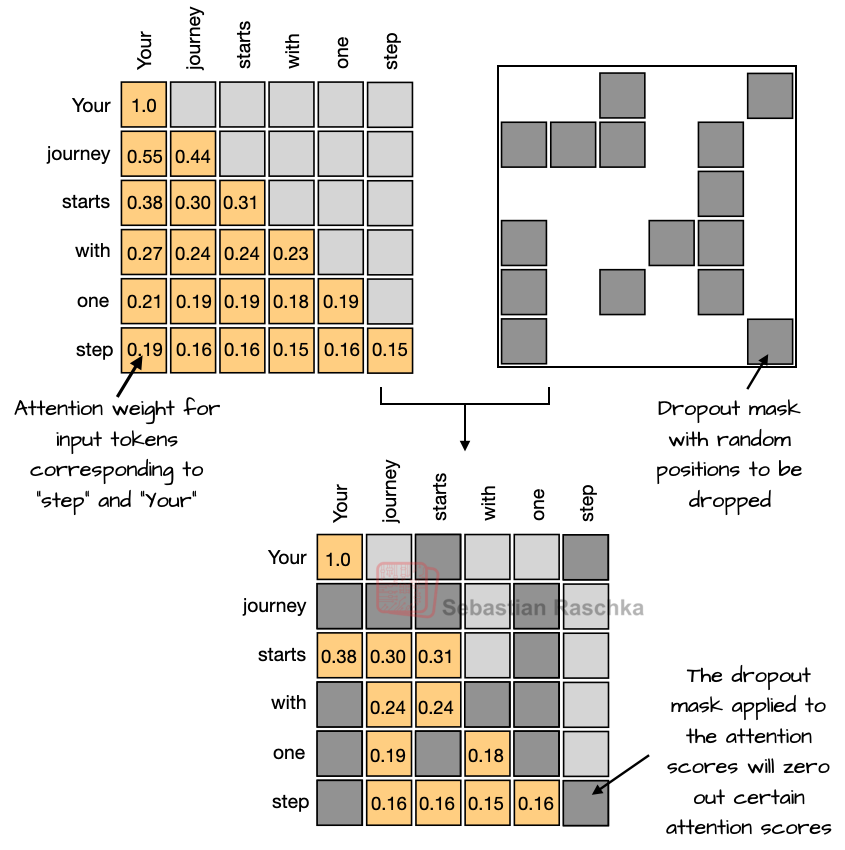 図3:アテンションスコア行列に適用されたドロップアウトの図。
図3:アテンションスコア行列に適用されたドロップアウトの図。
ドロップアウトが元々GPT-2で使用されていたのは、元のトランスフォーマーアーキテクチャから継承されたためだと私は推測します。研究者たちは、それがLLMの性能を実際には改善しないことに気づいたのでしょう(私は小規模なGPT-2の再現実験でも同じことを観察しました)。これはおそらく、LLMは通常、大規模なデータセットに対してたった1エポックしか訓練されないのに対し、ドロップアウトが最初に導入されたのは数百エポックに及ぶ訓練体制だったためです。したがって、LLMは訓練中に各トークンを一度しか見ないため、過学習のリスクはほとんどありません。
興味深いことに、ドロップアウトはLLMアーキテクチャ設計において何年も無視されてきましたが、私は2025年の研究論文(小規模LLM実験、Pythia 1.4B)で、このような単一エポック体制ではドロップアウトが下流タスクの性能を悪化させることを確認したものを見つけました。
2.2 絶対的位置埋め込みに代わるRoPE
トランスフォーマーベースのLLMでは、アテンションメカニズムのために位置エンコーディングが必要です。デフォルトでは、アテンションは入力トークンに順序がないかのように扱います。元のGPTアーキテクチャでは、絶対的位置埋め込みがこれに対処しました。シーケンス内の各位置に対して学習された埋め込みベクトル(図4)を追加し、それをトークン埋め込みに加算するという方法です。
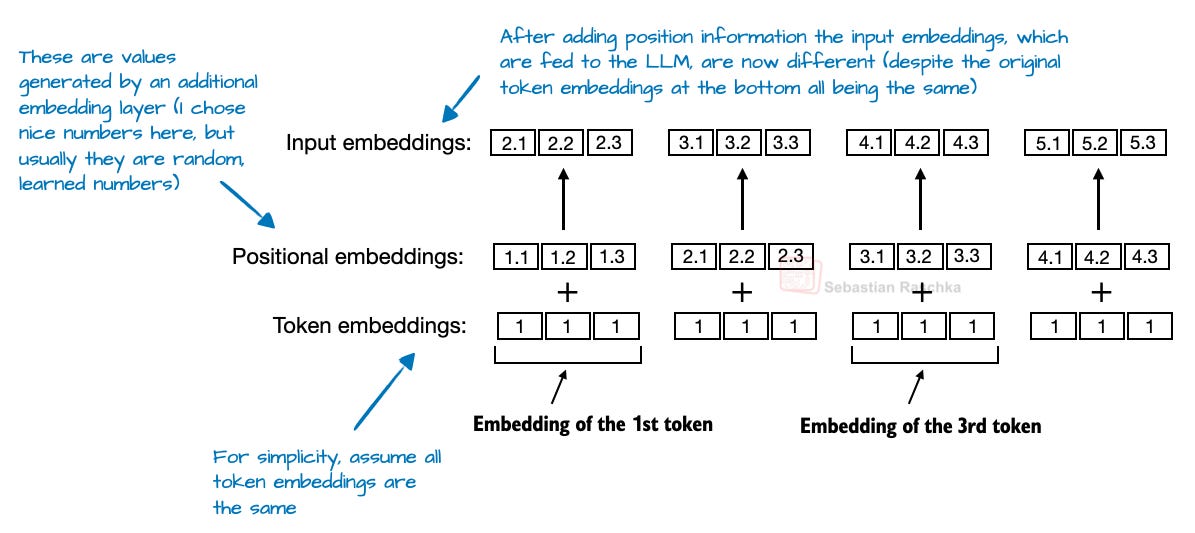 図4:絶対的位置埋め込みの図。
図4:絶対的位置埋め込みの図。
RoPE(Rotary Position Embedding)は異なるアプローチを導入しました:位置情報を別個の埋め込みとして追加する代わりに、各トークンの位置に依存する方法でクエリとキーベクトルを回転させることで位置をエンコードします。(RoPEはエレガントなアイデアですが、説明するのが少し難しいトピックでもあります。私は…(続く)
原文を表示
From GPT-2 to gpt-oss: Analyzing the Architectural Advances
And How They Stack Up Against Qwen3
Sebastian Raschka, PhDAug 09, 20256194755ShareOpenAI just released their new open-weight LLMs this week: gpt-oss-120b and gpt-oss-20b, their first open-weight models since GPT-2 in 2019. And yes, thanks to some clever optimizations, they can run locally (but more about this later).
