Snowflake と Amazon QuickSight を活用した AI 駆動 BI の実現
AWS と Snowflake の連携により、データレイヤーにビジネスロジックを統合する「セマンティックビュー」を活用することで、AI と BI システム間の数値不整合を解消し、信頼性の高い意思決定を可能にする実装手法が示されています。
キーポイント
データの不整合と信頼性低下の課題
組織内でアプリケーションごとにビジネスロジックが分断されているため、ダッシュボードやチャットエージェント間で数値に矛盾が生じ、意思決定の遅延やデータへの不信感が生じている。
セマンティックビューによる解決策
Snowflake の「セマンティックビュー」機能を用いて、テーブル定義やメトリクスなどのビジネスロジックをデータレイヤーに一元化し、AI と BI システムが同一の定義を参照する仕組みを提供する。
Cortex Analyst と QuickSight の統合
Snowflake Cortex Analyst で自然言語クエリを実行して分析を行い、その結果を Amazon QuickSight のデータセットとして連携させることで、統制されたデータレイヤーからの信頼できる回答を実現する。
ガバナンスとセキュリティの強化
セマンティックビューをネイティブな Snowflake オブジェクトとして扱い、テーブルやビューと同様にオブジェクトレベルでのアクセス制御を適用することで、権限管理された安全な利用環境を整備する。
影響分析・編集コメントを表示
影響分析
この記事は、AI と BI が別々のロジックで動作することで生じる「データの分断」問題を解決する具体的なアーキテクチャを示しており、企業におけるデータドリブンな意思決定の信頼性を根本から高める可能性を秘めています。特に、LLM の出力信頼性向上と既存 BI ツールの活用を両立させる実装パターンは、多くの組織が直面している AI 導入のボトルネックを解消する重要な指針となります。
編集コメント
AI と BI の融合において、単なるツールの連携だけでなく「データ定義の統一」という根本課題にアプローチした点は非常に示唆に富んでいます。実務レベルで即座に適用可能な解決策であり、データ信頼性を確保しながら AI を活用したい組織にとって必読の内容です。
あるダッシュボードでは 42,000 のアクティブな映画視聴数が表示され、別のダッシュボードでは 38,500 が表示されています。一方、チャットエージェントは全く異なる第 3 の数値を参照しています。データチームは戦略的な質問に答えるのではなく、数値の整合性を合わせるために何時間も費やし、分析への信頼が損なわれています。
これは多くの組織で共通して見られるパターンです。チームは実際に数値を活用するよりも、数値の整合性を合わせることに多くの労力を割き、結果として意思決定が遅れ、データに対する自信が徐々に削られていきます。
その根本原因は通常、「ラストマイルギャップ」にあります。つまり、ビジネスロジックが各アプリケーション内部に個別に存在しており、すべてのアプリケーションで共有できるデータレイヤーに存在していないことです。
Snowflake 上の Amazon Quick Sight データセットと セマンティックビュー(*semantic views*)がこのギャップを埋めます。*セマンティックビュー*とは、表、関係性、メトリクス、次元といったビジネス定義をデータに直接紐付ける Snowflake スキーマオブジェクトです。このセマンティックビューをクエリするすべての後続アプリケーションは、同じ定義を引き継ぐため、AI システムと BI システムの両方が情報を一貫して解釈します。これにより信頼性の高い回答が得られ、AI のハルシネーション(幻覚)リスクが大幅に軽減されます。
Cortex Analyst ではセマンティックビューを使用でき、SELECT ステートメントでこれらのビューをクエリできます。また、セマンティックビューはプライベートリストでも共有可能です。ネイティブな Snowflake スキーマオブジェクトとして、セマンティックビューにはオブジェクトレベルのアクセス制御が適用されます。テーブルやビューと同様に、使用権限やクエリ権限の付与・制限を行うことができ、SQL、BI、AI エンドポイント全体で承認され、ガバナンスされた利用をサポートします。Semantic SQL の書き方については、Snowflake ドキュメントをご覧ください。
