深層エージェントのためのコンテキスト管理
LangChain は、長期実行タスクにおけるコンテキスト制限を克服するため、ファイルシステムへのオフローディングと要約を組み合わせた新しい「Deep Agents SDK」を発表した。
キーポイント
コンテキスト圧縮の必要性
AI エージェントが実行するタスクが複雑化・長期化する中で、LLM の有限なメモリ(コンテキストウィンドウ)を効率的に管理し、「コンテキストの劣化」を防ぐ技術が不可欠となっている。
3 つの主要圧縮手法
Deep Agents SDK は、大規模なツール結果や入力のファイルシステムへのオフローディング、および残存情報の要約という 3 つの段階的な圧縮手法を実装している。
動的閾値トリガー
モデルのコンテキストウィンドウサイズの特定の割合(例:85%)に達した際に自動的に圧縮ステップがトリガーされ、不要な情報をファイルシステムへ退避させる。
ファイルシステム抽象化層
エージェントはファイルリスト、検索、パターンマッチング、実行などの操作を通じてオフロードされたコンテンツを必要に応じて再読み込み・検索できる抽象化レイヤーを提供する。
ファイル操作のコンテキスト最適化
セッションコンテキストが利用可能ウィンドウの85%に達すると、Deep Agents は古いツール呼び出しを切り捨て、ディスク上のファイルへのポインタに置き換えてアクティブなコンテキストサイズを削減します。
要約と永続化の二重アプローチ
オフローディングでは空間が不足した場合、LLM による構造化された会話要約(セッション意図や次ステップを含む)で作業メモリを置き換えつつ、完全な履歴はファイルシステムに保存して詳細検索を可能にします。
ベンチマークでの機能強化テスト
実世界タスクでは圧縮が散発的に発生するため、ベンチマークでは意図的に要約トリガー閾値(10-20%)を低く設定してイベント数を増やし、プロンプト構成などの改善効果を明確に評価します。
影響分析・編集コメントを表示
影響分析
この記事は、LLM のコンテキストウィンドウという物理的制約が、より高度で自律的なエージェントの実現における最大のボトルネックとなっている現状に対する具体的な解決策を示しています。ファイルシステムを活用した外部記憶と動的圧縮技術の組み合わせは、実務レベルでの長期タスク実行を可能にする重要なステップであり、開発者がスケーラブルな AI エージェントを構築する際の標準的なパターンとして定着することが期待されます。
編集コメント
