TokenSpeed:エージェントワークロード向け光速 LLM 推論エンジン
NVIDIA DevTech との共同開発により、LLM推論エンジン「TokenSpeed」がアジェンティブワークロード向けに最適化され、TensorRT-LLM を上回るスループットと低遅延を実現した。
キーポイント
コンパイラベースの最適化機構
従来の手法とは異なり、コンパイラをバックボーンとしたモデリングメカニズムを採用し、アジェンティブワークロードにおける速度と効率を最大化します。
Nvidia Blackwell 向け最適化
「TokenSpeed MLA」という独自最適化技術により、次世代 GPU の Nvidia Blackwell アーキテクチャの性能をさらに引き出すことに成功しています。
コーディングエージェントでの実証
典型的なアジェンティブワークロード、特にコーディングエージェントにおいて、既存の高性能エンジンである TensorRT-LLM を上回るスループットと低遅延を達成しました。
影響分析・編集コメントを表示
影響分析
この技術は、自律型 AI エージェントが実社会で広く展開される際のボトルネックである推論速度と遅延を解決する重要な一歩となります。特に NVIDIA の最新ハードウェアとの親和性が高いことは、データセンターやエッジ環境での大規模導入を加速させる要因となるでしょう。
編集コメント
アジェンティブ AI の実用化において、推論速度は決定的な要素です。TensorRT-LLM を凌駕する性能を示す TokenSpeed の登場は、開発者にとって大きな追い風となるでしょう。
エージェント型コーディングは、有望なデモから急速に拡大し、ソフトウェアの開発方法や最先端 AI システムの構築・展開方法を再定義する力となっています。Claude Code、Codex、Cursor などのシステムは膨大なユーザー採用を獲得し、現在では莫大な量のトークンを生成しています。この成長に対応するため、数十ギガワットの電力を必要とするデータセンターが建設され、数百億ドル規模の投資によって支えられています。
このスケールにおいて、モデル推論を調整するシステムの効率が極めて重要になります。GPU あたりのスループットにおけるわずかな改善であっても、生産環境のファーム全体に適用すれば、増大し続ける需要に応えながら、大幅な容量節約を実現できます。
TokenSpeed の概要
TokenSpeed は、エージェント型推論の領域のために第一原理から設計されています。これは、エージェントワークロードに対して「光速」の推論を提供し、*並列化のためのコンパイラ支援モデリング機構、高性能スケジューラ、安全な KV リソース再利用制限、異種アクセラレータをサポートするプラグイン可能な階層型カーネルシステム*、および低オーバーヘッドの CPU 側リクエストエントリーポイントを実現するための SMG 統合を備えています。
モデル層は、パフォーマンスと使いやすさを両立するローカル SPMD(Single Program, Multiple Data)設計を採用しています。TokenSpeed を利用すれば、開発者はモジュール境界で I/O 配置注釈を指定できます。その後、軽量な静的コンパイラがモデル構築時に必要な集合演算を自動的に生成するため、通信ロジックを手動で実装する必要がありません。
