コスト最適化されたドキュメント処理のために Amazon Nova 2 Lite と Claude を組み合わせる方法
AWS は、Amazon Nova 2 Lite と Anthropic の Claude Sonnet 4.6 を組み合わせることで、スキャン文書からの名面孔対応処理をコスト約 3 分の 1 に削減する実証済みのパイプラインを発表した。
キーポイント
2 モデル構成による最適化
画像検出・文字抽出に特化した Amazon Nova 2 Lite と、空間推論に優れた Claude Sonnet 4.6 を連携させることで、単一モデルでの処理よりも効率的なパイプラインを構築している。
顕著なコスト削減効果
336 ページの年次誌データで検証した結果、1 ページあたりのコストが単一ビジョン言語モデルを使用する場合と比較して約 3 分の 2(33%)に削減された。
高精度な名面孔対応
ページレイアウトに基づく空間推論により、93% のケースで信頼度スコア 0.95 以上の精度で名前と顔の対応付けを実現した。
単一 API 呼び出しによる多機能処理
Nova 2 Lite を使用すると、1 つの API 呼び出しで写真検出、名前と位置情報の抽出、構造化メタデータの生成を同時に行うことができます。
Claude と Nova の連携による空間推論
Nova が取得した座標データを Claude に渡すことで、両者が同じ 0–1000 の座標系を使用しているため正規化不要で、名前と顔を正確にマッチングさせることができます。
構造化データによる高度な活用
抽出されたメタデータは検索インデックスの構築やイベントタイプごとのフィルタリング、数百ページにわたる目次作成などに直接利用可能です。
高信頼度の名前と顔の紐付け
336ページの年次誌を処理した結果、93.3%の関連付けが0.95以上の信頼スコアを獲得し、特に肖像グリッドページで高い精度を発揮しました。
影響分析・編集コメントを表示
影響分析
このアプローチは、大規模な文書デジタル化プロジェクトにおいて、高コストな単一モデル依存からの脱却を示す重要な指標です。特定のタスクに特化した軽量モデルと推論能力の高いモデルを段階的に連携させる「モデルの分業」戦略が、実務レベルで明確な ROI(投資対効果)を生むことを証明しており、業界全体のパイプライン設計におけるベストプラクティスとして定着する可能性があります。
編集コメント
単一モデルで全てを解決しようとする従来のアプローチから、タスクを分解して最適なモデルを組み合わせる「分業型」アーキテクチャへの転換を示す実例です。コスト削減効果が明確であるため、大規模データ処理の現場での即座の実装が期待されます。
スキャンされた年鑑のページには、176 の印刷された名前と 4 つの肖像写真が含まれていますが、これらをリンクする機械可読な構造は存在しません。このページをデジタル化するには、バウンディングボックス付きの信頼性の高い写真検出機能と、正確な名前の抽出が必要です。また、ページのレイアウトに基づいて、どの名前がどの顔に対応するかを判断する方法も必要です。
本稿では、Amazon Nova 2 Lite と Anthropic の Claude Sonnet 4.6 を組み合わせることで、スキャンされた文書を大規模にデジタル化する効率的なソリューションを実現できることを示します。私たちは、スキャンされた年鑑のページをデジタル化するために、Amazon Bedrock 上で 2 つのモデルからなるパイプラインを構築しました。Amazon Nova 2 Lite は、単一の呼び出しでネイティブなマルチモーダル抽出を行い、写真の検出、座標付きの可視名前の抽出、およびページレベルのメタデータの返却を担当します。その後、Claude Sonnet 4.6 がページのレイアウトに基づいて名前と顔を空間推論によってマッチングさせます。
このパイプラインを 336 ページのスキャンされた年鑑に対して実行した結果、93% のケースで信頼度が 0.95 以上となり、合計 3,122 の「名前と顔の対応付け」が生成されました。この 2 モデルアプローチは、単一のビジョン・ランゲージモデルにすべてのタスクを任せる単一モデルのアプローチと比較して、ページあたりのコストが約 3 分の 2 削減されます。詳細な内訳については「コストに関する考慮事項」セクションをご覧ください。
ソリューションの概要
このパイプラインには 2 つのステージがあります。各ステージでは、特定のタスクに最適化された異なるモデルが使用されます。
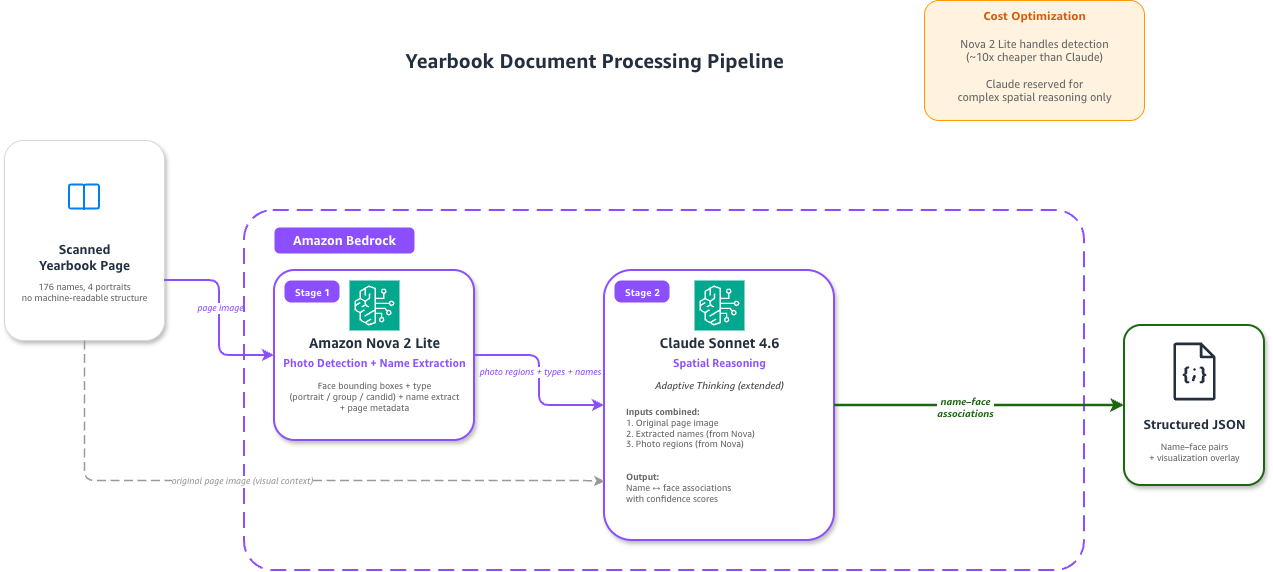
図 1. 2 モデルパイプラインアーキテクチャ。スキャンされたページ画像は、2 つの連続するステージを流れます。ステージ 1 では、Amazon Nova 2 Lite が単一の API コールでネイティブなマルチモーダル抽出を実行します。これは、境界ボックス付きで写真を検出・分類し、ページ上の可視名を読み取ってその概略位置を返すとともに、ページレベルのメタデータを出力します。ステージ 2 では、Claude Sonnet 4.6 が空間推論を行い、Nova の出力を組み合わせて名前と顔をマッチングさせます。
Amazon Nova 2 Lite が最初に実行されます。テキストと画像をネイティブに扱うため、単一の Converse コールで以下の 3 つが返されます:
- 境界ボックスと分類が付いた検出された写真。
- 概略位置付きでページ上に表示されている名前。
- タイトルやカテゴリなどのページレベルのメタデータ。