LLM のコンテキスト制限を克服するための実用的なアーキテクチャパターンが提示されており、長期的なタスクを実行する自律型エージェントの開発において即座に活用できる価値があります。特にファイルシステムを活用したオフローディング戦略は、コスト効率と機能性のバランスが取れた優れたアプローチと言えます。
 imageチェスター・カームとメイソン・ドーハーティによる
imageチェスター・カームとメイソン・ドーハーティによる
AI エージェントの処理可能なタスク長が継続して拡大する中、コンテキストローテーション(context rot)を防ぎ、LLM の有限なメモリ制約を管理するために、効果的なコンテキスト管理が極めて重要になっています。
Deep Agents SDK は、LangChain が提供するオープンソースで、標準機能を含むエージェントハネスです。計画立案やサブエージェントの起動、ファイルシステムとの連携による複雑で長時間実行されるタスクの実行能力を持つエージェントを構築するための容易な道筋を提供します。これらの種類のタスクは一般的にモデルのコンテキストウィンドウを超えるため、SDK はコンテキスト圧縮を促進するさまざまな機能を実装しています。
コンテキスト圧縮とは、タスク完了に関連する詳細情報を保持しつつ、エージェントの作業メモリ内の情報量を削減する技術を指します。これには、過去の対話の要約、古くなった情報のフィルタリング、あるいは何を保持し何を破棄するかを戦略的に決定することが含まれます。
Deep Agents は、ファイルの一覧表示、読み取り、書き込み、検索、パターンマッチング、およびファイルの実行などの操作をエージェントが行えるようにするファイルシステム抽象化を実装しています。エージェントは必要に応じてファイルシステムを使用してオフロードされたコンテンツを検索・取得します。
Deep Agents は、異なる頻度でトリガーされる 3 つの主要な圧縮技術を実装しています:
大規模なツール結果のオフローディング:大規模なツールの応答が発生した際には、常にそれをファイルシステムにオフロードします。
大規模なツール入力のオフロード:コンテキストサイズしきい値を超えた場合、ツール呼び出しからの古い書き込み/編集引数をファイルシステムにオフロードします。
要約処理:コンテキストサイズがしきい値を超え、さらにオフロード可能なコンテキストが存在しない場合、メッセージ履歴を圧縮するための要約ステップを実行します。
コンテキスト制限の管理のため、Deep Agents SDK はモデルのコンテキストウィンドウサイズのしきい値比率でこれらの圧縮ステップをトリガーします。(内部では、特定のモデルに対するトークンしきい値にアクセスするために LangChain のモデルプロファイルを使用しています。)