TokenSpeed スケジューラは、制御プレーンと実行プレーンを分離しています。制御プレーンは C++ で実装された有限状態機械(FSM)として機能し、型システムと連携してコンパイル時に KV キャッシュの状態転送や使用を含む安全なリソース管理を強制します。リクエストのライフサイクル、KV キャッシュリソース、オーバーラップタイミングは、明示的な FSM 遷移と所有権セマンティクスを通じて表現されるため、正しさが慣習に頼るのではなく、検証可能な制御システムによって保証されます。一方、実行プレーンは Python で実装されており、開発効率を維持しつつ、研究者やエンジニアにとって機能の反復速度を高め、認知負荷を低減しています。
TokenSpeed カーネル TokenSpeed kernel レイヤーは、カーネルをコアエンジンから分離し、それをファーストクラスのモジュールサブシステムとして扱います。これは、ポータブルなパブリック API、中央集権的なレジストリと選択モデル、整理された実装、異種アクセラレーター向けの拡張可能なプラグイン機構、厳選された依存関係、そして迅速な反復のための統一されたインフラストラクチャを提供します。また、NVIDIA Blackwell におけるパフォーマンス最適化にも多大な投資を行っており、例えばアジェンシーワークロード向けに最も高速な MLA (Multi-head Latent Attention) カーネル の一つを構築しました。デコードカーネルでは、q_seqlen と num_heads をグループ化して、一部のユースケースで num_heads が小さい場合でも Tensor Cores を完全に活用できるようにしています。バイナリプリフェッチカーネルには、微調整されたソフトマックス実装が含まれています。TokenSpeed MLA は vLLM によって採用されています。
パフォーマンスプレビュー
本日、TokenSpeed のパフォーマンスプレビューを共有します。開発は 2026 年 3 月中旬に開始されました。*エンジンとカーネルは現在も活発に開発が続けられており、本番環境での堅牢化は来月に行われる予定です。今後数週間で多くの追加 PR がマージされる見込みです。*
コーディングエージェントは、非常に過酷な推論ワークロードを呈します。コンテキストは通常 50K トークンを越え、会話は何十ものターンにわたることが珍しくありません。ほとんどのパブリックベンチマークでは、この振る舞いを完全に捉えきれていません。私たちは EvalScope チームと協力し、TokenSpeed を SWE-smith のトレースに対して評価しました。これは、本番環境でのコーディングエージェントのトラフィックを非常に忠実に模倣するものです。生成速度はエージェントにおけるユーザー体験にとって決定的に重要であるため、私たちの目標は *1 人あたりの TPS(秒間トークン数)の下限を維持しつつ、GPU あたりの TPM(分間トークン数)を最大化すること* です — 通常は 70 TPS で、場合によっては 200 TPS またはそれ以上です。
私たちは、TensorRT-LLM(NVIDIA Blackwell における現在の最先端技術)に対して 設計のベンチマーク を実施し、エージェントワークロードにおいてより良いトレードオフが存在すると考える箇所では、そのアプローチからあえて逸脱しました。
注記: このブログは、単一(非分離型)デプロイメントに焦点を当てています。PD 分離型のサポートについては現在クリーンアップ中で、専用のフォローアップブログで取り上げる予定です。
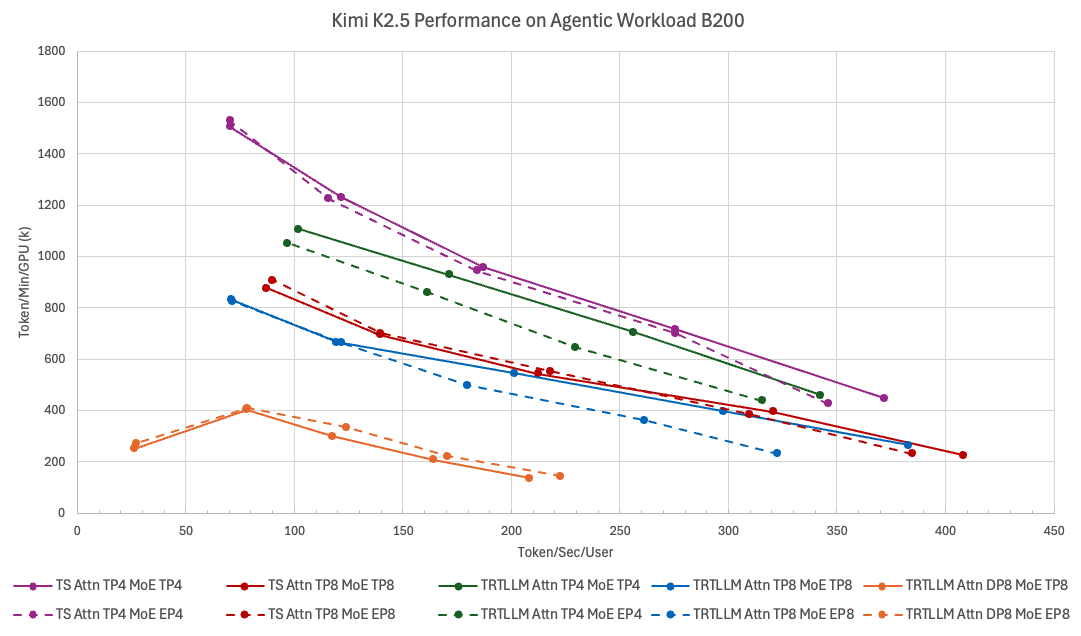
