正式検証済みAES-XTS:s2n-bignumに初参加するAESアルゴリズム
AWSは、顧客データ保護に使用されるAES-XTS暗号化アルゴリズムのArm64アセンブリ実装を、数学的に正しさを証明する形式検証によって初めて検証し、s2n-bignumライブラリに統合した。
キーポイント
形式検証による暗号実装の安全性保証
AWSは、AES-XTS復号化の最適化されたArm64アセンブリ実装を数学的に形式検証し、仕様を満たすことを証明した。これは手動レビューでは保証できない複雑なコードの正しさを確立する。
実運用での広範な適用
検証対象のAES-256-XTSアルゴリズムは、EBS、Nitroカード、DynamoDBなどのAWSサービスで顧客データの保護に使用されており、実用上の重要性が極めて高い。
技術的複雑性と最適化
検証されたコードは、可変長データ(16バイト〜16MB)を処理する5倍アンロール版で、複数のレジスタで並列実行され、現代のCPUパイプライン向けに最適化されている。
s2n-bignumライブラリへの統合
この形式検証済みAES-XTSは、s2n-bignum暗号ライブラリに組み込まれる最初のAESアルゴリズムとなり、ライブラリの信頼性を高める。
開発手法と成果
HOL Light定理証明支援系を用いた証明駆動開発により、s2n-bignumライブラリで最大規模の証明を達成し、AES-XTSのArm64アセンブリ実装を改善した。
AES-XTSの仕組みと特徴
ストレージ暗号化向けに設計されたAES-XTSは、セクタ番号から生成される位置依存のツイークと、部分ブロックを扱う暗号文盗用により、ランダムアクセスとデータサイズ保存を実現する。
既存実装の複雑な制御フロー
既存のAWS-LC実装は、バッファオーバーリードを防ぐために複雑なポインタ操作と制御フローを持ち、ループカウンターの増減や複数の出口ポイントを含む。
影響分析・編集コメントを表示
影響分析
この成果は、クラウドセキュリティの基盤を数学的に堅牢化する重要な一歩である。形式検証により、暗号実装のバグや脆弱性を原理的に排除できる可能性を示し、特に金融、医療など高信頼性が要求される分野でのクラウドサービス採用に弾みをつける。また、自動化された検証技術の実用化が進むことで、より複雑なシステムの安全性保証への応用が期待される。
編集コメント
PR色はあるが、形式検証という高度な技術を実用的な暗号実装に適用した点で技術的価値が高く、クラウドセキュリティの信頼性向上に直接寄与する重要な進展として評価できる。
コア演算のアセンブリコードを簡素化し明確にすることで、自動化された最適化と検証が可能になりました。
自動推論
Yan Peng Nevine Ebeid June Lee March 20, 12:38 PM March 20, 12:41 PM 暗号化アルゴリズムは、読み取り可能なデータをランダムなビット列のように見える暗号文に変換する数学的手順です。この暗号文は、対応する復号アルゴリズムと正しい鍵によってのみ復号できます。
保存データ(ディスクやデータベースに保存された情報)の場合、AES-XTSなどのアルゴリズムが、データがストレージに書き込まれる前に各ブロックを暗号化し、物理的な盗難やストレージシステムへの不正アクセスから保護します。転送データ(ネットワークを流れる情報)の場合、TLSなどのプロトコルは複数のアルゴリズムを組み合わせます。非対称暗号アルゴリズム(RSAや楕円曲線)は安全な接続を確立し、高速な対称暗号アルゴリズム(AES-GCMなど)は実際のデータストリームを保護し、改ざんされていないことを検証します。Amazon Web Services (AWS) では、AES-XTSをEBS、Nitroカード、DynamoDBなどのサービスで顧客データを保護するために使用し、AES-GCMを用いたTLSがサービス間および顧客との間のすべてのネットワーク通信を保護しています。
私たちは、最適化されたArm64アセンブリ実装によるAES-XTS復号を形式的に検証するという課題に取り組みました。形式的検証とは、エンジニアリングされたシステムが特定の仕様を満たすことを数学的に証明するプロセスです。
