Loka が Amazon Nova 2 Sonic を活用した低遅延・自然な音声エージェントを構築
Loka は Amazon Nova 2 Sonic を活用したネイティブ音声対音声モデルにより、従来のパイプライン型 AI が抱える遅延とコストの問題を解決し、自然で低遅延な顧客対応を実現した。
キーポイント
従来型音声アシスタントの課題
STT→LLM→TTS の三段階パイプラインによる累積的な遅延(3〜5秒)と、テキスト変換過程での感情・文脈情報の喪失が、自然な対話体験を阻害し、顧客離れやコスト増の原因となっている。
ネイティブ音声対音声モデルの導入
Amazon Nova 2 Sonic のような「音声入力→音声出力」を直接行うモデルを採用することで、中間処理ステップを排除し、リアルタイム性の高い自然な応答を実現した。
コストと精度の両立
AWS 基盤上で構築されたこのアーキテクチャは、Big Bench Audio などのベンチマークで高い推論精度を維持しつつ、従来のリアルタイム音声システムよりも大幅に低コストかつ高速な応答を実現している。
複雑な文脈の理解
自動販売店のシナリオのように、否定形や時間制約など複数の情報を同時に処理する複雑な顧客の要求に対し、音声のままの文脈を保持することで正確に解釈し、即座に対応できる。
影響分析・編集コメントを表示
影響分析
この事例は、音声 AI のアーキテクチャが従来の「テキスト経由」から「ネイティブ音声処理」へ転換する重要な転換点を示しています。これにより、実世界の複雑な対話シナリオにおけるリアルタイム性とコスト効率性が劇的に向上し、コールセンターやカスタマーサポート分野での AI 導入障壁を大幅に下げる可能性があります。
編集コメント
音声 AI の遅延問題は長年の課題でしたが、ネイティブモデルの登場により「会話の自然さ」と「コスト効率」を両立させる道が開かれました。実装事例として非常に参考になるケーススタディです。
Loka は、Amazon Nova 2 Sonic を活用した会話型 AI エージェントを構築することで、顧客との音声対話を革新し、自然で応答性の高い体験を通じて顧客の関与を維持しています。彼らの AWS ベースのソリューションは、Big Bench Audio において高い音声推論精度を実現すると同時に、従来の音声 AI パイプラインと比較して大幅なコスト削減と応答時間の短縮をもたらします。本稿では、ロボットのようであり遅い音声アシスタントが顧客に電話を切られさせ、ブランドの評判を損ない、サポートコストを増大させるという一般的な課題に対し、Loka がどのようにアーキテクチャとアプローチで解決したかを紹介していきます。
従来の音声アシスタントの限界
従来の音声アシスタントは、根本的な問題を生み出す 3 つのステップのプロセスに従います。まず、音声認識システム(Speech-to-Text)を使用して、お客様の発話をテキストに変換します。次に、そのテキストを大規模言語モデル(LLM: Large Language Model)で処理します。最後に、テキスト応答をテキスト読み上げ技術(Text-to-Speech)を用いて再び音声に変換します。このパイプラインは各ステップで遅延が重なり合います。その結果、応答を聞くまでに通常 3 秒から 5 秒の一時停止が生じます。この遅延は、自然な会話という感覚を損なってしまいます。また、アシスタントへの割り込みや訂正を試みるときにも、ぎこちなくイライラするものにしてしまいます。
自動車ディーラーでの実際のシナリオを考えてみましょう。顧客が電話をかけて、「広告に出ているあの SUV を探しているのですが、ハイブリッド車ではなく、午後 5 時以降しか来られません」と言います。アシスタントは複数の情報を同時に解析する必要があります。意図、否定、スケジュールの制約を理解しなければなりません。従来のシステムはこの複雑さに苦戦します。なぜなら、変換過程で重要な情報が失われてしまうからです。トーン、ためらい、緊急性は、音声からテキストに変換される際に消えてしまいます。ディーラーという文脈において、これらの限界が痛烈に浮き彫りになります。顧客は電話をかければ即座に役立つ回答を期待します。販売の会話の中で 5 秒の一時停止は永遠のように感じられます。さらに悪いことに、アシスタントが誤解して確認が必要になると、遅延が重畳します。会話は有益なものではなく、退屈なもので終わってしまいます。