本記事では、Snowflake セマンティックビューと Amazon Quick 間のエンドツーエンド統合を構築する方法を学びます。サンプルデータは、メディア企業のユーザーレビューデータです。まず、Amazon Simple Storage Service(Amazon S3)から映画レビューデータを Snowflake にロードし、ビジネス上の意味を追加するために SQL でセマンティックビューを定義します。次に、Cortex Analyst を通じて自然言語クエリで探索し、その後 Amazon Quick のデータセットとダッシュボードを生成します。データセットは手動で作成するか、提供された自動化スクリプトを使用して作成できます。最後には、BI チームまたは AI チームがガバナンスされたデータレイヤーに対して自然言語の質問を行い、すべての回答が同じビジネスロジックを反映していることを信頼できるようになります。
ソリューションアーキテクチャ
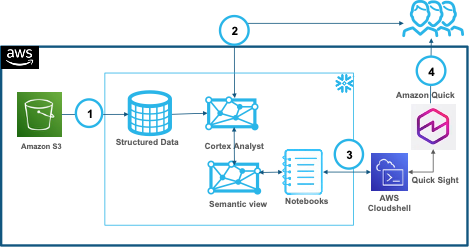
図1:エンドツーエンドのアーキテクチャ。データはAmazon S3からSnowflakeへ流れ、セマンティックビューがビジネス定義を統括し、Cortex Analystによる自然言語クエリとAmazon Quick Sightダッシュボードの両方を可能にします。
この統合では、Snowflakeのネイティブ機能を使用して、構造化された映画レビューデータを直接Amazon S3からデータベーススキーマに取り込みます。その後、SQLを用いてテーブル間の関係、次元、メトリクスを定義したSnowflakeのセマンティックビューを作成し、AI駆動型分析を強化します。このアプローチにより、個々のAI層やBI層ではなく、コアデータプラットフォームにセマンティックモデルがシフトし、すべてのツールが同じセマンティック概念を利用できるようになります。
ソリューションウォークスルー
本ウォークスルーでは、映画レビューのデータセットを使用して統合をデモンストレーションします。このデータセットは、Amazon S3からSnowflakeへロードする3つのテーブル(MOVIES、USERS、RATINGS)で構成されています。これらのテーブルの上に、生のカラムをビジネスに親和性のあるメトリクスと次元にマッピングするセマンティックビューを定義します。
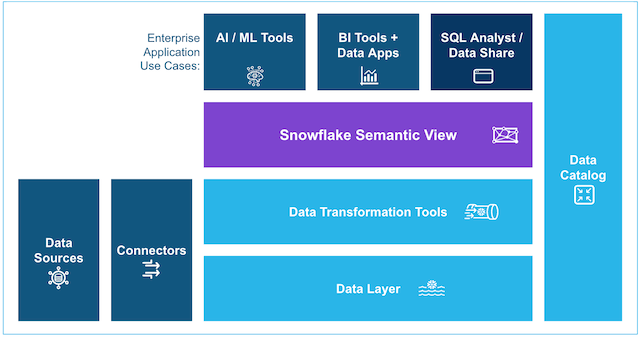
図2:Snowflakeのセマンティックビューは、生テーブルにビジネスコンテキスト(メトリクス、次元、関係性)を追加し、AIおよびBIツール向けの共有定義レイヤーを作成します。
この統合により、BI チームは自然言語を使用して対話型チャートやダッシュボードの作成、計算フィールドの構築、データストーリーの開発、および何らかのシナリオ分析(what-if scenarios)を行うことが可能になり、AI の幻覚(hallucinations)によるリスクが大幅に軽減されます。また、BI チームは Snowflake から取得したこのダッシュボードを Amazon Quick Movies Quick Space に組み込むことで、検索拡張生成(RAG: Retrieval Augmented Generation)を実現できます。
前提条件
開始する前に、以下の環境が整っていることを確認してください:
- AWS 上の Snowflake Enterprise アカウント。お持ちでない場合は、Snowflake のトライアルアカウントに登録し、AWS で Enterprise を選択してください。
- Snowflake における ACCOUNTADMIN ロールへのアクセス権限。このロールはセマンティックビューの作成とオブジェクトレベルの権限付与に必要です。
- AWS アカウント。お持ちでない場合は、AWS アカウントを作成してください。
- AWS リージョンの整合性。両方のアカウントを AWS US West (Oregon) または US East (N. Virginia) に登録してください。Amazon Quick Sight は、US East (N. Virginia)、US West (Oregon)、アジア太平洋地域(シドニー)、およびヨーロッパ(アイルランド)で利用可能です。最新のリージョン対応状況については、Amazon Quick の公式ドキュメントを参照してください。
- SQL および Python に関する基本的な知識。Snowsight(Snowflake の Web インターフェース)では SQL ステートメントを実行し、AWS CloudShell では Python ベースのスクリプトを実行します。
- テーブル、ディメンション、メトリクスなどのデータ分析概念への理解。
所要時間: このチュートリアルを最初から最後まで完了するには、60〜90 分程度を見込んでください。
推定コスト: このチュートリアルでは最小限のリソースを使用します。AWS と Snowflake の合計コストは 10 ドル未満を見込んでください。
ステップ 1: Snowflake 環境のセットアップとデータ読み込み