私たちの作業は、ブロック指向ストレージデバイスの暗号保護に関するIEEE標準1619に従い、AES-XTSのAES-256-XTSバリアントに焦点を当てています。256は暗号鍵のサイズを指定します。
固定サイズのブロックを処理するアルゴリズムとは異なり、AES-XTSは16バイトから16メガバイトまでの可変長データを扱い、不完全なブロックに対する特別なロジックを持ちます。検証されたアセンブリコードは5段アンロール版であり、そのループが5つのレジスタ(それぞれが入力ブロックを含む)にわたって並列実行されることを意味し、現代のCPUパイプライン向けに最適化されていました。その複雑さは、手動レビューでは正確性を保証できず、かつエラーが顧客データのセキュリティを損なう可能性があるほど重大であるというものでした。
Amazon Web Servicesの形式的に検証された多倍長整数演算ライブラリであるs2n-bignumの一部として、私たちは改善されたAES-XTS暗号化および復号のArm64アセンブリ実装と、チームメンバー(John Harrison)によって開発されたHOL Lightインタラクティブ定理証明器を用いた仕様および形式的検証を提供しました。
これは、入力長に基づく複数のパスを持つ大規模な関数の、証明駆動開発の実験でした。その結果、s2n-bignumライブラリにおいてこれまでで最大の証明が得られました。典型的な入力サイズである512バイトの場合、アルゴリズムの性能は、元のコードの性能に近いか、高度に最適化されたArmコアではわずかに向上しました。このアルゴリズムとその証明をs2n-bignumライブラリに追加することで、より多くのAESベースのアルゴリズムが追加される道を開きます。
アルゴリズムの説明
AESは鍵付き置換を実装するブロック暗号です。これは、平文ファイルをブロック(この場合は128ビットのブロック)単位で処理し、与えられた鍵に対して、各平文ブロックを一意の暗号文ブロックにマッピングする全単射(一対一で可逆な)関数を定義することを意味します。この数学的特性により、復号は元の平文を一意に回復できます。
AES-XTSは、ストレージ暗号化のために特別に設計されたモードです。AESを基礎となる構成要素として使用しますが、位置依存の調整(ツイーク)と、部分ブロックを扱う方法である暗号文盗用を追加し、任意のセクタへのランダムアクセスが必要であり、正確なデータサイズを保存しなければならないディスク暗号化の独自の要件に対応します。
AES-XTSは、二鍵アプローチを使用してストレージデータを暗号化します。各128ビットブロックとその位置依存のツイークは排他的論理和(XOR)演算(入力値が異なる場合にのみ1を出力する二項演算)の対象となります。この演算の結果はAESで暗号化され、再びツイークとXOR演算され、ディスク上の異なる位置にある同一のデータが異なる暗号文を生成することを保証します。ツイークは、セクタ番号を第二の鍵で暗号化し、ガロア体におけるαの累乗を乗算することで生成され、各ブロック位置に対して一意の値を作り出します。
最終ブロックが128ビット全体でない場合、暗号文盗用が発動します。暗号文盗用は前のブロックからバイトを借用し、パディングや無駄なスペースなしにあらゆる長さのデータの暗号化を可能にします。これにより、各ブロックの暗号化をその位置に基づきながら、任意のセクタを独立して読み書きできるようになります(ディスク暗号化にとって重要です)。これは望ましい特性です。なぜなら、ディスク暗号化のセキュリティモデルでは、敵対者が問題のセクタ以外のセクタにアクセスし、それらを変更し、その復号を要求することが許容されるからです。また、これにより暗号文のサイズが平文のサイズと完全に同じになることが保証され、元の場所に収まります。
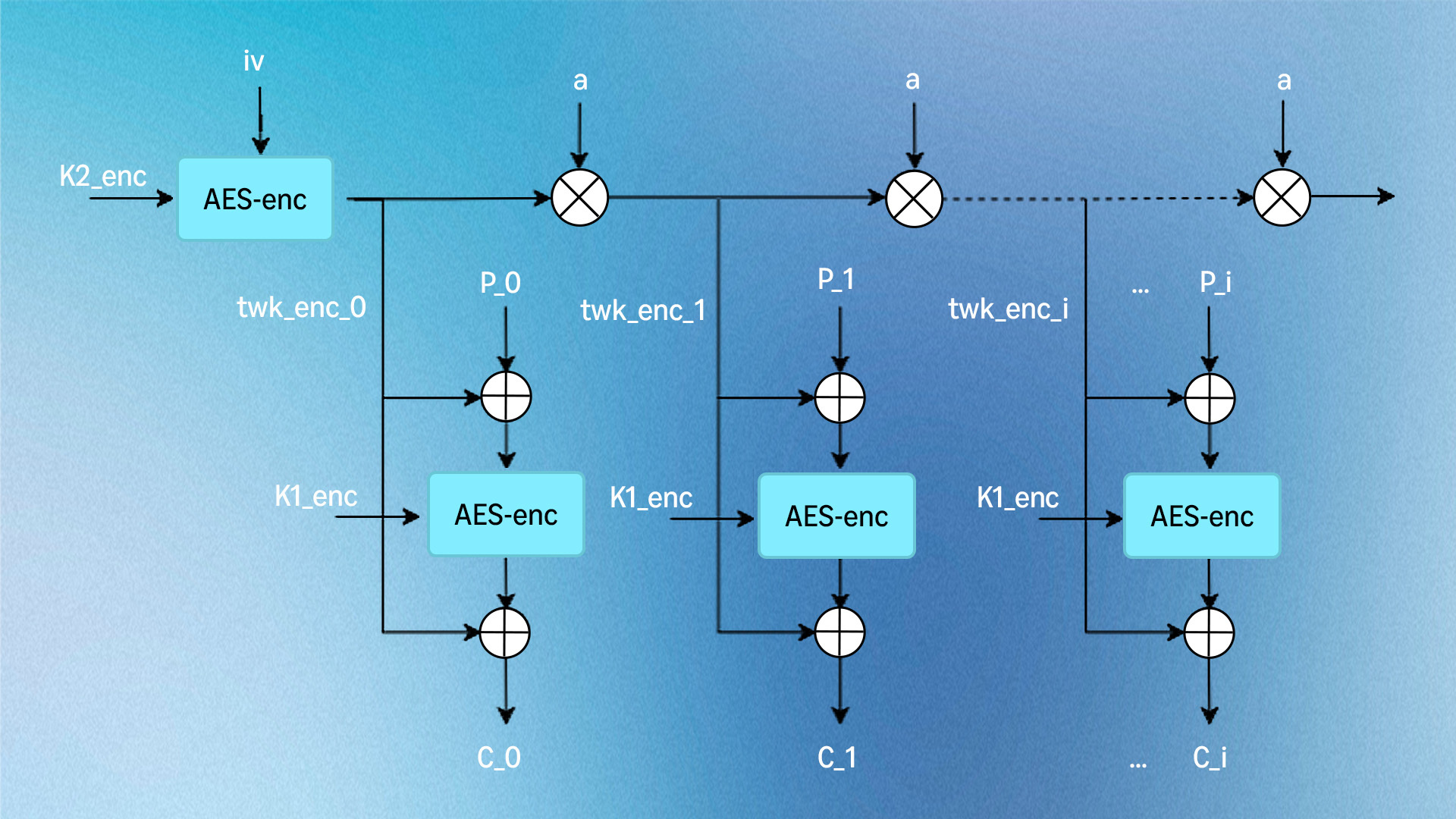 image XOR-Encrypt-XOR (XEX) 構造を用いたAES-XTS暗号化。
image XOR-Encrypt-XOR (XEX) 構造を用いたAES-XTS暗号化。 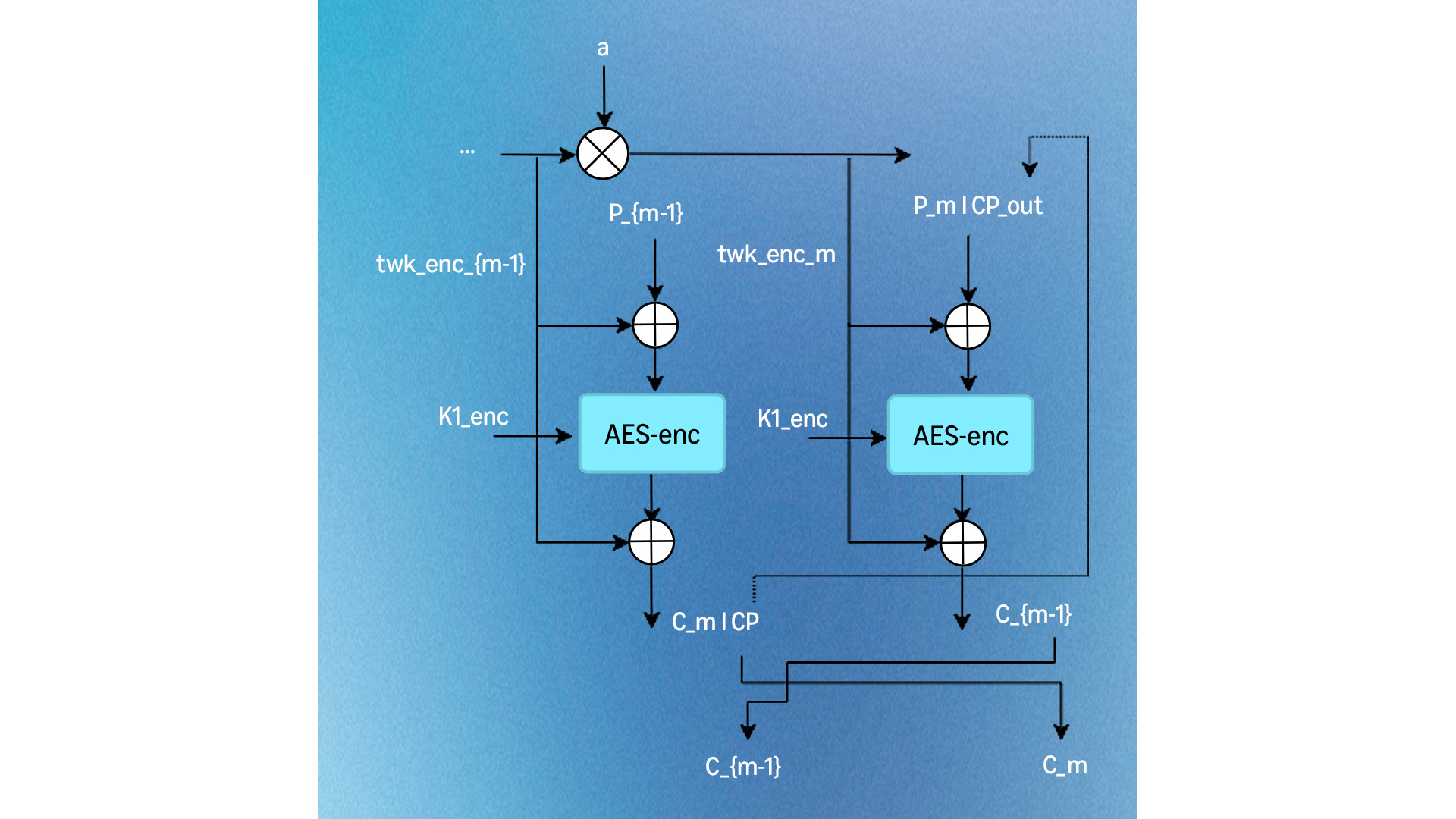 image 暗号文盗用は、最後から二番目のブロックを分割することで、暗号化中の部分ブロックを処理します。