このタスクでは、Converse API コールに推論設定を含めることで、推論をLOW(低)に設定しています。後続するステップ 1 のコードにある推論ブロックをご参照ください。336 ページすべてでテストした結果、この構造化抽出においては、LOW、MEDIUM(中)、HIGH(高)の各推論レベル間で意味のある精度差は見られず、LOWが最もコスト効率が良いオプションです。Nova はこの設定を reasoning_config フィールドを通じて公開しています。一方、Claude はステップ 2 で thinking フィールドを使用するため、両モデルは異なる名称で推論制御を行います。
*Nova 2 Lite* にページ上のすべての OCR トークンを求めるのではなく、名前だけを求めることが、第一段階を低コストに保つ鍵です。後段の空間推論ステップでは、学級名簿や行事説明の全文は必要ありません。写真の近くに現れる名前が必要なのです。Nova の出力を名前に制限することで、1 ページあたりの出力トークンコストを、フル OCR パスで生成される約 4,500 トークンではなく、約 1,000 トークンに抑えることができます。
Claude Sonnet 4.6 は、空間推論ステップである第 2 ステージでのみ登場します。Nova から取得した名前と位置情報、および写真のバウンディングボックスを基に、Claude がどの名前がどの顔に対応するかを特定します。このステップでは、年鑑のレイアウトはページごとに異なるため、レイアウトの変動への対応が必要です。キャプションは写真の上または下に配置されることもあり、一部のページではポートレートグリッドとグループショットが混在しています。Claude の適応思考機能により、各レイアウトタイプごとの追加のプロンプトエンジニアリングなしで、こうした変動を処理できます。
本ソリューションでは、Nova 2 Lite が高ボリュームの抽出作業をネイティブで、1 つの呼び出しで処理します。空間推論ステップには、ページごとに Claude を 1 回呼び出します。
Nova 2 Lite の画像ごとの固定価格設定:スケール時の予測可能なコスト
Amazon Nova 2 Lite の画像入力に対する課金方法に関する最近の変更により、数百万ページの処理などスケールした運用において、ページ単位の費用を予測可能にすることができるようになりました。
画像ごとの固定価格設定: Amazon Nova 2 Lite は、解像度やファイルサイズに関わらず、画像およびドキュメントのページ入力に対して*1 画像あたりの固定レート*で課金します。
この変更はドキュメント処理パイプラインにとって重要な意味を持ちます。以前は画像のトークンコストが解像度によって変動するため、代表的なサンプルで概念実証を行わない限り、ページごとのコストを予測することが困難でした。固定課金方式により、Nova 2 Lite が処理するすべての画像は、解像度に関係なく同じ画像あたりのレートで課金されます。
プロンプトと出力を含む完全なページ抽出の場合、ページあたりのコスト内訳は以下の通りです。
コンポーネント
トークン/ページ
レート
コスト/ページ
画像トークン(固定)
230
$0.30/M 入力
$0.000069
プロンプトトークン(推定)
500
$0.30/M 入力
$0.000150
出力トークン(推定)
1,000
$2.50/M 出力
$0.0025
合計
約 $0.0027
公開されている Nova 2 Lite の入力トークンレートにおいて、画像入力はページあたりの総コストのごく一部を占めるに過ぎません。現在のレートについては Amazon Bedrock プライシングページ をご覧ください。
年間数十万ページの年鑑規模のワークロードの場合、この固定価格設定によりコスト予測が容易になります。画像入力コストはページ数に対して線形にスケールし、ページ解像度には依存しないためです。解像度の正規化は不要です。
空間推論のための適応的思考
Amazon Bedrock 上の Claude は、適応的思考(adaptive thinking)をサポートしています。これは、入力データの複雑さに基づいてモデルが内部で適用する推論の量を自動的に決定する機能です。Converse API の思考設定において type を adaptive に設定することで有効化できます:
response = bedrock_runtime.converse(
modelId='us.anthropic.claude-sonnet-4-6',
messages=[{
'role': 'user',
'content': [
{'image': {'format': 'jpeg', 'source': {'bytes': image_bytes}}},
{'text': spatial_reasoning_prompt}
]
}],
additionalModelRequestFields={
'thinking': {
'type': 'adaptive'
}
}
)
適応的思考を有効にすると、Claude は受け取る情報に応じて推論の深さを調整します。8 つの名前が 8 つの顔の上に整然と配置された単純なポートレートグリッドに対しては、最小限の推論で直接的な回答が返されます。一方、3 枚のグループ写真がキャプションブロックを共有し、名前がサイドバーに表示されるページでは、段階的な空間分析が行われます。
