AWS 生成 AI モデルアジリティソリューション:LLM の移行に関する包括ガイド
AWS は、LLM の移行やアップグレードを体系的かつ自動化して行うための包括的なフレームワークとツールセットを公開し、組織が生成 AI プロダクション環境でのモデルアジリティを確保する道筋を示した。
キーポイント
構造化された移行フレームワークの提供
データ準備から最終評価基準まで、LLM の移行やアップグレードを最小限の運用リスクで実施するための標準化されたプロセスとガイドラインを提示している。
自動化されたプロンプト最適化と移行
Amazon Bedrock の Prompt Optimization や Anthropic の Metaprompt ツールを活用し、プロンプトの変換と最適化を自動化する機能を実装している。
多角的なモデル評価と比較分析
コスト、レイテンシ、精度、品質など複数のパフォーマンス次元を定量化して比較できるメトリクスとレポート機能を備え、データ駆動型の意思決定を支援する。
迅速な実装と適用可能性
具体的な機能例やユースケース事例を提供し、複雑さにもよるが通常 2 日から 2 週間で LLM の移行またはアップグレードを完了できる見通しを示している。
AWS Bedrock を使用したプロンプト最適化の自動化
Python の boto3 ライブラリを用いて、`optimize_prompt` API を呼び出し、指定されたターゲットモデル(例:Claude 3 Sonnet)に対して入力を解析・最適化するプロセスを自動化できます。
Anthropic Metaprompt ツールの活用
Claude がユーザーに代わってプロンプトテンプレートを作成するツールであり、タスクの目的や入力変数を定義することで、一貫性が高く正確な出力を得られる最適化された指示を生成します。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI の実運用において頻発する「どのモデルを使うか」「どう乗り換えるか」という課題に対し、単なるツール紹介ではなく、プロセスと評価基準まで含めた体系的な解決策を提示した点で業界に大きな影響を与える。特に、AWS と Anthropic の連携による自動化機能の提供は、企業の AI 運用コスト削減と開発スピード向上に直結する実用的な知見であり、LLM 移行のベストプラクティスを標準化する役割を果たす。
編集コメント
LLM の移行は技術的難易度だけでなく、評価基準の策定やプロンプトの最適化など多岐にわたる課題を伴いますが、AWS が提供するこのフレームワークはそれを体系的に解決する強力な指針となります。特に、2 日から 2 週間という具体的なタイムラインと自動化ツールの提示は、実務チームが即座に行動に移すための決定的な材料となるでしょう。
モデルの俊敏性を維持することは、組織が技術的進展に適応し、人工知能(AI)ソリューションを最適化するために不可欠です。異なる大規模言語モデル(LLM)ファミリー間での移行や、同じファミリー内での新バージョンへのアップグレードに関わらず、継続的なパフォーマンス向上を促進しつつ運用上の混乱を最小限に抑えるためには、構造化された移行アプローチと標準化されたプロセスが不可欠です。しかし、そのようなソリューションを開発することは、技術的および非技術的な両面において困難であり、その理由は以下の通りです:
- 多様なユースケースを網羅できるように汎用性を持たせる
- 新しいユーザーが対象のユースケースに適用できるよう、具体的であること
- LLM(大規模言語モデル)間での包括的かつ公平な比較を提供する
- 自動化可能でスケーラブルであること
- ドメイン固有およびタスク固有の知識と入力を取り込むこと
- データ準備のガイダンスから最終的な成功基準に至るまで、明確に定義されたエンドツーエンドのプロセスを有すること
