Deep Agents との連携によるプロンプトキャッシング
LangChain は Deep Agents の活用によりプロンプトキャッシング機能を公開し、LLM 推論におけるコスト削減とレイテンシ短縮の実現を可能にした。
キーポイント
Deep Agents を活用したプロンプトキャッシングの導入
LangChain が Deep Agents のアーキテクチャ特性を活用し、重複するプロンプト入力をキャッシュして再計算を防ぐ機能を公開した。
推論コストとレイテンシの大幅削減効果
同一または類似の入力に対する LLM 呼び出しを回避することで、クラウド利用料金の削減と応答速度の向上という二重のメリットを提供する。
エージェント型アプリケーションへの最適化
複雑な推論プロセスを要する Deep Agents の文脈において、効率的なリソース管理を実現し、スケーラビリティを高める設計となっている。
影響分析・編集コメントを表示
影響分析
この発表は、エージェント型 AI アプリケーションの開発者が直面する最大の課題である「推論コストの高騰」と「遅延」に対する実用的な解決策を提示した。特に Deep Agents のような複雑な推論パスを持つシステムにおいて、キャッシュ戦略を採用することで運用効率と経済性が劇的に向上するため、業界標準のベストプラクティスとして定着する可能性が高い。
編集コメント
LLM の利用拡大に伴い、コストと速度のバランスをどう取るかが最重要課題となる中、LangChain が実装レベルでこの解決策を提供した点は評価に値します。
スケーラブルかつコスト効率よくエージェントを運用するための強力なレバーは、プロンプトキャッシングです。これはモデルプロバイダーが提供する機能で、推論のトークンコストを 41〜80% 削減 することができます。Manus AI が述べているように -
💡
*"もし一つの指標しか選べないなら、KV キャッシュのヒット率(KV-cache hit rate)が生産段階の AI エージェントにとって最も重要な指標であると主張します。"*
しかし、モデルプロバイダーはキャッシングを制御するための戦略が多様であり、プロバイダーに依存しないキャッシングの実装はより困難な課題となります。
Deep Agents は、主要なすべてのプロバイダーでプロンプトキャッシング機能をサポートする、汎用かつモデル非依存のエージェントハーンです。ここでは Deep Agents が API コストを削減するためにプロンプトキャッシングをどのように活用しているかを探りますが、その前に、チャットモデルの会話においてプロンプトキャッシングがトークンコストをどのように削減するのかを見てみましょう。
TL;DR: プロンプトキャッシング

チャットモデルの会話におけるトークンコストは急速に増加します。新しいメッセージごとに、モデルは会話内のすべての先行トークンを再処理する必要があります。これには以下が含まれます:
- システムプロンプト
- ツール説明
- ロードされたスキル
- メッセージ履歴
- 新しいメッセージ
プロンプトキャッシングを有効にすると、プロバイダーはプロンプト処理後のモデルの状態のスナップショットを保存します:

次のリクエストでは、モデルはそのスナップショットから再開し、新しいテキストのみを処理します。
ただし、新しいスキルやツールを読み込むと、会話のより早い段階でプロンプトが変更され、キャッシュバスト(キャッシュ無効化)を引き起こす可能性があります。一部のモデルプロバイダーでは、プロンプトのより早い段階に明示的なキャッシュブレイクポイントを追加して、プロンプト全体を無効化するのではなく、一部のプロンプトに対してキャッシュヒットを実現できるようにしています。ただし、すべてのモデルプロバイダーが明示的なキャッシュブレイクポイントをサポートしているわけではありません:
Anthropic
OpenAI
Gemini
AWS Bedrock
Fireworks
Explicit Breakpoints (明示的なブレイクポイント)
✅
❌
✅
プロバイダー依存
❌