Snowsight(Snowflake の Web インターフェース)を使用して、提供されたノートブックをインポートして実行します。このノートブックは、必要な計算用ウェアハウス、データベース、スキーマを作成し、映画レビューデータをロードするため、セットアップ用の SQL を手動で実行する必要はありません。
ノートブックのインポート
開始するには、事前に構築されたチュートリアル用ノートブックを Snowflake 環境にインポートして、対話形式で手順を追えるようにします。
- GitHub リポジトリのアセットフォルダから
SF_Quick_Quickstart.ipynbという名前のノートブックをダウンロードします。 - Snowsight でプラス記号(+)を選択し、「Notebook」→「Import」をクリックして、ダウンロードしたノートブックファイルを選択します。
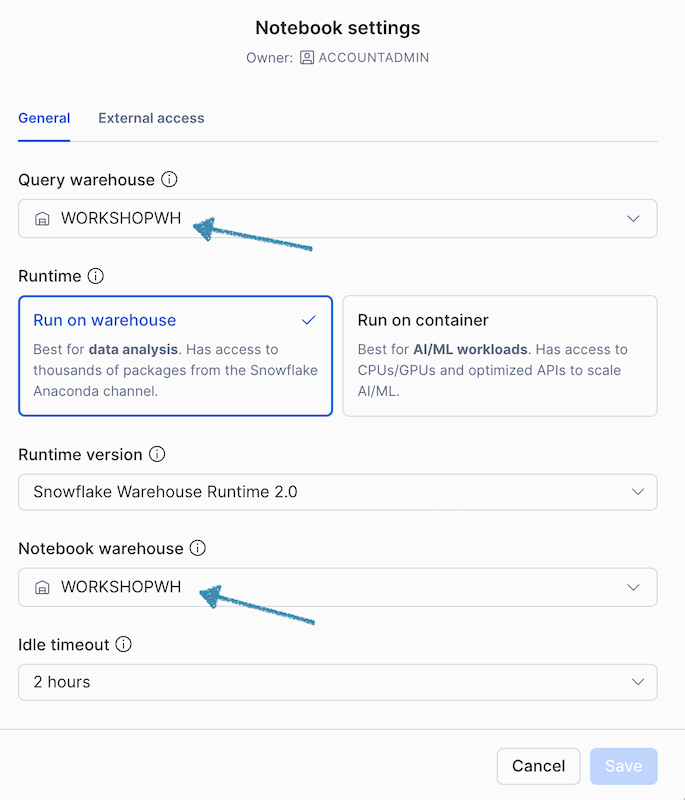
- デフォルト設定を受け入れ、「Run on Warehouse」を選択します。ノートブックはデフォルトで
SYSTEM$STREAMLIT_NOTEBOOK_WH(システムが提供する計算リソース)を使用しますが、ドロップダウンメニューから別のウェアハウスを選択することもできます。このチュートリアルでは、ノートブックがWORKSHOPWHという名前の新しいウェアハウスを作成します。
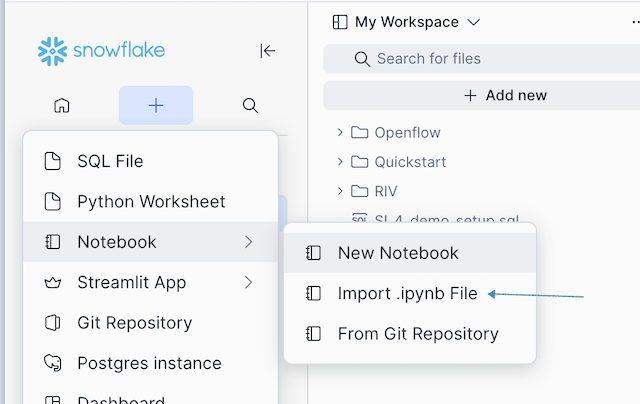
図 3: Snowsight のプラス(+)メニューを使用してノートブックをインポートする方法を示す画像。
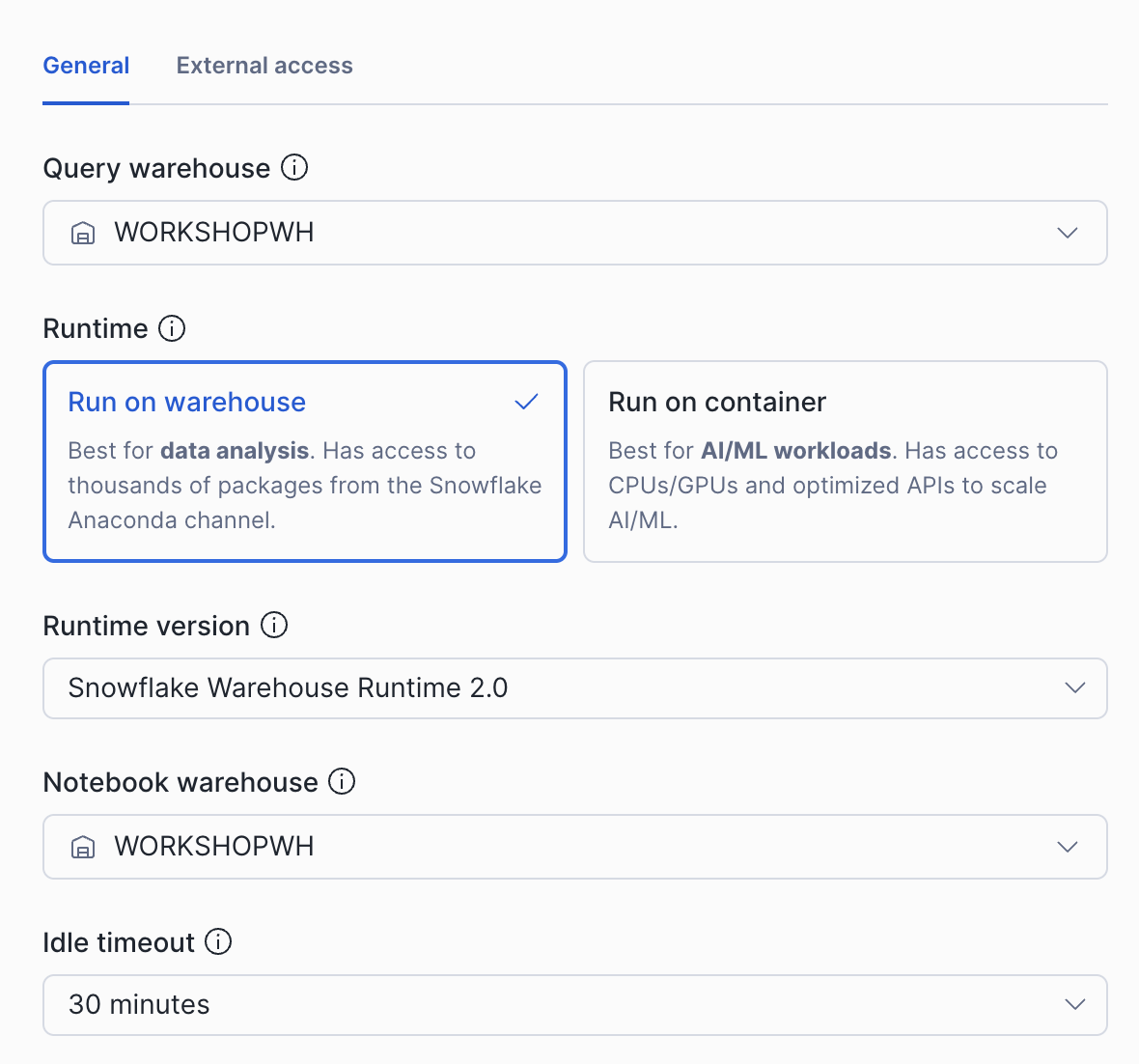
図 4:「Warehouse で実行」オプションを選択し、ノートブック作成時に計算用ウェアハウスを選択する様子を示す画像。
ノートブック作成後、ノートブック設定から異なるウェアハウスを選択できます。詳細については ノートブック設定 を参照してください。
ノートブックを実行してデータをロードする
Snowflake Notebooks には、numpy、pandas、matplotlib など一般的な Python ライブラリが事前にインストールされています。他のパッケージを追加するには、ノートブック右上の Packages ドロップダウンを選択してください。
すべてのセルを順次実行します。このノートブックは WORKSHOPWH ウェアハウスをプロビジョニングし、映画レビューデータを MOVIES データベースにロードします。各セルの実行が完了するたびに、その下に確認出力が表示されます。
セットアップの確認: すべてのセルを実行した後、MOVIES.PUBLIC スキーマ内に MOVIES、USERS、RATINGS の 3 つのテーブルが存在することを確認してください。
トラブルシューティング: セルの実行に失敗した場合は、ACCOUNTADMIN ロールを使用しているか確認してください。このロールはノートブックまたはワークシートの上記で以下のように設定できます:
USE ROLE ACCOUNTADMIN;
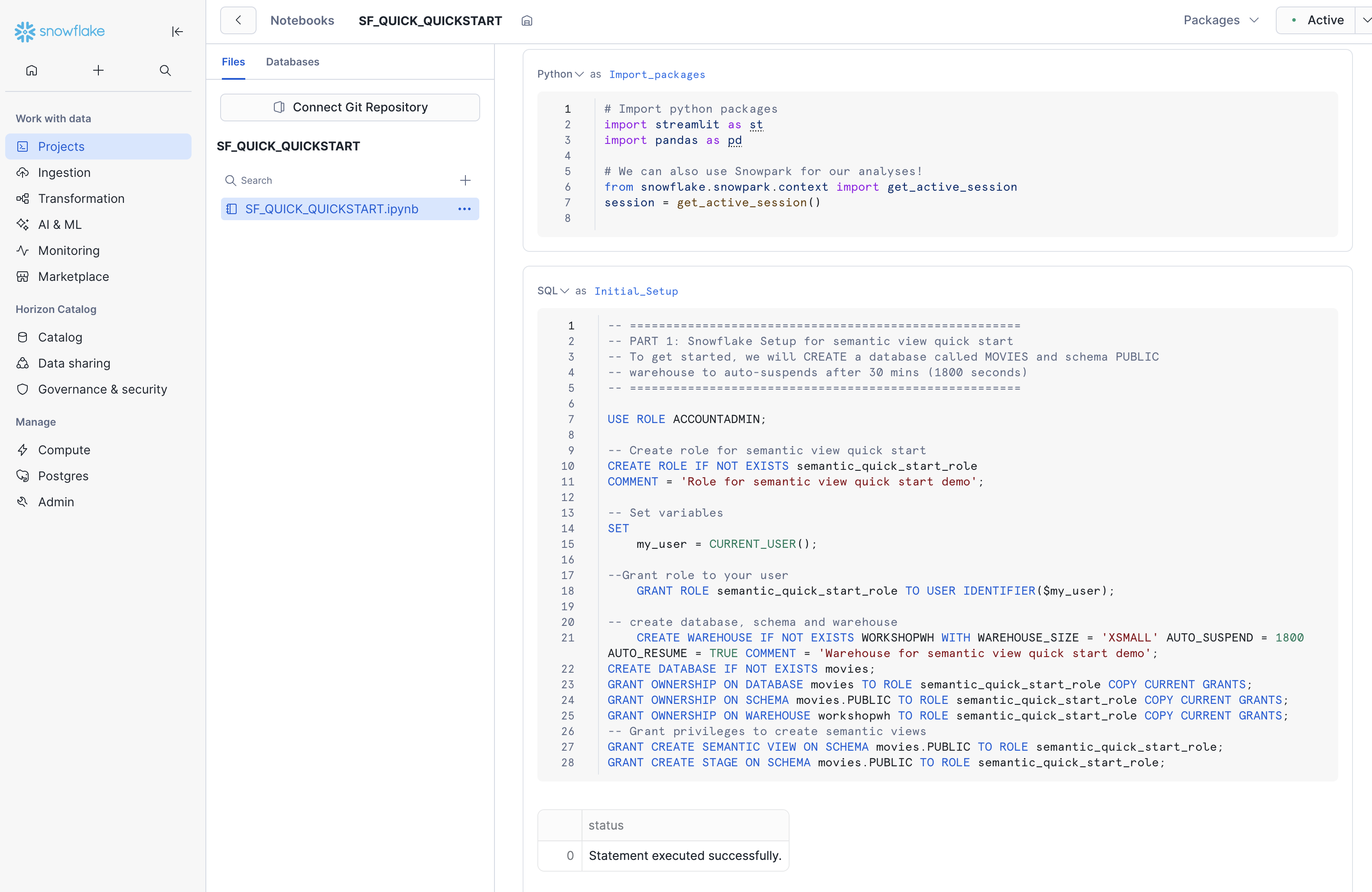
図 5:すべてのノートブックセルを実行して、データを MOVIES データベースにロードします。
ステップ 2:セマンティックビューの定義と DDL のエクスポート
すべてのセルが正常に実行されたら、Get_SV_DDL セルを探してください。このセルは以下の SQL を実行して、セマンティックビューの DDL(データ定義言語)を取得します。
SELECT TO_VARCHAR(GET_DDL(
'SEMANTIC_VIEW',
'MOVIES.PUBLIC.MOVIE_ANALYTICS_SV'
));
重要 Get_SV_DDL セルを実行した後、CSV としてダウンロードを選択し、ファイルを SF_DDL.csv として保存してください。このファイルはステップ 4 で Amazon QuickSight のデータセットを自動的に生成するために必要です。この手順をスキップすると、データセット生成ツールがスキーマを解析できません。
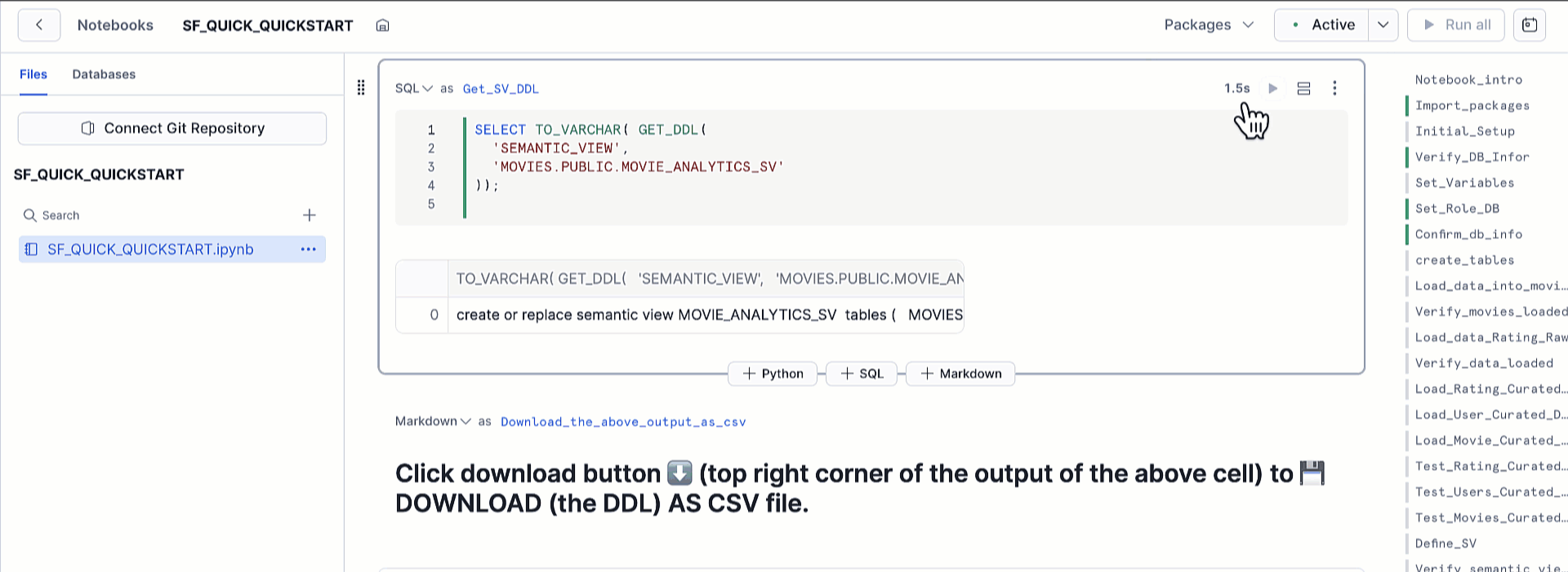
図 7:QuickSight データセット生成に必要な SF_DDL.csv を保存するには、CSV としてダウンロードを選択してください。
ステップ 3:Cortex Analyst でデータを探索する
セマンティックビューが作成されたので、SQL を使用せずに平易な英語ですぐにデータクエリを実行できます。この手順は、Amazon QuickSight に接続する前に、セマンティクスレイヤーが正しく機能していることを確認するために行います。
Snowsight でセマンティックビューを表示する
- Snowsight のナビゲーションペインから [AI & ML] を選択します。
- 先に作成した
SEMANTIC_QUICK_START_ROLEを選択し、適切な権限があることを確認します。