本記事では、生成 AI 生産における LLM の移行またはアップグレードのための体系的なフレームワークを紹介します。このフレームワークは、必要なツール、手法、ベストプラクティスを含んでおり、プロンプト変換と最適化のための堅牢なプロトコルを提供することで、異なる LLM(大規模言語モデル)間での移行を容易にします。また、複数のパフォーマンス次元を評価する評価メカニズムを含み、ソースモデルと宛先モデルの詳細かつ比較分析を通じてデータ駆動型の意思決定を可能にします。提案されたアプローチは、モデル移行の技術的側面を含む包括的なソリューションを提供し、移行の成功を検証しさらなる最適化の余地を特定するための定量化可能な指標を提供することで、シームレスな移行と継続的な改善を促進します。以下に本ソリューションのいくつかのハイライトを示します:
- さまざまな LLM 評価フレームワークを用いた多様なレポートオプションと、対象ユースケースにおける指標選定のための包括的なガイダンスを提供します。
- Amazon Bedrock のプロンプト最適化機能および Anthropic Metaprompt ツールを活用した自動化されたプロンプトの最適化・移行に加え、さらなるプロンプト最適化のためのベストプラクティスも提供します。
- コスト、レイテンシ、精度、品質に関するモデル比較のための包括的なガイダンスと、エンドツーエンドのソリューションを提供し、モデル選定を支援します。
- ユーザーが対象ユースケースに迅速に対応できるよう、機能例およびユースケース例を示します。
- このフレームワークに従って LLM の移行またはアップグレードを行うのに要する総時間は、ユースケースの複雑さにより 2 日から最大 2 週間となります。
ソリューション概要
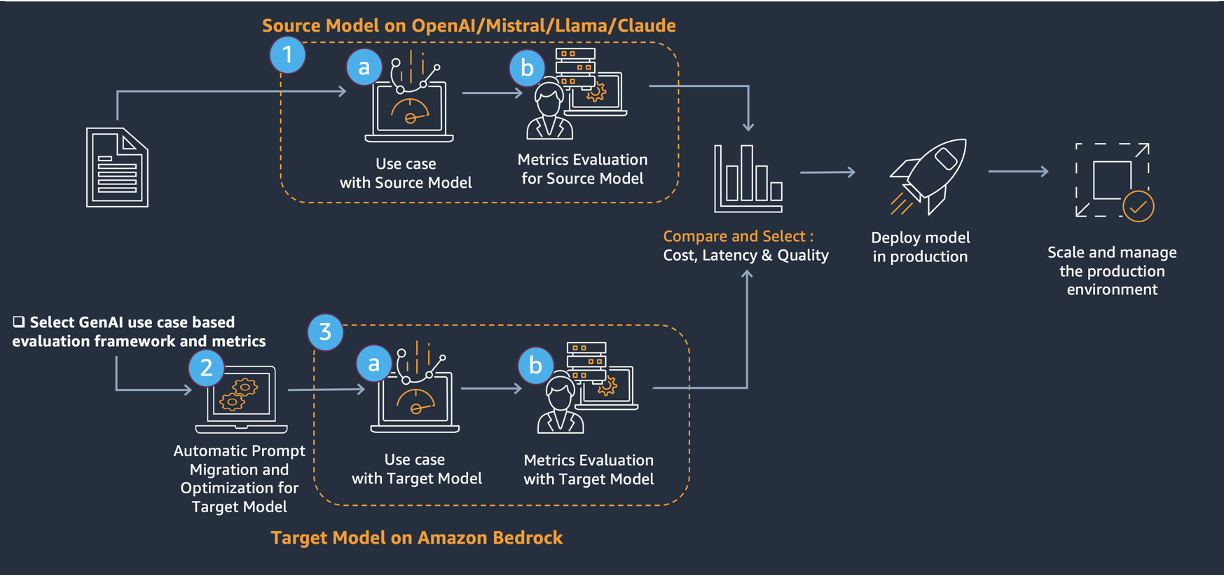
移行の核心は、前述の図に示される 3 つのステップからなるアプローチです。
- ソースモデルの評価
- Amazon Bedrock のプロンプト最適化機能および Anthropic Metaprompt ツールを用いたターゲットモデルへのプロンプト移行と最適化
- ターゲットモデルの評価
本ソリューションは、既存の生成 AI ソリューション(ソースモデル)を Amazon Bedrock 上の LLM(ターゲットモデル)へアップグレードするための包括的なアプローチを提供します。このソリューションは以下の技術的課題に対処します:
- さまざまな LLM を活用したフレームワークを用いた評価指標の選定
- Amazon Bedrock のプロンプト最適化機能および Anthropic の Metaprompt ツールを活用したプロンプトの改善と移行
- コスト、レイテンシ、パフォーマンスにわたるモデル比較
この構造化されたアプローチは、LLM の評価、移行、最適化のための堅牢なフレームワークを提供します。これらの手順に従うことで、モデル間の移行が可能となり、AI アプリケーションにおいて性能の向上、コスト効率の改善、機能の拡張を可能にする可能性があります。本プロセスは、綿密な準備、体系的な評価、継続的な改善を重視しており、高度な言語モデルを長期的に成功させるための基盤を整えます。
ソリューションの実装
データセットの準備
高品質なサンプルを含む評価用データセットは、移行プロセスにおいて極めて重要です。多くのユースケースでは、正解(ground truth)を含むサンプルが必要となりますが、他のユースケースにおいては、回答の関連性、忠実度、毒性、バイアスなど、正解を必要としない指標(*フレームワークの評価および指標選定* セクション参照)を決定基準として使用することができます。対象となるユースケース向けにサンプルデータを準備する際は、以下のガイダンスとデータフォーマットをご利用ください。
サンプルデータに推奨されるフィールドは次の通りです:
- ソースモデルで使用されたプロンプト
- プロンプト入力(該当する場合)、例:検索拡張生成 (RAG) ベースの回答生成のための質問とコンテキスト
- ソースモデル呼び出しに使用された設定、例:温度パラメータ、top_p、top_k など。
- グランドトゥルース(正解データ)
- ソースモデルからの出力
- ソースモデルのレイテンシ