This is the first time since GPT-2 that OpenAI has shared a large, fully open-weight model. Earlier GPT models showed how the transformer architecture scales. The 2022 ChatGPT release then made these models mainstream by demonstrating concrete usefulness for writing and knowledge (and later coding) tasks. Now they have shared some long-awaited weight model, and the architecture has some interesting details.
I spent the past few days reading through the code and technical reports to summarize the most interesting details. (Just days after, OpenAI also announced GPT-5, which I will briefly discuss in the context of the gpt-oss models at the end of this article.)
Below is a quick preview of what the article covers. For easier navigation, I recommend using the Table of Contents on the left of on the article page.
Model architecture comparisons with GPT-2
MXFP4 optimization to fit gpt-oss models onto single GPUs
Width versus depth trade-offs (gpt-oss vs Qwen3)
Attention bias and sinks
Benchmarks and comparisons with GPT-5
I hope you find it informative!
- Model Architecture Overview
Before we discuss the architecture in more detail, let's start with an overview of the two models, gpt-oss-20b and gpt-oss-120b, shown in Figure 1 below.
Figure 1: The two gpt-oss models side by side.
If you have looked at recent LLM architecture diagrams before, or read my previous Big Architecture Comparison article, you may notice that there is nothing novel or unusual at first glance.