技術的な遅延に加えて、経済的な問題もあります。数千もの場所に対応するには厳格なコスト管理が必要です。従来のリアルタイム音声システムは、特に連続するオーディオストリームを処理する場合、スケールすると費用対効果が著しく低下し、実用的でなくなる可能性があります。体験の質の低さと高コストという組み合わせが、音声 AI の普及を制限してきました。企業にはより良いソリューションが必要なのです。
ネイティブ音声対音声モデル
AI の最近の進展により、根本的に異なるアプローチが可能になりました。開発者は今や、理解、推論、生成を統合システムとして処理する音声対音声モデルにオーディオストリームを直接送信できます。オーディオをエンドツーエンドで処理することで、これらのモデルは従来のテキスト専用パイプラインでは見逃されるトーン、感情、微妙な手がかりを捉えることができます。
このアプローチを検証するには、厳格なテストが不可欠でした。私たちは、音声入力に対する推論能力を測定するベンチマークである Big Bench Audio を使用しました。Amazon Nova 2 Sonic は、音声推論スコアで 87.0 を達成しました。これは、71.0 の Gemini 2.5 Flash Native Audio (Live API) や、83.0 の GPT Realtime を上回る結果でした。これらのスコアは、ネイティブオーディオ処理が速度のために知能を犠牲にしないことを確認するものでした。このモデルは、実際の販売店シナリオにおける複雑で多段階の要求もリアルタイムで処理できました。
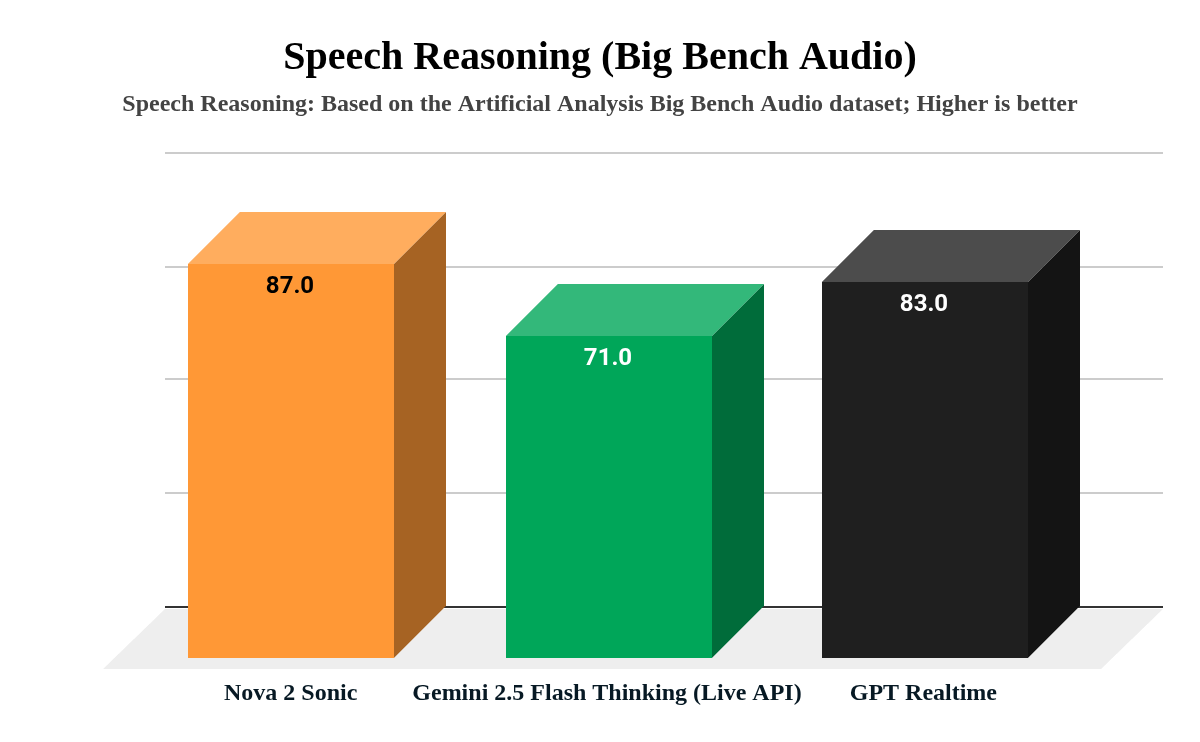
*図 1 – 音声推論スコアの比較 – Big Bench Audio*
推論能力だけでは、本番システムには不十分です。レイテンシ(応答遅延)が会話の自然さやロボットっぽさを決定します。Nova 2 Sonic は、最初の音声出力までの時間を 1.39 秒で達成しました。この応答速度により、自然な「バージイン」動作が可能になります。ユーザーが会話を中断した場合でも、音声エージェントは自然に対応します。この体験は人間の会話パターンと一致しています。
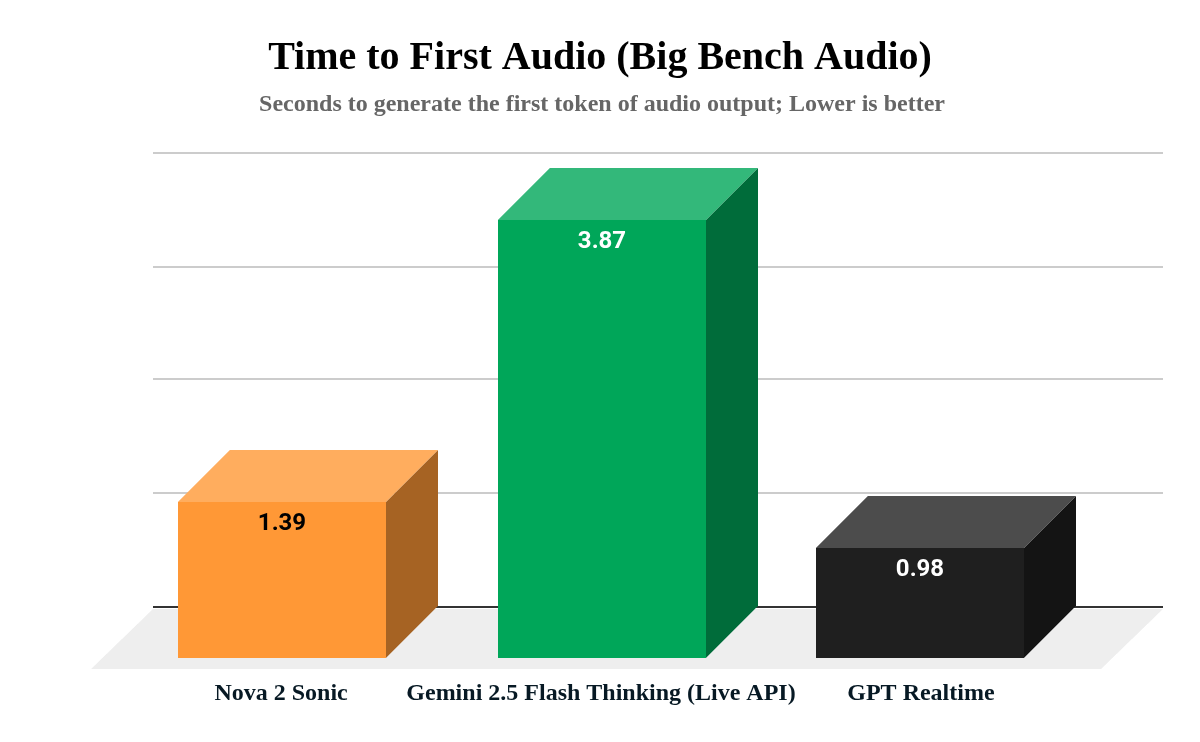
*図 2 – 最初の音声出力までの時間比較 – Big Bench Audio*
コスト効率も向上しました。Nova 2 Sonic の料金は、入力音声あたり約 1 時間 0.27 ドルです(公開時点の価格に基づく)。これは、同等のリアルタイムモデルや従来の手法よりも低コストです。
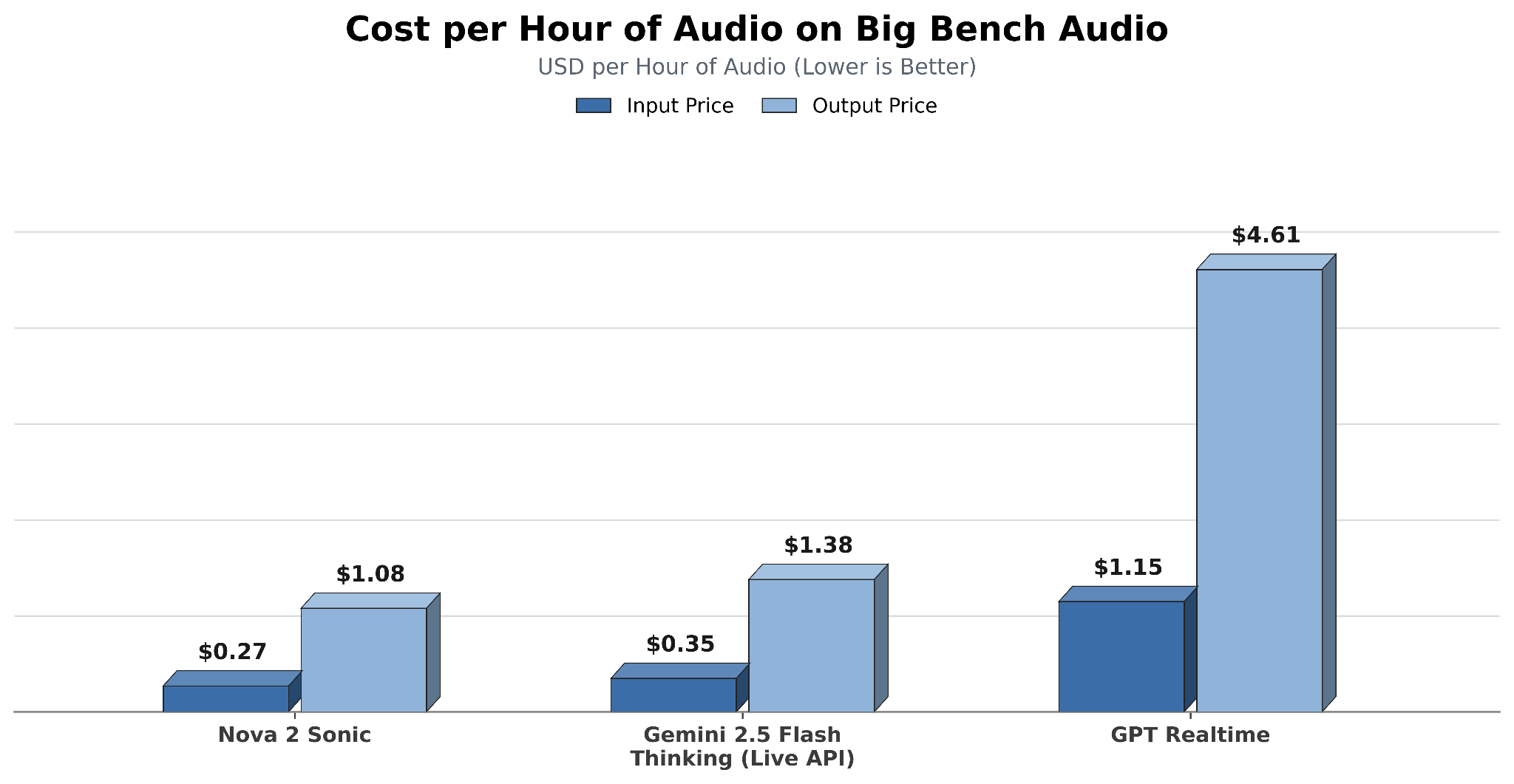
*図 3 – 音声あたりの時間別料金比較 – Big Bench Audio*
遅延やコストを超えた品質を測定するため、構造化された評価が必要でした。そこで、LLM をジャッジとして用いた自動化パイプラインを構築しました。各会話は 1 から 5 のスケールで 5 つの次元について採点されました。「応答の適切性」は、返信が関連性があり文脈的に正しいかどうかを測定します。「意図理解」は、エージェントがユーザーの根本的な目的を理解しているかを評価します。「完全性」は、必要な情報やアクションが提供されたかを追跡します。「会話的自然さ」は、流れ、ターン取り、トーン、人間らしさを測定します。