- ソースモデルの入力トークンおよび出力トークン(コスト計算に利用可能)
高品質なグランドトゥルースは、ほとんどのユースケースにおいて成功した移行のために不可欠であることを忘れないでください。グランドトゥルースは正しさについて検証されるだけでなく、分野の専門家 (SME) のガイダンスや評価基準に適合しているかも確認する必要があります。SME のガイダンスと評価基準の例については、「エラー分析」セクションを参照してください。
さらに、既存の評価指標(人間の評価スコアや SME からの「いいね」「ダメね」など)が利用可能な場合は、各データサンプルに対応する理由やコメントとともにそれらの指標を含めてください。自動評価が実施されている場合は、その自動評価スコア、手法、設定も含めてください。次のセクションでは、評価フレームワークの選択と指標の定義に関するより詳細なガイダンスを提供しますが、ステークホルダーから既存または優先される評価指標を収集して参照として残すことは依然として価値があります。
該当する場合は、以下の項目を含めてください:
- ソースモデルの既存の評価指標(例:ソースモデルに対する SME スコア)。
- ソースモデルの既存の自動評価指標(例:ソースモデルに対する LLM-as-a-judge スコア)。
以下の表は、データサンプルの形式例です:
sample_id
…
question
content
prompt_source_llm
answer_ground_truth
answer_ source_llm
latency_ source_llm
input_token_source_llm
output_token_source_llm
llm_judge_score_source_llm
human_score_source_llm
human_score_reasoning_source_llm
フレームワークの評価と指標の選定
情報とデータサンプルを収集した後、次のステップは、生成 AI のユースケースに適した評価指標を選択することです。SME による人的評価に加え、スケーラビリティが高く客観的であり、製品の長期的な健全性と持続可能性を支えるため、自動評価指標の使用が推奨されます。以下の表には、各ユースケースで利用可能な自動指標を示します。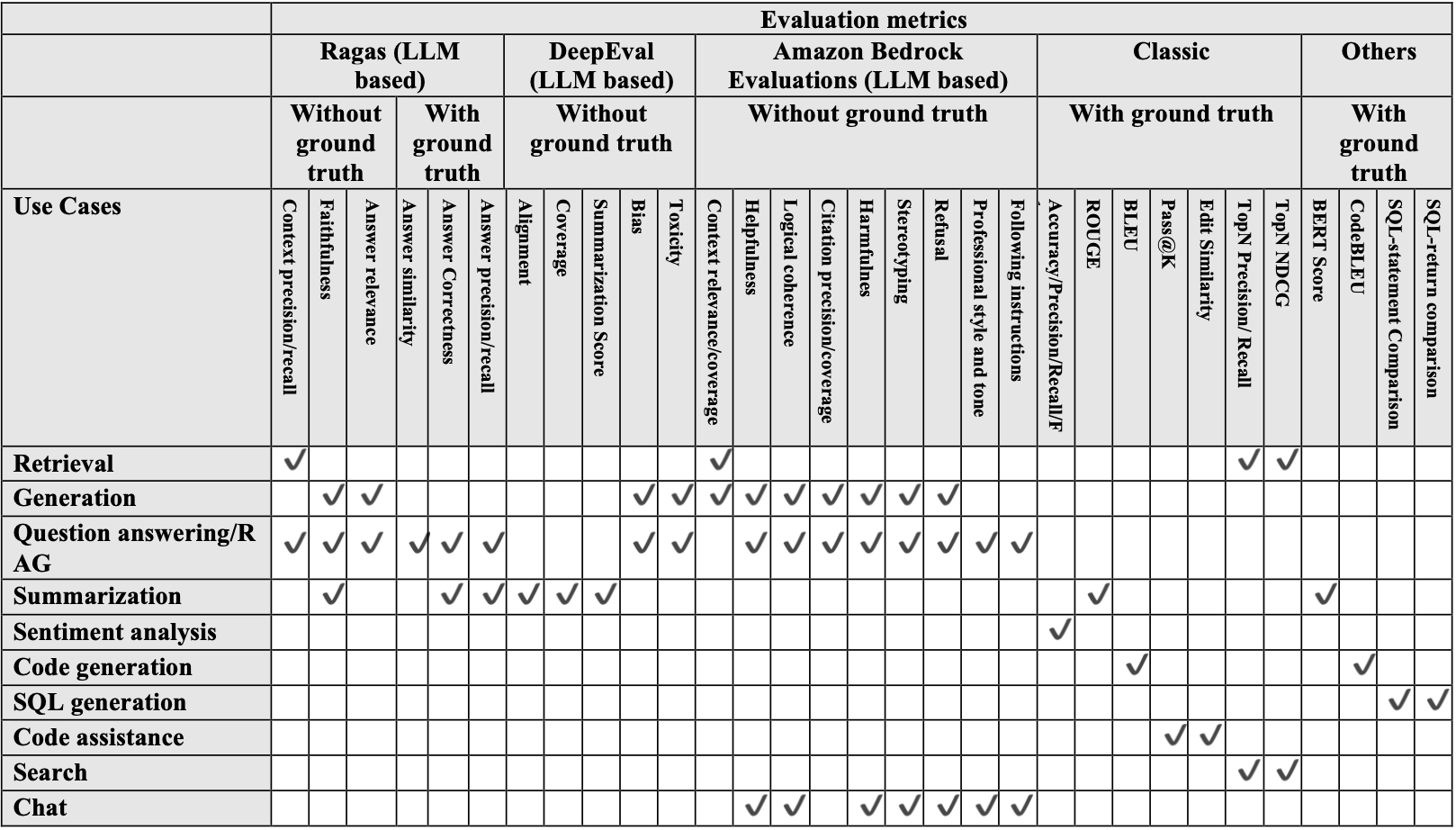 image
image
モデル選定
適切な LLM(大規模言語モデル)の選定には、複数の要因を慎重に考慮する必要があります。同じ LLM ファミリー内への移行であっても、異なる LLM ファミリーへの移行であっても、各モデルの主要な特徴と評価基準を理解することが成功のために不可欠です。LLM 間の移行を検討する際は、利用可能なさまざまな選択肢を注意深く比較・評価し、各モデルプロバイダーが公開しているモデルカードおよび対応するプロンプティングガイドを確認してください。LLM のオプションを評価する際には、以下の主要な基準を考慮する必要があります:
- 入力および出力モダリティ:テキスト、コード、マルチモーダル機能
- コンテキストウィンドウサイズ:モデルが処理できる最大入力トークン数
- 推論またはトークンあたりのコスト
- パフォーマンス指標:レイテンシとスループット
- 出力の品質と精度
- ドメイン特化性と特定のユースケースとの互換性
- ホスティングオプション:クラウド、オンプレミス、ハイブリッド
- データプライバシーおよびセキュリティ要件
これらの特性に基づいて初期フィルタリングを行った後、短縮されたモデルを比較するために、特定タスクでのパフォーマンスを評価するベンチマークテストを実施する必要があります。Amazon Bedrock は、統一 API を通じてさまざまな大規模言語モデル(LLM: Large Language Model)へのアクセスを提供する包括的なソリューションです。これにより、異なるモデルを実験し、そのパフォーマンスを比較し、単一の統合ポイントを保ちながら複数のモデルを並列で使用することも可能になります。このアプローチは技術的実装を簡素化するだけでなく、多様な AI モデル戦略を可能にすることでベンダーロックインの回避にも寄与します。