image 暗号文盗用は、最後から二番目のブロックを分割することで、暗号化中の部分ブロックを処理します。
原文を表示
Formally verified AES-XTS: The first AES algorithm to join s2n-bignum
Simplifying and clarifying the assembly code for core operations enabled automated optimization and verification.
Automated reasoning
Yan Peng Nevine Ebeid June Lee March 20, 12:38 PM March 20, 12:41 PM Cryptographic encryption algorithms are mathematical procedures that transform readable data into ciphertext that looks like a stream of random bits. The ciphertext can be decrypted only with the corresponding decryption algorithm and the correct key.
For data at rest information stored on disks or in databases algorithms like AES-XTS encrypt each block before its written to storage, protecting against physical theft or unauthorized access to storage systems. For data in transit information traveling across networks protocols like TLS combine multiple algorithms: asymmetric encryption algorithms (RSA or elliptic curves) establish secure connections, while fast symmetric encryption algorithms (like AES-GCM) protect the actual data stream and verify that it hasn't been tampered with. At Amazon Web Services (AWS), we use AES-XTS to protect customer data in services like EBS, Nitro cards, and DynamoDB, while TLS with AES-GCM secures all network communication between services and to customers.
We took on the challenge of formally verifying an optimized Arm64 assembly implementation of AES-XTS decryption, where formal verification is the process of proving mathematically that an engineered system meets a particular specification.
Our work follows the IEEE Standard 1619 for cryptographic protection of block-oriented storage devices and focuses on the AES-256-XTS variant of AES-XTS. The 256 specifies the size of the encryption key.