今回の 336 ページにわたる処理において、Claude はすべてのページで拡張された推論を使用しました。推論の痕跡(reasoning traces)は 544 文字から 1,658 文字の範囲でした。より単純なページであっても、年鑑のレイアウトが完全に均一であることは稀であるため、何らかの空間分析の恩恵を受けました。推論の痕跡からは、名前と顔の位置間の列アライメントや垂直オフセットを処理し、グループ写真が表示される際にはキャプションとの近接性を確認する Claude の作業プロセスがうかがえます。
この種の構造化された空間タスクにおいて、適応型思考(adaptive thinking)は、手動での調整を行わずに、ページごとに適切な推論量を提供します。固定のトークン予算を設定したり、レイアウト固有のプロンプトを作成したりする必要はありません。モデルが入力を読み取り、判断を行います。
コストに関する注意:適応型思考について 適応型思考を有効にする場合、以下の 3 つのコスト要因に留意してください。
- 推論トークンは、標準的な出力レート(Claude Sonnet 4.6 のクロスリージョン推論における出力トークン 100 万個あたり 15 ドル)で出力トークンとして請求されます。
- 推論トレースは API レスポンス内の別の思考コンテンツブロックに返されますが、エンドユーザーには表示されません。
- 実際のページあたりのコストを追跡するため、レスポンスメタデータの入力トーク数(inputTokens)と出力トーク数(outputTokens)を監視してください。複雑なページでは推論により出力トークン数が大幅に増加する可能性があるためです。
実装のウォークスルー
完全なソースコード、サンプル画像、および Jupyter ノートブックは、GitHub の AWS Samples リポジトリ で利用可能です。
前提条件
パイプラインを実行する前に、以下の準備が整っていることを確認してください:
- Amazon Nova 2 Lite と Claude Sonnet 4.6 が利用可能な AWS リージョンにおいて、Amazon Bedrock にアクセスできる AWS アカウント。
- Amazon Bedrock コンソールで、us.amazon.nova-2-lite-v1:0 および us.anthropic.claude-sonnet-4-6 の両モデルに対するアクセス権限が有効になっていること。
- 前述の 2 つのモデルに対して bedrock:InvokeModel および bedrock:Converse を呼び出す権限を持つ、AWS Identity and Access Management (IAM) プリンシパル。
- Python 3.10 以降で boto3 SDK がインストールされている環境。サンプルノートブックでは、名前の類似度マッチングに rapidfuzz を、可視化用のオーバーレイ表示に Pillow を使用しています。
- スキャンされたページ画像(JPEG または PNG)。Converse API を通じて画像を入力する場合は、リクエスト内で画像バイト列をインラインで渡します。
ステップ 1: Amazon Nova 2 Lite で写真の検出と名前の抽出
スキャンしたページを、検出された写真(バウンディングボックスおよび分類情報を含む)と表示されている名前(ページ上の概略位置を含む)の両方を要求するプロンプトと共に Amazon Nova 2 Lite に送信します。Nova のネイティブなマルチモーダル理解機能により、これらは単一の Converse 呼び出しで同時に返されます。
Nova は、写真および名前の両方に対して 0–1000 の座標スケールでバウンディングボックスを返します。これらをそのままステップ 2 に渡してください。Claude もプロンプト内で同じ座標空間を受け取るため、変換は不要です。
def extract_photos_and_names(image_bytes):
"""Amazon Nova 2 Lite を使用して写真の検出と表示されている名前の抽出を行う。"""
# Bedrock のすべての呼び出しに対して Converse API を一貫して使用する翻訳全文
各写真には境界ボックス、タイプ(ポートレート、グループ、またはスナップショット)、カテゴリタグ、および短い説明が付与されます。各名前には、ページ上の可視テキストとその境界ボックスが含まれます。page_title および category フィールドは、メタデータ抽出という第 2 のユースケースにも利用可能です。1 つの API コールで、Nova 2 Lite は写真検出、マッチングパイプライン用の位置付き名前、構造化されたメタデータを提供します。このメタデータは、検索インデックス作成、イベントタイプによるフィルタリング、または数百ページにわたる目次構築に使用できます。
ステップ 2: Claude を用いて名顔を一致させる
次に、Nova の位置付き名前と写真の境界ボックスを Claude に渡して空間推論を行います。両方とも同じ 0–1000 の座標空間を使用するため、正規化は不要です:
spatial_prompt = f"""Given these names with page coordinates:
{json.dumps(ocr_tokens)}
And these detected photos with bounding boxes:
{json.dumps(photo_detections)}
Match each person's name to their photo based on spatial position.