Amazon Nova Sonic と Amazon Nova 2 Sonic を比較すると、明確な進歩が見られました。応答の適切性は 2.5 から 2.9 に向上しました。意図理解は 2.9 から 3.0 に上昇しました。最も顕著なのは、完全性が 1.8 から 2.5 に跳ね上がったことです。これは、エージェントが複雑なタスクを完了する可能性が格段に高まったことを意味します。会話的自然さは 2.5 から 2.8 に改善されました。総合スコアは 2.4 から 2.7 に増加しました。これらの向上は、ディーラーにおける顧客成果の直接的な改善につながりました。
指標 (1-5 スケール)
Nova Sonic (ベースライン)
Nova 2 Sonic
変化
応答の適切性
2.5
2.9
+0.4
意図理解
2.9
3.0
+0.1
完全性
1.8
2.5
+0.7
会話的自然さ
2.5
2.8
+0.3
総合ジャッジスコア
2.4
2.7
+0.3
*表1 – 5 つの次元における音声対音声モデルのメトリクス比較*
会話型 AI エージェントのエンジニアリング
強力な基盤モデルを有する中で、次の課題は最適化でした。私たちはプロンプトをコードのように扱い、測定されたパフォーマンスに基づいて反復しました。ベースラインとなる Nova 2 Sonic の構成スコアは全体で 2.7 でした。最初のプロンプト改良後、スコアは 3.1 に上昇しました。2 回目の反復では 5.0 中 3.8 を達成しています。この改善は、より優れたターン制御と繰り返し抑制によるものです。エージェントは、話す時、聞く時、そして確認質問をするべき時を学習しました。
構成
応答
適切性
意図理解
完全性
エラー回復
会話的
自然さ
全体
審査員スコア
Amazon Nova 2 Sonic (ベースライン)
2.9
3.0
2.5
2.6
2.8
2.7
Amazon Nova 2 Sonic (プロンプト v1)
3.2
3.3
3.0
2.8
3.9
3.1
Amazon Nova 2 Sonic (プロンプト v2)
3.7
3.9
3.9
3.8
4.1
3.8
*表2 – プロンプト強化後の 5 つの次元における音声対音声モデルのメトリクス比較*
チームはベースラインプロンプトをいくつかの側面で強化し、2 つのプロンプトテンプレートへと進化させました。ハードコードされたディーラーの詳細情報を、{assistant_name} や {dealership_address} といったテンプレート化された変数に置き換えることで、この変更によりどのディーラーでも再利用可能なプロンプトとなりました。
チームは書式を番号付きリストから、明確な見出しの下にある箇条書きへと移行しました。「ツール使用ルール」「エラー回復」「会話の終了」などの見出しが、モデルに対してより明確な行動境界を与えました。この構造により、トピック間の指示の混同(インストラクション・ブリード)が減少しました。
チームはプロンプト全体に具体的な行動例を追加しました。これらの例では、通話者の発言をそのまま繰り返さずにどう acknowledgments を行うかを具体的に示しています。また、すべての返信前にモデルが自己監査を行うよう促す事前チェックリストも導入されました。
Amazon Bedrock Prompt Management は、このライフサイクル全体にとって自然な拠点となりました。これにより、チームは各テンプレートバージョンを一意の Amazon Resource Name (ARN) で保存できるようになりました。アプリケーションコードを変更することなく、変更内容をドラフトから本番環境へプロモートすることが可能になります。
新しいディーラーがオンボーディングされる際、その固有の変数は Amazon Bedrock API を通じてランタイム時に注入されます。これにより、コアとなるプロンプトはすべてのクライアントに対して共通して提供されながら、完全にカスタマイズ可能という状態を維持しています。
チームは、プロンプトの変更を作者、承認者、またはデプロイする者を制限するために AWS Identity and Access Management (AWS IAM) のアクセス制御を追加しました。これにより、以前は非公式な編集プロセスであったものに、適切なガバナンス層が導入されました。