大規模なツール結果のオフロード
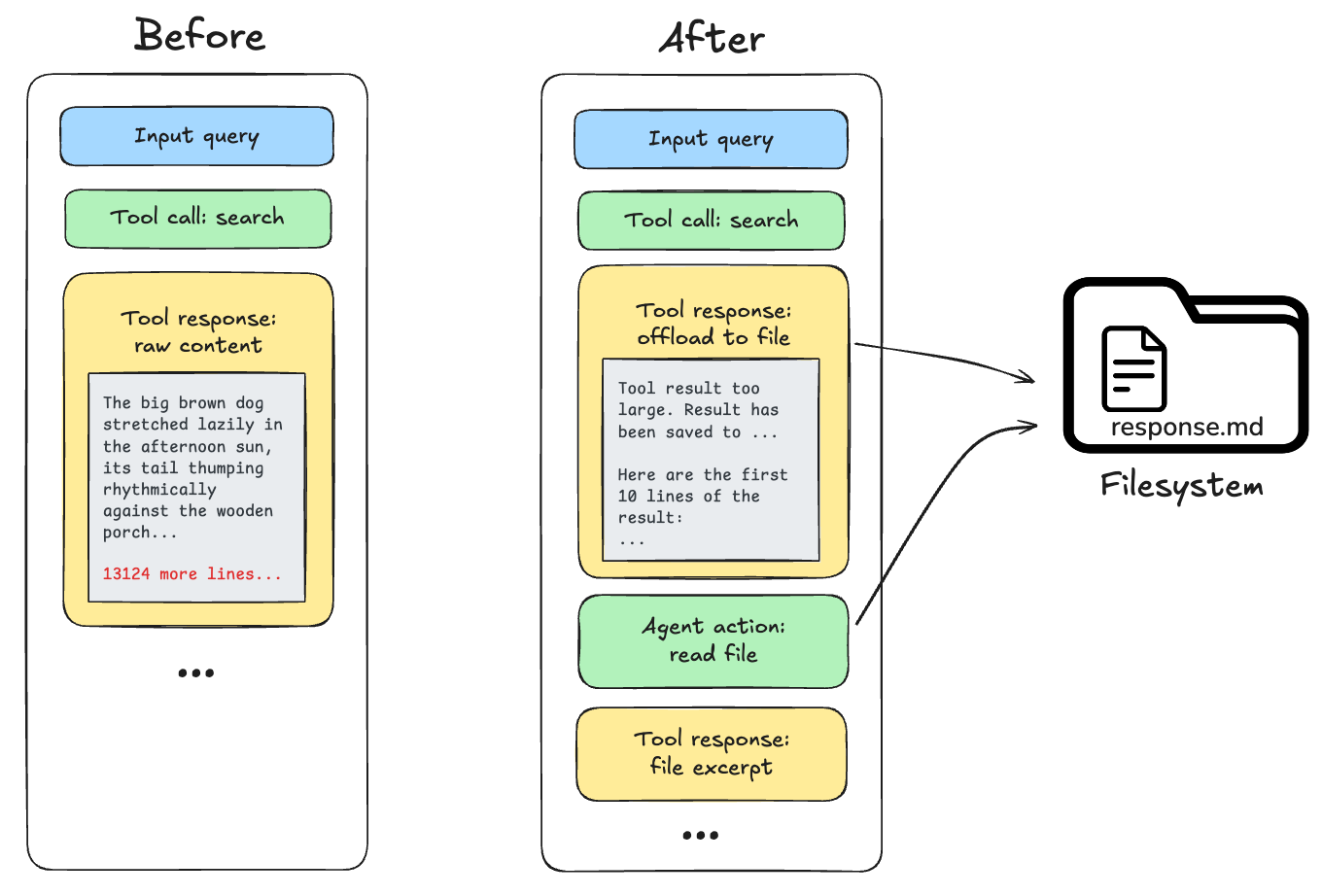
ツール呼び出しからの応答(例:大規模ファイルの読み取りや API 呼び出しの結果)は、モデルのコンテキストウィンドウを超える可能性があります。Deep Agents が 20,000 トークンを超えるツール応答を検出すると、その応答をファイルシステムにオフロードし、代わりにファイルパス参照と最初の 10 行のプレビューで置換します。その後、エージェントは必要に応じて内容を再読み込みまたは検索できます。
 image大規模なツール入力のオフロード
image大規模なツール入力のオフロード
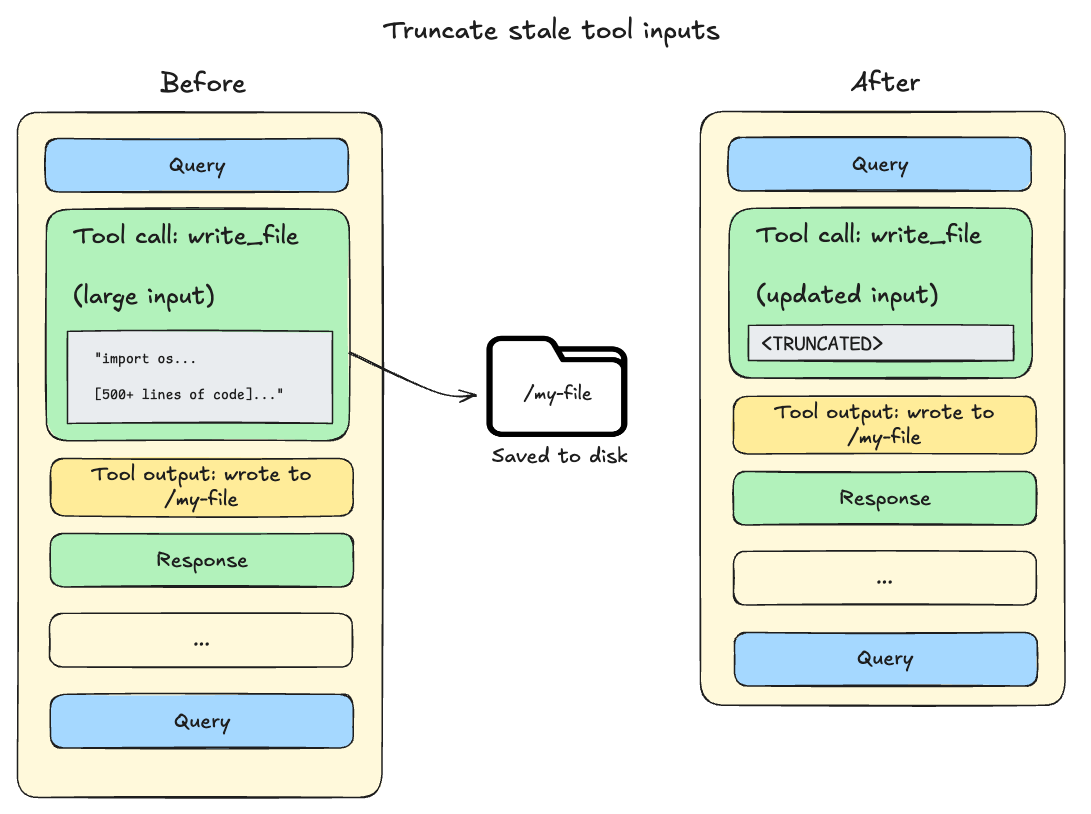
ファイルの書き込みおよび編集操作は、エージェントの会話履歴に完全なファイル内容を含むツール呼び出しを残します。このコンテンツはすでにファイルシステムに永続化されているため、多くの場合冗長です。セッションコンテキストがモデルの利用可能なウィンドウの 85% を超えると、Deep Agents は古いツール呼び出しを切り捨て、ディスク上のファイルへのポインタに置き換え、アクティブなコンテキストのサイズを縮小します。
 image要約
image要約
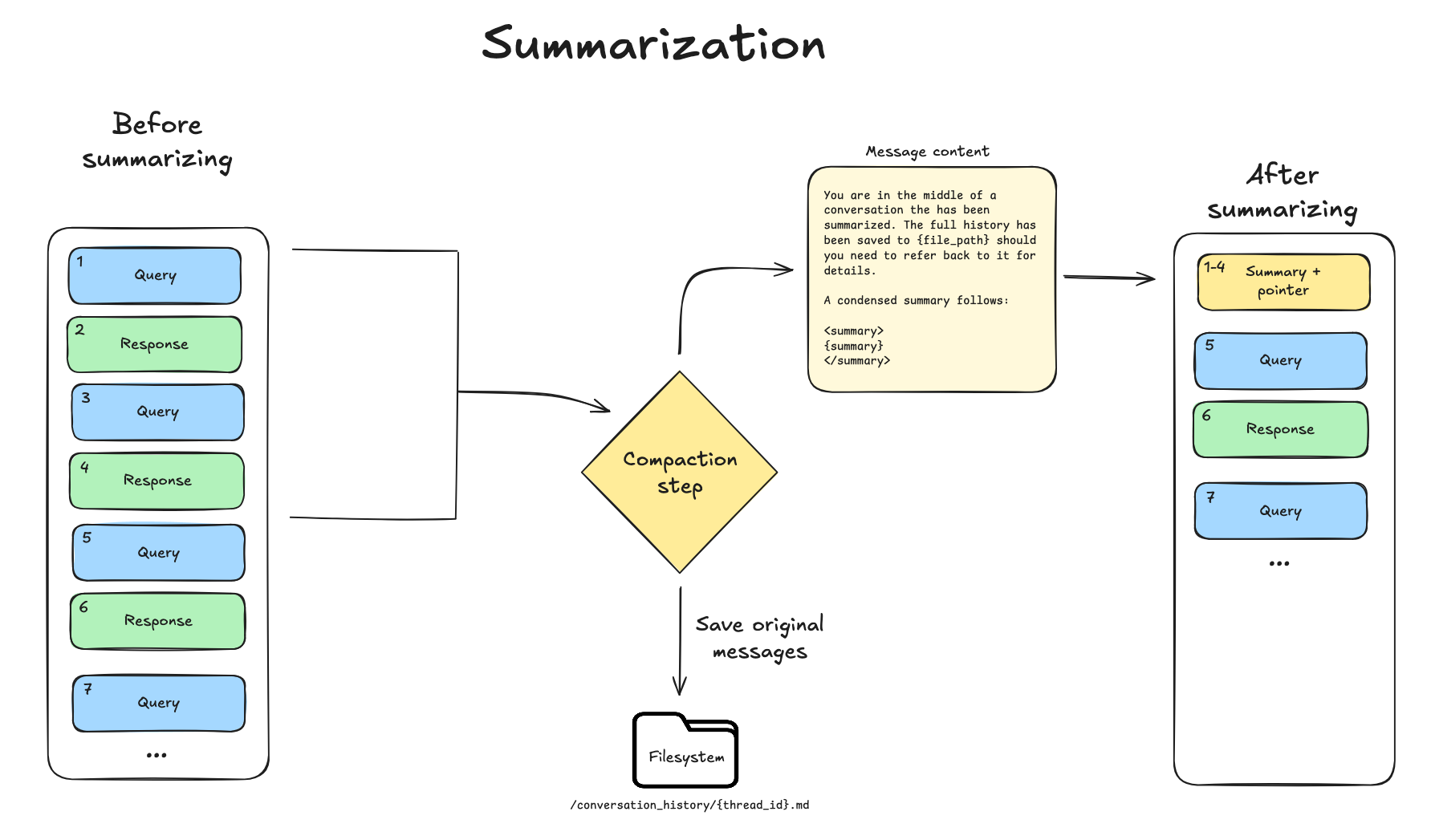
オフローディングではもはや十分なスペースが得られない場合、Deep Agents は要約に切り替えます。このプロセスには 2 つの構成要素があります。
コンテキスト内での要約:LLM が会話の構造化された要約(セッションの意図、作成されたアーティファクト、次のステップを含む)を生成し、これによりエージェントの作業メモリ内の完全な会話履歴が置き換えられます。(Deep Agents の要約プロンプトを参照してください。)
ファイルシステムの維持:完全な元の会話メッセージは、標準的な記録としてファイルシステムに書き込まれます。
この二重のアプローチにより、エージェントは要約を通じて目標と進捗の認識を維持しつつ、必要に応じて特定の詳細を検索機能で復元する能力も保持されます。以前オフロードされたメッセージを取得するために read_file ツールを使用しているモデルの例については、このトレースをご覧ください。
 image実践における外観
image実践における外観