プロンプト移行
ここでは、2 つの自動化されたプロンプト移行および最適化ツールが紹介されています:Amazon Bedrock Prompt Optimization および Anthropic Metaprompt ツールです。
Amazon Bedrock プロンプト最適化
Amazon Bedrock プロンプト最適化 は、Amazon Bedrock で利用可能なツールであり、ユーザーが作成したプロンプトを自動的に最適化する機能を提供します。これにより、ユーザーは Amazon Bedrock 上で高品質な生成 AI アプリケーションを構築できるようになり、他のプロバイダーから Amazon Bedrock へワークロードを移行する際の摩擦を軽減できます。Amazon Bedrock プロンプト最適化を使用すれば、既存のワークロードをソースモデルから Amazon Bedrock の大規模言語モデル(LLM: Large Language Model)へ、最小限のプロンプトエンジニアリングで移行することが可能になります。このツールでは、最適化する対象となるプロンプトに対してどのモデルを使用するかを選択し、ターゲットモデル向けの最適化されたプロンプトを生成できます。Amazon Bedrock プロンプト最適化の主な利点は、AWS Management Console for Amazon Bedrock から直接使用できる点です。コンソールを利用すれば、ターゲットモデル用の新しいプロンプトを迅速に生成できます。また、Bedrock API を使用して移行されたプロンプトを生成することも可能です。詳細な実装については以下をご覧ください。
オプション A) Amazon Bedrock コンソールからのプロンプト最適化
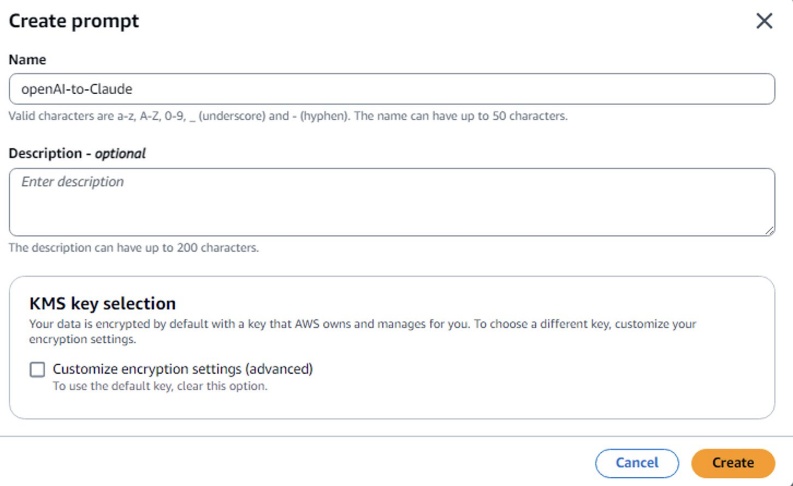
- Amazon Bedrock コンソールで、プロンプト管理 に移動します。
- [プロンプトの作成] を選択し、プロンプトテンプレートに名前を入力して [作成] をクリックします。
- ソースモデルのプロンプトを入力します。変数は二重のカッコ {{variable}} で名前を囲んで作成してください。[Test variables] セクションには、テスト時にこれらの変数を置き換える値を入力します。
- 最適化されたプロンプトのターゲットモデルを選択します。例えば、Anthropic の Claude Sonnet 4 などです。
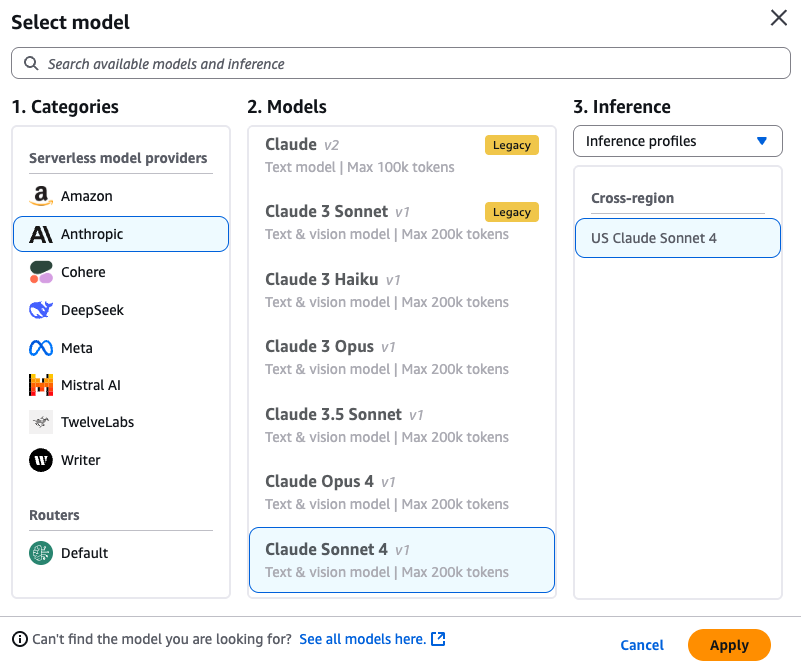
- [Optimize] ボタンを選択して、ターゲットモデル用の最適化されたプロンプトを生成します。

- プロンプトが生成されると、ソースモデルからの元のプロンプトとともに、ターゲットモデル用の最適化されたプロンプトの比較ウィンドウが表示されます。
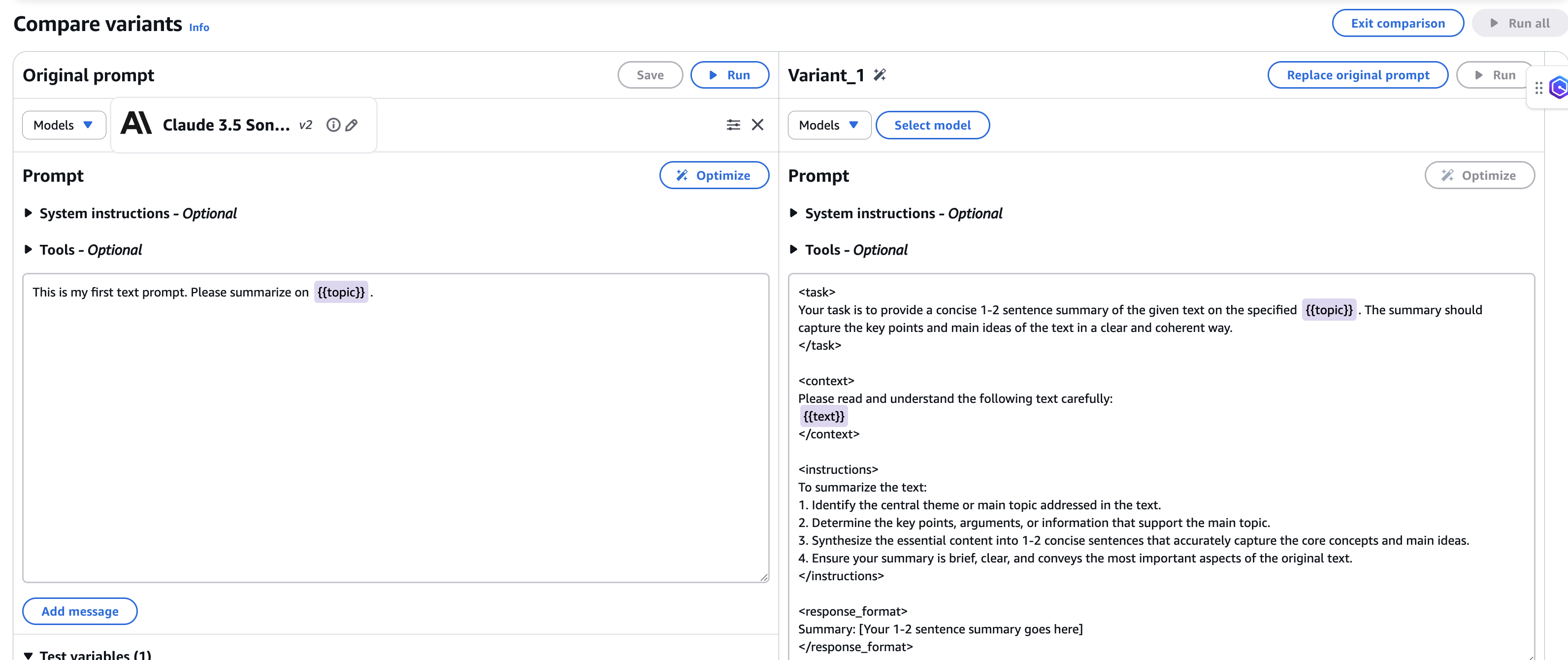
- 比較モードを終了する前に、新しい最適化されたプロンプトを保存してください。
オプション B) Amazon Bedrock API を使用したプロンプトの最適化
OptimizePrompt リクエスト(API 参照)を Agents for Amazon Bedrock runtime endpoint に送信することで、Bedrock API を使用して移行されたプロンプトも生成できます。最適化するプロンプトを入力オブジェクトに提供し、targetModelId フィールドで最適化対象のモデルを指定します。
レスポンスストリームは以下のイベントを返します:
- analyzePromptEvent – プロンプトの分析が完了した際に出現します。プロンプトの分析に関するメッセージを含みます。
- optimizedPromptEvent – プロンプトの書き換えが完了した際に出現します。最適化されたプロンプトを含みます。
