Amazon BedrockとAmazon Nova Reelを用いたビデオ生成のためのRAG活用
AWSはAmazon BedrockとNova Reelを活用し、OpenSearchによる画像検索とプロンプトを組み合わせたVRAGパイプラインを公開した。
キーポイント
VRAGパイプラインの設計
動画生成モデルの事前学習知識に依存する課題に対し、画像ライブラリを参照元とするVRAGマルチモーダルパイプラインを開発した。
AWSサービス連携の自動化
Amazon Bedrock、Nova Reel、OpenSearchベクトルエンジン、S3を統合し、画像取得からバッチ動画生成までを自動化した。
構造化プロンプトによるバッチ処理
テキストファイルからテンプレートを読み込み、複数の動画生成リクエストを一度に実行可能なスケーラブルな基盤を提供する。
影響分析・編集コメントを表示
影響分析
本記事は、動画生成AIの「事前学習知識への依存」という根本課題を、RAGアーキテクチャで解決する実用的なパターンを示した。これにより、企業はカスタム動画生成のハードルを下げつつ、コンテンツの正確性と制御性を両立できる。今後はVRAGが標準的な動画生成ワークフローの一つとして定着し、マルチモーダルAIの実装基準を再定義する可能性がある。
編集コメント
AWS公式ブログという性質上、自社サービスの紹介色は否めないが、技術構成とワークフローの記述は具体的で再現性が高い。実装前にOpenSearchのベクトルインデックス品質とNova Reelの出力制約を評価する必要がある。
高品質なカスタムビデオの生成は依然として大きな課題であり、これはビデオ生成モデルが事前学習された知識に制限されているためです。この限界は、広告、メディア制作、教育、ゲームなどの業界に影響を与えており、これらの分野ではビデオ生成のカスタマイズと制御が不可欠です。
これに対処するため、私たちは構造化テキストを画像ライブラリを参照として用いて個別のビデオに変換する Video Retrieval Augmented Generation (VRAG) 多モーダルパイプラインを開発しました。Amazon Bedrock、Amazon Nova Reel、Amazon OpenSearch Service vector engine(ベクトルエンジン)、および Amazon Simple Storage Service (Amazon S3) を使用することで、画像検索、プロンプトベースのビデオ生成、バッチ処理を単一の自動化されたワークフローにシームレスに統合しています。ユーザーは関心のあるオブジェクトを提供し、システムはインデックス付きデータセットから最も関連性の高い画像を検索します。その後、「カメラが時計回りに回転する」などのアクションプロンプトを定義し、検索された画像と組み合わせてビデオを生成します。テキストファイルからの構造化プロンプトにより、1 回の実行で複数のビデオを生成することが可能となり、AI 支援メディア生成のためのスケーラブルで再利用可能な基盤が構築されます。
本稿では、VRAG を通じた動画生成のアプローチについて探ります。これは、自然言語のテキストプロンプトと画像を変換し、根拠のある高品質な動画を生成するものです。この完全自動化されたソリューションにより、構造化されたテキストおよび画像入力から現実的な AI 駆動型動画シーケンスを生成でき、動画作成プロセスを効率化できます。
ソリューション概要
本ソリューションは、構造化されたテキストプロンプトを受け取り、最も関連性の高い画像を取得し、Amazon Nova Reel を用いて動画生成を行うように設計されています。このソリューションは、複数のコンポーネントをシームレスなワークフローに統合しています:
- イメージの検索と処理 – ユーザーは関心のあるオブジェクト(例:"青空")を提供し、本ソリューションは OpenSearch ベクトルエンジンにクエリを送信して、事前インデックス化された画像とその説明文を含む indexed データセットから最も関連性の高い画像を取得します。取得した最も関連性の高い画像は S3 バケットから読み出されます。
- プロンプトベースの動画生成 – ユーザーはアクションプロンプト(例:"カメラが下へパンする")を定義し、これと取得した画像を組み合わせて Amazon Nova Reel を使用して動画を生成します。
- 複数プロンプトに対するバッチ処理 – ソリューションは prompts.txt からテキストテンプレートのリストを読み込みます。このファイルにはプレースホルダーが含まれており、構造化されたバリエーションを備えた複数の動画生成リクエストのバッチ処理を可能にします:
– 検索されたオブジェクトで動的に置換されます。
- – カメラの動きやシーンのアクションで動的に置換されます。
- モニタリングと保存 – 動画生成は非同期で行われるため、ソリューションはジョブの状態を監視します。完了すると、動画は S3 バケットに保存され、自動的にダウンロードされてプレビューが可能になります。生成された動画はノートブックに表示され、対応するプロンプトがキャプションとして表示されます。
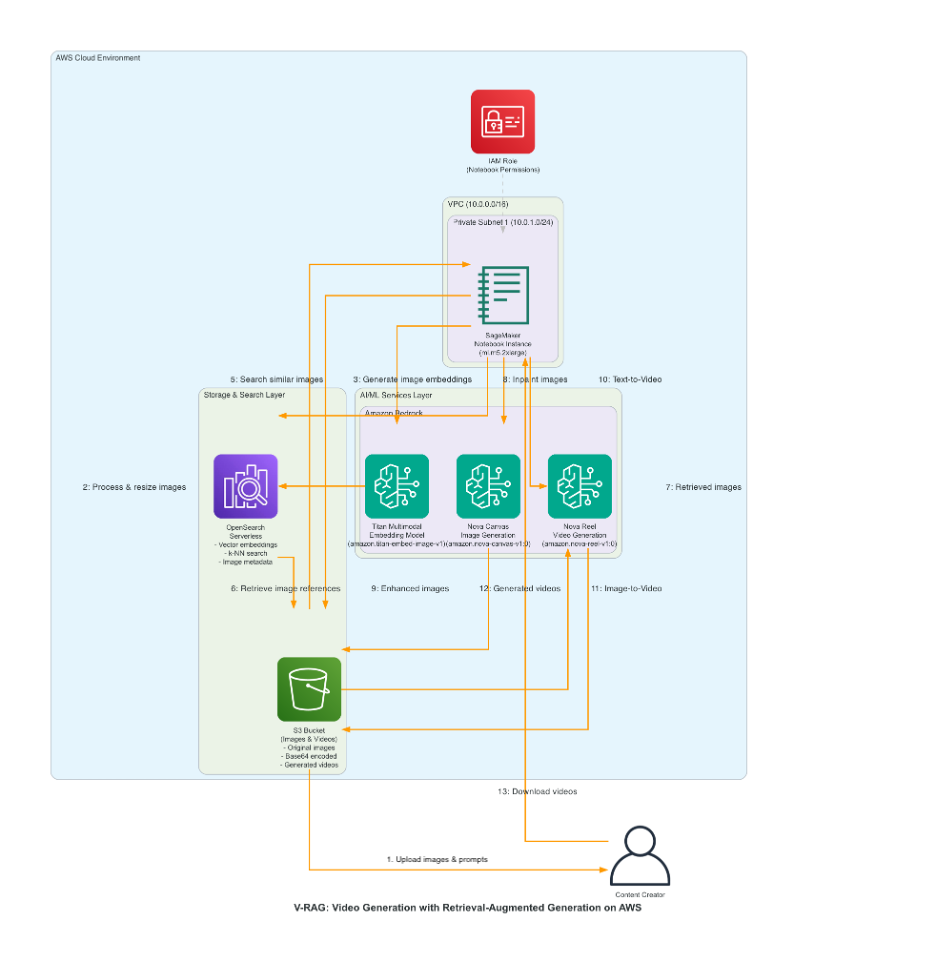
以下の図は本ソリューションのアーキテクチャを示しています。
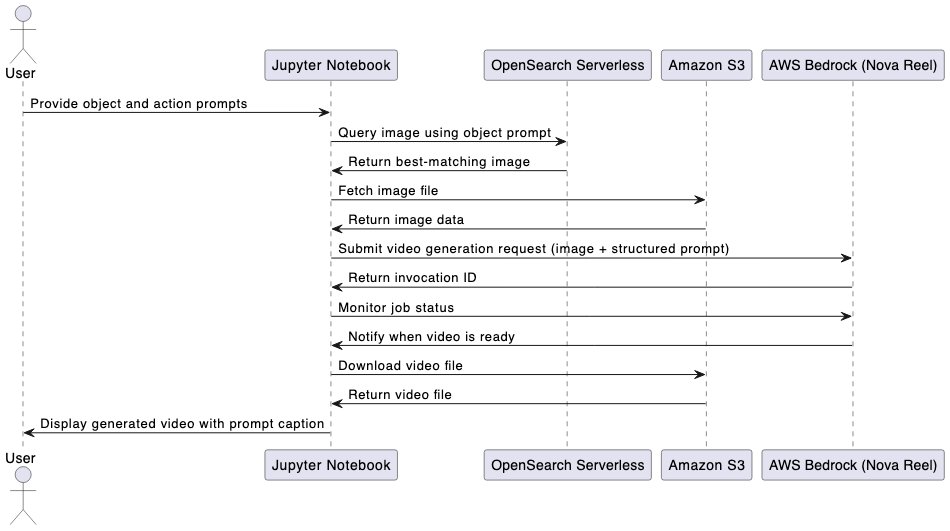
以下の図は、Jupyter ノートブックを使用したエンドツーエンドのワークフローを示しています。
このソリューションは、以下のユースケースに対応できます:
- 教育用動画 – 専門知識ベースから関連画像を抽出して、自動的に指導用動画を生成する
- マーケティング用動画 – 特定の人口統計や製品機能に合致する画像を抽出し、ターゲットを絞った広告動画を制作する
- パーソナライズされたコンテンツ – ユーザーの具体的な興味に基づいて画像を取得し、個人向けに動画コンテンツをカスタマイズする
次のセクションでは、各コンポーネントの詳細、その動作原理、およびご自身の AI ドライブ型動画ワークフローでこれをどのようにカスタマイズできるかについて解説します。
入力例
このセクションでは、Amazon Nova Reel の動画生成機能を、テキストのみを入力する方法と、テキストと画像の両方を入力する方法という 2 つの異なる入力方法を通じてデモンストレーションします。これらの例は、広告を想定したこのシナリオにおいて、入力画像を組み込むことで動画生成をさらにカスタマイズできることを示しています。当社の例では、旅行代理店が特定の場所からの美しいビーチ風景を特徴とし、カヤックへとパンすることで潜在的な休暇予約を誘発する広告を作成したいと考えています。ここでは、テキストのみを入力する方法と、静的画像を組み合わせた VRAG(Video Retrieval-Augmented Generation)を使用した場合の結果を比較します。
テキストのみ入力
テキストのみの例では、入力「青空からターコイズブルーの水に浮かぶカラフルなカヤックへと非常にゆっくりとパンダウンする」を使用します。すると、以下の結果が得られます。
##
テキストと画像の入力
同じテキストプロンプトを使用して、旅行代理店は自社の撮影地で行った特定のショットを利用できるようになります。この例では、以下の画像を使用します。

旅行代理店は、VRAG(Video RAG)を使用して既存のショットにコンテンツを追加できるようになります。使用するプロンプトは同じで、「青空からターコイズブルーの水に浮かぶカラフルなカヤックへと非常にゆっくりとパンダウンする」です。これにより、以下の動画が生成されます。

前提条件
このソリューションをデプロイする前に、以下の前提条件が整っていることを確認してください。
- 有効な AWS アカウントへのアクセス権限