- Movies データベースへ移動し、Public スキーマを選択した後、その構造を検査するために
MOVIES_ANALYST_SVセマンティックビューを選択します。
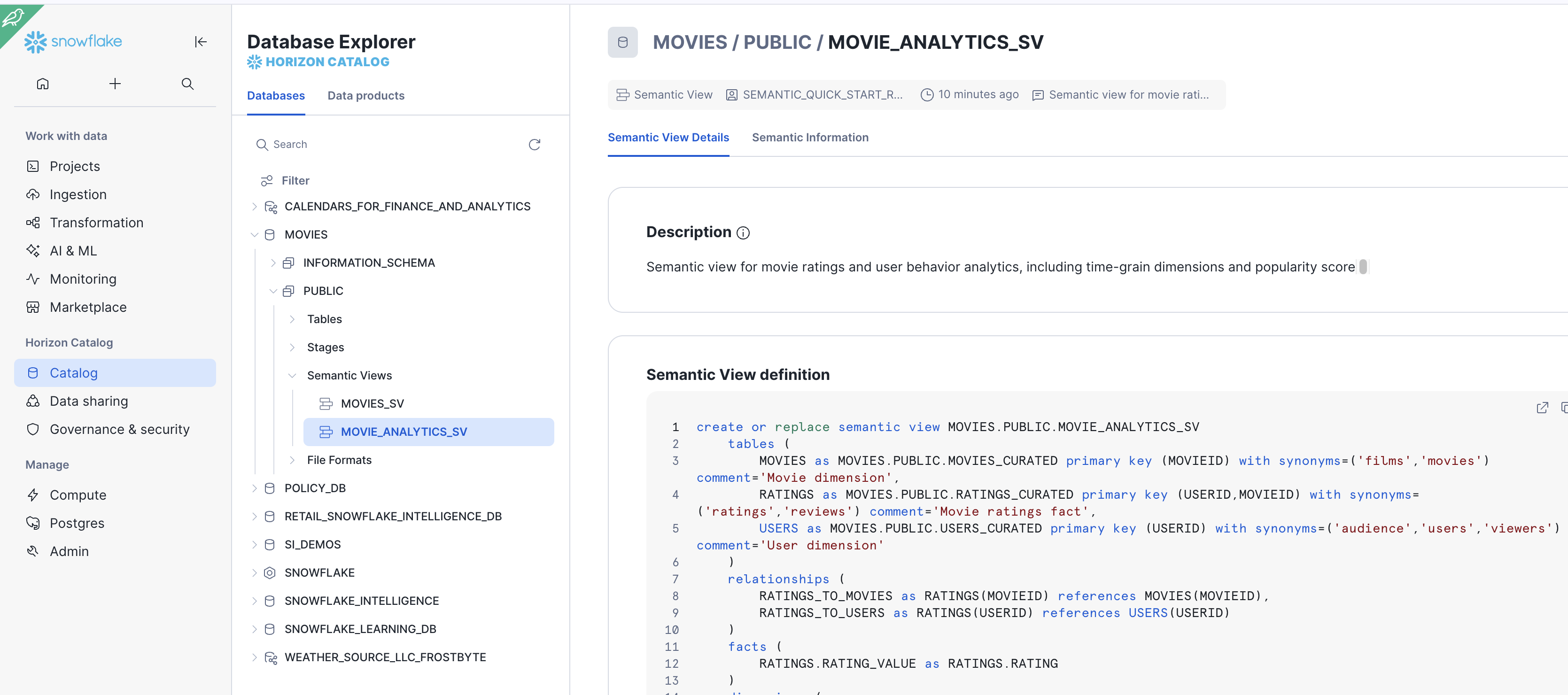
図 8: Snowsight の AI & ML セクションに表示される MOVIES_ANALYST_SV セマンティックビュー。
検証済みクエリの追加
検証済みクエリとは、正解が確認された例題質問のことです。これらは、同様の表現で質問された際に Cortex Analyst が回答する際の参照基準となり、精度の向上とクエリのレイテンシ(応答遅延)の削減に寄与します。自然言語による質問のテストを行う前に、少なくとも 1 つの検証済みクエリを追加してください。
例:「2023 年のすべての映画の平均評価は何ですか?」という問いに対して、Cortex Analyst が正しい SQL を生成することを確認することで検証を行います。ユーザーが後に同様の表現で質問した場合、Cortex Analyst はまずその質問を検証済みクエリと照合します。
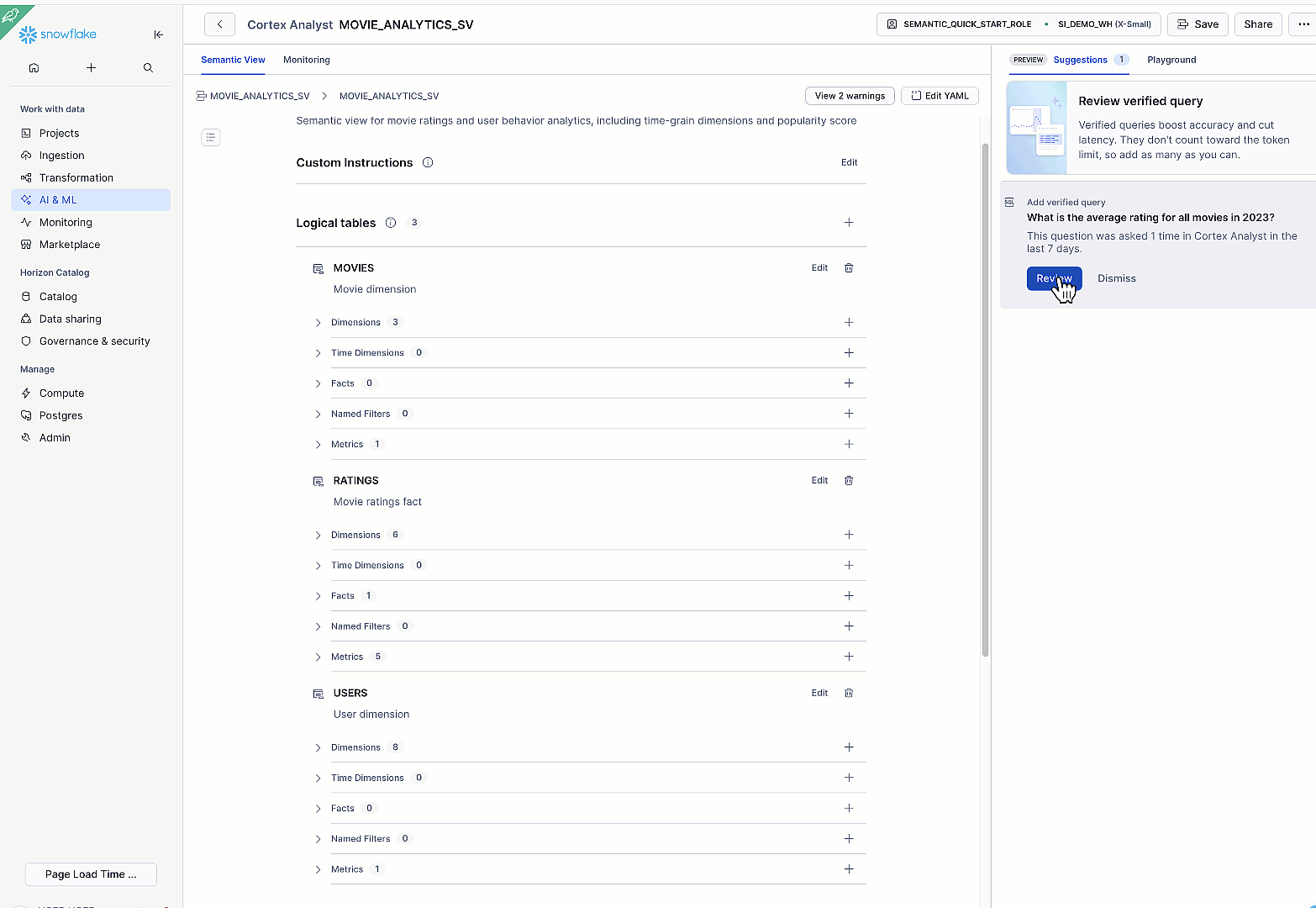
図 9: Snowsight で検証済みクエリを追加し、Cortex Analyst の精度を向上させる。
テキストベースのクエリを試す
セマンティックビューが正しく応答するか確認するために、以下のサンプル質問を試してください:
- 映画タイトルごとの総評価値を表示してください。
- 歴史上最も人気のある映画トップ 10 をリストアップしてください。
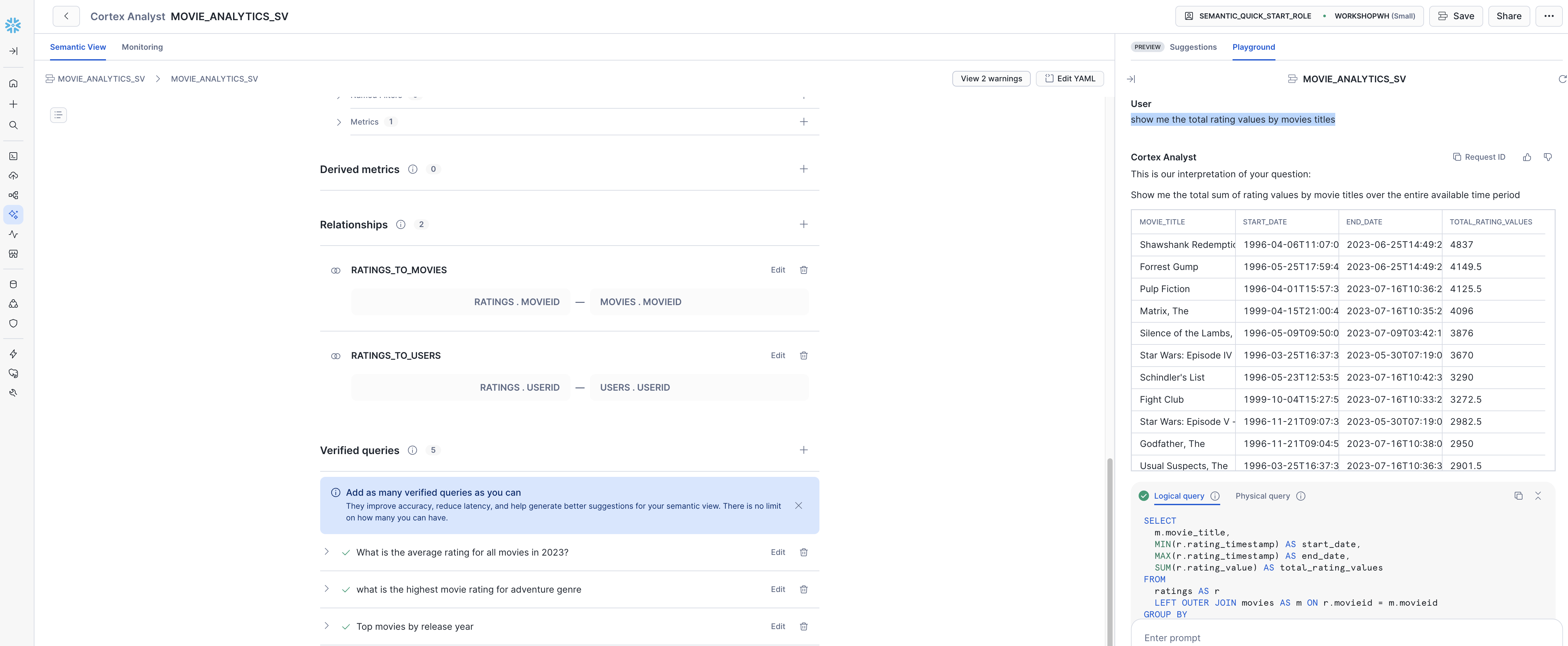
図 10: Cortex Analyst は、セマンティックビュー定義を使用して自然言語の質問を SQL に変換します。
セマンティックビューに対して直接 SQL を使用してクエリを実行するには、Snowflake のドキュメントにある セマンティックビューのクエリ例 を参照してください。
ステップ 4: Amazon QuickSight データセットの作成
これで Snowflake 内でデータがセマンティックに定義されたため、対話型ダッシュボードのために Amazon QuickSight に接続します。提供されている QuickSight データセット生成スクリプトは、Snowflake の DDL からクエリ可能な QuickSight データセットまでのパイプライン全体を自動化します。
オプション 1: Python パッケージをローカルで実行する
GitHub リポジトリ から完全なソリューションをダウンロードしてください。README.md のガイダンスに従って、Snowflake に接続し、セマンティックビュー定義を取得し、その定義を QuickSight データセットスキーマに変換し、QuickSight データセットを作成します。Python スクリプトは自己案内機能付きの対話式です。
オプション 2: AWS CloudShell で bash スクリプトを実行する
ローカルで Python スクリプトを実行する代わりに、提供された bash および Python スクリプトを直接 AWS CloudShell で実行することで、認証情報を安全に保存し、対話式で SPICE インジェスト機能を備えた完全に設定済みの QuickSight データセットを作成できます。これらはすべてコマンドラインから実行可能です。
ソリューションパッケージのアップロード
GitHub リポジトリ から Solution_Package.zip をダウンロードします。次に AWS Management Console にアクセスし、AWS CloudShell を起動します。CloudShell 内の Actions → Upload file オプションを使用して、Solution_Package.zip をアップロードしてください。
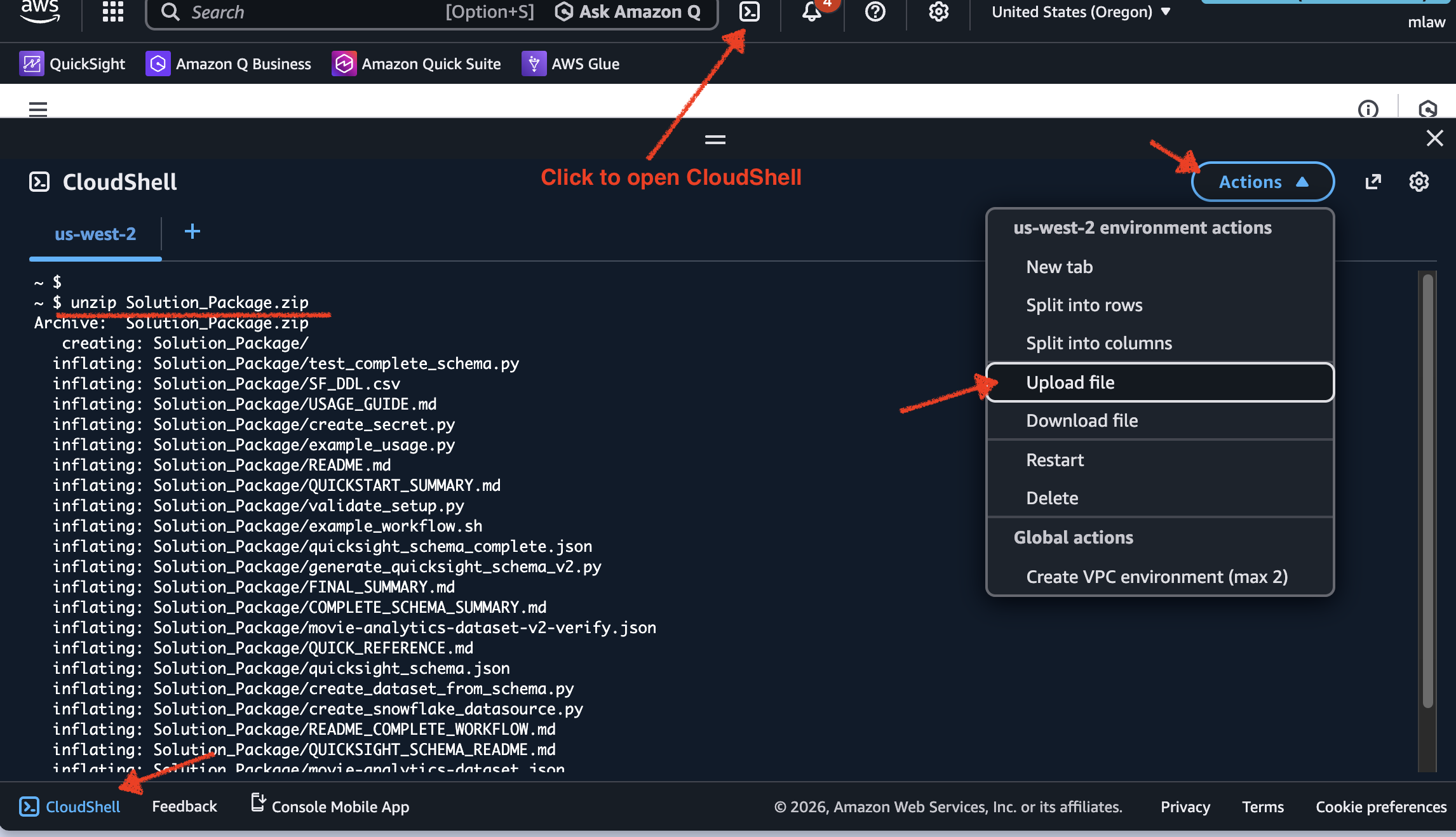
図 11: Actions メニューから Solution_Package.zip を AWS CloudShell にアップロードする。
データセット生成ワークフローの実行
以下の手順を順番に実行してください。
- アーカイブを解凍し、ディレクトリに入ります:
unzip Solution_Package.zip
cd Solution_Package
- Snowflake ノートブックからダウンロードした SF_DDL.csv ファイルをアップロードします(セマンティックビューに対する GET_DDL の出力です)。