Unlike algorithms that process fixed-size blocks, AES-XTS handles variable-length data from 16 bytes up to 16 megabytes, with special logic for incomplete blocks. The assembly code verified was a 5x-unrolled version, meaning that its loops were executed in parallel across five registers (each containing an input block), and it had been optimized for modern CPU pipelines. It was complex enough that manual review couldn't guarantee correctness yet critical enough that errors could compromise customer data security.
As part of Amazon Web Services s2n-bignum library of formally verified big-number operations, we contributed an improved Arm64 assembly implementation of AES-XTS encryption and decryption, as well as specification and formal verification using the HOL Light interactive theorem prover, which was developed by a member of our team (John Harrison).
This was an experiment in the proof-driven development of a large function with multiple paths based on the input length. It resulted in the largest proof so far in the s2n-bignum library. For the typical input size of 512 bytes, the performance of the algorithm either stayed close to that of original code or improved slightly on highly optimized Arm cores. By adding this algorithm and its proof to the s2n-bignum library, we pave the way for more AES-based algorithms to be added.
Description of the algorithm
AES is a block cipher that implements a keyed permutation. This means that it processes the plaintext files in blocks (in this case, blocks of 128 bits), and for any given key, it defines a bijective (one-to-one and invertible) function mapping each plaintext block to a unique ciphertext block. This mathematical property ensures that decryption can uniquely recover the original plaintext.
AES-XTS is the mode specifically designed for storage encryption. It uses AES as its underlying building block but adds position-dependent tweaks and ciphertext stealing a method for handling partial blocks to address the unique requirements of disk encryption, where you need random access to any sector and must preserve the exact data size.
AES-XTS encrypts storage data using a two-key approach where each 128-bit block and its position-dependent tweak are subjected to an exclusive-OR operation (XOR), a binary operation that outputs a one only if the input values differ. The result of the operation is encrypted with AES, then XORed with the tweak again, ensuring that identical data at different disk locations produces different ciphertext. The tweak is generated by encrypting the sector number with a second key, then multiplying by powers of in a Galois field, creating unique values for each block position.
When the final block isn't a full 128 bits, ciphertext stealing kicks in. Ciphertext stealing borrows bytes from the previous block, allowing encryption of data of any length without padding or wasted space. This lets you read or write any sector independently critical for disk encryption while basing each block's encryption on its position. That is a desired feature since the security model of disk encryption allows the adversary to access sectors other than those in question, modify them, and request their decryption. It also ensures that the size of the ciphertext is exactly the same as that of the plaintext, so it fits in its place.
image AES-XTS encryption employing an XOR-encrypt-XOR (XEX) structure. image Ciphertext stealing handles partial blocks during encryption by splitting the second-to-last block's output. 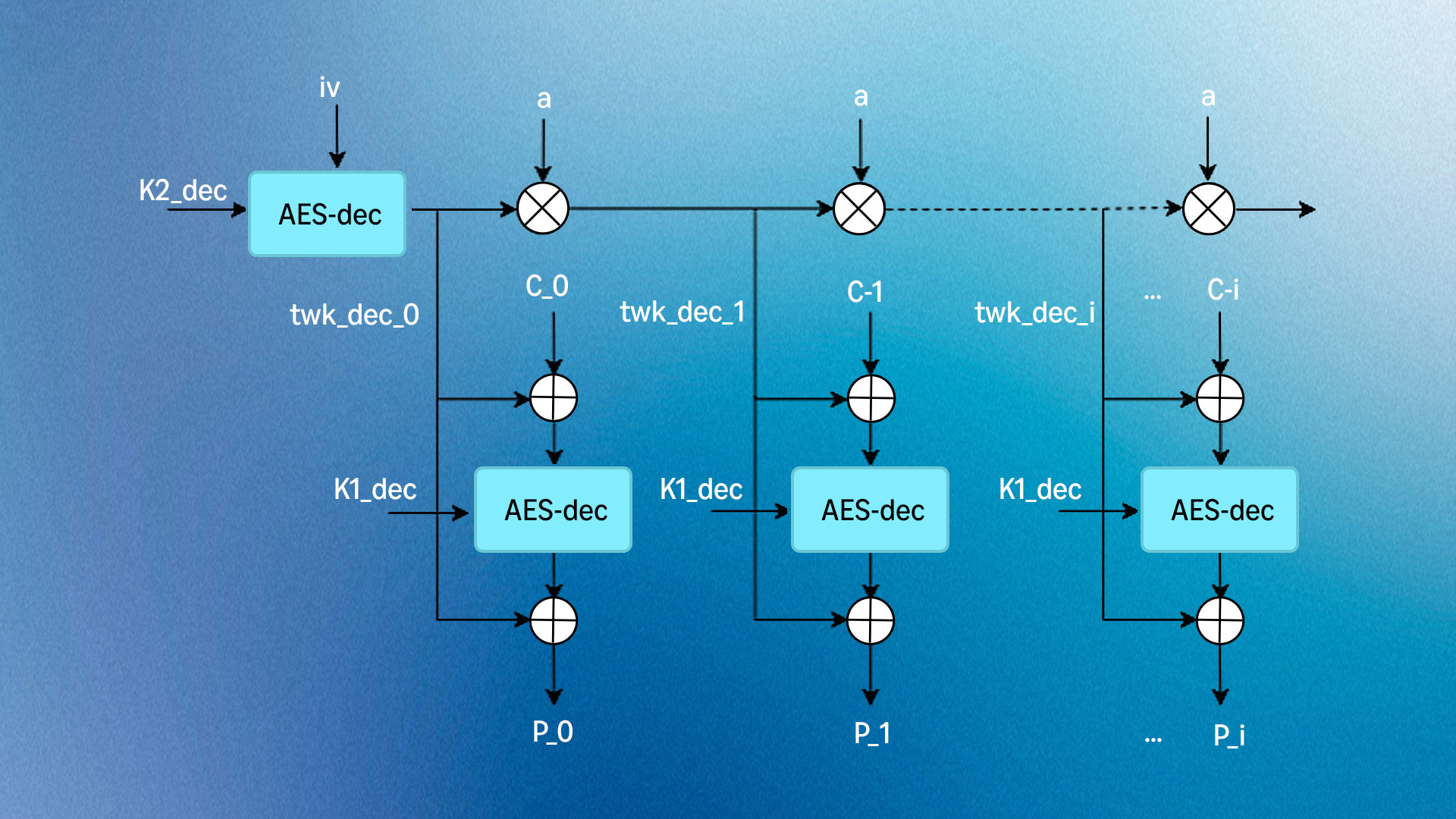 image The symmetric decryption process.