- Amazon SageMaker ノートブックインスタンスの使用方法に関する知識
ソリューションのデプロイ
本記事では、AWS CloudFormation テンプレートを使用して、US East (N. Virginia) AWS リージョンにソリューションをデプロイします。Amazon Nova Reel をサポートするリージョンの一覧については、Amazon Bedrock における AWS リージョン別のモデルサポート を参照してください。以下の手順を実行してください。
- 「スタックの起動」を選択してスタックをデプロイします:
- スタック名(例:vrag-blogpost)を入力し、デプロイの手順に従ってください。
- CloudFormation コンソールで vrag-blogpost スタックを見つけ、ステータスが CREATE_COMPLETE であることを確認してください。
- SageMaker AI コンソールで、ナビゲーションペインの [Notebooks] を選択します。
- [Notebook instances] タブで、本記事用にプロビジョニングされた notebook インスタンス vrag-blogpost-notebook を見つけ、[Open JupyterLab] をクリックしてください。
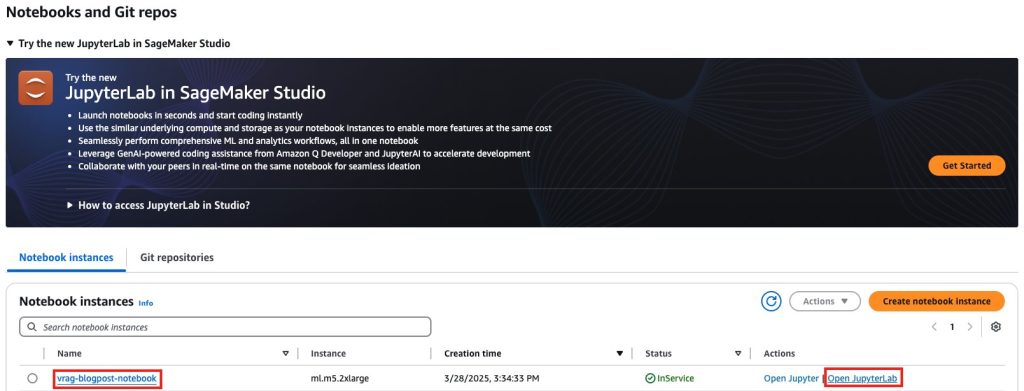
- sample-video-rag フォルダを開き、本記事に必要なノートブックを確認してください。
ノートブックの実行
本稿では、VRAG ソリューションの理解を深めるためのステップバイステップの手順と目的を示した 7 つの連続するノートブック(_00 から _06 まで)を提供しています。出力結果は本記事の例とは異なる場合があります。
画像処理(ノートブック _00)
_00_image_processing では、Amazon Bedrock、Amazon S3、SageMaker AI を使用して、以下の操作を実行します:
- 画像の処理とリサイズ
- Base64 エンコーディングの生成
- データを Amazon S3 に保存
- Amazon Nova を用いた画像説明の生成
- 結果の可視化の作成
このノートブックでは、以下の機能が示されています:
- 自動化された処理パイプライン:
バルク画像処理
- インテリジェントなリサイズと最適化
- API 互換性のための Base64 エンコーディング
- Amazon S3 による画像ストレージ
- AI 駆動型分析:
高度な画像説明生成
- コンテンツベースの画像理解
- マルチモーダル AI の統合
- 堅牢なデータ管理:
効率的なストレージ組織化
- メタデータの抽出とインデックス作成
この例では、以下の入力画像を使用します。

生成された画像キャプションとして、以下の内容が出力されます。「この画像には、白い花柄の付いた茶色のハンドバッグ、青いリボンのついた麦わら帽子、そして香水のボトルが写っています。ハンドバッグは表面に置かれており、麦わら帽子はその隣に配置されています。ハンドバッグにはストラップとチェーンが付属しており、麦わら帽子には青いリボンが巻かれています。香水のボトルはハンドバッグの隣に置かれています。」
画像取り込み(ノートブック _01)
_01_oss_ingestion.ipynb では、Amazon Bedrock(Amazon Titan Embeddings を使用して埋め込みを生成)、Amazon S3、OpenSearch Serverless(ベクトルストレージおよび検索用)、SageMaker AI(ノートブックホスティング用)を使用して、以下の処理を実行します:
- プロセスと画像のリサイズ
- ベース64エンコーディングの生成
- データをAmazon S3に保存
- Amazon Novaを使用して画像の説明を生成
- 結果の可視化を作成
このノートブックは以下の機能を示しています:
- ベクトルデータベース管理:
インデックス作成と設定
- バルクデータ取り込み
- 効率的なベクトルストレージ
- エンベディング生成:
マルチモーダルエンベディングの作成
- 次元最適化
- バッチ処理サポート
- セマンティック検索機能:
k-NN(k近傍法)検索の実装
- クエリベクトルの生成
- 結果の可視化
入力としてクエリ「Building」を使用し、以下の画像を結果として受け取ります。

画像には、関連するキャプションが出力されています:「この画像は、ガラス張りの外観を持つ複数の高層ビルを特徴とする現代的な建築シーンを描いています。これらの建物はガラスと鋼鉄を組み合わせて建設されており、すっきりとした現代的な外観を与えています。ガラスパネルは周囲の環境、つまり空や他の建物などを反射し、光と反射のダイナミックな相互作用を生み出しています。上空の空は部分的に雲がかかっており、青い部分がいくつか見えますが、これは晴れた日でありながら一部に雲があることを示唆しています。建物は背が高く細身で、ガラスパネルや鋼鉄フレームワークの構造によって縦線が強調されています。ガラス表面の反射には周囲の建物や空が映り込み、画像に奥行きを加えています。全体的な印象は、近代性、効率性、そして都市的な洗練さです。」
テキストのみからの動画生成(ノートブック _02)
_02_video_gen_text_only.ipynb では、Amazon Bedrock(Amazon Nova Reel にアクセスするため)と SageMaker AI(ノートブックのホスティング用)を使用して、以下の操作を実行します:
- テキストをプロンプトとして動画生成のためのリクエストペイロードを構築する
- Amazon Bedrock を使用して非同期ジョブを開始する
- 進捗を追跡し、完了するまで待機する
- 生成された動画を Amazon S3 から取得し、ノートブック内でレンダリングする
このノートブックでは、以下の機能を示しています:
- テキストを入力として動画生成を自動化する処理
- 観測可能性を備えた大規模な動画生成
入力プロンプトには「砂の中の大きな貝のクローズアップ、穏やかな波が貝の周りを流れる。カメラがズームインする。」を使用します。出力として以下の生成された動画を受信します。

テキストおよび画像プロンプトからの動画生成(ノートブック _03)
_03_video_gen_text_image.ipynb では、Amazon Bedrock(Amazon Nova Reel にアクセスするため)と SageMaker AI(ノートブックのホスティング用)を使用して、以下の操作を実行します:
- テキストと画像をプロンプトとして動画生成するためのリクエストペイロードを構築する
- Amazon Bedrock を使用して非同期ジョブを開始する
- 進捗を追跡し、完了まで待機する
- 生成された動画を Amazon S3 から取得し、ノートブック内でレンダリングする
このノートブックは以下の機能を示しています:
- テキストと画像を入力として動画生成を自動化する処理
- 観測可能性を備えた大規模な動画生成
入力にはプロンプト「道路から空へとカメラが上向きに傾く」と、以下の画像を使用します。

出力として以下の生成された動画を受信します。

多モーダル入力からの動画生成(ノートブック _04)
_04_video_gen_multi.ipynb では、Amazon Bedrock(Amazon Nova Reel にアクセスするため)と SageMaker AI(ノートブックのホスティング用)を使用して、以下の操作を実行します:
- 入力プロンプトの埋め込みベクトルを生成し、OpenSearch Serverless のベクトルコレクションインデックスを検索する
- テキストと取得した画像を組み合わせて動画を生成する
このノートブックは、以下の機能を示しています:
- VRAG プロセス
- 観測可能性を備えた大規模な動画生成
入力として次のプロンプトを使用します。「降り積もる雪の下に置かれた赤い靴の、清潔で映画のようなショット。周囲は静寂と静止に包まれている。」
これに対して、以下の動画を出力として受け取ります。

画像のインペインティングによる更新(ノートブック _05)
_05_inpainting.ipynb では、Amazon Bedrock(Amazon Nova Reel にアクセスするため)と SageMaker AI(ノートブックのホスティング用)を使用して、以下の操作を実行します:
- ベース 64 形式の画像を読み取る
- インペインティングを用いて画像を生成する
このノートブックは、以下の機能を示しています:
- 周囲の文脈とプロンプトに基づいて画像の一部を置き換えたり選択したりする
- 不要なオブジェクトを削除し、画像の一部を修正するか、画像の特定の領域を創造的に変更する
強化された画像を用いた動画生成(ノートブック _06)
_06_video_gen_inpainting.ipynb では、Amazon Bedrock(Amazon Nova Reel にアクセスするため)と SageMaker AI(ノートブックのホスティング用)を使用して、以下の操作を実行します:
- 自然言語クエリを用いて OpenSearch Service で関連する画像を検索する
- 明示的な画像マスクを使用して、インペイントを行う領域を定義する
- 強化された画像を用いて動画を生成する
このノートブックでは、以下の機能を示しています:
- インペイントを用いて画像を生成する
- 強化された画像を用いて動画を生成する
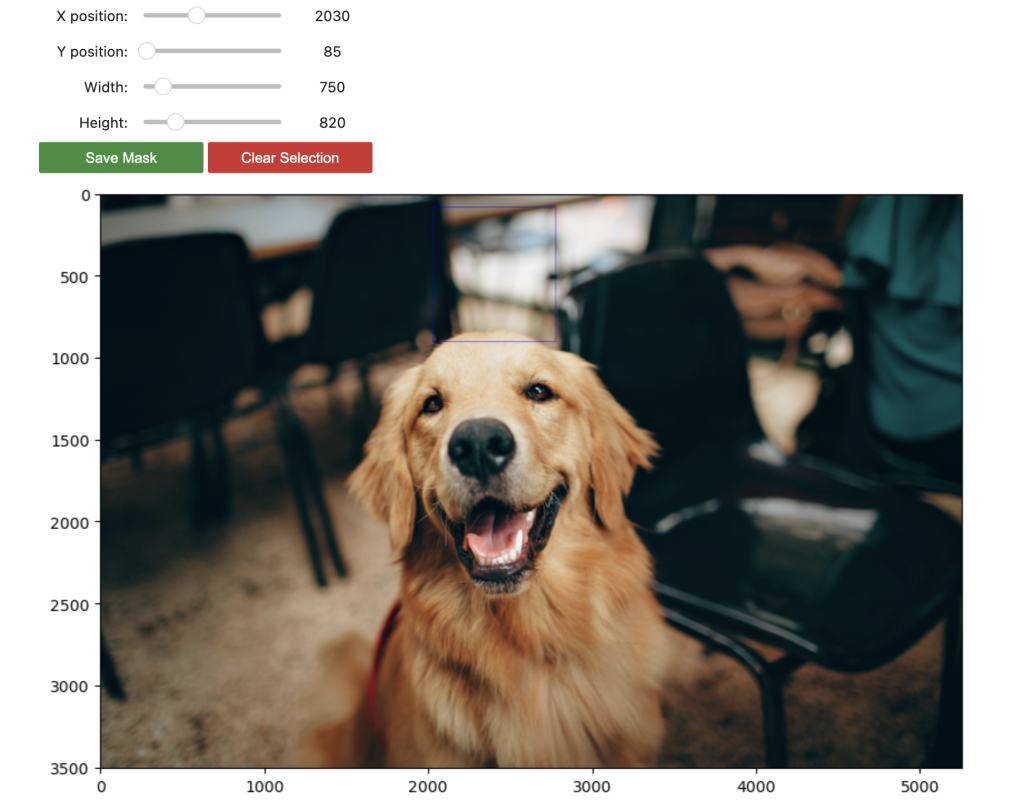
以下に示すスクリーンショットは、インペイントに使用する画像とマスクです。
以下に示すスクリーンショットは、出力として受け取る生成された画像(few-shot)です。

生成された画像から、以下の動画が出力として得られます。

ベストプラクティス
効率的な AI ビデオ生成プロセスには、データ管理、検索最適化、コンプライアンス対策のシームレスな統合が必要です。このプロセスは、高品質な入力データを処理しつつ、信頼性の高い処理のために最適化された OpenSearch 検索と Amazon Bedrock の統合を維持しなければなりません。適切な Amazon S3 の管理とユーザーエクスペリエンス機能の強化が円滑な運用を可能にし、
(注:入力テキストが途中で切れているため、翻訳も同様に途中までとなります。原文の構造と空行は保持されています。)
原文を表示
Generating high-quality custom videos remains a significant challenge, because video generation models are limited to their pre-trained knowledge. This limitation affects industries such as advertising, media production, education, and gaming, where customization and control of video generation is essential.