Return JSON: {{"associations": [{{"name": str, "face_idx": int,
"confidence": float, "reasoning": str}}]}}"""
response = bedrock_runtime.converse(
modelId='us.anthropic.claude-sonnet-4-6',
messages=[{
'role': 'user',
'content': [
{'image': {'format': 'jpeg', 'source': {'bytes': image_bytes}}},
{'text': spatial_prompt}
]
}],
additionalModelRequestFields={
'thinking': {'type': 'adaptive'}
}
)必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "各写真には境界ボックス、タイプ(ポートレート、グループ、またはスナップショット)、カテゴリタグ、および短い説明が付与されます。各名前には、ページ上の可視テキストとその境界ボックスが含まれます。page_title および category フィールドは、メタデータ抽出という第 2 のユースケースにも利用可能です。1 つの API コールで、Nova 2 Lite は写真検出、マッチングパイプライン用の位置付き名前、構造化されたメタデータを提供します。このメタデータは、検索インデックス作成、イベントタイプによるフィルタリング、または数百ページにわたる目次構築に使用できます。
ステップ 2: Claude を用いて名顔を一致させる
次に、Nova の位置付き名前と写真の境界ボックスを Claude に渡して空間推論を行います。両方とも同じ 0–1000 の座標空間を使用するため、正規化は不要です:
spatial_prompt = f"""Given these names with page coordinates:
{json.dumps(ocr_tokens)}
And these detected photos with bounding boxes:
{json.dumps(photo_detections)}
Match each person's name to their photo based on spatial position.
Return JSON: {{"associations": [{{"name": str, "face_idx": int,
"confidence": float, "reasoning": str}}]}}"""
response = bedrock_runtime.converse(
modelId='us.anthropic.claude-sonnet-4-6',
messages=[{
'role': 'user',
'content': [
{'image': {'format': 'jpeg', 'source': {'bytes': image_bytes}}},
{'text': spatial_prompt}
]
}],
additionalModelRequestFields={
'thinking': {'type': 'adaptive'}
}
)必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:"}
テストセットの50ページにおいて、Novaは176件の名前エントリと4つの写真バウンディングボックスを返しました。これらの名前のほとんどは、ページの他の場所にある名簿や本文の一部です。写真に隣接する名前のみが対応付け可能であるため、Claudeは5つの関連付けを生成しました:
翻訳全文
各関連付けには、空間的なロジックを説明する推論文字列が含まれています。これは、関連付けに失敗したページのデバッグに役立ちます。
ステップ 3: 結果の検証と統合
最終ステップでは、信頼度閾値の適用と、rapidfuzz を用いたファジー名照合により、低品質な関連付けをフィルタリングします。このパイプラインはページごとに 2 つの出力を生成します。1 つは関連付けデータを含む JSON ファイル、もう 1 つは一致した名前と顔の間に線が引かれた可視化画像です。
結果
本パイプラインを通じて、336 ページのスキャンされた学年誌ページを処理しました。その結果、名前から顔への関連付けが合計 3,122 件生成され、そのうち 93.3% が信頼度スコア 0.95 以上を記録しました。信頼度閾値 0.90 を下回ったのはわずか 0.3% でした。
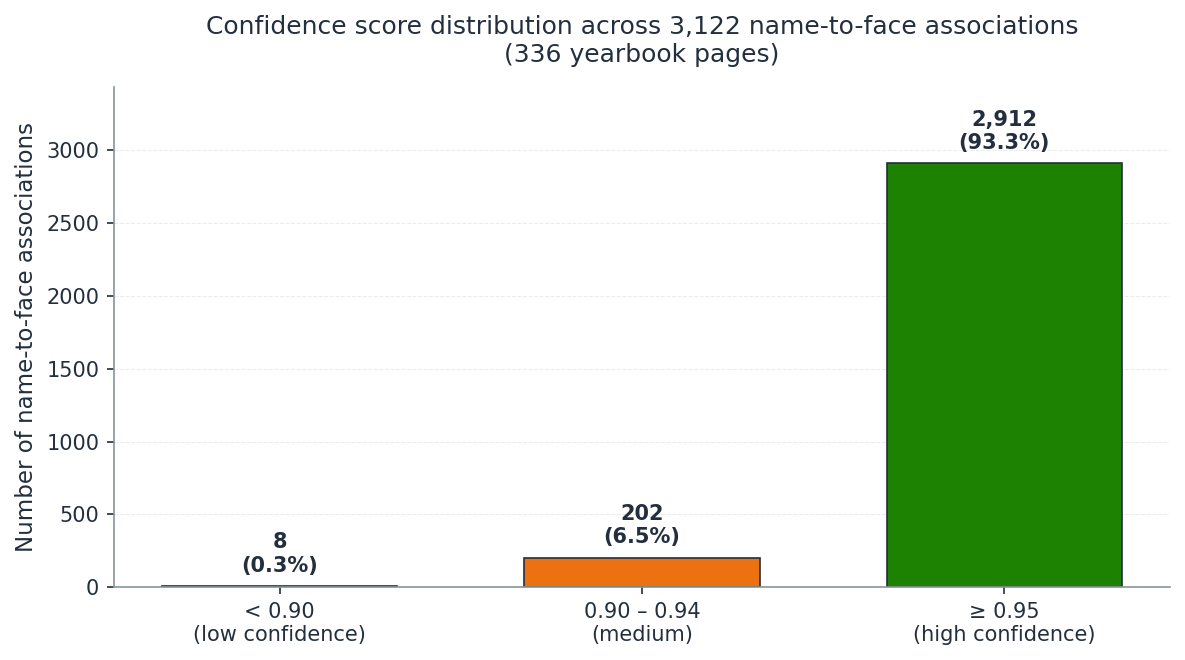
図 2. 336 ページのスキャンされた学年誌ページから生成された 3,122 の名前と顔の対応付けにおける信頼スコアの分布。この分布は高い信頼度側に強く偏っており、2,912 の対応付け(93.3%)が 0.95 以上、202 の対応付け(6.5%)が 0.90 から 0.94 の間、そしてわずか 8 の対応付け(0.3%)が 0.90 を下回っています。Claude Sonnet 4.6 は空間推論ステップ中に信頼スコアを生成しました。これは、特定のトークン化された名前が特定の顔のバウンディングボックスにマッピングされるというモデルの不確実性を反映したものです。** 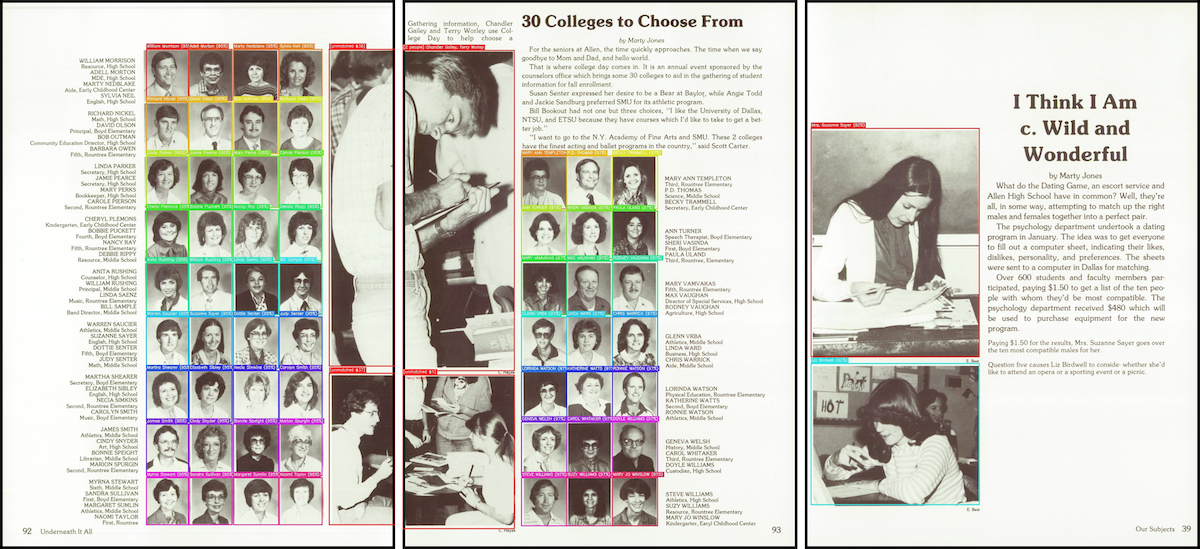 image
image
- ポートレートグリッドページ(336 ページ中 282 ページ)は、1 ページあたり平均 10.9 の関連付けを記録しました。これらのページは名前が対応する写真の直上または直下に配置される規則的なレイアウトであり、パイプラインはこれを確実に処理しました。