image The symmetric decryption process. 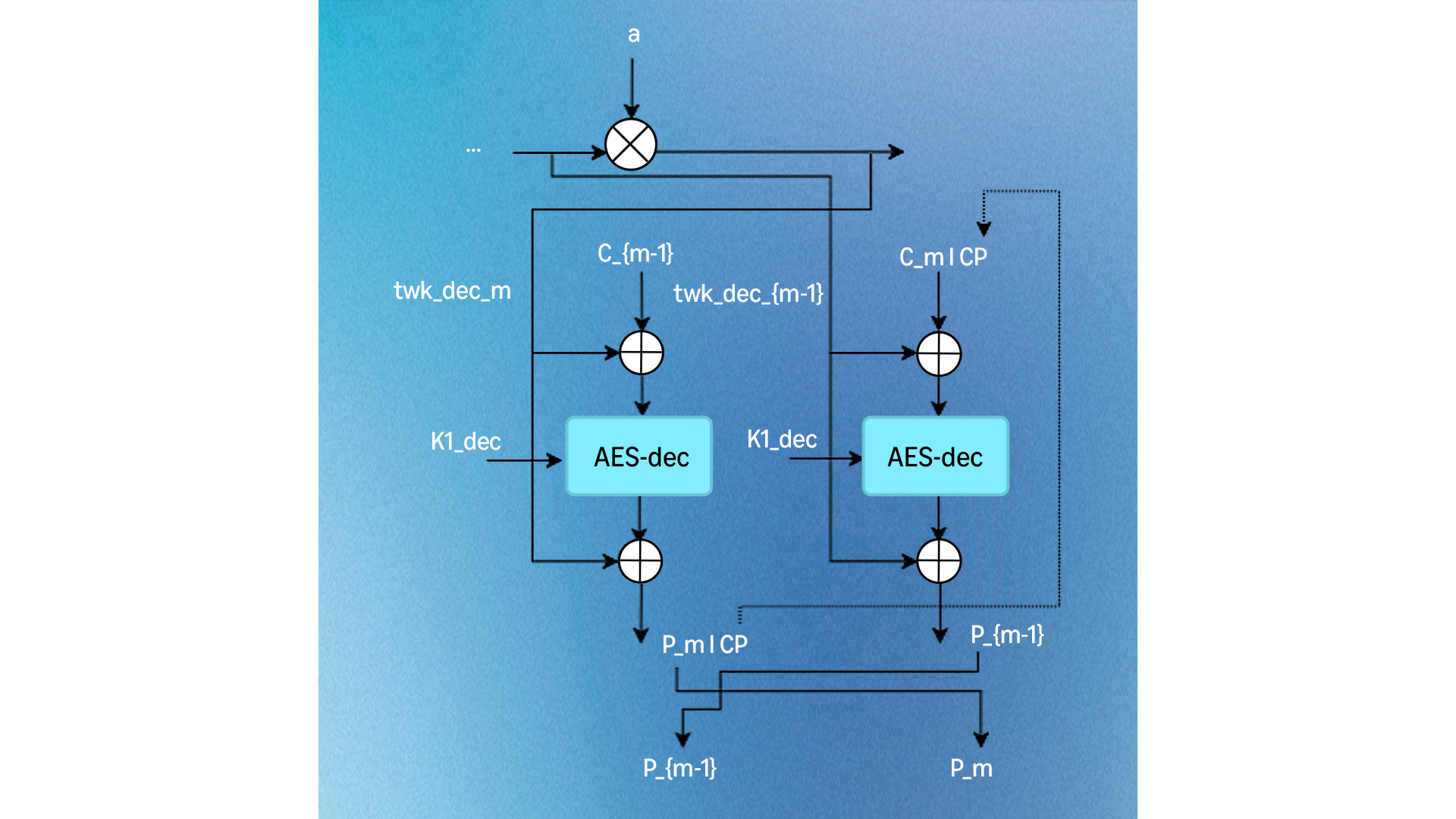 image Reverse ciphertext stealing for decryption. Control flow of the assembly implementation
image Reverse ciphertext stealing for decryption. Control flow of the assembly implementation
We started from an existing implementation of AES-XTS in Amazons AWS-LC cryptographic library. AES-XTS loops through the plaintext in 128-bit blocks, and encryption of each block requires 15 steps, each with its own round key derived from the encryption key. The existing implementation is 5x unrolled, meaning it processes blocks in parallel, five at a time. If the final block is less than 128 bits in length, theres a risk of buffer overread, or reading beyond the limits of the input buffer.
To avoid overread, the existing implementation does complex manipulation over the pointer to the current location in the input buffer. This requires a sophisticated control flow that can be hard to follow: the loop counter is incremented and decremented multiple times before and during the loop, and the loop has two additional exit points other than the final loop-back branch.
