Stable Diffusion 3.5モデル、TensorRT最適化によりNVIDIA RTX GPUで性能2倍向上・メモリ使用量40%削減を実現
Stability AI と NVIDIA の連携により、Stable Diffusion 3.5 モデルが TensorRT および FP8 量子化で最適化され、NVIDIA RTX GPU 上で生成速度が最大 2.3 倍向上し VRAM 使用量が 40% 削減された。
キーポイント
劇的なパフォーマンス向上とメモリ削減
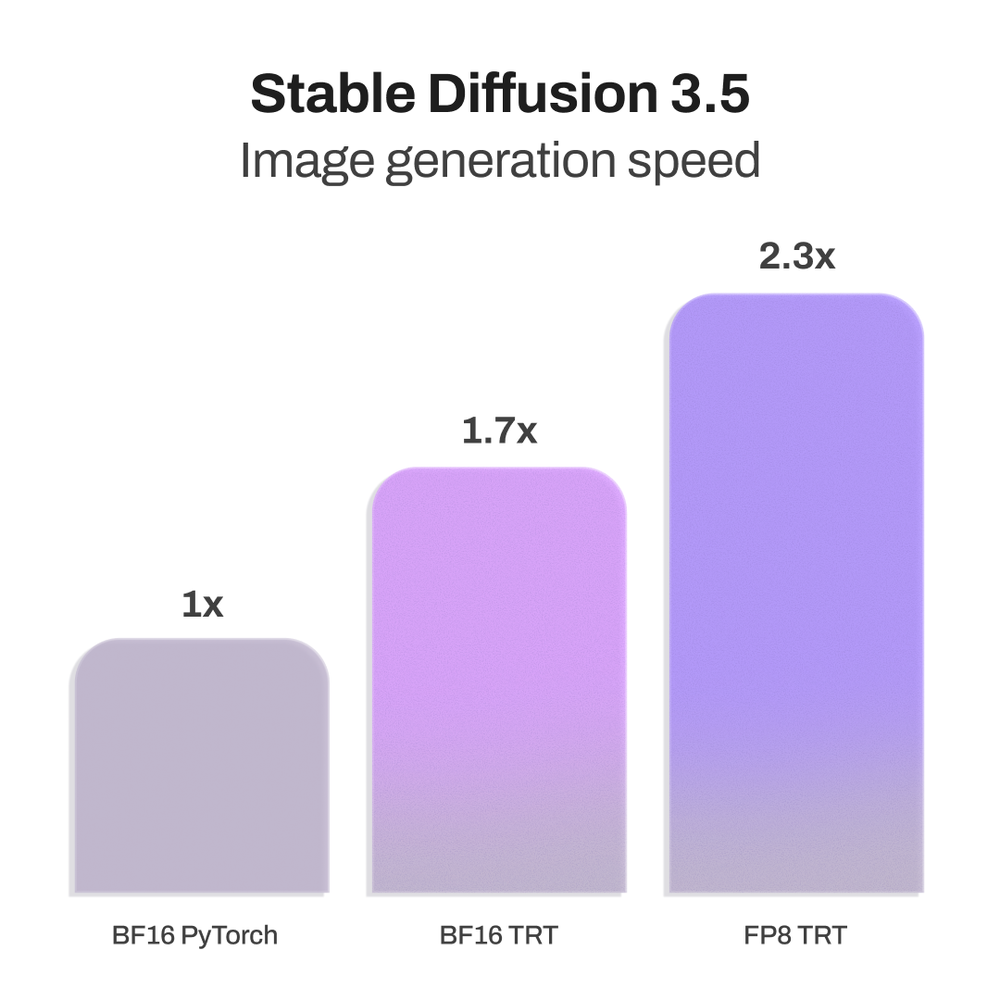
TensorRT と FP8 量子化の導入により、SD3.5 Large で最大 2.3 倍、Medium で 1.7 倍の高速化が達成され、VRAM 使用量が 40% 削減された。
ハードウェアアクセシビリティの拡大
最適化により、RTX 50 シリーズシステム 5 台で SD3.5 Large が動作可能となり、以前は 1 台のみだった環境から大幅に利用範囲が広がった。
商用・非商用ライセンスの開放
最適化されたモデルは Stability AI コミュニティライセンスの下で商用および非商用利用が可能となり、Hugging Face と NVIDIA GitHub で公開されている。
大幅な性能向上とメモリ削減
SD3.5 Large は BF16 PyTorch モデルと比較して最大 2.3 倍高速化され、VRAM 使用量が 40%(19GB から 11GB)削減されます。
幅広い GPU ハードウェアでの対応
GeForce RTX 50/40 シリーズおよび Blackwell や Ada Lovelace 世代の RTX PRO グラフィックスカードを含む、NVIDIA RTX GPU 全体で効率的に動作します。
商用利用可能なオープンソース
最適化されたモデルは Hugging Face で重み、GitHub でコードが公開され、Stability AI のコミュニティライセンスに基づき商用・非商用を問わず利用可能です。
影響分析・編集コメントを表示
影響分析
この発表は、高品質な画像生成モデルをより広範なエンタープライズおよび消費者向けハードウェアで実行可能にする重要な一歩であり、Stable Diffusion 3.5 の実用性を決定づける要因となります。特に VRAM 要件の削減と速度向上により、コスト効率の高い大規模画像生成パイプラインの構築が容易になり、クリエイティブ産業や開発現場での導入障壁を大幅に下げます。
編集コメント
Stable Diffusion の最新モデルが、ハードウェアの制約を克服する形で最適化されたことは、現場開発者にとって即座に活用できる大きな朗報です。特に「5 台で 1 台分」のメモリ効率向上は、コスト削減とスケーラビリティにおいて実務的な価値が極めて高いと言えます。
タイトル: TensorRTで最適化されたStable Diffusion 3.5モデルがNVIDIA RTX GPUで2倍以上の高速化と40%のメモリ削減を実現
Key Takeaways:
NVIDIAと協業し、Stable Diffusion 3.5(SD3.5)のNVIDIA TensorRT最適化バージョンを提供開始しました。これにより、より幅広いNVIDIA RTX GPUでエンタープライズグレードの画像生成が利用可能になります。
SD3.5 TensorRT最適化モデルは、SD3.5 Largeでは最大2.3倍、SD3.5 Mediumでは最大1.7倍の高速な画像生成を実現し、同時に必要なVRAMを40%削減します。
最適化されたモデルは、寛容なStability AI Community Licenseの下で商用・非商用利用が可能です。モデル重みはHugging Faceで、コードはNVIDIAのGitHubからダウンロードできます。
NVIDIAと協力し、TensorRTとFP8を用いてSD3.5ファミリのモデルを最適化しました。これにより、対応するRTX GPUでの生成速度が向上し、必要なVRAMが削減されます。
SD3.5は、コンシューマー向けハードウェアでそのまま動作するよう開発されました。NVIDIAによる最適化により、多様なハードウェア環境で作業するクリエイティブプロフェッショナルや開発者にとって、さらにアクセスしやすくなっています。
これらのパフォーマンス向上により、SD3.5の中核的な強みがより活用しやすくなります。SD3.5は以下の分野で優れており、プロンプト遵守と画質においてトップクラスの性能を維持しつつ、市場で最もカスタマイズ性の高い画像モデルの一つとなっています:
多様なスタイル: 3D、写真、絵画、線画など、想像できるほぼあらゆる視覚スタイルや美学を生成可能です。
多様な出力: 広範なプロンプトを必要とせず、異なる肌の色や特徴を持つ、多様な人々を表現した画像を生成します。
プロンプト遵守: 当社の分析によると、SD3.5 Largeはプロンプト遵守において市場をリードしており、与えられたテキストプロンプトを忠実に反映します。効率的で高品質なパフォーマンスを求める場合の最適な選択肢です。