以下のコードサンプルを実行して、プロンプトを最適化してください:
import boto3
# ここに値を設定します
TARGET_MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0" # 最適化する対象のモデル。モデル ID は https://docs.aws.amazon.com/bedrock/latest/userguide/model-ids.html を参照してください。
PROMPT = "Please summarize this text: " # 最適化したいプロンプトdef get_input(prompt):
return {
"textPrompt": {
"text": prompt
}
}
def handle_response_stream(response):
try:
event_stream = response['optimizedPrompt']
for event in event_stream:
if 'optimizedPromptEvent' in event:
print("========================== OPTIMIZED PROMPT ======================")
optimized_prompt = event['optimizedPromptEvent']
print(optimized_prompt)
else:
print("========================= ANALYZE PROMPT =======================")
analyze_prompt = event['analyzePromptEvent']
print(analyze_prompt)
except Exception as e:
raise e
if __name__ == '__main__':
client = boto3.client('bedrock-agent-runtime')
try:
response = client.optimize_prompt(
input=get_input(PROMPT),
targetModelId=TARGET_MODEL_ID
)
print("Request ID:", response.get("ResponseMetadata").get("RequestId"))
print("========================== INPUT PROMPT ======================")
print(PROMPT)
handle_response_stream(response)
except Exception as e:
raise e
Anthropic Metaprompt ツール
Metaprompt は、Anthropic が提供するプロンプト最適化ツールであり、Claude にユーザーに代わって特定のトピックやタスクに基づいてプロンプトテンプレートを作成させるものです。これを用いることで、与えられた目標を一貫性かつ正確に達成するために、Claude に対して最適なプロンプトの構築方法を指示することができます。
主な手順は以下の通りです:
- 生のプロンプトテンプレートを指定し、タスクの内容を説明するとともに、入力変数と期待される出力を明確にします。
- ソースモデルからの生プロンプトを入力として、Claude-3-Sonnet などの Claude LLM を用いて Metaprompt を実行します。
これにより、Claude LLM のベストプラクティスに従った最適化された一連の指示とフォーマットを備えた新しいプロンプトテンプレートが生成されます。
原文を表示