One exit point is for the case when four blocks remain during the final iteration of the loop; the other exit point is for the case of one to three blocks remaining. The flow of the loop interleaves the load/store instructions with the AES and XOR instructions in an effort to maximize pipeline usage. After the loop exit, the processing of the remaining blocks is intertwined for the lengths of four down to one; if theres a partial block at the end, the algorithm performs the ciphertext-stealing procedure. Additionally, only seven of the 15 rounds keys were kept in registers; the other eight were repeatedly loaded from memory in the loop and outside it.
We first investigated whether we could improve the performance of the main loop by letting SLOTHY, a superoptimizer for Arm code, rearrange the instructions to maximize pipeline usage. SLOTHY contains simplified models of various Arm microarchitectures. It uses a constraint solver to provide optimal instruction schedule, register renaming, and periodic loop interleaving.
However, for SLOTHY to identify and optimize a loop, the loop has to exhibit typical loop behavior, decreasing the counter at the end of each iteration and then jumping back to the beginning. SLOTHY also cannot handle the nested loop created by loading the eight-round keys.
This gave us a reason to start cleaning up the loop. First, we freed up registers to permanently hold all round keys; this was possible as the optimized order of instructions required fewer temporary registers than the original code. Second, we removed the multiple exit points and the manipulation of the loop counter to handle the remaining blocks. The value of the counter always indicates the number of five-block chunks remaining in the buffer, conforming to SLOTHYs requirement; the loop ends before the handling of the remaining blocks.
Once the loop ends, we have a separate processing branch to handle each possible number of remaining blocks, from one to four; all four branches end in ciphertext stealing. This can be seen in the control flow graphs of the encrypt and decrypt algorithms (see below). Throughout the code, we maintained the constant-time design mindset; that is, branching and special processing are based not on secret data but only on public values, the input byte lengths.
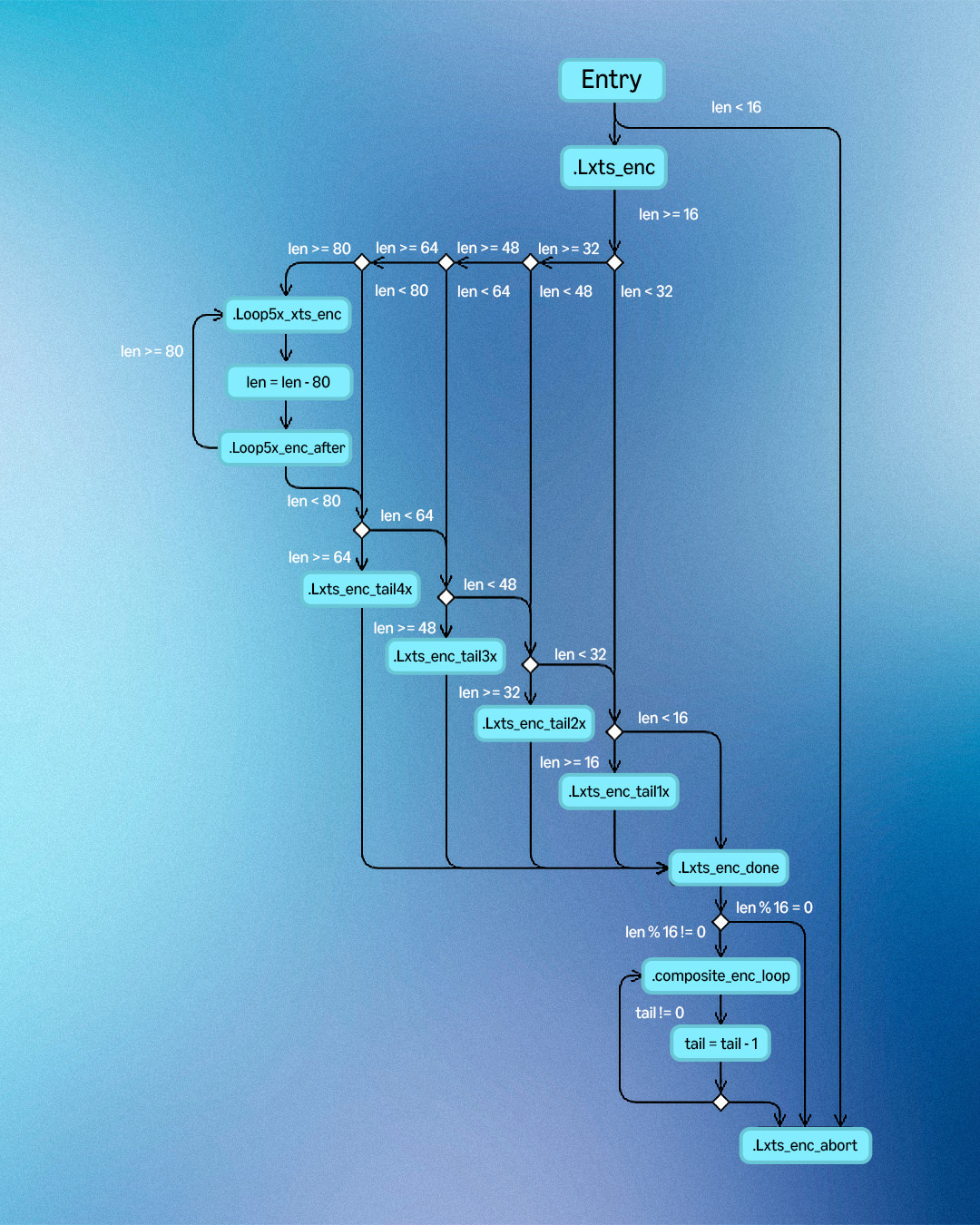 image AES-256-XTS encryption control flow graph.