上記の手法は文脈管理のための仕組みを提供しますが、実際に機能しているかどうかをどう確認すればよいでしょうか?terminal-bench などのベンチマークで捉えられた実世界のタスクでの実行では、文脈圧縮が断続的にトリガーされるため、その影響を単独で特定することが困難です。
私たちは、ベンチマークデータセット上でこれらの機能をより積極的に活用することで、ハネスの個々の機能のシグナルを増幅させることが有用であると発見しました。例えば、利用可能なコンテキストウィンドウの 10〜20% で要約をトリガーすると全体の性能が最適化されない可能性がありますが、その分はるかに多くの要約イベントが発生します。これにより、異なる構成(実装のバリエーションなど)を比較することが可能になります。例えば、エージェントに頻繁な要約を強制することで、セッションの意図と次のステップのために専用のフィールドを追加した deepagents の要約プロンプトに対する単純な変更が、どのように性能向上につながるかを特定できます。
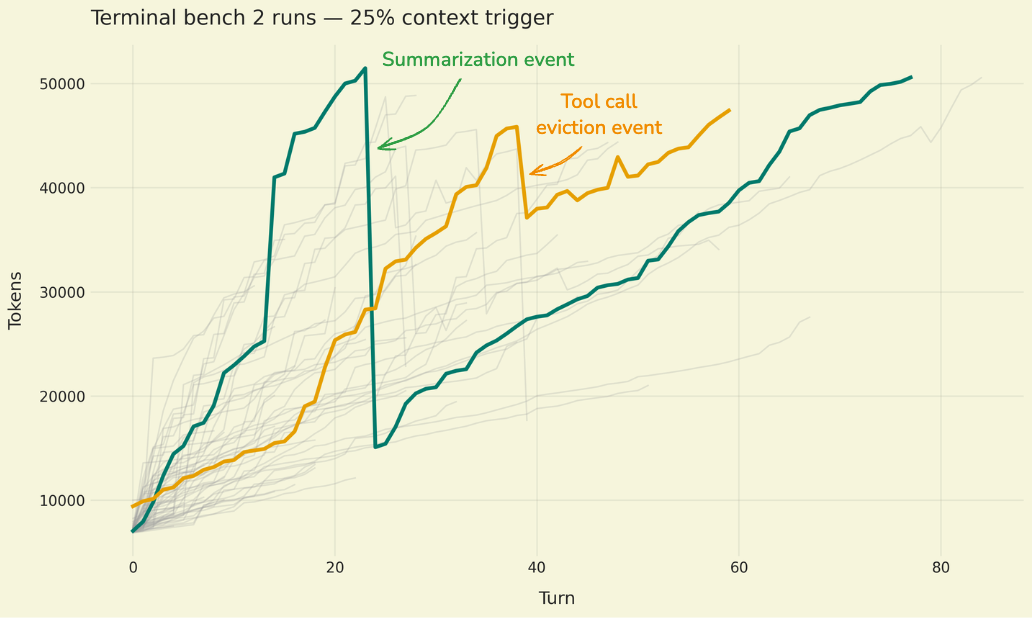
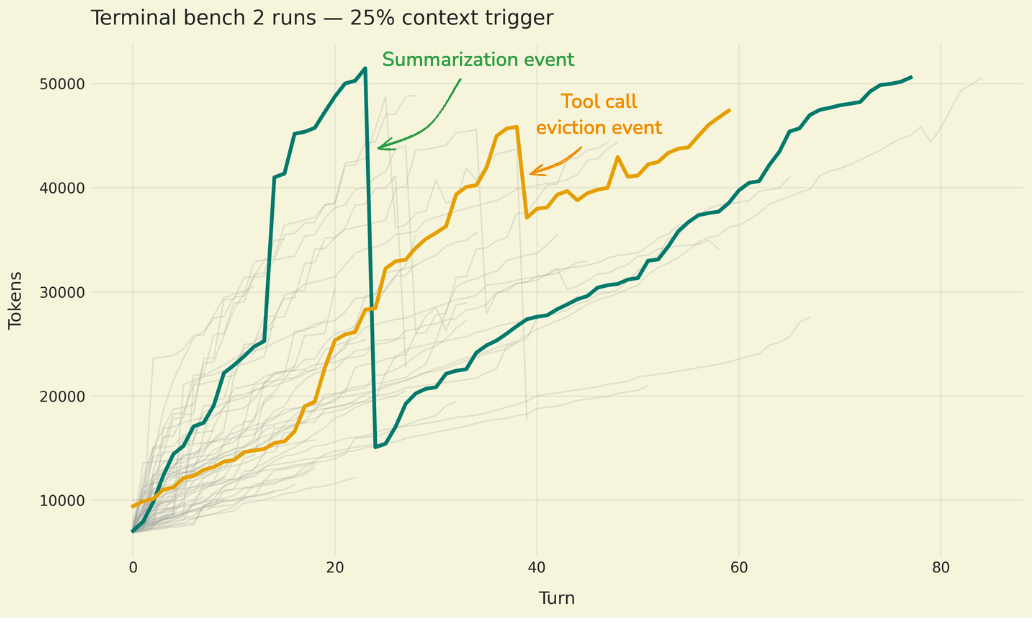 image図:Claude Sonnet 4.5 のターミナルベンチマーク 2(terminal-bench-2)におけるサンプル実行時のトークン使用量の推移(灰色の線はすべての実行、色のついた線は特定の 2 つの例を強調表示)。緑色の線は、要約イベントが会話履歴を圧縮するターン 20 付近で劇的なトークンの減少を示しています。オレンジ色の線は、大きなファイル書き込みツール呼び出しがコンテキストから除外されるターン 40 付近でのより小さな削減を示しています。Deep Agents のデフォルトである 85% ではなく、コンテキストウィンドウの 25% で圧縮トリガーを発生させることで、研究対象となるイベント数を増やしています。
image図:Claude Sonnet 4.5 のターミナルベンチマーク 2(terminal-bench-2)におけるサンプル実行時のトークン使用量の推移(灰色の線はすべての実行、色のついた線は特定の 2 つの例を強調表示)。緑色の線は、要約イベントが会話履歴を圧縮するターン 20 付近で劇的なトークンの減少を示しています。オレンジ色の線は、大きなファイル書き込みツール呼び出しがコンテキストから除外されるターン 40 付近でのより小さな削減を示しています。Deep Agents のデフォルトである 85% ではなく、コンテキストウィンドウの 25% で圧縮トリガーを発生させることで、研究対象となるイベント数を増やしています。