Maintaining model agility is crucial for organizations to adapt to technological advancements and optimize their artificial intelligence (AI) solutions. Whether transitioning between different large language model (LLM) families or upgrading to newer versions within the same family, a structured migration approach and a standardized process are essential for facilitating continuous performance improvement while minimizing operational disruptions. However, developing such a solution is challenging in both technical and non-technical aspects because the solution needs to:
- Be generic to cover a variety of use cases
- Be specific so that a new user can apply it to the target use case
- Provide comprehensive and fair comparison between LLMs
- Be automated and scalable
- Incorporate domain- and task-specific knowledge and inputs
- Have a well-defined, end-to-end process from data preparation guidance to final success criteria
In this post, we introduce a systematic framework for LLM migration or upgrade in generative AI production, encompassing essential tools, methodologies, and best practices. The framework facilitates transitions between different LLMs by providing robust protocols for prompt conversion and optimization. It includes evaluation mechanisms that assess multiple performance dimensions, enabling data-driven decision-making through detailed and comparative analysis of source and destination models. The proposed approach offers a comprehensive solution that includes the technical aspects of model migration and provides quantifiable metrics to validate successful migration and identify areas for further optimization, facilitating a seamless transition and continuous improvement. Here are a few highlights of the solution:
- Provides a variety of reporting options with various LLM evaluation frameworks and comprehensive guidance for metrics selection for target use cases.