明示的なキャッシングは、プロバイダー間でサポート状況が異なるプロンプトキャッシング機能の一つに過ぎません:
Anthropic
OpenAI
Gemini
AWS Bedrock
Fireworks
Explicit Breakpoints (明示的なブレイクポイント)
✅
❌
✅
プロバイダー依存
❌
Configurable TTL (設定可能な TTL: Time To Live)
✅
モデル依存
✅
プロバイダー依存
❌
キャッシュプリウォーム
✅
❌
❌
Anthropic
❌
ルーティングキー (Routing Key)
❌
✅
❌
OpenAI
✅
*プロンプトキャッシュ機能のサポート状況は急速に変化しています。各モデルプロバイダーのドキュメントを確認して、機能サポートについて参照してください。
異なるプロンプトキャッシュの実装や、プロバイダー間の機能サポートの違いにより、複数のプロバイダーにわたって最大のコスト削減を実現するのは課題となる場合があります。
Deep Agents における解決策
Deep Agents ハーネスは、自動的に以下の対応を行うことで、プロンプトキャッシュ機能の活用を最善の努力で実現します:
- サポートされている場合、明示的なキャッシュブレイクポイントを設定する
- 明示的なブレイクポイントがサポートされていない場合、プロバイダー側の暗黙的キャッシュ (implicit caching) にオプトインする
- キャッシュ読み取りを最大化するようにプロンプトを構造化する
これらの戦略は主要なすべてのプロバイダーでサポートされているため、いつでもプロバイダーを切り替えても、最大限のトークン削減効果を享受できます。プロバイダー固有の特徴を活用するためには、ハーネスが現在のモデルプロバイダーを検出し、プロバイダー固有のミドルウェア にキャッシュ処理を委譲します。また、ご自身の createAgent() 関数でこのミドルウェアを使用することで、プロンプトキャッシュによる削減効果にオプトインすることも可能です:
// Deep Agents では、プロンプトキャッシングが無料で利用できます!
const agent = createDeepAgent({ model: 'gpt-5.5' });
// LangChain では、ミドルウェア経由でオプトインします:
const agent = createAgent({
model: 'claude-haiku-4-5-20251001',
middleware: [anthropicPromptCachingMiddleware()],
});
Deep Agents のハッシュは、キャッシュの劣化を最小限に抑えるために、プロンプトと明示的なキャッシュポイントを構造化します。理想的には、モデル呼び出しにおける静的プレフィックス(ツール説明、スキル、システムプロンプト)は不変のまま維持されます。ただし、メモリの更新や会話の圧縮などを行う際にこれらが変更されることがあり、その結果キャッシュが破綻(キャッシュバust)する可能性があります。Deep Agents は、例えばメモリが更新された場合でもプロンプトの一部に対してキャッシュ読み取りが可能となるように、プロンプトと明示的なキャッシュポイントを構造化することで、影響範囲を最小限に抑えます。
プロンプトキャッシングによる本当の節約額
機能テーブルは可能性を示すのみです。プロンプトキャッシングが実際にどれほどの節約をもたらすかを確認するため、3 つのプロバイダーからそれぞれミッドティアモデル(claude-haiku-4-5、gpt-5.4-mini、gemini-3.5-flash)を用いて、Deep Agents の 評価スイート を実行しました。その結果が以下のチャートです。実際のエージェントの軌跡において、プロンプトキャッシングはトークンコストを 49–80% 削減しました。
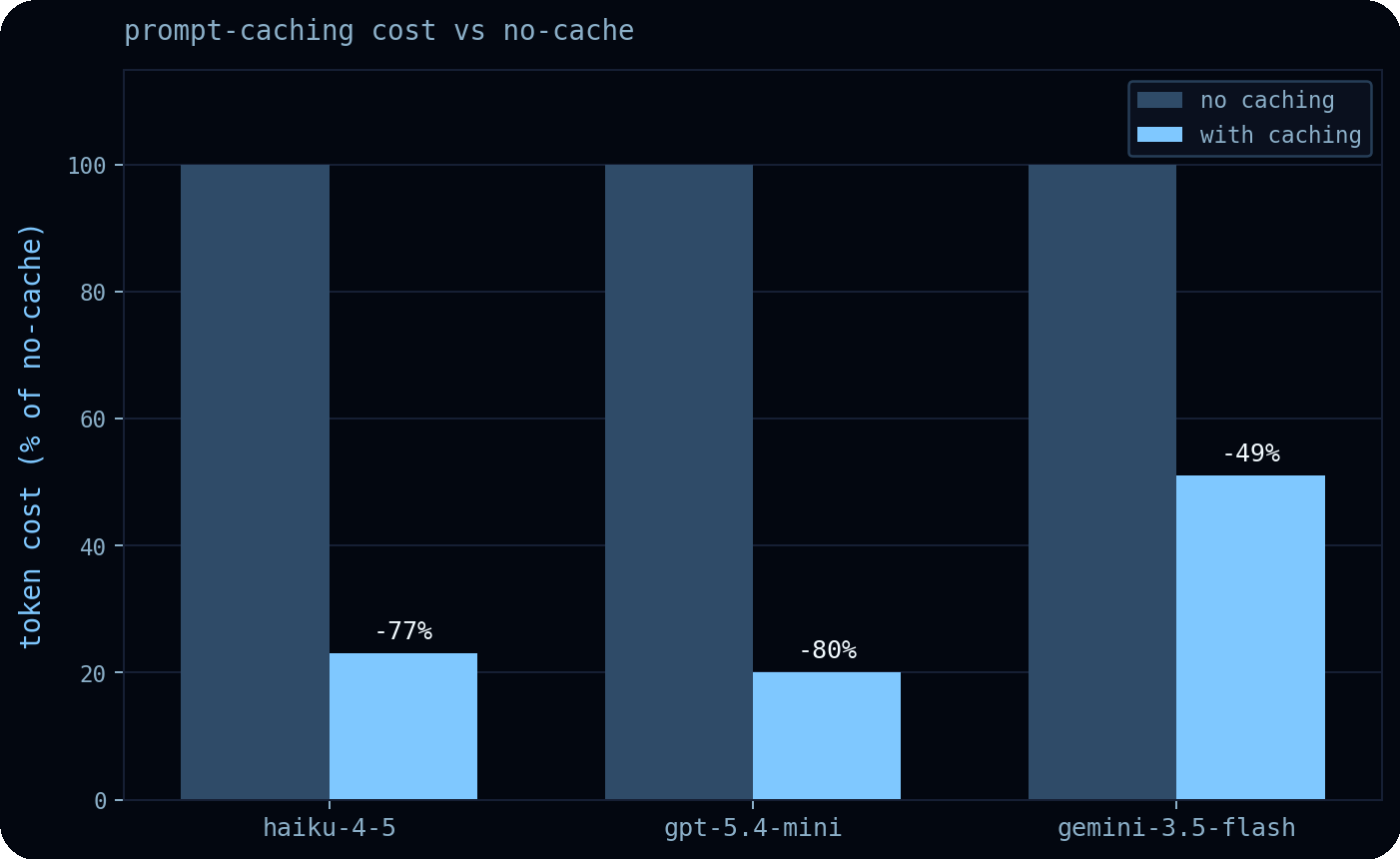
- claude-haiku-4-5: -77%。Anthropic の明示的なブレークポイントを使用することで、プロンプトの大部分をキャッシュ状態に保つことができます。これにより、各リクエストのトークンコストが大幅に削減されました。