このアプローチにより、プロンプトエンジニアリングは単発のタスクから、反復可能で監査可能なワークフローへと変化しました。ディーラー数とユースケースが増えるにつれて、このワークフローもスケールしていきました。
実世界でのテストには、実際のディーラー通話に匹敵するエッジケースが必要でした。怒った顧客、忙しい親、おしゃべりな顧客、混乱した顧客、そして高齢の電話客を想定してテストを行いました。
「忙しい親」シナリオは 5 つの次元すべてで 5.0 のスコアを獲得しました。エージェントは割り込み、背景ノイズ、時間的プレッシャーを完璧に処理しました。「怒った顧客」ケースでは全体として 4.5 のスコアでした。エージェントは冷静さを保ち、共感的かつ解決策指向の対応を行いました。「混乱した顧客」シナリオも 4.5 のスコアでした。エージェントは威圧的に聞こえることなく、忍耐強く説明を澄清しました。
チャット例
回答の適切性
意図の理解
完全性
エラー回復
会話的自然さ
全体評価スコア
怒った顧客
4.5
4.5
4.0
4.5
4.5
4.5
忙しい親の顧客
5.0
5.0
5.0
5.0
5.0
5.0
おしゃべりな顧客
3.5
3.0
2.5
2.0
4.0
3.0
混乱した顧客
4.5
4.5
4.5
5.0
4.5
4.5
高齢の顧客
3.5
3.0
2.5
2.0
4.0
3.0
平均
4.2
4.0
3.7
3.7
4.4
4.0
*表 3 – 顧客ペルソナに基づく音声対音声モデルの評価*
2 つのシナリオで、さらなる改善の余地が明らかになりました。チャット好きな顧客と高齢の顧客のケースはどちらも総合評価が 3.0 でした。ユーザーが入力する内容が長く、蛇行している場合、音声エージェントは構造化に苦戦しました。これらの状況では完全性スコアは 2.5 に低下し、エラー回復力は 2.0 まで落ち込みました。これらの結果は、今後のプロンプトエンジニアリングにおいて明確な改善領域を特定するものでした。それでも、平均的なエッジケースのスコアが 4.0 だったことは、実世界での運用準備が整っていることを示しています。
本番環境への展開には適切なアーキテクチャの構築が重要でした。私たちは LiveKit をトランスポート層として用いたサーバーレスでイベント駆動型のシステムを設計しました。LiveKit は、Web クライアント向けの WebRTC や電話通話用の セッション開始プロトコル (SIP) の複雑さを抽象化します。これにより、エンジニアリングチームはエージェントロジックの構築に完全に集中することができました。
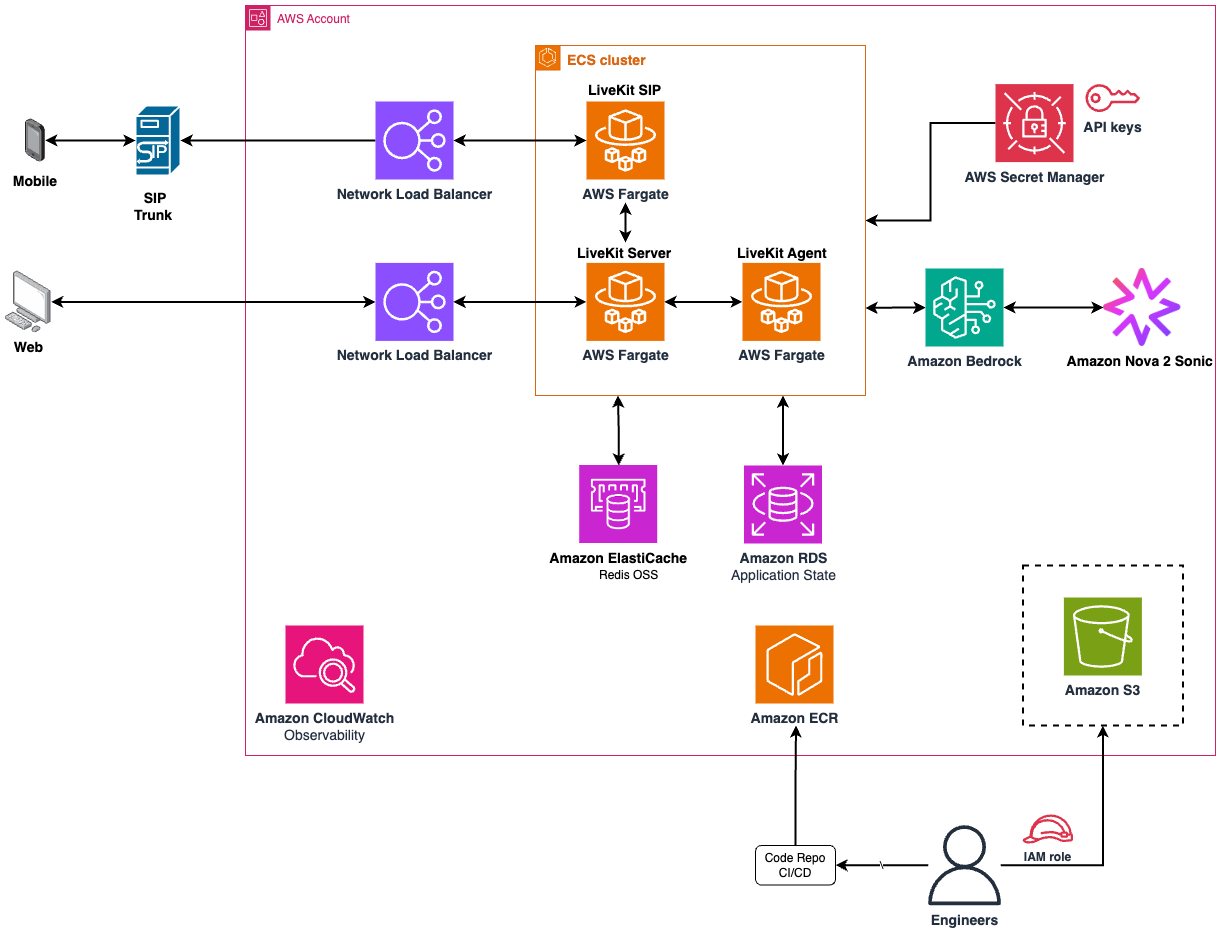
*図 4 – 会話型 AI アシスタント – ソリューションアーキテクチャ*
音声エージェントは、会話中にアシスタントが実行できるアクションを表す Python 関数ベースのツールを通じて、ディーラー業務と統合されます。一般的なツールには、在庫検索、予約管理、顧客データ照会が含まれます。これらのツールは、Amazon Nova 2 Sonic とバックエンドサービス間の統合層として機能します。モデルはツールの使用タイミングを判断し、Python 関数が対応する GraphQL クエリまたはミューテーションを実行して、構造化データをエージェントに返します。
AWS Fargate が計算層を提供しました。LiveKit エージェントは Amazon Elastic Container Service (Amazon ECS) 上でコンテナ化されました。これにより、エージェントワーカーとメディアサーバーを独立してスケールできるようになりました。ディーラーの繁忙時間帯にはリソースを動的に最適化できます。Amazon Relational Database Service (Amazon RDS) は、ディーラー設定、会話履歴、顧客記録など、構造化アプリケーションデータの永続的な関係型ストレージとして使用されました。