- テキストのみで構成されたページ(クラス名簿、イベント説明、索引ページ)には検出対象の写真がなく、正しくスキップされました。
- ポートレートとグループショットが同一ページに混在するレイアウトでは、部分的な関連付けが生じました。パイプラインは名前をポートレート写真にマッチングさせましたが、キャプションが曖昧な場合はグループショットのマッチングを行いませんでした。
パイプラインは各ページごとに JSON レポートと可視化データを出力します。この可視化では、各名前のトークンから対応する顔まで色付きの線で結ばれ、手動レビュー時にエラーを容易に特定できるようになっています。
コストに関する考慮事項
2 つのモデルを分割して使用することで、写真・名前(位置情報付き)・メタデータの抽出呼び出しには Nova 2 Lite の料率が適用され、各ページごとに 1 回の推論呼び出しには Claude の料率が適用されます。Nova 2 Lite の固定画像単価に基づき、第 1 ステージのコストは予測可能であり、入力解像度に依存しません。一方、Claude を用いた推論ステップがページあたりのコストを支配します。
ページ別コスト内訳**
ステージ
サービス
コスト要因
ページあたり概算コスト
写真と名の抽出
Amazon Nova 2 Lite
固定 230 イメージトークン + プロンプト約 500 + 出力約 1,000
約$0.0027
空間推論
Claude Sonnet 4.6
画像 + Nova JSON + 適応型推論トークン
約$0.030
パイプライン合計
約$0.033
以下の表は、各ページを1回の呼び出しで OCR(光学文字認識)、写真検出、空間マッチングの 3 つのタスクすべてを実行させるために Claude に送信する単一モデルアプローチと比較したものです。
次元
2 モデル構成パイプライン
単一モデル Claude
入力トークン
画像(Nova: 固定 230)+ Nova JSON → Claude
画像 @ 約1,500 トークン + プロンプト @ 約1,300 = 約2,800 トークン @ $3/M = 約$0.008
出力トークン
Nova
原文を表示
A scanned yearbook page contains 176 printed names, 4 portrait photographs, and zero machine-readable structure linking them. To digitize this page, you need reliable photo detection with bounding boxes and accurate name extraction. You also need a way to determine which name belongs to which face based on page layout.
In this post, we show how pairing Amazon Nova 2 Lite with Anthropic’s Claude Sonnet 4.6 delivers an efficient solution for digitizing scanned documents at scale. We built a two-model pipeline on Amazon Bedrock for digitizing scanned yearbook pages. Amazon Nova 2 Lite handles native multimodal extraction in a single call: detecting photos, extracting visible names with coordinates, and returning page-level metadata. Claude Sonnet 4.6 then performs spatial reasoning to match names to faces based on page layout.
We ran this pipeline against 336 scanned yearbook pages and produced 3,122 name-to-face associations, with 93 percent scoring at or above 0.95 confidence. This two-model approach costs about two-thirds less per page than a single-model alternative that sends the entire task to one vision-language model. See the Cost considerations section for the detailed breakdown.
Solution overview
The pipeline has two stages. Each stage uses a different model, chosen for the specific task it performs.