- gpt-5.4-mini: -80%。OpenAI の自動最長接頭辞キャッシング(longest-prefix caching)により、約 80% という大きなコスト削減を実現しています。
- gemini-3.5-flash: -49%。Gemini の暗黙的なキャッシングは明示的な節約保証を提供していませんが、それでも相当な節約効果を確認できました。
また、キャッシュの恩恵は会話が続くほど大きくなる点にも注目に値します。キャッシュされた接頭辞はすべてのターンで再利用されるため、長期にわたるタスク(long-horizon tasks)こそが最も大きな利益を得ることになります。
LangSmith による観測可能性
プロンプトキャッシングによるコスト削減効果は、それを測定する能力次第です。LangSmith は、API コスト、キャッシュ読み取り回数、トークン使用量について、各呼び出し単位および各軌跡(per-trajectory)レベルでの可視性を提供します:

各呼び出しに対して、最初のトークンまでの時間、総入力トーク数、キャッシュ読み取りトーク数、総出力トーク数が、軌跡ごとの集計値としてまとめられます。キャッシュ読み取りは個別に項目化されているため、プロンプトのどの部分が再処理されることなくキャッシュから提供されたのかを正確に把握できます。
これはまさに、本記事で提示した数値を算出するために使用した手法でもあります:
- Deep Agents の評価スイートを各エージェント構成に対して実行する
- LangSmith ダッシュボード内のトレースデータを検査し、実行結果を検証する
- LangSmith Client SDK を経由して実行データを取得する
- Jupyter ノートブックにデータを読み込む(またはエージェントが LangSmith Skills を使用して支援する)ことで、プロバイダーごとのコスト差を計算する
LangSmith により、キャッシュによる節約、トランジェクト長、およびより安価なターンからの節約を分離して分析できるため、エージェントの最適化方法を決定する際の参考になります。LangSmith のデータの見方と対応方法については こちら をご覧ください。
プロンプトキャッシングの次なるステップ
モデルプロバイダーはまだプロンプトキャッシングのための共通機能セットに収束していません。上記で示した明示的なブレイクポイントがいくつかの節約をもたらしましたが、それは始まりに過ぎません。キャッシュプリウォーム、ルーティングキー、設定可能な TTL(Time To Live)といった数少ない他の機能も、さらなるコスト削減とレイテンシの改善を実現する可能性があります。
現在サポートされている機能は、createDeepAgent を使用することで今日から活用できます。追加の設定は不要です。モデルプロバイダーが追加の機能サポートを追加していくにつれ、既存のハーンネスにもそれらを継続的に組み込んでいきます。
原文を表示
A powerful lever in running agents cost-efficiently at scale is Prompt Caching, a feature offered by model providers that can reduce the token cost of inference by 41-80%. As Manus AI puts it -
💡
*"If I had to choose just one metric, I'd argue that the KV-cache hit rate is the single most important metric for a production-stage AI agent."*
However, model providers support varied strategies for controlling caching, making provider-agnostic caching a trickier solve.