リアルタイム音声エージェントはデータベースの遅延を許容できません。Amazon ElastiCache は、分散タスクにわたるルーム管理と一時的なセッション調整を担当するために使用されます。Amazon Bedrock により、Nova 2 Sonic モデルへの直接アクセスが可能になりました。
ブラウザクライアントは、ピアツーピアのオーディオ、ビデオ、データ伝送のためのオープンソースフレームワークである WebRTC(Web Real-Time Communications)を使用して接続されています。従来の電話通話は、ネットワークロードバランサーを介してルーティングされる SIP トランクを通じて入力されました。これにより、メディアパケットに対する TCP/UDP のスループットが可能になりました。
観測機能は、AWS でセルフホストされた Langfuse から提供されました。これは、すべてのエージェントの意思決定とツール呼び出しを追跡します。このデータは、継続的な改善のために評価パイプラインにフィードバックされます。
デモ
以下の動画で機能を実演しています。
## 対話型 AI の新たな基準
テキストベースのチャットボットからリアルタイム音声エージェントへの移行は、単なるインターフェースの変更を超えています。これは根本的に異なるインフラと思考を必要とします。Nova 2 Sonic は、3 つの重要なエンジニアリング要件を同時に満たしています。第一に、中間的なテキスト変換なしで高い推論能力を提供することです。第二に、自然な人間のような割り込みを可能にする低遅延を実現することです。第三に、数千の場所でのコスト効果の高い生産環境としての実現可能性を提供することです。
自動車ディーラーにとって、この技術はすでに生産現場で収益を生み出しています。顧客は電話をかけると即座に役立つ回答を受け取ります。複雑なリクエストも、単一の会話内でスムーズに処理されます。予約は、イライラさせる行き来のやり取りを避けて正しくスケジュールされます。
その影響は自動車販売の範囲を超えて広がり、リアルタイムかつ知的な音声対話を必要とするあらゆる産業が恩恵を受けることができます。自然な会話を通じて休暇全体を計画する旅行代理店を想像してみてください。あなたの話し方や学習ペースに合わせて適応する教育用チューターを思い浮かべてみてください。複雑な保険や空き状況の問い合わせに対応する医療予約システムもその一例です。
音声対音声 AI はすでに実用段階に達しています。AWS 環境で Nova 2 Sonic の実験を開始し、プロトタイプを作成し、エッジケースを検証し、貴社のビジネスにおいて何が実現可能かを探求してください。
本記事は、実用レベルの AI ソリューション構築を専門とする AWS と Loka の共同執筆によるものです。Loka チームはすでにアーキテクチャ、評価、最適化に関する困難な課題を解決しています。彼らの自動車ディーラーにおける経験は、他の産業にも直接応用可能です。
音声対音声 AI はまだ黎明期にあります。最良のアプリケーションはまだ発明されていません。貴社の業界知識とこの技術を組み合わせることで、画期的なソリューションが生まれる可能性があります。Nova 2 Sonic と <a href="https://partners.amazonaws.com/partners/0010h00001
原文を表示
Loka transformed customer voice interactions by building a conversational AI agent with Amazon Nova 2 Sonic that keeps customers engaged with natural, responsive experiences. Their AWS-based solution achieves high speech reasoning accuracy on Big Bench Audio while delivering significantly