V-RAGの紹介:検索拡張生成でAIを活用した映像制作に革命を
AWSはテキストプロンプトの限界を克服し、動画生成の予測可能性と制御性を向上させるため、「V-RAG(Video Retrieval-Augmented Generation)」という手法を公式ブログで発表した。
キーポイント
AI動画生成の現状と課題
従来の制作コストや専門知識を大幅に削減できる一方、結果の予測不能性やテキストプロンプトのみでは詳細な制御が難しいという課題が残っている。
V-RAGの概念と目的
検索拡張生成(RAG)の原理を動画AIモデルに適用し、生成プロセスに外部知識や参照データを組み込むことで、効率的かつ信頼性の高い動画作成を実現する。
テキストプロンプトの限界とカスタマイズ
トークン制限や曖昧な解釈を防ぐため、スタイルや雰囲気などの詳細パラメータを指定する高度なカスタマイズツールの必要性が強調されている。
影響分析・編集コメントを表示
影響分析
本記事は、生成系AIの動画分野における「制御性」と「信頼性」の課題を解決する具体的な手法としてV-RAGを提示しており、クラウド事業者が自社モデルやサービスと連携させる基盤整備を進めている兆候を示している。これにより、エンタメやマーケティング現場での実用化が加速し、AI動画生成の標準的なワークフローにRAGアーキテクチャが組み込まれる可能性が高い。
編集コメント
動画生成モデルの「黒箱」問題を解決するRAGの応用は、実務導入への重要な一歩である。AWSが自社のエコシステムに組み込む形で標準化を進めるなら、今後は他社モデルとの互換性や評価指標の公開にも注目したい。
生成 AI における重要な進展の一つに、AI を活用した動画生成があります。AI が登場する以前は、動的な動画コンテンツを作成するには膨大なリソース、専門的な技術知識、そして多大な手作業が必要でした。今日では、AI モデルが単純な入力から動画を生成できるようになりましたが、組織はまだ予測不能な結果といった課題に直面しています。本稿では、動画コンテンツ作成の改善を支援するアプローチである「Video Retrieval-Augmented Generation(V-RAG)」を紹介します。検索拡張生成と高度な動画 AI モデルを組み合わせることで、V-RAG は AI 動画生成のための効率的かつ信頼性の高いソリューションを提供します。
ビデオ生成
AI によるビデオ生成は、デジタルコンテンツ制作における変革の最前線であり、従来の撮影やアニメーションのプロセスを経ずに、動的な視覚的物語を自動的に生産することを可能にします。ディープラーニングアーキテクチャ(deep learning architectures)を用いることで、これらのシステムは現実的なまたは様式化されたビデオシーケンスを合成することができます。カメラ、俳優、そして広範なポストプロダクションを必要とする従来のビデオ制作とは異なり、AI 生成は膨大なトレーニングデータセットからパターンを分析して一貫した視覚的物語を描き出すことで、計算プロセスを通じて完全にコンテンツを生み出します。個人や組織は、この技術を利用して最小限の専門知識で視覚的コンテンツを製作でき、従来必要とされていた時間、リソース、および専門スキルを削減できます。これらのモデルが継続的に進化していくにつれ、エンターテインメントやマーケティングから教育やコミュニケーションに至るまで、業界全体にわたって視覚的物語がどのように構想され、制作され、共有されるかを根本的に再構築することを約束しています。
テキストから動画への生成
テキストから動画への生成は、物語的または主題的なテキストプロンプトから動的な動画コンテンツを作成する技術です。この技術はテキスト記述を解釈し、指定された物語に従って一貫した視覚シーケンスへと変換します。テキストプロンプトは全体的なテーマやストーリーラインを効果的に導く一方で、非常に具体的な視覚的詳細を正確に捉える点では時として不十分となる場合があります。テキストから動画への生成は、記述的な言語のみに基づいてコンテンツを生成できる AI 動画作成の基盤となります。
Video generation customization