To address this, we developed a Video Retrieval Augmented Generation (VRAG) multimodal pipeline that transforms structured text into bespoke videos using a library of images as reference. Using Amazon Bedrock, Amazon Nova Reel, the Amazon OpenSearch Service vector engine, and Amazon Simple Storage Service (Amazon S3), the solution seamlessly integrates image retrieval, prompt-based video generation, and batch processing into a single automated workflow. Users provide an object of interest, and the solution retrieves the most relevant image from an indexed dataset. They then define an action prompt (for example, “Camera rotates clockwise”), which is combined with the retrieved image to generate the video. Structured prompts from text files allow multiple videos to be generated in one execution, creating a scalable, reusable foundation for AI-assisted media generation.
In this post, we explore our approach to video generation through VRAG, transforming natural language text prompts and images into grounded, high-quality videos. Through this fully automated solution, you can generate realistic, AI-powered video sequences from structured text and image inputs, streamlining the video creation process.
Solution overview
Our solution is designed to take a structured text prompt, retrieve the most relevant image, and use Amazon Nova Reel for video generation. This solution integrates multiple components into a seamless workflow:
- Image retrieval and processing – Users provide an object of interest (for example, “blue sky”) and the solution queries the OpenSearch vector engine to retrieve the most relevant image from an indexed dataset, which contains pre-indexed images and descriptions. The most relevant image is retrieved from an S3 bucket.
- Prompt-based video generation – Users define an action prompt (for example, “Camera pans down”), which is combined with the retrieved image to generate a video using Amazon Nova Reel.