以下の図は、TokenSpeed と TensorRT-LLM の Kimi K2.5 性能のパレート曲線を示しています。これは異なるデプロイ構成(PD 非集約あり)における比較です。各曲線は、レイテンシ指標として TPS/User(x 軸)、スループット指標として TPM/GPU(y 軸)を使用し、並行度を掃引することでトレースされています。コーディングエージェント向け(70 TPS/User 以上)において、最適な構成は「Attention TP4 + MoE TP4」です。この構成では、TokenSpeed はパレートフロンティア全体で TensorRT-LLM を上回ります:最小レイテンシケース(バッチサイズ 1)では約 9% 高速であり、100 TPS/User 付近のスループットは約 11% 高いです。
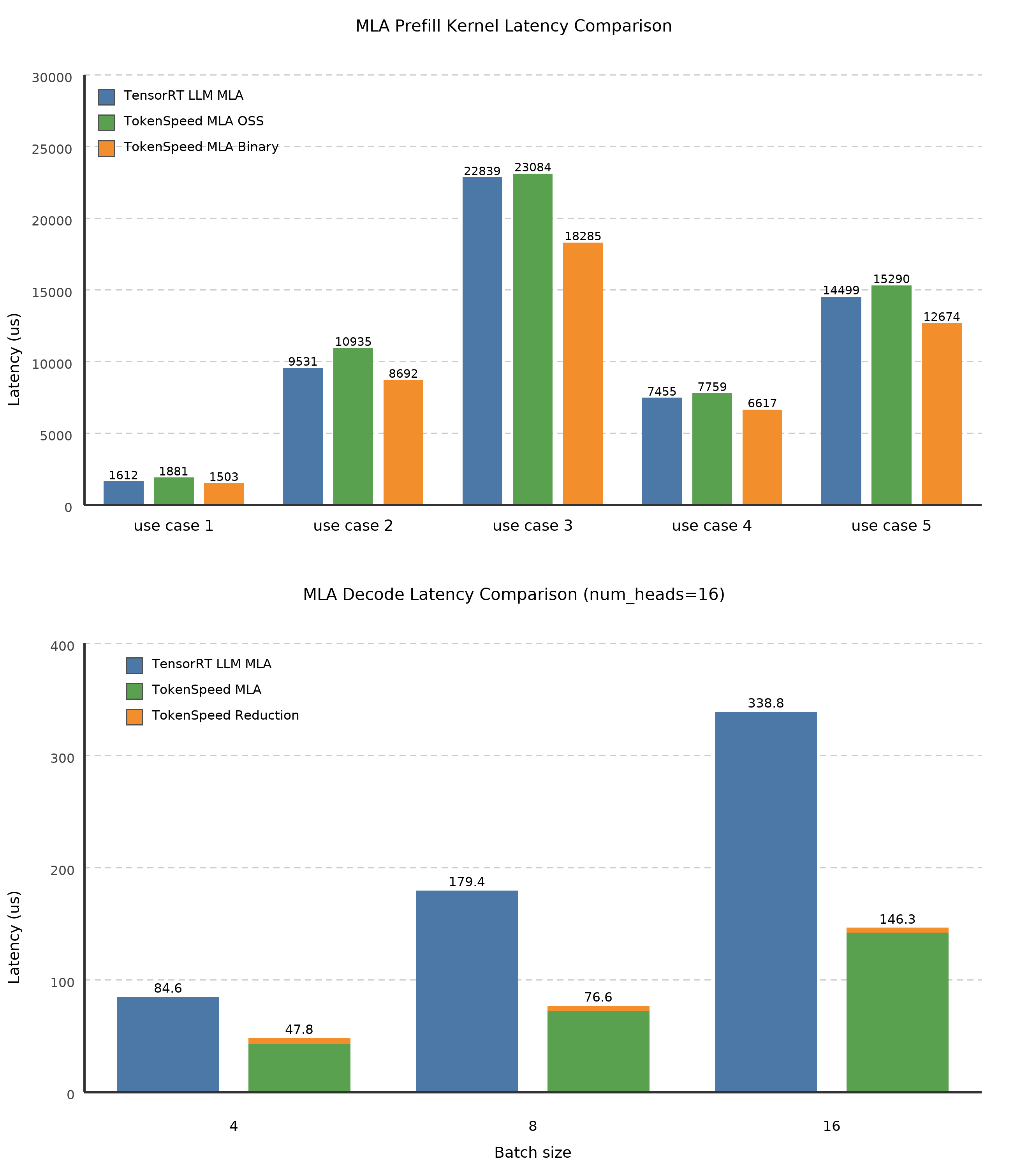
当社のコア最適化の一つに TokenSpeed MLA があります。以下の図は、NVIDIA Blackwell における現在の最良技術(SoTA)である TensorRT-LLM の MLA と比較した TokenSpeed MLA を示しています。当社の最適化されたバイナリ版プリフィルルカーネルは、NVIDIA 内部の調整パラメータを使用してソフトマックス実装を微調整しており、コーディングエージェントにおける典型的な 5 つのプリフィルルワークロード(長いプレフィックス KV キャッシュ付き)すべてで TensorRT-LLM の MLA を上回っています。デコードカーネルは、クエリシーケンス軸をヘッド軸に折りたたむことで BMM1 M タイルをより効率的に埋め込み、Tensor Core の利用率を向上させています。他の最適化と組み合わせることで、推測的デコーディング(バッチサイズ 4, 8, 16 と長いプレフィックス KV キャッシュ)を含む典型的なデコードワークロードにおいて、レイテンシが TensorRT-LLM に対してほぼ半減します。
謝辞
TokenSpeed は、NVIDIA DevTech、AMD Triton、Qwen Inference、Together AI、Mooncake、LongCat、FluentLLM、EvalScope、NVIDIA Dynamo、および LightSeek Foundation との共同開発により実現されました。[[1]](#fn1)
TensorRT-LLM のメンテナーの皆様には深く感謝いたします。彼らの業績が私たちが自らの成果を測るための基準を設定してくれました。私たちの多くの最適化手法は TensorRT-LLM にインスピレーションを得たものであり、特に 1 つの CUDA グラフ(CUDA graph)最適化や順伝播(forward pass)の最適化などがその例です。また、プロダクション環境での大規模言語モデル(LLM)推論サービスが到達しうる可能性を押し広げてくれた、より広いオープンソース推論コミュニティ(Triton、FluentLLM、vLLM、EvalScope、FlashInfer、SGLang など)の皆様にも感謝申し上げます。
OpenAI、NVIDIA、AMD、Verda、および Nebius からの計算リソース支援についても、深く謝意を表します。