- AWS シークレットを作成します。Snowflake の認証情報(アカウント識別子、ユーザー名、パスワード)を AWS Secrets Manager のシークレットとして保存します。このスクリプトは Quick Sight データソースの作成時にこのシークレットを参照します。
python create_secret.py
- インタラクティブワークフローを実行します。シークレットが作成された後、単一のインタラクティブスクリプトを実行します:
python run_workflow.py
このインタラクティブワークフロースクリプトは、Snowflake データソースの選択または作成、新規または既存のデータセットの設定、SF_DDL.csv の解析による Quick Sight スキーマの生成、SPICE 取り込みによるデータセットの作成または更新、そして完了までの取り込み進捗の監視をガイドします。オプションで、Quick Sight コンソール上で取り込みステータスを確認し、他の Quick Sight ユーザーとデータセットを共有することもできます。
ステップ 5: Amazon Quick Sight でダッシュボードを構築する
取り込みが完了したら、Amazon Quick Sight コンソールを開き、データセットに移動します。movie-analytics-datasetを選択してデータが正しく読み込まれたことを確認し、その後分析の作成を選択して構築を開始します。
自然言語による質問で探索する
Cortex Analyst でテストしたのと同じ自然言語質問をそのまま投げてください。QuickSight が自動的に該当する視覚化結果を生成します。まずは以下のサンプル質問を試してみてください:
- 「最も評価の高い映画を表示」 – 平均評価で映画をランク付けする棒グラフを生成します。
- 「レビュー数が最も多い上位 10 本の映画は?」 – レビュー数によるランク付けリストを表示します。
- 「評価はジャンル別にどのように分布していますか?」 – ジャンル別の内訳を生成します。
- 「評価の時間経過に伴う推移を示してください」 – 評価活動の推移を示す折れ線グラフを作成します。
- 「最も多くのレビューを投稿したユーザーは誰ですか?」 – 最も活発なレビュアーを強調表示します。
原文を表示
One dashboard shows 42,000 active movie view counts while another shows 38,500. Your chat agent references a third number entirely. Data teams spend hours reconciling numbers instead of answering strategic questions, and trust in analytics erodes.
This is a pattern that we see across many organizations. Teams spend more effort reconciling numbers than actually using them, quietly slowing down decision-making and chipping away at confidence in the data.
The root cause is usually a *last-mile gap*: business logic lives inside each individual application rather than at the data layer where every application can share it.
Amazon Quick Sight datasets on top of Snowflake semantic views close that gap. A *semantic view* is a Snowflake schema object that attaches business definitions (table, relationships, metrics, and dimensions) directly to your data. Any downstream application that queries the semantic view inherits the same definitions, so both AI and BI systems interpret information uniformly. This leads to trustworthy answers and significantly reduces the risk of AI hallucinations.