The Big LLM Architecture Comparison
This is not surprising, since leading LLM developers tend to use the same base architecture and then apply smaller tweaks. This is pure speculation on my part, but I think this is because
There is significant rotation of employees between these labs.
We still have not found anything better than the transformer architecture. Even though state space models and text diffusion models exist, as far as I know no one has shown that they perform as well as transformers at this scale. (Most of the comparisons I found focus only on benchmark performance. It is still unclear how well the models handle real-world, multi-turn writing and coding tasks. At the time of writing, the highest-ranking non-purely-transformer-based model on the LM Arena is Jamba, which is a transformer–state space model hybrid, at rank 96. EDIT: Someone kindly pointed out that there's a higher-ranking hybrid model: Hunyuan-TurboS at rank 22.)
Most of the gains likely come from data and algorithm tweaks rather than from major architecture changes.
That being said, there are still many interesting aspects of their design choices. Some are shown in the figure above (while others are not, but we will discuss them later as well). In the rest of this article, I will highlight these features and compare them to other architectures, one at a time.
I should also note that I am not affiliated with OpenAI in any way. My information comes from reviewing the released model code and reading their technical reports. If you want to learn how to use these models locally, the best place to start is OpenAI's official model hub pages:
https://huggingface.co/openai/gpt-oss-20b
https://huggingface.co/openai/gpt-oss-120b
The 20B model can run on a consumer GPU with up to 16 GB of RAM. The 120B model can run on a single H100 with 80 GB of RAM or newer hardware. I will return to this later, as there are some important caveats.
- Coming From GPT-2
Before we jump into comparisons between gpt-oss and a more recent architecture, let's hop into the time machine and take a side-by-side look at GPT-2 (Figure 2) to see just how far things have come.
Figure 2: A side-by-side comparison between gpt-oss-20b and GPT-2 XL 1.5B.
Both gpt-oss and GPT-2 are decoder-only LLMs built on the transformer architecture introduced in the Attention Is All You Need (2017) paper. Over the years, many details have evolved.
However, these changes are not unique to gpt-oss. And as we will see later, they appear in many other LLMs. Since I discussed many of these aspects in the previous Big Architecture Comparison article, I will try to keep each subsection brief and focused.
2.1 Removing Dropout
Dropout (2012) is a traditional technique to prevent overfitting by randomly "dropping out" (i.e., setting to zero) a fraction of the layer activations or attention scores (Figure 3) during training. However, dropout is rarely used in modern LLMs, and most models after GPT-2 have dropped it (no pun intended).
Figure 3: An illustration of dropout applied to the attention score matrix.
I assume that dropout was originally used in GPT-2 because it was inherited from the original transformer architecture. Researchers likely noticed that it does not really improve LLM performance (I observed the same in my small-scale GPT-2 replication runs). This is likely because LLMs are typically trained for only a single epoch over massive datasets, which is in contrast to the multi-hundred-epoch training regimes for which dropout was first introduced. So, since LLMs see each token only once during training, there is little risk of overfitting.
Interestingly, while Dropout is kind of ignored in LLM architecture design for many years, I found a 2025 research paper with small scale LLM experiments (Pythia 1.4B) that confirms that Dropout results in worse downstream performance in these single-epoch regimes.
2.2 RoPE Replaces Absolute Positional Embeddings
In transformer-based LLMs, positional encoding is necessary because of the attention mechanism. By default, attention treats the input tokens as if they have no order. In the original GPT architecture, absolute positional embeddings addressed this by adding a learned embedding vector for each position in the sequence (Figure 4), which is then added to the token embeddings.
Figure 4: Illustration of absolute positional embeddings.
RoPE (Rotary Position Embedding) introduced a different approach: instead of adding position information as separate embeddings, it encodes position by rotating the query and key vectors in a way that depends on each token's position. (RoPE is an elegant idea but also a bit of a tricky topic to explain. I plan to cover separately in more detail one day.)
While first introduced in 2021, RoPE became widely adopted with the release of the original Llama model in 2023 and has since become a staple in modern LLMs.