- コントリビューター:共創者。Enwei Zhu, Jiying Dong, Xipeng Li (NVIDIA) · Pengzhan Zhao, Kyle Wang, Lei Zhang (AMD) · Jiandong Jiang, Tuan Zhang, Minmin Sun (Qwen Inference) · Jue Wang, Yineng Zhang (Together AI) · Hongtao Chen, Mingxing Zhang (Mooncake) · Bo Wang, Fengcun Li (LongCat) · Xiangyang Ji, Yulei Qian (FluentLLM)。コアランタイム:スケジューラー — Yulei Qian, Fengcun Li, Bo Wang。カーネル — Lei Zhang, Pengzhan Zhao, Kyle Wang。モデリング — Yulei Qian, Xiangyang Ji, Jue Wang。MLA(Multi-Head Latent Attention)— Albert Di, Jiying Dong。文法とサンプリング — Jue Wang, Weicong Wu。MoE(Mixture of Experts)— Hongtao Chen。VLM(Vision Language Model)— Hongtao Chen, Fengcun Li, Bo Wang。
モデル最適化:Kimi K2.5 の光速最適化 — Enwei Zhu, Jiying Dong, Yue Weng, Albert Di。Qwen 3.6 — Minmin Sun, Tuan Zhang, Jiandong Jiang。DeepSeek V4 — Jiying Dong, Qingquan Song, Qiukai Chen, Yechan Kim, Hejian Sang。AMD 上の GPT-OSS — Pengzhan Zhao, Kyle Wang。Minimax M2.7 — Fan Yin, Jue Wang。
システムと統合:分散ランタイム — Xuchun Shang, Teng Ma。推測的デコーディング(Speculative Decoding)— Yue Weng。AsyncLLM と SMG — Simo Lin, Keyang Ru, Xipeng Guan。TensorRT-LLM カーネル — Aaron Liu, Enwei Zhu。メトリクス — Fred Wang。EvalScope ベンチマーク — Xingjun Wang, Yunlin Mao。Dynamo 統合 — Yuewei Na, William Arnold。↩︎
原文を表示
Agentic coding has quickly scaled from promising demos to a force that is reshaping how software is developed and how frontier AI systems are built and deployed. Systems like Claude Code, Codex, and Cursor have gained massive user adoption and now generate an extraordinary volume of tokens. To meet this growth, data centers requiring tens of gigawatts of power are being built, backed by hundreds of billions of dollars in investment.