You can use semantic views in Cortex Analyst and query these views in a SELECT statement. You can also share semantic views in private listings. As native Snowflake schema objects, semantic views have object-level access controls. You can grant or restrict usage and query rights just as with tables and views, supporting authorized, governed usage across SQL, BI, and AI endpoints. You can read more about how to write Semantic SQL in the Snowflake documentation.
In this post, you will learn how to build an end-to-end integration between Snowflake semantic views and Amazon Quick. The sample data is user review data for a media company. You start by loading movie review data from Amazon Simple Storage Service (Amazon S3) into Snowflake, define a semantic view in SQL to add business meaning, explore it with natural-language queries through Cortex Analyst, and then generate an Amazon Quick dataset and dashboard. The dataset can be created manually or with a provided automation script. By the end, your BI team or AI team can ask natural-language questions against a governed data layer and trust that every response reflects the same business logic.
Solution architecture
Figure 1: End-to-end architecture—data flows from Amazon S3 into Snowflake, where a semantic view governs business definitions, enabling both Cortex Analyst natural-language queries and Amazon Quick Sight dashboards.
This integration uses Snowflake’s native capabilities to ingest structured movie review data directly from Amazon S3 into a database schema. You then define a Snowflake semantic view with table relationships, dimensions, and metrics to enhance AI-powered analytics, all with SQL. The semantic model shifts from individual AI or BI layers to the core data platform, so all tools use the same semantic concepts.
Solution walkthrough
This walkthrough uses a movie review dataset to demonstrate the integration. The dataset consists of three tables (MOVIES, USERS, and RATINGS) that you load from Amazon S3 into Snowflake. On top of those tables, you define a semantic view that maps raw columns to business-friendly metrics and dimensions.
Figure 2: A Snowflake semantic view adds business context (metrics, dimensions, and relationships) to raw tables, creating a shared definition layer for AI and BI tools.