image AES-256-XTS encryption control flow graph. 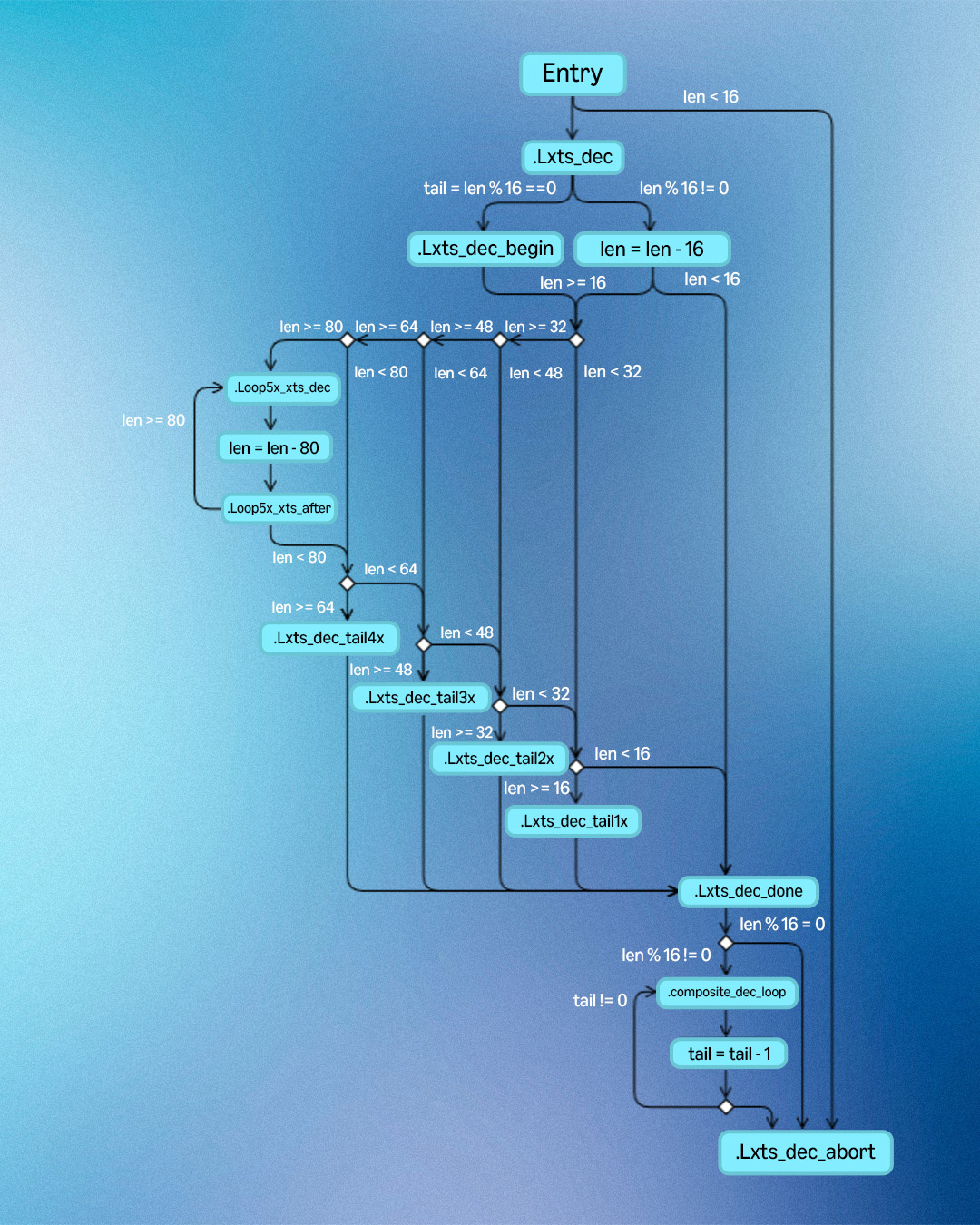 image AES-256-XTS decryption control flow graph. Performance
image AES-256-XTS decryption control flow graph. Performance
With our modifications to the code, we were able to use SLOTHY to optimize the encrypt algorithm. This resulted in slight performance gains on the AWS Graviton family of Arm processors, although the gains were smaller on the more advanced chips, which have an optimized out-of-order pipeline. Compared to the original implementation, keeping round keys in registers throughout the algorithms execution, to save on loading them from memory, allowed us to offset the effects of not interleaving the AES instructions with other ones.
Having a cleaner flow of instructions in the loop and modular exit processing allowed us to experiment with various unrolling factors for the loop iterations. We experimented with 3x, 4x, and 6x factors and concluded that 5x is still the best choice across various microarchitectures.
Ensuring correctness through formal verification
To deploy optimized cryptographic code in production, we need mathematical certainty that it works correctly. While random testing quickly checks simple cases, we rely on formal verification to deliver the highest level of assurance for our AES-XTS implementation.
To prove that our implementation matches the IEEE 1619 specification, we use HOL Light, an interactive theorem prover developed by our colleague John Harrison. HOL Light is a particularly simple implementation of the "correct by construction" approach to software development, in which code is verified as its written. HOL Lights trusted kernel is just a few hundred lines of code, which implements basic logical inference rules. This means that even if there's a bug in our proof tactics or automation, it cannot cause HOL Light to accept an incorrect proof. At worst, a bug prevents us from completing a proof, but it cannot make a false statement provable.
We chose HOL Light for several reasons specific to AES-XTS verification:
Assembly-level verification: We write our implementations directly in assembly rather than relying on compiled code. While more challenging, this makes our proofs independent of any compiler. HOL Light reasons directly about machine code bytes using CPU instruction specifications, providing assurance at the lowest level of the software stack.
Existing cryptographic infrastructure: S2n-bignum already provides extensive support for cryptographic verification, including symbolic simulation that strips away execution artifacts and leaves purely mathematical problems, specialized tactics for word operations, and byte list handling. We add proven lemmas about AES operations that we can reuse for the proofs of other AES modes.