より多くのNVIDIA RTX GPUで利用可能に
TensorRT最適化は、NVIDIAハードウェア上でのモデル実行を効率化することで、品質を維持しながらモデルサイズを削減します。モデルサイズの削減は、FP8量子化によって達成されます。この技術は、高品質な出力を維持しながらモデルを効率化します。これらの改善により、最適化前は1システムのみだったのが、現在では5つのRTX 50シリーズシステムがメモリ上でSD3.5 Largeを実行できるようになりました。
NVIDIA RTX GPU全体でパフォーマンス向上
SD3.5 TensorRT最適化モデルは、NVIDIA GeForce RTX 50および40シリーズGPU、ならびにNVIDIA BlackwellおよびAda LovelaceアーキテクチャのNVIDIA RTX PRO GPUにおいて、より効率的に実行されます。SD3.5 Largeでは最大2.3倍、SD3.5 Mediumでは最大1.7倍の高速な生成を実現し、VRAM要件を40%削減します。
FP8 TensorRTは、BF16 PyTorchと比較してSD3.5 Largeの性能を2.3倍向上させ、メモリ使用量を40%削減します。SD3.5 Mediumでは、BF16 TensorRTが1.7倍の高速化を実現します。
SD3.5 Large
ベースのPyTorchモデルと比較して、画像生成が最大2.3倍高速化。
プロフェッショナル品質を維持したまま、メモリ使用量が40%削減(19GBから11GBへ)。
SD3.5 Medium
速度と効率を優先するユーザー向けに、画像生成が最大1.7倍高速化。
メモリフットプリントが低く、ミッドレンジのRTXハードウェアで作業するクリエイターに理想的です。
Getting started
最適化されたモデルは、寛容なStability AI Community Licenseの下で商用・非商用利用が可能です。モデル重みはHugging Faceで、コードはNVIDIAのGitHubからダウンロードできます。
最新情報については、X、LinkedIn、Instagramでフォローいただくか、Discordコミュニティにご参加ください。
原文を表示
Key Takeaways:
We've collaborated with NVIDIA to deliver NVIDIA TensorRT-optimized versions of Stable Diffusion 3.5 (SD3.5), making enterprise-grade image generation available on a wider range of NVIDIA RTX GPUs.
The SD3.5 TensorRT-optimized models deliver up to 2.3x faster generation on SD3.5 Large and 1.7x faster on SD3.5 Medium, while reducing VRAM requirements by 40%.
The optimized models are now available for commercial and non-commercial use under the permissive Stability AI Community License.You can download the weights on Hugging Face and code on NVIDIA’s GitHub.
 image
image
In collaboration with NVIDIA, we've optimized the SD3.5 family of models using TensorRT and FP8, improving generation speed and reducing VRAM requirements on supported RTX GPUs.
SD3.5 was developed to run on consumer hardware out of the box. The Nvidia optimizations extend that accessibility further for creative professionals and developers working across a variety of hardware setups.
Where the models excel
These performance improvements make SD3.5's core strengths more accessible. SD3.5 excels in the following areas, making it one of the most customizable image models on the market, while maintaining top-tier performance in prompt adherence and image quality:
Versatile Styles: Capable of generating a wide range of styles and aesthetics like 3D, photography, painting, line art, and virtually any visual style imaginable.
Diverse Outputs: Creates images representative of the world, not just one type of person, with different skin tones and features, without the need for extensive prompting.
Prompt Adherence: Our analysis shows that SD3.5 Large leads the market in prompt adherence, allowing the model to closely follow a given text prompt, making it a top choice for efficient, high-quality performance.
Now available across more NVIDIA RTX GPUs
TensorRT optimization reduces model size while maintaining quality by streamlining how models run on NVIDIA hardware. Model size reduction is achieved through FP8 quantization, a technique that makes models more efficient while maintaining high output quality. These improvements mean that five RTX 50 Series systems can now run SD3.5 Large from memory, compared to just one system before optimization.
Enhanced performance across NVIDIA RTX GPUs
SD3.5 TensorRT-optimized models run more efficiently across NVIDIA GeForce RTX 50 and 40 Series GPUs, as well as NVIDIA Blackwell and Ada Lovelace generation NVIDIA RTX PRO GPUs. They deliver up to 2.3x faster generation on SD3.5 Large and 1.7x faster on SD3.5 Medium, while reducing VRAM requirements by 40%.
 image
image
FP8 TensorRT boosts SD3.5 Large performance by 2.3x vs. BF16 PyTorch, with 40% less memory use. For SD3.5 Medium, BF16 TensorRT delivers a 1.7x speedup.
SD3.5 Large
2.3x faster image generation compared to compared to the base PyTorch models.
Memory use reduced by 40%, from 19GB to 11GB, all while maintaining professional quality.
SD3.5 Medium
1.7x faster image generation for users prioritizing speed and efficiency.
Lower memory footprint, ideal for creators working on mid-range RTX hardware.
Getting started
The optimized models are now available for commercial and non-commercial use under the permissive Stability AI Community License.You can download the weights on Hugging Face and code on NVIDIA’s GitHub.
To stay updated on our progress, follow us on X, LinkedIn, Instagram, and join our Discord Community.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み