Deep Agents is our general purpose, model-agnostic agent harness which supports prompt caching features across all major providers. We’re going to dig into how Deep Agents uses prompt caching to cut API costs, but first let’s look at how prompt caching reduces token costs in a chat model conversation.
TL;DR: prompt caching
The token cost of a chat model conversation grows quickly. For each new message, the model must reprocess every prior token in the conversation, including the:
- System prompt
- Tool descriptions
- Loaded skills
- Message history
- New message
When we opt into prompt caching, the provider stores a snapshot of the model’s state after processing a prompt:

On the next request, the model picks up from that snapshot and only processes new text.
However, loading a new skill or tool can modify our prompt *earlier* in the conversation, potentially causing a cache bust. Some model providers enable us to add explicit cache breakpoints earlier in the prompt, resulting in a cache hit on a subset of the prompt rather than a full cache bust. However, not all model providers support explicit cache breakpoints:
Anthropic
OpenAI
Gemini
AWS Bedrock
Fireworks
Explicit Breakpoints
✅
❌
✅
Per-provider
❌
Explicit caching is also just one prompt caching feature with varied support among providers:
Anthropic
OpenAI
Gemini
AWS Bedrock
Fireworks
Explicit Breakpoints
✅
❌
✅
Per-provider
❌
Configurable TTL
✅
Per-model
✅
Per-provider
❌
Cache Prewarm
✅
❌
❌
Anthropic
❌
Routing Key
❌
✅
❌
OpenAI
✅
*The prompt caching feature support landscape changes quickly. Be sure to check model provider docs for reference on feature support.*
Between differing prompt caching implementations and feature support among providers, it can be a challenge to achieve maximal cost savings across providers.