Complex control flow handling: Unlike fully automated provers that might fail on complex proofs without enough explanation, HOL Light's interactive approach lets us guide proofs through the intricate invariants required for our 5x-unrolled loops, processing arbitrarily long blocks of data and performing the complex memory reasoning required by variable-length inputs and partial blocks.
Using s2n-bignum to implement AES-XTS serves two purposes: it's both a framework for formally verifying assembly code in x86-64 and Arm architectures and a collection of fast, verified assembly functions for cryptography. The library already contains verified implementations of numerous cryptographic algorithms, especially those pertaining to big-number mathematical operations (hence the name), which are the foundation of public-key cryptographic primitives. For details on how HOL Light was used to prove public-key algorithms as part of s2n-bignum, please refer to the previous Amazon Science blog posts Formal verification makes RSA faster and faster to deploy and Better-performing 25519 elliptic-curve cryptography.
As we mentioned, AES-XTS is one of the modes of the AES block cipher. AES is based on a substitution-permutation network (SPN) structure, which combines substitution operations (SubBytes using the S-box), permutation operations (ShiftRows, MixColumns), and key mixing. By expanding s2n-bignum to include the AES instruction set architecture (ISA) found in Arm64 and x86_64 processors, specifications for the AES block cipher, and additional specifications for AES-XTS, we're paving the way for the same rigorous verification of more AES-based algorithms.
The SPN nature of AES and the modes that are based on it cannot be expressed using simple mathematical formulae such as modular multiplication, which is fundamental to public-key cryptography that can be innately understood by a theorem prover. They require writing descriptions of the steps for processing the data. This is why, before verifying the assembly, we needed confidence that our HOL Light specification accurately captured the IEEE standard.
We wrote the specification to mirror the standard's structure, using byte lists for input/output and 128-bit words for internal block operations. Then we developed conversions, HOL Light functions that we used to evaluate specifications with concrete inputs while generating proofs that the evaluations are mathematically correct.
We validated our specification by conducting unit tests that cover different AES-XTS encryption/decryption scenarios, exercising the processing of all blocks (using recursion) and ciphertext stealing.
These tests confirmed that our specification matched the IEEE standard before we tackled the more complex assembly verification. This two-phase approach first ensuring that the specification is correct through testing, then formally verifying that the implementation matches the specification gave us confidence we were proving the right thing.
Our proofs are compositional, meaning they break the overall problem into subproblems that can be proved separately. Depending on the subproblem, the subproofs can be bounded true only for a range of inputs or unbounded.
For inputs with fewer than five (or six, in the case of decrypt) blocks, we wrote bounded proofs that exhaustively verify each case. For inputs with five (six, in the case of decrypt) or more blocks, we developed loop invariants mathematical statements that remain true throughout loop execution to prove correctness for arbitrarily long inputs. The loop invariants track three critical factors until the loop exit condition is met: register states at each iteration, the evolution of "tweaks" (which make each block's encryption unique), and memory contents as blocks are processed. For partial-block (tail) handling, we proved a separate theorem for ciphertext stealing that could be reused across all cases.
The top-level correctness theorem composes all proofs together, asserting the following statement:
Most recently, s2n-bignum was equipped with new functions and tactics for formally defining the constant-time and memory safety properties of assembly functions. With these resources, many assembly subroutines in s2n-bignum were verified to be constant time and memory safe, including top-level scalar-multiplication functions in elliptic curves, big-integer arithmetic for RSA, and the Arm implementation of the ML-KEM cryptography standard (the subject of a forthcoming blog post on Amazon Science). All assembly subroutines identified for use in AWS-LC as of October 2025 were formally verified to be constant time and memory safe.
We are exploring whether the new tactics can easily be used to verify assembly subroutines that have subsequently been added, such as AES-XTS. As we mentioned, AES-XTS has a remarkably complex control flow, which resulted in a long and involved functional-correctness proof. That complexity is also a challenge for safety proofs. The process is ongoing, but we have already proved safety properties for the ciphertext-stealing subroutines of the decryption and encryption algorithms.
These first proofs focused on crucial memory access procedures that are prone to buffer overread. Proofs for the remaining parts of the decryption and encryption algorithms can use the same methodology, where the constant-time and memory-safety proofs follow the same structure as the functional-correctness proofs but are simpler, since their proof goal is more focused.
We've integrated formal verification into s2n-bignum's continuous-integration (CI) workflow. This provides assurance that no changes to our AES-XTS implementation can be committed without successfully passing a formal proof of correctness. As part of CI, the CPU instruction modeling is validated through randomized testing against real hardware, "fuzzing out" inaccuracies to ensure our specifications are correct and the proofs hold in practice.
Furthermore, the proof guarantees correctness for all possible inputs, since theyre represented in the proof as symbols. This overcomes the typical shortcoming of coverage testing, which may cover all paths of the code but may not be able to cover all input values. For example, a constant-time code, like the one used here, is written without branching on secret values. Typically, then, secret values are incorporated into the operation through the use of masks derived from them. The same instructions are executed irrespective of the secret value. Hence, achieving line coverage is usually within the reach of a developer, but achieving value coverage is left to the formal verification of correctness.
This same methodology has enabled AWS to deploy optimized cryptographic implementations with mathematical guarantees of correctness while achieving significant performance improvements. This allows the developer and tools to further optimize the code freely without worrying about introducing bugs, since these will be automatically caught by the proof. Our experience with AES-XTS shows that proof-driven development of assembly code yields a control flow that is easier to understand, review, maintain, and optimize while never ceasing to be provably correct.
Why HOL Light for AES-XTS?The s2n-bignum frameworkDeveloping and testing the specificationThe proof strategyMemory safety and constant-time proofsContinuous assurance of correctness
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み