Figure 1. Two-model pipeline architecture. The scanned page image flows through two sequential stages. In stage 1, Amazon Nova 2 Lite performs native multimodal extraction in a single API call. It detects and classifies photos with bounding boxes, reads visible names on the page and returns their approximate positions, and emits page-level metadata. In stage 2, Claude Sonnet 4.6 performs spatial reasoning to match names to faces using the combined Nova output.
Amazon Nova 2 Lite runs first. Because it handles interleaved text and images natively, a single Converse call returns three things:
- The detected photos with bounding boxes and classifications.
- The names visible on the page with approximate positions.
- Page-level metadata like titles and categories.
We set reasoning to LOW for this task by including a reasoning configuration in the Converse API call. See the reasoning block in the Step 1 code that follows. Testing across all 336 pages showed no meaningful accuracy difference between LOW, MEDIUM, and HIGH reasoning levels for this structured extraction, and LOW is the cheapest option. Nova exposes this setting through the reasoning_config field. Claude, in Step 2, uses a separate thinking field, so the two models control reasoning under different names.
Asking *Nova 2 Lite* only for names, not every OCR token on the page, is what keeps the first stage cheap. The downstream spatial reasoning step doesn’t need the full text of class rosters or event descriptions. It needs names that appear near photos. Constraining Nova output to names keeps the output-token cost at approximately 1,000 tokens per page instead of the approximated 4,500 tokens a full OCR pass would produce.
Claude Sonnet 4.6 enters only at stage 2 for the spatial reasoning step. Given Nova names-with-positions and photo bounding boxes, Claude determines which names correspond to which faces. This step requires handling page layout variability, because yearbook layouts vary from page to page. Captions might appear above or below photos, and some pages mix portrait grids with group shots. Claude adaptive thinking handles this variability without additional prompt engineering per layout type.
In this solution, Nova 2 Lite handles the high-volume extraction work natively, in one call. Claude is called once per page for the spatial reasoning step.
Nova 2 Lite fixed per-image pricing: Predictable cost at scale
A recent change to how Amazon Nova 2 Lite bills image inputs makes per-page cost predictable at scale, which matters when you are processing hundreds of thousands of pages.
Fixed per-image pricing: Amazon Nova 2 Lite bills image and document page inputs at *a fixed per-image rate*, regardless of resolution or file size.