This integration empowers the BI team to use natural language for creating interactive charts and dashboards, building calculated fields, developing data stories, and conducting what-if scenarios—and significantly reduces the risk of AI hallucinations. The BI team can also incorporate this Snowflake-sourced dashboard into the Amazon Quick Movies Quick Space to enable retrieval augmented generation (RAG).
Prerequisites
Before you begin, make sure that you have the following in place:
- Snowflake Enterprise account on AWS. If you don’t have one, sign up for a Snowflake trial account and select Enterprise on AWS.
- ACCOUNTADMIN role access in Snowflake. This role is required for creating semantic views and granting object-level privileges.
- AWS account. If you don’t have one, create an AWS account.
- AWS Region alignment. Sign up for both accounts in AWS US West (Oregon) or US East (N. Virginia). Amazon Quick Sight is available in US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), and Europe (Ireland). Refer to the Amazon Quick documentation for the latest Regional availability.
- Basic familiarity with SQL and Python. You run SQL statements in Snowsight (Snowflake’s web interface) and run a Python-based script in AWS CloudShell.
- Familiarity with data analysis concepts such as tables, dimensions, and metrics.
Time commitment: Allow 60–90 minutes to complete this tutorial end to end.
Estimated cost: This tutorial uses minimal resources. Expect less than $10 in combined AWS and Snowflake costs.
Step 1: Set up your Snowflake environment and load data
You use Snowsight, Snowflake’s web interface, to import and run a provided notebook. The notebook creates the necessary compute warehouse, database, and schema, then loads the movie review data, so you don’t need to run the setup SQL manually.
Import the notebook
To get started, import the pre-built tutorial notebook into your Snowflake environment so you can follow along interactively.
- Download the notebook SF_Quick_Quickstart.ipynb from the assets folder in the GitHub repository.