- Batch processing for multiple prompts – The solution reads a list of text templates from prompts.txt, which contain placeholders to enable batch processing of multiple video generation requests with structured variations:
– Dynamically replaced with the queried object.
- – Dynamically replaced with the camera movement or scene action.
- Monitoring and storage – The video generation is asynchronous, so the solution monitors the job status. When it’s complete, the video is stored in an S3 bucket and automatically downloaded for preview. The generated videos are displayed in the notebook, with the corresponding prompt shown as a caption.
The following diagram illustrates the solution architecture.
The following diagram illustrates the end-to-end workflow using a Jupyter notebook.
This solution can serve the following use cases:
- Educational videos – Automatically creating instructional videos by pulling relevant images from a subject matter knowledge base
- Marketing videos – Creating targeted video ads by pulling images that align with specific demographics or product features
- Personalized content – Tailoring video content to individual users by retrieving images based on their specific interests
In the following sections, we break down each component, how it works, and how you can customize it for your own AI-driven video workflows.
Example input
In this section, we demonstrate the video generation capabilities of Amazon Nova Reel through two distinct input methods: text-only and text and image inputs. These examples illustrate how video generation can be further customized by incorporating input images, in this scenario for advertising. For our example, a travel agency wants to create an advertisement featuring a beautiful beach scene from a specific location and panning to a kayak to entice potential vacation bookings. We compare the results of using a text-only input approach vs. VRAG with a static image to achieve this goal.
Text-only input
For the text-only example, we use the input “Very slow pan down from blue sky to a colorful kayak floating on turquoise water.” We get the following result.
###
Text and image input
Using the same text prompt, the travel agency can now use a specific shot they took at their location. For this example, we use the following image.
Travel agency can now add content into their existing shot using VRAG. They use the same prompt: “Very slow pan down from blue sky to a colorful kayak floating on turquoise water.” This generates the following video.
Prerequisites
Before you deploy this solution, make sure the following prerequisites are in place:
- Access to a valid AWS account
- Familiarity with Amazon SageMaker notebook instances
Deploy the solution
For this post, we use an AWS CloudFormation template to deploy the solution in the US East (N. Virginia) AWS Region. For a list of Regions that support Amazon Nova Reel, see Model support by AWS Region in Amazon Bedrock. Complete the following steps:
- Choose Launch Stack to deploy the stack:
- Enter a name for the stack, such as vrag-blogpost, and follow the steps to deploy.
- On the CloudFormation console, locate the vrag-blogpost stack and confirm that its status is CREATE_COMPLETE.
- On the SageMaker AI console, choose Notebooks in the navigation pane.
- On the Notebook instances tab, locate the notebook instance vrag-blogpost-notebook provisioned for this post and chose Open JupyterLab.
- Open the folder sample-video-rag to view the notebooks needed for this post.
Run notebooks
We have provided seven sequential notebooks, numbered from _00 to _06, with step-by-step instructions and objectives to help you build your understanding of a VRAG solution. Your output might vary from the examples in this post.
Image processing (notebook _00)
In _00_image_processing, you use Amazon Bedrock, Amazon S3, and SageMaker AI to perform the following actions:
- Process and resize images
- Generate Base64 encodings
- Store data in Amazon S3
- Generate image descriptions using Amazon Nova
- Create a visualization of the results
This notebook illustrates the following capabilities:
- Automated processing pipeline:
Bulk image processing
- Intelligent resizing and optimization
- Base64 encoding for API compatibility
- Amazon S3 storage of images
- AI-powered analysis:
Advanced image description generation
- Content-based image understanding
- Multi-modal AI integration
- Robust data management:
Efficient storage organization
- Metadata extraction and indexing
For this example, we use the following input image.
We receive the following generated image caption as output: “The image features a brown handbag with white floral patterns, a straw hat with a blue ribbon, and a bottle of perfume. The handbag is placed on a surface, and the straw hat is positioned next to it. The handbag has a strap and a chain attached to it, and the straw hat has a blue ribbon tied around it. The perfume bottle is placed next to the handbag.”