テキストプロンプトだけでは、ビデオ生成において限界があります。テキスト記述のみを頼りにする場合、モデルがプロンプトの重要な部分を無視したり、意図とは異なる解釈をしたりする可能性があるため、本質的に制御が限られます。特定の視覚的概念は言葉だけで説明するのが難しい場合もあり、さらにモデルのトークン制限によって指示の詳細さに上限が設けられるという制約もあります。このような状況において、さらなるカスタマイズ機能が極めて重要となります。ユーザーは、スタイル、ムード、複雑な視覚的美しさなど、テキストでは効率的に伝えきれない多数のパラメータを指定できる堅牢なカスタマイズツールを利用できます。これらの制御機能は、出力に影響を与える直接的な手段を提供することで、テキストプロンプトの限界を克服するのに役立ちます。このような機能がなければ、クリエイターはモデルが自らの意図を正しく解釈してくれることを願うしかなく、創造プロセスを積極的に主導することができません。カスタマイズは、あいまいな生成と精密な視覚制御の間のギャップを埋め、AI ビデオツールを実用的な専門用途で真に有用なものにします。
モデルのファインチューニング
ファインチューニングは、事前学習済み動画生成モデルを特定のドメイン、スタイル、またはユースケースに適応させるプロセスです。このプロセスにより、組織は一貫したブランディングを持つ製品デモンストレーションの作成や、医療教育コンテンツの生成、あるいは独自の芸術的スタイルでの動画制作など、特定のタスクに優れた専門的な動画ジェネレーターを作成することが可能になります。ファインチューニングは通常、対象ドメインを代表するように慎重に選別されたデータセットを用いて既存モデルをさらに訓練することを含み、これによりモデルが専門的なアプリケーションに必要な独自の視覚パターン、動き、およびスタイル要素を学習できるようになります。しかし、動画生成モデルのファインチューニングには重大な課題が存在します。根本的な障壁はデータ取得から始まります。トレーニングに適した高品質な動画データは、入手に多額の費用がかかり、かつ困難を伴うからです。組織は、特定のユースケースを網羅し、技術的な品質基準を満たす特定フォーマットの多様で適切にラベル付けされた映像素材を必要とします。計算リソースの要求も非常に大きく、これが参入障壁となっています。単一のファインチューニング実行には、連続稼働する複数のハイエンド GPU が必要となる場合があり、新しい機能を組み込むための再学習では、その都度これらのコストが倍増します。完璧なデータと無制限の計算リソースがあったとしても、一貫性、物理的正確さ、照明の一貫性、オブジェクトの持続性といった動画要素が相互に密接に関連しているため、成功は不確実なままです。ある分野での改善が他の分野での予期せぬ劣化をもたらすことが多く、単純な解決策では対応できない複雑な最適化課題を生み出しています。
Image-to-video
画像から動画への生成は、テキストベースのアプローチを補完し、追加の視覚的制御を提供します。入力画像をリファレンスとして使用することで、ユーザーはオブジェクトの色、スタイル、その他の属性などの具体的な詳細が生成された動画に正確に表現されることを保証できます。例えば、ユーザーが動画で赤い財布を特集したい場合、その正確な財布の画像を提供することは、テキストの説明だけでは達成できない視覚的忠実度を保証します。この手法は、条件付けを通じて一貫性を維持しプロンプトへの準拠を改善しながら、動的な動きとより広い物語的文脈内での統合を可能にします。画像から動画への生成には、微調整(fine-tuning)は不要です。
V-RAG: an effective approach in video generation customization
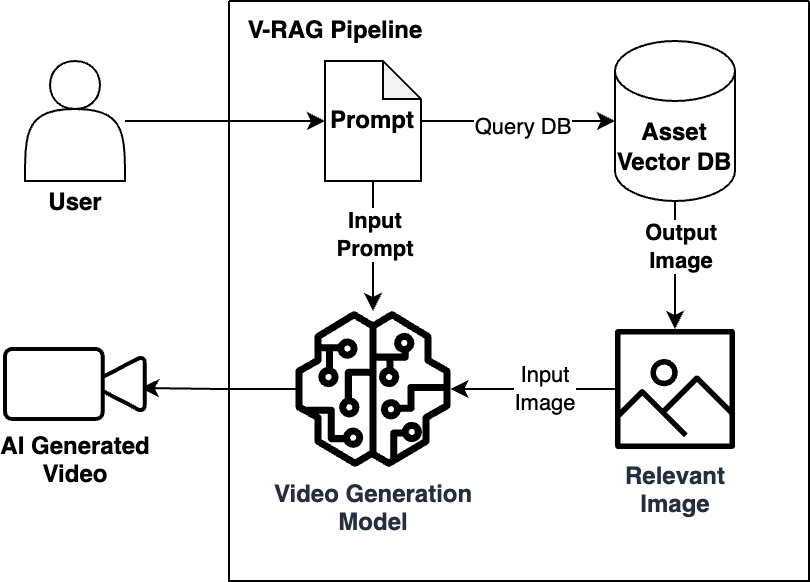