This change is significant for document processing pipelines. Previously, image token costs varied based on resolution, making it difficult to project per-page costs without running a proof-of-concept on representative samples. With fixed billing, every image Nova 2 Lite processes is billed at the same per-image rate, regardless of resolution.
For a full page extraction including prompt and output, the per-page cost breaks down as follows:
Component
Tokens/Page
Rate
Cost/Page
Image tokens (fixed)
230
$0.30/M input
$0.000069
Prompt tokens (estimated)
500
$0.30/M input
$0.000150
Output tokens (estimated)
1,000
$2.50/M output
$0.0025
Total
~$0.0027
At published Nova 2 Lite input-token rates, image input is a small fraction of total per-page cost. For current rates, see the Amazon Bedrock pricing page.
For yearbook-scale workloads (hundreds of thousands of pages annually), this fixed pricing makes cost forecasting straightforward because image input cost scales linearly with page count and is independent of page resolution. No resolution normalization is required.
Adaptive thinking for spatial reasoning
Claude on Amazon Bedrock supports adaptive thinking, a feature where the model decides how much internal reasoning to apply based on the input complexity. You enable it by setting type to adaptive in the thinking configuration of the Converse API:
response = bedrock_runtime.converse(
modelId='us.anthropic.claude-sonnet-4-6',
messages=[{
'role': 'user',
'content': [
{'image': {'format': 'jpeg', 'source': {'bytes': image_bytes}}},
{'text': spatial_reasoning_prompt}
]
}],
additionalModelRequestFields={
'thinking': {
'type': 'adaptive'
}
}
)With adaptive thinking enabled, Claude adjusts its reasoning depth based on what it receives. A straightforward portrait grid with eight names neatly arranged above eight faces gets a direct response with minimal reasoning. A page where three group photos share a caption block and names appear in a sidebar triggers step-by-step spatial analysis.
In our 336-page run, Claude used extended reasoning on every page, with reasoning traces ranging from 544 to 1,658 characters. Even the simpler pages benefited from some spatial analysis because yearbook layouts are rarely perfectly uniform. The reasoning traces show Claude working through column alignment and vertical offsets between name positions and face positions, and checking caption proximity when group photos appear on the page.
For this type of structured spatial task, adaptive thinking gives you the right amount of reasoning per page without manual tuning. You don’t need to set a fixed token budget or write layout-specific prompts. The model reads the inputs and decides.
Cost note on adaptive thinking: When adaptive thinking is enabled, keep three cost factors in mind.
- Reasoning tokens are billed as output tokens at the standard output rate ($15.00/M output tokens for Claude Sonnet 4.6 through cross-Region inference).
- Reasoning traces are returned in the API response under a separate thinking content block, but aren’t shown to end users.
- Monitor inputTokens and outputTokens in the response metadata to track actual cost per page, because reasoning can significantly increase output token counts on complex pages.
Implementation walkthrough
The full source code, sample images, and Jupyter notebook are available in the AWS Samples repository on GitHub.
Prerequisites
Before running the pipeline, make sure that you have the following in place:
- An AWS account with access to Amazon Bedrock in an AWS Region where Amazon Nova 2 Lite and Claude Sonnet 4.6 are available.
- Model access enabled in the Amazon Bedrock console for both us.amazon.nova-2-lite-v1:0 and us.anthropic.claude-sonnet-4-6.
- An AWS Identity and Access Management (IAM) principal with permission to call bedrock:InvokeModel and bedrock:Converse on the preceding two models.
- Python 3.10 or later with the boto3 SDK installed. The sample notebook also uses rapidfuzz for fuzzy name matching and Pillow for visualization overlays.
- Scanned page images (JPEG or PNG). For image input through the Converse API, image bytes are passed inline in the request.
Step 1: Detect photos and extract names with Amazon Nova 2 Lite
Send the scanned page to Amazon Nova 2 Lite with a prompt that requests both detected photos (with bounding boxes and classifications) and visible names (with approximate positions on the page). Nova native multimodal understanding returns both in a single Converse call.
Nova returns bounding boxes on a 0–1000 coordinate scale for both photos and names. Pass both directly into Step 2. Claude reads the same coordinate space when given in the prompt, so no conversion is needed.
def extract_photos_and_names(image_bytes):
"""Detect photos and extract visible names with Amazon Nova 2 Lite."""
# Using the Converse API consistently for all Bedrock calls
response = bedrock_runtime.converse(
modelId='us.amazon.nova-2-lite-v1:0',
# Note: cross-region inference profile (us.amazon.nova-2-lite-v1:0)
messages=[{
'role': 'user',
'content': [
{
'image': {
'format': 'jpeg',
'source': {'bytes': image_bytes}
}
},
{'text': PHOTO_AND_NAME_EXTRACTION_PROMPT}
]
}],
inferenceConfig={
'maxTokens': 8000,
'temperature': 0
},
additionalModelRequestFields={
'reasoning_config': {
'type': 'enabled',
'level': 'LOW'
}
}
)
raw = response['output']['message']['content'][0]['text']
return json.loads(raw)The prompt instructs Nova to return a JSON object with both the photos and the names visible on the page.