2.3 Swish/SwiGLU Replaces GELU
Early GPT architectures used GELU. Why now use Swish over GELU? Swish (also referred to as sigmoid linear unit or SiLU) is considered computationally slightly cheaper, and in my opinion, that all there is to it. Depending on which paper you look at, you will find that one is slightly better than the other in terms of modeling performance. In my opinion, these small differences are probably within a standard error, and your mileage will vary based on hyperparameter sensitivity.
Activation functions used to be a hot topic of debate until the deep learning community largely settled on ReLU more than a decade ago. Since then, researchers have proposed and tried many ReLU-like variants with smoother curves, and GELU and Swish (Figure 5) are the ones that stuck.
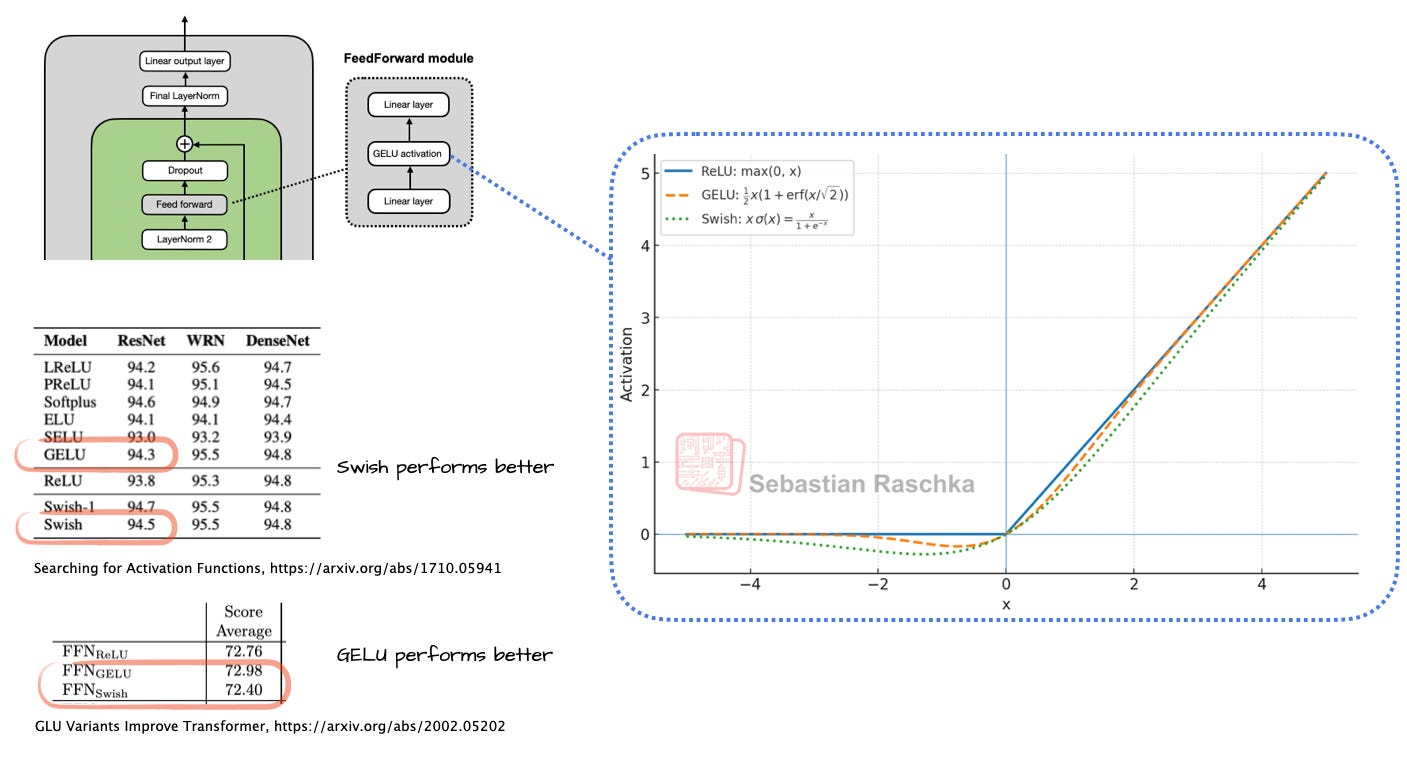 Figure 5: Comparison between Swish and GELU activations, which are both smoother versions or ReLU.