lower costs and faster response times than traditional voice AI pipelines. In this post, we demonstrate the architecture and approach Loka used to solve a common frustration: robotic, slow voice assistants that cause customers to hang up, damaging brand reputation and driving up support costs.
Why traditional voice assistants fall short
Traditional voice assistants follow a three-step process that creates the fundamental problem. First, they convert your speech into text using Speech-to-Text systems. Next, they process that text through a Large Language Model (LLM). Finally, they convert the text response back into speech using Text-to-Speech technology. This pipeline introduces compounding delays at every step. The result is often a 3 to 5 second pause before you hear a response. That delay destroys the feeling of natural conversation. It makes interrupting or correcting the assistant feel clunky and frustrating.
Consider a real scenario at an automotive dealership. A customer calls and says, *“I’m looking for that SUV you advertised, but not the hybrid one. I can only come in after 5 PM.”* The assistant needs to parse multiple pieces of information simultaneously. It must understand the intent, negation, and scheduling constraints. Traditional systems struggle with this complexity because they lose crucial information during conversion. Tone, hesitation, and urgency disappear when speech becomes text. The dealership context makes these limitations painfully clear. Customers expect immediate, helpful responses when they call. A five-second pause feels like an eternity in a sales conversation. Worse, if the assistant misunderstands and needs clarification, delays compound. The conversation becomes tedious rather than helpful.