動画検索拡張生成(Video Retrieval-Augmented Generation:V-RAG)は、画像から動画への技術を基盤として、動画のカスタマイズ機能を拡大します。従来の画像から動画への技術が単一の参照画像を動きに変換するのに対し、V-RAG はデータベースから関連する画像を検索・取得し、それを動画生成に組み込むことでこの機能を拡張します。このアプローチは、モデルのトレーニングや再トレーニングを必要とせずに、いくつかの機能を提供します。組織は自社の画像コレクションをベクトルデータベース(vector database)に取り込み、クエリを実行してその出力を既存の動画生成モデルに供給することで、即座に tailored content の生産を開始できます。
V-RAG の効率性は、動画のトレーニングデータよりも一般的に入手しやすい静止画像のみを必要とする点にあります。これらの画像はベクトルデータベースにその場で追加できるため、計算上の遅延なく次の生成タスクのために即座に利用可能になります。このプロセスを通じて生成されるすべての動画は、そのソース画像に対する明確な追跡可能性を維持し、検証およびデバッグ機能を強化する監査可能なトレイルを作成します。システムは、ハルシネーション(幻覚)リスクの低減と計算コストの管理を支援するために設計された特定の参照イメージに基づいて動画出力を grounding します。組織は、異なる部門やユースケースのために別々のビジュアルナレッジベースを維持し、すべてのソース材料がシステムに入る前に徹底的に審査されることでコンプライアンスを簡素化できます。
*V-RAG の論理図*
##
V-RAG の進化の性質
V-RAG は固定された技術ではなく、AI 能力の進展とともに継続的に拡張されていく動的なフレームワークを代表しています。現在の実装は主に画像データベースを利用していますが、根本的な検索強化アプローチはモダリティに依存しないものです。マルチモーダル AI モデルが成熟するにつれ、V-RAG システムは生成プロセスにおいて音声サンプル、動画スニペット、3D モデル(3D models)を参照点として自然に取り込むようになります。今後のバージョンでは、取得した音声パターンに基づいて完全なオーディオ・ビジュアル体験を合成し、完璧に同期された音声や現実的な環境音、カスタム音楽スコアを備えた動画を生成する機能をサポートするようになるでしょう。この柔軟性は、V-RAG を特定の実装ではなく基盤となるパラダイムとして位置づけ、より広範な AI の進展に合わせて適応しつつも、追跡可能性、効率性、ハルシネーション(幻覚)の低減という中核的な利点を維持することを可能にします。究極のビジョンはオーディオ・ビジュアルコンテンツを超え、インタラクティブ要素を潜在的に組み込むことで、信頼性の高い参照資料に基づきつつも魅力的な出力を生み出す包括的なマルチモーダル生成システムを創出することへと広がっています。
V-RAG の主な利点
V-RAG を通じて取得した画像を用いて動画を生成することは、精度の向上、関連性の強化、文脈理解の深化といった大きなメリットをもたらします。このアプローチは、生成されたコンテンツを特定の知識ベースに根ざさせることで、動画制作を導く役割を果たします。これによりハルシネーション(幻覚的生成)が減少し、動画が画像ソースからの情報と整合性を持つことを保証するため、教育用、ドキュメンタリー、解説動画のフォーマットにおいて特に有用です。画像から V-RAG を利用する主な利点は以下の通りです。
- 事実の正確さ – 生成された動画コンテンツが実際の情報に基づいていることを保証し、不正確または誤解を招くビジュアルの可能性を低減します。
- 文脈的な関連性 – 与えられたトピックやクエリに非常に高い関連性を持つ画像を取得することで、より一貫性があり焦点の絞られた動画ナラティブを実現します。
- ダイナミックなコンテンツ生成 – ユーザー入力や変化する要件に基づいて画像を動的に選択・組み立てることで、柔軟な動画制作を可能にします。
- 開発時間の短縮 – 既存の知識ベースを活用することで、動画制作のために視覚資産を集め、キュレーションするに必要な時間を削減します。
- パーソナライズされたコンテンツ – 個々のユーザーのニーズに合わせて動画を調整し、関連性が高く魅力的なコンテンツを生成するように設計されています。
- スケーラビリティ(拡張性) – ベクトルデータベースに追加画像を取り込むことで、スケーリングできるように設計されています。
V-RAG の実世界での応用