Figure 5: Comparison between Swish and GELU activations, which are both smoother versions or ReLU.
Early GPT architectures used GELU, which is defined as 0.5x * [1 + erf(x / sqrt(2))]
In practice, Swish is computationally slightly cheaper than GELU, and that's probably the main reason it replaced GELU in most newer models. Depending on which paper we look at, one might be somewhat better in terms of modeling performance. But I'd say these gains are often within standard error, and the winner will depend heavily on hyperparameter tuning.
Swish is used in most architectures today. However, GELU is not entirely forgotten; for example, Google's Gemma models still use GELU.
What's more notable, though, is that the feed forward module (a small multi-layer perceptron) is replaced by a gated "GLU" counterpart, where GLU stands for gated linear unit and was proposed in a 2020 paper. Concretely, the 2 fully connected layers are replaced by 3 fully connected layers that are used as shown in Figure 6 below.
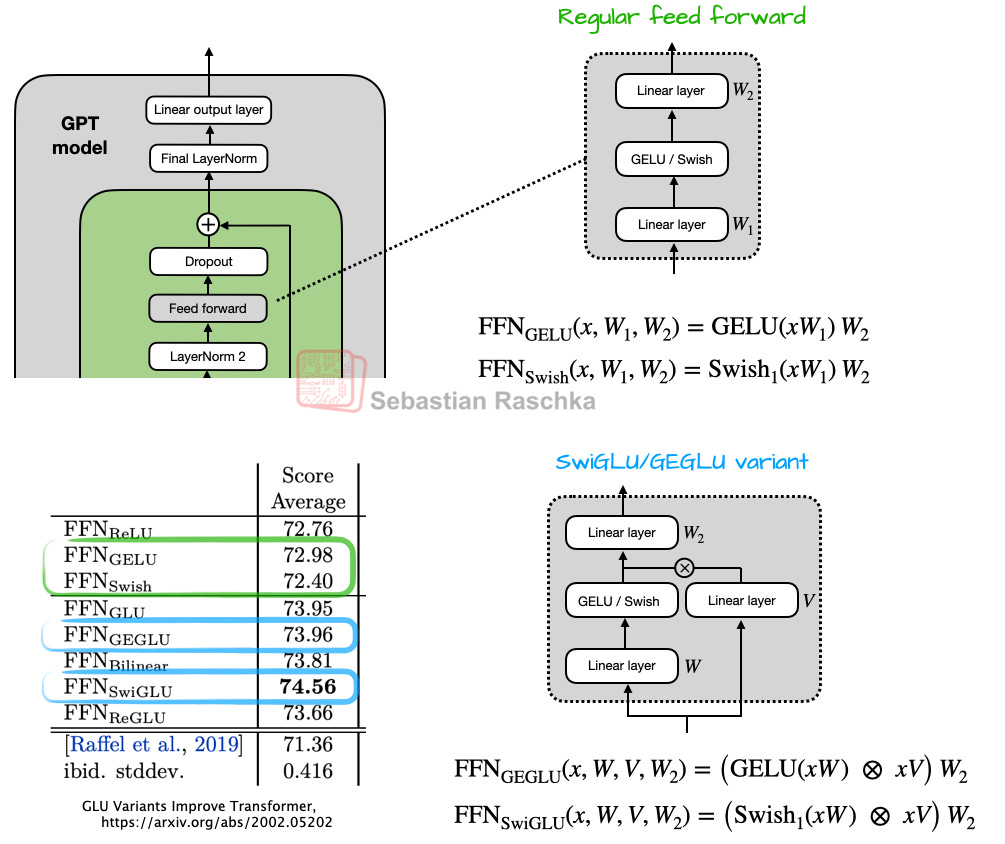 Figure 6: A comparison between Swish and GELU and their gated counterparts, SwiGLU and GEGLU.