Beyond the technical delays, there’s an economic problem. Serving thousands of locations requires strict cost control. Traditional real-time voice systems can become cost-prohibitive at scale, particularly when processing continuous audio streams. The combination of poor experience and high cost has limited voice AI adoption. Businesses need a better solution.
Native speech-to-speech models
Recent advances in AI have unlocked a fundamentally different approach. Developers can now send audio streams directly to speech-to-speech models that handle understanding, reasoning, and generation as a unified system. By processing audio end-to-end, these models capture tone, emotion, and subtle cues that traditional text-only pipelines miss.
To validate this approach, rigorous testing was essential. We used Big Bench Audio, a benchmark that measures reasoning over speech inputs. Amazon Nova 2 Sonic achieved a speech reasoning score of 87.0. This outperformed Gemini 2.5 Flash Native Audio (Live API) at 71.0 and exceeded GPT Realtime’s 83.0. These scores confirmed that native audio processing doesn’t sacrifice intelligence for speed. The model could handle complex, multi-part requests in real dealership scenarios.
*Figure 1 – Speech reasoning scores comparison – Big Bench Audio*
Reasoning ability alone isn’t enough for production systems. Latency determines whether conversations feel natural or robotic. Nova 2 Sonic achieved Time to First Audio of 1.39 seconds. This response time allows for natural “barge-in” behavior. When users interrupt the conversation, the voice agent responded naturally. This experience matches human conversation patterns.
*Figure 2 – Time to first Audio comparison – Big Bench Audio*
Cost efficiency also improved. Nova 2 Sonic costs approximately $0.27 per hour of the input audio (based on pricing as of the time of publishing). This is lower than comparable real-time models and traditional methods.
*Figure 3 – Cost per hour of audio comparison – Big Bench Audio*
To measure quality beyond latency and cost, we needed a structured evaluation. We built an automated pipeline using LLM as a judge. Each conversation was scored on five dimensions using a 1-5 scale. Response Appropriateness measured whether replies were relevant and contextually correct. Intent Understanding assessed whether the agent grasped the user’s underlying goal. Completeness tracked required information or actions were provided. Conversational Naturalness measured flow, turn-taking, tone, and human-likeness.
Comparing Amazon Nova Sonic to Amazon Nova 2 Sonic revealed clear progress. Response Appropriateness improved from 2.5 to 2.9. Intent Understanding rose from 2.9 to 3.0. Most significantly, Completeness jumped from 1.8 to 2.5. This meant agents were far more likely to finish complex tasks. Conversational Naturalness improved from 2.5 to 2.8. The overall score increased from 2.4 to 2.7. These gains translated directly to better customer outcomes at dealerships.
Metric (1-5 Scale)
Nova Sonic (Baseline)
Nova 2 Sonic
Change
Response Appropriateness
2.5
2.9
+0.4
Intent Understanding
2.9
3.0
+0.1
Completeness
1.8
2.5
+0.7
Conversational Naturalness
2.5
2.8
+0.3
Overall Judge Score
2.4
2.7
+0.3
*Table 1 – Speech-to-speech model metrics comparison on the five dimensions*
Engineering conversational AI agents
With a strong foundation model, the next challenge was optimization. We treated prompts like code, iterating based on measured performance. The baseline Nova 2 Sonic configuration scored 2.7 overall. After the first prompt refinement, the score rose to 3.1. The second iteration achieved 3.8 out of 5.0. This improvement came from better turn discipline and repetition control. The agent learned when to speak, when to listen, and when to ask clarifying questions.
Configuration
Response
Appropriateness
Intent Understanding
Completeness
Error Recovery
Conversational
Naturalness
Overall
Judge Score
Amazon Nova 2 Sonic (Baseline)
2.9
3.0
2.5
2.6
2.8
2.7
Amazon Nova 2 Sonic (Prompt v1)
3.2
3.3
3.0
2.8
3.9
3.1
Amazon Nova 2 Sonic (Prompt v2)
3.7
3.9
3.9
3.8
4.1
3.8
*Table 2 – Speech-to-speech model metrics comparison on the five dimensions after prompt enhancements*
The team enhanced the baseline prompt in several ways, evolving it into two prompt templates. They replaced hardcoded dealership details with templatized variables like {assistant_name} and {dealership_address}. This change made the prompt reusable across any dealership.
The team shifted formatting from numbered lists to bullet points under clearly labeled headings. Headings like “Tool Usage Rules,” “Error Recovery,” and “Conversation Endings” gave the model sharper behavioral boundaries. This structure reduced instruction bleed between topics.
The team added concrete behavior examples throughout the prompt. These examples showed exactly how to acknowledge without echoing the caller. They also introduced a pre-response checklist that prompts the model to self-audit before every reply.
Amazon Bedrock Prompt Management became a natural home for this entire lifecycle. It allowed the team to store each template version with a unique Amazon Resource Name (ARN). They could promote changes from draft to production without touching application code.
When a new dealership was onboarded, their specific variables were injected at runtime through the Amazon Bedrock API. This meant the same core prompt served every client while remaining fully customizable.
The team added AWS Identity and Access Management (AWS IAM) access controls to restrict who could author, approve, or deploy prompt changes. This brought a proper governance layer to what was previously an informal editing process.
This approach turned prompt engineering from a one-off task into a repeatable, auditable workflow. The workflow scaled as the number of dealerships and use cases grew.
Real-world testing required edge cases that mirror actual dealership calls. We tested angry customers, busy parents, chatty customers, confused customers, and elderly callers.