ターゲット評価
Deep Agents SDK は、個々のコンテキスト管理メカニズムを分離して検証するために設計された一連のターゲット評価(evals)を維持しています。これらは意図的に小規模なテストであり、特定の失敗モードを明白かつデバッグ可能にするものです。
これらの評価の目的は、広範なタスク解決能力を測定することではなく、エージェントのハッチが特定のタスクの妨げにならないことを保証することです。例えば:
要約はエージェントの目標を維持したか?一部の評価では、意図的にタスク実行中に要約トリガーを発生させ、その後エージェントが継続して動作するかを確認します。これにより、要約がエージェントの状態だけでなく、その軌道(trajectory)も維持していることを保証します。
エージェントは要約によって失われた情報を回復できるでしょうか?ここでは、会話の初期段階に「干し草の山の中の針」となる事実を埋め込み、要約イベントを強制的に発生させた後、タスクを完了するためにその事実を後で思い出させる必要があります。要約後のアクティブなコンテキストにはこの事実は存在せず、ファイルシステム検索を通じて回復する必要があります。
これらのターゲット型評価は、コンテキスト管理の統合テストとして機能します。これらは完全なベンチマーク実行を代替するものではありませんが、反復回数を大幅に削減し、失敗の原因をエージェント全体の挙動ではなく、特定の圧縮メカニズムに特定可能にします。
ガイダンス
独自のコンテキスト圧縮戦略を評価する際には、以下の点を強調します:
まず実世界のベンチマークから始め、個々の機能をストレステストしてください。最初に代表的なタスクでハーンネスを実行し、ベースラインパフォーマンスを確立します。その後、より積極的に人工的に圧縮トリガーを発生させます(例えば、コンテキストの 85% ではなく 10-20% で)。これにより、各実行あたりの圧縮イベント数が増加し、個々の機能からのシグナルが強調されます。その結果、異なるアプローチ(例:要約プロンプトの変異)を比較することが容易になります。
回復性をテストしてください。コンテキスト圧縮は、重要な情報が依然としてアクセス可能である場合にのみ有用です。圧縮後もエージェントが元の目標に向かって継続できること、かつ必要に応じて特定の情報を回復できることを検証するターゲット型テストを含めてください(例:重要な事実が要約されてしまうが、後で検索しなければならない「干し草の山の中の針」シナリオなど)。