Figure 6: A comparison between Swish and GELU and their gated counterparts, SwiGLU and GEGLU.
At first glance, it may appear that the GEGLU/SwiGLU variants may be better than the regular feed forward layers because there are simply more parameters due to the extra layer. But this is deceiving because in practice, the W
To illustrate this better, consider the concrete code implementations of the regular and GLU variants:
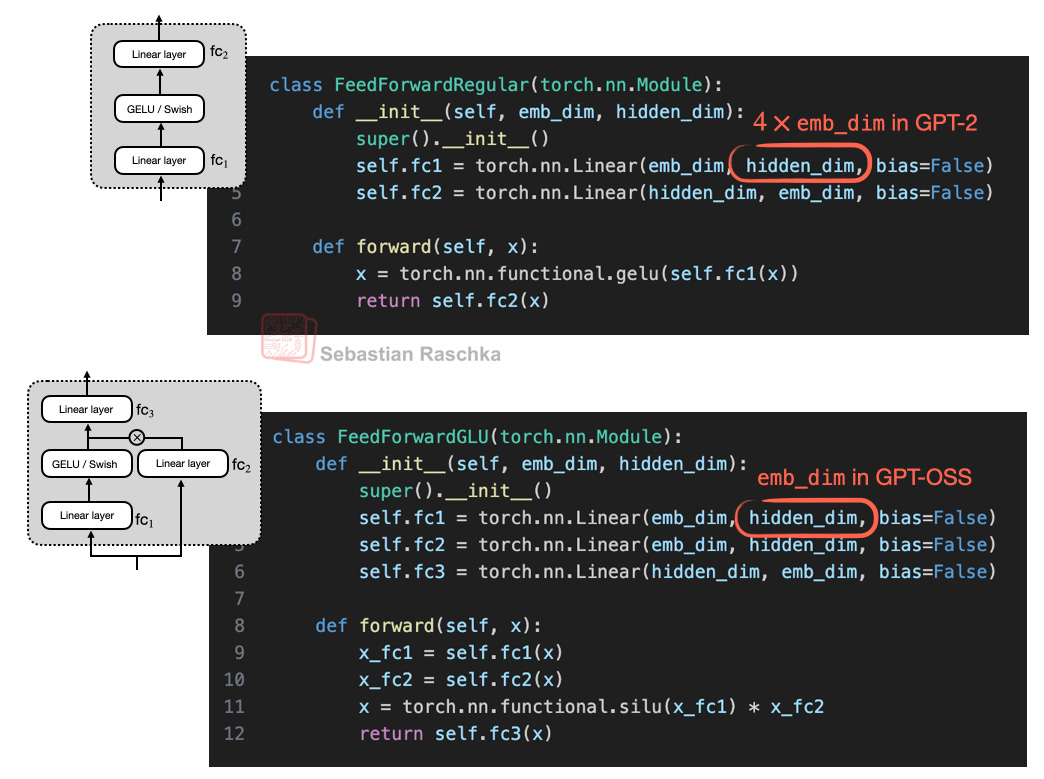 Figure 7: Regular feed forward module (top) and SwiGLU variant (bottom) next to each other. Note that the Swish function is implemented as “silu” in PyTorch.
Figure 7: Regular feed forward module (top) and SwiGLU variant (bottom) next to each other. Note that the Swish function is implemented as “silu” in PyTorch.
So, suppose we have an embedding dimension of 1024. In the regular feed forward case, this would then be
fc1: 1024 × 4096 = 4,194,304
fc2: 1024 × 4096 = 4,194,304
That is fc1 + fc2 = 8,388,608 parameters.
For the GLU variant, we have
fc1: 1024 × 1024 = 1,048,576
fc2: 1024 × 1024 = 1,048,576
fc3: 1024 × 1024 = 1,048,576
I.e., 3 × 1,048,576 = 3,145,728 weight parameters.
So, overall, using the GLU variants results in fewer parameters, and they perform better as well. The reason for this better performance is that these GLU variants provide an additional multiplicative interaction, which improves expressivity (the same reason deep & slim neural nets perform better than shallow & wide neural nets,
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み