At this scale, the efficiency of the systems orchestrating model inference becomes critically important. Even small improvements in throughput per GPU, when applied across a production fleet, can translate into substantial capacity savings while serving ever-growing demand.
TokenSpeed Overview
TokenSpeed is designed from first principles for the agentic-inference regime. It delivers *speed-of-light* inference for agentic workloads, with *a compiler-backed modeling mechanism for parallelism, a high performance scheduler, a safe KV resource reuse restriction, a pluggable layered kernel system that supports heterogeneous accelerators*, and SMG integration for a low-overhead CPU-side request entrypoint.
The modeling layer adopts a local SPMD (Single Program, Multiple Data) design that balances performance and usability. TokenSpeed enables developers to specify I/O placement annotations at module boundaries. A lightweight static compiler then automatically generates the required collective operations during model construction, eliminating the need to manually implement communication logic.
The TokenSpeed scheduler decouples the control plane from the execution plane. The control plane is implemented in C++ as a finite-state machine that works with the type system to enforce safe resource management, including KV cache state transfer and usage, at compile time rather than at runtime. Request lifecycle, KV cache resources, and overlap timing are represented through explicit FSM transitions and ownership semantics, so correctness is enforced by a verifiable control system rather than convention. The execution plane is implemented in Python to maintain development efficiency, enabling faster feature iteration and lower cognitive load for researchers and engineers.
The TokenSpeed kernel layer separates kernels from the core engine and treats them as a first-class modular subsystem. It provides a portable public API, a centralized registry and selection model, organized implementations, an extensible plugin mechanism for heterogeneous accelerators, curated dependencies, and unified infrastructure for rapid iteration. We have also invested heavily in performance optimization on NVIDIA Blackwell — for example, we built one of the fastest MLA (Multi-head Latent Attention) kernels for agentic workloads. In the decode kernel, we grouped q_seqlen and num_heads to fully utilize Tensor Cores as num_heads are small in some of these use cases. The binary prefill kernel includes a fine-tuned softmax implementation. TokenSpeed MLA has been adopted by vLLM.
Performance Preview
Today, we are sharing a performance preview of TokenSpeed. Development began in mid-March 2026. *The engine and kernels remain under active development, with production hardening planned over the next month. Many additional PRs are expected to land in the coming weeks.*
Coding agents present unusually demanding inference workloads. Contexts routinely exceed 50K tokens, and conversations often span dozens of turns. Most public benchmarks do not fully capture this behavior. Together with the EvalScope team, we evaluate TokenSpeed against SWE-smith traces, which closely mirror production coding-agent traffic. Because generation speed is crucial to the user experience for agents, our objective is to *maximize per-GPU TPM (tokens per minute) while maintaining a per-user TPS (tokens per second) floor* — typically 70 TPS, and sometimes 200 TPS or higher.
We benchmarked our design against TensorRT-LLM — the current state of the art on NVIDIA Blackwell — and diverged from its approach wherever we believe better trade-offs exist for agentic workloads.