{
"page_title": "Junior Class Officers",
"photos": [
{
"bbox": [245, 180, 410, 520],
"type": "portrait",
"category": "class_officers",
"summary": "Individual portrait photo"
}
],
"names": [
{
"text": "Cecilia Phillips",
"bbox": [260, 540, 395, 570]
},
{
"text": "John Kolander",
"bbox": [420, 540, 555, 570]
}
]
}Each photo gets a bounding box, a type (portrait, group, or candid), a category tag, and a short description. Each name gets its visible text and its bounding box on the page. The page_title and category fields also serve a second use case: metadata extraction. With one API call, Nova 2 Lite gives you photo detection, names-with-positions for the matching pipeline, and structured metadata. You can use this metadata for search indexing, filtering by event type, or building a table of contents across hundreds of pages.
Step 2: Match names to faces with Claude
Now pass Nova names-with-positions and photo bounding boxes to Claude for spatial reasoning. Both use the same 0–1000 coordinate space, so no normalization is needed:
spatial_prompt = f"""Given these names with page coordinates:
{json.dumps(ocr_tokens)}
And these detected photos with bounding boxes:
{json.dumps(photo_detections)}
Match each person's name to their photo based on spatial position.
Return JSON: {{"associations": [{{"name": str, "face_idx": int,
"confidence": float, "reasoning": str}}]}}"""
response = bedrock_runtime.converse(
modelId='us.anthropic.claude-sonnet-4-6',
messages=[{
'role': 'user',
'content': [
{'image': {'format': 'jpeg', 'source': {'bytes': image_bytes}}},
{'text': spatial_prompt}
]
}],
additionalModelRequestFields={
'thinking': {'type': 'adaptive'}
}
)On page 50 of our test set, Nova returned 176 name entries and 4 photo bounding boxes. Most of those names are roster and body text elsewhere on the page. Only the names adjacent to the 4 photos are matchable, so Claude produced 5 associations:
{
"associations": [
{"name": "Cecilia Phillips", "face_idx": 0, "confidence": 0.95,
"reasoning": "Row 0, position 1 of 3 - matches caption above photo"},
{"name": "John Kolander", "face_idx": 1, "confidence": 0.95,
"reasoning": "Row 0, position 2 of 3 - matches caption above photo"},
{"name": "Julie Ostrander", "face_idx": 2, "confidence": 0.95,
"reasoning": "Row 0, position 3 of 3 - matches caption above photo"}
]
}Each association includes a reasoning string that explains the spatial logic. This is useful for debugging pages where associations fail.
Step 3: Validate and assemble results
The final step applies confidence thresholds and fuzzy name matching (using rapidfuzz) to filter out low-quality associations. The pipeline writes two outputs per page: a JSON file with the association data and a visualization image showing lines drawn between matched names and faces.
Results
We processed 336 scanned yearbook pages through this pipeline. The pipeline produced 3,122 name-to-face associations total, with 93.3 percent of those associations scoring confidence at or above 0.95. Only 0.3 percent fell below the 0.90 confidence threshold.
Figure 2. Confidence score distribution across the 3,122 name-to-face associations produced from 336 scanned yearbook pages. The distribution is heavily skewed toward high confidence: 2,912 associations (93.3 percent) scored at or above 0.95, 202 (6.5 percent) scored between 0.90 and 0.94, and only 8 (0.3 percent) fell below 0.90. Claude Sonnet 4.6 produced confidence scores during the spatial reasoning step. They reflect the model’s certainty that a given name token maps to a specific face bounding box.**
- Portrait grid pages (282 of 336 pages) averaged 10.9 associations per page. These pages have a regular layout where names appear directly above or below corresponding photos, and the pipeline handled them reliably.
- Text-only pages (class rosters, event descriptions, index pages) had no photos to detect and were correctly skipped.
- Mixed-layout pages with portraits and group shots on the same page produced partial associations. The pipeline matched names to portrait photos but left group shots unmatched when captions were ambiguous.
The pipeline outputs a JSON report and a visualization for each page. The visualization draws colored lines from each name token to its matched face, which makes it easy to spot errors during manual review.
Cost considerations
The two-model split means that you pay Nova 2 Lite rates for the combined extraction call (photos, names-with-positions, metadata) and Claude rates for one reasoning call per page. Under Nova 2 Lite’s fixed per-image pricing, the first stage cost is predictable and independent of input resolution. Claude reasoning step dominates per-page cost.
Per-page cost breakdown**
Stage
Service
Cost Driver
Approximate Cost/Page
Photo + name extraction
Amazon Nova 2 Lite
Fixed 230 image tokens + ~500 prompt + ~1,000 output
~$0.0027
Spatial reasoning
Claude Sonnet 4.6
Image + Nova JSON + adaptive reasoning tokens
~$0.030
Pipeline total
~$0.033
The following table compares the pipeline against a single-model approach where each page is sent to Claude to do all three tasks (OCR, photo detection, and spatial matching) in one call.
Dimension
Two-model pipeline
Single-model Claude
Input tokens
Image (Nova: 230 fixed) + Nova JSON → Claude
Image @ ~1,500 tokens + prompt @ ~1,300 = ~2,800 tokens @ $3/M = ~$0.008
Output tokens
Nova
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み