V-RAG の実世界での応用は広範かつ多岐にわたります。教育分野では、V-RAG は専門知識ベースから関連画像を抽出して自動的に講義動画を作成できます。パーソナライズされたコンテンツにおいては、ユーザーの特定の興味に基づいて画像を取得することで、個々のユーザー向けに動画コンテンツを調整することが可能です。マーケティングにおいては、特定の人口統計や製品機能と一致する画像を抽出して、ターゲットを絞った動画広告を作成できます。
結論
AI テクノロジーが継続的に進化していく中で、V-RAG の柔軟なフレームワークは、高度な音声統合からインタラクティブ要素に至るまで、新たなモダリティや機能を組み込む準備を整えています。AWS による実装は、組織が既存のクラウドサービスを通じてすでにこの技術の利用を開始できることを示しており、AI 動画生成をより広範なユーザー層にアクセス可能にしています。今後を見据えると、V-RAG のビデオコンテンツ制作への影響は、現在の教育やマーケティングにおける応用をはるかに超えて拡大していくでしょう。技術が成熟するにつれ、このアプローチは動画制作のアクセシビリティを高めつつ、品質、正確性、カスタマイズ性を支える可能性を秘めています。これは AI 駆動型動画生成にとって有望な道筋を提供し、組織が魅力的な視覚コンテンツを作成することを可能にします。
参考文献
- Amazon Nova Reel を用いた動画生成
- Amazon Nova Reel
- Amazon OpenSearch Service
謝辞
貢献してくださったヴィシュワ・グプタ、シャオ・カオ、セイフの皆さんに心から感謝いたします。
著者紹介

ニック・ビソ
ニック・ビソは、AWS Professional Services の機械学習エンジニアです。データサイエンスとエンジニアリングを活用して、組織的および技術的な複雑な課題の解決に取り組んでいます。また、AWS クラウド上で AI/ML モデルの構築とデプロイも行っています。彼の情熱は旅行や多様な文化的体験にも及んでいます。

マドゥニカ・ミッキリ
マドゥニカ・ミッキリは、AWS のデータおよび機械学習エンジニアです。データ分析と機械学習を活用して顧客が目標を達成できるよう支援することに情熱を持っています。

マリア・マスード
マリア・マスードは、エージェント型 AI(Agentic AI)、強化学習による微調整(Reinforcement Fine-tuning)、および多ターンエージェントのトレーニングを専門としています。機械学習における専門知識を持ち、大規模言語モデルのカスタマイズ、報酬モデリング、AI エージェント向けのエンドツーエンドなトレーニングパイプラインの構築などを経験しています。心からサステナビリティを愛するマリアは、ガーデニングやラテ作りを楽しんでいます。
原文を表示
A key development in generative AI is AI-powered video generation. Before AI, creating dynamic video content required extensive resources, technical expertise, and significant manual effort. Today, AI models can generate videos from simple inputs, but organizations still face challenges like unpredictable results. This post introduces Video Retrieval-Augmented Generation (V-RAG), an approach to help improve video content creation. By combining retrieval augmented generation with advanced video AI models, V-RAG offers an efficient, and reliable solution for generating AI videos.