ゴールのドリフトを監視する。最も危険な失敗モードは、要約後にユーザーの意図を追跡できなくなるエージェントである。これは、要約後のターンで明確化を求めるためにタスクが完了してしまう、あるいは誤ってタスク完了と宣言してしまう形で現れることがある。意図されたタスクからのより微妙な逸脱は、要約に起因するものとして特定するのが難しい場合がある。サンプルデータセットに対して頻繁な要約を強制することで、これらの失敗を表面化できる可能性がある。
Deep Agents ハーネスのすべての機能はオープンソースである。最新バージョンを試していただき、あなたのユースケースにおいてどの圧縮戦略が最も効果的か教えてほしい!
原文を表示
imageBy Chester Curme and Mason Daugherty
As the addressable task length of AI agents continues to grow, effective context management becomes critical to prevent context rot and to manage LLMs’ finite memory constraints.
The Deep Agents SDK is LangChain’s open source, batteries-included agent harness. It provides an easy path to build agents with the ability to plan, spawn subagents, and work with a filesystem to execute complex, long-running tasks. Because these sorts of tasks can generally exceed models’ context windows, the SDK implements various features that facilitate context compression.
Context compression refers to techniques that reduce the volume of information in an agent's working memory while preserving the details relevant to completing the task. This might involve summarizing previous interactions, filtering out stale information, or strategically deciding what to retain and what to discard.
Deep Agents implements a filesystem abstraction that allows agents to perform operations such as listing, reading, and writing files, as well as search, pattern matching, and file execution. Agents use the filesystem to search and retrieve offloaded content as needed.
Deep Agents implements three main compression techniques, triggered at different frequencies:
Offloading large tool results: We offload large tool responses to the filesystem whenever they occur.
Offloading large tool inputs: When the context size crosses a threshold, we offload old write/edit arguments from tool calls to the filesystem.
Summarization: When the context size crosses the threshold, and there is no more context eligible for offloading, we perform a summarization step to compress the message history.
To manage context limits, the Deep Agents SDK triggers these compression steps at threshold fractions of the model's context window size. (Under the hood, we use LangChain's model profiles to access the token threshold for a given model.)