Image ingestion (notebook _01)
In _01_oss_ingestion.ipynb, you use Amazon Bedrock (with Amazon Titan Embeddings to generate embeddings), Amazon S3, OpenSearch Serverless (for vector storage and search), and SageMaker AI (for notebook hosting) to perform the following actions:
- Process and resize images
- Generate base64 encodings
- Store data in Amazon S3
- Generate image descriptions using Amazon Nova
- Create visualization of the results
This notebook illustrates the following capabilities:
- Vector database management:
Index creation and configuration
- Bulk data ingestion
- Efficient vector storage
- Embedding generation:
Multi-modal embedding creation
- Dimension optimization
- Batch processing support
- Semantic search capabilities:
k-NN search implementation
- Query vector generation
- Result visualization
For our input, we use the query “Building” and receive the following image as a result.
The image has the associated caption as output: “The image depicts a modern architectural scene featuring several high-rise buildings with glass facades. The buildings are constructed with a combination of glass and steel, giving them a sleek and contemporary appearance. The glass panels reflect the surrounding environment, including the sky and other buildings, creating a dynamic interplay of light and reflections. The sky above is partly cloudy, with patches of blue visible, suggesting a clear day with some cloud cover. The buildings are tall and narrow, with vertical lines emphasized by the structure of the glass panels and steel framework. The reflections on the glass surfaces show the surrounding buildings and the sky, adding depth to the image. The overall impression is one of modernity, efficiency, and urban sophistication.”
Video generation from text only (notebook _02)
In _02_video_gen_text_only.ipynb, you use Amazon Bedrock (to access Amazon Nova Reel) and SageMaker AI (for notebook hosting) to perform the following actions:
- Construct the request payload for video generation with text as prompt
- Initiate an asynchronous job using Amazon Bedrock
- Track progress and wait until completion
- Retrieve the generated video from Amazon S3 and render it in the notebook
This notebook illustrates the following capabilities:
- Automated processing of video generation with text as input
- Video generation at scale with observability
We use the following input prompt: “Closeup of a large seashell in the sand, gentle waves flow around the shell. Camera zoom in.”We receive the following generated video as output.
Video generation from text and image prompts (notebook _03)
In _03_video_gen_text_image.ipynb, you use Amazon Bedrock (to access Amazon Nova Reel) and SageMaker AI (for notebook hosting) to perform the following actions:
- Construct the request payload for video generation with text and image as prompt
- Initiate an asynchronous job using Amazon Bedrock
- Track progress and wait until completion
- Retrieve the generated video from Amazon S3 and render it in the notebook
This notebook illustrates the following capabilities:
- Automated processing of video generation with text and image as input
- Video generation at scale with observability
We use the prompt “camera tilt up from the road to the sky” and the following image as input.
We receive the following generated video as output.
Video generation from multi-modal inputs (notebook _04)
In _04_video_gen_multi.ipynb, you use Amazon Bedrock (to access Amazon Nova Reel) and SageMaker AI (for notebook hosting) to perform the following actions:
- Generate embedding for input prompt and search the OpenSearch Serverless vector collection index
- Combine text and retrieved images to generate videos
This notebook illustrates the following capabilities:
- The VRAG process
- Video generation at scale with observability
We use the following prompt as input: “A clean cinematic shot of red shoes placed under falling snow, while the environment stays silent and still.”We receive the following video as output.
Update images with in-painting (notebook _05)
In _05_inpainting.ipynb, you use Amazon Bedrock (to access Amazon Nova Reel) and SageMaker AI (for notebook hosting) to perform the following actions:
- Read base 64 image
- Generate images with in-painting
This notebook illustrates the following capabilities:
- Replace and select regions of an image based on surrounding context and prompts
- Remove unwanted objects and fix portions of images or creatively modify specific areas of an image
Generate videos with enhanced images (notebook _06)
In _06_video_gen_inpainting.ipynb, you use Amazon Bedrock (to access Amazon Nova Reel) and SageMaker AI (for notebook hosting) to perform the following actions:
- Search for relevant images in OpenSearch Service using natural language queries
- Use explicit image masks to define areas for in-painting
- Generate videos using enhanced images
This notebook illustrates the following capabilities:
- Use in-painting to generate an image
- Generate a video using the enhanced image
The following screenshot shows the image and mask we use for in-painting.
The following screenshot shows the generated images (few-shot) we receive as output.
From the generated image, we receive the following video as output.
Best practices
An efficient AI video generation process requires seamless integration of data management, search optimization, and compliance measures. The process must handle high-quality input data while maintaining optimized OpenSearch queries and Amazon Bedrock integration for reliable processing. Proper Amazon S3 management and enhanced user experience features facilitate smooth operation, and strict adherence to <a href="https://digital-strategy.ec.europa.eu/
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み