Video generation
AI video generation represents a transformative frontier in digital content creation, enabling the automated production of dynamic visual narratives without traditional filming or animation processes. By using deep learning architectures, these systems can synthesize realistic or stylized video sequences. Unlike conventional video production that requires cameras, actors, and extensive post-production, AI generation creates content entirely through computational processes analyzing patterns from massive training datasets to render coherent visual stories. Individuals and organizations can use this technology to produce visual content with minimal technical expertise, reducing the time, resources, and specialized skills traditionally required. As these models continue to evolve, they promise to fundamentally reshape how visual stories are conceived, produced, and shared across industries ranging from entertainment and marketing to education and communication.
Text-to-video generation
Text-to-video generation creates dynamic video content from narrative or thematic text prompts. This technology interprets textual descriptions and transforms them into coherent visual sequences that follow the specified narrative. While text prompts effectively guide the overall theme and storyline, they can sometimes fall short in capturing highly specific visual details with precision. Text-to-video serves as the foundation of AI video creation, where users can generate content based on descriptive language alone.
Video generation customization
Text prompting can only get you so far with video generation. There’s inherently limited control when relying solely on text descriptions, as models can ignore crucial parts of your prompt or interpret them differently than you intended. Certain visual concepts prove difficult to explain in words alone, additionally, you’re constrained by the model’s token limit that caps how detailed your instructions can be. This is where further customization becomes invaluable. Users can use robust customization tools to specify numerous parameters beyond what text can efficiently communicate, such as style, mood, and intricate visual aesthetics. These controls help overcome the limitations of text prompting by providing direct mechanisms to influence the output. Without such capabilities, creators are left hoping the model correctly interprets their intentions rather than actively directing the creative process. Customization bridges the gap between vague generation and precise visual control, making AI video tools truly useful for professional applications.
Model fine-tuning
Fine-tuning adapts pre-trained video generation models to specific domains, styles, or use cases. This process allows organizations to create specialized video generators that excel at tasks whether they’re producing product demonstrations with consistent branding, generating medical educational content, or creating videos in a distinctive artistic style. Fine-tuning typically involves further training of existing models on carefully curated datasets representing the target domain, allowing the model to learn the unique visual patterns, movements, and stylistic elements required for specialized applications. However, fine-tuning video generation models presents significant challenges. The fundamental obstacle begins with data acquisition because high-quality video data that’s suitable for training is both expensive and difficult to obtain. Organizations need diverse, well-labeled footage in a specific format covering specific use cases while meeting technical quality standards. The computational demands are substantial, representing a major barrier to entry. A single fine-tuning run can require multiple high-end GPUs operating continuously, and retraining to incorporate new capabilities multiplies these costs with each iteration. Even with perfect data and unlimited computational resources, success remains uncertain due to the interconnected nature of video elements like coherence, physical accuracy, lighting consistency, and object persistence. Improvements in one area often led to unexpected degradation in others, creating complex optimization challenges resistant to simple solutions.
Image-to-video
Image-to-video generation complements text-based approaches by offering additional visual control. By using an input image as a reference, users can ensure specific details such as the color, style, and other attributes of objects are accurately represented in the generated video. For example, if a user wants to feature a red purse in their video, providing an image of that exact purse guarantees visual fidelity that text descriptions alone might not achieve. This technique maintains consistency and improves prompt adherence through conditioning, while enabling dynamic movement and integration within the broader narrative context. Image-to-video generation doesn’t require any fine-tuning.
V-RAG: an effective approach in video generation customization
Video Retrieval-Augmented Generation (V-RAG) builds upon image-to-video technology to expand video customization capabilities. While traditional image-to-video converts a single reference image into motion, V-RAG expands this capability by retrieving and incorporating a relevant image from a database to feed into a video generation. This approach offers several capabilities without requiring any model training or retraining. Organizations can ingest their image collections into a vector database, query it, and feed its output to an existing video generation model and start producing tailored content immediately.