- In Snowsight, choose the plus (+), Notebook, Import, then select the downloaded notebook file.
- Accept the default settings and select Run on Warehouse. The notebook defaults to SYSTEM$STREAMLIT_NOTEBOOK_WH (a system-provided compute resource), but you can choose a different warehouse from the dropdown. The notebook creates a new warehouse called WORKSHOPWH for this tutorial.
Figure 3: Image showing how to import the notebook in Snowsight using the plus (+) menu.
Figure 4: Image showing the select Run on Warehouse option and the compute warehouse at notebook creation seclection.
After notebook creation, you can choose a different warehouse from the notebook settings. For more information, see notebook settings.
Run the notebook to load data
Snowflake Notebooks come pre-installed with common Python libraries—numpy, pandas, matplotlib, and more. To add other packages, choose the Packages dropdown in the top right of the notebook.
Run all cells in sequence. The notebook provisions the WORKSHOPWH warehouse and loads the movie review data into the MOVIES database. After each cell completes, you see confirmation output below the cell.
Verify the setup: After running all cells, confirm that you see three tables: MOVIES, USERS, and RATINGS in the MOVIES.PUBLIC schema.
Troubleshooting: If a cell fails to execute, verify that you’re using the ACCOUNTADMIN role. You can set this at the top of your notebook or worksheet with:
USE ROLE ACCOUNTADMIN;Figure 5: Run all notebook cells to load data into the MOVIES database.
Step 2: Define the semantic view and export the semantic view DDL
After all cells run successfully, locate the Get_SV_DDL cell. This cell executes the following SQL to retrieve the semantic view’s DDL:
SELECT TO_VARCHAR(GET_DDL(
'SEMANTIC_VIEW',
'MOVIES.PUBLIC.MOVIE_ANALYTICS_SV'
));Important After running the Get_SV_DDL cell, choose Download as CSV and save the file as SF_DDL.csv. You need this file in Step 4 to generate your Amazon Quick Sight dataset automatically. If you skip this step, the dataset generator can’t parse your schema.
Figure 7: Choose Download as CSV to save SF_DDL.csv—required for the Quick Sight dataset generator.
Step 3: Explore your data with Cortex Analyst
With the semantic view created, you can immediately start querying your data in plain English—no SQL required. This step verifies that the semantic layer works correctly before you connect Amazon Quick Sight.
View the semantic view in Snowsight
- In Snowsight, select AI & ML from the navigation pane.
- Select the SEMANTIC_QUICK_START_ROLE that you created earlier to confirm you have the right permissions.
- Navigate to the Movies database, then Public schema and select the MOVIES_ANALYST_SV semantic view to inspect its structure.
Figure 8: The MOVIES_ANALYST_SV semantic view visible in the Snowsight AI & ML section.
Add verified queries
Verified queries are example questions with confirmed correct answers. They give Cortex Analyst a reference when responding to similarly phrased questions, improving accuracy and reducing query latency. Add at least one verified query before testing natural-language questions.
Example: verify “What is the average rating for all movies in 2023?” by confirming that Cortex Analyst generates the correct SQL. When a user later asks a similarly worded question, Cortex Analyst matches it against your verified queries first.
Figure 9: Add verified queries in Snowsight to improve Cortex Analyst accuracy.
Test natural-language queries
Try the following sample questions to confirm the semantic view responds correctly:
- Show me the total rating values by movie title.
- List the top 10 most popular movies of all time.
Figure 10: Cortex Analyst translates natural-language questions into SQL using your semantic view definitions.
To use SQL to query a semantic view directly, refer to the semantic view query examples in the Snowflake documentation.
Step 4: Create an Amazon Quick Sight dataset
Now that your data is semantically defined in Snowflake, connect it to Amazon Quick Sight for interactive dashboards. The provided Quick Sight Dataset Generator script automates the entire pipeline from Snowflake DDL to a ready-to-query Quick Sight dataset.
Option 1: Run the Python package locally
Download the full solution from the GitHub repository. Follow the guidance in the README.md to connect to Snowflake, fetch the semantic view definition, convert the definition into Quick dataset schema, and create the Quick dataset. The Python scripts are interactive with self-guidance.
Option 2: Run the bash scripts in AWS CloudShell
As an alternative to running Python scripts locally, you can run the provided bash and Python scripts directly in AWS CloudShell to store credentials securely, and interactively create a fully configured Quick Sight dataset with SPICE ingestion—all from the command line.
Upload the solution package
Download Solution_Package.zip from the GitHub repository. Then open the AWS Management Console and launch AWS CloudShell. Upload Solution_Package.zip using the Actions → Upload file option in CloudShell.
Figure 11: Upload Solution_Package.zip to AWS CloudShell from the Actions menu.
Run the dataset generator workflow
Follow these steps in sequence.
- Unzip and enter the directory:
unzip Solution_Package.zip
cd Solution_Package- Upload the SF_DDL.csv file you downloaded from the Snowflake notebook (the output of GET_DDL on the semantic view).
- Create an AWS secret. Store your Snowflake credentials (account identifier, username, and password) as an AWS Secrets Manager secret. The script references this secret when creating the Quick Sight data source.
python create_secret.py- Run the interactive workflow.After the secret is created, run the single interactive script:
python run_workflow.pyThe interactive workflow script guides you through selecting or creating a Snowflake data source, configuring a new or existing dataset, parsing your SF_DDL.csv to generate a Quick Sight schema, creating or updating the dataset with SPICE ingestion, and monitoring ingestion progress until completion. Optionally, you can verify the ingestion status in the Quick Sight console and share the dataset with other Quick Sight users.
Step 5: Build your dashboard in Amazon Quick Sight
After ingestion completes, open the Amazon Quick Sight console and navigate to Datasets. Select movie-analytics-dataset to confirm the data loaded correctly, then choose Create analysis to start building.
Explore with natural-language questions
Ask the same natural-language questions you tested in Cortex Analyst. Quick Sight generates corresponding visuals automatically. Try these sample questions to get started:
- “Show me the highest-rated movies” – generates a bar chart ranking movies by average rating.
- “What are the top 10 most-reviewed movies?” – displays a ranked list by review count.
- “How do ratings distribute across genres?” – produces a breakdown by genre.
- “Show me the trend of ratings over time” – creates a line chart of rating activity.
- “Which users have submitted the most reviews?” – highlights the most active reviewers.
関連記事
ハンティントン銀行:AWS を活用し 4 億件超の文書から機密データを除去
米国トップ10 のハンティントン銀行は、約 10 年間で蓄積された 4 億件を超える文書から顧客の機密情報を体系的に特定・削除する課題に対し、AWS の技術を活用して解決した。
Amazon Nova 2 Sonic を活用した医療予約エージェントの構築方法
AWS は、米国医療機関で問題となる欠席率の高さに対応するため、Amazon Nova 2 Sonic を使用して患者の予約確認や再調整を行う自動エージェントを構築する手法を公開しました。
Loka が Amazon Nova 2 Sonic を活用した低遅延・自然な音声エージェントを構築
Loka は AWS ベースのソリューションで、Amazon Nova 2 Sonic を用いて顧客との対話を自然かつ低遅延に実現する会話型 AI エージェントを開発し、音声推論精度も向上させた。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み