Offloading large tool results
Responses from tool invocations (e.g., the result of reading a large file or an API call) can exceed a model's context window. When Deep Agents detects a tool response exceeding 20,000 tokens, it offloads the response to the filesystem and substitutes it with a file path reference and a preview of the first 10 lines. Agents can then re-read or search the content as needed.
imageOffloading large tool inputs
File write and edit operations leave behind tool calls containing the complete file content in the agent's conversation history. Since this content is already persisted to the filesystem, it's often redundant. As the session context crosses 85% of the model’s available window, Deep Agents will truncate older tool calls, replacing them with a pointer to the file on disk and reducing the size of the active context.
imageSummarization
When offloading no longer yields sufficient space, Deep Agents falls back to summarization. This process has two components:
In-context summary: An LLM generates a structured summary of the conversation—including session intent, artifacts created, and next steps—which replaces the full conversation history in the agent's working memory. (See the Deep Agents summarization prompt.)
Filesystem preservation: The complete, original conversation messages are written to the filesystem as a canonical record.
This dual approach ensures the agent maintains awareness of its goals and progress (via the summary) while preserving the ability to recover specific details when needed (via filesystem search). See an example in this trace, where the model uses the read_file tool to fetch previously offloaded messages.
imageWhat this looks like in practice
While the techniques above provide the machinery for context management, how do we know they're actually working? Runs on real-world tasks, as captured in benchmarks such as terminal-bench, may trigger context compression sporadically, making it difficult to isolate their impact.
We’ve found it useful to increase the signal of individual features of the harness by engaging them more aggressively on benchmark datasets. For example, while triggering summarization at 10 - 20% of the available context window may lead to suboptimal overall performance, it produces significantly more summarization events. This allows for different configurations (e.g., variations of your implementation) to be compared. For example, by forcing the agent to summarize frequently, we could identify how simple changes to the deepagents summarization prompt, in which we added dedicated fields for the session intent and next steps, help improve performance.
imageFigure: Token usage over time in sample runs of Claude Sonnet 4.5 on terminal-bench-2 (gray lines show all runs; colored lines highlight two specific examples). The green line shows a dramatic token drop around turn 20 when a summarization event compresses the conversation history. The orange line shows a smaller reduction around turn 40 when a large file write tool call is evicted from context. By triggering compression at 25% of the context window (rather than the Deep Agents default of 85%), we generate more events to study.
Targeted evals
The Deep Agents SDK maintains a set of targeted evaluations designed to isolate and validate individual context-management mechanisms. These are deliberately small tests that make specific failure modes obvious and debuggable.
The goal of these evals is not to measure broad task-solving ability, but to ensure that the agent’s harness does not get in the way of certain tasks. For example:
Did summarization preserve the agent’s objective? Some evals deliberately trigger summarization mid-task and then check whether the agent continues. This ensures that summarization preserves not only agent state but also its trajectory.
Can the agent recover information that was summarized away? Here we embed a “needle-in-the-haystack” fact early in the conversation, force a summarization event, and then require the agent to recall that fact later to complete the task. The fact is not present in the active context after summarization and must be recovered via filesystem search.
These targeted evals act as integration tests for context management: they don’t replace full benchmark runs, but they significantly reduce iteration time and make failures attributable to specific compression mechanisms rather than overall agent behavior.
Guidance
When evaluating your own context compression strategies, we’d emphasize:
Start with real-world benchmarks, then stress-test individual features. Run your harness on representative tasks first to establish baseline performance. Then, artificially trigger compression more aggressively (e.g., at 10-20% of context instead of 85%) to generate more compression events per run. This amplifies the signal from individual features, making it easier to compare different approaches (e.g. variations in your summarization prompt).
Test recoverability. Context compression is only useful if critical information remains accessible. Include targeted tests that verify agents can both continue toward their original goal after compression and recover specific details when needed (e.g., needle-in-the-haystack scenarios where a key fact is summarized away but must be retrieved later).
Monitor for goal drift. The most insidious failure mode is an agent that loses track of the user's intent after summarization. This may manifest as the agent completing in the turn after summarization to ask for clarification, or to mistakenly declare the task complete. More subtle deviations from the intended task may be harder to attribute to summarization; forcing frequent summarization on sample datasets may help surface these failures.
All features of the Deep Agents harness are open source. Try out the latest version and let us know what compression strategies work best for your use cases!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み