- Provides automated prompt optimization and migration with Amazon Bedrock Prompt Optimization and the Anthropic Metaprompt tool, in addition to best practices for further prompt optimization.
- Provides comprehensive guidance for model selection and an end-to-end solution for model comparison regarding cost, latency, accuracy, and quality.
- Provides feature examples and use case examples for users to quickly apply the solution to the target use case.
- The total time required for an LLM migration or upgrade by following this framework is from two days up to two weeks depending on the complexity of the use case.
Solution overview
The core of the migration involves a three-step approach, shown in the preceding diagram.
- Evaluate the source model.
- Prompt migration to and optimization of the target model with Amazon Bedrock prompt optimization and the Anthropic Metaprompt tool.
- Evaluate the target model.
This solution provides a comprehensive approach to upgrade existing generative AI solutions (source model) to LLMs on Amazon Bedrock (target model). This solution addresses technical challenges through:
- Evaluation metrics selection with a framework that uses various LLMs
- Prompt improvement and migration with Amazon Bedrock Prompt Optimization and the Anthropic Metaprompt tool
- Model comparison across cost, latency, and performance
This structured approach provides a robust framework for evaluating, migrating, and optimizing LLMs. By following these steps, we can transition between models, potentially unlocking improved performance, cost-efficiency, and capabilities in your AI applications. The process emphasizes thorough preparation, systematic evaluation, and continuous improvement; setting the stage for long-term success in using advanced language models.
Solution implementation
Dataset preparation
An evaluation dataset with high-quality samples is critical to the migration process. For most use cases, samples with ground truth answers are required; while for other use cases, metrics that don’t require ground truth—such as answer relevancy, faithfulness, toxicity, and bias (see *Evaluation of frameworks and metrics selection* section)—can be used as the determination metrics. Use the following guidance and data format to prepare the sample data for the target use cases.
Suggested fields for sample data include:
- Prompt used for the source model
- Prompt input (if any), for example: Questions and context for Retrieval-Augmented Generation (RAG)-based answer generation
- Configurations used for source model invocation, for example, temperature, top_p, top_k, and so on.
- Ground truths
- Output from the source model
- Latency of the source model
- Input and output tokens from the source model, which can be used for cost calculation
It’s important to remember that high quality ground truths are essential to successful migration for most use cases. Ground truths should not only be validated regarding correctness, but also to verify that they fit the subject matter expert’s (SME’s) guidance and evaluation criteria. See *Error **Analysis section* for an example of a SME’s guidance and evaluation criteria.
In addition, if any existing evaluation metrics are available, such as a human evaluation score or thumbs up/thumbs down from a SME, include those metrics and corresponding reasoning or comments for each data sample. If any automated evaluations have been conducted, include the automated evaluation scores, methods, and configurations. The following section provides more detailed guidance on selecting evaluation frameworks and defining the metrics. However, it’s still valuable to collect the existing or preferred evaluation metrics from stakeholders for reference.
Include the following fields if applicable:
- Existing human evaluation metrics for the source model, for example, the SME score for source model.
- Existing automated evaluation metrics for the source model, for example, the LLM-as-a-judge score for the source model.
The following table is an example format of the data samples:
sample_id
…
question
content
prompt_source_llm
answer_ground_truth
answer_ source_llm
latency_ source_llm
input_token_source_llm
output_token_source_llm
llm_judge_score_source_llm
human_score_source_llm
human_score_reasoning_source_llm
Evaluation of frameworks and metrics selection
After collecting information and data samples, the next step is to choose the proper evaluation metrics for the generative AI use case. Besides human evaluation by a SME, automated evaluation metrics are recommended because they are more scalable and objective and support the long-term health and sustainability of the product. The following table shows the automated metrics that are available for each use case.