Note: This blog focuses on single (non-disaggregated) deployment. PD disaggregation support is undergoing cleanup, and we will cover it in a dedicated follow-up blog.
The figure below shows the Kimi K2.5 performance Pareto curves of TokenSpeed and TensorRT-LLM across different deployment configurations (without PD disaggregation). Each curve uses TPS/User (x-axis) as the latency metric and TPM/GPU (y-axis) as the throughput metric, and is traced by sweeping concurrency. For coding agents (above 70 TPS/User), the best configuration is Attention TP4 + MoE TP4, where TokenSpeed dominates TensorRT-LLM across the entire Pareto frontier: roughly 9% faster in the min-latency case (batch size 1), and roughly 11% higher throughput around 100 TPS/User.
One of our core optimizations is TokenSpeed MLA. The figure below compares TokenSpeed MLA against TensorRT-LLM's MLA, the current SoTA on NVIDIA Blackwell. Our optimized binary-version prefill kernel uses NVIDIA-internal knobs to fine-tune the softmax implementation, outperforming TensorRT-LLM's MLA across all five typical prefill workloads for coding agents (prefill with long prefix KV cache). The decode kernel folds the query-sequence axis into the head axis to better fill the BMM1 M tile, improving Tensor Core utilization. Combined with other optimizations, this nearly halves latency relative to TensorRT-LLM on typical decode workloads with speculative decoding (batch sizes 4, 8, and 16 with long prefix KV cache).
Acknowledgments
TokenSpeed is developed in collaboration with NVIDIA DevTech, AMD Triton, Qwen Inference, Together AI, Mooncake, LongCat, FluentLLM, EvalScope, NVIDIA Dynamo, and the LightSeek Foundation.[[1]](#fn1)
We are grateful to the TensorRT-LLM maintainers, whose work set the bar we measured ourselves against. Many of our optimizations were inspired by TensorRT-LLM, including the one-CUDA-graph optimization and forward pass optimizations. We are also grateful to the broader open-source inference community — including Triton, FluentLLM, vLLM, EvalScope, FlashInfer, SGLang, and others — for raising the ceiling on what production LLM serving can look like.
We acknowledge and appreciate the compute support from OpenAI, NVIDIA, AMD, Verda, and Nebius.
- ContributorsCo-creators. Enwei Zhu, Jiying Dong, Xipeng Li (NVIDIA) · Pengzhan Zhao, Kyle Wang, Lei Zhang (AMD) · Jiandong Jiang, Tuan Zhang, Minmin Sun (Qwen Inference) · Jue Wang, Yineng Zhang (Together AI) · Hongtao Chen, Mingxing Zhang (Mooncake) · Bo Wang, Fengcun Li (LongCat) · Xiangyang Ji, Yulei Qian (FluentLLM).Core runtime. Scheduler — Yulei Qian, Fengcun Li, Bo Wang. Kernels — Lei Zhang, Pengzhan Zhao, Kyle Wang. Modeling — Yulei Qian, Xiangyang Ji, Jue Wang. MLA — Albert Di, Jiying Dong. Grammar and sampling — Jue Wang, Weicong Wu. MoE — Hongtao Chen. VLM — Hongtao Chen, Fengcun Li, Bo Wang.Model optimization. Kimi K2.5 speed-of-light optimization — Enwei Zhu, Jiying Dong, Yue Weng, Albert Di. Qwen 3.6 — Minmin Sun, Tuan Zhang, Jiandong Jiang. DeepSeek V4 — Jiying Dong, Qingquan Song, Qiukai Chen, Yechan Kim, Hejian Sang. GPT-OSS on AMD — Pengzhan Zhao, Kyle Wang. Minimax M2.7 — Fan Yin, Jue Wang.System and integration. Distributed runtime — Xuchun Shang, Teng Ma. Speculative decoding — Yue Weng. AsyncLLM and SMG — Simo Lin, Keyang Ru, Xipeng Guan. TensorRT-LLM kernels — Aaron Liu, Enwei Zhu. Metrics — Fred Wang. EvalScope benchmark — Xingjun Wang, Yunlin Mao. Dynamo integration — Yuewei Na, William Arnold. ↩︎
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み