The Busy Parent scenario scored 5.0 across the five dimensions. The agent handled interruptions, background noise, and time pressure flawlessly. The Angry Customer case scored 4.5 overall. The agent remained calm, empathetic, and solution focused. The Confused Customer scenario also scored 4.5. The agent patiently clarified without sounding condescending.
Chat Examples
Response Appropriateness
Intent Understanding
Completeness
Error Recovery
Conversational Naturalness
Overall Judge Score
Angry Customer
4.5
4.5
4.0
4.5
4.5
4.5
Busy Parent Customer
5.0
5.0
5.0
5.0
5.0
5.0
Chatty Customer
3.5
3.0
2.5
2.0
4.0
3.0
Confused Customer
4.5
4.5
4.5
5.0
4.5
4.5
Elderly Customer
3.5
3.0
2.5
2.0
4.0
3.0
Average
4.2
4.0
3.7
3.7
4.4
4.0
*Table 3 – Speech to Speech model evaluation based on customer personas*
Two scenarios revealed the remaining opportunities. The Chatty Customer and Elderly Customer cases both scored 3.0 overall. When users provided long, meandering inputs, the voice agent struggled with the structure. Completeness scores dropped to 2.5 in these situations. Error recovery fell to 2.0. These results identified clear areas for future prompt engineering. Still, the average edge-case score of 4.0 indicated strong real-world readiness.
Building the right architecture was important for production deployment. We designed a serverless, event-driven system using LiveKit as the transport layer. LiveKit abstracts the complexities of WebRTC for web clients and Session Initiation Protocol (SIP) for phone calls. This allowed the engineering team to focus entirely on agent logic.
*Figure 4 – Conversational AI assistant – Solution architecture*
The voice agent integrates with dealership operations through Python function-based tools, which represent actions the assistant can perform during a conversation. Common tools include inventory search, appointment booking, and customer data lookup. These tools act as the integration layer between Amazon Nova 2 Sonic and backend services. The model decides when a tool should be used, and the Python function executes the corresponding GraphQL query or mutation, returning structured data back to the agent.
AWS Fargate provided the compute layer. We containerized LiveKit Agents on Amazon Elastic Container Service (Amazon ECS). This enabled independent scaling of agent workers versus media servers. Resources could be optimized dynamically during peak dealership hours. Amazon Relational Database Service (Amazon RDS) was used as the persistent relational store for structured application data including dealership configurations, conversation history, and customer records.
Real-time voice agents cannot tolerate database latency. Amazon ElastiCache is used to handle room management and ephemeral session coordination across distributed tasks. Amazon Bedrock provided direct access to the Nova 2 Sonic model.
Browser clients connected using WebRTC (Web Real-Time Communications), open-source framework for peer-to-peer audio, video and data transmission. Traditional phone calls entered through a SIP Trunk routed via Network Load Balancer. This allowed TCP/UDP throughput for media packets.
Observability came from Langfuse, self-hosted on AWS. It traced every agent decision and tool call. This data was fed back into the evaluation pipeline for continuous improvement.
Demo
The following video demonstrates the functionality.
A new standard for conversational AI
The transition from text-based chatbots to real-time voice agents represents more than an interface change. It requires fundamentally different infrastructure and thinking. Nova 2 Sonic hits three critical engineering requirements simultaneously. First, it provides high reasoning capability without intermediate text conversion. Second, it delivers low latency that enables natural, human-like interruption. Third, it offers production viability with cost-effectiveness for thousands of locations.
For automotive dealerships, this technology is already driving revenue in production. Customers receive immediate, helpful responses when they call. Complex requests get handled smoothly in a single conversation. Appointments get scheduled correctly without frustrating back-and-forth exchanges.
The implications extend far beyond automotive sales. Industries requiring real-time, intelligent voice interactions can benefit. Imagine a travel agent that helps you plan an entire holiday through natural conversation. Picture an educational tutor that adapts to your speaking style and learning pace. Consider healthcare scheduling systems that handle complex insurance and availability questions.
Speech-to-speech AI has reached production readiness. Start experimenting with Nova 2 Sonic in your own AWS environment. Build prototypes, test edge cases, and explore what’s possible for your business.
This post represents a collaboration between AWS and Loka, who specialize in building production-ready AI solutions. Loka’s team has already solved the hard problems around architecture, evaluation, and optimization. Their automotive dealership experience translates directly to other industries.
Speech-to-speech AI is still in its early days. The best applications haven’t been invented yet. Your industry knowledge combined with this technology could create breakthrough solutions. Start your journey with Nova 2 Sonic and <a href="https://partners.amazonaws.com/partners/0010h00001
関連記事
Amazon、インドでの AI インフラへの新たな 130 億ドル投資で賭けを強化
Amazon はインド市場における AI 競争力を高めるため、新たに 130 億ドル規模の AI インフラ設備への投資を発表した。
Amazon Nova 2 Sonic を活用した医療予約エージェントの構築方法
AWS は、米国医療機関で問題となる欠席率の高さに対応するため、Amazon Nova 2 Sonic を使用して患者の予約確認や再調整を行う自動エージェントを構築する手法を公開しました。
NVIDIA と AWS が大規模な AI の実用化に向けて協力
NVIDIA と Amazon Web Services(AWS)が、AI を大規模に生産環境で運用するための協力を開始した。両社はインフラと技術の統合により、企業による AI の実装を加速させる方針を示している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み