V-RAG’s efficiency comes from requiring only static images, which are generally more readily available than video training data. These images can be added to the vector database on the fly, making them instantly available for the next generation task without computational delays. Every video generated through this process maintains clear traceability to its source images, creating an auditable trail that enhances verification and debugging capabilities. The system grounds video outputs in specific reference imagery, which is designed to help reduce hallucination risks and manage computational costs. Organizations can maintain separate visual knowledge bases for different departments or use cases, streamlining compliance as all source materials can be thoroughly vetted before entering the system.
*Logical Diagram of V-RAG*
##
The evolving nature of V-RAG
V-RAG represents not a fixed technology, but an evolving framework that will continuously expand as AI capabilities advance. While current implementations primarily utilize image databases, the fundamental retrieval augmentation approach is modality-agnostic. As multimodal AI models mature, V-RAG systems will naturally incorporate audio samples, video snippets, and 3D models as reference points during generation. Future iterations will likely support synthesizing complete audio-visual experiences, generating videos with perfectly synchronized speech, realistic environmental sounds, and custom musical scores based on retrieved audio patterns. This flexibility positions V-RAG as a foundational paradigm rather than a specific implementation, allowing it to adapt alongside broader AI advancements while maintaining its core benefits of traceability, efficiency, and reduced hallucination. The ultimate vision extends beyond even audiovisual content to potentially incorporating interactive elements, creating a comprehensive multimodal generation system that can produce engaging outputs while maintaining grounding in reliable reference material.
Key benefits of V-RAG
Generating videos using images retrieved through V-RAG offers significant benefits like increased accuracy, relevance, and contextual understanding. This approach grounds generated content in a specific knowledge base to help guide video creation. This reduces hallucination and ensures that the video aligns with information from the image source, making it particularly useful for educational, documentary, or explainer video formats. Key benefits of using V-RAG from images include:
- Factual accuracy – Ensuring the generated video content is grounded in real information, reducing the likelihood of inaccurate or misleading visuals.
- Contextual relevance – Retrieving images that are highly relevant to the given topic or query, leading to a more cohesive and focused video narrative.
- Dynamic content generation – Allowing for flexible video creation by dynamically selecting and assembling images based on user input or changing requirements.
- Reduced development time – Using a pre-existing knowledge base to cut down on the time needed to gather and curate visual assets for video creation.
- Personalized content – Tailoring videos to individual user needs, generating content designed to be relevant and engaging.
- Scalability – Designed to scale by ingesting additional images into the vector database.
Real-world applications of V-RAG
Real-world applications of V-RAG are vast and varied. In education, V-RAG can automatically create instructional videos by pulling relevant images from a subject matter knowledge base. For personalized content, V-RAG can tailor video content to individual users by retrieving images based on their specific interests. For marketing, V-RAG can create targeted video ads by pulling images that align with specific demographics or product features.
Conclusion
As AI technology continues to evolve, V-RAG’s flexible framework positions it to incorporate new modalities and capabilities, from advanced audio integration to interactive elements. The AWS implementation demonstrates how organizations can already begin using this technology through existing cloud services, making AI video generation accessible to a broader range of users. Looking ahead, V-RAG’s impact on video content creation will likely extend far beyond its current applications in education, and marketing. As the technology matures, it has the potential to make video production accessible while supporting quality, accuracy, and customization. This approach offers a promising path for AI-powered video generation, enabling organizations to create compelling visual content.
References
- Generating Videos with Amazon Nova Reel
- Amazon Nova Reel
- Amazon OpenSearch Service
Acknowledgement
Special thanks to Vishwa Gupta, Shuai Cao and Seif for their contribution.
About the authors
Nick Biso
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Madhunika Mikkili
Madhunika Mikkili is a Data and Machine Learning Engineer at AWS. She is passionate about helping customers achieve their goals using data analytics and machine learning.
Maria Masood
Maria Masood specializes in agentic AI, reinforcement fine-tuning, and multi-turn agent training. She has expertise in Machine Learning, spanning large language model customization, reward modeling, and building end-to-end training pipelines for AI agents. A sustainability enthusiast at heart, Maria enjoys gardening and making lattes.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み