How we’re solving this in Deep Agents
The Deep Agents harness makes a best-effort attempt at utilizing prompt caching features by automatically:
- Setting explicit cache breakpoints when supported
- Opting in to provider-side implicit caching when explicit breakpoints aren’t supported
- Structuring your prompt to maximize cache reads
These strategies are supported for all major providers, so you’re able to switch provider at any time and still reap maximal token savings. To take advantage of provider-specific features, the harness detects the current model provider and delegates caching to provider-specific middleware. You can also use the middleware in your own createAgent() to opt in to prompt caching savings:
// In Deep Agents you get prompt caching for free!
const agent = createDeepAgent({ model: 'gpt-5.5' });
// In LangChain, opt in via our middleware:
const agent = createAgent({
model: 'claude-haiku-4-5-20251001',
middleware: [anthropicPromptCachingMiddleware()],
});
The Deep Agents harness also structures your prompt and explicit cache points to minimize cache degradation. Optimally the static prefix (your tool descriptions, skills, system prompt) in a model invocation remains static. It *can* however change when doing things like updating a memory or compacting a conversation, leading to a cache bust. Deep Agents minimizes the blast radius by structuring your prompt and explicit cache points such that if e.g. a memory is updated, you still get a cache read on a subset of your prompt.
The real savings of prompt caching
Feature tables tell us what's possible. To see what prompt caching actually saves, we ran the Deep Agents eval suite across a mid-tier model from each of three providers: claude-haiku-4-5, gpt-5.4-mini, and gemini-3.5-flash. The result is the chart below. On real agent trajectories, prompt caching cut token cost by 49–80%.
- claude-haiku-4-5: -77%. Using Anthropic's explicit breakpoints, we can keep a large portion of the prompt cached. This significantly reduced the token cost of each request.
- gpt-5.4-mini: -80%. OpenAI's automatic longest-prefix caching gives us a sizable 80% cost reduction
- gemini-3.5-flash: -49%. Gemini's implicit caching makes no explicit savings guarantee, but we still see considerable savings
It's also worth noting that caching pays off more the longer a conversation runs: the cached prefix is reused across every turn, so the long-horizon tasks are the ones that benefit most.
Observability with LangSmith
Cost savings from prompt caching are only as good as your ability to measure them. LangSmith offers visibility into API cost, cache reads, and token usage at a per-invocation and per-trajectory level:
For each invocation you get time-to-first-token, total input tokens, cache-read tokens, and total output tokens rolled up to a per-trajectory aggregate. Because cache reads are itemized separately, you can see exactly how much of each prompt was served from cache rather than reprocessed.
This is also how we produced the numbers in this post:
- Run the Deep Agents eval suite against each agent configuration
- Inspect trace data in the LangSmith dashboard to verify run results
- Pull the run data via the LangSmith Client SDK
- Compute per-provider cost deltas by dropping the data into a Jupyter notebook (or have an agent use LangSmith Skills to help)
LangSmith lets us disentangle savings from caching, trajectory length, and cheaper turns, which can inform how we optimize our agent. More on how to read and act on data in LangSmith here.
Next in prompt caching
Model providers have yet to converge on a common feature set for prompt caching. Explicit breakpoints drove some savings above, but it’s only the start. A handful of other features - cache prewarm, routing keys, configurable TTL - stand to unlock further cost savings and latency wins.
You can take advantage of the currently-supported features today by using createDeepAgent - no additional config needed. As model providers add additional feature support, we’ll continue to fold them into the existing harness.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み