Model selection
The selection of an appropriate LLM requires careful consideration of multiple factors. Whether migrating to an LLM within the same LLM family or to a different LLM family, understanding the key characteristics of each model and the evaluation criteria is crucial for success. When planning to migrate between LLMs, carefully compare and evaluate various available options and check out the model card and respective prompting guides released by each model provider. When evaluating LLM options, consider several key criteria:
- Input and output modalities: Text, code, and multi-modal capabilities
- Context window size: Maximum input tokens the model can process
- Cost per inference or token
- Performance metrics: Latency and throughput
- Output quality and accuracy
- Domain specialization and specific use case compatibility
- Hosting options: Cloud, on-premises, and hybrid
- Data privacy and security requirements
After initial filtering based on these characteristics, benchmarking tests should be conducted by evaluating performance on specific tasks to compare shortlisted models. Amazon Bedrock offers a comprehensive solution with access to various LLMs through a unified API. This allows us to experiment with different models, compare their performance, and even use multiple models in parallel, all while maintaining a single integration point. This approach not only simplifies the technical implementation but also helps avoid vendor lock-in by enabling a diversified AI model strategy.
Prompt migration
Two automated prompt migration and optimization tools are introduced here: the Amazon Bedrock Prompt Optimization and the Anthropic Metaprompt tool.
Amazon Bedrock Prompt Optimization
Amazon Bedrock Prompt Optimization is a tool available in Amazon Bedrock to automatically optimize prompts written by users. This helps users build high quality generative AI applications on Amazon Bedrock and reduces friction when moving workloads from other providers to Amazon Bedrock. Amazon Bedrock Prompt Optimization can enable migration of existing workloads from a source model to LLMs on Amazon Bedrock with minimal prompt engineering. With this tool, we can choose the model to optimize the prompt for and then generate an optimized prompt for the target model. The main advantage of using Amazon Bedrock Prompt Optimization is the ability to use it from the AWS Management Console for Amazon Bedrock. Using the console, we can quickly generate a new prompt for the target model. We can also use the Bedrock API to generate a migrated prompt, please see the detailed implementation below.
Option A) Optimize a prompt from the Amazon Bedrock Console
- In the Amazon Bedrock console, go to Prompt management.
- Choose Create prompt, enter a name for the prompt template, and choose Create.
- Enter the source model prompt. Create variables by enclosing a name with double curly braces: {{variable}}. In the Test variables section, enter values to replace the variables with when testing.
- Select a Target Model for your optimized prompt. For example, Anthropic’s Claude Sonnet 4.
- Choose the Optimize button to generate an optimized prompt for the target model.
- After the prompt is generated, the comparison window of the optimized prompt for the target model is shown with your original prompt from source model.
- Save the new optimized prompt before exiting comparing mode.
Option B) Optimize a prompt using Amazon Bedrock API
We can also use the Bedrock API to generate a migrated prompt, by sending an OptimizePromptrequest with an Agents for Amazon Bedrock runtime endpoint. Provide the prompt to optimize in the input object and specify the model to optimize for in the targetModelId field.
The response stream returns the following events:
- analyzePromptEvent – Appears when the prompt is finished being analyzed. Contains a message describing the analysis of the prompt.
- optimizedPromptEvent – Appears when the prompt has finished being rewritten. Contains the optimized prompt.
Run the following code sample to optimize a prompt:
import boto3
# Set values here
TARGET_MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0" # Model to optimize for. For model IDs, see https://docs.aws.amazon.com/bedrock/latest/userguide/model-ids.html
PROMPT = "Please summarize this text: " # Prompt to optimize
def get_input(prompt):
return {
"textPrompt": {
"text": prompt
}
}
def handle_response_stream(response):
try:
event_stream = response['optimizedPrompt']
for event in event_stream:
if 'optimizedPromptEvent' in event:
print("========================== OPTIMIZED PROMPT ======================\n")
optimized_prompt = event['optimizedPromptEvent']
print(optimized_prompt)
else:
print("========================= ANALYZE PROMPT =======================\n")
analyze_prompt = event['analyzePromptEvent']
print(analyze_prompt)
except Exception as e:
raise e
if __name__ == '__main__':
client = boto3.client('bedrock-agent-runtime')
try:
response = client.optimize_prompt(
input=get_input(PROMPT),
targetModelId=TARGET_MODEL_ID
)
print("Request ID:", response.get("ResponseMetadata").get("RequestId"))
print("========================== INPUT PROMPT ======================\n")
print(PROMPT)
handle_response_stream(response)
except Exception as e:
raise eAnthropic Metaprompt tool
The Metaprompt is a prompt optimization tool offered by Anthropic where Claude is prompted to write prompt templates on the user’s behalf based on a topic or task. We can use it to instruct Claude on how to best construct a prompt to achieve a given objective consistently and accurately.
The key steps are:
- Specify the raw prompt template, explain the task, and specify the input variables and the expected output.
- Run Metaprompt with a Claude LLM such as Claude-3-Sonnet by inputting the raw prompt from the source model.
The new prompt template is generated with an optimized set of instructions and format following Claude LLM’s bes
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み